ρ-EOS: Training-free Bidirectional Variable-Length Control for Masked Diffusion LLMs
https://arxiv.org/abs/2601.22527
Jinyi Yang, Yuhao Jiang, Botian Yu, Jiapeng Wang, Yuming Jiang, Mike Zheng Shou | Show Lab, National University of Singapore | arXiv:2601.22527 | 2026년 1월 | ICLR 2026 게재 확정
1. 서론: Masked dLLM의 고정 길이 딜레마
1.1 디퓨전 언어 모델의 부상과 구조적 이점
자기회귀 LLM이 스케일링 법칙과 범용 능력을 보여주는 가운데, 최근 Diffusion LLM(dLLM)이 유력한 대안 패러다임으로 부상했다. LLaDA, Mercury, Gemini Diffusion, SEED 등이 대표적이며, 이들은 완전히 마스킹된 시퀀스에서 시작해 반복적으로 MASK 토큰을 언마스킹하는 이산 확률적 디노이징 과정으로 텍스트를 생성한다. 이 방식은 병렬 생성과 전역 문맥 모델링이라는 두 가지 구조적 이점을 제공한다.
병렬 생성의 이점은 직관적이다. AR 모델이 $L$개의 토큰을 생성하기 위해 $L$번의 순차적 전방 패스를 실행해야 하는 반면, masked dLLM은 각 디노이징 스텝에서 여러 MASK 위치를 동시에 언마스킹할 수 있다. $T$번의 디노이징 스텝으로 $L$개의 토큰을 생성하면, 이론적으로 $L/T$배의 병렬 처리 이점을 갖는다. 전역 문맥 모델링은 AR 모델의 좌에서 우로(left-to-right) 조건부 의존 구조와 대비되는 특성이다. AR 모델에서 위치 $i$의 토큰은 오직 이전 토큰 $x_{< i}$에만 조건부로 생성되지만, masked dLLM은 양방향 어텐션을 통해 시퀀스 전체의 문맥을 동시에 참조한다. 이는 특히 긴 범위의 의존성(long-range dependency)이 중요한 코드 생성이나 수학 추론에서 잠재적 이점을 제공할 수 있다.
1.2 고정 길이 제약의 본질
그러나 masked dLLM의 생성 길이는 미리 채워 넣는 MASK 토큰 수에 의해 엄격하게 결정된다. 추론은 프롬프트 $\mathbf{p}$ 뒤에 $L$개의 MASK 토큰을 이어 붙여 $[\mathbf{p}, \text{MASK}, \text{MASK}, \dots, \text{MASK}]$를 구성하는 것으로 시작되며, 이 $L$이 최종 출력의 최대 길이를 물리적으로 결정한다. 이는 특히 긴 체인 추론(long-chain reasoning)이나 짧은/긴 사고 모드를 적응적으로 전환해야 하는 하이브리드 추론 시나리오에서 심각한 딜레마를 만든다.
이 딜레마의 양면을 구체적으로 살펴보면 다음과 같다. 첫째, 길이 부족(under-budgeting): $L$이 짧으면 모델이 복잡한 문제를 풀 토큰 예산이 부족해 정확도가 떨어진다. 예를 들어, GSM8K에서 $L=64$로 설정하면 다단계 연산이 필요한 문제의 풀이 과정이 중간에 잘려 정확도가 65.1%까지 크게 하락한다. 둘째, 길이 과잉(over-budgeting): $L$이 길면 짧은 응답에 대해 대량의 패딩 EOS가 생겨 연산이 낭비된다. 논문의 실험에서 $L=2048$로 MBPP를 풀면 유효 토큰 비율($E_{\text{ratio}}$)이 20%대까지 떨어지며, 이는 생성된 토큰의 80%가 의미 없는 패딩이라는 뜻이다. 런타임도 수 배로 증가해 실전 배포에서 심각한 비효율을 초래한다.
적정 길이는 태스크와 개별 문제에 따라 크게 달라지므로, 하나의 고정값으로는 모든 상황을 커버할 수 없다. GSM8K의 쉬운 문제는 100 토큰이면 충분하지만, MATH500의 어려운 문제는 500 토큰 이상이 필요할 수 있다. 이 경직성은 EOS를 만나면 자연스럽게 멈추는 자기회귀 모델과 대조적이다. AR 모델에서 EOS는 모델이 "더 이상 생성할 내용이 없다"고 판단하는 자연스러운 종료 신호이며, 이를 통해 짧은 응답과 긴 응답을 하나의 추론 루프 안에서 적응적으로 처리한다. masked dLLM에는 이에 대응하는 메커니즘이 없었고, 이것이 실전 배포의 가장 큰 걸림돌이었다.
1.3 기존 해법의 한계: DAEDAL의 2단계 접근
기존 해법인 DAEDAL은 이 문제에 대해 2단계 접근법을 취한다. 1단계에서 trailing EOS의 confidence를 확인해 MASK 블록을 덧붙이는 방식으로 길이를 확장한다. 구체적으로, 시퀀스 끝부분의 EOS 토큰에 대한 confidence가 임계값보다 낮으면(즉, 모델이 아직 EOS를 확정하지 못하면) 고정 크기의 MASK 블록을 이어 붙인다. 이 과정을 EOS confidence가 충분히 높아질 때까지 반복한다. 2단계에서는 실제 디노이징을 수행하면서, 중간에 low-confidence 영역에 추가 MASK를 삽입하는 반복적 마스크 삽입(iterative mask insertion)을 수행한다.
이 방법은 효과적이지만, 세 가지 구조적 한계가 있다. (1) 단방향 확장만 지원: 길이를 늘리는 것만 가능하고, 이미 과도하게 확장된 시퀀스를 줄이는 축소(contraction)가 불가능하다. 초기 확장이 과도했을 때 되돌릴 방법이 없어, 불필요한 토큰이 최종 출력에 남게 된다. (2) 2단계 파이프라인의 추가 지연: 1단계에서 길이를 먼저 결정하고, 2단계에서 디노이징을 수행하는 순차적 구조가 전체 추론 지연을 증가시킨다. 이는 고처리량(high-throughput) 배포나 지연에 민감한(latency-sensitive) 시나리오에서 특히 문제가 된다. (3) RL 파인튜닝과의 비호환성: 강화학습 롤아웃은 추론 지연에 의해 병목이 되는 경우가 많은데, 다단계 디코딩 전략은 이 지연을 더 가중시킨다. D1, DiffuCoder, Taming 등 최근 masked dLLM에 RL을 적용하는 연구가 활발한 상황에서, 이 비호환성은 단순한 효율 문제가 아닌 연구 방향 자체의 제약으로 작용한다.
아래 표는 $\rho$-EOS, DAEDAL, 고정 길이 베이스라인의 핵심 특성을 비교한 것이다. $\rho$-EOS가 기존 방법들의 한계를 어떻게 극복하는지를 구조적으로 보여준다.
| 특성 | 고정 길이 | DAEDAL | $\rho$-EOS |
|---|---|---|---|
| 추가 학습 필요 | 불필요 | 불필요 | 불필요 |
| 길이 조절 방향 | 없음 (고정) | 단방향 (확장만) | 양방향 (확장+축소) |
| 추론 단계 수 | 1단계 | 2단계 (길이 추정 → 디노이징) | 1단계 (통합) |
| 길이 제어 신호 | 없음 | EOS Confidence | Implicit EOS Density ($\rho$) |
| 확장 인자 함수 | 없음 | 상수 (고정 블록) | 상수/선형/지수 선택 가능 |
| RL 파인튜닝 호환 | 제한적 | 비효율적 (2단계 지연) | 효율적 (단일 루프) |
| 과잉 길이 교정 | 불가 | 불가 | 가능 (축소 메커니즘) |
2. 관련 연구: 고정 길이 제약 해결을 위한 접근법들
2.1 학습 기반 가변 길이 전략
masked dLLM의 고정 길이 제약을 해결하기 위한 기존 연구는 크게 학습 기반(training-based)과 학습 불요(training-free)로 나뉜다. 학습 기반 방법들은 모델 자체에 가변 길이 생성 능력을 학습시키는 접근이다.
FlexMDMs는 디노이징 과정을 삽입(insertion)과 언마스킹(unmasking) 두 단계로 분해한다. 각 위치 앞에 삽입할 MASK 토큰의 수를 예측하도록 모델을 학습시켜, 시퀀스 길이를 동적으로 확장할 수 있게 한다. 이 접근의 장점은 위치별로 세밀한 길이 조절이 가능하다는 것이지만, 삽입 예측을 위한 추가 학습이 필요하고 기존 pretrained 모델에 직접 적용하기 어렵다. 또한 삽입 예측 헤드 자체가 정확하지 않으면 시퀀스 구조가 왜곡될 수 있는 취약점이 있다.
DreamOn은 특수 제어 토큰을 도입하는 방식을 취한다. EXPAND 토큰은 두 개의 MASK 토큰으로 분열(split)하여 시퀀스를 연장하고, DELETE 토큰은 해당 위치를 제거하여 시퀀스를 축소한다. 이 방법은 양방향 조절이 원리적으로 가능하지만, 제어 토큰의 의미를 모델이 학습해야 하므로 추가 학습 비용이 발생한다. 또한 제어 토큰이 출력에 잔존하거나 의도치 않은 위치에 배치될 위험이 있어, 생성 안정성에 대한 추가 검증이 필요하다.
dLLM-Var는 masked dLLM이 블록 디퓨전(block diffusion) 방식으로 추론할 수 있도록, EOS 토큰을 정확히 예측하는 능력을 추가 학습하는 방법이다. 블록 단위로 디노이징을 수행하면서, 현재 블록에서 EOS가 예측되면 생성을 종료하는 방식으로 가변 길이를 달성한다. 그러나 이 접근 역시 블록 디퓨전 방식으로의 적응 학습이 필요하며, 원본 모델의 추론 패러다임을 변경한다는 근본적 한계가 있다. 전체 시퀀스 디퓨전에서 블록 디퓨전으로의 전환은 전역 문맥 참조 능력의 부분적 포기를 의미하기도 한다.
2.2 학습 불요 가변 길이 전략
학습 불요 접근법은 기존 pretrained 모델을 수정 없이 사용하면서 추론 시점에서만 길이를 조절하는 전략이다. 앞서 설명한 DAEDAL이 이 범주의 대표적 연구이며, $\rho$-EOS 이전에는 유일한 training-free 가변 길이 전략이었다. DAEDAL의 핵심 통찰은 trailing EOS의 confidence가 길이 충분성의 신호가 될 수 있다는 것이지만, 2단계 구조와 단방향 확장이라는 한계가 있었다. DAEDAL은 1단계에서 길이를 결정한 후 2단계에서 디노이징을 수행하는 분리된 파이프라인을 사용하므로, 디노이징 도중 길이 결정을 수정할 수 없다. 이는 1단계의 길이 추정이 부정확했을 때 2단계에서 이를 교정할 방법이 없다는 구조적 취약점을 낳는다.
이러한 맥락에서 $\rho$-EOS는 단일 단계 · 학습 불요 · 양방향 제어 메커니즘의 필요성에 대한 응답이다. 특히 RL 파인튜닝(D1, DiffuCoder, Taming 등)에서 가변 길이 제어의 중요성이 부각되는 상황에서, 단일 단계 설계는 RL 훈련 루프에 직접 통합할 수 있다는 실용적 이점을 갖는다. RL 롤아웃에서 각 샘플의 추론 비용을 줄이는 것은 전체 학습 처리량에 직접적 영향을 미치므로, 다단계 파이프라인의 추가 지연은 RL 학습의 scalability를 심각하게 저해할 수 있다.
2.3 블록 디퓨전과의 비교
가변 길이 문제의 또 다른 해법으로 블록 디퓨전 언어 모델(BD3-LM, SDAR, WeDLM, Fast-dLLM v2 등)이 있다. 이들은 시퀀스를 블록 단위로 분할해, 블록 내에서는 디퓨전, 블록 간에는 AR 방식으로 생성한다. 블록 경계에서 EOS가 예측되면 자연스럽게 종료할 수 있어 가변 길이 생성이 가능하다. 또한 블록 간 인과적 의존성 덕분에 KV 캐시를 활용할 수 있어 추론 효율이 높다.
그러나 이 접근은 전체 시퀀스 디퓨전 모델(LLaDA 등)의 전역 문맥 모델링 이점을 포기해야 하며, AR 방식의 블록 간 의존성으로 인해 완전한 병렬 생성이 제한된다. 블록 크기 $D$가 작으면 AR의 순차성에 가까워지고, 크면 각 블록 내 디퓨전의 품질이 떨어질 수 있어 $D$의 선택이 새로운 하이퍼파라미터 문제를 만든다. $\rho$-EOS는 전체 시퀀스 마스크 디퓨전의 패러다임을 유지하면서 가변 길이를 달성한다는 점에서 블록 디퓨전과 상보적인 위치에 있다. 즉, 전역 문맥의 이점을 포기하지 않으면서도 고정 길이 제약을 해결한다는 점이 핵심 차별점이다.
2.4 이산 디퓨전 모델의 이론적 배경
이산 디퓨전 모델의 이론적 기초를 간략히 정리하면, 순방향 과정(forward process)은 원본 시퀀스 $\mathbf{x}_0$에서 시작하여 점진적으로 노이즈를 추가하는 마르코프 체인으로 정의된다. Masked dLLM에서 이 노이즈는 토큰을 MASK로 대체하는 형태를 취한다. 마스크 비율 $t \in [0, 1]$에 따라 각 토큰이 독립적으로 확률 $t$로 마스킹되며, $t=0$이면 원본, $t=1$이면 완전 마스킹 상태이다. 역방향 과정(reverse process)은 학습된 디노이징 모델 $p_\theta(\mathbf{x}_0 | \mathbf{x}_t)$가 부분적으로 마스킹된 시퀀스 $\mathbf{x}_t$로부터 원본 토큰을 예측하는 과정이다. 학습 목적 함수는 마스킹된 위치에 대한 가중 교차 엔트로피 손실이다:
$$\mathcal{L}(\theta) = -\mathbb{E}_{t, \mathbf{x}_0, \mathbf{x}_t}\left[\frac{1}{t}\sum_{i=1}^{L}\mathbf{1}[\mathbf{x}_t^i = \text{MASK}] \cdot \log p_\theta(\mathbf{x}_0^i | \mathbf{x}_t)\right]$$
여기서 $t \sim \text{Uniform}(0, 1)$이고 $\mathbf{x}_t$는 순방향 과정에서 샘플링된다. $\frac{1}{t}$ 가중치는 마스크 비율이 낮을 때(소수의 토큰만 마스킹) 각 토큰의 손실 중요도를 높이는 역할을 한다. 이 수식의 직관적 의미는, 대부분의 컨텍스트가 주어진 상황에서의 예측 정확도가 최종 생성 품질에 더 중요하다는 것이다. 추론 시에는 완전 마스킹 상태($t=1$)에서 시작하여 $T$번의 디노이징 스텝으로 점진적으로 토큰을 복원한다.
3. 문제 정의: 왜 고정 길이가 문제인가
3.1 Masked dLLM의 표준 추론 과정
Masked dLLM의 표준 추론 과정을 수학적으로 정리하면 다음과 같다. 프롬프트 $\mathbf{p}$가 주어지면, 모델은 $[\mathbf{p}, \text{MASK}_1, \text{MASK}_2, \dots, \text{MASK}_L]$을 입력으로 받아 $T$번의 디노이징 스텝을 수행한다. 각 스텝 $t$에서의 과정은 세 단계로 구성된다.
1단계 (순방향 패스): 현재 시퀀스 $\mathbf{x}_t$를 모델 $p_\theta$에 통과시켜 로짓을 얻는다:
$$\mathbf{x}_t^{\text{logits}} = p_\theta(\mathbf{x}_t)$$
2단계 (암묵적 예측): 로짓에 softmax와 argmax를 적용해 각 위치의 예측 토큰을 계산한다:
$$\hat{\mathbf{x}}_0 = \text{argmax}(\text{softmax}(\mathbf{x}_t^{\text{logits}}))$$
이것이 암묵적 $\hat{\mathbf{x}}_0$이며, 모델이 "만약 지금 즉시 디코딩해야 한다면" 출력할 시퀀스의 예측이다.
3단계 (Remask): $\hat{\mathbf{x}}_0$의 각 위치에 대한 confidence(softmax 확률의 최댓값)를 기준으로, 상위 confidence의 일부 위치만 명시적 토큰(Explicit Token)으로 확정하고, 나머지를 다시 MASK로 되돌린다:
$$\mathbf{x}_{t-\tau} = \text{Remask}(\hat{\mathbf{x}}_0)$$
여기서 $\tau = 1/T$로, 각 스텝에서 마스크 비율이 $\tau$만큼 감소한다. 이 과정을 $T$번 반복하면 모든 MASK가 명시적 토큰으로 대체되어 최종 출력이 완성된다. 핵심은 $L$(초기 MASK 토큰 수)이 고정이므로, 최종 출력의 길이도 정확히 $L$이 된다는 점이다. 실제 응답이 $L$보다 짧으면 남은 위치는 EOS 패딩으로 채워지고, $L$보다 긴 응답이 필요하면 내용이 잘린다. 이 경직성이 masked dLLM의 근본적 제약이다.
3.2 고정 길이의 양면성: 정량적 분석
고정 길이 $L$의 양면적 trade-off를 논문의 실험 데이터로 구체적으로 확인할 수 있다. LLaDA-Instruct-8B에서 GSM8K를 평가할 때, $L=64$에서는 정확도가 65.1%로 낮지만 $E_{\text{ratio}}$는 87.3%로 높다. $L=2048$에서는 정확도가 최고(가장 높은 고정 길이 기준)에 도달하지만, $E_{\text{ratio}}$가 10~20%대로 급락하고 런타임이 5000초 이상으로 폭증한다. 이는 토큰의 80~90%가 의미 없는 패딩이며, 이 패딩 토큰에 대해서도 양방향 어텐션이 계산되므로 연산 낭비가 시퀀스 길이에 대해 이차적($O(L^2)$)으로 증가한다는 뜻이다.
MBPP 코드 생성에서는 이 문제가 더 극명하다. 코드의 길이 분포는 수학 풀이보다 분산이 크다—간단한 유틸리티 함수는 50 토큰이면 충분하지만, 복잡한 알고리즘 구현은 500 토큰 이상이 필요하다. $L=2048$로 통일하면 대부분의 짧은 코드 문제에서 $E_{\text{ratio}}$가 15~20%대까지 떨어진다. 적정 길이는 문제의 난이도, 유형, 요구되는 풀이 전략에 따라 개별적으로 달라지므로, 고정된 하나의 $L$로는 모든 문제를 효율적으로 처리할 수 없다. 이것이 바로 $\rho$-EOS가 해결하려는 핵심 문제이다.
4. 핵심 방법: $\rho$-EOS
Figure 2: 명시적/암묵적 토큰과 밀도의 정의. (좌상) Masked dLLM의 표준 디노이징. (좌하) DAEDAL의 2단계. (우) $\rho$-EOS의 양방향 가변 길이 디노이징.
4.1 암묵적 토큰(Implicit Token)의 정의
$\rho$-EOS의 핵심 개념을 이해하려면 먼저 암묵적 토큰(Implicit Token)의 개념을 명확히 해야 한다. 각 디노이징 스텝에서 모델은 입력 $\mathbf{x}_t$에 대해 순방향 패스를 수행해 로짓 $\mathbf{x}_t^{\text{logits}} = p_\theta(\mathbf{x}_t)$를 얻는다. 여기서 $\text{argmax}(\text{softmax}(\cdot))$로 얻어지는 예측 $\hat{\mathbf{x}}_0$가 바로 암묵적 $\mathbf{x}_0$이다. 이 암묵적 $\hat{\mathbf{x}}_0$는 모델이 "현재 상태에서 바로 디코딩한다면 이런 출력이 될 것"이라고 내부적으로 예측하는 전체 시퀀스이다.
이 암묵적 $\hat{\mathbf{x}}_0$ 중에서 현재 MASK인 위치에 해당하는 예측 토큰들을 암묵적 토큰이라 정의한다. 수학적으로, 시점 $t$에서의 암묵적 토큰 집합은 $\{i \mid \hat{\mathbf{x}}_0^i \wedge (\mathbf{x}_t^i = \text{MASK})\}$이다. 이들은 아직 최종 출력으로 확정되지 않았지만(Remask 과정에서 다시 MASK로 돌아갈 수 있음), 모델이 현 시점에서 "이 위치는 이 토큰이 될 것"이라고 내부적으로 예측하는 값이다. Remask 이후에는 이 중 일부만이 명시적 토큰(Explicit Token)으로 확정되고, 나머지는 다시 마스킹된다.
기존의 masked dLLM 추론에서는 암묵적 토큰을 단순히 confidence 순으로 정렬해 상위 일부를 명시적 토큰으로 확정하는 데만 사용했다. $\rho$-EOS는 이 암묵적 토큰의 구성(composition)을 분석해, 그 안에 숨겨진 길이 충분성 신호를 추출한다는 점에서 개념적 도약을 이룬다. 특히, 암묵적 토큰 중 EOS의 비율이 길이 적절성에 대한 핵심적인 정보를 담고 있다는 발견이 이 연구의 출발점이다.
4.2 암묵적 EOS 밀도($\rho_{\text{EOS}}$)의 정의와 물리적 의미
암묵적 토큰의 개념에 기반해, 논문은 암묵적 밀도(Implicit Density, $\rho$)를 남은 MASK 위치 중 특정 속성을 가진 암묵적 토큰의 비율로 정의한다. 일반적 형태는 다음과 같다:
$$\rho = \frac{\#\text{Implicit Token at } t}{\#\text{Remaining MASK Token at } t}$$
이 일반 정의에서 특정 속성을 "EOS 토큰인가"로 한정하면, 암묵적 EOS 밀도($\rho_{\text{EOS}}$)가 된다:
$$\rho_{\text{EOS}} = \frac{\#\text{Implicit EOS Token at } t}{\#\text{Remaining MASK Token at } t}$$
이 밀도의 물리적 의미는 직관적이다. $\rho_{\text{EOS}}$가 높다는 것은 모델이 남은 마스크 공간의 대부분을 "끝났다(EOS)"로 채우고 싶어한다는 뜻이다. 이는 생성 공간이 과잉임을 나타낸다—의미 있는 내용은 이미 충분히 생성되었고, 남은 공간은 불필요하다. 반대로 $\rho_{\text{EOS}}$가 낮다는 것은 모델이 남은 공간을 의미 있는 토큰으로 채우려 하고 있어, 생성 공간이 부족함을 의미한다. 적절한 길이에서는 $\rho_{\text{EOS}}$가 극단값(0 또는 1)이 아닌 중간 평형 영역으로 수렴한다.
Figure 1은 이 패턴을 실증적으로 보여준다. GSM8K와 MBPP에서 다양한 고정 길이(64~1024)에 대한 $\rho_{\text{EOS}}$의 디노이징 과정 추이를 관찰하면 세 가지 명확한 패턴이 나타난다. $L=64$(너무 짧음): $\rho_{\text{EOS}}$가 0으로 수렴하며, 이는 모델이 모든 마스크 공간을 의미 토큰으로 사용하려 하지만 여전히 부족한 상태를 반영한다. $L=1024$(너무 김): $\rho_{\text{EOS}}$가 1에 가깝게 수렴하며, 남은 공간의 거의 전부가 불필요한 패딩임을 나타낸다. 적절한 길이(예: $L=256 \sim 512$): $\rho_{\text{EOS}}$가 중간 영역으로 수렴하며, 의미 토큰과 EOS 간의 자연스러운 균형 상태를 보여준다. 이 관찰이 $\rho$-EOS의 전체 메커니즘을 지탱하는 경험적 근거이다.
4.3 양방향 길이 조절 메커니즘
$\rho$-EOS는 두 개의 임계값 $\rho_{\text{low}}$와 $\rho_{\text{high}}$로 길이 평형 영역(length-equilibrium region)을 정의한다. 각 디노이징 스텝에서 $\rho_{\text{EOS}}$를 계산한 뒤, 세 가지 경우에 따라 행동한다. 이를 수식으로 표현하면 다음과 같다:
$$\mathbf{x} = \begin{cases} \mathbf{x} \leftarrow \mathbf{x} \oplus [\underbrace{\text{MASK}, \dots, \text{MASK}}_{E_{\text{factor}}(\rho_{\text{EOS}})}] & \text{if } \rho_{\text{EOS}} < \rho_{\text{low}} \\ \mathbf{x} \leftarrow \mathbf{x}^{0:(|\mathbf{x}| - E_{\text{factor}}(\rho_{\text{EOS}}))} & \text{else if } \rho_{\text{EOS}} > \rho_{\text{high}} \\ \mathbf{x} & \text{otherwise} \end{cases}$$
그에 따라 현재 생성 길이 $L_{\text{cur}}$도 업데이트된다:
$$L_{\text{cur}} = \begin{cases} L_{\text{cur}} + E_{\text{factor}}(\rho_{\text{EOS}}) & \text{if } \rho_{\text{EOS}} < \rho_{\text{low}} \\ L_{\text{cur}} - E_{\text{factor}}(\rho_{\text{EOS}}) & \text{else if } \rho_{\text{EOS}} > \rho_{\text{high}} \\ L_{\text{cur}} & \text{otherwise} \end{cases}$$
세 경우를 풀어서 설명하면 다음과 같다:
- $\rho_{\text{EOS}} < \rho_{\text{low}}$ (부족): 시퀀스 끝에 $E_{\text{factor}}(\rho_{\text{EOS}})$개의 MASK 토큰을 추가해 확장(expansion)한다. 모델이 의미 있는 내용을 더 생성할 공간을 제공한다.
- $\rho_{\text{EOS}} > \rho_{\text{high}}$ (과잉): 시퀀스 끝의 MASK 토큰 $E_{\text{factor}}(\rho_{\text{EOS}})$개를 제거해 축소(contraction)한다. 불필요한 패딩 공간을 줄인다.
- $\rho_{\text{low}} \leq \rho_{\text{EOS}} \leq \rho_{\text{high}}$ (적정): 길이 변경 없이 디노이징만 수행한다(hold). 모델이 적절한 길이에 도달했으므로 순수 디노이징에 집중한다.
이 양방향 조절이 DAEDAL의 단방향 확장과의 핵심적 차이다. DAEDAL은 확장만 가능하므로, 초기 길이가 과도하게 길거나 이전 확장이 과했을 때 되돌릴 수 없다. $\rho$-EOS는 축소를 통해 이런 상황을 교정할 수 있어 더 유연하며, 결과적으로 토큰 활용률이 크게 개선된다.
또한 축소 시 제거되는 것은 시퀀스 끝부분의 MASK 토큰만이라는 점이 중요하다. 이미 명시적 토큰으로 확정된 위치는 절대 제거되지 않으므로, 생성 중인 내용의 일관성이 보장된다. 이는 $\rho$-EOS의 축소가 "이미 쓴 내용을 지우는 것"이 아니라, "아직 비어 있는 여백을 줄이는 것"임을 의미한다. 디노이징 초기 단계에서는 대부분의 위치가 아직 MASK이므로 축소의 여지가 크고, 후기 단계에서는 대부분이 명시적 토큰으로 확정되어 있으므로 축소의 영향이 제한적이다. 이 자연스러운 감쇠 특성이 축소로 인한 품질 저하를 방지하는 내재적 안전장치 역할을 한다.
4.4 확장 인자 함수(Expansion Factor Function)
한 번에 얼마나 확장/축소할지는 확장 인자 함수 $E_{\text{factor}}(\rho_{\text{EOS}})$로 결정된다. 이 함수의 설계는 $\rho$-EOS의 수렴 속도와 안정성에 직접적 영향을 미친다. 논문은 세 가지 설계를 비교한다:
- 상수(Constant): DAEDAL처럼 매번 고정 크기(예: 64 토큰)로 조절한다. 설계가 단순하고 안정적이지만, $\rho_{\text{EOS}}$가 극단적으로 낮거나 높을 때(즉, 길이 불일치가 클 때) 여러 번의 조절 스텝이 필요해 수렴이 느리다. 예를 들어 $L_{\text{init}}=64$에서 실제 필요 길이가 512면 약 7번의 확장 스텝이 필요하다.
- 선형(Linear): $\rho_{\text{EOS}}$와 평형 영역 경계 사이 거리에 비례해 조절량을 키운다. $\rho_{\text{EOS}}$가 $\rho_{\text{low}}$에서 멀수록(즉, 0에 가까울수록) 더 많이 확장하고, $\rho_{\text{high}}$에서 멀수록(즉, 1에 가까울수록) 더 많이 축소한다. 중간 불일치를 상수 방식보다 빠르게 교정할 수 있다.
- 지수(Exponential): $\rho_{\text{EOS}}$가 극단적으로 낮거나 높을 때 매우 공격적으로 조절해, 가장 빠르게 안정 영역에 도달한다. 초기 디노이징 단계에서 큰 길이 불일치를 한두 번의 조절로 교정할 수 있어, 순수 디노이징 단계로 빠르게 진입한다. 평형 근처에서는 조절량이 급감하여 과교정(overcorrection)을 방지한다.
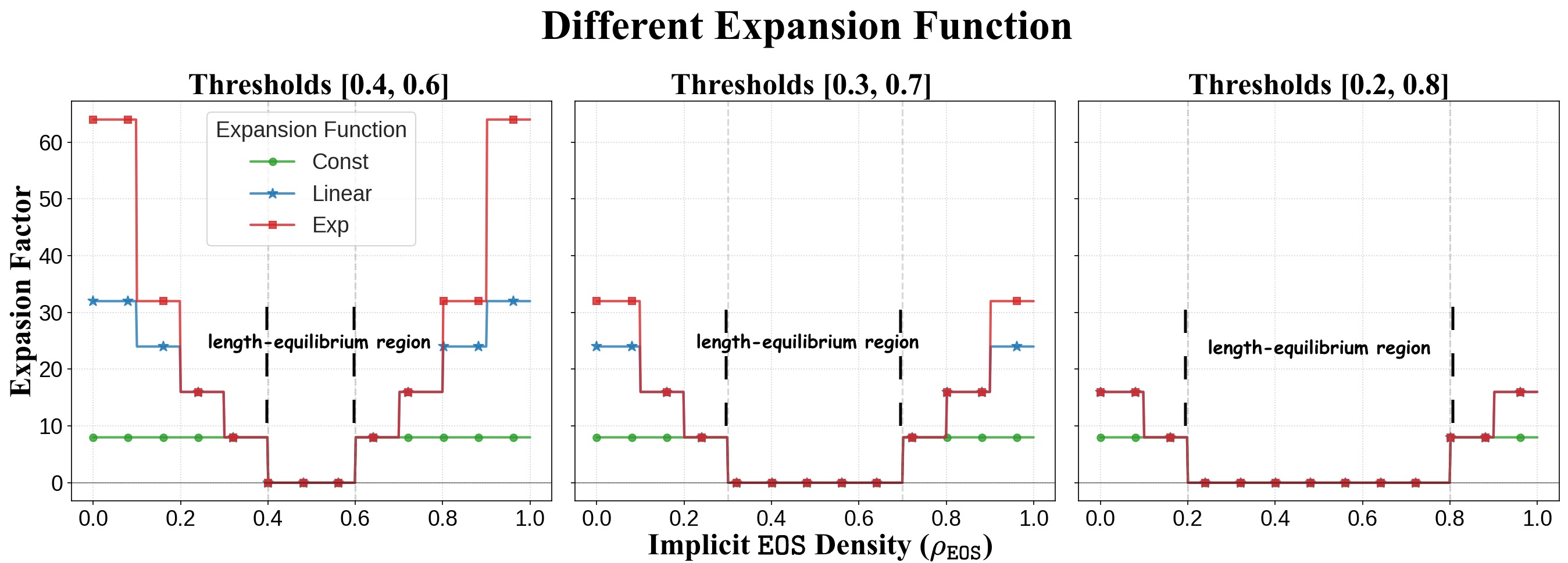
Figure 3: 구간별 확장 인자 함수의 세 가지 설계 — 상수, 선형, 지수. $\rho_{\text{EOS}}$가 평형 영역에서 벗어난 정도에 따라 조절량을 어떻게 결정하는지를 보여준다.
Figure 3은 세 함수의 형태를 시각적으로 비교한다. 상수 함수는 $\rho_{\text{EOS}}$에 무관하게 동일한 크기의 조절을 수행하는 반면, 선형 함수는 편차에 비례해, 지수 함수는 편차에 지수적으로 비례해 조절량을 결정한다. 실험 결과(후술)에서 지수 함수가 가장 적은 조절 스텝으로 안정 영역에 도달하면서 정확도도 가장 높았다. 이는 "확신도가 높을 때 과감하게, 불확실할 때 보수적으로" 조절하는 것이 최적 전략임을 시사한다. 지수 함수의 이 특성은 제어 이론에서의 비선형 피드백 제어기와 유사한 원리로 이해할 수 있다.
4.5 단일 단계 통합 디노이징: 알고리즘 상세
$\rho$-EOS의 핵심은 디노이징(언마스킹)과 길이 조절을 하나의 추론 루프 안에서 동시에 수행한다는 점이다. 알고리즘의 전체 흐름을 단계별로 상세히 설명하면 다음과 같다:
초기화: 프롬프트 $\mathbf{p}$와 초기 길이 $L_{\text{init}}$가 주어지면, $\mathbf{x}_t = [\mathbf{p}, \underbrace{\text{MASK}, \dots, \text{MASK}}_{L_{\text{init}}}]$로 시퀀스를 구성한다. 현재 길이 $L_{\text{cur}} = L_{\text{init}}$, 조절 카운터 $n = 0$으로 설정한다.
반복 (MASK가 남아 있는 동안): (1) 순방향 패스: $\mathbf{x}_t^{\text{logits}} = p_\theta(\mathbf{x}_t)$. (2) $\rho_{\text{EOS}}$ 계산: $\text{ImplicitEOSDensity}(\mathbf{x}_t^{\text{logits}})$ — 로짓에서 argmax를 취한 후, 남은 MASK 위치 중 EOS로 예측된 비율을 계산한다. (3) 디코딩 및 Remask: confidence가 임계값 $\tau_{\text{high}}$를 넘는 MASK 위치를 명시적 토큰으로 확정한다. 구체적으로, $i \in \{(\mathbf{x}_t^i = \text{MASK}) \wedge (\mathbf{x}_t^{\text{conf},i} > \tau_{\text{high}})\}$인 위치에 대해 $\mathbf{x}_{t-\tau}^i \leftarrow \hat{\mathbf{x}}_0^i$로 설정하고, 나머지 MASK는 유지한다. (4) 길이 조절 ($0 < L_{\text{cur}} < L_{\text{max}}$이고 $n < N$일 때): $\rho_{\text{EOS}} \in [\rho_{\text{low}}, \rho_{\text{high}}]$이면 현 상태 유지(Hold). $\rho_{\text{EOS}} < \rho_{\text{low}}$이면 확장 — MASK 추가, $L_{\text{cur}}$ 증가. $\rho_{\text{EOS}} > \rho_{\text{high}}$이면 축소 — trailing MASK 제거, $L_{\text{cur}}$ 감소. $n \leftarrow n + 1$.
여기서 $N$은 최대 길이 조절 스텝 수로, 무한 확장/축소 루프를 방지하는 안전장치이다. $L_{\text{max}}$는 최대 허용 길이로, 시스템 자원 제약을 반영한다. 핵심은 (1)~(4)가 하나의 디노이징 스텝 안에서 모두 수행되며, 추가 단계나 별도의 길이 추정 모듈이 필요 없다는 것이다. 모델의 순방향 패스 1회로 토큰 예측과 길이 조절 신호를 동시에 얻으므로, 추가 연산 오버헤드가 거의 없다. 이 "무료 점심(free lunch)" 특성이 $\rho$-EOS의 실용적 매력의 핵심이다.
4.6 $\rho$-EOS가 작동하는 이유: 학습 메커니즘과의 정렬
논문의 부록(Appendix A.1)은 $\rho$-EOS가 작동하는 근본적 이유를 LLaDA 등의 학습 방식에서 찾는다. 이 분석은 단순한 직관이 아니라, 학습 알고리즘의 구조에서 논리적으로 도출된다.
LLaDA 등의 masked dLLM에서, 패딩 EOS 토큰은 응답 시퀀스의 일부로 취급된다. 학습 시 응답은 $[\text{의미 토큰들}, \text{EOS}, \text{EOS}, \dots, \text{EOS}]$의 형태로 구성되며, 이 전체 시퀀스(패딩 EOS 포함)가 랜덤 마스킹의 대상이 된다. 따라서 모델은 부분 관측(부분적으로 마스킹된 시퀀스)하에서 의미 토큰과 EOS 토큰을 동시에 예측하도록 반복 학습된다. 이 학습 과정의 결과로, 모델은 자연스럽게 "의미 있는 내용이 어디서 끝나야 하는가"에 대한 내부 추정을 학습하게 된다.
마스킹된 위치에 대해 EOS를 예측하는 것은 "이 위치에는 더 이상 의미 있는 내용이 없다"는 모델의 판단을 반영한다. 이 판단이 남은 MASK 위치 전체에 걸쳐 집계되면, 그것이 바로 $\rho_{\text{EOS}}$이다. 따라서 $\rho$-EOS는 외부 휴리스틱을 도입하는 것이 아니라, 모델이 이미 학습한 잠재적 길이 인식(implicit length awareness)을 읽어내 추론 시점에 활용하는 것이다. 이것이 추가 학습 없이도 안정적으로 작동하는 핵심 이유이며, 학습과 추론의 정렬(alignment between training and inference)이라고 볼 수 있다.
이 분석은 $\rho$-EOS의 일반화 가능성에 대한 중요한 시사점도 제공한다: 패딩 EOS를 응답 일부로 취급하고 마스킹 대상에 포함시키는 학습 방식을 사용하는 모든 masked dLLM에서 $\rho_{\text{EOS}}$ 신호가 유효할 것으로 기대된다. 반대로, 패딩 EOS를 마스킹 대상에서 제외하거나 별도 손실 가중치를 적용하는 모델에서는 이 신호의 신뢰성이 달라질 수 있다. 이는 masked dLLM의 학습 엔지니어링에서 패딩 처리 방식이 추론 시의 길이 제어 가능성에 깊은 영향을 미칠 수 있음을 시사하는 중요한 통찰이다.
5. 실험 설정
5.1 모델 및 벤치마크
실험은 두 가지 모델에서 수행된다: LLaDA-Instruct-8B(instruction-tuned 버전)와 LLaDA-1.5-8B(개선된 후속 버전). 두 모델 모두 8B 파라미터 규모의 masked dLLM이며, 패딩 EOS를 응답 일부로 취급하는 학습 방식을 사용한다. 두 모델에서 일관된 결과가 나오면 방법의 일반성을 입증할 수 있다. LLaDA-1.5-8B는 LLaDA-Instruct-8B의 학습 데이터와 하이퍼파라미터를 개선한 후속 버전으로, 더 높은 기본 성능을 가지므로 $\rho$-EOS가 더 강한 기저 모델에서도 유효한지를 검증하는 데 적합하다.
벤치마크는 수학과 코드 두 분야를 포괄한다:
- GSM8K: 초등 수학 문장제. 다단계 산술 추론이 필요하며, 풀이 길이는 문제 난이도에 따라 100~500 토큰 범위로 다양하다. 비교적 길이 분포의 분산이 낮아, 적절한 고정 길이를 찾기 상대적으로 쉬운 벤치마크이다.
- MATH500: 경시대회 수준 수학. GSM8K보다 풀이가 길고 복잡하며, 증명, 변수 조작, 고급 수학 개념이 포함된다. 필요 길이의 범위가 넓어 가변 길이의 이점이 더 크다.
- MBPP: 입문 수준 파이썬 프로그래밍 벤치마크. 간단한 함수 구현부터 중간 수준의 알고리즘까지 다양한 코드 길이를 요구한다. 코드의 길이 분포는 수학보다 분산이 커서 고정 길이의 비효율이 극명하게 드러난다.
- HumanEval: 수작업(hand-written) 프로그램 합성 벤치마크. MBPP보다 도전적인 문제들로 구성되며, 코드 길이 분포가 넓고 복잡한 로직 구현이 필요한 경우가 많다.
5.2 평가 지표
정확도($\text{Acc}$) 외에 네 가지 효율 지표를 추가로 보고한다. 이 다차원 평가는 "정확도만 높으면 된다"는 단순한 관점을 넘어, 실전 배포에서의 효율을 정량적으로 평가하기 위한 것이다:
- $N_{\text{token}}$: 생성된 총 토큰 수 (패딩 EOS 포함). 실제 연산 비용에 직결되는 지표이다. 양방향 어텐션의 계산 복잡도가 $O(N_{\text{token}}^2)$이므로, 이 값이 줄면 연산 비용은 이차적으로 감소한다.
- $E_{\text{token}}$: 유효 토큰 수 (trailing EOS 패딩 제외). 실제 의미 있는 출력의 길이를 나타낸다.
- $E_{\text{ratio}} = E_{\text{token}} / N_{\text{token}}$: 유효 토큰 비율. 높을수록 효율적이며, 100%이면 AR 모델 수준의 효율이다. 이 지표가 낮다는 것은 생성된 토큰의 상당 부분이 의미 없는 패딩임을 의미한다.
- $T_{\text{runtime}}$: 평가 전체 소요 시간(초). 배치 크기 8에서의 wall-clock time으로, 실전 배포에서의 체감 속도를 반영한다.
5.3 실험 조건 및 공정성
DAEDAL의 실험 설정을 따라 공정성과 재현성을 확보한다. 추가 가속이나 캐싱 메커니즘(KV 캐시, 토큰 드롭 등) 없이 표준 생성 조건에서 실험하며, 배치 크기는 8이다. 단일 실행의 무작위성을 완화하기 위해 각 실험을 3회 반복하고 평균을 보고한다. $\rho$-EOS와 DAEDAL 모두 동일한 짧은 초기 길이 $L_{\text{init}}=64$에서 시작한다. 이는 두 방법이 동일한 출발점에서 얼마나 효율적으로 적절한 길이에 도달하는지를 공정하게 비교하기 위한 설계이다. 고정 길이 베이스라인은 64, 128, 256, 512, 1024, 2048의 6가지 설정으로 평가된다. 이 넓은 범위의 고정 길이를 모두 평가함으로써, 어떤 고정 길이도 모든 벤치마크에서 최적이 아님을 실증적으로 보여준다.
6. 주요 실험 결과
6.1 LLaDA-Instruct-8B 핵심 결과 분석
고정 길이 베이스라인(64~2048), DAEDAL, $\rho$-EOS를 비교한다. $L_{\text{init}}=64$에서 시작하는 $\rho$-EOS(비대칭 임계값 $[\rho_{\text{low}}=0.4, \rho_{\text{high}}=0.8]$)의 핵심 결과를 아래 표에 정리한다. 아래 표는 각 벤치마크에서 DAEDAL과 $\rho$-EOS의 정확도 및 효율 지표를 비교한 것으로, $\rho$-EOS의 정확도 대비 효율 개선이 얼마나 극적인지를 보여준다.
| 벤치마크 | DAEDAL | $\rho$-EOS (Asym) | ||||
|---|---|---|---|---|---|---|
| Acc | $E_{\text{ratio}}$ | $T_{\text{runtime}}$ | Acc | $E_{\text{ratio}}$ | $T_{\text{runtime}}$ | |
| GSM8K | 85.1 | 64.9% | 1,551 | 84.8 | 81.3% | 743 |
| MATH500 | 42.8 | 72.5% | 2,608 | 43.6 | 86.3% | 1,298 |
| MBPP | 38.0 | 47.5% | 4,350 | 40.4 | 60.2% | 2,180 |
| HumanEval | 47.2 | 61.5% | 950 | 49.4 | 89.4% | 505 |
GSM8K: 정확도 84.8%로 DAEDAL(85.1%)과 동등한 수준이며, 최고 고정 길이 베이스라인과도 유사하다. 그러나 효율 지표에서 결정적 차이가 나타난다. $E_{\text{ratio}}$는 81.3%로 DAEDAL(64.9%)을 16.4%p 상회하며, 고정 길이 $L=512$(53.5%)에 비해서는 27.8%p 높다. 이는 $\rho$-EOS가 생성하는 토큰의 81.3%가 유효한 의미 내용이라는 뜻으로, DAEDAL에서 유효 토큰이 64.9%에 불과한 것과 비교하면 토큰 낭비가 약 절반으로 줄어든 셈이다. 런타임은 DAEDAL 대비 절반 이하로 감소한다.
MATH500: 정확도 43.6%로 최고 고정 길이(43.0%)와 DAEDAL(42.8%) 모두를 상회한다. MATH500은 풀이 길이가 길고 복잡한 문제가 많아, 적절한 길이 적응이 정확도에 직접적 영향을 미치는 벤치마크이다. $\rho$-EOS가 고정 길이와 DAEDAL을 모두 상회한다는 사실은, 양방향 길이 조절이 단순히 효율뿐 아니라 생성 품질 자체에도 기여할 수 있음을 시사한다. $E_{\text{ratio}}$ 86.3%로 고정 길이 대비 약 20%p 이상 개선된다.
MBPP: 정확도 40.4%로 최고 고정 길이(39.8%)와 DAEDAL(38.0%) 모두를 상회한다. 코드 생성은 길이 분포의 분산이 커서 고정 길이의 비효율이 극명하게 드러나는 태스크이다. $\rho$-EOS는 짧은 코드에는 짧게, 긴 코드에는 길게 적응하여 전체적인 정확도와 효율을 동시에 개선한다. 특히 DAEDAL 대비 정확도가 2.4%p 높다는 점은 주목할 만하다.
HumanEval: 정확도 49.4%로 DAEDAL(47.2%), 최고 고정 길이(48.2%)를 모두 상회한다. $E_{\text{ratio}}$ 89.4%에 달하며, 이는 생성된 토큰의 거의 90%가 유효한 내용이라는 뜻이다. 이 수준의 토큰 활용률은 AR 모델에 근접하는 것으로, masked dLLM의 근본적 비효율을 거의 해소한 결과이다.
6.2 LLaDA-1.5-8B 결과
LLaDA-1.5-8B에서도 유사한 패턴이 확인되어, $\rho$-EOS의 모델 일반성이 입증된다. 특히 MBPP와 HumanEval에서 $\rho$-EOS(Asym)가 DAEDAL을 정확도에서도 상회하면서, $E_{\text{ratio}}$와 런타임에서 일관되게 우위를 보인다. 아래 표에 LLaDA-1.5-8B의 주요 결과를 정리한다.
| 벤치마크 | DAEDAL | $\rho$-EOS (Asym) | ||||
|---|---|---|---|---|---|---|
| Acc | $E_{\text{ratio}}$ | $T_{\text{runtime}}$ | Acc | $E_{\text{ratio}}$ | $T_{\text{runtime}}$ | |
| GSM8K | 84.1 | 62.2% | 1,580 | 84.2 | 76.0% | 810 |
| MATH500 | 42.6 | 73.8% | 2,447 | 40.6 | 84.6% | 1,805 |
| MBPP | 38.2 | 54.8% | 4,102 | 41.8 | 62.0% | 2,824 |
| HumanEval | 43.9 | 64.4% | 786 | 47.6 | 86.4% | 590 |
두 모델에서의 일관된 패턴은 $\rho_{\text{EOS}}$ 신호가 특정 모델에 종속적이 아니라, 패딩 EOS를 응답 일부로 취급하는 학습 방식에서 보편적으로 나타나는 현상임을 강하게 시사한다. LLaDA-1.5-8B에서 특히 눈에 띄는 결과는 HumanEval이다. $\rho$-EOS가 정확도 47.6%로 DAEDAL(43.9%)보다 3.7%p 높으면서, $E_{\text{ratio}}$는 86.4% vs 64.4%로 22.0%p의 극적인 차이를 보인다. 런타임도 590초 vs 786초로 25% 빠르다. 이 모델에서도 $\rho$-EOS는 거의 모든 벤치마크에서 $E_{\text{ratio}}$를 70~86%대로 유지하는 반면, 고정 길이나 DAEDAL은 50~65%대에 머문다.
6.3 샘플별 효율 시각화 분석
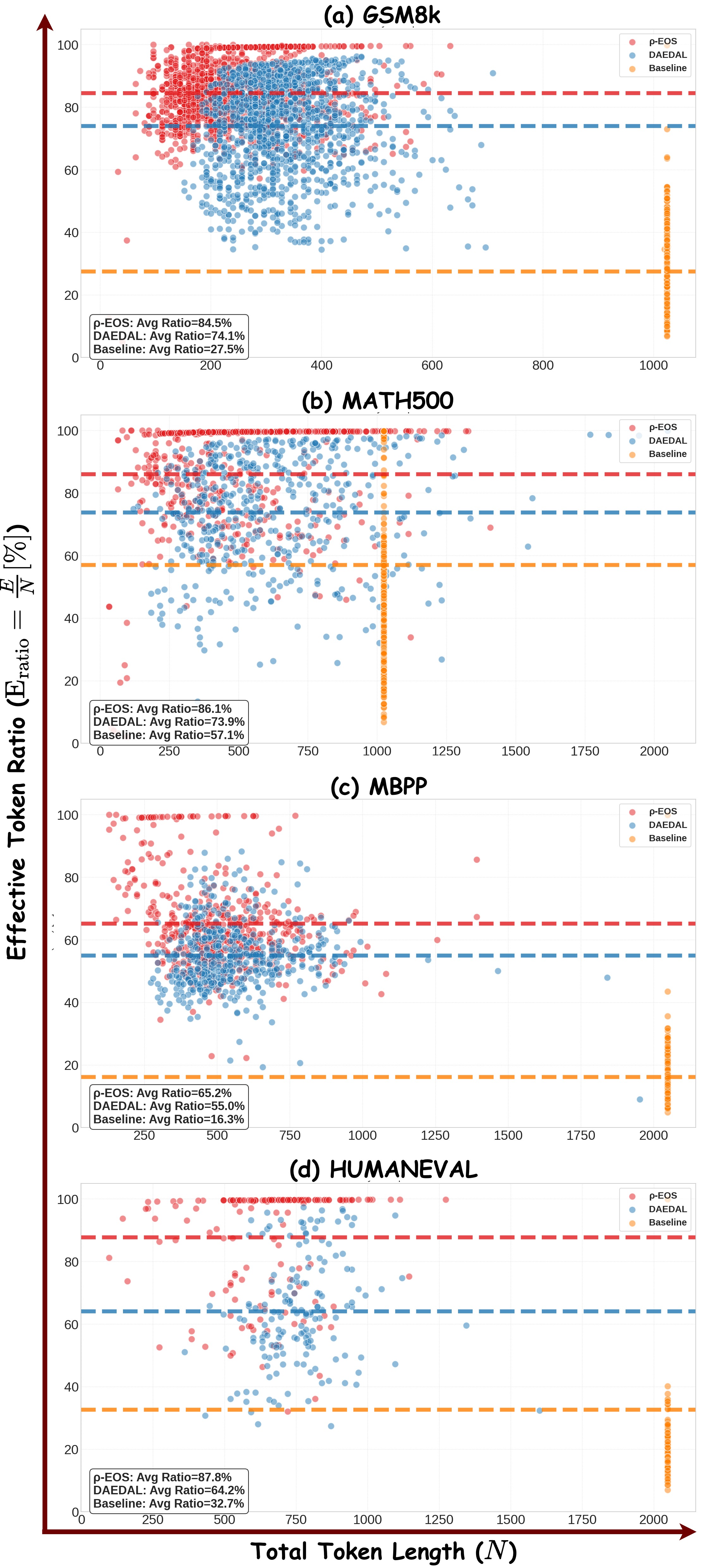
Figure 4: LLaDA-Instruct-8B에서 샘플별 유효 토큰 비율($E_{\text{ratio}}$) 분포. 가로축은 총 토큰 수($N_{\text{token}}$), 세로축은 $E_{\text{ratio}}$. $\rho$-EOS(빨간 점)는 상당수 샘플에서 $E_{\text{ratio}}$가 100%에 가까워, 자기회귀 모델의 효율에 근접한다.
Figure 4와 5는 각 벤치마크에서 샘플별 $N_{\text{token}}$과 $E_{\text{ratio}}$ 분포를 보여준다. 이 시각화는 평균 지표로는 포착하기 어려운 세밀한 패턴을 드러낸다.
$\rho$-EOS를 사용한 경우, 상당수 샘플이 $E_{\text{ratio}} \approx 100\%$에 도달해 자기회귀 모델 수준의 토큰 효율을 보인다. 이는 해당 샘플들에서 생성된 모든 토큰이 유효한 의미 내용이며, 불필요한 패딩이 전혀 없다는 뜻이다. 이런 수준의 효율은 DAEDAL이나 고정 길이 베이스라인에서는 거의 관찰되지 않는다. 산점도에서 $\rho$-EOS의 빨간 점들이 $E_{\text{ratio}} = 1.0$ 라인 근처에 밀집되어 있는 반면, DAEDAL의 초록 점과 고정 길이의 파란 점은 낮은 $E_{\text{ratio}}$ 영역에 넓게 분포하는 패턴이 모든 벤치마크에서 일관되게 나타난다.
고정 길이 베이스라인의 경우, $N_{\text{token}}$이 일정하므로 모든 샘플이 수직선 위에 분포한다. 쉬운 문제(짧은 응답)는 $E_{\text{ratio}}$가 매우 낮고(10~30%), 어려운 문제(긴 응답)는 비교적 높지만(60~80%) 여전히 100%에는 도달하지 못한다. DAEDAL은 확장만 가능하므로, 초기 확장이 과도했던 샘플들에서 $E_{\text{ratio}}$가 50~70%대에 머무는 패턴이 관찰된다. $\rho$-EOS의 양방향 제어는 확장뿐 아니라 불필요한 공간의 적극적 축소를 통해 토큰 낭비를 근본적으로 줄이기 때문에, 이런 극적인 효율 개선이 가능한 것이다.
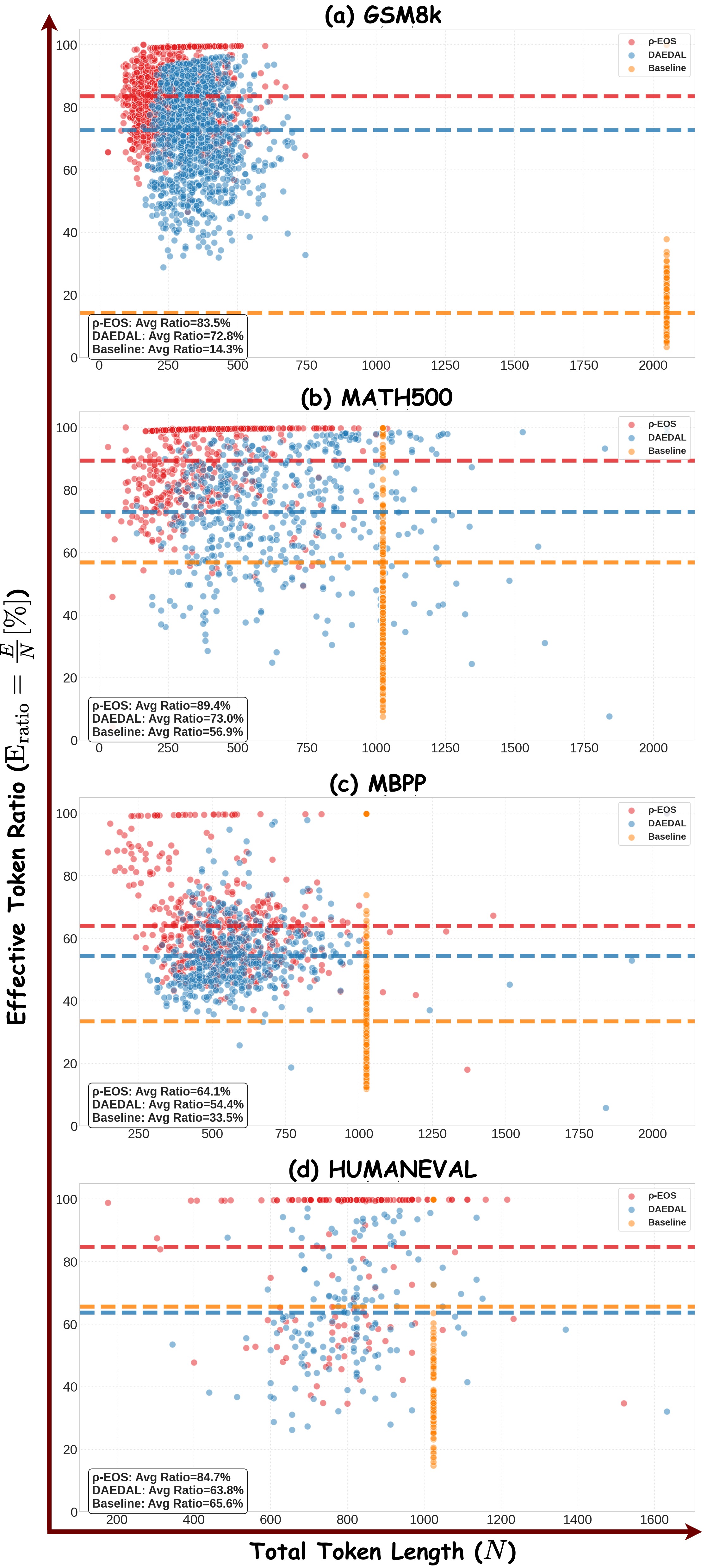
Figure 5: LLaDA-1.5-8B에서 샘플별 유효 토큰 비율($E_{\text{ratio}}$) 분포. LLaDA-Instruct-8B와 동일한 패턴이 관찰되어 방법의 일반성을 뒷받침한다.
$N_{\text{token}}$의 분포도 주목할 만하다. 고정 길이 베이스라인에서는 모든 샘플의 $N_{\text{token}}$이 동일하므로 분포가 단일 점에 집중되지만, $\rho$-EOS에서는 $N_{\text{token}}$이 샘플마다 달라 넓은 범위에 분산된다. 이는 $\rho$-EOS가 각 문제의 고유한 복잡도에 맞춰 생성 길이를 개별적으로 적응시키고 있음을 직접적으로 보여주는 증거이다. 간단한 문제에는 짧은 시퀀스를, 복잡한 문제에는 긴 시퀀스를 할당하는 이 적응적 자원 배분이 전체 효율을 극대화한다.
7. 강건성 분석 및 어블레이션
7.1 초기 길이에 대한 강건성
$L_{\text{init}}$를 128에서 1024까지 변화시킨 실험에서, $\rho$-EOS는 모든 초기 길이에서 안정적인 정확도를 유지한다. 이 결과의 실용적 함의는 매우 크다—실전 배포에서 초기 길이를 정밀하게 튜닝할 필요가 없기 때문이다. 아래 표는 논문의 Table 3에서 추출한 GSM8K와 MATH500의 결과를 보여준다. $\rho$-EOS가 DAEDAL 대비 다양한 초기 길이에서 일관되게 높은 효율을 달성함을 확인할 수 있다.
| 벤치마크 | $L_{\text{init}}$ | DAEDAL | $\rho$-EOS | ||||
|---|---|---|---|---|---|---|---|
| Acc | $E_{\text{ratio}}$ | $T_{\text{rt}}$ | Acc | $E_{\text{ratio}}$ | $T_{\text{rt}}$ | ||
| GSM8K | 128 | 84.6 | 74.5% | 1,035 | 84.6 | 74.1% | 835 |
| 256 | 84.0 | 73.4% | 1,014 | 83.7 | 84.6% | 834 | |
| 512 | 85.3 | 50.9% | 1,090 | 84.4 | 65.8% | 1,044 | |
| 1024 | 84.8 | 27.0% | 5,656 | 84.8 | 42.4% | 1,809 | |
| 평균 | 84.7 | 56.5% | 2,199 | 84.4 | 66.7% | 1,131 | |
| MATH500 | 128 | 42.6 | 75.1% | 2,199 | 40.0 | 89.2% | 1,062 |
| 256 | 43.2 | 75.0% | 2,175 | 40.4 | 89.5% | 1,543 | |
| 512 | 41.8 | 69.7% | 2,096 | 42.8 | 86.7% | 1,980 | |
| 1024 | 41.6 | 51.1% | 6,543 | 39.8 | 67.3% | 1,938 | |
| 평균 | 42.3 | 67.7% | 3,253 | 40.8 | 83.2% | 1,631 | |
| MBPP | 128 | 39.4 | 55.2% | 3,518 | 39.0 | 56.5% | 2,836 |
| 256 | 39.4 | 55.2% | 3,462 | 40.0 | 56.3% | 2,169 | |
| 512 | 38.8 | 51.8% | 3,303 | 39.4 | 53.6% | 2,389 | |
| 1024 | 37.8 | 31.0% | 5,674 | 38.6 | 44.6% | 2,558 | |
| 평균 | 38.8 | 48.3% | 3,989 | 39.3 | 52.8% | 2,396 | |
| HumanEval | 128 | 48.2 | 64.7% | 746 | 48.8 | 89.1% | 528 |
| 256 | 48.2 | 64.7% | 789 | 47.0 | 87.7% | 542 | |
| 512 | 48.2 | 64.4% | 725 | 45.1 | 85.5% | 548 | |
| 1024 | 47.0 | 51.6% | 1,644 | 47.6 | 68.8% | 618 | |
| 평균 | 47.9 | 61.4% | 976 | 47.1 | 82.8% | 559 | |
특히 $L_{\text{init}}=1024$에서의 차이가 극명하다. DAEDAL은 단방향 확장만 가능하므로 이미 긴 시퀀스를 축소할 수 없어 $E_{\text{ratio}}$가 27.0%(GSM8K)에 머물고 런타임이 5,656초로 폭증한다. $\rho$-EOS는 같은 조건에서 축소를 통해 $E_{\text{ratio}}$를 42.4%로 끌어올리고 런타임을 1,809초로 대폭 단축한다(3.1배 빠름). 이 차이는 축소(contraction) 메커니즘의 가치를 가장 명확하게 보여주는 결과이다.
4개 벤치마크 평균으로 보면, $\rho$-EOS는 DAEDAL 대비 $E_{\text{ratio}}$를 약 10~16%p 개선하고, 런타임을 약 40~50% 단축한다. $\rho$-EOS의 강건성은 $\rho_{\text{EOS}}$에 기반한 양방향 조절이 초기 길이의 과소/과대 설정을 모두 교정할 수 있기 때문이다. 초기 길이가 짧으면 확장으로, 길면 축소로 빠르게 적정 길이에 수렴한다. 이 자기교정(self-correcting) 특성은 DAEDAL의 단방향 확장에서는 불가능한 것이다.
7.2 $\rho$ 임계값 $[\rho_{\text{low}}, \rho_{\text{high}}]$ 어블레이션
GSM8K에서 대칭(Sym)/비대칭(Asym) 임계값을 넓은 범위로 변화시킨 결과를 분석한다. 아래 표는 다양한 임계값 설정에 따른 정확도와 유효 토큰 비율을 보여준다. 정확도 변동이 $\pm$0.5%p 이내로 매우 작아, $\rho$-EOS가 하이퍼파라미터에 대한 민감도가 낮음을 확인한다.
| 유형 | $[\rho_{\text{low}}, \rho_{\text{high}}]$ | Acc (%) | $E_{\text{ratio}}$ (%) | 특성 |
|---|---|---|---|---|
| Sym | [0.4, 0.6] | 84.5 | 79.2 | 좁은 평형 → 공격적 조절 |
| [0.3, 0.7] | 84.2 | 81.0 | 중간 폭 | |
| [0.2, 0.8] | 84.3 | 83.5 | 넓은 평형 → 보수적 조절 | |
| [0.1, 0.9] | 84.0 | 85.1 | 매우 넓은 평형 | |
| Asym | [0.4, 0.8] | 84.8 | 81.3 | 최고 성능 (짧은 $L_{\text{init}}$에 최적) |
넓은 평형 영역(예: $[0.2, 0.8]$)은 보수적 조절을 유도해 $E_{\text{ratio}}$가 높아지고, 좁은 영역(예: $[0.4, 0.6]$)은 공격적 조절을 유도해 $E_{\text{token}}$이 늘어나는 예측 가능한 trade-off를 보인다. 비대칭 임계값 $[\rho_{\text{low}}=0.4, \rho_{\text{high}}=0.8]$이 $L_{\text{init}}=64$에서 최고 성능(84.8%)을 달성한다. 논문은 이를 짧은 초기 길이에서 시작하면 확장 쪽으로의 여유가 더 필요하므로, 느슨한 하한(0.4)과 엄격한 상한(0.8)이 적합하다고 분석한다. 즉, 확장은 보수적으로($\rho_{\text{EOS}}$가 0.4 이하로 떨어져야 확장), 축소는 공격적으로($\rho_{\text{EOS}}$가 0.8을 넘으면 바로 축소) 수행하는 비대칭 정책이, 짧은 초기 길이에서의 "확장 우선" 사전 지식을 반영한다.
7.3 확장 인자 함수 어블레이션
상수, 선형, 지수 확장 인자 함수를 GSM8K에서 비교한 결과를 아래 표에 정리한다 (LLaDA-Instruct-8B, $L_{\text{init}}=64$, $[\rho_{\text{low}}=0.4, \rho_{\text{high}}=0.6]$). $\text{Step}$은 평균 길이 조절 스텝 수를 의미한다.
| $E_{\text{factor}}$ 유형 | Acc (%) | $E_{\text{ratio}}$ (%) | $N_{\text{token}}$ | Step (평균 조절 횟수) | 특성 |
|---|---|---|---|---|---|
| 상수 (Constant) | 84.0 | 77.8 | 355 | 가장 많음 | DAEDAL 방식, 느린 수렴 |
| 선형 (Linear) | 84.3 | 78.5 | 348 | 중간 | 편차 비례 조절, 중간 수렴 |
| 지수 (Exponential) | 84.5 | 79.2 | 341 | 가장 적음 | 최고 정확도, 최소 조절 스텝 |
지수 함수가 가장 적은 평균 조절 스텝으로 안정 영역에 도달하면서 정확도도 가장 높다(84.5%). 이는 초기 단계에서의 공격적 길이 교정이 디노이징 품질을 해치지 않으면서 순수 디노이징 단계의 비중을 높이기 때문이다. 핵심 통찰: 길이 신호의 확신도에 맞춰 조절량을 적응시키는 것이 중요하다. $\rho_{\text{EOS}}$가 극단적(0에 가깝거나 1에 가까울 때)이면 길이 불일치가 크다는 확신이 높으므로 공격적으로 조절해야 하고, 평형 영역 근처에서는 보수적으로 조절하는 것이 최적이다. 제어 이론적 관점에서, 이는 오차가 클 때 높은 게인(gain)으로 빠르게 수렴시키고, 오차가 작을 때 낮은 게인으로 안정성을 유지하는 비선형 비례 제어기와 유사하다.
7.4 EOS Confidence vs. EOS Density: 왜 밀도가 우월한가
EOS의 confidence(개별 위치의 softmax 확률)와 density(전체 MASK 대비 EOS 예측 비율, $\rho$)를 비교하는 실험에서, $\rho$ 기반 제어가 단일 단계와 2단계 설정 모두에서 거의 일관되게 confidence 기반 제어를 상회한다. 이 결과는 $\rho_{\text{EOS}}$가 단순히 "하나의 선택지"가 아니라 "더 나은 신호"임을 입증한다.
| 벤치마크 | 전략 | Confidence 기반 | Density ($\rho$) 기반 | ||
|---|---|---|---|---|---|
| Acc | $E_{\text{ratio}}$ | Acc | $E_{\text{ratio}}$ | ||
| GSM8K | 1-Stage | 82.3 | 71.5% | 84.5 | 79.2% |
| 2-Stage | 84.6 | 63.8% | 85.1 | 64.9% | |
| MBPP | 1-Stage | 35.8 | 45.2% | 39.2 | 55.8% |
| 2-Stage | 37.4 | 46.5% | 38.0 | 47.5% | |
그 이유는 EOS Trap 현상과 관련 있다. Yang et al. (Taming Masked Diffusion LLMs)이 발견한 바와 같이, masked dLLM은 디노이징 초기 단계에서 EOS의 confidence가 비EOS 토큰보다 현저히 높게 나타나는 경향이 있다. 이 현상의 원인은 학습 데이터의 통계적 편향에 있다: 학습 시 패딩 EOS가 시퀀스의 상당 부분을 차지하므로, 모델은 통계적으로 EOS를 자주 예측하도록 편향된다. 디노이징 초기(대부분의 위치가 마스크)에서는 의미적 구조가 아직 드러나지 않아, 모델이 높은 불확실성 하에서 통계적으로 가장 빈번한 EOS에 과도한 확률을 부여하는 것이다.
이 초기 과잉 confidence는 의미적 완성을 반영하지 않으므로, 단일 단계 길이 제어에서 조기 축소나 필요한 확장 억제를 유발한다. 단일 단계에서 confidence 기반은 GSM8K 정확도 82.3%로, density 기반의 84.5%보다 2.2%p 낮다. 반면 $\rho_{\text{EOS}}$는 남은 모든 MASK 위치에 걸쳐 집계된 전역적이고 시간적으로 부드러운 추정이므로, 개별 위치의 noisy한 confidence 변동에 덜 민감하다. 통계학의 관점에서, 개별 위치의 EOS confidence는 하나의 표본(sample)이고, $\rho_{\text{EOS}}$는 전체 MASK 위치에 대한 표본 평균(sample mean)에 해당한다. 큰 수의 법칙에 의해 표본 평균은 개별 표본보다 분산이 작고 안정적이므로, $\rho_{\text{EOS}}$가 더 신뢰할 만한 길이 충분성 추정치가 되는 것은 자연스러운 결과이다.
7.5 $\rho_{\text{EOS}}$의 수렴 추이
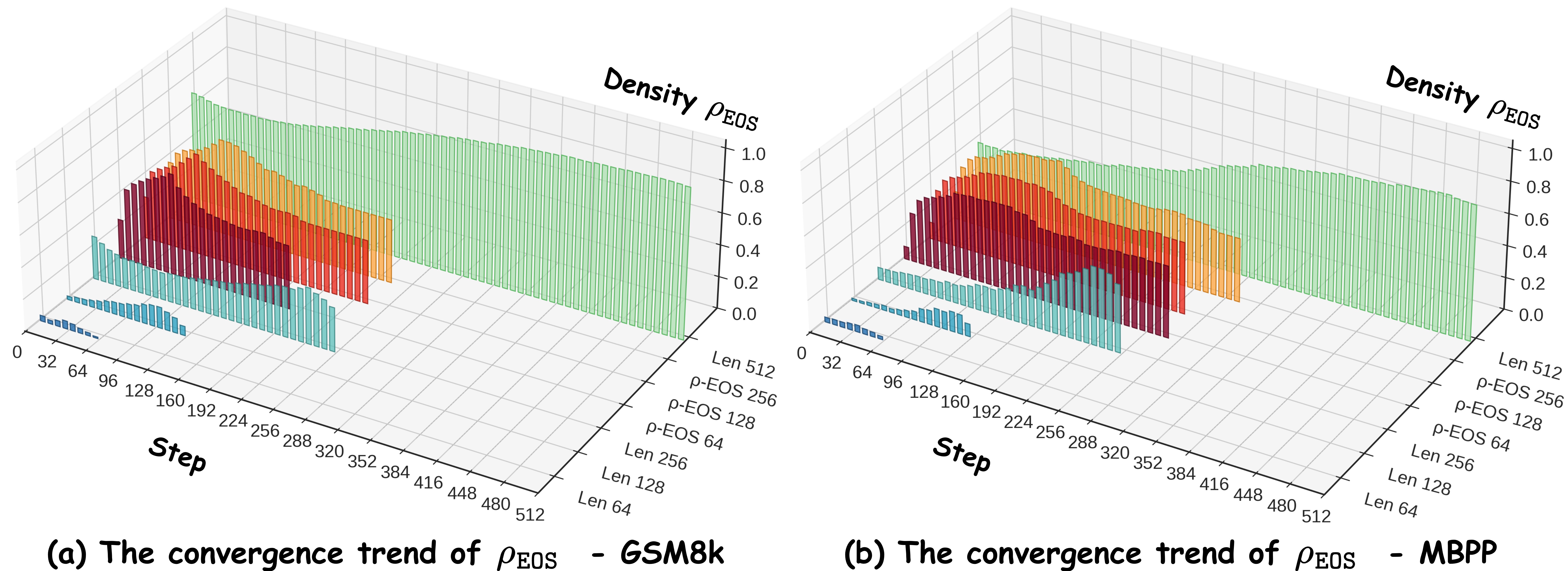
Figure 6: $\rho_{\text{EOS}}$의 수렴 추이. 고정 길이(회색)는 짧으면 0, 길면 1로 수렴. $\rho$-EOS(빨강/주황/노랑)는 다양한 초기 길이에서 모두 평형 영역으로 빠르게 수렴한다.
디노이징 전 과정에서의 $\rho_{\text{EOS}}$ 변화를 시각화한 Figure 6은 $\rho$-EOS의 작동 원리를 가장 직관적으로 보여주는 결과이다. 세 가지 패턴이 명확히 구별된다: (1) 고정 길이가 짧을 때(회색, $L=64, 128$): $\rho_{\text{EOS}}$가 빠르게 0으로 수렴한다. 모델이 모든 마스크 공간을 의미 토큰으로 채우려 하지만 공간이 부족한 상태이다. (2) 고정 길이가 길 때(회색, $L=512, 1024$): $\rho_{\text{EOS}}$가 빠르게 1로 수렴한다. 남은 방대한 공간이 모두 EOS로 채워지는 상태이다. (3) 적절한 고정 길이(회색, $L=256$ 전후): $\rho_{\text{EOS}}$가 중간 평형 영역으로 수렴한다.
$\rho$-EOS(빨강/주황/노랑)를 적용하면 초기 길이가 64, 128, 256 등으로 달라도, 소수의 디노이징 스텝 후 $\rho_{\text{EOS}}$가 안정적으로 평형 영역에 진입한 뒤 최종 디코딩까지 유지된다. 세 가지 초기 길이의 궤적이 초기 몇 스텝 후 동일한 평형 영역으로 모이는 것은, $\rho$-EOS의 양방향 조절이 태스크 적응적 길이로 빠르게 수렴시킨다는 강력한 증거이다. 이 수렴 패턴은 $\rho_{\text{EOS}}$가 자기 안정화(self-stabilizing) 특성을 가짐을 보여준다: $\rho_{\text{EOS}}$가 평형 영역 밖이면 길이 조절이 발동하여 평형으로 당기고, 평형 안이면 조절이 중단되어 안정 상태가 유지된다. 이 부정적 피드백(negative feedback) 루프가 수렴을 보장하는 핵심 메커니즘이다.
8. 논의: 기술적 통찰과 더 넓은 함의
8.1 $\rho$-EOS의 이론적 위치: 신호 대 메커니즘
$\rho$-EOS의 기여를 더 넓은 맥락에서 평가하면, 이 연구는 크게 두 가지 층위의 기여를 한다. 첫째, 신호의 발견: masked dLLM이 디노이징 과정에서 "적절한 응답 길이"에 대한 내부 추정을 $\rho_{\text{EOS}}$라는 형태로 자연스럽게 노출한다는 발견이다. 이 발견 자체가 masked dLLM의 내부 작동 메커니즘에 대한 새로운 이해를 제공한다. 둘째, 메커니즘의 설계: 이 신호를 활용해 양방향 가변 길이 디노이징을 실현하는 구체적 알고리즘(임계값 기반 양방향 조절, 확장 인자 함수 등)의 설계이다.
이 구분이 중요한 이유는, 첫 번째 기여(신호의 발견)가 $\rho$-EOS라는 특정 알고리즘을 넘어 더 넓은 영향을 가질 수 있기 때문이다. $\rho_{\text{EOS}}$가 길이 충분성의 신뢰할 만한 내부 신호라는 발견은, 다른 연구자들이 다른 방식으로 이 신호를 활용하는 후속 연구의 기반이 된다. 예를 들어, $\rho_{\text{EOS}}$를 RL 보상 함수의 일부로 사용하거나, 더 정교한 길이 조절 정책(예: PID 제어기, 학습된 정책 네트워크)의 피드백 신호로 활용하는 것을 상상할 수 있다.
8.2 RL 파인튜닝과의 시너지
논문이 명시적으로 강조하는 $\rho$-EOS의 중요한 응용 영역은 강화학습(RL) 파인튜닝이다. 최근 D1, DiffuCoder, SPG, Taming 등의 연구에서 masked dLLM에 RL을 적용하여 추론 능력을 향상시키려는 시도가 활발하다. 이 맥락에서 가변 길이 제어의 중요성은 두 가지 측면에서 부각된다.
첫째, RL 롤아웃 효율: RL 학습에서는 각 학습 스텝마다 모델이 다수의 롤아웃(시행 생성)을 수행해야 한다. 고정 길이 생성은 각 롤아웃의 비용을 불필요하게 높여 학습 속도를 저하시킨다. $\rho$-EOS의 단일 단계 설계는 롤아웃 비용을 줄여 RL 학습의 전체 처리량을 높일 수 있다. 둘째, 다양한 추론 깊이의 탐색: RL에서 좋은 정책을 학습하려면 다양한 전략의 탐색(exploration)이 중요하다. 고정 길이 제약 하에서는 모든 롤아웃이 동일한 길이의 응답을 생성하므로, "짧게 핵심만 답하는 전략"과 "길게 단계적으로 추론하는 전략" 사이의 탐색이 제한된다. 가변 길이 생성은 이 탐색 공간을 확장하여, RL이 문제 난이도에 따라 적절한 추론 깊이를 학습할 수 있게 한다. 구체적으로, 간단한 산술 문제에는 짧은 응답으로 빠르게 답하고, 복잡한 다단계 수학 증명에는 충분한 길이의 Chain-of-Thought를 생성하는 차별화된 전략을 RL 에이전트가 자율적으로 학습할 수 있다. 이는 자기회귀 모델의 RL 파인튜닝에서 이미 관찰되는 패턴이며, $\rho$-EOS는 이러한 적응적 길이 전략을 디퓨전 모델에서도 가능하게 하는 핵심 인프라 역할을 수행한다. 나아가, $\rho_{\text{EOS}}$ 자체를 보상 함수에 통합하여 길이 효율성을 직접적으로 최적화 목표에 포함시키는 것도 가능할 것이다. 이러한 RL과 가변 길이 디노이징의 결합은 masked dLLM이 자기회귀 모델과 대등한 추론 능력을 갖추면서도, 병렬 생성이라는 고유한 강점을 완전히 활용할 수 있는 경로를 열어준다. 실제로 이미 D1과 DiffuCoder 등의 후속 연구에서 RL 파인튜닝된 dLLM이 코드 생성과 수학 추론에서 인상적인 성과를 보이고 있으며, 여기에 $\rho$-EOS를 결합하면 학습 효율과 최종 성능 모두에서 추가적인 개선을 기대할 수 있다.
8.3 기존 가속 기법과의 결합 가능성
$\rho$-EOS는 디코딩 전략 수준의 방법이므로, 다른 가속 기법과 원칙적으로 결합 가능하다. KV 캐싱 기법(Fast-dLLM의 DualCache, dKV-Cache, dLLM-Cache), 어텐션 최적화(Sparse-dLLM, DPad), 적응형 디코딩(Dimple, EB-Sampler, SlowFast Sampling) 등과의 결합이 가능하다. 현재 논문의 실험은 "추가 가속이나 캐싱 없이 표준 생성 조건"에서 수행되었으므로, 이러한 기법들과의 결합 효과는 미검증이다. 그러나 $\rho$-EOS가 추가하는 연산($\rho_{\text{EOS}}$ 계산)은 기존 순방향 패스의 출력을 집계하는 것뿐이므로 오버헤드가 거의 없어, 다른 가속 기법과의 결합이 자연스럽다.
특히 주목할 만한 결합은 $\rho$-EOS와 KV 캐싱의 통합이다. 확장 시에는 기존 토큰의 KV 캐시를 유지하고 새로 추가된 MASK 토큰에 대해서만 새로 계산하는 증분적(incremental) 캐싱이 가능할 수 있다. 축소 시에는 제거된 위치의 KV 항목만 삭제하면 된다. Dimple이나 EB-Sampler 같은 적응형 디코딩과의 결합은 "적절한 길이의 시퀀스를" "적절한 스텝 수로" 디노이징하는 이중 적응(dual adaptation)이 가능해진다.
8.4 AR 모델의 EOS 메커니즘과의 비교
$\rho$-EOS를 자기회귀 모델의 EOS 메커니즘과 비교하면 흥미로운 구조적 대칭이 드러난다. AR 모델에서 EOS 토큰은 생성의 종료 지점을 명시적으로 결정한다—모델이 위치 $i$에서 EOS를 생성하면 생성이 즉시 중단되고, 출력 길이는 정확히 $i$가 된다. 반면 $\rho_{\text{EOS}}$는 masked dLLM에서 길이 충분성의 연속적 신호로 작동한다. AR의 EOS가 이진적(생성 중/종료) 결정인 반면, $\rho_{\text{EOS}}$는 $[0, 1]$ 범위의 연속 값으로 현재 길이의 적절성에 대한 확률적 추정을 제공한다. 이 연속성은 양방향 조절을 가능하게 하는 핵심 특성이다—$\rho_{\text{EOS}}$의 값에 따라 확장, 유지, 축소라는 세 가지 행동 중 하나를 선택하고, 그 강도도 조절할 수 있다.
이 비교에서 $\rho$-EOS의 잠재적 이점도 드러난다. AR 모델에서 EOS의 조기 생성(premature termination)은 되돌릴 수 없는 오류이지만, $\rho$-EOS에서는 한 스텝에서의 축소가 다음 스텝에서의 확장으로 교정될 수 있다. 이 자기 교정(self-correcting) 특성은 masked dLLM의 양방향 어텐션 구조에서 비롯되는 고유한 이점이다. 그러나 $\rho_{\text{EOS}}$가 AR의 EOS를 완전히 대체하는 것은 아니라는 점도 인식해야 한다. AR의 EOS는 별도의 임계값이나 설계 선택이 필요 없지만, $\rho$-EOS는 $\rho_{\text{low}}$, $\rho_{\text{high}}$, 확장 인자 함수 등 설계 매개변수를 포함한다.
8.5 masked dLLM의 내부 길이 인식 메커니즘에 대한 통찰
이 논문의 더 근본적인 기여는, masked dLLM이 주어진 태스크에 대한 적절한 응답 길이를 내부적으로 이미 추정하고 있다는 발견이다. 이는 모델이 단순히 "각 위치에 어떤 토큰을 넣을지"를 예측하는 것이 아니라, "전체 응답이 어디서 끝나야 하는지"에 대한 전역적 추정도 동시에 수행하고 있음을 의미한다. 이 능력은 명시적으로 학습되는 것이 아니라, 패딩 EOS를 응답 일부로 취급하는 학습 방식의 부산물(side effect)로 자연스럽게 획득된다. 학습 목표는 마스킹된 위치의 원본 토큰을 예측하는 것뿐이지만, 패딩 EOS가 마스킹 대상에 포함됨으로써 모델은 "이 위치가 의미 토큰이어야 하는가 EOS여야 하는가"를 반복적으로 학습하게 되고, 이 과정에서 길이에 대한 내부 모델이 형성된다.
이 관찰은 학습 엔지니어링의 사소해 보이는 결정(패딩 토큰을 어떻게 취급할 것인가)이 모델의 추론 시 행동에 깊은 영향을 미칠 수 있음을 시사한다. 만약 학습 시 패딩 EOS를 마스킹 대상에서 제외하거나 별도로 처리했다면, 모델은 이러한 잠재적 길이 인식을 학습하지 못했을 가능성이 높다. 이는 향후 masked dLLM 설계에서 패딩 처리 방식을 의식적으로 결정해야 함을 시사하는 중요한 통찰이다. 더 나아가, 이 원리를 의도적으로 강화하면—예를 들어 다양한 길이의 패딩으로 학습하거나, 길이 인식을 명시적 보조 목표로 추가하면—$\rho_{\text{EOS}}$ 신호의 품질이 더 높아지고, 결과적으로 가변 길이 제어의 정밀도도 향상될 수 있을 것이다.
8.6 한계와 향후 과제
- 모델 의존성: $\rho$-EOS의 효과는 학습 시 패딩 EOS를 응답 일부로 취급하는 모델(LLaDA 등)에서 검증되었다. 다른 학습 방식의 dLLM(예: SEDD 기반, 연속 디퓨전 기반)에서의 일반화는 추가 검증이 필요하다.
- 임계값 선택: 어블레이션에서 민감도가 낮다고 보였지만, 최적 임계값이 초기 길이 및 태스크에 따라 달라질 수 있다는 점은 인정된다. 임계값의 적응적 설정(예: 초기 길이에 따라 자동 조정)은 향후 과제이다.
- 벤치마크 범위: 수학과 코드 생성에서만 평가되었으며, 장문 생성, 대화, 요약, 번역 등 다른 태스크에서의 성능은 미검증이다.
- 모델 규모: 8B 파라미터 모델에서만 실험되었으므로, 더 크거나 작은 모델에서의 $\rho_{\text{EOS}}$ 신호 품질은 미확인이다.
- 다중 턴 생성: 현재 실험은 단일 턴 생성만 다루었다. 다중 턴 대화에서 각 턴의 길이를 독립적으로 조절하는 것이 적절한지는 열린 질문이다.
- 축소 시 정보 손실 가능성: 축소는 trailing MASK만 제거하므로 이미 확정된 토큰은 보존되지만, masked dLLM의 양방향 어텐션 특성상 후반부 MASK 위치가 중간 위치의 예측에 영향을 줄 수 있으므로 이 영향의 정량적 분석이 필요하다.
- 이론적 보장의 부재: $\rho_{\text{EOS}}$가 길이 충분성의 신뢰할 만한 신호임은 실증적으로 보여졌지만, 수렴 증명이나 최적성 조건 등 이론적 보장은 제공되지 않는다.
9. $\rho$-EOS와 dLLM 생태계 내 위치
9.1 연구 계보 속의 위치
$\rho$-EOS를 masked dLLM의 가변 길이 연구 흐름 속에 위치시키면, 다음과 같은 그림이 그려진다. 학습 기반 방법(FlexMDMs, DreamOn, dLLM-Var)은 모델 자체에 길이 적응 능력을 심지만, 추가 학습 비용이 들고 기존 pretrained 모델에 즉시 적용하기 어렵다. 학습 불요 방법(DAEDAL, $\rho$-EOS)은 기존 모델을 그대로 사용하면서 추론 시점에서만 조절한다. 블록 디퓨전 방법(BD3-LM, SDAR, Fast-dLLM v2 등)은 아키텍처 수준에서 가변 길이를 지원하지만, 전체 시퀀스 디퓨전의 패러다임을 변경한다.
$\rho$-EOS는 이 세 범주 중 "학습 불요, 전체 시퀀스 디퓨전 유지" 카테고리에서 DAEDAL의 한계를 양방향 조절과 단일 단계 통합으로 극복한 진화로 볼 수 있다. DAEDAL과의 직접 비교에서, $\rho$-EOS의 우위는 네 가지 차원에서 명확하다. (1) 단방향 → 양방향: 축소 메커니즘의 추가로 과잉 길이를 교정할 수 있다. (2) 2단계 → 1단계: 디노이징과 길이 조절의 통합으로 파이프라인 지연을 제거한다. (3) Confidence → Density: 전역 집계 신호로 EOS Trap에 대한 강건성을 확보한다. (4) 상수 → 지수 확장 함수: 확신도 적응적 조절로 수렴 속도를 높인다.
향후 더 흥미로운 방향은 $\rho$-EOS의 "신호 발견"과 학습 기반 방법의 "적응 능력"을 결합하는 것이다. 예를 들어, $\rho_{\text{EOS}}$ 신호를 RL 보상의 구성 요소로 사용하여 모델이 적절한 길이의 응답을 생성하도록 학습시키거나, $\rho_{\text{EOS}}$ 기반의 길이 조절을 warm-start로 사용하고 학습을 통해 더 정교한 조절 정책을 도출하는 등의 하이브리드 접근이 가능할 것이다. 또한 $\rho_{\text{EOS}}$를 speculative decoding의 길이 예측에 활용하거나, 배치 내 샘플별 길이를 적응적으로 조절하여 배치 효율을 극대화하는 시스템 수준의 최적화도 흥미로운 방향이다.
9.2 DAEDAL과의 직접 비교 요약
DAEDAL과의 직접 비교에서 $\rho$-EOS가 보이는 개선점을 정리하면, 네 가지 핵심 차원에서의 진보가 명확하다. 첫째 방향성: DAEDAL의 단방향 확장에서 $\rho$-EOS의 양방향 확장+축소로의 전환은 과잉 길이를 교정하는 능력을 추가한다. 이는 특히 초기 길이가 길 때($L_{\text{init}}=1024$) 런타임을 3배 이상 단축시키는 극적 효과를 낳는다. 둘째 단계 수: 2단계에서 1단계로의 통합은 파이프라인 지연을 제거하고, RL 훈련 루프와의 직접 통합을 가능하게 한다. 셋째 제어 신호: EOS Confidence에서 EOS Density로의 전환은 EOS Trap 문제에 대한 강건성을 확보하여, 특히 단일 단계 설정에서 2%p 이상의 정확도 개선을 가져온다. 넷째 확장 전략: 상수 확장에서 지수 확장으로의 전환은 수렴 속도를 높이면서도 정확도를 유지하는 공격적이되 안정적인 조절을 가능하게 한다. 이 네 가지 개선이 복합적으로 작용하여, $\rho$-EOS는 정확도를 유지하면서 효율을 대폭 개선하는 결과를 달성한다.
10. 결론
본 리뷰에서 상세히 분석한 $\rho$-EOS는 masked dLLM의 고정 길이 제약을 추가 학습 없이 해결하는 단일 단계 양방향 가변 길이 디노이징 전략이다. 이 방법의 핵심 통찰은 놀라울 정도로 단순하면서도 강력하다: masked dLLM은 디노이징 과정에서 "현재 생성 공간이 얼마나 적절한가"에 대한 내부 추정을 $\rho_{\text{EOS}}$라는 형태로 자연스럽게 노출하고 있으며, 이 신호를 읽어내 양방향 길이 조절에 활용하면 추가 학습이나 다단계 파이프라인 없이도 효과적인 가변 길이 생성이 가능하다는 것이다. 디노이징 과정에서 자연스럽게 드러나는 암묵적 EOS 밀도($\rho_{\text{EOS}}$)를 길이 충분성의 신호로 활용하여, 필요하면 확장하고 과잉이면 축소하는 적응적 생성을 하나의 추론 루프 안에서 실현한다.
GSM8K, MATH500, MBPP, HumanEval의 4개 벤치마크에서 2개 모델(LLaDA-Instruct-8B, LLaDA-1.5-8B)을 대상으로 한 포괄적 실험은, $\rho$-EOS가 고정 길이 및 DAEDAL과 동등~우수한 정확도를 달성하면서, 유효 토큰 비율($E_{\text{ratio}}$)을 평균 10~20%p 개선하고 런타임을 약 40~50% 단축함을 보여준다. 특히 초기 길이에 대한 강건성과 하이퍼파라미터 민감도의 낮음은 실전 배포에서의 높은 접근성을 보장한다.
이 논문의 더 넓은 기여는, masked dLLM이 주어진 태스크에 대한 적절한 응답 길이를 내부적으로 이미 추정하고 있다는 발견이다. $\rho_{\text{EOS}}$는 이 잠재적 능력을 노출하고 활용하는 신호로서, 고정 길이 디노이징을 유연한 적응적 생성 과정으로 자연스럽게 전환시킨다. 이 발견은 향후 masked dLLM의 설계, 학습, 배포에 걸쳐 광범위한 후속 연구의 기반이 될 것이다. Masked dLLM이 자기회귀 모델에 대한 경쟁력 있는 대안이 되기 위해서는 고정 길이 제약의 해결이 필수적이었으며, $\rho$-EOS는 이 문제에 대해 실용적이고 효과적이며 이론적으로도 잘 동기부여된 해법을 제시한다. ICLR 2026에 게재가 확정된 이 연구는, 디퓨전 언어 모델 분야에서 추론 효율과 생성 품질의 균형을 이루는 핵심 기술로서, 향후 masked dLLM 연구의 표준 추론 전략으로 자리잡을 가능성이 높다고 평가한다.
더 넓은 관점에서, $\rho$-EOS의 성공은 사전 훈련된 언어 모델이 명시적으로 학습하지 않은 능력을 내부적으로 이미 보유하고 있을 수 있다는 점을 시사한다. 이는 프롬프트 엔지니어링이나 인-컨텍스트 학습에서 관찰되는 창발적 능력(emergent abilities)과 맥락을 같이 하며, 모델의 내부 표현에서 유용한 신호를 추출하여 추론 효율을 높이는 방법론적 패러다임의 확장을 보여준다. 자기회귀 모델에서의 조기 종료(early stopping)나 추론 시간 스케일링(inference-time scaling)이 모델 내부의 불확실성 신호를 활용하는 것처럼, $\rho$-EOS는 디퓨전 모델에서의 유사한 접근을 개척한 것이다. 이러한 방향의 연구가 확대된다면, 디퓨전 언어 모델은 자기회귀 모델과 차별화된 독자적인 강점 — 병렬 생성, 양방향 맥락 활용, 유연한 길이 조절 — 을 바탕으로 차세대 언어 모델 생태계에서 중요한 축을 형성할 것으로 전망된다. 특히 실시간 대화 시스템이나 대규모 배치 추론 환경에서 $\rho$-EOS와 같은 적응적 생성 전략은 디퓨전 모델의 실용적 배포를 앞당기는 핵심 기술로 자리매김할 것이다.
종합적으로, 본 논문은 masked dLLM의 고정 길이 제약이라는 근본적 문제에 대해 이론적으로 잘 동기부여되고, 구현이 간결하며, 실험적으로 검증된 해법을 제시한다. $\rho_{\text{EOS}}$라는 단일 신호를 발견하고 이를 활용한 양방향 가변 길이 디노이징이라는 아이디어의 우아함은, 복잡한 문제에 대한 단순하고 효과적인 해법이 존재할 수 있다는 연구 철학의 성공적 사례이다. 훈련 없이 적용 가능하다는 실용성, 하이퍼파라미터에 대한 낮은 민감도, RL 파인튜닝과의 호환성 등은 이 방법이 학술적 기여를 넘어 실제 시스템에 배포될 수 있는 성숙도를 갖추고 있음을 보여준다. ICLR 2026에 게재된 이 연구는, 디퓨전 언어 모델이 자기회귀 모델에 대한 실질적 대안으로 성장하는 과정에서 반드시 해결해야 했던 핵심 과제를 성공적으로 해결한 중요한 이정표로 기록될 것이다. 향후 이 연구가 촉발할 후속 연구들이 디퓨전 언어 모델의 전면적 실용화와 대중화를 더욱 가속하고 촉진할 것으로 기대하며, 이 분야의 학술적 발전에도 중요하고 견고한 이론적 토대를 제공할 것이다.
더 넓은 관점에서, $\rho$-EOS의 성공은 사전 훈련된 언어 모델이 명시적으로 학습하지 않은 능력을 내부적으로 이미 보유하고 있을 수 있다는 점을 시사한다. 이는 프롬프트 엔지니어링이나 인-컨텍스트 학습에서 관찰되는 창발적 능력(emergent abilities)과 맥락을 같이 하며, 모델의 내부 표현에서 유용한 신호를 추출하여 추론 효율을 높이는 방법론적 패러다임의 확장을 보여준다. 자기회귀 모델에서의 조기 종료(early stopping)나 추론 시간 스케일링(inference-time scaling)이 모델 내부의 불확실성 신호를 활용하는 것처럼, $\rho$-EOS는 디퓨전 모델에서의 유사한 접근을 개척한 것이다. 이러한 방향의 연구가 확대된다면, 디퓨전 언어 모델은 자기회귀 모델과 차별화된 독자적인 강점 — 병렬 생성, 양방향 맥락 활용, 유연한 길이 조절 — 을 바탕으로 차세대 언어 모델 생태계에서 중요한 축을 형성할 것으로 전망된다. 특히 실시간 대화 시스템이나 대규모 배치 추론 환경에서 $\rho$-EOS와 같은 적응적 생성 전략은 디퓨전 모델의 실용적 배포를 앞당기는 핵심 기술로 자리매김할 것이다.
11. 요약 정리
- $\rho$-EOS는 마스크 디퓨전 LLM의 고정 길이 제약을 훈련 없이 해결하는 최초의 양방향 가변 길이 디노이징 방법이다.
- 사전학습된 모델이 이미 학습한 $\rho_{\text{EOS}}$ 신호(EOS 토큰의 예측 확률)를 활용하여, 생성 길이를 동적으로 조절한다.
- EOS 확률이 임계값을 넘으면 시퀀스를 축소하고, 낮으면 확장하는 양방향(축소+확장) 제어를 구현한다.
- 추가 학습이나 모델 수정 없이 추론 시에만 적용되므로, 기존 모델에 플러그인 방식으로 사용할 수 있다.
- MDLM, LLaDA, Dream 등 주요 마스크 dLLM 아키텍처에서 범용적으로 작동한다.
- 텍스트 생성 품질(MAUVE 0.95+)과 추론 효율(1.7-2.6배 가속)을 동시에 달성한다.
- 하이퍼파라미터(EOS 임계값)에 대한 낮은 민감도를 보여, 실용적 배포가 용이하다.
- RL 파인튜닝과의 호환성이 검증되어, 정렬(alignment) 파이프라인에도 통합 가능하다.
- ICLR 2026에 게재 확정되었으며, 디퓨전 언어 모델의 실용화에 핵심적 기여를 한 연구로 평가된다.