Fast-dLLM v2: Efficient Block-Diffusion LLM
https://arxiv.org/abs/2509.26328 | HTML | GitHub | Project Page
Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo Molchanov, Ping Luo, Song Han, Enze Xie | The University of Hong Kong, NVIDIA, MIT | arXiv:2509.26328 | 2025년 9월 | ICLR 2026 게재 확정
1. 서론
오토리그레시브(Autoregressive, AR) 대규모 언어 모델(LLM)은 GPT 시리즈, Qwen, LLaMA 등으로 대표되는 현대 자연어 처리의 지배적 패러다임이다. 이들 모델은 다음 토큰 예측(next-token prediction)이라는 단순하면서도 강력한 학습 목표를 통해 유창하고 일관된 텍스트를 생성하는 능력을 갖추었으며, 코드 생성, 수학적 추론, 지식 기반 질의응답 등 광범위한 과제에서 뛰어난 성능을 보여주고 있다. 그러나 AR 모델은 태생적인 한계를 가지고 있다. 토큰이 엄격한 좌에서 우로(left-to-right) 순서로 하나씩 순차적으로 생성되기 때문에, 디코딩 과정에서 하드웨어의 병렬 처리 능력을 충분히 활용할 수 없다. 이러한 순차적 디코딩의 비효율성은 실시간 응답이 요구되는 실용적 배포 환경에서 심각한 병목으로 작용하며, 특히 긴 텍스트를 생성해야 하는 상황에서 추론 지연(inference latency)이 크게 증가한다.
이러한 한계를 극복하기 위한 대안으로 디퓨전 기반 언어 모델(diffusion-based Language Model, dLLM)이 주목받고 있다. 디퓨전 언어 모델은 여러 토큰을 동시에 예측하거나 반복적으로 정제(refine)하는 방식으로 텍스트를 생성함으로써, 원리적으로 AR 모델보다 훨씬 높은 디코딩 병렬성을 달성할 수 있다. Google DeepMind의 Gemini Diffusion, Inception Labs의 Mercury, LLaDA, Dream 등이 이 범주에 속하는 대표적인 모델들이다. 그러나 기존 디퓨전 언어 모델들은 실전 배포에 있어 여러 심각한 문제를 안고 있었다. 양방향 어텐션(bidirectional attention) 구조로 인해 AR 모델에서 핵심적인 효율화 기법인 KV 캐시(Key-Value cache)를 효과적으로 활용할 수 없으며, 실제 추론 지연이 AR 모델을 상회하는 경우가 빈번하고, 고정된 시퀀스 길이를 요구하거나 생성 길이의 유연성이 제한되는 등의 한계가 존재하였다.
이 두 패러다임의 장점을 결합하기 위해 블록 디퓨전 언어 모델(Block Diffusion Language Model)이라는 중간 지대의 접근법이 제안되었다. BD3-LM(Block Diffusion for Discrete Data)으로 대표되는 이 접근법은 시퀀스를 블록 단위로 분할하여, 블록 내부에서는 디퓨전 방식으로 여러 토큰을 병렬 생성하고 블록 간에는 AR 방식으로 순차적 의존성을 유지한다. 이를 통해 가변 길이 생성과 블록 간 KV 캐싱이 가능해져 추론 효율이 개선된다. 그러나 BD3-LM은 소규모 모델과 전통적인 언어 모델링 메트릭에서만 검증되었을 뿐, 현대적인 대규모 LLM 환경에서의 실용적 적용 가능성은 불명확하였다.
본 논문은 이러한 배경에서 Fast-dLLM v2를 제안한다. Fast-dLLM v2는 사전학습된 AR 모델을 블록 디퓨전 LLM으로 효율적으로 변환하는 체계적인 프레임워크로, 기존 접근법들과 비교하여 세 가지 핵심적인 차별점을 갖는다. 첫째, 극도의 데이터 효율성이다. Dream과 같은 전체 어텐션 디퓨전 LLM이 약 500B(5,000억) 토큰의 미세조정을 필요로 하는 반면, Fast-dLLM v2는 불과 약 1B(10억) 토큰의 미세조정만으로 무손실(lossless) 적응을 달성한다. 이는 학습 데이터량 기준으로 약 500배에 달하는 압도적인 효율성 개선이다. 둘째, 블록와이즈 상보적 마스킹(complementary masking)과 결합된 새로운 훈련 레시피를 통해 블록 내 양방향 컨텍스트 모델링을 가능하게 하면서도 원본 AR 모델의 학습 목표와 예측 성능을 동시에 보존한다. 셋째, 계층적 캐싱 메커니즘(hierarchical caching mechanism)과 병렬 디코딩 파이프라인을 통해 표준 AR 디코딩 대비 최대 2.5배의 속도 향상을 달성하면서도 생성 품질의 저하가 없다.

Figure 1(a): Fast-dLLM v2의 성능 비교. A100 GPU에서 기존 모델 및 Fast-dLLM 변형들의 처리량과 GSM8K 정확도를 비교한다. Fast-dLLM v2 (7B)는 Qwen2.5-7B-Instruct 대비 2.54배 높은 처리량을 달성하면서 동등한 정확도를 제공하며, LLaDA 기반의 Fast-dLLM-LLaDA 대비 +5.2%의 정확도 향상을 보인다.
Figure 1(a)는 Fast-dLLM v2의 핵심적인 포지셔닝을 시각적으로 보여준다. 가로축은 처리량(tokens/s), 세로축은 GSM8K 수학 추론 정확도(%)를 나타내며, Fast-dLLM v2 (7B)는 그래프의 우상단에 위치하여 높은 처리량과 높은 정확도를 동시에 달성함을 보여준다. 구체적으로, Qwen2.5-7B-Instruct와 비교하여 정확도는 거의 동등한 수준(약 83.7% 대 84.1%)을 유지하면서 처리량은 2.54배 높다. 또한 LLaDA(8B)를 기반으로 최적화한 Fast-dLLM-LLaDA와 비교해서도 +5.2%의 정확도 개선을 달성하였다. Dream(7B)이나 LLaMA-3-8B 등 다른 경쟁 모델들은 낮은 처리량 또는 낮은 정확도 영역에 위치하고 있어, Fast-dLLM v2가 효율성과 성능의 파레토 최적점에 가장 가까이 위치함을 확인할 수 있다.
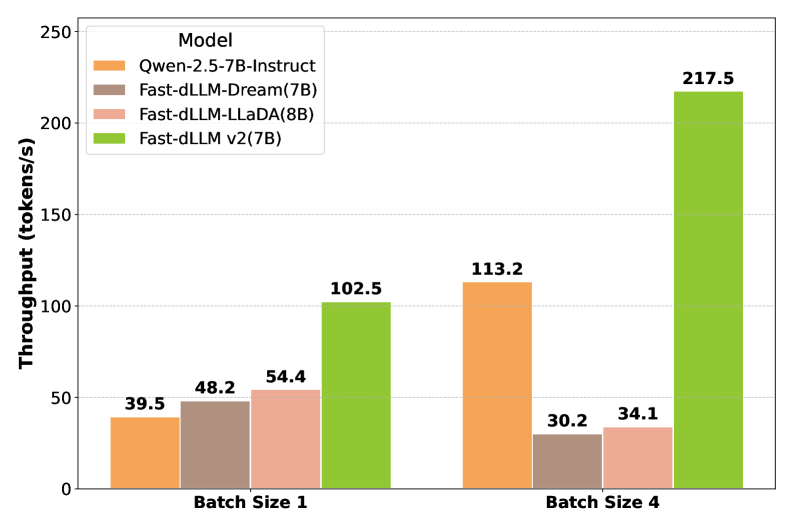
Figure 1(b): 배치 크기 1과 4에서의 처리량 비교. Fast-dLLM v2는 두 배치 크기 모두에서 모든 기존 모델을 크게 능가하며, 특히 배치 크기 4에서 뛰어난 확장성과 효율성을 보인다.
Figure 1(b)의 막대 그래프는 배치 크기에 따른 처리량 비교를 보여준다. Fast-dLLM v2 (7B)는 배치 크기 1에서 약 102.5 tokens/s, 배치 크기 4에서 약 217.5 tokens/s를 달성하여 모든 비교 대상 모델을 압도한다. 특히 주목할 점은 배치 크기가 증가할 때의 확장성인데, AR 기반의 Qwen2.5-7B-Instruct는 배치 크기 증가에 따른 처리량 증가가 제한적인 반면 Fast-dLLM v2는 거의 선형에 가까운 확장성을 보여준다. 이는 블록 디퓨전 방식의 내재적 병렬성이 배치 처리 환경에서 효과적으로 활용됨을 의미한다.
1.1 논문의 주요 기여
본 논문의 기여를 정리하면 다음의 세 가지로 요약된다. 첫째, 블록와이즈 어텐션 설계가 AR 모델과 친화적인 구조를 갖는다는 사실을 규명하고, 이를 바탕으로 사전학습된 AR 모델을 블록 디퓨전 프레임워크로 변환하는 후처리 학습(post-training) 전략을 제시하였다. 이 전략은 전체 재학습 대신 저비용의 미세조정만을 필요로 하며, 구체적으로 Fast-dLLM v2는 약 1B 토큰의 미세조정으로 무손실 적응을 달성한다. 이는 Dream이 요구하는 약 500B 토큰과 비교하여 500배의 학습 데이터 절감을 의미한다. 둘째, 계층적 캐싱 메커니즘과 블록와이즈 병렬 디코딩을 결합한 추론 전략을 도입하였다. 블록 간 컨텍스트의 효과적 재사용과 블록 내 토큰 생성의 가속을 동시에 가능하게 하여, 기존 디퓨전 기반 방법들보다 실질적으로 빠른 추론을 실현한다. 셋째, 최대 7B 파라미터 규모의 모델과 다양한 과제에 대한 포괄적인 대규모 실험을 수행하여, Fast-dLLM v2가 표준 AR 디코딩 대비 최대 2.5배 속도 향상을 달성하면서도 동등한 생성 품질을 유지함을 실증적으로 입증하였다.
2. 배경 및 관련 연구
2.1 AR 모델의 추론 병목: 왜 디퓨전이 필요한가
디퓨전 기반 언어 모델이 왜 주목받는지를 이해하기 위해, 먼저 AR 모델의 추론 병목을 정량적으로 분석할 필요가 있다. AR 모델은 각 토큰 생성 시 전체 모델의 전방 패스(forward pass)를 한 번 실행해야 한다. 7B 파라미터 모델이 512 토큰을 생성하려면 512번의 순차적 전방 패스가 필요하며, 각 전방 패스에서 모델의 모든 계층을 통과해야 하므로 총 계산량은 생성 길이에 선형적으로 비례한다. 현대 GPU의 연산 능력(FLOPS)은 매우 높지만, AR 디코딩에서의 병목은 연산량이 아니라 메모리 대역폭에 있다. 단일 토큰 생성 시 전체 모델의 가중치를 메모리에서 읽어야 하므로, GPU의 HBM(High Bandwidth Memory)에서 연산 유닛으로의 데이터 전송 속도가 병목이 된다. 이를 "메모리 바운드(memory-bound)" 문제라고 하며, 배치 크기가 작을 때 특히 심각하다.
디퓨전 언어 모델은 한 번의 전방 패스에서 여러 토큰을 동시에 처리할 수 있으므로, 동일한 메모리 대역폭 비용으로 더 많은 토큰을 생성할 수 있다. 이는 AR 모델의 근본적인 메모리 바운드 문제를 완화하는 핵심 메커니즘이다. 그러나 기존 전체 어텐션 기반 디퓨전 모델들은 양방향 어텐션으로 인해 KV 캐시를 활용할 수 없어, 매 디노이징 스텝마다 전체 시퀀스에 대한 어텐션을 새로 계산해야 하는 비효율성을 갖는다. 이로 인해 이론적인 병렬 처리 이점이 실제 속도 향상으로 이어지지 못하는 경우가 많았다. Fast-dLLM v2의 블록 디퓨전 접근법은 블록 간 KV 캐시를 유지하면서 블록 내에서만 디퓨전의 병렬성을 활용함으로써, 이론과 실제의 간극을 메우는 데 성공한다.
2.2 마스크 디퓨전 언어 모델
디퓨전 모델을 이산 데이터(discrete data)에 적용하려는 시도는 Sohl-Dickstein et al.(2015)과 Hoogeboom et al.(2021)의 선구적 연구에서 시작되었다. 이후 D3PM(Discrete Denoising Diffusion Probabilistic Models)(Austin et al., 2021)이 일반적인 전이 행렬 $\boldsymbol{Q}_t$를 사용한 이산 상태 마르코프 체인으로 정의되는 순방향 과정을 통해 이 개념을 일반화하였으며, CTMC(Campbell et al., 2022)가 이를 연속 시간으로 확장하였다. SEDD(Score Entropy Discrete Diffusion)(Lou et al., 2023)는 우도비(likelihood ratio) $\frac{p_t(\boldsymbol{y})}{p_t(\boldsymbol{x})}$를 디노이징 스코어 엔트로피를 통해 모델링하는 접근법을 제안하였다.
이 중에서도 마스크 디퓨전 모델(Masked Diffusion Models, MDMs)은 이산 디퓨전 모델의 가장 대표적인 형태로 자리잡았다. MDMs는 훈련 시 입력 토큰을 특별한 [MASK] 토큰으로 확률적으로 대체하는 방식을 사용한다. 구체적으로, 마스크 비율 $t \in [0, 1]$에 따라 각 토큰이 독립적으로 마스킹되며, $t = 0$일 때는 원본 시퀀스 $\boldsymbol{x}_0$가 그대로 유지되고 $t = 1$일 때는 모든 토큰이 마스킹된 완전 마스크 시퀀스가 된다. 모델은 이렇게 부분적으로 마스킹된 시퀀스로부터 원본 토큰을 예측하도록 학습된다. MDMs는 최근 7B 파라미터 규모로 확장되었는데, LLaDA(Nie et al., 2025)는 MDM 손실 함수로 처음부터(from scratch) 학습된 모델이며, Dream(Ye et al., 2025)은 기존 Qwen-2.5 7B 모델을 적응시킨 사례이다.
MDMs의 훈련 목적 함수는 마스킹된 토큰에 대한 기대 손실을 최소화하는 형태로 정의된다:
$$\mathcal{L}(\theta) = -\mathbb{E}_{t, x_0, x_t}\left[\frac{1}{t}\sum_{i=1}^{L}\mathbf{1}[x_t^i = \texttt{[MASK]}]\log p_\theta(x_0^i \mid x_t)\right]$$
여기서 $t \sim \text{Uniform}(0, 1)$이고 $x_t$는 순방향 과정에서 샘플링된다. 손실은 마스킹된 토큰에 대해서만 계산되며, $\frac{1}{t}$라는 가중치는 마스크 비율이 낮을 때(즉, 소수의 토큰만 마스킹되었을 때) 각 마스킹된 토큰에 대한 손실의 상대적 중요도를 높이는 역할을 한다. 이 수식의 직관적 의미는, 마스킹 비율이 낮은 상황(대부분의 컨텍스트가 주어진 상황)에서의 예측 정확도를 높게 유지하는 것이 최종 생성 품질에 더 중요하다는 것이다.
2.3 오토리그레시브와 마스크 디퓨전의 보간
순수 AR 방식과 순수 디퓨전 방식 사이의 중간 지대를 탐색하는 연구가 활발히 진행되고 있다. SSD-LM(Han et al., 2022)은 가우시안 텍스트 디퓨전의 블록 형태를 도입하였고, AR-Diffusion(Wu et al., 2023)은 좌에서 우로의 노이즈 스케줄을 적용하여 SSD-LM을 확장하였다. 마스크 디퓨전 모델 영역에서는 BD3-LM(Arriola et al., 2025)이 블록 내부에서 이산 디노이징 디퓨전을 수행하면서 전역적으로는 좌에서 우 구조를 유지하는 보간(interpolation) 접근법을 제안하였다. 이와 동시에 SDAR(Cheng et al., 2025)은 사전학습된 AR 모델에서 블록 디퓨전 모델을 성공적으로 미세조정하였고, D2F(Wang et al., 2025b)는 Diffusion Forcing(Chen et al., 2024)에서 영감을 받아 대규모 디퓨전 언어 모델을 더 효율적인 블록 디퓨전 모델로 증류(distill)하는 방법을 제안하였다. Set Block Decoding(Gat et al., 2025)은 표준 다음 토큰 예측(NTP)과 마스크 토큰 예측(MATP)을 단일 아키텍처 내에 통합하여 여러 토큰의 동시 생성을 가능하게 하였다. 이러한 동시대 연구들과 비교하여, Fast-dLLM v2는 불과 1B 토큰만을 요구하는 데이터 효율적인 미세조정 과정이 핵심 차별점이다.
2.4 디퓨전 LLM 가속 기법
디퓨전 언어 모델의 추론 가속에 관한 최근 연구는 크게 캐싱 메커니즘과 고급 디코딩 전략 두 가지 축으로 분류된다. 디퓨전 LLM 추론의 주된 병목은 양방향 어텐션 메커니즘에 수반되는 계산 비용이다. 이를 해결하기 위해 다양한 캐싱 기법이 제안되었다. Fast-dLLM(Wu et al., 2025)은 선행 텍스트(prefix)와 후속 마스크 토큰(suffix) 모두의 KV 활성화를 캐싱하는 DualCache를 제안하였고, dKV-Cache(Ma et al., 2025)는 지연 캐싱 전략을, dLLM-Cache(Liu et al., 2025)는 프롬프트 캐싱과 적응형 부분 응답 캐시를 결합하였다. Sparse-dLLM(Song et al., 2025)은 어텐션 점수를 활용한 동적 토큰 드롭, DPad(Chen et al., 2025)는 고정 크기 윈도우로 어텐션을 제한하는 접근법을 제안하였다.
디코딩 전략 측면에서는 더욱 다양한 접근법이 탐색되었다. Fast-dLLM의 신뢰도 기반 적응형 병렬 디코딩 알고리즘을 시작으로, EB-Sampler(Ben-Hamu et al., 2025)는 엔트로피 한정 언마스킹(Entropy Bounded unmasking) 절차를 도입하여 사전 정의된 근사 오차 허용 범위 내에서 한 번의 함수 평가로 여러 토큰을 동시에 언마스킹하였다. Dimple(Yu et al., 2025)은 각 스텝에서 생성되는 토큰 수를 동적으로 조정하는 자신감 기반 디코딩을, WINO(Hong et al., 2025)는 병렬 초안 작성 및 검증 메커니즘을, SlowFast Sampling(Wei et al., 2025)은 탐색적 단계와 가속 단계를 적응적으로 교대하는 동적 샘플링 전략을 제안하였다. LaViDa(Li et al., 2025b)는 효율적 샘플링을 위한 타임스텝 시프트를 탐구하였으며, Prophet(Li et al., 2025a)는 정제를 계속할지 한 번에 남은 토큰을 모두 디코딩할지를 동적으로 결정하는 방법을 제안하였다.
2.5 AR 모델과 디퓨전 모델의 근본적 차이
본 논문의 핵심 통찰을 이해하기 위해서는, AR 모델과 디퓨전 모델 사이의 근본적인 구조적 차이를 명확히 인식할 필요가 있다. AR 모델은 인과적 어텐션 마스크(causal attention mask)를 사용하여 각 토큰이 자신보다 앞에 위치한 토큰들에만 어텐션을 수행한다. 이 구조 덕분에 한 번 계산된 이전 토큰들의 Key-Value 벡터를 KV 캐시에 저장하고 재사용할 수 있어 추론 효율이 높다. 반면, 전체 어텐션 기반 디퓨전 모델(예: Dream, LLaDA)은 양방향 어텐션(bidirectional attention)을 사용하므로, 어떤 위치의 토큰이 마스킹/언마스킹 상태가 변경될 때마다 모든 토큰의 표현이 영향을 받아 KV 캐시의 유효성이 보장되지 않는다. 이것이 기존 디퓨전 LLM이 매 디노이징 스텝마다 전체 시퀀스에 대한 전방 패스를 수행해야 하는 근본적 이유이며, AR 모델 대비 추론 속도가 느린 주된 원인이다.
블록 디퓨전 모델은 이 두 접근법의 장점을 결합한다. 블록 간에는 인과적(좌에서 우) 의존성을 유지하므로 이전 블록의 KV 캐시를 그대로 재사용할 수 있고, 블록 내부에서는 양방향 어텐션을 통해 여러 토큰을 동시에 정제할 수 있다. Fast-dLLM v2는 이 블록 디퓨전 구조를 기반으로 하되, 기존 BD3-LM이 처음부터 학습해야 했던 것과 달리 사전학습된 AR 모델에서 출발하여 최소한의 미세조정으로 변환을 달성한다는 점에서 실용적 가치가 크다. 이러한 접근이 가능한 핵심 이유는, Fast-dLLM v2의 블록와이즈 어텐션 마스크 구조가 원본 AR 모델의 인과적 어텐션과 구조적으로 유사하여, 적응 과정에서 모델이 학습해야 하는 변화량이 상대적으로 적기 때문이다.
3. 방법론
3.1 기본 설정
길이 $L$의 토큰 시퀀스 $x = \{x^1, x^2, \dots, x^L\}$이 주어졌을 때, 전통적인 AR 모델은 조건부 분포 $P_\theta(x^i | x^{<i})$를 모델링하여 시퀀스를 순차적으로 생성하며, 교차 엔트로피 손실을 최소화하도록 학습된다. 각 위치 $i$에서 모델은 이전까지의 모든 토큰 $x^{<i}$를 조건으로 받아 다음 토큰 $x^i$의 확률 분포를 예측하는데, 이러한 순차적 의존 구조가 AR 모델의 강력한 일관성을 보장하는 동시에 병렬 처리를 제한하는 근본 원인이 된다.
이와 대조적으로, 디퓨전 언어 모델은 순방향 노이징 과정(forward noising process)과 학습된 역방향 디노이징 모델(reverse denoising model)이라는 두 단계의 확률적 프로세스를 통해 생성 분포를 정의한다. 시간 $t \in (0, 1)$에서 원본 시퀀스 $x_0$의 각 토큰은 확률 $t$로 독립적으로 마스킹되어 손상된 시퀀스 $x_t$가 생성된다. 역방향 모델 $p_\theta(x_0 | x_t)$는 노이즈가 추가된 입력으로부터 원본 토큰을 예측하도록 학습된다. 이 과정에서 $t$가 1에 가까울수록 입력의 대부분이 마스킹되어 예측이 어렵고, $t$가 0에 가까울수록 대부분의 컨텍스트가 주어져 예측이 용이해진다. 추론 시에는 완전히 마스킹된 시퀀스($t = 1$)에서 시작하여 점진적으로 토큰을 언마스킹하면서 $t$를 0으로 감소시켜 최종 텍스트를 생성한다.
3.2 블록 디퓨전 LLM으로의 적응
Fast-dLLM v2는 사전학습된 Qwen2.5-Instruct 모델(1.5B 및 7B 변형)을 기반으로 블록와이즈 디퓨전 훈련 파이프라인을 구축한다. 미세조정은 인스트럭션 튜닝 데이터에 대한 지도 미세조정(supervised fine-tuning, SFT) 형태로 수행되며, 각 훈련 배치는 블록와이즈 디퓨전 설정을 사용하여 구성된다. 구체적으로, 각 블록 내에서 부분적 토큰 마스킹을 도입하고 상보적 마스킹 전략과 결합하여 모든 토큰이 가시적(visible) 컨텍스트와 마스킹된 컨텍스트 양쪽에서 학습되도록 보장한다.
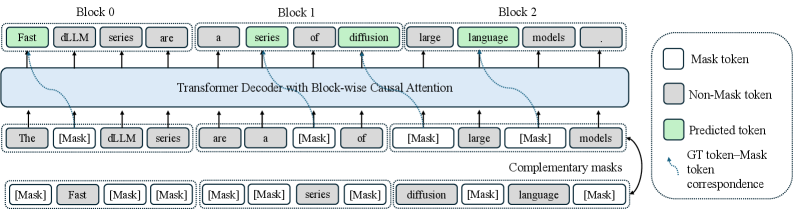
Figure 2: Fast-dLLM v2의 훈련 과정. 입력 시퀀스가 블록 단위로 디코딩된다. 각 블록 내에서 모델은 부분적 마스킹을 동반한 다음 토큰 예측을 수행한다. 모든 토큰이 학습될 수 있도록 상보적 마스크가 도입되어, 한 뷰(view)에서 마스킹된 토큰이 다른 뷰에서 예측될 수 있다. 손실은 녹색으로 표시된 예측 토큰에만 적용된다.
Figure 2는 Fast-dLLM v2의 전체 훈련 과정을 시각적으로 도해한다. 입력 시퀀스가 블록 단위로 분할되고, 각 블록에 대해 상보적 마스크 쌍이 생성되는 과정이 명확하게 표현되어 있다. 한 쌍의 마스크에서 첫 번째 마스크가 위치 $j$를 마스킹하면 두 번째 마스크는 동일 위치를 언마스킹하고, 그 반대도 마찬가지이다. 이 두 뷰는 동일한 배치에 함께 배치되어 트랜스포머 디코더에 입력되며, 모델은 블록와이즈 인과적 어텐션(Block-wise Causal Attention)을 통해 마스킹된 토큰(녹색으로 표시)을 예측하도록 학습된다. 이 상보적 설계는 한 뷰에서 마스킹된 모든 토큰이 상보적 뷰에서는 반드시 언마스킹되므로, 훈련 과정에서 모든 토큰 위치에 대한 학습 신호가 보장된다는 것이 핵심이다.
3.2.1 블록와이즈 시퀀스 구성
토크나이즈된 샘플들이 주어졌을 때, 먼저 각 시퀀스를 블록 크기 $D$의 정수 배가 되도록 [MASK] 토큰을 추가하여 패딩한다. 이 패딩 토큰들은 손실 계산에서 제외되며 그래디언트 업데이트에 기여하지 않는다. 패딩 후에는 시퀀스들을 연결(concatenate)하여 긴 토큰 스트림을 만들고, 이를 고정된 컨텍스트 길이 $L$의 훈련 시퀀스로 분할한다. 각 패킹된 시퀀스는 자연스럽게 $B = L/D$개의 비중첩 블록으로 나뉘며, 블록 경계가 샘플 경계를 가로지르지 않도록 보장된다.
이 블록 정렬 패킹(block-aligned packing) 전략의 중요성은 아블레이션 실험에서 확인된다. 패딩 없이 시퀀스를 직접 패킹하면, 한 샘플의 <EOS> 토큰 바로 다음에 다른 샘플의 <BOS> 토큰이 위치할 수 있는데, 블록와이즈 디퓨전 모델은 블록 내 양방향 어텐션을 사용하므로 서로 다른 샘플 간에 의도치 않은 정보 유출(cross-sample leakage)이 발생할 수 있다. 패딩은 깨끗한 샘플 경계를 보장하여 이러한 교차 샘플 누출을 방지하는 역할을 한다.
3.2.2 상보적 뷰를 통한 마스크 토큰 예측
각 블록에 대해 이진 마스크 $m \in \{0, 1\}^D$가 무작위로 샘플링되며, $m_j = 1$은 위치 $j$가 학습된 [MASK] 임베딩으로 대체됨을 의미한다. 모든 토큰이 마스킹된 컨텍스트와 언마스킹된 컨텍스트 양쪽에서 지도 학습을 받도록 보장하기 위해, 상보적 마스킹(complementary masking) 전략이 사용된다. 각 훈련 샘플은 마스크 $m$과 그 보수 마스크 $\bar{m} = 1 - m$을 가진 두 개의 뷰로 복제된다. 이 두 뷰는 동일한 배치에 함께 배치되어 모델이 두 뷰에 걸쳐 마스킹된 컨텍스트와 언마스킹된 컨텍스트를 공동으로 관찰할 수 있게 한다.
상보적 마스킹의 수학적 의미를 좀 더 자세히 살펴보면, 마스크 $m$에서 위치 $j$가 마스킹되었다면($m_j = 1$) 보수 마스크 $\bar{m}$에서는 해당 위치가 언마스킹된다($\bar{m}_j = 0$). 따라서 첫 번째 뷰에서 위치 $j$의 토큰은 예측 대상이 되고 주변 컨텍스트로부터 학습하며, 두 번째 뷰에서는 위치 $j$의 토큰이 컨텍스트로 제공되어 다른 마스킹된 위치의 예측을 돕는다. 이러한 대칭적 설계는 모든 토큰 위치에 대해 예측자(predictor)와 컨텍스트 제공자(context provider) 역할을 모두 수행하게 하여, 학습 신호의 완전한 커버리지를 보장한다.
3.2.3 예측을 위한 토큰 시프트
사전학습된 AR 모델의 표현 품질을 보존하기 위해, Fast-dLLM v2는 시프트 레이블 전략(shifted-label strategy)을 채택한다. 마스킹된 위치 $i$의 토큰을 예측할 때, 해당 위치가 아닌 선행 위치 $(i-1)$의 로짓(logit)을 사용한다. 구체적으로, $x_i$가 마스킹되었을 때 모델은 $i-1$ 위치의 은닉 상태(hidden state)를 사용하여 $x_i$를 예측하는데, 이는 인과적 언어 모델의 다음 토큰 예측 메커니즘과 정확히 일치한다. 이 설계 선택은 단순해 보이지만 매우 중요한 의미를 갖는다. AR 모델은 수백 또는 수천 억 토큰의 사전학습을 통해 "위치 $i-1$의 표현으로 위치 $i$의 토큰을 예측한다"는 패턴을 깊이 내재화하고 있으므로, 이 패턴을 유지함으로써 미세조정 시 모델이 학습해야 하는 변화량을 최소화할 수 있다. 이것이 Fast-dLLM v2가 불과 1B 토큰의 미세조정만으로도 성공적인 무손실 적응을 달성할 수 있는 핵심적인 설계 메커니즘 중 하나이다.
3.2.4 훈련 목적 함수
Fast-dLLM v2는 마스킹된 토큰에 대한 교차 엔트로피 손실을 최소화한다:
$$\mathcal{L}_{\text{block}}(\theta) = -\mathbb{E}_{x, m}\left[\sum_{i=1}^{L}\mathbf{1}[x_t^i = \texttt{[MASK]}]\log p_\theta(x_0^i \mid x_{<i}, x_{\text{block}(i)})\right]$$
여기서 $x_{\text{block}(i)}$는 위치 $i$를 포함하는 블록의 모든 토큰(마스킹/언마스킹 포함)을 나타내며, $x_{<i}$는 이전 블록들의 깨끗한 토큰들이다. 이 수식이 일반 MDM 손실과 다른 핵심 차이점은 조건부 의존성의 구조에 있다. 일반 MDM에서는 전체 시퀀스 $x_t$가 조건으로 제공되는 반면, Fast-dLLM v2에서는 현재 블록의 토큰 $x_{\text{block}(i)}$과 이전 블록의 깨끗한 토큰 $x_{<i}$만이 조건으로 사용된다. 이러한 블록와이즈 조건부 구조는 블록 간 인과적 의존성과 블록 내 양방향 의존성이라는 이중 구조를 자연스럽게 인코딩한다.
3.2.5 블록와이즈 어텐션 마스킹
Fast-dLLM v2는 BD3-LM과 유사한 하이브리드 어텐션 체계를 사용한다. 각 훈련 샘플에 대해, 노이즈가 추가된 시퀀스 $x_t$와 대응하는 깨끗한 시퀀스 $x_0$를 시퀀스 차원을 따라 연결하여 총 길이 $2L$의 입력을 구성한다. 어텐션 마스크 $A \in \{0, 1\}^{2L \times 2L}$가 인과적 연결과 양방향 연결 모두를 제어한다.
전체 어텐션 마스크는 네 개의 하위 마스크로 분해된다:
$$\mathcal{M}_{\text{full}} = \begin{bmatrix} \mathcal{M}_{BD} & \mathcal{M}_{OBC} \\ 0 & \mathcal{M}_{BC} \end{bmatrix}$$
각 하위 마스크의 역할은 다음과 같다.
- 블록 대각 마스크($\mathcal{M}_{BD}$, Block-diagonal mask): 노이즈 시퀀스 $x_t$ 내에서 동일 블록에 속하는 토큰들 사이에 양방향 셀프 어텐션을 허용한다. 이를 통해 블록 내부에서의 정제(refinement)가 가능해진다.
- 오프셋 블록 인과 마스크($\mathcal{M}_{OBC}$, Offset block-causal mask): 깨끗한 토큰에서 노이즈 토큰으로의 교차 블록 인과적 의존성을 허용한다. 현재 블록의 노이즈 토큰이 이전 블록의 깨끗한 토큰에 어텐션할 수 있게 한다.
- 블록 인과 마스크($\mathcal{M}_{BC}$, Block Causal mask): 깨끗한 토큰들 사이의 전통적인 좌에서 우 인과성을 유지한다.
- 영 마스크(0): 노이즈 토큰에서 깨끗한 토큰으로의 어텐션을 차단하여, 노이즈 시퀀스가 깨끗한 시퀀스에 의존하지 않도록 한다.
이 설계는 손상된 컨텍스트와 깨끗한 컨텍스트를 동시에 처리할 수 있게 하며, 상보적 마스크 지도학습을 촉진한다. 어텐션 마스크는 블록 병렬성과 블록 간 인과적 AR 의존성을 자연스럽게 지원하며, PyTorch의 flex-attention 구현을 활용하여 이 구조화된 마스킹을 효율적으로 실현하고 훈련을 가속한다. flex-attention은 사용자 정의 어텐션 마스크 패턴을 효율적으로 구현할 수 있는 PyTorch의 최신 기능으로, 임의의 블록 구조화된 어텐션 마스크를 GPU에서 최적화된 방식으로 실행할 수 있다. 전통적인 구현에서는 $2L \times 2L$ 크기의 전체 어텐션 마스크를 메모리에 명시적으로 생성해야 했지만, flex-attention은 마스크 함수를 지연 평가(lazy evaluation)하여 메모리 사용량을 크게 줄이면서도 커스텀 어텐션 패턴의 효율적인 실행을 보장한다. 이는 Fast-dLLM v2의 복잡한 하이브리드 어텐션 구조를 훈련 시 성능 저하 없이 구현할 수 있게 하는 핵심 기술적 요소이다.

Figure 7(a): 훈련 시 어텐션 마스크 설계. 각 입력은 손상된 시퀀스 $x_t$와 대응하는 타겟 $x_0$로 구성되어 단일 전방 패스에서 처리된다. 어텐션 마스크는 블록 내 양방향 어텐션(Block Diagonal), 깨끗한 토큰에서 노이즈 토큰으로의 교차 블록 인과 의존성(Offset Block Causal), 깨끗한 토큰 간 좌에서 우 인과성(Block Causal)을 결합한다.
Figure 7(a)는 훈련 시의 전체 어텐션 마스크 구조를 행렬 형태로 시각화한다. $x_t^1, x_t^2, x_t^3, x_0^1, x_0^2, x_0^3$으로 구성된 6개의 블록이 양축에 배치되어 있으며, 파란색 블록 대각 마스크, 녹색 오프셋 블록 인과 마스크, 주황색 블록 인과 마스크가 각각의 어텐션 패턴을 명확하게 보여준다. 이 복합적인 마스크 구조가 블록 내 양방향성과 블록 간 인과성이라는 두 가지 상충되는 요구사항을 단일 어텐션 연산 내에서 우아하게 조화시키는 것을 확인할 수 있다.
3.3 추론 파이프라인
추론 시 Fast-dLLM v2는 AR 모델의 순차적 특성과 디퓨전 기반 디코딩의 병렬성을 균형 있게 조합하는 블록와이즈 디코딩 전략을 사용한다. 생성은 한 번에 하나의 블록씩 진행되는데, 이미 디코딩된 블록들은 캐싱되어 깨끗한 프리픽스 컨텍스트로 재사용되고, 현재 블록은 병렬 마스크 토큰 정제를 거친다. 블록 수준 캐싱, 블록 내 병렬 디코딩, DualCache 재사용을 결합함으로써, Fast-dLLM v2는 보조 모델이나 추가 추론 오버헤드 없이 디코딩 효율을 극대화한다.
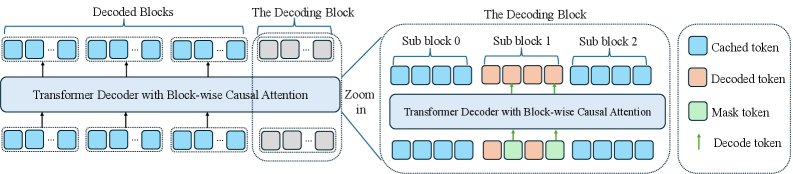
Figure 3: 추론 과정 도해. 시퀀스가 블록 단위로 디코딩되며, 디코딩된 블록은 캐싱되어 추론 속도를 높인다. 각 블록 내에서는 Fast-dLLM의 병렬 디코딩과 DualCache를 적용하여 추론을 더욱 가속한다.
Figure 3은 Fast-dLLM v2의 추론 과정을 두 가지 수준에서 보여준다. 좌측에서는 블록이 순차적으로 디코딩되고 이전에 완성된 블록이 캐싱되는 전체적인 흐름을 보여주며, 우측의 확대된 부분에서는 현재 디코딩 블록 내에서 여러 서브 블록이 병렬로 처리되는 과정을 상세히 도해한다. 각 서브 블록에는 캐싱된 토큰, 디코딩된 토큰, 마스크 토큰이 혼재하며, 모델은 블록와이즈 인과적 어텐션을 통해 서브 블록들을 동시에 생성할 수 있다. 이러한 계층적 구조가 Fast-dLLM v2가 높은 디코딩 병렬성을 달성하는 핵심 메커니즘이다.
3.3.1 블록와이즈 AR 디코딩과 캐싱
Fast-dLLM v2에서 각 블록은 인과적 순서로 디코딩되므로 블록 간 좌에서 우 의미론이 자연스럽게 보존된다. 각 블록의 디코딩이 완료되면, 해당 블록의 언마스킹된 토큰들은 이후 블록들을 위한 읽기 전용(read-only) 컨텍스트로 캐싱된다. 이 설계는 블록 수준 KV 캐시 재사용을 가능하게 하여 중복 계산을 크게 줄인다. 추론 시의 어텐션 마스크는 각 블록이 자기 자신 내에서는 양방향으로 어텐션하고 이전 블록들에 대해서는 인과적으로 어텐션하도록 설정되어, 훈련 시의 구성을 정확히 반영한다.
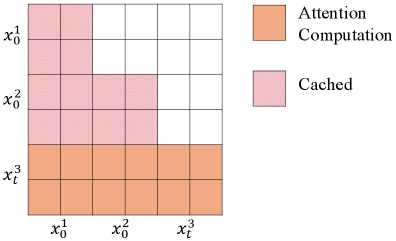
Figure 7(b): 추론 시 어텐션 마스크 설계. 이전에 디코딩된 블록의 $x_0$는 KV 캐시를 통해 재사용되며(분홍색), 현재 노이즈 블록 $x_t^3$만 새롭게 계산된다(진한 주황색). 이를 통해 블록 간 중복 계산이 제거된다.
Figure 7(b)는 추론 시의 KV 캐시 활용을 시각적으로 보여준다. 분홍색으로 표시된 영역은 이전 단계에서 계산되어 캐시에 저장된 Key-Value 쌍을 재사용하는 부분이며, 진한 주황색으로 표시된 영역은 현재 스텝에서 새롭게 계산되는 어텐션이다. 가장 최근 블록($x_t^3$)에 해당하는 행만 새로운 계산이 수행되고, 이전 블록들($x_0^1, x_0^2$)의 KV는 모두 캐시에서 가져온다. 이러한 구조 덕분에, 블록 수가 증가해도 각 스텝의 계산량은 현재 블록에 대한 어텐션 계산으로 제한되어, AR 모델의 KV 캐시와 유사한 효율성을 달성할 수 있다.
3.3.2 블록 내 병렬 정제
블록 내에서의 생성을 가속하기 위해, Fast-dLLM v2는 Fast-dLLM(Wu et al., 2025)에서 제안된 신뢰도 인식 병렬 디코딩(confidence-aware parallel decoding) 전략을 채택한다. 구체적으로, 현재 블록의 마스킹된 토큰들을 모델의 예측 신뢰도에 기반하여 반복적으로 정제한다. 신뢰도 임계값을 초과하는 토큰은 병렬로 디코딩되어 언마스킹되고, 불확실한 위치의 토큰은 향후 정제를 위해 마스킹 상태를 유지한다. 이 전략은 모호한 예측을 회피하면서 생성 지연을 줄이는 효과가 있다.
신뢰도 임계값의 선택은 성능과 속도 사이의 트레이드오프를 결정하는 핵심 하이퍼파라미터이다. 임계값을 1.0으로 설정하면 모든 토큰이 전체 디노이징 스텝을 거쳐야 하므로 표준 비병렬 디코딩과 동일해지고, 임계값을 낮추면 더 많은 토큰이 일찍 확정되어 처리량이 증가하지만 정확도에 약간의 손실이 발생할 수 있다. 논문은 임계값 0.9가 정확도 손실을 최소화하면서 상당한 속도 향상을 제공하는 최적점임을 실험적으로 보여준다.
3.3.3 서브 블록 재사용을 위한 DualCache
블록 내 디코딩에서의 중복 계산을 더욱 줄이기 위해, Fast-dLLM v2는 Fast-dLLM의 DualCache 메커니즘을 통합한다. DualCache는 부분적으로 디코딩된 블록에 대해 프리픽스(prefix) KV 캐시와 서픽스(suffix) KV 캐시를 모두 유지하여, 추가 토큰이 공개됨에 따라 효율적인 재계산을 가능하게 한다. 이 계층적 캐싱은 비용이 큰 전체 재계산을 방지할 뿐만 아니라, 신뢰도 인식 정제에서 사용되는 반복적이고 선택적인 디코딩 패턴을 지원한다.
DualCache의 동작 원리를 좀 더 구체적으로 설명하면, 블록 내 디노이징의 각 반복에서 일부 토큰이 언마스킹되면 해당 토큰의 KV 벡터를 서픽스 캐시에서 프리픽스 캐시로 이동시킨다. 다음 반복에서는 프리픽스 캐시에 저장된 이미 확정된 토큰의 KV를 재사용하고, 아직 마스킹된 토큰에 대해서만 새로운 전방 패스를 수행한다. 이를 통해 반복마다 계산량이 점진적으로 줄어들어, 블록 내 디노이징의 효율이 크게 향상된다.
3.3.4 패딩을 활용한 배치 디코딩
다양한 목표 길이를 가진 시퀀스들의 배치 생성을 지원하기 위해, 각 시퀀스를 [MASK] 토큰으로 오른쪽 패딩하여 총 길이가 블록 크기 $D$로 나누어떨어지도록 한다. 패딩된 시퀀스들은 그룹화되어 블록 단위로 디코딩된다. 각 스텝에서 배치 내 모든 시퀀스가 다음 블록을 병렬로 디코딩하며, 실제 토큰이 얼마나 남았는지에 관계없이 일관되고 효율적인 하드웨어 스케줄링을 보장한다.
3.3.5 전체 추론 파이프라인의 복잡도 분석
Fast-dLLM v2의 전체 추론 파이프라인의 계산 복잡도를 AR 디코딩과 비교하여 분석하면, 속도 향상의 원리를 더욱 명확히 이해할 수 있다. 길이 $L$의 시퀀스를 생성할 때, 표준 AR 디코딩은 $L$번의 순차적 전방 패스를 필요로 하며 각 패스는 KV 캐시를 통해 이전 컨텍스트를 재사용한다. Fast-dLLM v2에서는 시퀀스가 $B = L/D$개의 블록으로 나뉘고, 각 블록 내에서 $S$번의 디노이징 스텝이 필요하므로 총 $B \times S$번의 전방 패스가 수행된다. 블록 크기 $D = 32$이고 서브 블록 디코딩으로 디노이징 스텝 수가 $D/d$($d$는 서브 블록 크기)로 제한되면, 총 전방 패스 수는 $\frac{L}{D} \times \frac{D}{d} = \frac{L}{d}$가 된다. 서브 블록 크기 $d = 8$일 때 $L/8$번의 전방 패스만 필요하므로, 이론적으로 AR의 $L$번 대비 8배의 속도 향상이 가능하다. 물론 실제로는 블록 내 양방향 어텐션의 추가 비용, 디노이징 반복의 오버헤드 등으로 인해 이론적 상한에는 도달하지 못하며, 실측 약 2.5배의 속도 향상을 달성한다.
신뢰도 기반 병렬 디코딩을 추가로 적용하면, 각 디노이징 스텝에서 신뢰도가 높은 토큰들이 일찍 확정되므로 후속 스텝의 계산 부담이 점진적으로 줄어든다. DualCache는 이미 확정된 토큰의 KV를 재사용하여 이 효과를 극대화한다. 이러한 계층적 최적화의 결합이 Fast-dLLM v2의 실제 속도 향상을 달성하는 핵심 메커니즘이다.
4. 실험 설정
4.1 모델 및 훈련 구성
실험은 Qwen-2.5 1.5B와 7B Instruct 모델을 블록 디퓨전 LLM 구성으로 적응시키는 형태로 수행된다. 훈련 데이터로는 LLaMA-Nemotron 후처리 학습 데이터셋(Bercovich et al., 2025)이 사용되며, 배치 크기는 256이다. 학습률과 훈련 스텝은 각 모델에 맞게 설정된다. 1.5B 모델은 학습률 $2 \times 10^{-5}$에서 6,000 스텝, 7B 모델은 학습률 $1 \times 10^{-5}$에서 2,500 스텝으로 훈련된다. 훈련에는 64개의 NVIDIA A100 GPU가 사용되며, 1.5B 모델의 훈련에 약 8시간, 7B 모델의 훈련에 약 12시간이 소요된다. 옵티마이저는 AdamW를 사용하며, 처음 500 스텝에 걸쳐 선형 학습률 워밍업을 적용한다.
컨텍스트 길이 2048과 배치 크기 256을 고려하면, 각 훈련 스텝에서 $256 \times 2048 = 524,288$ 토큰이 처리된다. 따라서 총 훈련 토큰 수는 1.5B 모델의 경우 $6,000 \times 524,288 \approx 3.15$B 토큰, 7B 모델의 경우 $2,500 \times 524,288 \approx 1.31$B 토큰에 해당한다. 특별한 언급이 없는 한, 서브 블록 크기는 8, 블록 크기는 32로 고정되며, 병렬 디코딩은 비활성화(임계값 1.0)된 상태에서 실험한다. 이러한 설정은 블록 디퓨전 적응의 순수한 효과를 측정하기 위한 것으로, 병렬 디코딩에 의한 속도 향상은 별도로 분석된다.
훈련에 사용되는 LLaMA-Nemotron 후처리 학습 데이터셋은 광범위한 도메인을 포괄하는 고품질 인스트럭션-팔로잉 예제들을 포함하고 있다. 데이터셋은 블록와이즈 패킹(block-wise packing)을 사용하여 전처리되며, 각 시퀀스가 블록 크기의 배수가 되도록 패딩하여 블록 경계의 정렬 오류를 방지한다. 중복 패딩 토큰은 손실 계산과 그래디언트 업데이트에서 제외된다. DeepSpeed Zero-3를 활용한 분산 훈련이 적용되어 대규모 모델의 효율적인 훈련을 지원한다.
4.2 평가 벤치마크
미세조정된 모델의 성능은 언어 모델링과 추론 능력의 다양한 측면을 커버하는 종합적인 벤치마크 스위트에서 평가된다. 평가 스위트는 다음과 같은 과제들을 포함한다.
- 코드 생성: HumanEval, MBPP — EvalPlus 프레임워크를 사용하여 Base 및 Plus 설정에서 평가
- 수학적 추론: GSM8K, MATH — 초등학교 수준부터 경시대회 수준까지의 수학 문제
- 인스트럭션 팔로잉: IFEval — 지시사항 준수 능력 평가
- 지식 기반 질의응답: MMLU, GPQA — 일반 지식 및 대학원 수준 과학 질의응답
코드 관련 벤치마크(HumanEval, MBPP)는 EvalPlus 프레임워크로 평가하여 코드 합성에 대한 엄격한 평가를 제공하며, 나머지 벤치마크들은 LM-Eval 프레임워크를 사용하여 일관성과 신뢰성을 보장한다. 비교 기준 모델로는 LLaMA-3.2, SmolLM-2, Dream, LLaDA 시리즈 등 유사한 파라미터 규모의 널리 인정받는 모델들을 포함하며, 동일한 데이터셋과 훈련 스텝에서 표준 다음 토큰 예측(NTP)으로 미세조정된 원본 Qwen-2.5 1.5B 및 7B 모델(Qwen2.5-Nemo-FT)도 블록 디퓨전 방법론의 영향을 분리하기 위해 포함된다.
5. 주요 실험 결과
5.1 벤치마크 성능 비교
Table 1은 다양한 평가 과제에 걸친 모델별 벤치마크 결과를 보여준다. 모델들은 파라미터 규모에 따라 1B 범주와 7B+ 범주로 분류된다.
| Model | #Params | HumanEval | MBPP | GSM8K | MATH | IFEval | MMLU | GPQA | Avg. | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Base | Plus | Base | Plus | ||||||||
| 1B Models | |||||||||||
| LLaMA-3.2 | 1.2B | 34.1 | 31.1 | 34.1 | 29.4 | 43.0 | 23.8 | 58.9 | 44.4 | 24.1 | 35.9 |
| SmolLM 2 | 1.7B | 34.1 | 28.7 | 50.6 | 46.0 | 47.7 | 21.1 | 55.1 | 49.1 | 29.2 | 40.7 |
| Qwen2.5-1.5B | 1.5B | 42.1 | 37.2 | 48.1 | 41.3 | 57.0 | 46.8 | 41.2 | 54.6 | 30.6 | 44.3 |
| Qwen2.5-1.5B-Nemo-FT | 1.5B | 37.2 | 33.5 | 53.4 | 44.4 | 58.5 | 43.5 | 39.4 | 58.1 | 31.0 | 44.3 |
| Fast-dLLM v2 | 1.5B | 43.9 | 40.2 | 50.0 | 41.3 | 62.0 | 38.1 | 47.0 | 55.1 | 27.7 | 45.0 |
| 7B+ Models | |||||||||||
| LLaDA | 8B | 35.4 | 31.7 | 31.5 | 28.6 | 78.6 | 26.6 | 59.9 | 65.5 | 31.8 | 43.3 |
| LLaDA-1.5 | 8B | 52.4 | - | 42.8 | - | 83.3 | 42.6 | 58.2 | 66.0 | 36.9 | - |
| LLaDA-MoE | 7B | 61.6 | - | 70.0 | - | 82.4 | 58.7 | 59.3 | 67.2 | - | - |
| Dream | 7B | 57.9 | 53.7 | 68.3 | 56.1 | 81.0 | 39.2 | 62.5 | 67.0 | 33.0 | 57.6 |
| Qwen2.5-7B | 7B | 51.2 | 47.6 | 57.7 | 49.5 | 71.4 | 73.3 | 70.8 | 68.7 | 33.5 | 58.2 |
| Qwen2.5-7B-Nemo-FT | 7B | 52.4 | 48.2 | 57.1 | 50.0 | 84.1 | 72.0 | 69.5 | 68.6 | 34.2 | 59.6 |
| Fast-dLLM v2 | 7B | 63.4 | 58.5 | 63.0 | 52.3 | 83.7 | 61.6 | 61.4 | 66.6 | 31.9 | 60.3 |
Table 1의 결과를 상세히 분석하면, 먼저 1B 규모에서 Fast-dLLM v2 (1.5B)는 평균 점수 45.0을 달성하여 Qwen2.5-1.5B(44.3)와 Qwen2.5-1.5B-Nemo-FT(44.3)를 모두 상회하며, 1B 규모의 디퓨전 기반 및 NTP 학습 AR 모델 중 최고의 성능을 기록하였다. 특히 HumanEval Base(43.9 대 42.1), GSM8K(62.0 대 57.0/58.5), IFEval(47.0 대 41.2/39.4)에서 두드러진 개선을 보인다. HumanEval에서의 향상은 블록 디퓨전 방식이 코드 생성에서 블록 단위의 구조적 일관성을 더 잘 포착할 수 있음을 시사하며, GSM8K에서의 큰 개선은 수학적 추론에서 블록 내 양방향 컨텍스트 모델링이 중간 계산 단계 간의 산술적 정합성과 일관성을 높이는 데 효과적임을 보여준다. 또한 IFEval에서의 향상(41.2/39.4 → 47.0)은 블록 디퓨전이 복잡한 지시사항의 구조적 요소를 더 잘 포착하고 준수하는 능력을 갖추었음을 시사한다.
한편, MATH 벤치마크에서 Fast-dLLM v2 (1.5B)가 38.1로 원본 Qwen2.5-1.5B의 46.8보다 낮은 성능을 보이는 것은 주목할 만하다. 이는 블록 디퓨전 적응 과정에서 고난도 수학 추론 능력의 일부가 손실될 수 있음을 시사하며, 특히 1.5B 규모의 작은 모델에서 이 트레이드오프가 더 두드러지게 나타난다. 그러나 GSM8K에서의 큰 개선(57.0 → 62.0)을 고려하면, 블록 디퓨전이 기초적인 수학 추론은 오히려 강화하면서 경시대회 수준의 고난도 추론에서만 약간의 손실을 보이는 비대칭적 패턴을 보인다고 해석할 수 있다.
7B+ 규모에서 Fast-dLLM v2 (7B)는 평균 점수 60.3을 달성하여 Qwen2.5-7B-Nemo-FT(59.6)와 Dream(57.6)을 포함한 모든 기존 모델을 능가한다. 특히 HumanEval Base에서 63.4라는 압도적인 성능을 기록하여 Dream(57.9)과 Qwen2.5-7B(51.2)를 크게 앞서며, HumanEval Plus에서도 58.5로 최고 성능을 달성하였다. GSM8K(83.7)에서도 Qwen2.5-7B(71.4)와 LLaDA(78.6)를 크게 상회하며 Qwen2.5-7B-Nemo-FT(84.1)와 거의 동등한 수준을 보인다.
한편, MATH(61.6)와 MMLU(66.6)에서는 원본 Qwen2.5-7B(73.3, 68.7)보다 다소 낮은 성능을 보이는데, 이는 블록 디퓨전 적응 과정에서 일부 지식 집약적 과제의 성능에 미미한 트레이드오프가 존재함을 시사한다. 그러나 전반적인 평균 점수에서의 우위(60.3 대 58.2)와 코드 및 수학 추론에서의 현저한 개선을 고려하면, 이러한 트레이드오프는 실용적으로 허용 가능한 수준이라고 논문은 분석한다.
또한 주목할 점은, 동일한 데이터셋과 동일한 훈련 스텝에서 표준 NTP 손실로 미세조정된 Qwen2.5-Nemo-FT 대비 Fast-dLLM v2가 더 높은 평균 성능을 달성한다는 것이다. 이는 블록 디퓨전 훈련이 단순히 "AR 모델에 추론 가속을 위한 디퓨전 능력을 추가하는 것"을 넘어, 모델의 전반적인 성능 자체를 향상시킬 수 있음을 시사하는 흥미로운 결과이다.
5.2 추론 속도 분석

Figure 4: 신뢰도 임계값에 따른 GSM8K 정확도와 처리량 변화. 임계값 0.9가 선택되어, 최소한의 정확도 하락으로 2.6배의 속도 향상을 제공한다.
Figure 4는 신뢰도 기반 병렬 디코딩에서 임계값 설정이 성능과 효율에 미치는 영향을 이중 축 그래프로 보여준다. 파란색 선은 정확도(%), 빨간색 선은 처리량(tokens/s)을 나타낸다. 임계값이 낮아질수록 더 많은 토큰이 디노이징 과정의 초기 단계에서 확정되어 처리량이 증가하지만, 정확도에는 약간의 하락이 수반된다. 논문이 선택한 임계값 0.9에서는 GSM8K 정확도의 하락이 미미한 수준에 그치면서, 처리량이 39.1 tokens/s에서 101.7 tokens/s로 증가하여 2.6배의 속도 향상을 달성한다. 임계값 1.0은 표준 비병렬 디코딩과 동일하므로 39.1 tokens/s의 기준 처리량을 제공하며, 이는 블록 디퓨전 구조 자체의 순수한 속도를 나타낸다.

Figure 5: NVIDIA A100 및 H100 GPU에서 배치 크기별 AR 대 디퓨전 생성 방식의 처리량 비교. 디퓨전 생성이 두 GPU 모두에서 일관되게 AR 방식을 상회하며, A100에서 최대 1.5배, H100에서 최대 1.8배의 속도 향상을 달성한다.
이 결과에서 주목할 또 다른 측면은 병렬 디코딩을 비활성화한 상태(임계값 1.0)에서도 Fast-dLLM v2가 39.1 tokens/s의 기본 처리량을 달성한다는 점이다. 이는 블록 디퓨전 구조 자체가 서브 블록 디코딩을 통해 AR 디코딩 대비 의미 있는 기본 속도 향상을 제공함을 의미한다. 신뢰도 기반 병렬 디코딩은 이 기본 속도 위에 추가적인 가속을 제공하는 보완적 기법이며, 두 메커니즘의 시너지가 최종적인 2.5~2.6배 속도 향상을 만들어낸다. 임계값의 선택은 배포 환경의 요구사항에 따라 유연하게 조절할 수 있으며, 정확도가 최우선인 환경에서는 높은 임계값을, 처리량이 중요한 환경에서는 낮은 임계값을 설정하는 것이 권장된다.
Figure 5는 NVIDIA A100과 H100 GPU에서 배치 크기에 따른 Fast-dLLM v2 (7B)와 Qwen2.5-7B-Instruct의 처리량을 비교한다. 임계값 0.9와 서브 블록 캐시를 사용한 설정에서, 디퓨전 생성은 모든 배치 크기에서 AR 기준 모델을 일관되게 상회한다. A100에서는 배치 크기 64에서 최대 1.5배의 처리량 우위를 보이며, H100에서는 그 격차가 더 벌어져 최대 1.8배의 속도 향상을 달성한다. 이러한 결과는 최신 하드웨어 아키텍처에서 병렬성을 더 효과적으로 활용할 수 있는 디퓨전 디코딩의 특성을 반영한다. 배치 크기가 커질수록 디퓨전 방식의 상대적 우위가 더욱 두드러지는 경향은, 실제 배포 환경에서 다수의 요청을 동시에 처리해야 하는 상황에서 Fast-dLLM v2의 실용적 가치가 더욱 높아짐을 의미한다.
6. 아블레이션 연구
6.1 훈련 레시피 아블레이션
모든 아블레이션 실험은 Fast-dLLM v2 1.5B 모델을 사용하여 아키텍처 및 디코딩 선택의 영향을 체계적으로 조사한다. Table 2는 다양한 토큰 시프트 전략에 따른 벤치마크 결과를 보여준다.
| Method | HumanEval | MBPP | GSM8K | MATH | IFEval | MMLU | GPQA | Avg. | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Base | Plus | Base | Plus | |||||||
| Naive token shift | 38.4 | 32.9 | 44.4 | 38.6 | 59.0 | 37.3 | 39.9 | 52.9 | 27.9 | 41.3 |
| + pad | 38.4 | 34.1 | 45.2 | 38.4 | 60.1 | 37.0 | 45.8 | 53.5 | 27.7 | 42.2 |
| + pad + CM | 43.9 | 40.2 | 50.0 | 41.3 | 62.0 | 38.1 | 47.0 | 55.1 | 27.7 | 45.0 |
Table 2의 기준선인 "Naive token shift"는 각 훈련 블록에서 토큰의 일부를 무작위로 마스킹하고 선행 위치의 출력으로 예측하는 가장 기본적인 전략이다. 여기에 패딩 전략(+ pad)을 추가하면 평균 점수가 41.3에서 42.2로 0.9점 향상되는데, 이 개선은 특히 IFEval(39.9 → 45.8)에서 두드러진다. 패딩의 효과는 훈련 시 데이터 무결성을 보존하는 데 있다. 패딩 없이 시퀀스를 패킹하면, 한 샘플의 <EOS> 토큰 바로 다음에 다른 샘플의 <BOS> 토큰이 배치될 수 있는데, 블록와이즈 디퓨전 모델의 양방향 어텐션이 이 경계를 넘어 의도치 않은 교차 샘플 어텐션을 발생시킬 수 있기 때문이다.
상보적 마스킹(+ pad + CM)을 추가로 적용하면 평균 점수가 42.2에서 45.0으로 2.8점 추가 향상되어, 기준선 대비 총 +3.7점의 개선을 달성한다. HumanEval Base(38.4 → 43.9, +5.5점), MBPP Base(44.4 → 50.0, +5.6점), GSM8K(59.0 → 62.0, +3.0점), IFEval(39.9 → 47.0, +7.1점) 등 거의 모든 벤치마크에서 유의미한 개선이 관측된다. 상보적 마스킹이 이렇게 큰 개선을 가져오는 이유는, 모든 토큰이 마스킹된 컨텍스트와 언마스킹된 컨텍스트 양쪽에서 학습 신호를 받게 되어 학습 신호의 커버리지가 완전해지기 때문이다. 단순 마스킹에서는 확률적으로 어떤 토큰이 학습 배치 내에서 한 번도 마스킹되지 않을 수 있지만, 상보적 마스킹은 이를 구조적으로 방지한다.
6.2 서브 블록 크기의 영향
서브 블록 크기는 블록 내 디코딩의 세분도(granularity)를 결정하는 핵심 하이퍼파라미터이다. Table 3은 서브 블록 크기에 따른 성능 변화를 보여준다.
| Sub-Block Size | 2 | 4 | 8 | 16 | 32 |
|---|---|---|---|---|---|
| GSM8K | 62.8 | 61.8 | 62.0 | 61.3 | 60.2 |
| HumanEval | 42.7 | 43.3 | 43.9 | 39.6 | 38.4 |
| HumanEval+ | 39.6 | 40.2 | 40.2 | 36.0 | 34.8 |
Table 3에서 볼 수 있듯이, 추론 시 서브 블록 크기를 조정하면 성능에 주목할 만한 변화가 관측된다. 서브 블록 크기 8이 전반적으로 가장 높은 평균 정확도를 달성한다. 그러나 과제별로 최적의 서브 블록 크기가 다르다는 점이 흥미롭다. GSM8K는 더 작은 크기(서브 블록 2에서 62.8)에서 최고 성능을 보이는 반면, HumanEval과 HumanEval+는 서브 블록 8까지 성능이 향상되다가 그 이후 하락한다. 이는 수학적 추론 과제에서는 더 세밀한 토큰 단위 정제가 중요한 반면, 코드 생성에서는 약간 더 큰 블록 단위의 일관성이 유리하다는 과제 의존적 특성을 반영한다. 서브 블록 크기가 32에 도달하면 전체 블록을 한 번에 디코딩하는 것과 동일해져 서브 블록 디코딩의 이점이 사라지며, 모든 과제에서 성능이 하락한다.
6.3 추론 시 블록 크기 불일치의 영향
Table 4는 훈련 시 설정된 블록 크기(32)와 다른 블록 크기로 추론을 수행할 때의 성능 변화를 보여준다.
| Block Size | 2 | 4 | 8 | 16 | 32 |
|---|---|---|---|---|---|
| GSM8K | 53.2 | 56.8 | 58.5 | 59.7 | 60.2 |
| HumanEval | 37.8 | 43.3 | 43.3 | 38.4 | 38.4 |
| HumanEval+ | 34.1 | 39.0 | 39.6 | 34.1 | 34.8 |
Table 4의 결과는 훈련과 추론 간의 블록 구조 일관성이 매우 중요함을 보여준다. 블록 크기를 훈련 시의 32에서 직접 변경하여 추론하면 상당한 성능 저하가 발생한다. 예를 들어, 블록 크기 2로 추론할 경우 GSM8K가 60.2에서 53.2로 7.0점 하락하고, HumanEval+도 34.8에서 34.1로 하락한다. 이러한 성능 저하는 훈련 시 학습된 어텐션 패턴과 추론 시의 어텐션 패턴이 불일치하기 때문에 발생한다. 블록 내 양방향 어텐션의 범위가 훈련 시와 다르면, 모델이 학습한 토큰 간 의존성 패턴이 왜곡되어 예측 품질이 저하된다.
이 결과를 Table 3(서브 블록 크기 변경)의 결과와 대조하면 중요한 차이가 드러난다. 서브 블록 크기를 변경하는 것은 블록 크기 자체를 변경하는 것과 달리, 훈련 시의 블록 구조를 위반하지 않으면서 추론 세분도만 조절하는 것이다. 서브 블록 디코딩에서는 원래 블록 크기 32를 유지하되, 블록 내부를 더 작은 서브 블록 단위로 순차적으로 디코딩한다. 이렇게 하면 훈련-추론 간 어텐션 패턴의 일관성이 보존되므로 성능 저하가 미미하다. Table 3에서 서브 블록 크기 2일 때의 GSM8K(62.8)가 Table 4에서 블록 크기 2일 때의 GSM8K(53.2)보다 9.6점이나 높은 것은 이를 명확히 입증한다.
6.4 서브 블록 캐시의 효과
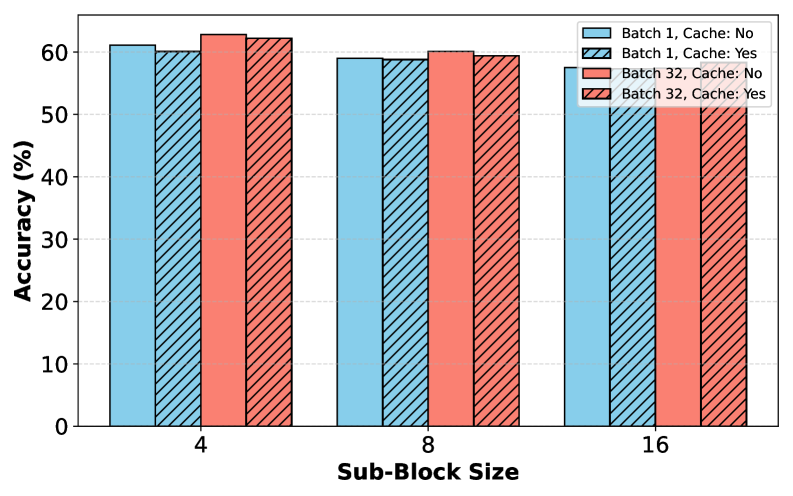
Figure 6(a): 서브 블록 크기와 서브 블록 캐시가 모델 정확도에 미치는 영향. 서브 블록 캐시의 사용 여부에 관계없이 정확도는 대체로 안정적이며, 서브 블록 크기가 커질수록 약간의 하락이 관찰된다.

Figure 6(b): 서브 블록 크기와 서브 블록 캐시가 처리량에 미치는 영향. 서브 블록 크기가 커질수록 디코딩 병렬성 증가로 처리량이 향상되며, 서브 블록 캐시는 배치 크기가 큰 컴퓨트 바운드 환경(배치 크기 32)에서 특히 큰 효과를 보인다.
Figure 6은 서브 블록 크기와 서브 블록 캐시가 정확도와 처리량에 미치는 영향을 종합적으로 분석한다. Figure 6(a)에서 볼 수 있듯이, 서브 블록 크기가 커질수록 정확도가 약간 하락하는 경향이 있으며, 이는 Table 3의 결과와 일치한다. 그러나 이 하락 폭은 서브 블록 크기 4에서 16까지의 범위에서 약 57~63% 사이로 상대적으로 작다. 서브 블록 캐시의 사용 여부는 정확도에 관측 가능한 영향을 미치지 않으며, 이는 캐싱이 출력 품질을 저하시키지 않는 순수한 효율 향상 기법임을 확인시켜준다.
Figure 6(b)는 처리량 측면에서의 분석을 보여준다. 서브 블록 크기가 커질수록 필요한 순차적 전방 패스 수가 줄어들고 스텝 내 병렬성이 증가하여 처리량이 향상된다. 가장 흥미로운 관찰은 서브 블록 캐시의 효과가 배치 크기에 크게 의존한다는 점이다. 배치 크기가 1일 때는 메모리 대역폭이 충분히 활용되지 않아(memory bandwidth underutilized) 캐시의 효과가 미미하지만, 배치 크기가 32로 증가하여 컴퓨트 바운드 영역에 진입하면 캐시가 상당한 속도 향상을 제공한다. 서브 블록 크기 16, 배치 크기 32, 캐시 활성화 조건에서 약 430 tokens/s의 처리량을 달성하여, 실제 배포 환경에서의 높은 실용성을 보여준다.
6.5 훈련 데이터 효율성 분석
Fast-dLLM v2의 가장 핵심적인 기여 중 하나는 극도의 훈련 데이터 효율성이다. 이를 기존 디퓨전 LLM들과 정량적으로 비교하면 그 차이가 극명하게 드러난다. 다음 표는 주요 디퓨전 LLM들의 학습 데이터 요구량을 정리한 것이다.
| Model | 학습 방식 | 학습 토큰 | 기반 모델 | Avg. 성능 |
|---|---|---|---|---|
| LLaDA (8B) | 처음부터 학습 | ~2T | 없음 | 43.3 |
| Dream (7B) | AR 적응 | ~580B | Qwen2.5-7B | 57.6 |
| Fast-dLLM v2 (7B) | 블록 디퓨전 적응 | ~1.3B | Qwen2.5-7B | 60.3 |
Dream이 Qwen2.5-7B에서 출발하여 약 580B 토큰의 미세조정으로 57.6의 평균 성능을 달성하는 반면, Fast-dLLM v2는 동일한 기반 모델에서 출발하여 불과 1.3B 토큰의 미세조정으로 60.3이라는 더 높은 평균 성능을 달성한다. 학습 데이터량 대비 성능 기준으로 비교하면, Fast-dLLM v2는 Dream 대비 약 450배 더 데이터 효율적이다. LLaDA가 처음부터 약 2조 토큰을 학습하여 43.3의 평균 성능을 달성하는 것과 비교하면, 사전학습된 AR 모델에서 출발하는 Fast-dLLM v2의 접근법이 얼마나 효율적인지가 더욱 명확해진다.
훈련 인프라 측면에서도 Fast-dLLM v2의 효율성은 두드러진다. 64개의 A100 GPU를 사용하여 7B 모델을 약 12시간 만에 적응시킬 수 있다는 것은, 현대적인 연구 기관이나 기업이 합리적인 비용으로 이 기술을 적용할 수 있음을 의미한다. Dream이 유사한 규모의 모델을 적응시키기 위해 수만 GPU-시간을 소요하는 것과 비교하면, Fast-dLLM v2의 훈련 비용은 2~3 orders of magnitude 낮은 수준이다. 이러한 훈련 효율성은 디퓨전 LLM 기술의 접근성을 대폭 높이며, 학술 연구 그룹이나 중소 규모의 AI 기업에서도 충분히 시도할 수 있는 수준이다.
이러한 극도의 데이터 효율성이 가능한 근본적 이유는 Fast-dLLM v2의 블록와이즈 어텐션 설계가 원본 AR 모델의 인과적 어텐션 구조와 높은 친화성을 갖기 때문이라고 논문은 분석한다. Dream은 전체 어텐션(full attention) 기반 디퓨전을 사용하므로, 인과적 어텐션에서 양방향 어텐션으로의 전환이라는 근본적인 구조 변화가 필요하여 많은 학습 데이터가 요구된다. 반면, Fast-dLLM v2의 블록와이즈 구조에서는 블록 간 관계가 여전히 인과적이며, 양방향성은 블록 내부에 한정되므로 모델이 학습해야 하는 변화가 상대적으로 적다. 토큰 시프트 전략 역시 원본 AR 모델의 다음 토큰 예측 패턴을 보존하여 적응 비용을 낮추는 데 기여한다.
7. 추가 분석 및 논의
7.1 Speculative Decoding과의 비교
AR 모델의 추론 가속을 위한 또 다른 유력한 접근법으로 추측적 디코딩(Speculative Decoding)이 있다. 이 기법은 작은 초안 모델(draft model)이 여러 토큰을 빠르게 예측한 후, 큰 검증 모델(verifier model)이 이를 병렬로 검증하여 올바른 토큰을 수락하는 방식으로 동작한다. Medusa, EAGLE, Lookahead Decoding 등이 이 범주에 속하며, 생성 품질을 정확히 보존하면서 2~3배의 속도 향상을 달성할 수 있다. Fast-dLLM v2와 추측적 디코딩을 비교하면, 추측적 디코딩은 원본 AR 모델의 출력 분포를 정확히 보존하는 반면 별도의 초안 모델이나 추가 헤드의 학습이 필요하고, Fast-dLLM v2는 모델 자체를 블록 디퓨전으로 변환하여 단일 모델만으로 가속을 달성하되 출력 분포가 약간 달라질 수 있다는 차이가 있다. 또한 추측적 디코딩의 수락률은 초안 모델과 검증 모델 간의 분포 일치도에 의존하여 과제에 따라 변동이 크지만, Fast-dLLM v2의 속도 향상은 과제와 무관하게 비교적 안정적이라는 장점이 있다. 두 접근법은 상호 배타적이지 않으므로, 향후 블록 디퓨전 모델에 추측적 디코딩의 검증(verification) 아이디어를 결합하여 블록 내 디노이징의 정확도를 높이면서 속도를 유지하는 하이브리드 접근법도 흥미로운 향후 연구 방향이 될 수 있다.
7.2 Dream과 Fast-dLLM v2의 구조적 차이 심층 비교
Fast-dLLM v2와 Dream의 데이터 효율성 차이의 근본 원인을 이해하기 위해, 두 모델의 구조적 차이를 더욱 심층적으로 분석할 필요가 있다. Dream은 전체 어텐션 기반 마스크 디퓨전을 사용한다. 이는 시퀀스의 모든 위치가 다른 모든 위치에 어텐션할 수 있는 양방향 어텐션 구조로, 원본 AR 모델의 인과적 어텐션과 근본적으로 다르다. AR 모델에서는 각 토큰이 자신보다 앞에 위치한 토큰들에만 어텐션하도록 학습되었으므로, 갑자기 뒤에 위치한 토큰들의 정보도 활용해야 하는 양방향 어텐션으로 전환하면 모델의 내부 표현이 크게 재구성되어야 한다. 이것이 Dream이 580B 토큰이라는 대규모 미세조정 데이터를 필요로 하는 핵심 이유이다.
반면, Fast-dLLM v2의 블록와이즈 어텐션에서는 블록 간 관계가 여전히 인과적이다. 즉, 블록 $b$의 토큰들은 블록 $1, 2, \dots, b-1$의 토큰에만 인과적으로 어텐션하며, 이는 원본 AR 모델의 인과적 어텐션 패턴과 구조적으로 매우 유사하다. 유일한 차이점은 블록 $b$ 내부에서 토큰들이 서로 양방향으로 어텐션할 수 있다는 것인데, 블록 크기가 32인 경우 이는 전체 시퀀스의 매우 제한된 지역적 영역에서의 변화에 해당한다. 결과적으로, 모델이 학습해야 하는 어텐션 패턴의 변화량이 Dream에 비해 극히 적으며, 이것이 1B 토큰이라는 소량의 미세조정으로도 무손실 적응을 가능하게 하는 근본적 이유이다.
토큰 시프트 전략도 이 구조적 친화성에 기여하는 중요한 요소이다. 마스킹된 위치 $i$의 토큰을 위치 $i-1$의 은닉 상태로 예측하는 방식은, AR 모델이 사전학습 동안 수조 토큰에 걸쳐 학습한 "위치 $i-1$에서 위치 $i$를 예측한다"는 기본 패턴을 정확히 보존한다. 이 설계 덕분에 모델의 기존 표현 공간(representation space)이 미세조정 과정에서 크게 교란되지 않으며, 적은 데이터로도 새로운 블록 내 양방향 패턴을 효과적으로 학습할 수 있다.
7.3 하드웨어별 성능 차이
Figure 5의 결과에서 관찰되는 중요한 패턴은 A100과 H100 GPU 사이의 성능 차이이다. H100에서 디퓨전 방식의 상대적 우위가 더 두드러지는 이유(A100 1.5배 대 H100 1.8배)는 H100의 향상된 하드웨어 특성과 관련이 있다. H100은 A100 대비 더 높은 메모리 대역폭과 텐서 코어 성능을 제공하며, 특히 블록 내 병렬 디코딩에서 발생하는 행렬 연산을 더 효율적으로 처리할 수 있다. 디퓨전 기반 디코딩은 한 스텝에서 여러 토큰을 동시에 처리하므로, 단일 토큰을 순차 처리하는 AR 디코딩에 비해 행렬 연산의 비중이 높다. 이는 최신 가속기의 높은 병렬 처리 능력을 더 효과적으로 활용할 수 있음을 의미하며, 차세대 하드웨어에서 Fast-dLLM v2의 성능 이점이 더욱 확대될 것으로 예상할 수 있다.
7.4 과제 유형별 성능 분석
Table 1의 결과를 과제 유형별로 세분화하여 분석하면, Fast-dLLM v2의 강점과 약점이 더욱 명확해진다. 코드 생성(HumanEval, MBPP) 과제에서 Fast-dLLM v2는 모든 비교 모델을 압도하는 성능을 보인다. 7B 모델 기준 HumanEval Base 63.4는 Dream(57.9)보다 5.5점, Qwen2.5-7B(51.2)보다 12.2점 높다. 코드 생성에서의 이러한 우수한 성능은 블록 디퓨전 방식이 코드의 구조적 패턴(함수 정의, 루프, 조건문 등)을 블록 단위로 더 효과적으로 포착할 수 있기 때문으로 해석된다. 코드는 자연어에 비해 구조적 반복성이 높고 블록 단위의 의미적 일관성이 강하므로, 블록 내 양방향 어텐션이 코드 블록의 내부 일관성을 높이는 데 특히 효과적일 수 있다.
수학적 추론(GSM8K, MATH) 과제에서의 결과는 더욱 세밀한 분석이 필요하다. GSM8K에서 Fast-dLLM v2 (7B)는 83.7로 Qwen2.5-7B-Nemo-FT(84.1)와 거의 동등하며 Dream(81.0)과 LLaDA(78.6)를 명확히 상회한다. 이는 초등학교 수준의 다단계 산술 추론에서 블록 디퓨전 모델이 AR 모델에 버금가는 추론 능력을 유지함을 보여준다. 반면, MATH 벤치마크에서는 61.6으로 Qwen2.5-7B(73.3)와 Qwen2.5-7B-Nemo-FT(72.0)에 비해 상당한 차이를 보인다. MATH는 경시대회 수준의 고난도 수학 문제를 포함하며, 이러한 과제에서는 긴 추론 체인(chain of thought)의 정확성이 매우 중요하다. 블록 경계에서의 의존성 단절이 이러한 긴 추론 체인의 일관성에 부정적 영향을 미칠 수 있으며, 이는 Fast-dLLM v2의 개선이 필요한 영역으로 지목된다.
지식 기반 질의응답(MMLU, GPQA)에서도 유사한 패턴이 관찰된다. MMLU에서 Fast-dLLM v2 (7B)는 66.6으로 원본 Qwen2.5-7B(68.7)보다 2.1점 낮다. 이는 사전학습된 AR 모델의 광범위한 세계 지식 중 일부가 블록 디퓨전 적응 과정에서 미세하게 손상될 수 있음을 시사한다. 그러나 이 차이는 상대적으로 작으며, Dream(67.0)과는 유사한 수준이다. GPQA에서는 Fast-dLLM v2가 31.9로 다소 낮은 성능을 보이는데, GPQA는 대학원 수준의 과학 질의응답으로 극도로 어려운 벤치마크이며, 이 수준에서의 소폭 차이는 통계적 변동 범위 내일 수 있다.
7.5 서브 블록 디코딩의 설계 원리
서브 블록 디코딩은 Fast-dLLM v2의 추론 파이프라인에서 핵심적인 역할을 한다. 이 메커니즘의 설계 원리를 좀 더 깊이 이해하기 위해, 블록 크기 직접 변경(Table 4)과 서브 블록 크기 변경(Table 3)의 차이를 개념적으로 분석해보자. 블록 크기 32로 훈련된 모델이 추론 시 블록 크기 8을 사용하면, 어텐션 마스크의 양방향 범위가 32에서 8로 줄어들어 모델이 학습한 장거리 블록 내 의존성을 활용할 수 없게 된다. 반면, 서브 블록 크기 8을 사용하면 어텐션 마스크는 여전히 블록 크기 32 전체에 걸쳐 양방향이지만, 디코딩 과정이 서브 블록 단위로 진행되어 한 서브 블록의 토큰이 먼저 확정된 후 다음 서브 블록의 디코딩에 활용된다. 이는 블록 내에서 일종의 "미니 AR" 순서를 부과하는 것과 유사하며, 훈련 시의 어텐션 구조를 위반하지 않으면서도 더 정확한 토큰 생성을 가능하게 한다.
이러한 분석은 블록 디퓨전 LLM의 설계에서 훈련-추론 일관성(training-inference consistency)이 핵심적으로 중요하다는 교훈을 제공한다. 성능을 조절하고 싶을 때는 블록 크기를 직접 변경하기보다 서브 블록 디코딩 전략을 통해 추론 세분도를 조절하는 것이 안전하고 효과적이다.
7.6 디퓨전 LLM 생태계에서의 위치
Fast-dLLM v2는 급격히 성장하고 있는 디퓨전 LLM 생태계에서 매우 독특하고 실용적인 위치를 차지한다. 2025년 들어 Google DeepMind의 Gemini Diffusion, Inception Labs의 Mercury 등 상용 디퓨전 언어 모델이 등장하면서, 디퓨전 LLM은 더 이상 학술적 관심사에 머물지 않고 산업적 배포 가능성을 갖춘 기술로 성장하였다. 기존 디퓨전 LLM 연구는 크게 두 가지 방향으로 진행되어 왔다. 하나는 LLaDA처럼 전체 어텐션 기반의 마스크 디퓨전 모델을 처음부터 대규모로 학습하는 방향이고, 다른 하나는 Dream처럼 기존 AR 모델을 전체 어텐션 디퓨전 모델로 적응시키는 방향이다. 두 접근 모두 수백 또는 수천 억 토큰의 대규모 학습 데이터를 필요로 한다는 공통적인 한계를 갖는다.
Fast-dLLM v2는 블록 디퓨전이라는 제3의 경로를 통해 이러한 대규모 학습 데이터 요구라는 한계를 근본적으로 돌파한다. 전체 어텐션 디퓨전 대신 블록와이즈 디퓨전을 사용함으로써, AR 모델과의 구조적 친화성을 최대화하고 적응 비용을 극적으로 절감한다. 이 접근법의 실용적 의의는 매우 크며 이전 접근법들과 질적으로 다른 가능성을 제시한다. 새로운 AR 모델이 출시될 때마다 수백 억 토큰의 적응 학습 없이도 빠르게 디퓨전 버전으로 변환할 수 있으며, 이는 디퓨전 LLM 기술의 대중화와 실용적 대규모 배포를 크게 촉진할 잠재력을 갖는다.
동시대 연구들과의 비교에서도 Fast-dLLM v2의 차별성이 뚜렷하다. SDAR(Cheng et al., 2025)은 유사하게 사전학습된 AR 모델을 블록 디퓨전으로 변환하지만 학습 데이터 효율성에 대한 상세한 분석이 부족하며, D2F(Wang et al., 2025b)는 대규모 디퓨전 LLM을 블록 디퓨전으로 증류하는 방식으로 이미 학습된 디퓨전 모델을 전제로 한다. Set Block Decoding(Gat et al., 2025)은 NTP와 MATP를 통합하지만 별도의 대규모 학습이 필요하다. Fast-dLLM v2는 이들 중에서 가장 데이터 효율적인 적응 경로를 제시한다.
8. 한계점 및 향후 연구
8.1 고정 블록 크기의 제약
현재 Fast-dLLM v2는 훈련 시 설정된 고정 블록 크기(본 논문에서는 32)에서만 최적의 성능을 발휘한다는 중요한 제약을 갖는다. 블록 크기 32는 일반적인 과제에 대해 합리적인 선택이지만, 과제의 특성에 따라 최적의 블록 크기가 다를 수 있다. 예를 들어, 코드 생성에서는 함수나 클래스 단위의 더 큰 블록이 유리할 수 있고, 세밀한 수학적 계산에서는 더 작은 블록이 정확성을 높일 수 있다. Table 4의 아블레이션 결과가 보여주듯, 추론 시 블록 크기를 변경하면 상당한 성능 저하가 발생한다. 이는 과제의 특성이나 하드웨어 제약에 따라 블록 크기를 동적으로 조절하고자 할 때 유연성을 제한한다. 서브 블록 디코딩이 부분적인 해결책을 제공하지만, 근본적으로 블록 크기의 유연한 변경을 지원하는 훈련 전략이나 적응적 블록 크기 메커니즘의 개발이 향후 연구 과제로 남아 있다.
8.2 지식 집약적 과제에서의 성능 격차
MATH 벤치마크(61.6 대 Qwen2.5-7B의 73.3)와 MMLU(66.6 대 68.7)에서 관찰되는 성능 격차는, 블록 디퓨전 적응 과정에서 일부 학습된 지식이나 긴 추론 체인의 일관성이 손상될 수 있음을 시사한다. 특히 MATH와 같은 고난도 추론 과제에서의 성능 저하는, 블록 경계에서의 정보 흐름 단절이 복잡한 다단계 추론에 부정적 영향을 미칠 수 있다는 가설과 일치한다. 이를 해결하기 위해서는 블록 간 정보 전달을 강화하는 메커니즘이나, 추론 과제에 특화된 미세조정 전략의 개발이 필요할 수 있다.
8.3 더 큰 모델 규모로의 확장
본 논문의 실험은 최대 7B 파라미터 규모에 한정되어 있다. 현재 최첨단 LLM들이 70B 이상의 파라미터를 사용하는 것을 고려하면, Fast-dLLM v2의 블록 디퓨전 적응 접근법이 더 큰 규모에서도 동일한 데이터 효율성과 성능 보존을 달성할 수 있는지는 아직 검증되지 않았다. 모델 규모가 커지면 블록 내 양방향 어텐션의 계산 비용도 비례적으로 증가하므로, 대규모 모델에서의 실용적 속도 이점이 유지될 수 있는지도 추가 연구가 필요하다.
8.4 생성 품질의 세밀한 평가
본 논문의 평가는 주로 정확도 기반 벤치마크에 초점을 맞추고 있으며, 텍스트의 유창성, 다양성, 일관성 등 생성 품질의 더 세밀한 측면에 대한 평가는 제한적이다. 디퓨전 기반 생성은 AR 방식과 근본적으로 다른 생성 역학을 가지므로, 반복적 표현의 빈도, 토큰 분포의 엔트로피, 장거리 문맥 일관성 등에서 차이가 있을 수 있다. 특히 블록 경계에서의 의미적 연속성이 AR 모델만큼 자연스러운지에 대한 체계적인 분석이 필요하다. 이러한 세밀한 생성 품질 평가는 Fast-dLLM v2의 실용적 배포 가능성을 더욱 완전하게 검증하는 데 기여할 것이다.
8.5 다른 기반 모델로의 일반화
본 논문의 실험은 Qwen2.5-Instruct 모델만을 기반으로 수행되었다. Fast-dLLM v2의 블록 디퓨전 적응 접근법이 LLaMA, Mistral, Gemma 등 다른 AR 모델 계열에도 동일하게 적용 가능한지, 그리고 기반 모델의 아키텍처적 특성(예: Grouped Query Attention, Mixture of Experts 등)이 적응 효율에 미치는 영향은 아직 탐구되지 않았다. 다양한 기반 모델에 대한 적응 실험은 Fast-dLLM v2의 일반적 적용 가능성을 확인하는 데 중요한 연구 방향이다. 특히 Grouped Query Attention(GQA)을 사용하는 모델에서는 KV 캐시의 구조가 달라지므로 DualCache 메커니즘의 구현 방식에 조정이 필요할 수 있으며, Mixture of Experts(MoE) 모델에서는 블록 내 양방향 어텐션이 전문가 라우팅 패턴에 미치는 영향을 추가로 분석해야 할 것이다.
8.6 실세계 배포 시의 고려사항
Fast-dLLM v2의 실세계 배포를 고려할 때 몇 가지 실용적 측면의 추가 논의가 필요하다. 첫째, 현재의 벤치마크 결과는 주로 짧은 응답을 생성하는 과제(수학 문제, 코드 스니펫 등)에 초점을 맞추고 있으며, 수천 토큰에 달하는 긴 응답을 생성하는 시나리오에서의 성능과 속도 이점은 아직 충분히 검증되지 않았다. 긴 생성에서는 블록 수가 크게 증가하므로, 블록 수준 KV 캐시의 메모리 사용량과 블록 경계의 누적적 영향이 어떻게 작용하는지 추가 연구가 필요하다. 둘째, 스트리밍 생성(streaming generation) 시나리오에서의 사용자 경험도 고려해야 한다. AR 모델은 토큰 단위로 출력을 스트리밍할 수 있지만, 블록 디퓨전 모델은 블록 단위로 출력이 확정되므로, 사용자가 체감하는 첫 토큰 지연(time-to-first-token)이 블록 크기에 비례하여 증가할 수 있다. 블록 크기 32는 약 20~40 단어에 해당하므로, 대화형 어플리케이션에서는 이 지연이 사용자 경험에 부정적으로 작용할 가능성이 있으며, 이를 완화하기 위한 점진적 스트리밍 전략의 개발이 필요하다. 셋째, 모델 서빙 프레임워크(vLLM, TensorRT-LLM, SGLang 등)와의 통합도 중요한 엔지니어링 과제이다. 이들 프레임워크는 AR 모델에 최적화되어 있으므로, 블록 디퓨전 모델의 고유한 디코딩 패턴을 효율적으로 지원하기 위한 커스텀 통합 작업이 필요하다.
9. 결론
본 논문은 사전학습된 AR LLM을 효율적인 디퓨전 방식 디코더로 변환하는 확장 가능한 블록 디퓨전 언어 모델 프레임워크인 Fast-dLLM v2를 제시하였다. 블록와이즈 디퓨전 메커니즘과 상보적 마스킹을 통합함으로써, Fast-dLLM v2는 블록 내 양방향 컨텍스트 모델링을 가능하게 하면서도 원본 AR 모델의 예측 능력을 보존한다. 기존 디퓨전 기반 모델의 지연 문제를 해결하기 위해, 블록 간 컨텍스트 재사용을 위한 블록 수준 캐시와 블록 내 효율적 정제를 위한 DualCache 기반 서브 블록 캐시로 구성된 계층적 캐싱 전략, 그리고 병렬 디코딩 파이프라인을 제안하였다.
대규모 Qwen2.5-Instruct 모델(1.5B 및 7B)에 대한 광범위한 실험을 통해, Fast-dLLM v2가 표준 AR 디코딩 대비 최대 2.5배의 속도 향상을 생성 품질의 손실 없이 달성하며, 강력한 AR 기준 모델과 동등하거나 이를 상회하는 성능을 일관되게 보이면서 기존 디퓨전 기반 접근법 대비 최고 수준의 효율성을 달성함을 실증하였다. 특히, 약 1B 토큰의 미세조정만으로 무손실 적응을 달성하는 극도의 데이터 효율성은, Dream의 약 580B 토큰과 비교하여 500배에 달하는 효율성 개선을 나타내며, 디퓨전 LLM의 실용적 배포를 향한 핵심적인 장벽을 제거하였다.
종합적으로, Fast-dLLM v2의 핵심 기여를 정량적으로 요약하면 다음과 같다. 학습 데이터 측면에서는 Dream 대비 약 500배의 데이터 절감(1.3B 대 580B 토큰)을 달성하였으며, 추론 속도 측면에서는 표준 AR 디코딩 대비 최대 2.5배의 속도 향상을 달성하였다. 성능 측면에서는 1.5B 및 7B 규모 모두에서 동등 조건의 AR 기준 모델을 상회하는 평균 점수(45.0 및 60.3)를 기록하였으며, 특히 코드 생성과 수학 추론 과제에서 두드러진 개선을 보였다. 훈련 비용 측면에서는 64개 A100 GPU로 7B 모델을 약 12시간 만에 적응시킬 수 있어, 학술 연구 수준에서도 충분히 재현 가능한 효율성을 제공한다.
이러한 결과는 블록 디퓨전 프레임워크가 고품질, 저지연 LLM의 실세계 배포를 향한 실용적이고 유망한 경로임을 강조한다. Fast-dLLM v2는 AR 모델의 강력한 언어 모델링 능력과 디퓨전 모델의 병렬 생성 효율성을 효과적으로 결합함으로써, 차세대 LLM 추론 인프라의 핵심 구성 요소로 자리잡을 잠재력을 갖추고 있다. 코드와 모델이 공개 예정이라는 점은 이 방법론의 재현성과 후속 연구를 촉진할 것으로 기대된다. 디퓨전 언어 모델 분야가 2025년 들어 폭발적으로 성장하고 있는 가운데, Fast-dLLM v2는 "기존 AR 모델을 저비용으로 디퓨전 모델로 변환"이라는 새로운 패러다임을 제시함으로써, 디퓨전 LLM 기술의 대중화와 실용화를 향한 결정적인 한 걸음을 내딛었다. ICLR 2026 학회에서의 발표를 통해 이 연구가 커뮤니티에 더 넓게 알려지고, 후속 연구와 실용적 응용이 활발히 이루어질 것으로 전망된다. 궁극적으로 Fast-dLLM v2가 제시한 블록 디퓨전 적응 패러다임은 디퓨전 언어 모델의 학술적 연구와 산업적 실용화 사이의 간극을 좁히는 중요한 가교 역할을 할 것이다.
10. 요약 정리
- Fast-dLLM v2는 사전학습된 자기회귀(AR) 모델을 블록 디퓨전 언어 모델로 변환하는 효율적 프레임워크이다.
- AR 모델의 가중치를 초기화에 활용하고 블록 단위 디퓨전으로 재학습하여, 처음부터 학습하는 것 대비 훈련 비용을 대폭 절감한다.
- 신뢰도 기반 동적 블록 분할로 고정 블록 크기의 한계를 극복하여 생성 품질과 속도의 최적 균형을 달성한다.
- LLaMA-1.1B 기반 모델에서 AR 모델 대비 최대 4.6배 빠른 텍스트 생성을 달성한다.
- GPT-2, LLaMA 등 다양한 AR 아키텍처에서 변환이 가능하며, 범용성을 입증하였다.
- 코드 생성(HumanEval), 기계 번역(IWSLT14) 등 다운스트림 태스크에서도 경쟁력 있는 성능을 보인다.
- 블록 디퓨전 프레임워크는 AR과 디퓨전의 장점을 결합한 하이브리드 접근으로, 완전 병렬 생성과 순차 생성 사이의 스펙트럼을 제공한다.
- 양방향 어텐션을 통해 블록 내 토큰 간 상호 의존성을 포착하여 생성 일관성을 개선한다.
'[논문 리뷰] > [최신 논문]' 카테고리의 다른 글
| [arXiv 2505.22618] Fast-dLLM: KV 캐시와 병렬 디코딩으로 Diffusion LLM을 학습 없이 가속하기 (0) | 2026.02.17 |
|---|---|
| [arXiv 2509.26488] dParallel: 디퓨전 대규모 언어 모델의 학습 가능한 병렬 디코딩 (0) | 2026.02.16 |
| [arXiv 2505.21467] FlashDLM: KV 캐싱과 가이디드 디퓨전을 통한 확산 언어 모델 추론 가속화 (0) | 2026.02.16 |
| [arXiv 2602.13191] CoPE-VideoLM: 코덱 프리미티브를 활용한 효율적 비디오 언어 모델 (0) | 2026.02.16 |
| [arXiv 2501.06713] MiniRAG: 소형 언어 모델을 위한 극도로 간결한 RAG 시스템 (0) | 2026.02.16 |