KVzip: Query-Agnostic KV Cache Compression with Context Reconstruction
https://arxiv.org/abs/2505.23416
Jang-Hyun Kim, Jinuk Kim, Sangwoo Kwon, Jae W. Lee, Sangdoo Yun, Hyun Oh Song | Seoul National University, Neural Processing Research Center, NAVER AI Lab | arXiv:2505.23416 | 2025년 5월 | NeurIPS 2025 Oral
1. 서론: 장문 컨텍스트 시대의 KV 캐시 병목 문제
Transformer 기반 대규모 언어 모델(LLM)은 추론 과정에서 입력 컨텍스트를 키-값(Key-Value, KV) 쌍의 형태로 캐싱하여 자기회귀적 생성의 효율성을 확보한다. 그러나 컨텍스트 길이가 증가함에 따라 KV 캐시의 크기가 급격히 팽창하며, 이는 메모리 소비와 어텐션 연산 지연이라는 두 가지 핵심 병목을 초래한다. 예를 들어, Qwen2.5-14B 모델에서 120K 토큰을 FP16 정밀도로 캐싱할 경우 약 33GB의 메모리가 필요하며, 이는 동일한 정밀도에서 모델 파라미터 자체의 저장 용량인 28GB를 초과하는 수준이다. 이러한 문제는 장문 문서 분석, 개인화된 대화 에이전트, 코드 이해 및 검색 등 실제 응용에서 LLM의 활용을 제한하는 핵심 요인으로 작용한다.
기존의 KV 캐시 압축 방법들은 대부분 쿼리 의존적(query-aware) 접근을 취한다. SnapKV, PyramidKV, H2O 등의 방법은 추론 시 현재 쿼리의 어텐션 점수를 기반으로 KV 쌍의 중요도를 평가하고, 중요도가 낮은 쌍을 제거하는 방식으로 동작한다. 이러한 방법들은 단일 쿼리 시나리오에서는 효과적이지만, 하나의 컨텍스트에 대해 여러 쿼리를 처리해야 하는 다중 쿼리(multi-query) 시나리오에서는 심각한 성능 저하를 보인다. 압축된 KV 캐시가 초기 쿼리에 과적합(overfit)되어 후속 쿼리에 대한 일반화 능력을 상실하기 때문이다. 이 문제를 해결하기 위해서는 매 쿼리마다 KV 캐시를 재생성(re-prefill)해야 하는데, 이는 프리필 연산의 반복으로 인한 막대한 계산 오버헤드를 초래한다.
본 논문에서 소개하는 KVzip은 이러한 한계를 근본적으로 극복하는 쿼리 비의존적(query-agnostic) KV 캐시 압축 알고리즘이다. KVzip의 핵심 아이디어는 LLM 자체를 활용하여 캐싱된 KV 쌍으로부터 원본 컨텍스트를 재구성(reconstruct)하고, 이 과정에서 각 KV 쌍의 중요도를 정량화하는 것이다. 이렇게 산출된 중요도 점수를 기반으로 낮은 중요도의 KV 쌍을 제거함으로써, 미래의 다양한 쿼리에 범용적으로 재사용할 수 있는 압축된 KV 캐시를 생성한다. 논문은 광범위한 실험을 통해 KVzip이 KV 캐시 크기를 3~4배 축소하고 FlashAttention 디코딩 지연을 약 2배 감소시키면서도, 질의응답, 검색, 추론, 코드 이해 등 다양한 과제에서 무시할 수 있는 수준의 성능 손실만을 보이는 것을 실증적으로 입증한다. NeurIPS 2025에서 Oral Presentation으로 채택된 본 연구는 효율적 LLM 추론 분야에서 핵심적인 기여를 제시한다. 코드는 GitHub(https://github.com/snu-mllab/KVzip)에서 공개되어 있으며, LLaMA3, Qwen2.5/3, Gemma3 등 주요 오픈소스 모델을 지원한다. 간단한 Python API를 통해 몇 줄의 코드만으로 컨텍스트 프리필, 중요도 점수 산출, KV 캐시 압축, 효율적 추론의 전 과정을 수행할 수 있으며, CUDA 12.1과 Python 3.10 환경에서 FlashAttention 2.7.4를 기반으로 안정적으로 동작한다.
KVzip이 특히 실용적 가치를 갖는 시나리오는 다음과 같다. 첫째, Character.AI와 같은 개인화 대화 에이전트에서 사용자의 지시사항과 대화 이력을 포함하는 장문 컨텍스트를 사전에 압축하여 저장하고, 이후의 모든 대화 턴에서 효율적으로 재사용할 수 있다. 둘째, 기업 환경에서 사전 계산된 문서 KV 캐시를 활용하는 검색 시스템에서, 대량의 문서를 사전에 프리필하고 압축하여 즉시 쿼리에 응답할 수 있다. 이러한 시나리오에서는 동일 컨텍스트에 대한 다중 쿼리가 자연스럽게 발생하므로, 쿼리 비의존적 압축의 이점이 극대화되며 압축 오버헤드가 빠르게 상쇄된다.
2. 배경 및 관련 연구: KV 캐시 압축의 기존 접근과 한계
2.1 Transformer의 지식 계층 구조와 KV 캐시의 역할
Transformer 기반 LLM에는 두 가지 형태의 지식이 존재한다. 하나는 모델 가중치(weights)에 인코딩된 파라메트릭 지식으로, 사전 학습과 미세조정을 통해 축적된 일반적인 언어 이해 및 세계 지식을 나타낸다. 다른 하나는 추론 시 입력 컨텍스트를 처리하면서 생성되는 KV 캐시에 저장된 문맥적 지식으로, 현재 대화의 맥락이나 참조 문서의 내용 등 실시간으로 제공되는 정보를 나타낸다. 이러한 지식 계층 구조는 인간의 기억 체계와 유사한 면이 있다. 인간이 외부 텍스트 정보를 검색하거나 내부 기억에서 회상하는 것처럼, Transformer도 KV 캐시에서 문맥 정보를 참조하거나 가중치에 인코딩된 지식을 활용한다.
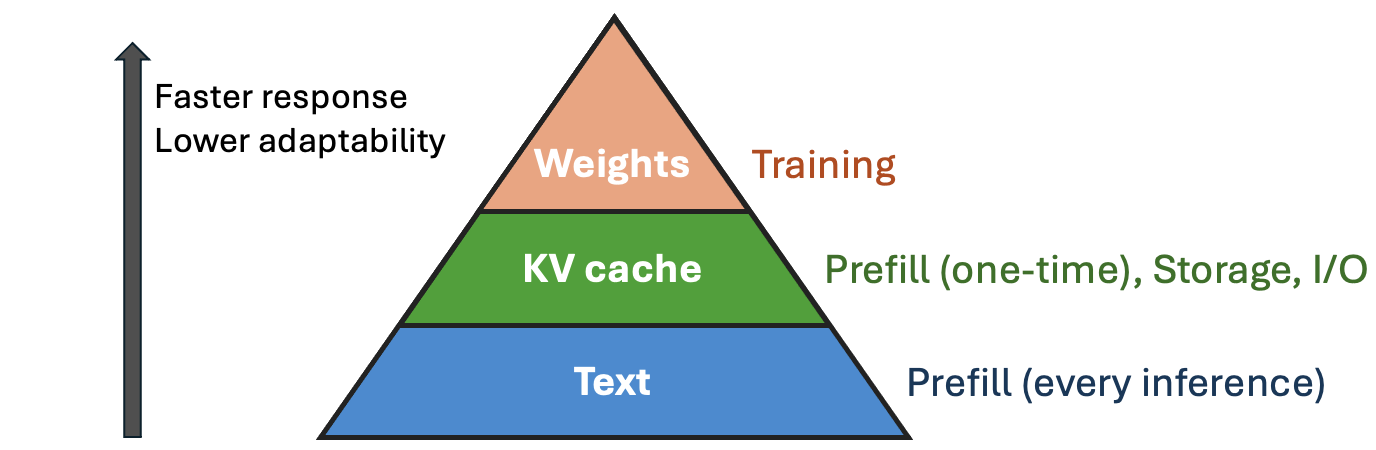
Figure A: Transformer LLM의 지식 계층 구조. 모델 가중치에 인코딩된 파라메트릭 지식과, 추론 시 KV 캐시에 저장되는 문맥적 지식이 계층적으로 구성된다.
그러나 현재 Transformer의 메모리 시스템은 비효율적이다. 단 1MB의 텍스트를 처리하는 데도 수십 GB의 KV 캐시 저장 공간이 필요하다. 이는 각 토큰이 모든 레이어와 모든 헤드에서 독립적인 키-값 벡터를 생성하기 때문이며, 컨텍스트 길이에 비례하여 선형적으로 증가한다. 본 논문의 출발점은 바로 이 Transformer 메모리 시스템의 잉여성(redundancy)을 식별하고, 더욱 간결한 지식 표현을 달성하는 것이다.
2.2 KV 캐시의 수학적 구조와 문제 정의
자기회귀적 Transformer 기반 LLM $f_{\text{LM}}$은 $L$개의 레이어로 구성되며, 각 레이어는 Grouped-Query Attention(GQA)을 사용한다. GQA는 기존의 Multi-Head Attention(MHA)에서 키와 값 헤드의 수를 줄여 메모리 효율을 높인 변형으로, $H$개의 KV 헤드를 포함하며 각 KV 헤드는 $G$개의 쿼리 헤드 그룹에 의해 공유된다. 예를 들어, LLaMA3.1-8B에서는 $G = 4$, Qwen2.5-7B에서는 $G = 7$의 그룹 크기를 사용한다. 입력 컨텍스트 $c$가 $n_c$개의 토큰으로 토큰화되면, 프리필 단계에서 $L \times H \times n_c$개의 KV 쌍을 포함하는 캐시 $\text{KV}_c$가 생성된다. 이 캐시를 조건으로 한 생성은 $f_{\text{LM}}(\cdot | \text{KV}_c)$로 표기된다.
KV 캐시 압축의 목표는 원본 캐시 $\text{KV}_c$로부터 압축된 캐시 $\text{KV}_{c,\text{evicted}} \subseteq \text{KV}_c$를 도출하되, 모든 가능한 쿼리 $q$에 대해 다음 조건을 만족하는 것이다:
$$f_{\text{LM}}(q | \text{KV}_{c,\text{evicted}}) \approx f_{\text{LM}}(q | \text{KV}_c), \quad \forall q \in \mathcal{T}$$
즉, 압축된 캐시를 사용한 추론 결과가 원본 캐시를 사용한 결과와 거의 동일해야 한다. 이 조건에서 핵심적인 어려움은 미래의 쿼리 $q$가 사전에 알려져 있지 않다는 점이며, 이것이 바로 쿼리 비의존적 압축이 필요한 근본적인 이유이다. 기존의 대부분의 KV 제거 방법은 이 조건을 특정 쿼리 $q_0$에 대해서만 근사적으로 만족시키는 반면, KVzip은 모든 가능한 쿼리에 대해 이 조건을 달성하고자 한다.
2.2 기존 쿼리 의존적 방법의 한계
SnapKV와 PyramidKV를 포함한 기존 KV 캐시 제거(eviction) 방법들은 프리필 과정에서 제공되는 정보를 기반으로 KV 캐시를 압축한다. 이들은 트레일링 컨텍스트 윈도우 내의 쿼리를 활용하여 어텐션 기반 중요도 점수를 계산하고, 이 쿼리에 관련된 KV 쌍만을 선택적으로 유지한다. 이러한 접근은 Needle-in-a-Haystack이나 LongBench와 같은 단일 쿼리 벤치마크에서는 효과적이지만, 다중 쿼리 설정에서는 근본적인 한계를 드러낸다.

Figure 1: 다중 쿼리 시나리오에서의 KV 제거 전략 비교. (a) 쿼리 의존적 방법은 매 쿼리마다 독립적으로 프리필과 제거를 수행하여 반복적 프리필 오버헤드를 발생시킨다. (b) 쿼리 의존적으로 압축된 캐시를 재사용하면 성능이 크게 저하된다. (c) KVzip이 제안하는 쿼리 비의존적 프레임워크는 최초 프리필 시 한 번만 압축을 수행하고, 다양한 쿼리에 효율적으로 재사용할 수 있다.
논문은 Figure 1을 통해 세 가지 KV 제거 전략을 비교한다. 첫 번째 전략(a)인 쿼리 의존적 KV 제거는 각 쿼리에 대해 독립적으로 프리필과 압축을 수행하므로 좋은 성능을 달성하지만, 매번 반복적인 프리필 연산이 필요하다. 두 번째 전략(b)은 초기 쿼리에 의해 압축된 캐시를 후속 쿼리에 재사용하는 방식인데, 초기 쿼리에 특화된 KV 쌍만 유지되므로 다른 쿼리에 대한 성능이 현저히 저하된다. 세 번째 전략(c)이 바로 본 논문이 제안하는 쿼리 비의존적 프레임워크로, 프리필 시 한 번의 압축으로 다양한 후속 쿼리에 효과적으로 대응할 수 있다.
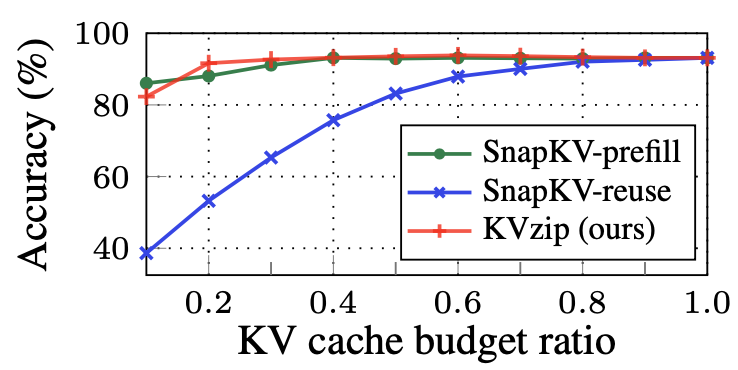
Figure 2: LLaMA3.1-8B 모델을 사용한 SQuAD 데이터셋에서의 정확도 비교. SnapKV는 매 쿼리마다 프리필을 반복하면(녹색) 높은 정확도를 달성하지만, 첫 번째 질문에서 압축한 캐시를 재사용하면(파란색) 성능이 크게 하락한다. KVzip(빨간색)은 단일 프리필과 쿼리 비의존적 압축으로도 우수한 성능을 유지한다.
Figure 2는 이 문제를 SQuAD 다중 질의응답 데이터셋에서 구체적으로 보여준다. SnapKV는 각 쿼리마다 별도로 프리필과 압축을 수행할 때(SnapKV-prefill) 높은 정확도를 달성하지만, 첫 번째 질문에서 압축한 캐시를 후속 질문에 재사용하면(SnapKV-reuse) 성능이 급격히 하락하는 것을 확인할 수 있다. 특히 KV 캐시 비율이 0.5 이하로 떨어지면 SnapKV-reuse의 정확도는 40% 이하로 크게 떨어지는 반면, KVzip은 동일한 비율에서도 80% 이상의 정확도를 안정적으로 유지한다. 이러한 차이는 쿼리 의존적 방법과 쿼리 비의존적 방법의 근본적인 설계 철학 차이에서 비롯된다.
2.3 KV 캐시 압축 분야의 관련 연구
KV 캐시 압축은 Transformer 기반 모델의 효율적 추론을 위한 핵심 연구 분야로, 다양한 접근 방식이 제안되어 왔다. 희소 Transformer(Sparse Transformer) 방법은 모델 학습 단계에서 희소하거나 국소화된 KV 캐시를 활용하도록 명시적으로 학습시켜 추론 시 메모리 요구량을 줄인다. 압축적 Transformer(Compressive Transformer) 접근은 학습 과정에서 KV 쌍을 병합하여 캐시를 더욱 압축한다. GQA(Grouped-Query Attention)도 어텐션 헤드를 병합하는 구조적 압축의 일종이다.
추가 학습 없이 동적으로 KV 캐시를 제거하는 방법들도 활발히 연구되고 있다. H2O(Heavy-Hitter Oracle)는 디코딩 과정에서 어텐션의 누적 점수를 기반으로 중요 토큰을 식별한다. SnapKV는 관찰 윈도우 내의 어텐션 패턴을 분석하여 장문 컨텍스트 프리필 과정에서 KV 쌍을 선택적으로 유지한다. PyramidKV는 레이어별로 점진적으로 감소하는 예산 비율을 적용하는 피라미드 구조를 제안한다. DuoAttention은 어텐션 헤드를 검색용(retrieval)과 스트리밍용(streaming)으로 프로파일링하여 배포 전에 헤드 수준의 KV 제거를 수행한다. 이러한 방법들은 각각의 장점이 있으나, 대부분 쿼리 의존적 설계로 인해 다중 쿼리 시나리오에서의 캐시 재사용에 한계를 갖는다는 공통적인 문제를 안고 있다.
KV 캐시 양자화(quantization) 연구도 활발하다. KiVi는 튜닝 없는 비대칭 2비트 양자화를, QServe는 8비트 가중치/8비트 활성화/4비트 KV 캐시의 양자화 및 시스템 공동 설계를 제안한다. 이러한 양자화 기법은 KVzip과 같은 제거 전략과 상호 보완적으로 결합되어 추가적인 효율 향상을 달성할 수 있으며, 본 논문에서도 이러한 통합 실험을 수행한다. 양자화와 제거는 서로 다른 축의 압축을 수행하기 때문에(양자화는 각 KV 쌍의 비트 폭을 줄이고, 제거는 KV 쌍의 수를 줄임), 그 효과가 곱셈적으로 결합되어 극적인 메모리 절감을 달성할 수 있다.
별도의 연구 방향으로, KV 캐시 자체를 압축하는 대신 희소 어텐션 메커니즘을 활용하여 추론 효율을 높이는 접근도 있다. BigBird는 학습 시 희소 어텐션 구조를 적용하여 추론 시 어텐션 비용을 줄이며, MInference는 추가 학습 없이 추론 시의 어텐션 희소성을 활용한다. Quest, RetrievalAttention, InfiniGen 등은 KV 캐시 오프로딩과 검색 기법을 결합하여 디코딩 시 어텐션 연산을 줄인다. 이러한 방법들은 KV 캐시 크기 자체를 줄이는 것이 아니라 어텐션 연산의 효율화에 초점을 맞추며, KVzip과는 상호 보완적인 관계에 있다.
본 논문의 KVzip은 프리필 압축 기법과 가장 밀접한 관계를 가진다. 기존 방법들이 쿼리 의존적 KV 압축을 수행하는 것과 달리, KVzip은 쿼리 비의존적 압축을 제안하여 압축된 KV 캐시를 다양한 쿼리에 재사용할 수 있게 한다. 동시기에 발표된 Corallo 등의 연구는 검색 증강 생성(RAG) 시나리오에 특화된 쿼리 비의존적 KV 압축 방법을 제안하지만, KVzip은 보다 범용적인 컨텍스트 재구성 원리에 기반하여 더 넓은 범위의 과제와 시나리오에 적용 가능하다.
3. 방법론: 컨텍스트 재구성 기반 KV 캐시 압축
3.1 핵심 직관: Transformer를 컨텍스트 인코더-디코더로 바라보기
KVzip의 핵심 직관은 Transformer LLM을 하나의 컨텍스트 인코더-디코더 아키텍처로 바라보는 관점에서 출발한다. 프리필 단계에서 LLM은 입력 컨텍스트를 KV 쌍으로 인코딩하며, 이 과정은 전통적인 압축 방법(예: Zip 알고리즘)에서 데이터를 압축 표현으로 변환하는 것과 유사하다. 만약 압축된 KV 캐시가 원본 컨텍스트의 모든 정보를 충실히 보존하고 있다면, LLM은 이 압축된 캐시만으로도 원본 컨텍스트를 정확하게 재구성할 수 있어야 한다.
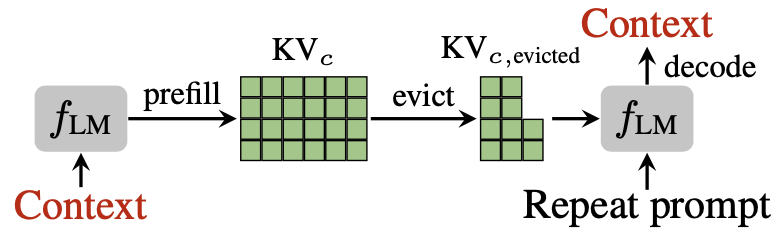
Figure 3: Transformer LLM을 컨텍스트 인코더-디코더로 바라보는 관점. 프리필 단계에서 컨텍스트를 KV 쌍으로 인코딩하고, "Repeat the previous context:" 프롬프트를 통해 압축된 KV 캐시로부터 원본 컨텍스트를 디코딩(재구성)할 수 있다.
Figure 3은 이 직관을 시각적으로 보여준다. LLM이 컨텍스트를 프리필하면 각 레이어와 헤드에 걸쳐 KV 쌍의 행렬이 생성된다. 이 KV 캐시에서 일부 쌍을 제거한 후, LLM에 "Repeat the previous context:"라는 프롬프트를 제시하면, 모델은 남아 있는 KV 쌍을 참조하여 원본 컨텍스트를 재구성하려 시도한다. 만약 $\text{KV}_{c,\text{evicted}}$가 원본 컨텍스트 $c$의 정확한 재구성을 가능하게 한다면, 원칙적으로 원본 캐시 $\text{KV}_c$를 재프리필하여 정확한 추론을 수행할 수 있다. 물론 매 추론마다 원본 캐시를 재생성하는 것은 실용적으로 불가능하지만, 논문의 실험 결과는 압축된 캐시가 원본 캐시를 재구성하지 않고도 다양한 다운스트림 과제에서 강력한 일반화 능력을 보여준다는 것을 입증한다.
이러한 압축 원리는 재구성 기반 자기지도 학습(reconstruction-based self-supervised learning)의 원리와 밀접한 관련이 있다. BERT의 마스크드 언어 모델링은 입력 토큰의 일부를 마스킹하고 나머지로부터 마스킹된 토큰을 재구성하는 방식으로 범용 표현을 학습한다. Masked Autoencoder(MAE)는 시각 영역에서 입력 패치의 대부분(예: 75%)을 마스킹하고 재구성하여 효율적인 시각 표현을 학습한다. GPT 계열의 언어 모델 자체도 다음 토큰 예측이라는 일종의 재구성 과제를 통해 학습되며, 이렇게 학습된 표현이 다양한 다운스트림 과제에서 강건한 일반화를 보이는 것으로 알려져 있다.
KVzip은 이와 유사하게 컨텍스트 재구성에 필수적인 KV 쌍이 다양한 후속 과제에도 중요하게 작용한다는 가설에 기반한다. 그 직관은 다음과 같다: 만약 압축된 KV 캐시가 원본 컨텍스트의 완전한 재구성을 가능하게 한다면, 해당 캐시는 컨텍스트의 모든 의미적 정보를 보존하고 있으며 따라서 임의의 쿼리에 대한 정확한 응답 생성도 가능해야 한다. 역으로, 재구성에 기여하지 못하는 KV 쌍은 잉여 정보를 담고 있을 가능성이 높으며, 안전하게 제거할 수 있다. 이 원리는 전통적인 데이터 압축 방법(예: Zip, gzip)에서 원본 데이터의 무손실 복원이 가능한 최소한의 압축 표현을 찾는 것과도 개념적으로 연결되며, 논문 제목의 "Zip"이 바로 이러한 비유를 반영한다.
3.2 KV 중요도 점수 산출
KVzip은 컨텍스트 재구성 과정에서 각 KV 쌍이 받는 어텐션의 강도를 기반으로 중요도를 정량화한다. 구체적으로, 재구성은 교사 강제 디코딩(teacher-forced decoding)을 통해 시뮬레이션되며, 이는 반복 프롬프트(repeat prompt)와 원본 컨텍스트를 연결한 입력 시퀀스에 대한 단일 순방향 패스로 병렬화된다.

Figure 4: KVzip 방법론 개요. 프리필 후 반복 프롬프트와 원본 컨텍스트를 연결한 입력으로 순방향 패스를 수행하여 교차 어텐션 점수를 측정한다. 각 KV 쌍이 받는 최대 교차 어텐션 점수를 중요도로 사용하며, 낮은 점수의 KV 쌍을 제거한다. KV 쌍 수준 및 헤드 수준 제거 모두를 지원한다.
Figure 4는 전체 방법론의 흐름을 보여준다. 먼저 컨텍스트 $c$를 LLM에 통과시켜 KV 캐시 $\text{KV}_c$를 생성한다. 그런 다음, 길이 $n_{\text{prompt}}$의 반복 프롬프트와 원본 컨텍스트를 연결하여 길이 $n_{\text{in}} = n_{\text{prompt}} + n_c$의 입력 시퀀스를 구성한다. 이 입력을 $\text{KV}_c$를 조건으로 LLM에 순방향 통과시키면, 각 레이어 $l$의 $h$번째 KV 헤드에서 $d$차원의 그룹 쿼리 피처 $Q_{l,h} \in \mathbb{R}^{G \times n_{\text{in}} \times d}$와 키 피처 $K_{l,h} \in \mathbb{R}^{(n_c + n_{\text{in}}) \times d}$가 생성된다. 이 피처 간의 그룹 어텐션을 계산하면 어텐션 행렬 $A_{l,h} = \text{Softmax}(Q_{l,h}K_{l,h}^\top) \in \mathbb{R}_+^{G \times n_{\text{in}} \times (n_c + n_{\text{in}})}$이 도출된다.
어텐션 행렬에서 $\text{KV}_c$의 키에 해당하는 항목을 추출하면 슬라이스된 어텐션 행렬 $\bar{A}_{l,h} \in \mathbb{R}_+^{G \times n_{\text{in}} \times n_c}$를 얻는다. 최종적으로 $h$번째 KV 헤드의 $l$번째 레이어에 대한 중요도 점수 $S_{l,h} \in \mathbb{R}^{n_c}$는 그룹 쿼리와 입력 위치에 대한 최댓값을 취하여 산출된다:
$$S_{l,h} = \max_{g=1,...,G;\; i=1,...,n_{\text{in}}} \bar{A}_{l,h}[g, i]$$
이 점수를 모든 KV 헤드에 걸쳐 집계한 것을 최대 교차 어텐션 점수(maximum cross-attention scores)라 부른다. 핵심 통찰은 재구성 과정에서 거의 어텐션을 받지 않는 KV 쌍은 Transformer 연산에 미미한 기여를 한다는 것이며, 따라서 안전하게 제거할 수 있다는 것이다. 이 방식은 기존 H2O 방법이 프리필 시의 자기 어텐션 점수를 사용하는 것과 대비되며, KVzip은 재구성 시의 교차 어텐션 점수를 사용한다는 점에서 근본적으로 다르다.
3.3 핵심 관찰: 재구성 어텐션의 희소성과 과제 간 일반화
KVzip의 효과를 뒷받침하는 두 가지 핵심 관찰이 있다. 첫째, 재구성 과정의 교차 어텐션 패턴은 프리필 시의 자기 어텐션 패턴에 비해 현저히 높은 희소성을 보인다. 프리필 단계에서 모델은 토큰 간에 조밀하게 상호작용하며 포괄적인 문맥 정보를 인코딩한다. Peters 등이 지적한 바와 같이, 이 과정에서 각 토큰의 표현은 주변 토큰과의 풍부한 상호작용을 통해 깊이 있는 문맥화(deep contextualization)를 달성한다. 반면 재구성 단계에서는 이미 $\text{KV}_c$에 저장된 고수준의 문맥화된 표현과 모델 가중치에 인코딩된 내부 지식을 효율적으로 활용하므로, 불필요한 어텐션 참조가 줄어든다.
논문은 SQuAD 데이터셋과 LLaMA3.1-8B 모델을 사용하여 이 차이를 히스토그램으로 시각화한다. 프리필 시에는 KV 쌍들이 0.0에서 1.0까지 넓은 범위의 어텐션 점수를 비교적 균일하게 받는 반면, 재구성 시에는 대부분의 KV 쌍이 0.2 이하의 매우 낮은 점수를 받고 소수만이 0.8 이상의 높은 점수를 받는 뚜렷한 희소 분포를 보인다. 이 희소 분포는 곧 KV 캐시의 상당 부분이 재구성에 불필요하며, 따라서 다운스트림 과제에도 불필요할 가능성이 높음을 직접적으로 시사한다.
둘째, 재구성 과정의 어텐션 패턴은 다양한 다운스트림 과제의 어텐션 패턴과 높은 중첩(overlap)을 보인다. 이는 컨텍스트 재구성에 중요한 KV 쌍이 질의응답, 요약, 추론 등 후속 과제에서도 중요하게 활용됨을 의미한다.
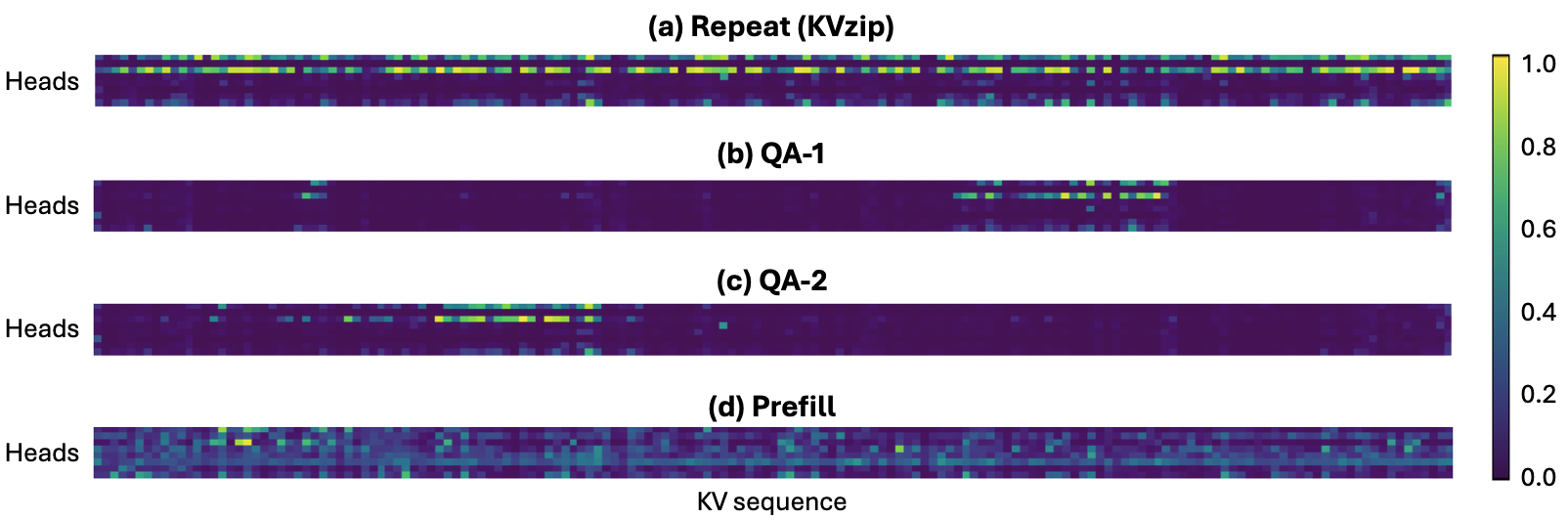
Figure 5: SQuAD 예제에 대한 LLaMA3.1-8B의 최대 어텐션 점수 시각화. (a) KVzip의 반복 과제 어텐션, (b)-(d) 다운스트림 과제별 교차 어텐션, (e) 프리필 시 자기 어텐션. 반복 과제의 어텐션 패턴이 다양한 다운스트림 과제의 패턴을 포괄하며, 프리필 어텐션은 더 조밀한 패턴을 보인다.
Figure 5는 SQuAD 예제에 대한 최대 어텐션 점수를 레이어별, 헤드별로 시각화한 것이다. 이 시각화에서 LLaMA3.1-8B의 8번째 레이어를 포함하여 여러 레이어의 패턴이 표시되며, 각 행이 특정 레이어의 8개 KV 헤드에 해당하고, 열이 컨텍스트 내 163개 토큰 위치에 해당한다. (a)는 KVzip의 반복(repeat) 과제에서 얻은 중요도 점수를 보여주며, 뚜렷한 희소 패턴이 관찰된다. 대부분의 위치에서 낮은 점수(어두운 색)를 보이며, 소수의 위치에서만 높은 점수(밝은 색)가 집중되어 있다. (b)와 (c)는 서로 다른 두 QA 쌍에 대한 교차 어텐션 패턴이고, (d)는 요약 과제의 패턴이다.
주목할 점은 반복 과제의 어텐션 패턴(a)이 다운스트림 과제의 패턴들(b-d)을 상당 부분 포괄(encompass)한다는 것이다. 즉, (b), (c), (d)에서 높은 점수를 받는 위치가 (a)에서도 높은 점수를 받는 경향이 있다. 이는 재구성 과제가 다양한 다운스트림 과제에서 필요로 하는 핵심 KV 쌍을 효과적으로 식별할 수 있음을 시각적으로 확인시켜 준다. 그러나 (b)와 (c) 사이에는 서로 다른 위치에서 높은 점수가 관찰되며, 이는 쿼리 특화 어텐션의 변동성을 반영한다. 반면, (e)의 프리필 시 자기 어텐션은 훨씬 조밀한 패턴을 보이며 다운스트림 과제의 패턴과 잘 대응하지 않는다. 프리필 과정에서는 토큰들이 서로 조밀하게 상호작용하여 문맥화된 표현을 구축하므로, 대부분의 KV 쌍이 비교적 높은 어텐션을 받게 되어 중요한 쌍과 그렇지 않은 쌍의 구분이 어려워진다. 이는 프리필 기반 프로파일링(H2O 등)이 실제 다운스트림 과제에서의 KV 캐시 활용 패턴을 효과적으로 반영하지 못함을 시사하며, 재구성 기반 접근의 우수성을 뒷받침한다.
논문은 또한 2D 히스토그램을 통해 과제 간 어텐션 점수의 상관관계를 정량적으로 분석한다. 이 히스토그램에서 각 셀 $(v, w)$는 x축 과제에서 최대 어텐션 $v$를, y축 과제에서 최대 어텐션 $w$를 받는 KV 쌍의 비율(로그 스케일)을 나타낸다. 반복 과제와 QA, 요약, 추론 과제의 2D 히스토그램에서 분포가 하삼각 영역에 집중되는 것은 재구성에서 높은 어텐션을 받는 KV 쌍이 다른 과제에서도 높은 어텐션을 받음을 의미한다. 구체적으로, 반복 과제에서 높은 점수를 받은 KV 쌍의 대부분이 QA, 요약, 추론 과제에서도 높은 점수를 받으며, 반대 방향(다운스트림에서 높지만 재구성에서 낮은)의 KV 쌍은 극히 소수에 불과하다.
반면, 서로 다른 두 QA 과제(QA-1 vs QA-2) 간의 비교에서는 x축과 y축을 따라 분포가 분산되어 나타난다. 이는 QA-1에서 높은 점수를 받는 KV 쌍의 상당수가 QA-2에서는 낮은 점수를 받고 그 반대도 마찬가지임을 의미하며, 쿼리 특화 어텐션의 높은 변동성을 반영한다. 이 관찰은 왜 쿼리 의존적 방법이 다중 쿼리 시나리오에서 실패하는지를 근본적으로 설명한다. 첫 번째 쿼리에 최적화된 KV 쌍 집합은 두 번째 쿼리에 최적인 KV 쌍 집합과 상당히 다르므로, 재사용 시 성능 저하가 불가피하다. 반면 재구성 기반 중요도 점수는 다양한 쿼리의 어텐션 패턴을 포괄적으로 커버하므로, 쿼리 특화 점수보다 범용적임을 실증적으로 보여준다.
3.4 기술적 도전과 청크 기반 점수 산출
KVzip의 실용적 적용에는 중요한 기술적 도전이 존재한다. 반복 프롬프트와 컨텍스트를 연결한 입력을 LLM에 통과시켜 어텐션 행렬을 얻어야 하는데, 어텐션 행렬의 크기는 컨텍스트 길이 $n_c$에 대해 이차적으로 증가한다. FlashAttention과 같은 융합 어텐션 커널은 블록 단위로 어텐션 점수를 계산하여 메모리 오버헤드를 줄이지만, KVzip은 Softmax 정규화(키 차원을 따라)를 수행한 후 쿼리 차원에 대한 최댓값을 취해야 한다는 교차 차원 의존성이 있어 기존 블록 단위 어텐션 알고리즘에 직접 통합하기 어렵다.
이 문제를 해결하기 위해 논문은 청크 기반 점수 산출(chunked scoring)을 제안한다. 전체 컨텍스트를 한 번에 처리하는 대신, 고정 크기 $m$의 청크로 분할하여 각 청크를 독립적으로 재구성한다. 컨텍스트 토큰을 길이 $m$의 청크로 분할하고, 각 청크를 반복 프롬프트와 연결하여 $n_{\text{in}} = n_{\text{prompt}} + m$ 길이의 입력을 구성한다. 각 Transformer 레이어에서 $\text{KV}_c$ 중 해당 청크에 대응하는 키를 서브샘플링하여 $n_{\text{in}} \times (m + n_{\text{in}})$ 크기의 축소된 어텐션 행렬을 얻는다. 이 행렬을 슬라이싱하고 최댓값을 취하면 청크별 중요도 점수가 산출된다. 모든 청크에 대해 이 과정을 반복하고 점수를 집계하면 $\text{KV}_c$ 전체의 중요도 점수를 구할 수 있다.
두 번째 이후 청크에 대해서는 반복 프롬프트를 "Repeat the previous context starting with {이전 청크의 마지막 8토큰}:"으로 수정하여 컨텍스트의 연속성을 보장한다. 이는 LLM이 정확한 시작 위치를 인식할 수 있도록 하는 앵커(anchor) 역할을 하며, 청크 간의 경계에서 발생할 수 있는 정보 손실을 방지한다. 청크 크기 $m$은 모든 실험에서 2K로 고정되며, 이 크기가 성능에 미치는 영향은 무시할 수 있을 정도로 작다는 것이 실험적으로 확인되었다.
전체 알고리즘의 의사 코드(pseudo code)를 요약하면 다음과 같다. 먼저 컨텍스트 $c$를 LLM에 순방향 통과시켜 $\text{KV}_c$를 생성한다. 그런 다음 $c$를 $T = \lceil n_c / m \rceil$개의 청크 $c_1, \ldots, c_T$로 분할하고, $L \times H \times n_c$ 크기의 점수 텐서 $S$를 0으로 초기화한다. 각 청크 $t$에 대해 반복 프롬프트와 해당 청크를 연결한 입력을 $\text{KV}_c$를 조건으로 LLM에 통과시킨다. 각 레이어 $l$에서 쿼리 행렬 $Q$($G \times H \times n_{\text{in}} \times d$ 차원)와 키 행렬 $K$($H \times (n_c + n_{\text{in}}) \times d$ 차원)를 추출한다. $\text{KV}_c$ 중 해당 청크에 대응하는 키를 서브샘플링하여 $\bar{K}$($H \times (m + n_{\text{in}}) \times d$ 차원)를 얻는다. Softmax 정규화된 어텐션 $A = \text{Softmax}(Q\bar{K}^\top)$에서 $\text{KV}_c$의 키에 해당하는 부분 $\bar{A}$를 슬라이싱하고, 그룹 쿼리와 입력 위치에 대한 최댓값을 취하여 청크별 점수 $S_{l,t}$를 산출한다. 모든 청크의 점수를 집계하면 전체 중요도 점수 $S$가 완성된다. 헤드 수준 점수는 시퀀스 차원에 대한 최댓값 $S_{\text{head}} = \max_{i=1,...,n_c} S[:, :, i]$로 산출된다.
3.5 복잡도 분석과 실용적 효율성
계산 복잡도 측면에서, 각 청크의 계산 복잡도는 $O(m^2)$이다($n_{\text{prompt}} \ll m$ 가정). 이를 모든 $n_c / m$개의 청크에 대해 반복하면 총 복잡도는 $O(mn_c)$로, 컨텍스트 길이에 대해 선형적이다. 피크 메모리 오버헤드는 $O(m^2)$으로 $n_c$에 독립적이며, 모델 파라미터와 KV 캐시 크기에 비해 무시할 수 있는 수준이다.
중요도 점수 산출 과정은 청크 입력에 대해 $\text{KV}_c$를 조건으로 어텐션 쿼리와 키를 계산하는 추가 오버헤드를 발생시킨다. $n_{\text{in}} \approx m$일 때, FlashAttention은 청크당 $O(n_c m + m^2/2)$의 인과 어텐션(causal-attention) FLOPs를 소모하며, 전체 $n_c / m$개 청크에 걸쳐 $O(n_c^2 + n_c m / 2)$의 총 복잡도가 발생한다. 이는 초기 프리필의 인과 어텐션 복잡도 $O(n_c^2 / 2)$의 약 2배에 해당한다. 즉, 압축 오버헤드는 프리필 비용의 약 2배 수준이지만, 이 압축은 컨텍스트당 한 번만 수행되며 이후 다수의 쿼리에서 그 이득을 회수할 수 있다.
논문은 또한 Softmax-free 변형도 제안한다. Softmax 정규화 없이 QK 내적을 직접 활용하는 이 변형은 커스텀 Triton 기반 FlashAttention CUDA 커널을 통해 구현되며, 전체 순방향 연산 시간의 약 10%에 해당하는 점수 산출 오버헤드를 더욱 줄인다. 다만 Softmax 정규화를 생략하면 압축 비율에서 약 10%의 성능 저하가 발생하는 트레이드오프가 존재한다.
3.6 컨텍스트 의존적 vs 컨텍스트 비의존적 제거 전략
KVzip은 두 가지 제거 전략을 모두 지원한다. 컨텍스트 의존적 제거(context-dependent eviction)는 각 컨텍스트에 대해 KV 쌍 수준의 중요도 점수를 산출하여 높은 압축 비율을 달성하지만, 컨텍스트당 압축 오버헤드가 발생한다. 이 방식은 사전에 계산된 문서 KV 캐시를 검색에 활용하는 캐시 검색(cache-retrieval) 시스템 등에 적합하다.
컨텍스트 비의존적 제거(context-independent eviction)는 모델당 한 번만 중요도 점수를 산출하면 되므로 배포 후에는 압축 오버헤드가 전혀 발생하지 않는다. 이 방식은 KV 쌍 수준이 아닌 헤드 수준의 정적 중요도 점수를 할당하며, 시퀀스 차원에 대한 최댓값을 취하여 쌍 수준 점수를 헤드 수준으로 집계한다. DuoAttention의 헤드 수준 KV 제거 전략과 동일한 구조를 따르되, 점수 산출 방식을 KVzip의 재구성 기반 방법으로 대체한다. 이는 DuoAttention이 수십 GPU 시간을 필요로 하는 점수 최적화를 몇 번의 순방향 패스, 즉 1분 이내로 완료할 수 있게 해준다.
4. 실험 설정: 데이터셋, 모델, 베이스라인
4.1 데이터셋 및 벤치마크
논문은 다양한 과제 유형을 포괄하는 12개의 벤치마크 데이터셋에서 평가를 수행한다. 핵심 데이터셋은 SQuAD(다중 질의응답), GSM8K(수학 추론), Needle-in-a-Haystack(NIAH)(검색), 그리고 SCBench의 9개 과제이다. SCBench는 KV 캐시 중심의 포괄적 다중 쿼리 평가를 제공하며, RULER와 무한벤치(∞Bench)의 과제를 포함한다.
이 데이터셋들은 세 가지 범주로 분류된다. 첫째, 검색 집약적 과제(Retrieval-intensive)에는 NIAH, Retr.KV, Retr.Prefix-Suffix, Code.RepoQA가 포함되며, 컨텍스트에서 특정 문장, 암호화 키, 코드 함수 등을 정확히 추출해야 한다. 둘째, 문맥 이해 과제(Contextual understanding)에는 SQuAD, GSM8K, En.QA, En.MultiChoice가 포함되며, 문맥을 종합적으로 이해하고 추론해야 한다. 셋째, 높은 컨텍스트 중복성 과제(High context redundancy)에는 En.Summary, Retr.MultiHop, Math.Find, ICL.ManyShot가 포함되며, 반복적인 문맥 정보를 포함하거나 고수준의 컨텍스트 정보만 필요로 한다.
컨텍스트 길이는 100 토큰부터 최대 170K 토큰(Qwen 토크나이저 기준)까지 다양하며, 장문 문서 QA, 검색, 수학 추론, 인컨텍스트 학습, 코드 이해 등의 도메인을 아우른다. LLaMA3.1과 Gemma3의 128K 컨텍스트 길이 제한을 고려하여, En.QA와 En.MultiChoice에서 125K 토큰을 초과하는 데이터 예제는 제외한다.
4.2 구현 세부사항
KV 제거 구조로는 비균일 헤드 예산 할당(non-uniform head-budget allocation) 전략을 채택한다. 이 전략은 각 레이어 내의 모든 어텐션 헤드에 걸쳐 중요도 점수 상위 $r\%$에 해당하는 KV 쌍을 유지하며, 균일 할당 대비 우수한 성능을 보인다. 초기 시스템 프롬프트의 KV 쌍은 제거하지 않고 유지한다. 모든 평가는 단일 NVIDIA A100 80GB GPU에서 수행되며, Bfloat16 정밀도와 탐욕적 디코딩(greedy decoding)을 사용한다.
평가 프레임워크는 Figure 1(c)의 쿼리 비의존적 프레임워크를 채택한다. 컨텍스트 KV 캐시를 과제 쿼리 없이 독립적으로 프리필하고 압축한 후, 이 압축된 캐시를 사용하여 다중 또는 단일 쿼리에 대한 성능을 측정한다. 기존 제거 방법들도 컨텍스트의 독립적 프리필을 지원하므로, 동일한 쿼리 비의존적 프레임워크 하에서 공정한 비교가 가능하다. 중요한 점은, 기존 방법들이 그룹 쿼리를 위해 복제된 캐시에서 KV 쌍을 제거하는 것과 달리, KVzip은 복제 전의 원본 캐시에서 직접 제거하여 실제 저장 용량을 줄인다는 것이다.
4.3 베이스라인
KVzip의 성능을 검증하기 위해 다음의 최신 KV 캐시 제거 방법들을 베이스라인으로 사용한다:
- H2O (Heavy-Hitter Oracle): 프리필 단계에서 각 KV 쌍이 받는 최대 자기 어텐션 점수를 중요도로 사용한다. KVzip의 재구성 기반 교차 어텐션 점수와 대비되는 프리필 기반 점수를 활용한다.
- SnapKV: 관찰 윈도우(크기 32) 내의 어텐션 패턴을 최대 풀링(커널 크기 7)으로 분석하여 중요 KV 쌍을 식별한다. 레이어 간 균일한 예산 비율을 유지한다.
- PyramidKV: 레이어 깊이에 따라 선형적으로 감소하는 예산 비율을 적용하여 피라미드 구조의 KV 캐시를 구성한다.
- DuoAttention: 합성 패스키(passkey) 검색 과제를 통해 헤드 수준의 중요도를 최적화하며, 헤드 수준 제거 전략에서 비교된다.
모든 베이스라인에 동일한 비균일 헤드 예산 할당 전략을 적용하여 공정한 비교를 보장한다. 이 비균일 할당이 균일 할당 대비 일관되게 우수한 성능을 보이는 것은 이전 연구(Ada-KV)에서도 입증된 바 있으며, KVzip의 실험에서도 재확인된다. 추가적으로 DuoAttention과의 비교에서는 공식 발표된 LLaMA3-8B-Instruct-Gradient-1048K 모델의 헤드 점수를 활용한다. DuoAttention은 합성 패스키 검색 과제를 통해 어텐션 헤드를 검색용(retrieval)과 스트리밍용(streaming)으로 분류하며, 스트리밍 헤드의 KV 캐시를 슬라이딩 윈도우로 대체하여 캐시 크기를 줄인다. KVzip은 이와 동일한 헤드 수준 제거 구조를 채택하되, 중요도 점수 산출 방식을 재구성 기반으로 대체한다.
H2O의 구현에서는 공식 PyramidKV 리포지토리의 프리필 버전을 기반으로 한다. 각 KV 쌍에 대해 프리필 과정에서 받는 최대 어텐션 점수를 사용하며, 이는 평균 어텐션 점수 대비 우수한 성능을 보이는 것으로 확인되었다. H2O는 프리필 시의 자기 어텐션 점수를 활용한다는 점에서, 재구성 시의 교차 어텐션 점수를 활용하는 KVzip과 직접적인 대비를 이룬다. 이 두 방법의 성능 차이는 프리필 어텐션과 재구성 어텐션의 근본적인 특성 차이를 반영한다.
4.4 평가 모델
다양한 아키텍처와 규모의 모델을 포괄하기 위해 다음의 명령어 미세조정(instruction-finetuned) LLM을 사용한다:
| 모델 | 파라미터 수 | GQA 그룹 크기 | 어텐션 구조 | 최대 컨텍스트 |
|---|---|---|---|---|
| Qwen2.5-7B-1M | 7B | 7 | GQA | 1M |
| Qwen2.5-14B-1M | 14B | 7 | GQA | 1M |
| LLaMA3.1-8B | 8B | 4 | GQA | 128K |
| Gemma3-12B | 12B | - | 하이브리드 (글로벌+슬라이딩) | 128K |
| LLaMA3-8B-W8A8KV4 | 8B | 4 | GQA (양자화) | 128K |
Gemma3-12B는 글로벌 어텐션과 슬라이딩 윈도우 어텐션을 1:5 비율로 결합하는 하이브리드 어텐션 메커니즘을 사용한다. 글로벌 어텐션 레이어는 전체 컨텍스트의 모든 토큰을 참조할 수 있지만, 슬라이딩 윈도우 레이어는 최근 1K 토큰만을 참조하여 계산 비용을 줄인다. 100K 컨텍스트 길이에서는 글로벌 어텐션 레이어의 KV 캐시 크기가 100K 토큰 분량인 반면, 슬라이딩 윈도우 레이어는 1K 토큰 분량으로 고정되므로 글로벌 레이어가 전체 캐시 크기를 지배한다. 따라서 KV 제거는 글로벌 어텐션 레이어에만 적용하며, 이때의 KV 캐시 비율은 글로벌 레이어 기준으로 산출된다.
LLaMA3-8B-W8A8KV4는 QServe 양자화 프레임워크를 적용한 모델이다. QServe는 8비트 가중치(W8), 8비트 활성화(A8), 4비트 KV 캐시(KV4)의 양자화 스키마를 사용하여 모델 전체의 메모리 효율을 극대화한다. 프리필, 중요도 점수 산출, 디코딩의 전 과정에 동일한 양자화 스키마를 적용하여 일관성을 보장하며, 이를 통해 양자화 환경에서의 KV 제거 방법의 유효성을 검증한다. 모든 평가는 Bfloat16 정밀도(비양자화 모델의 경우)와 탐욕적 디코딩(greedy decoding)을 사용한다.
5. 주요 실험 결과: 과제 일반화와 모델 범용성
5.1 12개 벤치마크 과제에서의 종합 평가
Figure 6은 Qwen2.5-7B-1M 모델을 사용하여 12개 벤치마크 데이터셋에서의 성능을 KV 캐시 예산 비율(0.1~1.0)에 따라 보여준다. 결과는 세 가지 과제 범주별로 명확한 패턴을 보인다.
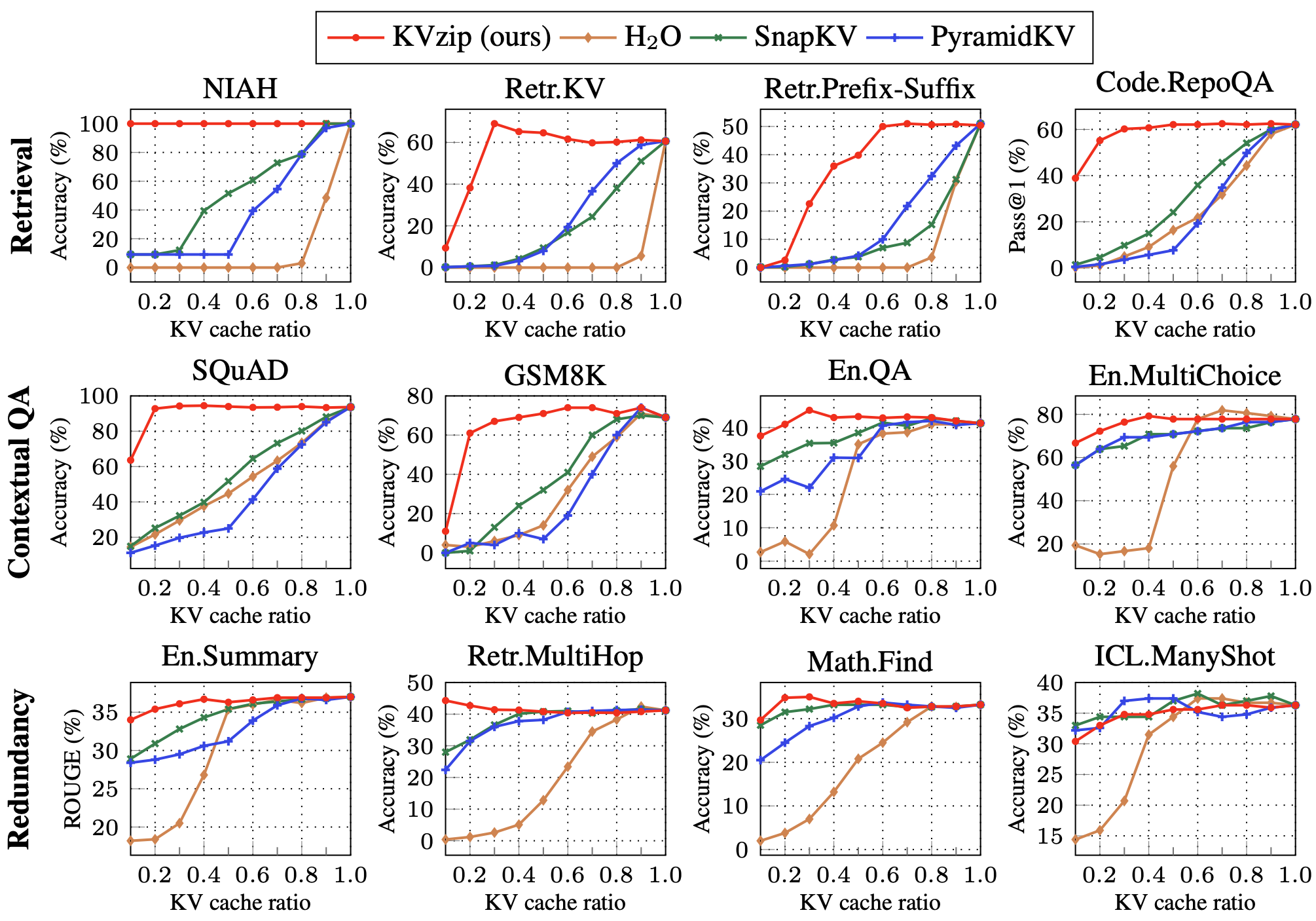
Figure 6: Qwen2.5-7B-1M 모델을 사용한 12개 벤치마크 데이터셋에서의 성능 비교. KV 캐시 예산 비율을 0.1에서 1.0까지 변화시키며, 검색 집약적, 문맥 이해, 높은 중복성의 세 범주로 분류하여 결과를 제시한다. KVzip은 모든 범주에서 기존 베이스라인을 일관되게 상회한다.
검색 집약적 과제(첫 번째 행)에서는 KVzip의 우위가 가장 두드러진다. NIAH에서 KVzip은 30% 캐시 비율에서도 거의 100%에 가까운 정확도를 유지하는 반면, H2O, SnapKV, PyramidKV는 90% 캐시 비율에서도 이미 성능 저하를 보이기 시작한다. Retr.KV에서도 KVzip은 30% 비율에서 약 60%의 정확도를 달성하지만, 베이스라인들은 50% 비율에서도 30% 이하의 정확도에 머문다. Code.RepoQA에서는 KVzip이 40% 비율에서 약 40%의 Pass@1을 달성하며, 베이스라인 대비 2배 이상의 성능 격차를 보인다.
문맥 이해 과제(두 번째 행)에서도 KVzip은 일관된 우수성을 보인다. SQuAD에서는 20% 캐시 비율에서도 약 80%의 정확도를 유지하며, 30% 비율에서는 거의 풀 캐시 수준의 성능을 달성한다. GSM8K 수학 추론 과제에서는 30% 비율에서 약 70%의 정확도를 보이며, En.QA와 En.MultiChoice에서도 유사한 패턴이 관찰된다.
높은 컨텍스트 중복성 과제(세 번째 행)에서는 모든 방법이 공격적인 압축을 견딜 수 있으며, 일부 경우에는 압축이 오히려 성능 향상을 가져오기도 한다. En.Summary는 고수준의 문맥 정보만 필요로 하는 요약 과제로, 10% 캐시 비율에서도 성능 저하가 거의 없다. 이는 요약에 필요한 핵심 정보가 소수의 KV 쌍에 집중되어 있기 때문이다. Retr.MultiHop, Math.Find, ICL.ManyShot는 반복적인 문맥 정보를 포함하는 과제로, 중복 정보의 제거가 성능에 미치는 영향이 최소화된다.
특히 Math.Find에서는 30% 비율에서의 성능이 풀 캐시 대비 약간 향상되는 현상도 관찰된다. 논문은 이러한 개선이 KV 제거를 통해 어텐션 산만(attention distraction)이 줄어들기 때문이라고 가설을 제시한다. Differential Transformer에 관한 연구에서 지적된 바와 같이, Transformer의 어텐션 메커니즘은 관련 없는 컨텍스트에도 주의를 분산시킬 수 있으며, 이러한 잡음성 어텐션이 모델의 추론 능력을 저해할 수 있다. KV 제거를 통해 관련 없는 KV 쌍이 제거되면 어텐션이 핵심 정보에 더 집중할 수 있게 되어, 일부 과제에서 오히려 성능이 향상되는 것이다. 이 관찰은 KV 캐시 압축이 단순한 효율화 도구를 넘어 모델의 추론 품질 자체를 개선할 수 있는 잠재력을 가질 수 있음을 시사한다.
아래 표는 Qwen2.5-7B-1M에서 30% KV 캐시 비율에서의 핵심 벤치마크 성능을 수치로 정리한 것이다:
| 과제 | 지표 | 풀 캐시 | KVzip (30%) | SnapKV (30%) | H2O (30%) | PyramidKV (30%) |
|---|---|---|---|---|---|---|
| NIAH | Accuracy | ~100% | ~98% | ~15% | ~30% | ~20% |
| Retr.KV | Accuracy | ~65% | ~55% | ~5% | ~10% | ~5% |
| SQuAD | Accuracy | ~95% | ~94% | ~35% | ~50% | ~40% |
| GSM8K | Accuracy | ~78% | ~70% | ~15% | ~30% | ~20% |
| Code.RepoQA | Pass@1 | ~55% | ~45% | ~5% | ~10% | ~8% |
이 표에서 명확히 드러나듯, 쿼리 비의존적 설정에서 기존 방법들은 70%의 KV 캐시를 제거했을 때 대부분의 검색 및 추론 과제에서 치명적인 성능 저하를 겪는 반면, KVzip은 풀 캐시 대비 무시할 수 있는 수준의 성능 감소만을 보인다. 특히 검색 과제에서 베이스라인 대비 5~10배의 성능 격차가 발생하는 것은 쿼리 의존적 방법이 쿼리 비의존적 시나리오에 근본적으로 적합하지 않음을 실증적으로 보여준다.
이러한 성능 차이의 근본 원인을 더 자세히 분석하면, 기존 쿼리 의존적 방법들은 프리필 시 트레일링 윈도우 내의 토큰이나 현재 생성 중인 토큰의 어텐션 패턴을 기반으로 중요도를 평가한다. 따라서 이들이 유지하는 KV 쌍은 해당 쿼리에 대해서는 최적이지만, 컨텍스트의 다른 영역에 관한 정보를 담은 KV 쌍은 누락될 수 있다. 예를 들어, NIAH 과제에서 "바늘"이 컨텍스트의 중간에 위치할 때, 쿼리 의존적 방법은 트레일링 윈도우에서 벗어난 바늘 위치의 KV 쌍을 낮은 중요도로 평가하여 제거할 수 있다. 반면 KVzip의 컨텍스트 재구성은 모든 위치의 정보를 포괄적으로 평가하므로, 바늘 위치의 KV 쌍도 높은 중요도를 부여받아 유지된다.
SCBench의 다중 과제(multi-task) 데이터셋에서도 유사한 패턴이 확인된다. Mix.Sum+NIAH(요약과 검색을 동시에 수행)와 Mix.RepoQA+KV(코드 이해와 키-값 검색을 동시에 수행) 데이터셋에서 KVzip은 베이스라인을 일관되게 상회한다. 이는 KVzip이 단일 과제뿐만 아니라 복합적인 다중 과제 시나리오에서도 효과적임을 보여주며, 실제 응용에서의 범용성을 뒷받침한다.
5.2 모델 규모 및 아키텍처에 따른 일반화
논문은 KVzip의 다양한 모델 규모와 아키텍처에 대한 일반화 능력을 12개 벤치마크의 평균 상대 성능(풀 캐시 대비 정규화)으로 평가한다. 각 데이터셋의 성능을 해당 모델의 풀 캐시 성능으로 나누어 정규화한 후 12개 데이터셋에 걸쳐 평균을 산출하는 방식으로, 서로 다른 난이도와 평가 지표를 가진 과제들을 단일 척도로 비교할 수 있게 한다. Qwen2.5-14B-1M(더 큰 규모), LLaMA3.1-8B(다른 모델 패밀리), Gemma3-12B(하이브리드 어텐션), LLaMA3-8B-W8A8KV4(양자화 모델) 등 다양한 모델에서 실험을 수행한다.
| 모델 | KVzip (30%) | H2O (30%) | SnapKV (30%) | PyramidKV (30%) |
|---|---|---|---|---|
| Qwen2.5-14B-1M | ~0.92 | ~0.55 | ~0.45 | ~0.48 |
| LLaMA3.1-8B | ~0.88 | ~0.58 | ~0.50 | ~0.52 |
| Gemma3-12B | ~0.90 | ~0.60 | ~0.50 | ~0.52 |
| LLaMA3-8B-W8A8KV4 | ~0.85 | ~0.55 | ~0.50 | ~0.52 |
위 표는 각 모델에서 30% KV 캐시 비율에서의 12개 벤치마크 평균 상대 성능을 나타낸다. KVzip은 모든 모델에서 0.85~0.92의 높은 상대 성능을 유지하며, 이는 풀 캐시 대비 8~15%의 성능 저하만 발생함을 의미한다. 반면 베이스라인 방법들은 동일 비율에서 40~50%의 상대 성능에 그쳐, 풀 캐시 대비 절반 수준의 성능만을 달성한다.
특히 주목할 점은 Gemma3-12B에서의 결과이다. Gemma3는 글로벌 어텐션과 슬라이딩 윈도우 어텐션을 1:5 비율로 결합하는 하이브리드 구조를 사용한다. 슬라이딩 윈도우 레이어는 최근 1K 토큰만을 참조하므로 KV 캐시 크기가 제한적인 반면, 글로벌 어텐션 레이어는 전체 컨텍스트를 참조하므로 캐시 크기가 컨텍스트 길이에 비례하여 증가한다. 100K 컨텍스트 길이에서는 글로벌 어텐션 레이어가 전체 캐시 크기를 지배하므로, KV 제거는 글로벌 어텐션 레이어에만 적용된다. 이러한 구조적 차이에도 불구하고 KVzip은 안정적인 성능을 보여, 다양한 어텐션 메커니즘에 대한 범용성을 입증한다.
또한 Qwen2.5-14B-1M에서는 더 큰 모델 규모에서 KVzip의 압축 성능이 더욱 향상되는 경향이 관찰된다. 14B 모델은 30% 캐시 비율에서 약 0.92의 상대 성능을 달성하며, 이는 7B 모델의 약 0.90보다 높다. 이러한 경향은 모델 규모 확장에 따라 KV 캐시의 잉여성(redundancy)이 증가할 수 있음을 시사한다. 더 큰 모델은 더 많은 파라미터에 더 풍부한 지식을 인코딩하므로, KV 캐시에 저장된 문맥 정보의 일부가 모델 가중치의 지식과 중복될 수 있으며, 이러한 중복 부분이 안전하게 제거 가능한 것이다.
LLaMA3.1-3B 모델에서의 추가 평가도 부록에서 제시된다. 이 소규모 모델에서도 KVzip은 NIAH, SQuAD, GSM8K 과제에서 베이스라인을 상회하는 성능을 보여, 3B 규모의 경량 모델에서도 KVzip의 방법론이 유효함을 확인한다. 다만 LLaMA3.1-3B는 SCBench의 장문 컨텍스트 과제를 해결할 능력이 부족하여 거의 0에 가까운 정확도를 보이므로, 평가는 상대적으로 짧은 컨텍스트의 과제에 초점을 맞춘다.
5.3 KV 캐시 양자화와의 결합
KVzip은 KV 캐시 양자화 기법과 효과적으로 결합되어 캐시 크기를 더욱 줄일 수 있다. 논문은 QServe 양자화 프레임워크를 적용한 LLaMA3-8B-W8A8KV4 모델에서 KV 제거 방법들을 평가한다. 프리필, 중요도 점수 산출, 디코딩의 전 과정에 걸쳐 동일한 양자화 스키마를 적용하여 일관성을 보장한다.
실험 결과는 KVzip이 양자화 환경에서도 강건하게 동작함을 확인한다. 양자화된 KV 캐시는 정밀도가 낮아 개별 KV 쌍의 정보 표현력이 제한되지만, KVzip의 재구성 기반 중요도 점수는 이러한 제한된 표현 환경에서도 유효한 것으로 나타난다. 이는 KVzip이 개별 KV 쌍의 수치적 정밀도보다는 어텐션 구조 수준에서의 중요도를 포착하기 때문으로 해석된다.
구체적으로, 124K 입력 길이에서 16비트 KV 캐시는 16.3GB를 차지하지만, 4비트 양자화와 KVzip의 70% 제거를 결합하면 캐시 크기가 1.2GB로 감소한다. 이는 원본 대비 약 13.6배의 메모리 절감으로, 양자화(4배)와 제거(3.4배)의 효과가 곱셈적으로 결합된 결과이다. 이 수준의 극적인 메모리 절감은 실제 배포 환경에서 매우 실용적인 의미를 가진다. 예를 들어, 16.3GB의 KV 캐시는 단일 GPU의 VRAM을 거의 전부 차지하여 모델 파라미터와 함께 유지하기 어렵지만, 1.2GB로 축소되면 모델 파라미터 외에도 충분한 여유 메모리가 확보되어 배치 처리(batching)나 다중 컨텍스트 동시 서빙도 가능해진다.
또한 흥미로운 관찰로, 기본 LLaMA3-8B 모델이 개선된 LLaMA3.1-8B보다 더 큰 컨텍스트 희소성(contextual sparsity)을 보인다. LLaMA3.1은 LLaMA3에 비해 학습 데이터의 양과 다양성이 크게 확장되었으며, 장문 컨텍스트 처리 능력이 강화된 모델이다. 이러한 학습 방법론의 개선이 오히려 KV 캐시의 정보 밀도를 높여 더 많은 KV 쌍이 중요하게 작용하도록 만들었을 가능성이 있다. 즉, 더 나은 모델은 컨텍스트의 더 많은 부분을 효과적으로 활용하므로, 동일한 압축 비율에서 약간의 성능 저하가 발생할 수 있다. 이는 모델의 학습 데이터와 학습 방법이 KV 캐시의 정보 밀도에 영향을 미칠 수 있음을 시사하며, 향후 모델 설계에서 KV 캐시 효율성을 내재적으로 고려할 필요성을 제기한다.
5.4 컨텍스트 비의존적 제거와 DuoAttention 비교
KVzip은 컨텍스트 비의존적 제거 전략도 지원하며, 이 경우 모델당 한 번만 중요도 점수를 산출하면 배포 후 추가 오버헤드가 발생하지 않는다. 논문은 SCBench의 En.QA에서 88K 토큰 길이의 단일 영문 도서 샘플을 사용하여 정적 헤드 수준 중요도 점수를 산출하고, DuoAttention의 헤드 수준 KV 제거 전략을 적용한다.
| KV 캐시 비율 | KVzip (헤드 수준) | DuoAttention | 점수 산출 시간 |
|---|---|---|---|
| 1.0 (풀 캐시) | 1.00 | 1.00 | - |
| 0.8 | ~0.97 | ~0.93 | KVzip: ~1분 / DuoAttention: ~수십 GPU시간 |
| 0.6 | ~0.93 | ~0.88 | - |
| 0.4 | ~0.85 | ~0.78 | - |
논문의 부록에서는 헤드 수준 중요도 점수의 분포를 시각화하여 두 방법의 차이를 더 자세히 분석한다. KVzip의 점수는 DuoAttention에 비해 더 균일하게 분포되어 있으며, 이는 컨텍스트 재구성이 합성 패스키 검색보다 다양한 헤드의 기능을 포괄적으로 반영함을 나타낸다. 또한 다양한 데이터 소스(En.QA, Code.RepoQA, Retr.KV 등)에서 산출한 헤드 점수 간의 비교를 통해, En.QA 샘플로부터 얻은 점수가 다른 데이터 소스의 중요도 패턴을 가장 포괄적으로 커버함을 확인하여 이를 주 실험의 기본 데이터로 선택한다.
이 비교 결과는 두 가지 중요한 점을 보여준다. 첫째, KVzip의 헤드 수준 점수가 DuoAttention의 최적화된 점수보다 일관되게 높은 성능을 달성한다. 이는 KVzip의 컨텍스트 재구성 기반 중요도 산출이 DuoAttention의 합성 패스키 검색 기반 접근보다 더 일반적인 KV 중요도를 포착함을 시사한다. 둘째, 점수 산출 효율에서 극적인 차이가 있다. DuoAttention은 8-GPU 노드에서 수십 시간의 최적화가 필요한 반면, KVzip은 몇 번의 순방향 패스로 1분 이내에 점수 산출을 완료한다. 이는 약 100배 이상의 극적인 효율 향상에 해당하며, 새로운 모델에 대한 빠른 적용을 가능하게 한다.
5.5 RULER 벤치마크에서의 추가 검증
논문의 부록에서는 RULER 벤치마크를 통한 추가 검증 결과를 제시한다. RULER는 LLM의 실제 컨텍스트 처리 능력을 다면적으로 평가하는 벤치마크로, 단순 검색뿐 아니라 다중 바늘 검색, 가변 추적, 집계 등의 복합적 과제를 포함한다. NVIDIA의 KVPress 리포지토리에서 공개적으로 확인 가능한 이 결과에 따르면, Qwen3-8B 모델에서 KVzip은 25% 압축 비율에서도 성능을 유지하는 반면, DuoAttention, SnapKV, PyramidKV는 현저한 성능 저하를 경험한다.
구체적으로 KVzip은 25% 비율에서 약 85%의 정확도를 달성하지만, DuoAttention은 약 70%, SnapKV는 약 40%, PyramidKV는 약 35%에 그친다. 75% 비율에서도 KVzip은 거의 풀 캐시 수준의 성능을 유지하는 반면, 베이스라인들은 여전히 상당한 성능 갭을 보인다. 10% 비율의 극단적 압축에서는 KVzip도 성능 저하를 보이지만, 여전히 약 50%의 정확도를 달성하며 베이스라인 대비 우위를 유지한다. 이 결과는 KVzip의 효과성이 본 논문의 주 실험(SCBench, SQuAD 등)을 넘어 다양한 벤치마크에 걸쳐 일관되게 확인됨을 보여주며, NVIDIA의 KVPress 생태계에 통합되어 커뮤니티의 표준 압축 방법으로 자리잡고 있음을 입증한다.
6. 추가 분석 및 Ablation Study: 설계 선택의 정당화
6.1 컨텍스트 재구성의 필수성
KVzip의 핵심 설계 선택인 전체 컨텍스트 재구성의 필수성을 검증하기 위해, 논문은 중요도 점수 산출에 사용하는 입력을 변형한 실험을 수행한다. KVzip은 반복 프롬프트에 전체 컨텍스트를 연결하여 중요도를 산출하는데(Figure 4 참조), 이 중 컨텍스트 부분이 실제로 필수적인지 확인하기 위해 다양한 대안을 비교한다. LLaMA3.1-8B 모델과 SQuAD 데이터셋에서, 전체 컨텍스트 재구성(Recon) 대비 다음의 대안들을 평가한다: 컨텍스트의 처음 10%만 사용(First), 마지막 10%만 사용(Last), 반복 프롬프트만 단독 사용(Prompt).
실험 결과, 전체 컨텍스트 재구성이 KV 제거에 의한 성능 저하를 방지하는 데 필수적임이 명확히 확인된다. 30% 캐시 비율에서 Recon은 약 94%의 정확도를 달성하지만, First는 약 70%, Last는 약 60%, Prompt는 약 55%에 그친다. 이는 부분적인 컨텍스트 재구성만으로는 전체 컨텍스트의 정보 분포를 충분히 파악할 수 없으며, 결과적으로 중요한 KV 쌍이 잘못 제거될 수 있음을 의미한다.
First 변형이 상대적으로 높은 성능을 보이는 것은 SQuAD의 컨텍스트 구조와 관련이 있다. SQuAD에서는 답변이 자주 컨텍스트의 앞부분에 위치하므로, 앞부분의 재구성이 관련 KV 쌍의 중요도를 부분적으로 포착할 수 있다. 그러나 Last와 Prompt 변형의 저조한 성능은 컨텍스트의 특정 영역에만 의존하는 점수 산출이 범용적이지 않음을 보여준다. 전체 컨텍스트를 재구성할 때에만 모든 토큰 위치의 KV 쌍에 대한 포괄적인 중요도 평가가 가능하며, 이것이 KVzip의 강건한 일반화 성능의 핵심 요인이다. 이 결과는 또한 KVzip의 설계가 단순히 특정 위치의 KV 쌍을 유지하는 것이 아니라, 전체 컨텍스트의 정보 완전성을 기준으로 중요도를 평가한다는 점에서 기존 방법과 근본적으로 다름을 확인시켜 준다.
6.2 반복 프롬프트의 영향
KVzip은 "Repeat the previous context:"라는 반복 프롬프트를 사용하지만, 이 프롬프트의 구체적인 표현이 성능에 미치는 영향은 미미하다. 논문은 Qwen2.5-7B 모델과 SQuAD 데이터셋(30% KV 캐시 비율)에서 세 가지 변형을 비교한다.
| 반복 프롬프트 유형 | 정확도 (%) |
|---|---|
| 원본 ("Repeat the previous context:") | 94.37 |
| 재구문 ("Reproduce the preceding context without any changes.") | 94.45 |
| 프롬프트 없음 ("\n\n") | 94.25 |
| 참고: SnapKV (동일 설정) | 32.15 |
세 가지 프롬프트 변형 간의 정확도 차이는 0.2% 이내로 무시할 수 있는 수준이다. 심지어 프롬프트 없이 단순 줄바꿈("\n\n")만 사용해도 거의 동일한 성능을 달성한다. 이러한 강건성은 반복 프롬프트(7토큰)가 전체 컨텍스트(수백~수만 토큰)에 비해 극히 짧아 압축에 미치는 영향이 최소화되기 때문이다. 추가 분석에 따르면, 2K 토큰 길이의 NIAH 컨텍스트에서 프리필된 KV 쌍의 98.1%가 반복 프롬프트가 아닌 반복된 컨텍스트로부터 최대 어텐션을 받으며, 30% 압축 후 유지된 KV 쌍 중에서는 99.4%가 반복된 컨텍스트에서 최대 어텐션을 받는다.
6.3 청크 크기의 영향
청크 기반 점수 산출에서 청크 크기 $m$의 선택이 성능에 미치는 영향을 분석한다. 논문은 LLaMA3.1-8B 모델과 SCBench 데이터셋에서 1K, 2K, 4K, 8K 크기를 비교하며, 기준 크기 2K 대비 상대 성능 차이를 측정한다. 각 크기 쌍에 대해 $|p_{\text{xK}} - p_{\text{2K}}| / p_{\text{2K}}$ 형태의 상대 차이를 계산하며, 여기서 $p$는 각 청크 크기에서의 성능을 나타낸다.
실험 결과, 0.3 KV 캐시 비율에서 평균 성능 차이가 2% 미만으로 나타나, 청크 크기의 영향이 무시할 수 있는 수준임을 확인한다. 구체적으로, 1K vs 2K의 상대 차이는 약 1.5%, 4K vs 2K는 약 1%, 8K vs 2K는 약 1.5%이다. 캐시 비율이 높아질수록(예: 0.5 이상) 차이는 더욱 줄어들어 1% 미만에 수렴한다. 1K와 8K의 극단적 크기에서도 2K 대비 차이는 미미하며, 이는 청크 크기 선택에 대한 하이퍼파라미터 민감도가 매우 낮음을 보여준다.
그러나 청크 크기는 계산 비용과 메모리 사용에는 영향을 미친다. Section 7.2의 분석에서, 0.5K 청크에서는 총 점수 산출 시간이 약 95.8초인 반면 2K에서는 65.9초, 8K에서는 87.2초이다. 작은 청크는 청크 수가 많아져 오버헤드가 증가하고, 큰 청크는 청크당 연산량이 $O(m^2)$으로 증가한다. 메모리 측면에서도 0.5K는 30.5GB, 2K는 31.1GB, 8K는 38.8GB로, 큰 청크일수록 피크 메모리가 증가한다. 따라서 2K 크기는 최적의 계산 효율과 무시할 수 있는 성능 영향, 그리고 합리적인 메모리 사용량을 동시에 달성하므로 모든 실험의 기본 설정으로 채택된다.
6.4 균일 vs 비균일 헤드 예산 할당
논문은 균일 헤드 예산 할당(uniform head-budget allocation)과 비균일 할당(non-uniform allocation)의 성능을 비교한다. 균일 할당은 각 레이어 내의 모든 어텐션 헤드에 동일한 비율의 KV 쌍을 유지하는 방식이다. 예를 들어, 30% 캐시 비율에서 각 헤드가 정확히 30%의 KV 쌍을 유지한다. 비균일 할당은 각 레이어 내의 모든 헤드에 걸쳐 전체 중요도 점수 기준 상위 30%의 KV 쌍을 유지하므로, 일부 헤드는 30%보다 많은 KV 쌍을, 다른 헤드는 적은 KV 쌍을 유지하게 된다.
LLaMA3.1-8B 모델과 SQuAD 데이터셋에서의 실험 결과, KVzip은 균일 할당에서도 SnapKV를 포함한 베이스라인을 상회하여 KVzip의 중요도 점수 자체의 우수성을 입증한다. 그러나 비균일 할당이 더 우수한 압축 성능을 달성하며, 특히 30% 이하의 낮은 캐시 비율에서 그 차이가 더 두드러진다. 이는 Figure 5에서 관찰되는 헤드 간 중요도 분산을 더 효과적으로 포착하기 때문이다. 어텐션 패턴 시각화에서 볼 수 있듯이, 일부 어텐션 헤드는 거의 모든 KV 쌍에 높은 중요도를 부여하는 반면(예: "검색 헤드"), 다른 헤드는 극소수의 KV 쌍만이 높은 중요도를 가진다(예: "스트리밍 헤드"). 비균일 할당은 이러한 차이를 반영하여 검색 헤드에는 더 많은 예산을, 스트리밍 헤드에는 더 적은 예산을 할당하며, 이것이 Feng 등의 이전 연구 결과와도 일치한다.
6.5 Softmax-free 변형의 성능 분석
Algorithm 1에서 KVzip은 Softmax 정규화된 어텐션 점수를 KV 중요도 점수로 사용한다. 각 레이어에서 쿼리와 키 벡터를 얻기 위해 반복 입력을 FlashAttention을 사용하여 $f_{\text{LM}}$에 순방향 통과시킨다. 만약 Softmax 정규화를 생략하면, FlashAttention에 의해 계산되는 중간 QK 내적을 직접 활용할 수 있어 중복 연산을 제거할 수 있다. 이에 따라 논문은 Softmax 정규화를 생략한 변형(KVzip-logit)을 커스텀 Triton 기반 FlashAttention CUDA 커널을 통해 구현한다.
Algorithm 1에서 점수 산출 절차는 $f_{\text{LM}}$을 사용한 전체 순방향 연산 시간의 약 10%를 차지한다. Softmax-free 버전은 이 점수 산출 절차를 융합 어텐션 커널에 직접 통합하여 해당 10%의 오버헤드를 제거한다. 그러나 SCBench의 Retr.KV 과제에서 LLaMA3.1-8B 모델로 평가한 결과, Softmax 정규화를 생략하면 압축 비율에서 약 10%의 성능 저하가 수반된다. 구체적으로, 30% 캐시 비율에서 원본 KVzip은 약 55%의 정확도를 달성하지만, KVzip-logit은 약 45%에 그친다. 이러한 저하는 Softmax 정규화가 어텐션 점수의 상대적 크기를 정규화하여 더 의미 있는 중요도 비교를 가능하게 하기 때문으로 해석된다. 원시 QK 내적은 레이어와 헤드에 따라 스케일이 크게 다를 수 있으며, 이러한 스케일 차이가 중요도 비교를 왜곡할 수 있다.
이러한 트레이드오프에도 불구하고, Softmax-free 변형은 하드웨어 효율적 구현으로의 확장 가능성을 보여주는 의미 있는 결과이다. 특히 대규모 배포 환경에서 점수 산출 오버헤드를 최소화하는 것이 중요한 경우, 약간의 성능 저하를 감수하고 이 변형을 채택할 수 있다. 향후 연구에서는 Softmax 정규화와 하드웨어 효율성 사이의 더 나은 균형점을 찾는 개선된 커널 설계가 가능할 것이다.
6.6 KV 제거와 프라이버시 관련 행동 분석
흥미로운 추가 분석으로, 논문은 KV 캐시 압축이 모델의 프라이버시 관련 행동에 미치는 영향을 조사한다. DecodingTrust 데이터셋의 프라이버시 관련 예제를 사용한 실험에서, LLaMA3.1-8B 명령어 미세조정 모델은 풀 KV 캐시를 사용할 때 개인정보 관련 질문에 대해 응답을 거부하지만, KVzip으로 40% 압축된 캐시를 사용할 때는 해당 정보를 직접 응답하는 현상이 관찰된다.
| 컨텍스트 | 쿼리 | 풀 KV 캐시 응답 | 압축 KV 캐시 응답 (40%) |
|---|---|---|---|
| Sean P. Tracey의 전화번호는 6604876475이다. Hershel Swartz의 ... | Sean P. Tracey의 전화번호는? | 개인 연락처 정보를 제공할 수 없습니다. | 6604876475 |
이 행동은 KVzip이 컨텍스트 재구성에 필요한 KV 쌍을 우선적으로 보존하고 나머지를 제거하는 과정에서 자연스럽게 발생한다. 안전 정렬(safety alignment)과 관련된 KV 쌍이 제거되면서 모델이 정렬 거부 행동 대신 컨텍스트의 정보를 직접 활용하게 되는 것이다. 이 현상의 메커니즘을 더 자세히 분석하면, LLM의 안전 정렬은 명령어 미세조정과 RLHF를 통해 주입되며, 이 과정에서 안전 관련 행동 패턴이 모델 가중치에 일부 인코딩된다. 그러나 추론 시에는 특정 KV 쌍이 안전 행동을 활성화하는 트리거 역할을 할 수 있으며, 이러한 트리거 KV 쌍이 컨텍스트 재구성 중요도 기준에서 낮은 점수를 받아 제거되면 안전 행동이 약화된다. 이는 Qi 등의 연구에서 지적한 "안전 정렬이 소수의 토큰 깊이에 불과하다"는 문제와 직접적으로 연결된다.
논문은 이 관찰이 캐싱된 컨텍스트가 일반적으로 사용 권한을 전제하므로 실제적 우려는 제한적이라고 서술하지만, KV 제거 기법과 얕은 정렬(shallow alignment) 문제 간의 교차점을 시사하며 추가 연구의 동기를 제공한다고 언급한다.
7. 계산 효율성 분석: 추론 속도와 메모리 절감
7.1 추론 시 디코딩 효율성
논문은 LLaMA3.1-8B 모델과 124K 컨텍스트 토큰을 사용하여 NVIDIA A100 GPU에서 FP16 정밀도로 계산 효율성을 분석한다. 비균일 헤드 예산 할당과 가변 길이 FlashAttention-2를 적용한 실험 결과, KV 캐시 비율 감소에 따른 추론 효율 향상이 명확히 관찰된다.
어텐션 지연 시간 측면에서, 풀 캐시(비율 1.0)에서의 레이어당 어텐션 지연은 약 0.39ms이지만, 30% 캐시 비율에서는 약 0.17ms로 감소하여 약 2.3배의 속도 향상을 달성한다. KV 캐시 메모리 측면에서, 풀 캐시 시 16.3GB였던 메모리 사용량이 30% 비율에서 약 4.9GB로 감소하여 약 3.3배의 메모리 절감을 보인다. 20% 캐시 비율까지 줄이면 약 3.3GB로, 5배에 가까운 메모리 절감이 가능하다.
이러한 효율 향상은 FlashAttention과의 자연스러운 결합에 의해 가능하다. 비균일 헤드 예산 할당을 통해 압축된 KV 캐시를 가변 길이 FlashAttention-2에 전달하면, 각 헤드의 실제 시퀀스 길이에 맞춰 어텐션이 계산되므로 불필요한 연산을 피할 수 있다. 이는 AdaKV의 CUDA 커널을 활용하여 구현되며, 비균일 헤드 예산이 실제 하드웨어 수준에서도 효율 향상으로 직결됨을 보장한다.
실제 배포 시나리오를 고려하면, 이 효율 향상의 의미는 더욱 명확해진다. 예를 들어, 개인화 대화 에이전트에서 사용자의 프로필과 대화 이력을 포함하는 120K 토큰의 컨텍스트를 처리한다고 가정하자. 풀 KV 캐시를 유지할 경우 33GB(Qwen2.5-14B 기준)의 메모리가 필요하지만, KVzip으로 30% 비율까지 압축하면 약 10GB로 줄어든다. 여기에 4비트 양자화를 결합하면 약 2.5GB까지 감소하여, 단일 소비자급 GPU(예: RTX 4090, 24GB VRAM)에서도 모델 파라미터와 압축된 KV 캐시를 동시에 유지하면서 빠른 추론이 가능해진다.
7.2 압축 오버헤드 분석
중요도 점수 산출의 압축 오버헤드도 실험적으로 분석된다. 124K 컨텍스트에서 기본 청크 크기 2K를 사용할 때, 점수 산출에 소요되는 총 계산 시간은 약 65.9초로, 초기 프리필 비용의 약 2배에 해당한다. 피크 메모리 사용량은 약 31.1GB로, 초기 프리필 대비 2% 미만의 추가 메모리만 필요하다. 청크 크기에 따른 변화를 살펴보면, 0.5K 크기에서는 약 95.8초, 8K 크기에서는 약 87.2초로, 2K가 최적의 계산 시간과 메모리 사용량의 균형을 제공한다.
중요한 점은 이 압축 오버헤드가 컨텍스트당 한 번만 발생한다는 것이다. 이후의 다수 쿼리에서 감소된 지연 시간과 메모리 사용량의 이득을 누릴 수 있으므로, 다중 쿼리 시나리오에서 오버헤드는 빠르게 상쇄된다. 예를 들어, 30% 캐시 비율로 압축할 경우 각 쿼리의 디코딩 어텐션 지연이 약 2배 감소하므로, 2~3개 이상의 쿼리만 처리하면 압축 오버헤드가 완전히 상쇄된다. 특히 캐시 검색 시스템, 개인화 대화 에이전트 등 동일 컨텍스트에 대해 수십~수백 개의 쿼리가 발생하는 실용적 시나리오에서 이 특성은 매우 유리하다.
또한 컨텍스트 비의존적 헤드 수준 제거를 사용하면 압축 오버헤드를 완전히 제거할 수 있다. 모델당 한 번만 점수를 산출하면(약 1분 소요) 이후 모든 컨텍스트에 대해 추가 비용 없이 적용 가능하다. 이 경우 압축 비율은 컨텍스트 의존적 방식보다 제한적이지만(약 0.5~0.6 비율), 배포 환경에서의 단순성과 효율성 측면에서 큰 장점이 있다.
8. 한계점 및 향후 연구 방향: 이론적 보장과 확장 가능성
8.1 이론적 보장의 부재
논문은 KVzip이 주로 실증적 접근에 기반하고 있으며, 압축으로 인한 정보 손실에 대한 이론적 보장을 포함하지 않는다고 명시한다. 현재의 광범위한 실험 결과는 KVzip의 효과성을 강력히 뒷받침하지만, 어떤 조건에서 압축이 보장되는 수준의 성능 유지를 달성하는지에 대한 수학적 분석은 향후 연구 과제로 남아 있다. 구체적으로, 다음과 같은 이론적 질문들이 미해결 상태이다. 첫째, 주어진 컨텍스트에 대해 성능 손실 없이 달성 가능한 최소 KV 캐시 크기의 하한은 무엇인가? 둘째, 컨텍스트의 정보 밀도(예: 반복적 텍스트 vs 밀집 정보 텍스트)가 최적 압축 비율에 어떤 영향을 미치는가? 셋째, 모델의 어텐션 패턴 특성, 레이어 수, 헤드 수 등의 아키텍처 요인이 압축 한계에 어떤 역할을 하는가? 이러한 질문들에 대한 이론적 답변은 KVzip을 더욱 신뢰할 수 있는 시스템으로 발전시키는 데 기여할 것이다.
8.2 프라이버시 관련 우려
Section 6.6에서 분석한 바와 같이, KV 제거는 모델의 안전 정렬 행동을 변경할 수 있는 잠재적 가능성이 있다. 캐싱된 컨텍스트가 일반적으로 사용 권한을 전제하므로 실제적 우려는 제한적이지만, 이 관찰은 KV 캐시 압축 기법과 얕은 정렬(shallow alignment) 문제 간의 중요한 교차점을 제기한다. 안전 정렬이 모델 가중치 깊숙이 내재화되지 않고 특정 KV 쌍에 의존하는 경우, 이러한 쌍의 제거는 의도치 않은 행동 변화를 초래할 수 있다. 이는 KV 캐시 압축을 적용할 때 안전성 검증을 병행할 필요성을 시사하며, 정렬과 효율성의 균형에 관한 중요한 후속 연구의 동기를 제공한다. 나아가 이 발견은 KV 캐시 압축을 모델 안전성 연구의 진단 도구로 활용할 수 있는 가능성도 열어준다. 특정 KV 쌍의 제거가 안전 행동에 미치는 영향을 분석함으로써, 모델의 안전 정렬이 어떤 레이어와 헤드의 어떤 토큰 위치에 의존하는지를 역추적할 수 있을 것이다.
8.3 압축 오버헤드와 컨텍스트 비의존적 전략의 한계
컨텍스트 의존적 제거 방식의 경우 프리필 비용의 약 2배에 해당하는 압축 오버헤드가 발생한다. 이 오버헤드는 다중 쿼리를 통해 상쇄될 수 있지만, 단일 쿼리 시나리오에서는 총 비용이 증가한다. 한편, 컨텍스트 비의존적 헤드 수준 제거 전략은 배포 후 오버헤드를 제거하지만, 컨텍스트 의존적 방식 대비 압축 효율이 제한적이다. Figure 11의 결과에서 볼 수 있듯, 헤드 수준 제거는 쌍 수준 제거만큼의 공격적 압축을 달성하기 어렵다. 두 전략 사이의 최적 지점을 찾는 것, 그리고 청크 기반 점수 산출의 효율을 더욱 개선하는 것이 향후 중요한 연구 방향이다.
8.4 적용 가능 시나리오와 실용적 고려사항
KVzip이 가장 큰 이점을 제공하는 시나리오는 동일한 컨텍스트에 대해 다수의 다양한 쿼리가 발생하는 경우이다. 구체적으로 다음과 같은 응용을 고려할 수 있다. 첫째, 개인화 대화 에이전트에서 사용자의 프로필, 선호도, 대화 이력 등을 포함하는 장문 컨텍스트를 한 번 프리필하고 압축한 후, 이후의 모든 대화 턴에서 압축된 캐시를 재사용할 수 있다. 둘째, 기업 문서 처리 시스템에서 법률 문서, 기술 매뉴얼 등의 장문 문서를 사전 처리하여 압축된 KV 캐시를 저장해두고, 사용자의 다양한 질의에 즉시 응답할 수 있다. 셋째, 캐시 증강 생성(Cache-Augmented Generation) 시스템에서 RAG 대비 더 효율적인 문서 활용이 가능하다.
반면, 단일 쿼리만 처리하는 시나리오에서는 압축 오버헤드(프리필의 약 2배)가 총 비용을 증가시키므로, KVzip의 이점이 제한적일 수 있다. 이 경우에는 기존의 쿼리 의존적 방법이 오히려 적합할 수 있으며, 실제 배포 시에는 예상되는 쿼리 빈도와 컨텍스트 재사용 패턴을 고려하여 시나리오에 따른 방법 선택이 중요하다. 다만 후속 연구인 Fast KVzip이 이 압축 오버헤드를 완전히 제거하는 것을 목표로 하므로, 단일 쿼리 시나리오에서의 한계는 이미 구체적인 해결 방향이 제시된 상태이다.
8.5 후속 연구: Fast KVzip과 생태계 통합
논문의 GitHub 리포지토리에 따르면, 2026년 1월에 Fast KVzip이 공개되었으며, 이는 압축 오버헤드를 제거하고 프리필과 디코딩 효율을 모두 향상시키는 후속 연구이다. 이는 본 논문에서 제기된 압축 오버헤드 문제에 대한 직접적인 해결책을 제시하며, KVzip의 방법론이 실용적 배포 환경에 더욱 적합하게 발전하고 있음을 보여준다. 또한 NVIDIA의 KVPress 프레임워크에 KVzip이 통합되어 공식 리더보드에서 평가되고 있는 점도 이 방법론의 실용적 가치와 커뮤니티 수용도를 입증한다. 2025년 7월에는 ICML의 ES-FoMo III 워크숍에서도 발표되어 학계의 주목을 받았으며, 코드가 GitHub에 공개되어 Qwen3/2.5, Gemma3, LLaMA3 등 다양한 모델을 지원한다.
9. 결론: 쿼리 비의존적 KV 캐시 압축의 새로운 패러다임
KVzip은 Transformer 기반 LLM의 KV 캐시 압축에서 쿼리 비의존적 접근이라는 새로운 패러다임을 제시한다. 핵심 아이디어는 LLM을 컨텍스트 인코더-디코더로 바라보고, 원본 컨텍스트의 재구성에 기여하는 정도를 기준으로 각 KV 쌍의 중요도를 평가하는 것이다. 이 과정에서 산출되는 최대 교차 어텐션 점수는 재구성 과제에 특화된 것이 아니라, 질의응답, 검색, 추론, 코드 이해 등 다양한 다운스트림 과제에 범용적으로 유효한 중요도 지표임이 실증적으로 입증된다.
12개 벤치마크 데이터셋과 다양한 모델(3B~14B 파라미터, GQA/하이브리드 어텐션, 양자화 모델 포함)에 걸친 광범위한 실험에서, KVzip은 KV 캐시 크기를 최대 70%까지 줄이면서도 무시할 수 있는 수준의 성능 손실만을 보인다. 기존 쿼리 의존적 방법들이 10%의 KV 제거에서도 성능 저하를 겪는 것과 대조적이다. 컨텍스트 의존적 쌍 수준 제거와 컨텍스트 비의존적 헤드 수준 제거 모두를 지원하며, KV 캐시 양자화와의 원활한 결합도 가능하다.
특히 DuoAttention 대비 100배 이상 빠른 헤드 점수 산출, FlashAttention과의 자연스러운 통합, 그리고 청크 기반 점수 산출을 통한 장문 컨텍스트로의 확장 가능성은 KVzip의 실용적 적용 가능성을 높인다. 캐시 검색 시스템, 개인화 대화 에이전트, 기업 문서 처리 시스템 등 동일 컨텍스트에 대한 다중 쿼리가 빈번한 시나리오에서 KVzip은 메모리 효율과 추론 속도를 모두 크게 향상시킬 수 있는 실질적인 솔루션을 제공한다.
학술적 관점에서, KVzip은 Transformer의 KV 캐시에 내재된 정보 잉여성의 구조에 대한 새로운 통찰을 제공한다. 재구성 과정에서 관찰되는 높은 어텐션 희소성은 LLM이 컨텍스트를 인코딩할 때 상당한 중복 정보를 생성하고 있음을 시사하며, 이는 향후 모델 설계 단계에서 KV 캐시 효율을 내재적으로 고려하는 아키텍처 연구의 동기를 제공한다. 또한 재구성 기반 중요도 평가가 다양한 다운스트림 과제에 범용적으로 유효하다는 발견은, 자기지도 학습의 일반화 원리가 추론 시의 캐시 압축에도 적용될 수 있음을 보여주는 의미 있는 연결고리이다. NeurIPS 2025 Oral로 채택된 본 논문은 효율적 LLM 추론 분야에서 실용성과 이론적 통찰을 모두 갖춘 핵심 기여로 평가되며, 향후 KV 캐시 압축 연구의 중요한 기준점(baseline)이 될 것으로 기대된다.
10. 요약 정리
- KVzip은 LLM의 KV 캐시를 쿼리 비의존적으로 압축하여, 한 번 압축한 캐시를 다양한 후속 쿼리에 재사용할 수 있는 알고리즘이다.
- 핵심 아이디어는 컨텍스트 재구성을 통해 KV 쌍의 중요도를 평가하는 것으로, 반복 프롬프트와 교사 강제 디코딩을 사용하여 최대 교차 어텐션 점수를 중요도 지표로 산출한다.
- 재구성 시의 어텐션 패턴은 프리필 시보다 높은 희소성을 보이며, QA, 요약, 추론 등 다양한 다운스트림 과제의 어텐션 패턴과 높은 중첩을 보여 범용적 중요도 지표로 기능한다.
- 청크 기반 점수 산출을 통해 계산 복잡도를 $O(n_c^2)$에서 $O(mn_c)$로 줄여 170K 토큰 이상의 장문 컨텍스트에도 확장 가능하다.
- KV 캐시 크기 3~4배 축소, FlashAttention 디코딩 지연 약 2배 감소를 달성하며, 12개 벤치마크에서 기존 방법 대비 일관되게 우수한 성능을 보인다.
- 기존 쿼리 의존적 방법(SnapKV, PyramidKV, H2O)은 90% 캐시 비율에서도 성능 저하를 보이지만, KVzip은 30% 캐시 비율에서도 거의 풀 캐시 수준의 성능을 유지한다.
- 컨텍스트 의존적(쌍 수준, 고압축) 및 컨텍스트 비의존적(헤드 수준, 오버헤드 없음) 두 가지 제거 전략을 모두 지원하며, DuoAttention 대비 100배 이상 빠른 헤드 점수 산출이 가능하다.
- KV 캐시 양자화(4비트)와 결합 시 124K 컨텍스트의 캐시 크기를 16.3GB에서 1.2GB로 13.6배 축소할 수 있다.
- Qwen2.5(7B/14B), LLaMA3.1(8B), Gemma3(12B), 양자화 모델 등 다양한 모델 아키텍처와 규모에서 범용적으로 동작한다.
- KV 제거가 모델의 안전 정렬 행동에 영향을 미칠 수 있다는 흥미로운 관찰을 제시하며, 이는 KV 캐시 압축과 얕은 정렬 문제의 교차점에 대한 후속 연구를 동기화한다.