UltraQuant: 4-bit KV Caching for Context-Heavy Agents
https://arxiv.org/abs/2606.20474
Inesh Chakrabarti, David Limpus, Aditi Ghai Rana, Bowen Bao, Spandan Tiwari, Thiago Crepaldi, Ashish Sirasao | AMD, UCLA, Purdue University | arXiv:2606.20474 | 2026년 6월
1. 서론: 에이전트 시대의 병목은 모델 파라미터보다 KV cache가 된다
LLM 에이전트는 짧은 질의응답 모델과 다른 방식으로 GPU 메모리를 압박한다. 사용자는 한 번의 대화에서 저장소 전체, 긴 시스템 프롬프트, 도구 정의, 검색 문서, 이전 실행 로그를 계속 쌓고, 모델은 매 턴마다 그 누적 문맥을 다시 바라본다. 이때 self-attention이 저장하는 KV cache는 context length에 거의 선형으로 커지며, batch와 동시 세션 수가 늘어날수록 HBM을 먼저 소모한다. UltraQuant 논문은 이 병목을 “긴 문맥을 처리할 수 있는가”에서 “긴 문맥을 GPU에 계속 resident하게 둘 수 있는가”라는 serving 문제로 재정의한다.
기존 배포 기준에서 FP8 KV caching은 꽤 강한 baseline이다. BF16 대비 대략 절반의 cache footprint를 쓰면서도 하드웨어 지원을 받기 때문에, 단순한 4-bit 아이디어가 FP8을 이기기는 쉽지 않다. 반면 TurboQuant 계열 4-bit KV 압축은 cache 용량을 더 줄일 수 있지만, decode attention 안에서 codebook lookup과 software dequantization을 수행해야 하므로 긴 context에서 latency가 커질 수 있다. UltraQuant의 흥미로운 지점은 압축률만 강조하지 않고, 4-bit representation이 실제 matrix core instruction으로 바로 소비될 수 있는지를 핵심 설계 기준으로 둔다는 점이다.
논문이 겨냥하는 workload는 특히 context-heavy agents다. 일반 chat benchmark처럼 prompt 하나를 넣고 긴 답변을 생성하는 상황보다, 에이전트 세션은 긴 prefix를 여러 짧은 turn에서 반복 재사용한다. cache가 남아 있으면 다음 turn의 time-to-first-token이 짧아지지만, cache가 밀려나면 같은 prefix를 다시 prefill해야 한다. 따라서 serving 성능은 단순 token throughput을 넘어 TTFT, TPOT, cache residency, concurrency가 함께 엮인 시스템 지표로 봐야 한다.
읽을 포인트는 세 가지다. 첫째, UltraQuant가 왜 “4-bit KV”라는 같은 이름 아래에서도 TurboQuant와 다른 배포 경로를 택하는지다. 둘째, Walsh-Hadamard rotation, per-block absmax scale, FP4 E2M1 grid, UE8M0 scale byte가 어떤 식으로 연결되어 codebook lookup을 제거하는지다. 셋째, 성능 수치가 좋게 나오는 조건이 어디인지와 AIME25 같은 reasoning benchmark에서 accuracy regression이 왜 중요한 한계로 남는지다.
1.1 논문의 핵심 문제 정의
UltraQuant는 “4-bit로 줄이면 메모리가 절반 더 줄어든다”는 단순한 주장에 머물지 않는다. 논문은 agent serving에서 cache 압축이 실제 이득으로 바뀌려면 세 가지 조건을 동시에 만족해야 한다고 본다. 첫째, 압축된 KV가 long-context quality를 지나치게 떨어뜨리지 않아야 한다. 둘째, vLLM 같은 paged serving stack에 들어갔을 때 cache residency가 실제 TTFT 개선으로 이어져야 한다. 셋째, decode step에서 quantized cache를 읽는 경로가 software gather나 LUT 병목을 만들지 않아야 한다. 이 세 조건을 동시에 놓고 보면, 4-bit KV cache는 모델 압축 문제를 넘어 serving kernel과 memory hierarchy를 함께 설계하는 문제에 가깝다.
- 대상 workload: 긴 prefix가 여러 turn에서 반복 재사용되는 multi-round agent session
- 기준 baseline: vLLM의 hardware FP8 KV cache와 TurboQuant-style 4-bit codebook path
- 주요 목표: FP8보다 작은 cache footprint를 유지하면서 FP8에 가까운 decode kernel 속도를 얻는 것
- 핵심 결과: cache-pressured late rounds에서 P50 TTFT $3.47\times$, 전체 round 기준 $2.3\times$, output throughput $1.63\times$ 개선
2. 배경 및 관련 연구: KV cache 압축은 알고리즘과 커널의 접점에 있다
2.1 긴 문맥 모델에서 KV cache가 커지는 방식
Transformer decoder는 매 token마다 각 layer의 key와 value를 저장한다. 이 저장소가 있으면 다음 token에서 과거 token을 다시 계산하지 않고 attention score와 weighted sum을 만들 수 있다. 문제는 cache 크기가 layer 수, head 수, head dimension, sequence length, precision에 비례한다는 점이다. context window가 32K에서 128K, 1M으로 커지면 parameter memory보다 KV cache가 serving capacity를 먼저 제한하는 경우가 늘어난다. 특히 여러 사용자의 세션을 동시에 처리하는 서버에서는 한 세션이 너무 많은 KV를 붙잡으면 다른 세션의 resident prefix가 밀려나고, 이는 scheduling과 latency tail에 영향을 준다.
KV cache를 줄이는 방법은 크게 두 부류로 나뉜다. 하나는 model architecture 자체를 바꾸는 접근이다. 예를 들어 multi-head latent attention은 full key/value 대신 low-rank latent representation을 저장해 cache footprint를 줄인다. 이 위키에서 이전에 정리한 MLA KV Cache Compression도 같은 축에 놓인다. 다른 하나는 model interface를 유지하면서 cache representation만 낮은 bit로 바꾸는 접근이다. UltraQuant는 후자에 속한다. 표준 attention interface를 유지하므로 기존 model weight와 serving scheduler를 크게 바꾸지 않는 대신, quantization error와 kernel overhead를 아주 세밀하게 다뤄야 한다.
이 차이는 배포 관점에서 중요하다. architecture-level compression은 모델을 새로 학습하거나 fine-tuning해야 할 수 있지만, KV quantization은 기존 checkpoint 위에 serving-time 또는 calibration-time 변환으로 붙을 수 있다. 그래서 production stack에서는 “얼마나 압축되는가”뿐 아니라 “어떤 GPU instruction으로 읽히는가”, “attention kernel의 inner loop에 어떤 추가 연산이 들어가는가”, “paged cache layout과 맞는가”가 곧 성능을 결정한다. UltraQuant는 바로 이 접점에서 FP4 micro-tensor layout을 설계한다.
2.2 FP8 baseline과 TurboQuant baseline의 역할
논문에서 FP8 KV caching은 약한 비교 대상이 아니다. FP8은 하드웨어가 직접 지원하고, vLLM 같은 serving runtime에서 이미 실용성이 입증된 경로다. BF16 대비 cache bytes를 절반으로 줄이면서도 dequantization이 비교적 자연스럽게 matrix core path에 들어간다. 따라서 4-bit 방법이 FP8보다 메모리를 더 아껴도, decode attention에서 추가 overhead가 크면 사용자는 latency나 throughput 손실을 감수해야 한다. 이 때문에 논문은 FP8을 deployment anchor로 둔다.
TurboQuant는 quality anchor에 가깝다. TurboQuant 계열은 rotation과 scalar codebook을 이용해 raw KV 분포를 4-bit로 표현한다. Walsh-Hadamard rotation이 outlier energy를 여러 coordinate로 퍼뜨리면, 각 coordinate의 분포가 더 가벼운 tail을 갖고 작은 codebook으로 근사하기 쉬워진다. 다만 codebook representation은 decode 때 index를 읽고 centroid를 lookup한 뒤 값을 복원해야 한다. 긴 context의 attention tile마다 이 작업이 반복되면 irregular memory access와 software gather가 병목이 된다.
UltraQuant는 두 baseline 사이에서 절충을 시도한다. TurboQuant의 rotation과 4-bit quality 관찰은 유지하되, arbitrary codebook을 버리고 hardware-native FP4 E2M1 grid로 바꾼다. codebook이 고정된 FP4 grid로 바뀌면 Lloyd-Max optimality에서는 손해를 볼 수 있지만, AMD CDNA4의 scaled-MFMA instruction이 FP4 code와 UE8M0 scale을 직접 읽을 수 있다. 즉 논문은 quantization error를 조금 더 받아들이고, kernel inner loop에서 codebook lookup을 없애는 쪽을 택한다.
2.3 이전 리뷰와의 연결
이 논문은 이전에 정리한 MLA 기반 long-context serving 글과 직접 연결된다. MLA는 attention 구조 안에서 저장해야 할 KV representation 자체를 줄이는 방향이고, UltraQuant는 기존 KV tensor를 더 낮은 precision으로 저장하는 방향이다. 두 접근은 경쟁만 하는 관계가 아니라, 긴 문맥 serving에서 HBM 압박을 줄이려는 서로 다른 층의 선택지다. 내가 특히 흥미롭게 본 부분은 UltraQuant가 “memory-efficient attention”을 모델 설계 문제로만 보지 않고, cache residency와 GPU instruction의 결합 문제로 밀어붙인다는 점이다.
3. 방법론: UltraQuant가 4-bit KV를 hardware-native path로 바꾸는 방식
3.1 전체 pipeline: rotation, grouping, FP4 code, UE8M0 scale
UltraQuant의 write path는 비교적 단순하게 요약된다. key tensor는 Walsh-Hadamard rotation을 거쳐 outlier가 완화된 basis로 바뀐다. 그 다음 key와 value를 head dimension 방향으로 32-channel group으로 나눈다. 각 group마다 absolute maximum $m=\max_i |x_i|$를 구하고, global constant $c$를 곱한 뒤 power-of-two exponent로 반올림해 UE8M0 scale byte를 만든다. 각 coordinate는 $x_i / 2^E$를 FP4 E2M1 level 중 가장 가까운 값으로 round한다. 저장 형식은 32개의 FP4 code를 두 개씩 한 byte에 pack하고, group마다 scale byte 하나를 붙이는 구조다.
이 layout은 compression ratio를 명확하게 보여 준다. 32-channel group 하나는 $32\times4\text{ bits}=16\text{B}$의 FP4 code와 1 byte scale을 가진다. 총 17 byte이므로 element당 $4.25$ bit에 해당한다. 이상적인 4-bit 대비 약간의 scale overhead가 있지만, FP8 cache의 절반에 가까운 footprint를 얻는다. 중요한 점은 scale이 arbitrary FP32가 아니라 UE8M0 exponent라는 사실이다. 이 scale byte는 hardware instruction이 exponent shift로 소비할 수 있어, runtime multiply나 BF16 materialization을 줄인다.
| 구성 요소 | UltraQuant 설계 | 의미 |
|---|---|---|
| Rotation | Walsh-Hadamard rotation on K | outlier energy를 퍼뜨려 4-bit scalar quantization이 다룰 수 있는 분포로 변환 |
| Group size | 32 channels per group | FP4 code 32개와 UE8M0 scale 1개를 묶어 matrix core scale operand와 맞춤 |
| Code grid | FP4 E2M1 levels | arbitrary Lloyd codebook 대신 hardware-native low-precision grid 사용 |
| Scale | UE8M0 exponent byte | 값 복원을 곱셈보다 exponent shift에 가깝게 만들고 scaled-MFMA에 fold |
| Stored footprint | 17B per 32 elements | $4.25$ bit/element로 FP8 대비 약 절반의 KV footprint |
3.2 dequantization rule과 scaled-MFMA
논문의 dequantization rule은 다음처럼 쓸 수 있다. $\texttt{value}=\texttt{code}\times2^{\texttt{scale}}$, $\texttt{scale}=\texttt{byte}-127$이다. 여기서 scale이 power-of-two exponent이므로, 실제 구현은 일반적인 floating-point multiply를 반복하는 모양이 아니다. FP4 codepoint의 exponent를 조정하는 연산으로 해석할 수 있고, AMD CDNA4의 $\texttt{MFMA\_SCALE\_F32\_*\_F8F6F4}$ 계열 instruction이 FP4 code와 UE8M0 scale을 함께 받아 누산한다. 이 때문에 keys와 values를 BF16으로 완전히 복원한 뒤 attention을 하는 경로를 피할 수 있다.
QK product에서는 query도 key basis에 맞춰 rotation된 뒤 FP8 E4M3로 round된다. 그러면 QK는 FP8 query와 FP4 key, 그리고 scale operand가 결합된 scaled-MFMA 경로로 들어간다. V path도 FP4 code와 scale을 hardware-supported conversion path로 처리한다. codebook 방식에서는 attention tile마다 packed index를 unpack하고 centroid를 shared memory 또는 register로 가져오는 작업이 필요하지만, UltraQuant는 이 irregular lookup을 제거한다. 따라서 논문의 시스템적 기여는 “4-bit를 쓴다”에서 “4-bit를 matrix core가 바로 읽게 만든다”에 가깝다.
3.3 constant-optimized scaling
FP4 grid는 hardware-native라는 장점이 있지만, arbitrary distribution에 대해 Lloyd-Max centroid처럼 최적화된 codebook은 아니다. UltraQuant는 이 gap을 constant-optimized per-block scaling으로 줄인다. group의 absmax $m$에 global constant $c$를 곱하고, 그 값을 가장 가까운 power-of-two scale로 저장한다. 논문은 $c=0.156$을 offline calibration으로 선택한다. 목적 함수는 normalized coordinate가 FP4 codepoint로 round된 뒤 원래 값과 갖는 MSE를 최소화하는 1차원 문제로 표현된다.
이 constant가 model-agnostic하게 작동할 수 있다는 주장은 rotation 이후 분포 가정에 기대고 있다. Hadamard rotation 후 group 내부 coordinate는 unit-vector coordinate처럼 더 규칙적인 모양을 띠며, per-group absmax가 크기 변동을 흡수한다. 그러면 남는 문제는 고정된 FP4 grid 위에 이 normalized shape를 어디에 놓을지, 즉 $s/m$ 비율을 고르는 문제가 된다. 이 설명은 약간 이상화되어 있지만, 논문의 ablation은 per-block absmax와 $c=0.156$이 실제 accuracy에 영향을 준다는 점을 보여 준다.
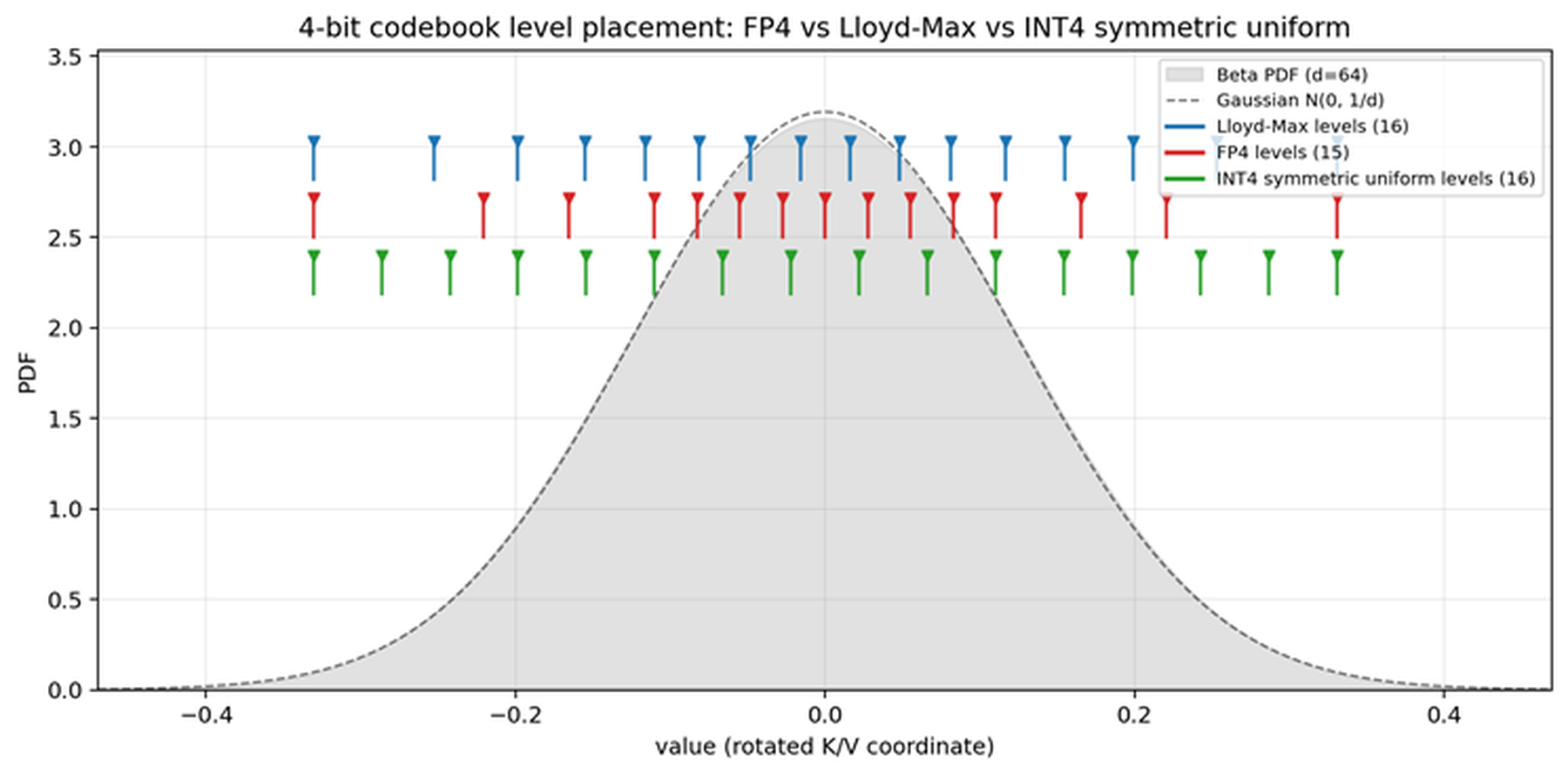
Figure 1: rotated unit-vector distribution에서 Lloyd-Max, FP4 E2M1, INT4 codebook level 배치 비교
이 그림은 UltraQuant가 왜 Lloyd-Max codebook을 그대로 쓰지 않는지 보여 준다. Lloyd-Max centroid는 확률질량이 큰 중앙부에 더 촘촘하게 배치되고 tail에는 넓게 배치된다. FP4 E2M1은 그보다 거칠지만 hardware가 직접 이해하는 격자라는 장점이 있다. 논문은 이 격자의 약점을 per-block scale과 constant calibration으로 줄이려 하며, INT4 uniform grid는 같은 4-bit라도 분포 적합성이 낮은 기준선으로 사용된다.
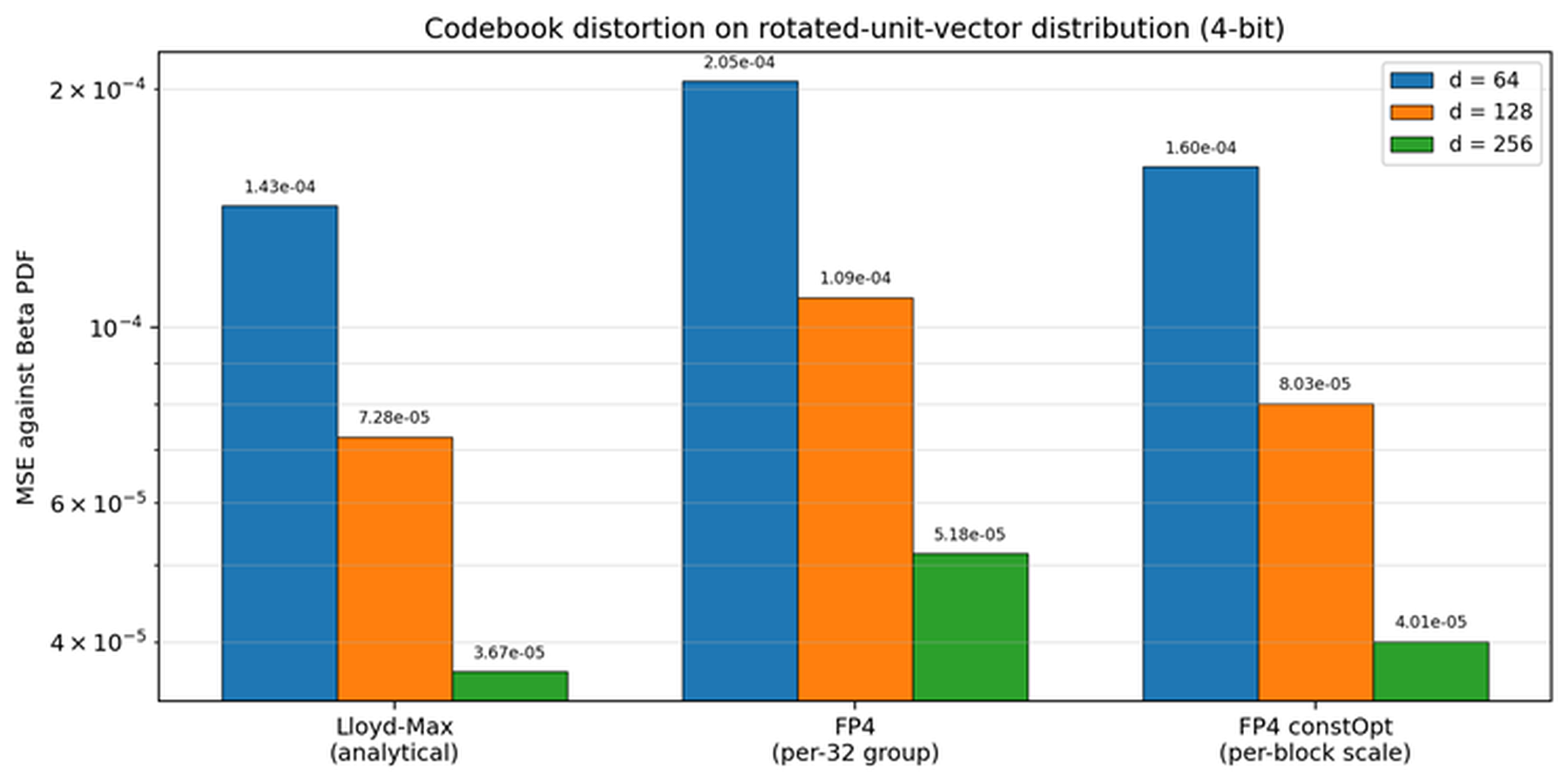
Figure 2: rotated unit-vector distribution에서 codebook distortion과 constOpt scale의 효과
distortion 그림은 FP4가 이론적 Lloyd-Max floor보다 MSE가 높다는 사실을 숨기지 않는다. 대신 constOpt per-block scaling을 붙이면 그 차이가 상당히 줄어든다는 점을 보여 준다. 이 결과는 UltraQuant의 철학을 잘 압축한다. 순수 quantization 관점의 최적 codebook을 포기하되, hardware-native representation의 속도 이득을 얻고, 남는 오차는 scale 설계로 통제한다는 선택이다.
3.4 Ultra-TQ와 UltraQuant의 분기
논문에는 Ultra-TQ와 UltraQuant라는 두 endpoint가 함께 나온다. Ultra-TQ는 TurboQuant representation을 유지하면서 kernel을 최적화한 경로다. GQA-aware tiling, structure-of-arrays layout, AMD-specific MFMA dispatch, LUT access 개선을 통해 open-source TurboQuant path보다 훨씬 빠르게 만든다. 반면 UltraQuant는 representation 자체를 FP4 micro-tensor로 바꾼다. 따라서 Ultra-TQ는 quality-preserving codebook path이고, UltraQuant는 hardware-native FP4 path로 이해하면 된다.
이 구분은 실험 해석에서 중요하다. Ultra-TQ가 더 나은 accuracy를 보이는 benchmark가 있을 수 있고, UltraQuant는 latency와 cache residency에서 더 강하다. production에서 어느 쪽을 택할지는 workload가 accuracy-sensitive reasoning인지, long-context multi-turn serving인지, AMD CDNA4 scaled-MFMA 경로를 사용할 수 있는지에 따라 달라진다. 논문은 최종적으로 context-heavy agent serving에서는 UltraQuant가 FP8에 가까운 kernel speed와 4-bit footprint를 함께 제공한다고 주장한다.
4. 실험 설정: multi-turn agent serving과 production accuracy를 함께 본다
4.1 데이터셋 및 벤치마크
성능 실험의 중심은 vLLM native multi-turn benchmark다. 논문은 ShareGPT conversation data를 사용해 실제 사용자/assistant 형식의 multi-round chat session을 구성하고, 32개의 concurrent chat session을 serve한다. 입력 context는 turn을 거치며 누적되고, 각 client의 prefix가 길어진다. 이 환경은 단일 prompt benchmark보다 agent serving에 가깝다. 긴 system prompt와 tool context가 여러 turn에 걸쳐 재사용되고, cache가 resident하면 다음 turn의 TTFT가 줄어드는 효과가 드러난다.
accuracy 측정은 세 모델과 여러 benchmark를 포함한다. Qwen3.5-A3B, MiniMax-M2.5, Qwen2.5-72B가 등장하고, GPQA-Diamond, LCB-128K, AIME25, MATH500이 사용된다. 이 조합은 과학 QA, 긴 context coding, 수학 reasoning, 일반 수학 문제를 섞은 것이다. 논문은 특히 boundary-layer protection을 적용해 첫 두 attention layer와 마지막 두 attention layer는 BF16 KV cache로 유지한다. 낮은 bit cache가 모든 layer에 똑같이 안전하다고 가정하지 않고, 민감한 경계 layer를 보호한 production-style setting으로 평가한다.
4.2 구현 세부사항
serving 성능 실험은 MiniMax-M2.5, tensor parallelism $TP=2$, $2\times$ AMD MI355X, 32K input / 1K output, concurrency $C=64$ 같은 조건을 중심으로 보고된다. baseline은 BF16 AITER FlashAttention, hardware FP8 KV, vLLM OSS TurboQuant, Ultra-TQ, UltraQuant이다. 모든 throughput과 latency는 BF16 AITER baseline을 $1.00\times$로 두고 상대값으로 제시된다. 이 상대값 기준 덕분에 논문은 absolute token/sec보다 kernel path 간 차이를 더 명확히 보여 준다.
UltraQuant kernel은 CDNA4 scaled-MFMA family, 특히 $\texttt{v\_mfma\_scale\_f32\_16x16x128\_f8f6f4}$ instruction을 겨냥한다. query는 K-tile inner loop 밖에서 FP8로 미리 round되어 반복 packing을 줄이고, cache layout은 scale operand layout에 맞춰 배치된다. 이 구현 세부사항은 논문 결과의 적용 범위를 제한한다. 같은 FP4 idea라도 GPU가 scaled-MFMA 형태로 FP4와 scale을 함께 소비하지 못하면 UltraQuant의 latency story가 그대로 재현되기 어렵다.
4.3 베이스라인
BF16 baseline은 dequantization이 필요 없는 가장 단순한 경로지만 cache footprint가 가장 크다. FP8 KV baseline은 cache footprint를 절반으로 줄이고 hardware path를 유지한다. vLLM OSS TurboQuant는 4-bit cache라는 capacity 장점은 있지만 software dequantization bottleneck이 뚜렷한 비교 대상이다. Ultra-TQ는 TurboQuant representation을 AMD GPU에 맞게 최대한 최적화한 내부 baseline이고, UltraQuant는 FP4와 UE8M0 scale을 사용하는 최종 제안이다.
| 평가 축 | 설정 | 해석 포인트 |
|---|---|---|
| Agentic serving | ShareGPT 기반 multi-turn, 32 concurrent sessions | prefix reuse와 resident cache가 TTFT에 미치는 영향 확인 |
| Hardware | MiniMax-M2.5, TP=2, 2× AMD MI355X | CDNA4 scaled-MFMA 경로에서 UltraQuant의 실제 배포성 확인 |
| Latency metrics | P50 TTFT, P50 TPOT, inter-token latency | prefill 재계산과 decode inner loop overhead를 분리해서 관찰 |
| Accuracy benchmarks | GPQA-Diamond, LCB-128K, AIME25, MATH500 | 4-bit FP4 cache가 reasoning/coding task에 주는 품질 손실 확인 |
| Layer policy | first/last two attention layers BF16 | 민감한 boundary layer를 보호한 production-style 조건 |
5. 주요 실험 결과: cache residency가 TTFT를 바꾸는 구간
5.1 multi-round agentic serving 결과
가장 눈에 띄는 수치는 late rounds에서의 TTFT 개선이다. warm rounds인 r2-r3에서는 UltraQuant가 FP8보다 $0.86\times$로 약간 불리하다. 이 구간에서는 아직 FP8 cache가 충분히 resident하고, 4-bit path의 encoding 또는 kernel overhead가 두드러질 수 있다. 그러나 r4-r6처럼 per-client prefix가 길어지고 resident-cache capacity가 압박받는 구간에서는 상황이 바뀐다. UltraQuant는 FP8 대비 P50 TTFT를 $3.47\times$ 개선한다. 전체 round로 보면 $2.3\times$, output throughput은 $1.63\times$다.
| Metric | UltraQuant vs. FP8 KV | 해석 |
|---|---|---|
| P50 TTFT — warm rounds (r2–3) | $0.86\times$ (FP8 faster) | cache pressure가 낮을 때는 FP8의 hardware path가 더 단순할 수 있음 |
| P50 TTFT — late rounds (r4–6) | $3.47\times$ | 긴 prefix가 FP8 resident capacity를 넘는 구간에서 재-prefill 회피 효과가 커짐 |
| P50 TTFT — all rounds | $2.3\times$ | 초반 손실보다 후반 cache residency 이득이 더 큼 |
| Output throughput | $1.63\times$ | 동시 세션과 긴 prefix가 있을 때 resident cache 증가가 처리량으로 연결 |
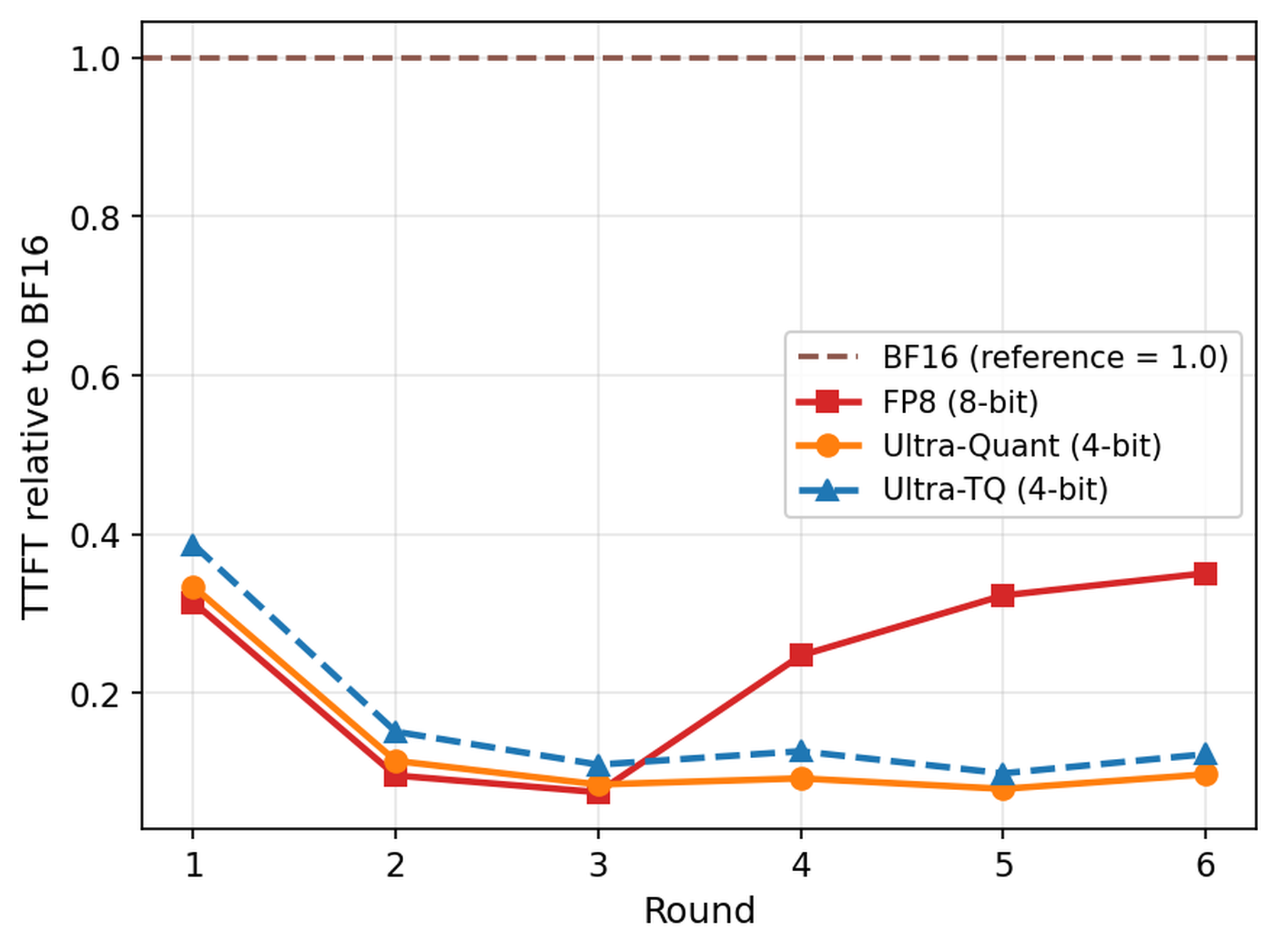
Figure 3: multi-turn agentic workload에서 round별 TTFT 비교
TTFT 그래프는 UltraQuant가 모든 상황에서 항상 빠르다는 메시지보다, cache pressure가 커질수록 이득이 커진다는 구조를 보여 준다. 초기 round에서는 FP8 path가 충분히 버티지만, 누적 context가 resident cache budget을 넘는 순간 FP8은 재계산 비용을 떠안는다. UltraQuant는 4-bit footprint 덕분에 더 많은 prefix를 GPU에 남기므로 late round의 첫 token 대기시간을 크게 줄인다.
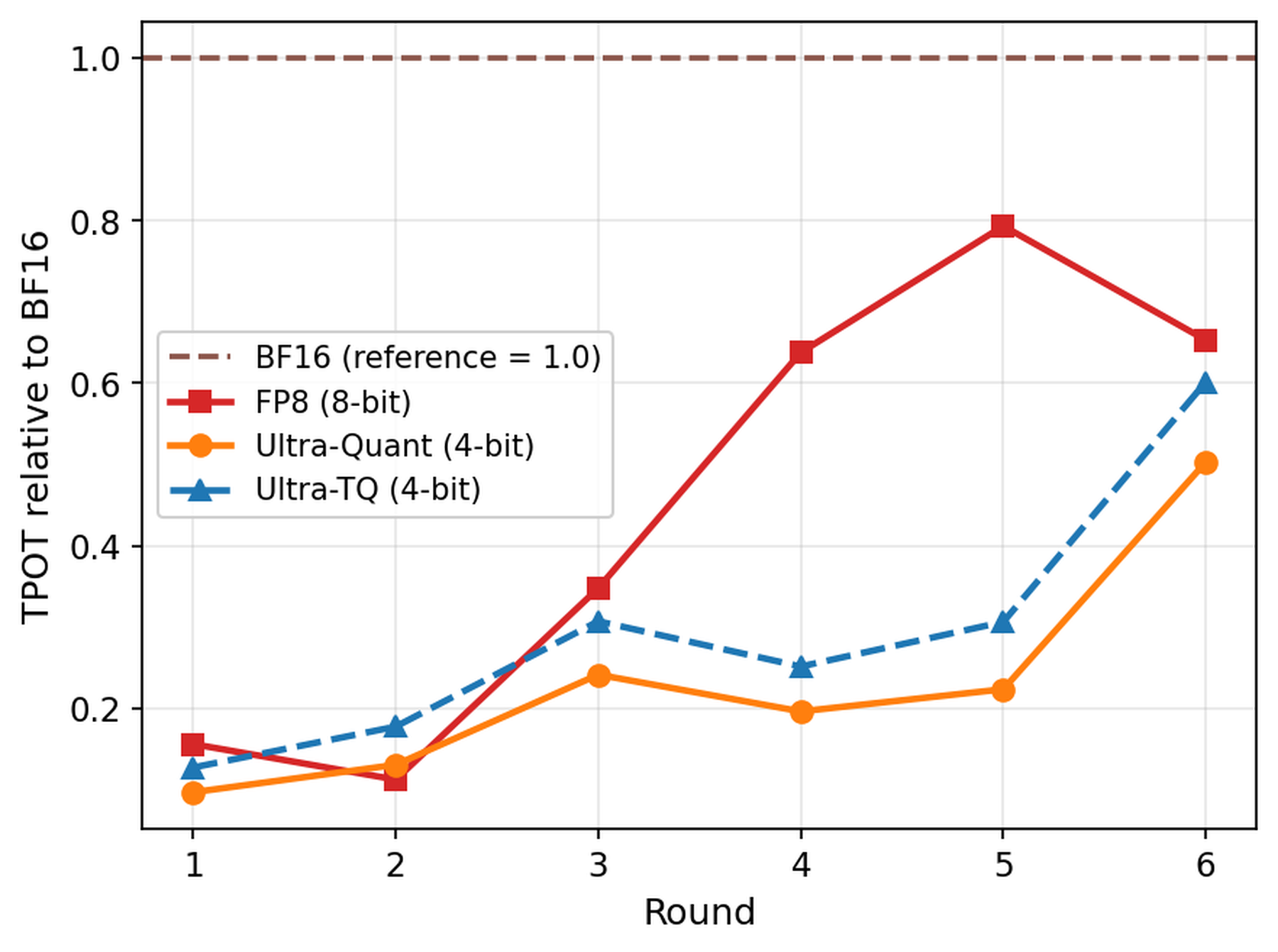
Figure 4: multi-turn agentic workload에서 round별 TPOT 비교
TPOT 그림은 TTFT와 다른 병목을 보여 준다. TTFT가 cache eviction과 prefill 재계산의 영향을 크게 받는다면, TPOT는 decode attention inner loop의 비용을 더 직접적으로 반영한다. UltraQuant가 software TurboQuant보다 안정적으로 낮은 TPOT를 유지하는 이유는 codebook lookup을 제거했기 때문이다. 이 그림은 4-bit cache가 capacity만 늘리는 설계로 끝나면 충분하지 않고, decode kernel path가 함께 가벼워야 한다는 점을 강조한다.
5.2 throughput과 per-token latency
throughput 결과에서 UltraQuant는 BF16 대비 $1.38\times$ output throughput을 보이고, hardware FP8 KV의 $1.37\times$와 거의 같은 수준에 도달한다. 이 수치는 중요하다. FP8은 hardware-native 경로라는 강점을 갖고 있기 때문에, 4-bit 방법이 FP8과 비슷한 throughput을 내면서 cache footprint를 더 줄이면 serving capacity 측면에서 실질적 이득이 생긴다. Ultra-TQ는 codebook path를 최적화해도 representation 자체가 lookup을 요구하므로, FP4 scaled-MFMA path와 같은 ceiling에 도달하기 어렵다.
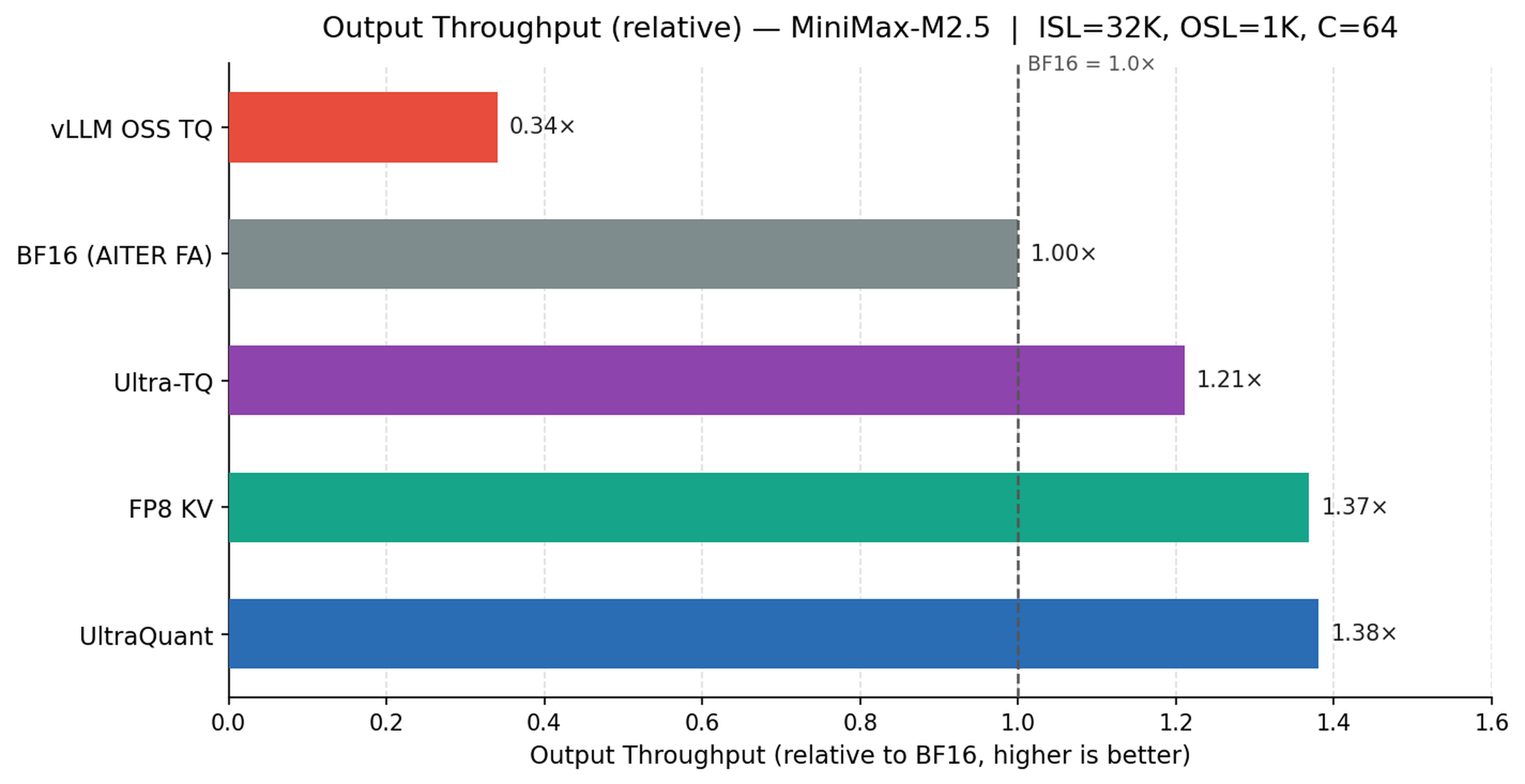
Figure 5: MiniMax-M2.5 serving에서 BF16 대비 output throughput 비교
throughput figure는 UltraQuant가 FP8 KV path와 거의 같은 instruction efficiency를 얻었다는 주장을 뒷받침한다. vLLM OSS TurboQuant는 4-bit cache임에도 software dequantization 때문에 낮은 위치에 머문다. Ultra-TQ는 최적화로 격차를 줄이지만, UltraQuant는 FP4 code와 UE8M0 scale을 matrix core가 직접 소비하게 만들어 FP8과 비슷한 처리량에 접근한다.
TPOT에서는 UltraQuant가 BF16 대비 $1.40\times$로 보고된다. BF16은 dequantization이 없으므로 absolute decode latency에서는 여전히 강하다. 하지만 UltraQuant는 hardware FP8 KV의 $1.37\times$와 약 $2\%$ 수준 차이로 붙어 있고, Ultra-TQ의 $1.58\times$, vLLM OSS TurboQuant의 $5.56\times$보다 훨씬 낮다. 이 결과는 FP4 representation이 kernel inner loop에서 실제로 가벼워졌다는 근거다. 단순히 cache를 압축했기 때문에 throughput이 좋아진 것이 아니라, dequantization을 critical path 밖으로 밀어낸 효과가 관찰된다.
| Kernel path | Median TPOT vs. BF16 | 특징 |
|---|---|---|
| BF16 AITER FlashAttention | $1.00\times$ | dequantization 없음, cache footprint 최대 |
| Hardware FP8 KV | $1.37\times$ | 하드웨어 지원과 절반 cache footprint |
| UltraQuant | $1.40\times$ | FP4 KV와 UE8M0 scale을 scaled-MFMA 경로로 소비 |
| Ultra-TQ | $1.58\times$ | 최적화된 codebook path지만 LUT/dequant overhead 존재 |
| vLLM OSS TurboQuant | $5.56\times$ | software dequantization 병목이 긴 context에서 크게 드러남 |
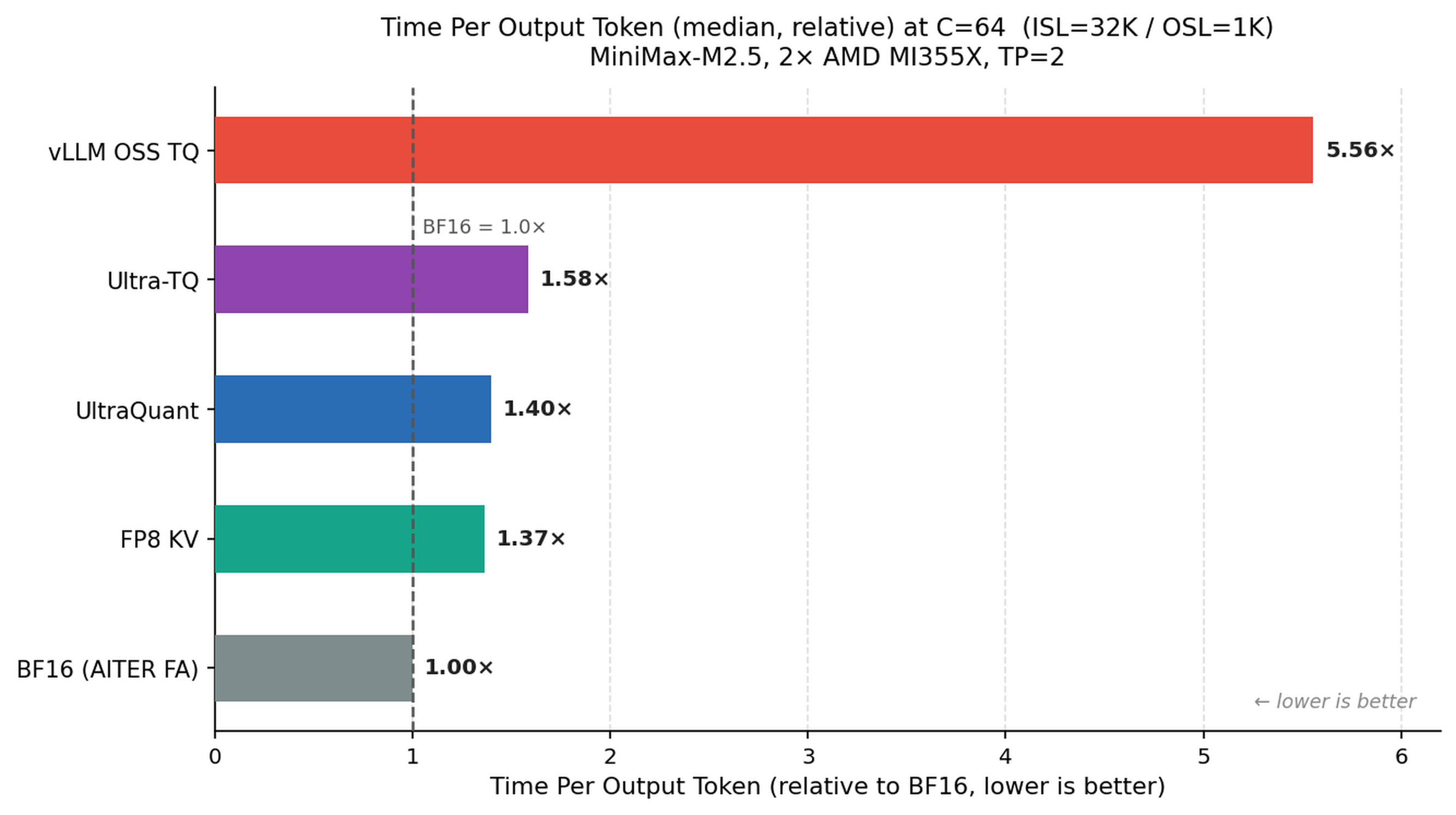
Figure 6: 32K/1K, concurrency 64 설정에서 median TPOT 상대값
이 그림은 FP4 path의 장점과 한계를 함께 보여 준다. UltraQuant는 BF16보다 per-token decode가 느리지만, FP8 KV와 거의 같은 범위에 들어간다. 반면 codebook 기반 4-bit path는 cache bytes는 줄어도 decode마다 centroid를 복원해야 해 latency가 커진다. production serving에서는 memory footprint와 per-token latency가 함께 중요하므로, 이 간격이 UltraQuant의 배포 가치를 만든다.
5.3 context length sweep
inter-token latency sweep에서는 context length가 길어질수록 UltraQuant의 상대적 이득이 커진다. 논문은 8K에서 64K까지 입력 context를 늘리며 FP8, UltraQuant, Ultra-TQ를 비교한다. UltraQuant는 긴 context로 갈수록 BF16 대비 상대 latency가 좋아지고, 64K에서는 약 $0.5\times$ 수준까지 내려간다고 설명한다. 이는 cache footprint가 줄어든 효과가 context length가 커질수록 더 직접적으로 나타난다는 뜻이다.
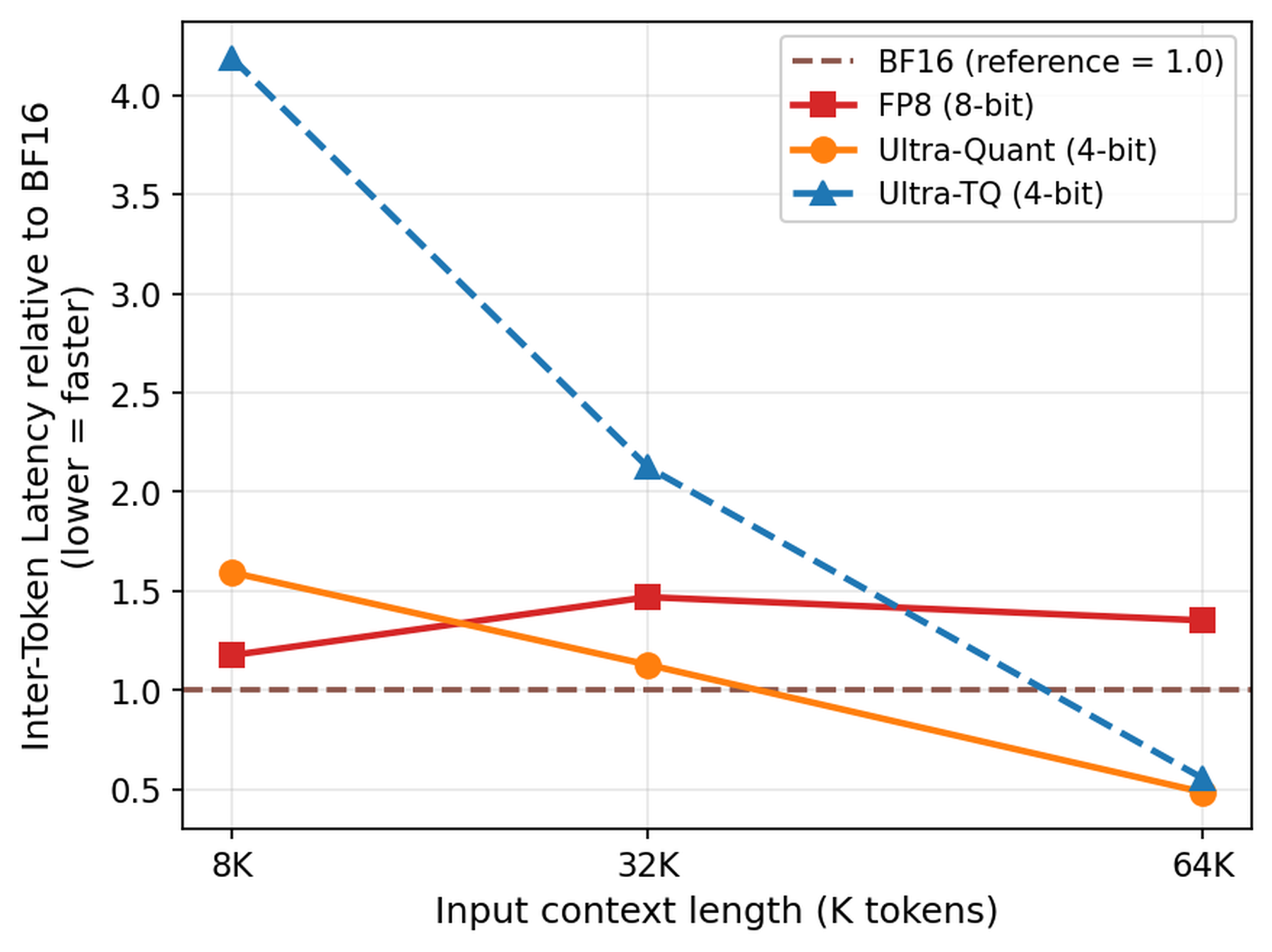
Figure 7: input context length에 따른 inter-token latency 비교
context sweep은 UltraQuant가 짧은 prompt용 최적화라기보다 long-context serving용 최적화라는 점을 분명히 한다. 8K 부근에서는 FP8이나 BF16의 단순한 경로가 충분히 경쟁적이지만, 64K에 가까워질수록 cache footprint가 decode scheduling과 memory traffic을 좌우한다. UltraQuant가 긴 context에서 상대적으로 좋아지는 패턴은 agent workload의 late-round TTFT 개선과 같은 원인에서 나온다.
5.4 왜 late-round TTFT가 serving 비용을 바꾸는가
UltraQuant 결과에서 late-round TTFT가 큰 폭으로 줄어드는 현상은 사용자가 체감하는 대기시간과 직접 연결된다. multi-turn agent는 매 round마다 새 답변을 길게 생성하기보다, 긴 prefix를 다시 읽고 짧은 action이나 tool call을 내는 경우가 많다. 이때 첫 token이 늦게 나오면 전체 상호작용이 멈춘 것처럼 느껴진다. resident KV cache가 충분하면 model은 이전 context를 다시 prefill하지 않고 바로 decode로 넘어가지만, cache가 evict되면 긴 prefix를 다시 계산해야 한다. UltraQuant의 cache footprint 절감은 바로 이 재-prefill 위험을 줄이는 방향으로 작동한다.
이 차이는 단순 평균 throughput으로는 잘 보이지 않는다. 동일한 output token/sec라도 한 사용자의 round가 cache miss를 만나면 TTFT tail이 커지고, scheduler는 긴 prefill job과 짧은 decode job을 함께 다뤄야 한다. FP8 KV는 짧은 context나 낮은 concurrency에서 매우 합리적이지만, context가 누적된 에이전트 세션이 여러 개 동시에 살아 있으면 resident prefix 수가 부족해질 수 있다. UltraQuant는 element당 약 $4.25$ bit에 가까운 footprint로 더 많은 prefix를 HBM에 남기므로, late-round에서 scheduler가 prefill로 되돌아가는 빈도를 낮춘다.
논문이 ShareGPT multi-round setting을 사용한 이유도 여기에 있다. 일반적인 single-turn benchmark는 cache eviction과 reuse의 동학을 충분히 만들지 못한다. 반면 agentic workload에서는 conversation state, tool result, retrieved document, code snippet이 누적되며, 같은 session의 이전 prefix가 다음 round에서 다시 사용된다. cache residency와 TTFT를 함께 보면, 낮은 bit cache가 단지 메모리 절약이 아니라 user-perceived interactivity를 개선하는 자원 관리 전략으로 해석된다.
| Serving 상황 | FP8 KV에서의 위험 | UltraQuant가 줄이는 비용 |
|---|---|---|
| 짧은 single-turn 질의 | cache pressure가 낮아 FP8 hardware path가 충분히 빠름 | footprint 이득은 있지만 latency 이득은 작을 수 있음 |
| 긴 prefix를 가진 multi-turn agent | resident prefix 부족으로 late-round prefill 재계산 발생 | 더 많은 session prefix를 남겨 TTFT tail을 낮춤 |
| 높은 concurrency serving | 한 session의 긴 KV가 다른 session cache를 밀어냄 | HBM budget 안에서 동시 resident session 수를 늘림 |
| 짧은 output을 반복하는 tool-use loop | 생성 token보다 첫 token 대기시간이 체감 성능을 좌우 | decode throughput보다 prefix reuse 경로를 안정화 |
따라서 UltraQuant의 성능 결과는 “4-bit가 FP8보다 빠르다”처럼 읽기보다, cache pressure regime을 찾아낸 결과로 읽는 편이 정확하다. 같은 모델과 같은 kernel도 GMU, concurrency, prompt length, output length, scheduler policy가 바뀌면 상대 순위가 달라질 수 있다. 논문이 warm rounds에서 FP8이 더 빠를 수 있음을 함께 보여 준 점은 이 해석을 더 탄탄하게 만든다. 좋은 시스템 논문은 평균 성능 하나로 주장하지 않고, 어떤 구간에서 이득이 생기고 어떤 구간에서 baseline이 유리한지 분해한다.
6. 추가 분석 및 Ablation Study: 성능 이득을 만드는 세부 선택들
6.1 per-block scale ablation
per-block scale ablation은 UltraQuant 설계에서 무엇이 실제로 load-bearing component인지 보여 준다. GPT-OSS-20B GPQA medium effort single seed 조건에서, per-token $\ell_2$ norm을 쓰는 K+V Lloyd 설정은 $0.6237$을 기록한다. 여기에 per-block absmax를 적용한 LMPb full은 $0.6559$로 올라간다. 반대로 per-block absmax가 고정되면 calibrated Lloyd codebook과 uniform codebook의 차이는 $0.6559$와 $0.6528$로 single-seed noise 범위에 가깝다.
| Configuration | Adaptation | Codebook | GPQA |
|---|---|---|---|
| TQ-t4nc (production) | per-token $\ell_2$ | Lloyd (calib.) | 0.6503 |
| K+V Lloyd, per-token | per-token $\ell_2$ | Lloyd (calib.) | 0.6237 |
| LMPb full | per-block absmax | Lloyd (calib.) | 0.6559 |
| Variant E | per-block absmax | uniform (RTN) | 0.6528 |
이 표는 논문의 핵심 직관을 강하게 뒷받침한다. 좋은 codebook을 찾는 것보다, group 단위 scale을 어떻게 잡느냐가 더 큰 영향을 준다. 물론 codebook과 adaptation이 완전히 독립적으로 분리된 실험은 아니기 때문에 결과를 과도하게 일반화하면 안 된다. 하지만 UltraQuant가 arbitrary Lloyd codebook을 버리고 fixed FP4 grid를 택할 수 있는 근거는 이 ablation에 있다. per-block absmax가 충분히 안정적이면, hardware-native grid의 속도 이득을 위해 codebook optimality를 일부 포기할 수 있다.
6.2 global constant ablation
global constant $c$도 성능에 민감하다. 논문은 default $c=0.156$이 MSE-optimal이고, 같은 evaluation에서 FP8 baseline보다 $+4.4$ percentage point 높은 accuracy를 보였다고 보고한다. $c=0.195$로 키우면 FP8 baseline과 같아지고, $c=1.0$처럼 raw absmax를 그대로 쓰면 FP8보다 $-4.3$ pp 낮아진다. 즉 scale을 조금만 잘못 잡아도 FP4 grid의 effective dynamic range가 달라지고, quantization error가 reasoning accuracy로 번진다.
| Scheme | Accuracy | vs. FP8 baseline |
|---|---|---|
| FP8 (8-bit baseline) | 63.0% | — |
| fp4 $c=0.156$ (default) | 67.4% | +4.4 pp |
| fp4 $c=0.195$ | 63.0% | 0.0 pp |
| fp4 $c=1.0$ (no shrinkage) | 58.7% | -4.3 pp |
이 ablation은 UltraQuant가 “FP4를 쓰면 된다”는 방식의 단순한 하드웨어 찬양이 아니라는 점을 보여 준다. FP4 codepoint는 고정되어 있고, 실제 값 분포를 그 grid 위에 올리는 scale 선택이 품질을 좌우한다. $c=0.156$이라는 값은 작아 보이지만, group absmax를 그대로 scale로 쓰면 tail에 너무 많은 grid range가 배정되고 중앙부 resolution이 떨어진다. shrinkage constant는 중앙부의 빈번한 값을 더 잘 표현하도록 scale을 당기는 역할을 한다.
6.3 kernel optimization ladder
논문은 Ultra-TQ와 UltraQuant 각각에 대해 optimization ladder를 제시한다. Ultra-TQ는 Triton kernel 개선, native ISA implementation, FlyDSL JIT 경로를 거치며 TurboQuant codebook path의 overhead를 줄인다. UltraQuant는 여기에서 representation을 FP4 plus UE8M0 cache layout으로 바꾸고, QK product를 scaled F8F6F4 MFMA로 보내며, V-dequant LUT를 hardware conversion path로 대체한다. 이 ladder는 시스템 논문으로서 중요한 장면이다. 같은 algorithmic idea라도, kernel implementation 단계에서 어떤 operand layout을 택하느냐에 따라 실험 결과가 크게 달라진다.
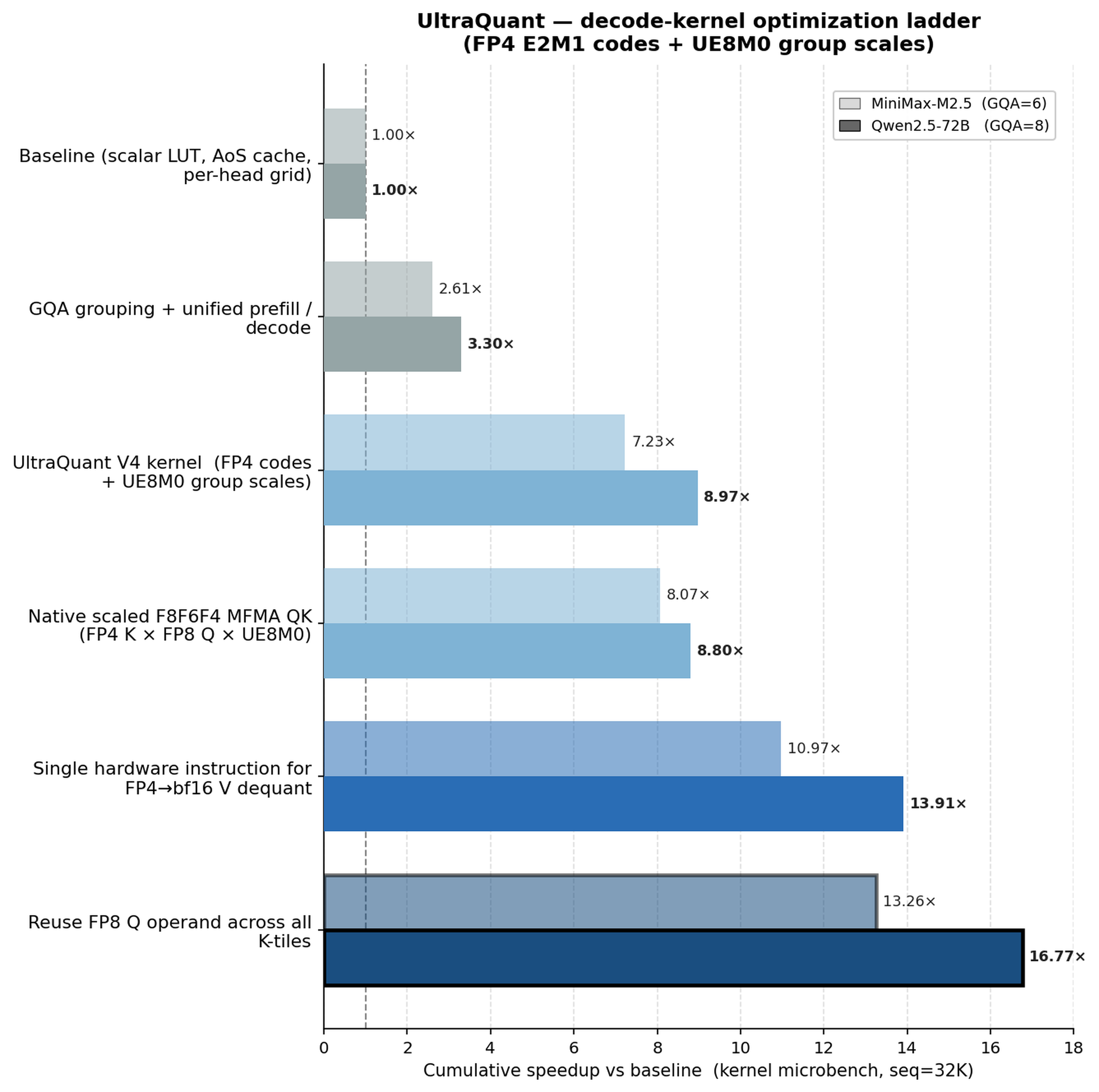
Figure 8: FP4 decode-attention kernel을 hardware-native path로 만드는 최적화 ladder
UltraQuant ladder는 논문의 시스템 기여를 한 장에 요약한다. 첫 단계는 FP4 KV와 scale을 cache layout에 맞추는 것이고, 다음 단계는 QK와 PV 경로에서 software dequantization을 제거하는 것이다. query를 FP8로 미리 round해 tile loop 안의 반복 작업을 줄이고, scale operand를 MFMA instruction이 읽기 쉬운 형태로 배치한다. 이 구조 때문에 UltraQuant는 4-bit footprint를 유지하면서 FP8에 가까운 throughput ceiling에 접근한다.
6.4 cache pressure regime ablation
GMU ablation은 UltraQuant의 이득이 어떤 운영 조건에서 나타나는지 설명한다. GMU $0.60$에서는 resident-cache budget이 tight하여 FP8이 later rounds에서 악화되고, UltraQuant는 낮은 latency를 유지한다. GMU $0.65$처럼 cache budget이 커지면 FP8도 prefix를 더 오래 유지할 수 있어 세 방법의 차이가 줄어든다. 이 결과는 UltraQuant의 주장 범위를 정직하게 제한한다. cache pressure가 충분히 높은 상황에서는 4-bit residency가 큰 이득을 만들지만, memory budget이 넉넉하거나 context가 짧으면 FP8의 단순 경로가 여전히 강할 수 있다.
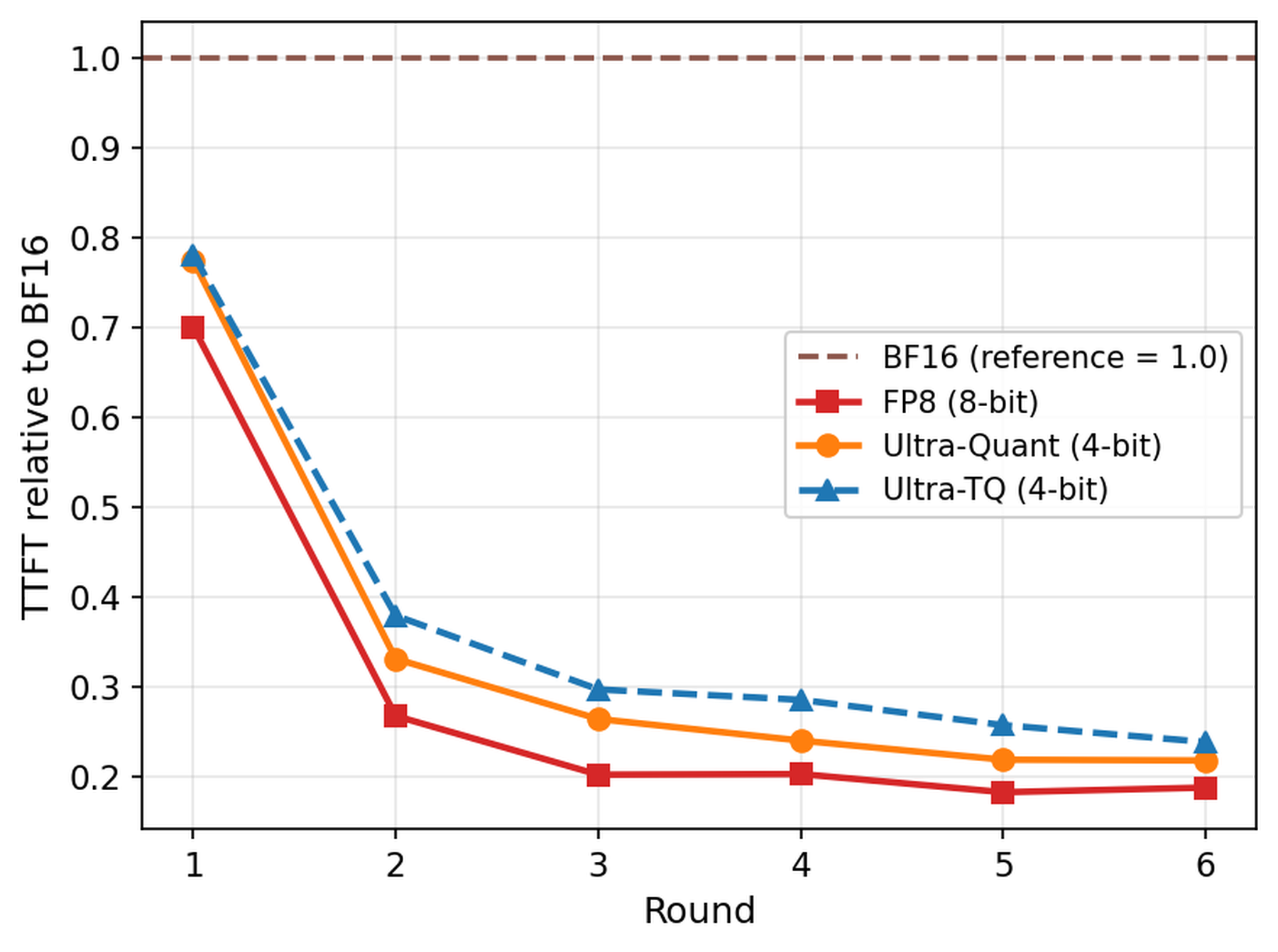
Figure 9: GPU memory utilization 조건 변화에 따른 TTFT ablation
GMU TTFT ablation은 serving system의 여유 메모리가 결과를 얼마나 바꿀 수 있는지 보여 준다. 같은 quantization scheme이라도 scheduler가 허용하는 resident cache budget이 다르면 late-round latency 양상이 달라진다. UltraQuant의 큰 TTFT 이득은 cache eviction이 실제로 발생하는 구간에서 나오므로, 배포자는 자신의 workload concurrency와 memory utilization policy를 함께 측정해야 한다.
6.5 FP4 grid 선택이 만드는 품질-성능 trade-off
UltraQuant의 가장 중요한 선택은 arbitrary scalar codebook을 버리고 FP4 E2M1 grid를 쓰는 것이다. codebook quantization 관점에서는 이 선택이 손해처럼 보인다. TurboQuant-style Lloyd-Max centroid는 calibration distribution에 맞춰 level 위치를 조정할 수 있고, 낮은 bit에서 MSE를 더 줄일 여지가 있다. 그러나 serving kernel 관점에서는 arbitrary centroid가 매 attention tile마다 lookup과 복원 비용을 만든다. UltraQuant는 이 비용을 줄이기 위해 quantization optimum을 일부 양보하고, hardware instruction이 직접 처리할 수 있는 number format을 택한다.
이 trade-off는 QK path와 PV path 모두에서 나타난다. QK에서는 query와 key의 dot product가 attention score를 만들고, key value의 scale과 code가 반복적으로 사용된다. PV에서는 softmax weight가 value cache와 곱해져 output hidden state를 만든다. 두 경로 모두 긴 context에서는 동일 cache tile을 자주 읽는다. codebook 방식은 value 복원 자체가 별도 단계로 끼어들기 쉬운 반면, UltraQuant는 scale operand를 matrix core instruction 주변으로 밀어 넣어 데이터 흐름을 단순화한다.
다만 FP4 grid를 쓴다고 모든 문제가 사라지지는 않는다. FP4 E2M1은 표현 가능한 level 수가 적고, exponent와 mantissa 구조가 매우 거칠다. 분포의 중앙부가 너무 넓게 퍼져 있거나, 특정 layer/head에서 outlier가 rotation 이후에도 남으면 scale 하나로 group 전체를 잘 맞추기 어렵다. 그래서 Hadamard rotation, per-block absmax, constant-optimized scaling이 한 세트로 필요하다. 어느 하나만 떼어내면 UltraQuant는 단순한 FP4 rounding으로 약해질 가능성이 크다.
논문에서 per-block absmax가 큰 역할을 하는 것도 같은 맥락이다. group 내부의 dynamic range를 local하게 잡아 주면, FP4 codepoint가 실제 값 분포의 유효 구간을 더 잘 덮는다. 여기에 $c=0.156$ 같은 shrinkage를 붙이면 raw absmax가 tail에 끌려 중앙부 resolution을 낭비하는 문제를 줄인다. 이 설계는 classic post-training quantization에서 activation clipping이나 percentile scaling을 쓰는 직관과 닮았지만, KV cache에서는 attention 품질과 decode kernel cost가 동시에 걸려 있다는 점이 다르다.
| 선택지 | 품질 측면 | 커널 측면 |
|---|---|---|
| Lloyd-Max codebook | calibration distribution에 맞춰 MSE를 낮추기 쉬움 | decode inner loop에서 LUT와 unpack overhead가 생김 |
| Uniform INT4 grid | 구현은 단순하지만 중앙부/꼬리 분포 적합성이 낮을 수 있음 | hardware path는 단순하나 floating distribution 표현력이 약함 |
| FP4 E2M1 + UE8M0 | scale calibration이 필요하지만 rotated KV에 잘 맞으면 충분한 품질 가능 | scaled-MFMA가 code와 scale을 직접 소비해 overhead를 낮춤 |
내가 보기에는 이 표가 UltraQuant의 설계 철학을 가장 잘 정리한다. 알고리즘만 보면 Lloyd-Max가 더 자연스럽고, 하드웨어만 보면 FP8이 더 단순하다. UltraQuant는 그 사이에서 hardware-native 4-bit라는 좁은 길을 잡는다. 이 길은 GPU instruction support가 있을 때 매우 강하지만, instruction과 runtime이 맞지 않으면 논문의 장점이 줄어든다. 그래서 이 방법을 평가할 때는 quantization error 표만 보지 말고, 실제 attention kernel에서 어떤 operand가 어떤 순서로 읽히는지까지 확인해야 한다.
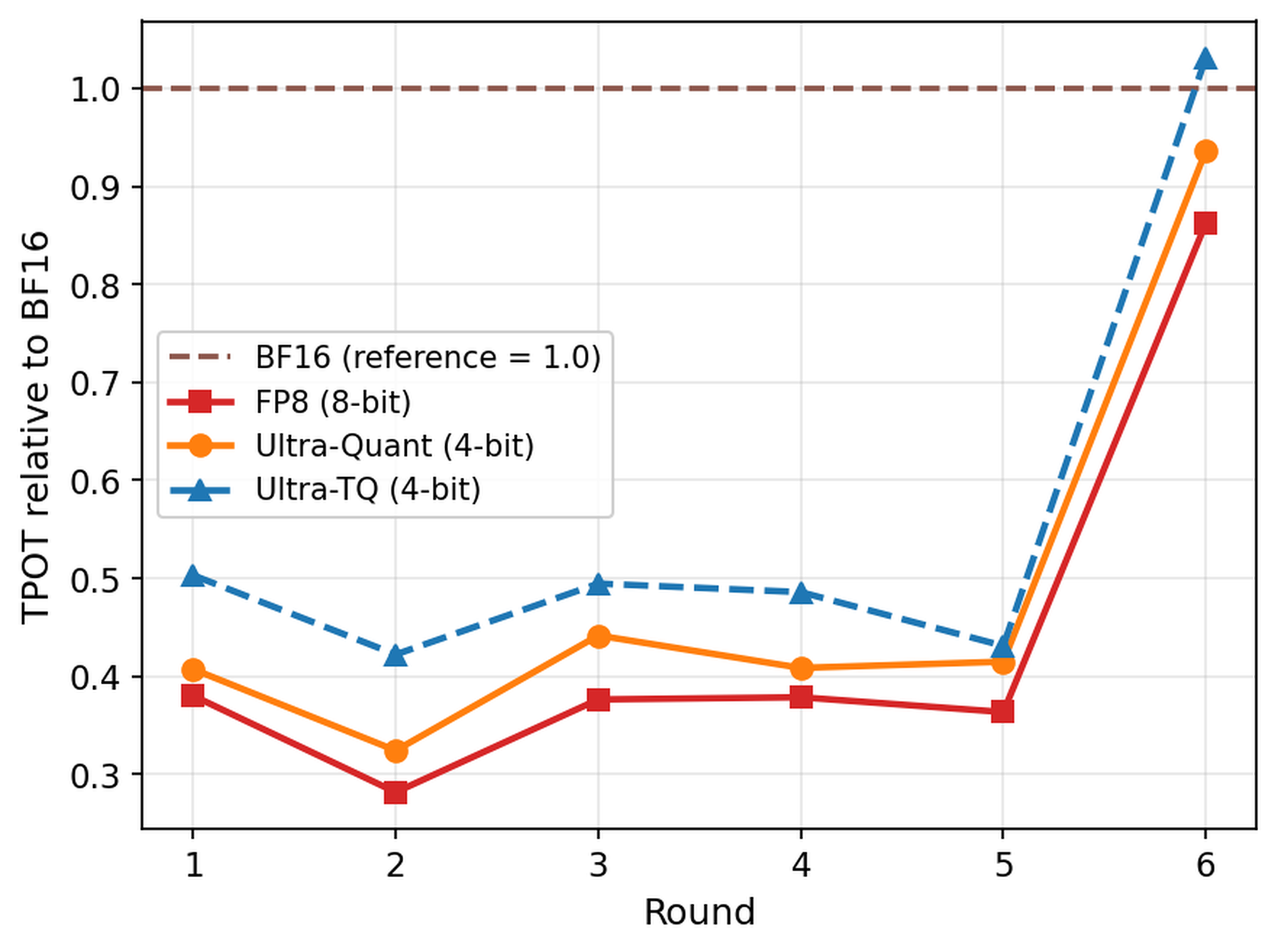
Figure 10: GPU memory utilization 조건 변화에 따른 TPOT ablation
TPOT ablation은 cache budget이 넉넉해질 때 per-token decode 비용 차이가 어떻게 줄어드는지 보여 준다. GMU가 높아지면 FP8도 더 많은 prefix를 유지할 수 있어 TTFT 차이가 작아지지만, decode path 자체의 overhead는 여전히 kernel implementation을 따른다. UltraQuant가 안정적인 TPOT를 유지하는 이유는 FP4 code와 UE8M0 scale을 attention kernel 안에서 직접 처리하도록 layout을 맞췄기 때문이다.
6.5.1 vLLM integration 관점에서의 의미
UltraQuant의 결과를 serving stack 관점에서 읽으면, 핵심은 quantized cache가 paged attention과 충돌하지 않는가에 있다. vLLM은 여러 요청의 KV block을 page 단위로 관리하면서 prefix reuse와 memory allocation을 조절한다. 낮은 bit cache가 실제로 도움이 되려면, block metadata와 cache layout이 scheduler가 기대하는 방식으로 움직여야 한다. UltraQuant는 group-32 FP4 code와 scale byte를 한데 묶어 cache block 안에 넣고, kernel이 그 format을 직접 읽도록 만든다. 이 구조는 compression format이 runtime 바깥의 offline artifact에 머무르지 않고, allocator와 attention kernel의 공통 언어가 된다는 뜻이다.
특히 multi-tenant serving에서는 GPU memory utilization 값을 어떻게 잡느냐가 중요하다. GMU를 너무 낮게 두면 cache eviction이 자주 발생하고, 너무 높게 두면 fragmentation이나 peak memory risk가 커질 수 있다. UltraQuant는 같은 GMU에서도 더 많은 logical context를 담을 수 있게 해 주지만, scheduler가 그 여유를 어떻게 배분하는지는 별도의 운영 문제다. 예를 들어 긴 세션 하나에 모든 이득을 몰아줄지, 여러 짧은 세션의 prefix를 넓게 보존할지는 서비스 policy가 결정한다.
이 관점에서 논문의 vLLM benchmark는 실제 production 실험의 출발점으로 볼 수 있다. offline kernel microbenchmark만으로는 allocator pressure, turn-by-turn reuse, concurrent session fairness가 보이지 않는다. 반대로 end-to-end serving benchmark는 kernel 최적화가 user-facing latency로 번역되는지 보여 준다. UltraQuant는 두 층을 모두 다룬다. scaled-MFMA로 decode path를 줄이고, resident cache capacity로 late-round TTFT를 줄이는 식이다.
6.5.2 비용 모델로 해석한 UltraQuant
간단한 비용 모델로 보면 UltraQuant의 이득은 세 항의 균형이다. 첫째는 KV bytes가 줄어 memory traffic과 HBM residency pressure가 낮아지는 항이다. 둘째는 FP4/scale decode를 처리하는 추가 kernel 비용이다. 셋째는 cache miss가 줄어 prefill replay가 줄어드는 항이다. 짧은 context에서는 첫째와 셋째가 작고 둘째가 눈에 띌 수 있다. 긴 context와 높은 concurrency에서는 첫째와 셋째가 커져 전체 지연 시간을 지배한다.
이 비용 모델은 왜 warm rounds에서 FP8이 앞서고 late rounds에서 UltraQuant가 앞서는지 설명한다. warm round에서는 cache가 아직 resident하고, FP8의 simple hardware path가 빠르다. late round에서는 prefix가 길어져 cache miss 비용이 커지고, UltraQuant의 작은 footprint가 replay를 막는다. 즉 UltraQuant의 장점은 decode token 하나를 극단적으로 빠르게 만드는 데서만 나오지 않는다. prefill replay avoidance와 long-context residency가 함께 작동할 때 system-level speedup이 커진다.
7. 한계점 및 향후 연구 방향: FP4 KV cache는 아직 uniformly near-lossless가 아니다
7.1 benchmark-dependent accuracy regression
가장 큰 한계는 accuracy가 benchmark-dependent하다는 점이다. 논문도 이 부분을 숨기지 않는다. MATH500에서는 UltraQuant가 BF16과 같거나 약간 더 나은 수치를 보이지만, AIME25에서는 Qwen3.5-A3B에서 $-13.33$ pp, MiniMax-M2.5에서 $-10.00$ pp regression이 나타난다. LCB-128K에서도 MiniMax-M2.5가 $-4.39$ pp 떨어진다. long-context serving에서 latency와 throughput이 좋아도, 어려운 수학 reasoning이나 coding task에서 품질 손실이 크면 production default로 쓰기 어렵다.
| Model | Benchmark | BF16 | UltraQuant | Delta |
|---|---|---|---|---|
| Qwen3.5-A3B | GPQA-Diamond | 79.80 | 79.80 | +0.00 |
| MiniMax-M2.5 | GPQA-Diamond | 84.34 | 82.32 | -2.02 |
| Qwen2.5-72B | GPQA-Diamond | 49.49 | 51.01 | +1.52 |
| Qwen3.5-A3B | LCB-128K | 76.54 | 74.07 | -2.47 |
| MiniMax-M2.5 | LCB-128K | 75.82 | 71.43 | -4.39 |
| Qwen3.5-A3B | AIME25 | 90.00 | 76.67 | -13.33 |
| MiniMax-M2.5 | AIME25 | 86.67 | 76.67 | -10.00 |
| Qwen3.5-A3B | MATH500 | 86.00 | 86.80 | +0.80 |
| MiniMax-M2.5 | MATH500 | 78.40 | 78.40 | +0.00 |
이 표에서 특히 AIME25 regression은 운영상 중요한 신호다. AIME25는 작은 수치 차이도 의미가 크고, multi-step reasoning에서 attention score의 미세한 변화가 최종 answer path를 바꿀 수 있다. UltraQuant가 boundary layer를 BF16으로 남겼는데도 regression이 남는다면, 어떤 layer 또는 head가 FP4 quantization에 민감한지 더 세밀한 분석이 필요하다. layer-wise constant, head-wise protection, task-aware fallback 같은 전략이 다음 단계로 자연스럽게 이어진다.
7.2 하드웨어 의존성과 이식성
UltraQuant의 성능 story는 AMD CDNA4 scaled-MFMA path와 강하게 연결되어 있다. FP4 code와 UE8M0 scale을 instruction이 직접 소비하기 때문에 codebook lookup을 제거할 수 있고, 이 지점이 FP8 수준 throughput에 접근하는 핵심이다. 만약 다른 GPU architecture가 같은 operand layout이나 scale format을 지원하지 않으면, UltraQuant의 algorithmic layout을 그대로 옮겨도 같은 latency가 나오지 않을 수 있다. 따라서 이 논문은 범용 quantization 알고리즘의 모양만 갖춘 것이 아니라, 특정 하드웨어 세대의 matrix core capability를 잘 활용한 co-design에 가깝다.
이 하드웨어 의존성은 단점이면서도 논문의 강점이다. 실제 배포에서 중요한 것은 paper algorithm의 이론적 우아함보다, 내가 쓰는 GPU와 runtime에서 빠르게 도는가다. UltraQuant는 AMD Instinct stack에서 vLLM path를 겨냥하고, AITER FlashAttention, FlyDSL, GCN ISA 같은 구체적 구성 요소를 드러낸다. 이 정도로 배포 환경을 명시하면 결과의 적용 범위가 선명해지고, 독자는 자신의 stack에서 재현 가능성을 더 현실적으로 판단할 수 있다.
7.3 calibration과 adaptive policy의 여지
논문은 single global constant $c=0.156$을 사용한다. 이 값은 단순성과 배포 편의성 측면에서 좋지만, 모든 model, layer, head, task에 최적이라고 보기는 어렵다. 저자들도 layer-wise 또는 distribution-dependent constant를 future work로 언급한다. 다만 constant를 너무 세밀하게 만들면 저장해야 할 metadata와 runtime branch가 늘어날 수 있다. UltraQuant의 매력은 fixed FP4 grid와 단순 scale layout에 있으므로, adaptive calibration을 추가하더라도 kernel path를 복잡하게 만들지 않는 균형이 필요하다.
또 다른 여지는 selective precision policy다. 현재 boundary-layer protection은 first/last two layers를 BF16으로 둔다. 하지만 AIME25 regression을 보면 task나 prompt에 따라 더 민감한 layer가 있을 가능성이 있다. static rule 대신 calibration set에서 layer sensitivity를 측정하고, 일부 layer나 head만 FP8/BF16으로 남기는 mixed policy를 만들 수 있다. 이 방향은 cache footprint를 조금 늘리지만, reasoning-heavy workload에서 품질 손실을 줄이는 운영 옵션이 될 수 있다.
7.4 운영 적용 시 필요한 guardrail
UltraQuant를 실제 서비스에 적용하려면 accuracy guardrail과 latency guardrail을 동시에 둬야 한다. latency 쪽에서는 TTFT, TPOT, cache hit ratio, prefill 재계산 횟수, resident session 수를 함께 기록해야 한다. UltraQuant가 도움이 되는 환경이라면 cache hit ratio가 올라가고 late-round TTFT가 내려가야 한다. 반대로 cache pressure가 낮은 workload에서 TPOT만 조금 늘어난다면 FP8을 유지하는 편이 낫다. 이 판단은 평균 token/sec 하나로 내리기 어렵다.
quality 쪽에서는 benchmark 평균보다 task class별 regression을 봐야 한다. AIME25 regression은 수학 reasoning에서 cache quantization noise가 더 크게 작동할 수 있음을 보여 준다. 코드 생성도 단순 completion과 repository-level debugging을 나눠 봐야 한다. 긴 context coding benchmark인 LCB-128K에서 MiniMax-M2.5가 $-4.39$ pp 떨어진 점을 보면, 긴 코드 문맥을 읽는 상황에서도 모델과 task에 따라 손실이 생길 수 있다. task-aware fallback이 필요한 이유다.
실무 배포안은 세 단계로 나눌 수 있다. 첫 단계에서는 offline replay로 기존 production prompt trace를 BF16, FP8, UltraQuant에 모두 통과시키고 answer equivalence와 latency를 비교한다. 둘째 단계에서는 low-risk traffic subset에만 UltraQuant를 켜고, user-visible latency와 failure signal을 모니터링한다. 셋째 단계에서는 prompt classifier나 scheduler signal을 이용해 긴 prefix reuse가 기대되는 세션에 우선 적용한다. 이렇게 하면 논문의 장점을 살리면서 AIME25류 regression 위험을 제한할 수 있다.
- Latency guardrail: TTFT P50/P95, TPOT, prefill replay count, cache hit ratio를 round별로 기록한다.
- Quality guardrail: math, coding, retrieval, summarization 등 task bucket별로 BF16/FP8 대비 regression을 따로 본다.
- Fallback policy: high-risk reasoning request는 FP8 또는 selective BF16 layer policy로 자동 전환한다.
- Hardware check: scaled-MFMA와 FP4/UE8M0 operand layout이 실제 runtime에서 사용되는지 kernel trace로 확인한다.
이 guardrail은 UltraQuant 논문의 한계를 약점으로만 보지 않게 해 준다. 논문이 제시한 큰 이득은 특정 workload regime에서 나온다. 그러므로 production 적용도 모든 traffic을 한 번에 바꾸는 방식보다, cache pressure가 높은 세션을 식별하고 그 세션에 낮은 bit KV를 배정하는 방식이 자연스럽다. 이런 관점에서는 UltraQuant가 단일 quantization method를 넘어, agent serving scheduler가 precision을 자원으로 다루는 방향을 열어 준다.
8. 내 해석: UltraQuant의 약점과 내가 붙여보고 싶은 후속 실험
나는 이 논문에서 가장 설득력 있는 부분이 “4-bit KV cache의 이득은 cache pressure가 생기는 운영 조건에서만 완전히 드러난다”는 점을 실험으로 보여 준 대목이라고 봤다. 단일 prompt latency나 평균 throughput만 보면 FP8 baseline이 여전히 강하고, UltraQuant의 장점이 흐려질 수 있다. 하지만 multi-turn agent workload에서는 긴 prefix가 계속 재사용되고, resident cache가 밀려나는 순간 TTFT가 크게 흔들린다. UltraQuant는 이 구간을 겨냥해 설계되어 있고, 그래서 $3.47\times$ TTFT 개선이라는 수치가 단순 커널 미세 최적화보다 더 큰 운영적 의미를 갖는다.
약점도 명확하다. 논문의 accuracy 결과는 UltraQuant를 모든 workload의 기본값으로 쓰기에는 아직 불안정하다는 신호를 준다. 특히 AIME25에서 두 모델 모두 두 자릿수 pp regression을 보인 점은, FP4 KV quantization이 multi-step mathematical reasoning의 attention trajectory를 건드릴 수 있음을 암시한다. boundary layer를 BF16으로 보호했는데도 손실이 남았다면, 민감한 정보가 첫/마지막 layer에만 모여 있다고 보기 어렵다. 내가 production serving에서 이 기법을 검토한다면, agent coding과 retrieval-heavy 업무에는 먼저 켜 보겠지만, olympiad-style reasoning이나 안전-critical decision trace에는 task-level fallback을 붙이지 않고 기본 적용하지는 않을 것 같다.
내가 후속으로 붙여보고 싶은 실험은 quality-aware cache precision routing이다. session이 시작될 때 prompt type, model confidence, tool-use plan, expected context length를 보고 KV precision policy를 선택하는 방식이다. 예를 들어 repository navigation이나 long-document summarization처럼 prefix reuse가 크고 exact reasoning pressure가 낮은 세션은 UltraQuant를 적극적으로 쓰고, AIME류 수학 문제나 verification-heavy coding task는 FP8 또는 selective BF16 layer를 유지한다. 이 routing이 가능하려면 benchmark 평균만 볼 것이 아니라 turn-level error, layer sensitivity, cache pressure를 함께 기록해야 한다. UltraQuant 논문은 그 첫 조건인 systems metric을 잘 세웠고, 다음 단계는 quality risk를 같은 scheduler 안에 넣는 일이라고 생각한다.
이전에 정리한 MLA KV Cache Compression과 비교하면, UltraQuant는 모델 구조를 바꾸지 않고 serving layer에서 붙일 수 있는 장점이 있다. 반대로 MLA나 hybrid architecture는 학습 단계부터 cache footprint를 줄이는 대신 모델 설계와 checkpoint 자체가 바뀐다. 두 접근을 함께 보면 긴 문맥 에이전트의 병목은 단일 해법으로 풀기 어렵다. architecture는 저장해야 할 state의 양을 줄이고, quantization은 남은 state의 bytes를 줄이며, scheduler는 어떤 state를 HBM에 남길지 결정한다. UltraQuant는 이 세 층 중 두 번째와 세 번째 사이를 아주 현실적으로 파고든 논문이다.
8.1 이 논문을 읽을 때 헷갈리기 쉬운 지점
UltraQuant를 처음 읽을 때 가장 헷갈리기 쉬운 부분은 cache compression과 model quantization을 같은 것으로 보는 것이다. weight quantization은 model parameter를 낮은 bit로 저장하고 matrix multiplication을 빠르게 만드는 방향이다. KV cache quantization은 이미 계산된 activation state를 낮은 bit로 저장했다가 다음 token에서 다시 attention에 사용하는 방향이다. 두 문제 모두 낮은 bit representation을 쓰지만, error가 들어가는 위치와 반복 사용 방식이 다르다. KV cache의 작은 오차는 다음 token의 attention distribution을 바꾸고, 긴 reasoning chain에서는 그 차이가 여러 step에 걸쳐 누적될 수 있다.
또 하나의 혼동은 memory saving과 latency saving을 자동으로 연결하는 것이다. cache bytes가 줄어도 decode kernel이 느려지면 TPOT가 나빠질 수 있다. TurboQuant OSS baseline이 이 사례다. 4-bit cache라서 메모리 footprint는 작지만 software dequantization이 길게 들어가면 실제 serving latency가 커진다. UltraQuant가 의미 있는 이유는 footprint를 줄인 뒤, 그 representation을 hardware-native path로 소비하려고 kernel을 같이 설계했기 때문이다. 이 점을 빼면 논문의 핵심이 흐려진다.
마지막으로, UltraQuant의 성능 수치를 단일 모델의 일반 성능으로 받아들이면 위험하다. 논문은 MiniMax-M2.5와 AMD MI355X, vLLM benchmark, 특정 GMU와 concurrency 조건을 중심으로 강한 결과를 보여 준다. 이 결과는 매우 유용하지만, 다른 GPU, 다른 runtime, 다른 model family에서는 다시 측정해야 한다. 특히 scaled-MFMA 경로가 없거나, serving scheduler가 cache eviction을 다르게 처리하면 TTFT 이득의 크기가 달라질 수 있다.
9. 결론: 4-bit KV caching을 배포 가능한 시스템 설계로 끌어내리기
UltraQuant는 4-bit KV cache를 단순 압축 알고리즘으로 다루지 않고, long-context agent serving의 memory hierarchy 문제로 다룬다. 논문의 중심은 FP4 E2M1 grid와 UE8M0 scale을 이용해 cache footprint를 FP8의 절반 수준으로 줄이면서, dequantization을 AMD CDNA4 scaled-MFMA path에 fold하는 것이다. 이 설계 덕분에 UltraQuant는 hardware FP8 KV와 비슷한 throughput ceiling에 접근하고, cache-pressured late rounds에서는 FP8보다 훨씬 낮은 TTFT를 보인다.
방법론적으로는 Walsh-Hadamard rotation, per-block absmax, global constant $c=0.156$, group-32 FP4 cache layout이 서로 맞물린다. rotation은 outlier를 완화하고, per-block scale은 local magnitude를 흡수하며, constant calibration은 fixed FP4 grid의 중앙부 resolution을 조정한다. kernel 측면에서는 query FP8 rounding, FP4 key/value code, UE8M0 scale operand가 scaled-MFMA instruction과 맞도록 배치된다. 이 조합이 codebook lookup 기반 4-bit path와 UltraQuant를 가르는 핵심이다.
다만 결과를 무조건적인 승리로 읽으면 안 된다. UltraQuant의 이득은 context length와 concurrency가 충분히 크고, cache residency가 실제 병목이 되는 구간에서 가장 잘 드러난다. accuracy도 uniformly near-lossless라고 보기 어렵다. AIME25 regression은 task-aware precision policy가 필요하다는 신호다. 따라서 이 논문은 “모든 KV cache를 FP4로 바꾸자”보다, “agent serving에서 cache pressure가 커지는 구간에는 hardware-native FP4 KV path가 강력한 선택지가 될 수 있다”는 결론에 가깝다.
실무적으로는 GPU 세대와 runtime stack이 맞는지, workload가 multi-turn prefix reuse를 충분히 갖는지, reasoning quality regression을 모니터링할 수 있는지부터 확인해야 한다. 이 조건이 맞으면 UltraQuant는 long-context agent serving의 비용 구조를 실제로 바꿀 수 있다. 특히 여러 사용자의 긴 세션을 동시에 유지해야 하는 환경에서는, token generation 속도보다 resident cache capacity가 서비스 체감 품질을 좌우하는 순간이 오기 때문에 이 논문이 제시한 평가 방식 자체도 참고할 만하다.
10. 요약 정리
- UltraQuant는 context-heavy LLM agent를 위해 설계된 4-bit KV-cache compression 방법이며, cache residency와 serving latency를 함께 평가한다.
- 핵심 설계는 FP4 E2M1 code와 UE8M0 group scale을 사용해 KV cache를 group-32 layout으로 저장하는 것이다.
- Walsh-Hadamard rotation은 key 분포의 outlier를 완화하고, per-block absmax와 global constant $c=0.156$은 fixed FP4 grid의 quantization error를 줄인다.
- UltraQuant는 codebook lookup을 없애고 AMD CDNA4 scaled-MFMA instruction이 FP4 KV와 scale을 직접 소비하게 만들어 decode critical path를 줄인다.
- multi-turn agent serving에서 late rounds의 P50 TTFT는 FP8 KV baseline 대비 $3.47\times$, 전체 round 기준 $2.3\times$, output throughput은 $1.63\times$ 개선된다.
- throughput은 BF16 대비 $1.38\times$로 hardware FP8 KV의 $1.37\times$와 거의 같고, TPOT도 FP8에 가까운 수준을 보인다.
- accuracy는 benchmark-dependent하며, AIME25에서는 Qwen3.5-A3B와 MiniMax-M2.5 모두 두 자릿수 pp regression을 보여 production default 적용에는 주의가 필요하다.
- per-block scale ablation은 codebook 자체보다 adaptation statistic이 품질에 더 큰 영향을 줄 수 있음을 보여 준다.
- 이 논문은 MLA 같은 architecture-level KV 절감과 달리, 기존 모델 interface를 유지한 채 serving layer에서 HBM pressure를 낮추는 실용적 선택지다.
- 후속 연구로는 task-aware precision routing, layer/head sensitivity 기반 mixed precision KV cache, quality-risk를 포함한 scheduler가 자연스럽다.