2026년 4월 29일 | AI 최신 트렌드
2026년 4월 29일 기준으로 내가 고른 흐름은 창작 도구에 직접 붙는 Claude, 오픈소스 음성 모델 VibeVoice, YouTube의 안내형 AI 검색, 에이전트 결제 인증, 국방 목적 AI 계약, 표 검색 견고성 논문이다. 선정 기준은 새 모델 이름보다 실행 권한, 사용자 접점, 검증 장치가 어디까지 내려왔는지였다.
겉으로는 제품 뉴스, 오픈소스 저장소, 보안 표준, 정책 논란, 논문이 따로 움직이는 것처럼 보인다. 그런데 한 칸 뒤로 물러나면 전부 같은 방향을 가리킨다. AI가 텍스트 답변을 잘하는 단계를 지나, 실제 앱을 조작하고, 영상을 골라 주고, 결제를 대신하고, 고위험 조직의 업무 표면으로 들어가며, 검색 시스템 내부의 표현 안정성까지 건드리고 있다. 나는 이런 날일수록 성능표보다 어떤 권한을 위임받았고, 어디서 검증되며, 실패하면 누가 멈추는가를 먼저 보게 된다.
1. Claude 창작 커넥터: 챗봇이 Photoshop과 Blender 안으로 들어가는 방식

Figure 1. Claude의 창작 도구 커넥터는 대화창 바깥의 실제 제작 앱을 조작 대상으로 삼는다.
The Verge에 따르면 Anthropic은 Claude가 Adobe Creative Cloud, Affinity, Blender, Ableton, Autodesk 같은 창작 도구에 연결될 수 있는 커넥터 묶음을 내놨다. 문서를 읽어 주는 수준을 넘어, 앱에 접근하고, 데이터를 가져오고, 연결된 서비스 안에서 행동을 실행하는 구조다. Blender 커넥터는 장면을 디버깅하거나 새 도구를 만들고, 여러 객체 변경을 일괄 적용하는 식의 작업을 Claude 인터페이스에서 다룰 수 있다고 설명된다.
나는 이 소식을 보면서 Claude가 업무용 문서나 코드 편집기에서 창작 툴 체인으로 이동하는 장면이 꽤 선명하다고 느꼈다. 창작자는 보통 한 앱 안에서만 일하지 않는다. Photoshop에서 이미지 레이어를 만지고, Blender에서 3D 장면을 조정하고, Ableton에서 오디오 흐름을 확인한다. AI가 여기 붙는다는 건 답변 생성보다 제작 과정의 중간 상태를 읽고 고치는 권한을 얻는다는 뜻이다.
재미있는 대목은 Anthropic이 Blender Foundation에 지원금을 제공한다는 점도 함께 보도됐다는 사실이다. 오픈소스 창작 도구와 프런티어 모델 회사의 관계가 단순 API 연동을 넘어 후원과 생태계 장악 사이 어딘가로 넓어지는 느낌이 있다. 앞으로 창작 AI 경쟁은 모델이 이미지를 얼마나 잘 만드는지뿐 아니라, 기존 제작 툴의 파일 구조와 작업 습관을 얼마나 덜 망가뜨리며 끼어드는지에서 갈릴 가능성이 크다.
원문: The Verge - Claude can now plug directly into Photoshop, Blender, and Ableton
2. VibeVoice: 긴 대화형 음성을 오픈소스 연구 프레임으로 밀어붙이는 흐름
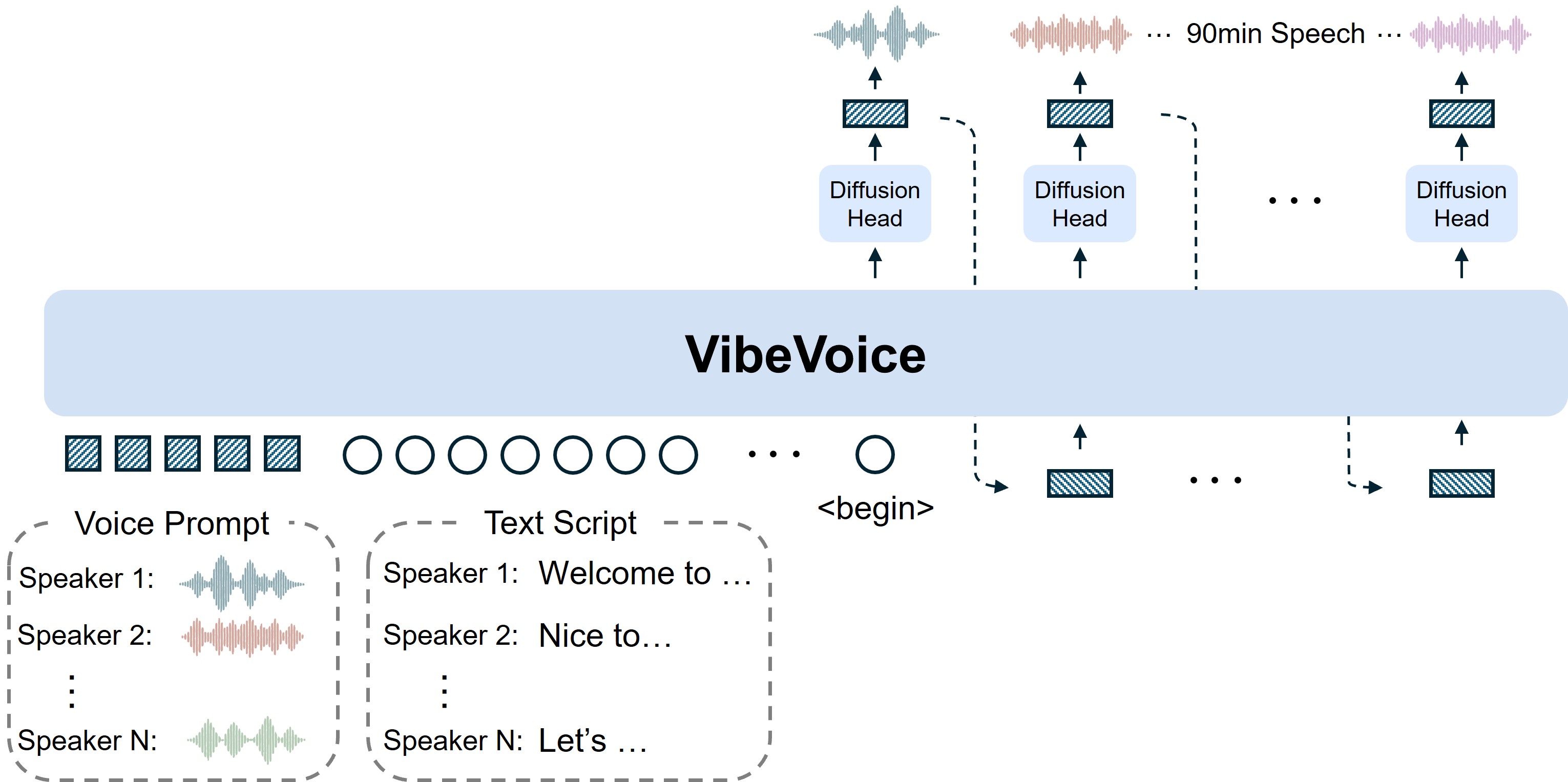
Figure 2. VibeVoice는 긴 형식의 다중 화자 대화 음성을 생성하는 오픈소스 음성 AI 프레임으로 소개된다.
Microsoft의 VibeVoice 저장소가 Hacker News에서 크게 올라왔다. 프로젝트 페이지 설명을 보면 VibeVoice는 팟캐스트 같은 긴 형식의 다중 화자 대화 음성을 텍스트에서 생성하기 위한 프레임워크다. 핵심 설명은 꽤 기술적이다. Acoustic token과 Semantic token을 쓰는 연속 음성 토크나이저를 7.5Hz라는 낮은 프레임레이트로 운용해, 긴 시퀀스를 다룰 때 계산 효율과 음질을 동시에 잡으려 한다.
음성 AI는 이미 데모가 많아서 새 저장소 하나만으로 놀라기는 어렵다. 그래도 VibeVoice가 눈에 들어온 이유는 긴 대화, 화자 일관성, 자연스러운 턴테이킹을 한꺼번에 전면에 둔 점 때문이다. 짧은 TTS 문장과 달리 팟캐스트나 인터뷰형 음성은 몇 분만 지나도 화자 톤이 흔들리고, 누가 언제 말하는지 어색해지며, 문장 사이 호흡이 티가 난다. 이 문제를 모델 크기 하나로만 밀어붙이지 않고 음성 표현 단위와 긴 시퀀스 처리의 문제로 잡는 점이 실무적으로 더 중요해 보인다.
README에는 VibeVoice-ASR 쪽도 함께 보인다. 긴 오디오를 한 번에 처리하고, 누가 말했는지, 언제 말했는지, 무엇을 말했는지를 구조화된 전사로 내는 방향이다. 생성과 인식이 모두 긴 형식으로 가면, 음성 AI는 짧은 클립 생성 도구보다 회의, 팟캐스트, 상담, 교육 콘텐츠의 전체 파이프라인에 가까워진다. 다만 오픈소스 음성 모델은 악용 가능성도 빨리 따라붙는다. 그래서 나는 이런 저장소를 볼 때 성능 데모만큼이나 라이선스, 사용 제한, 워터마킹, 공개 모델 배포 방식도 같이 봐야 한다고 느낀다.
원문: GitHub - microsoft/VibeVoice · VibeVoice project page
3. YouTube AI 검색: 검색 결과가 영상 목록에서 안내형 답변으로 바뀌는 순간

Figure 3. YouTube의 Ask YouTube 실험은 영상 검색을 텍스트·짧은 영상·긴 영상이 섞인 안내형 답변으로 바꾼다.
TechCrunch는 YouTube가 Ask YouTube라는 AI 검색 실험을 미국 Premium 가입자 일부에게 제공한다고 전했다. 예시는 “샌프란시스코에서 산타바바라까지 3일 로드트립을 계획해 줘” 같은 질의다. 기존 검색처럼 영상 목록만 보여 주는 대신, 텍스트 설명, 짧은 영상, 긴 영상, 관련 구간, 채널 정보를 섞어 단계별 결과를 보여 주고, 사용자는 “커피는 어디가 좋아?” 같은 후속 질문도 던질 수 있다.
이 변화는 YouTube에 챗봇 하나를 얹은 정도로만 보기 어렵다. YouTube는 이미 세계에서 가장 큰 실전 지식 저장소 중 하나다. 레시피, 여행, 수리, 운동, 악기, 강의처럼 영상으로 배우는 검색은 텍스트 웹 검색과 다르게 움직인다. AI가 이 표면에 들어가면 문제는 답변 생성이 아니라 어느 영상의 어느 구간을 어떤 순서로 보여 줄 것인가가 된다. 즉 추천 알고리즘과 검색 요약이 한 화면에서 섞인다.
나는 이 기능이 크리에이터 발견 방식도 바꿀 수 있다고 본다. AI가 영상 전체를 답으로 압축하면 편하지만, 잘못 설계하면 사용자는 원본 영상을 클릭하지 않고 요약만 소비할 수도 있다. 반대로 적절한 구간과 채널 정보를 같이 보여 주면, 긴 영상 검색의 진입 장벽을 낮춰 새 크리에이터를 발견하게 만들 수도 있다. 결국 YouTube AI 검색의 핵심은 답을 보여 주는 속도와 원본 영상 생태계의 유입을 어떻게 동시에 맞추느냐에 있다.
원문: TechCrunch - YouTube is testing an AI-powered search feature that shows guided answers
4. 에이전트 결제 인증: AI에게 카드를 맡기기 전에 필요한 암호학적 의도 증명

Figure 4. FIDO Alliance, Google, Mastercard의 움직임은 에이전트 상거래에 인증 표준이 먼저 필요하다는 신호다.
WIRED는 FIDO Alliance가 Google과 Mastercard의 초기 기여를 바탕으로 AI 에이전트가 수행하는 결제와 거래를 검증하기 위한 워킹그룹을 띄운다고 보도했다. 핵심은 사용자가 에이전트에게 “재입고되면 100달러 이하로 이 운동화를 사 줘”라고 맡겼을 때, 실제 결제 순간에 그 거래가 사용자의 의도였다는 암호학적 증거를 남기는 것이다.
Google은 Agent Payments Protocol, 줄여서 AP2를 기여하고, Mastercard는 Verifiable Intent 프레임워크를 내놓는다. 기사 설명에 따르면 방향은 단순 승인에 머물지 않고 선택적 공개까지 포함한다. 플랫폼, 상점, 결제망, 결제 서비스가 각자 필요한 정보만 보고도 “이 행동은 사용자가 인증한 범위 안에 있다”고 확인할 수 있어야 한다. 나는 이 부분이 꽤 중요하다고 봤다. 에이전트 상거래에서 가장 무서운 실패는 카드가 한 번 잘못 긁히는 것보다, 어떤 지시가 진짜 사용자 의도였는지 나중에 증명할 수 없는 상태다.
비밀번호가 웹의 기본 보안 구조로는 너무 오래 버틴 것처럼, 에이전트 결제도 초기에 대충 붙이면 나중에 고치기가 어렵다. FIDO 쪽이 이 문제를 빨리 잡으려는 이유도 여기에 있다. 나는 앞으로 “AI 에이전트가 대신 구매한다”는 데모가 나올 때마다 장바구니 UX보다 승인 범위, 철회 방법, 거래 로그, 선택적 공개를 먼저 확인하게 될 것 같다. 에이전트가 실제 돈을 움직이는 순간부터는 자연어 프롬프트만으로는 부족하다.
원문: WIRED - The Race Is on to Keep AI Agents From Running Wild With Your Credit Cards
5. Google과 Pentagon 계약 보도: 고위험 사용 경계가 다시 협상 테이블로 올라옴

Figure 5. Google과 미 국방부 계약 보도는 모델 공급자가 고위험 사용 범위를 어디까지 통제할 수 있는지 묻는다.
The Verge는 Google이 미국 국방부가 자사 AI 모델을 “합법적인 정부 목적”에 사용할 수 있도록 하는 기밀 계약을 맺었다고 보도했다. 보도에 따르면 이 계약은 Google이 정부 사용 방식을 사전에 거부할 권리를 갖는 형태가 아닌 것으로 전해졌다. 같은 맥락에서 Anthropic은 무기와 감시 관련 가드레일 제거 요구를 거부한 뒤 Pentagon 쪽에서 배제됐다는 설명도 함께 나온다.
이 뉴스는 Project Maven 이후 반복되는 질문을 다시 끌어올린다. 모델 회사가 공공기관이나 국방 조직에 기술을 공급할 때, 공급자는 어느 지점까지 사용 범위를 제한할 수 있을까. “합법적 목적”이라는 말은 넓다. 실제 사용 환경에서는 법적 허용, 내부 정책, 직원 반발, 국제 인권 기준, 모델 안전 정책이 한꺼번에 부딪힌다. 그래서 이 계약 보도는 특정 회사 하나의 문제가 아니라 프런티어 모델의 정부 사용권이 어떻게 팔리고 제한되는가를 보여 주는 장면에 가깝다.
나는 여기서 기업용 AI 계약의 다음 충돌 지점을 본다. 일반 기업 고객에게도 데이터 사용 제한과 책임 조항이 복잡한데, 국방·정보·치안 영역으로 가면 모델의 출력보다 사용 권한, 감사 로그, 금지 작업, 공급자 veto 권한이 더 중요해진다. 기술적으로는 같은 모델 API라도, 어떤 조직에 어떤 조건으로 열리는지에 따라 완전히 다른 제품이 된다.
원문: The Verge - Google and Pentagon reportedly agree on deal for ‘any lawful’ use of AI
6. 표 검색 견고성 논문: CSV와 HTML이 같은 표라도 검색 임베딩은 달라진다

Figure 6. 같은 표를 CSV, TSV, HTML, JSON으로 표현해도 retriever 임베딩 공간에서는 서로 다른 위치로 밀릴 수 있다.
Hugging Face Daily Papers 쪽에서 고른 논문은 Improving Robustness of Tabular Retrieval via Representational Stability다. 문제 설정이 실무적으로 좋다. Transformer 기반 table retriever는 표를 결국 1차원 토큰 시퀀스로 평탄화해야 한다. 그런데 같은 표라도 CSV, TSV, HTML, JSON처럼 직렬화 방식이 달라지면 의미는 같아도 임베딩 위치와 검색 순위가 흔들릴 수 있다.
저자들은 이 문제를 전처리 취향 정도가 아니라 검색 시스템의 1차 변수로 본다. 여러 serialization view의 임베딩을 평균낸 centroid를 format-agnostic한 안정 앵커로 보고, 매번 여러 표현을 모두 인코딩하지 않아도 되도록 residual bottleneck adapter가 그 평균 효과를 근사하게 만든다. 논문은 네 종류의 retriever family에서 serialization에 따른 불안정성을 측정하고, representation stability 관점으로 성능을 다시 잡으려 한다.
나는 이 논문이 RAG와 엔터프라이즈 검색에서 꽤 현실적인 문제를 건드린다고 봤다. 회사 문서 안의 표는 깔끔한 데이터프레임보다 PDF, HTML, CSV export, 위키 테이블, 복사 붙여넣기 조각으로 흩어지는 경우가 많다. 사람이 보기에는 같은 표라도 retriever가 다르게 읽으면, 답변 단계에서는 “왜 이 표를 못 찾았지?” 같은 허무한 실패가 난다. 결국 표 검색의 품질은 모델 크기만이 아니라 같은 구조 정보를 다른 표면으로 표현했을 때 임베딩이 얼마나 덜 흔들리는가에 달려 있다.
원문: arXiv - Improving Robustness of Tabular Retrieval via Representational Stability · HTML 본문
7. 묶어서 보면: AI의 다음 병목은 권한과 표현 안정성
여섯 소식을 한 줄로 묶으면, AI가 더 많은 권한을 얻는 동시에 더 단단한 표현과 검증 장치를 요구받기 시작했다는 이야기다. Claude는 창작 도구 안의 객체를 만지려 하고, VibeVoice는 긴 음성 파이프라인을 열어 둔다. YouTube는 검색 결과를 안내형 답변으로 바꾸고, FIDO·Google·Mastercard는 에이전트가 돈을 움직일 때 필요한 의도 증명을 만들려 한다. Google과 Pentagon 계약 보도는 고위험 사용권의 통제 문제를 드러내고, 표 검색 논문은 같은 정보라도 표현 방식이 바뀌면 검색 품질이 흔들린다는 점을 짚는다.
그래서 당분간 나는 AI 뉴스를 읽을 때 “무엇을 생성했나”보다 무엇을 대신 실행하게 됐나와 그 실행의 근거가 얼마나 안정적인가를 같이 보려고 한다. 앱 조작, 결제, 국방 사용, 검색, 음성 생성은 서로 다른 분야처럼 보여도, 실제 운영에서는 모두 같은 질문으로 돌아온다. 사용자가 맡긴 의도는 어디에 기록되는가. 모델이 읽은 정보는 표면이 바뀌어도 같은 의미로 남는가. 그리고 실패했을 때 멈출 수 있는 장치가 있는가.
출처
- The Verge | Claude can now plug directly into Photoshop, Blender, and Ableton
- GitHub | microsoft/VibeVoice
- Microsoft VibeVoice project page
- TechCrunch | YouTube is testing an AI-powered search feature that shows guided answers
- WIRED | The Race Is on to Keep AI Agents From Running Wild With Your Credit Cards
- The Verge | Google and Pentagon reportedly agree on deal for ‘any lawful’ use of AI
- arXiv | Improving Robustness of Tabular Retrieval via Representational Stability