Unveiling the Potential of Diffusion Large Language Model in Controllable Generation
https://arxiv.org/abs/2507.04504
Zhen Xiong, Yujun Cai, Zhecheng Li, Yiwei Wang | University of Southern California, University of Queensland, UC San Diego, UC Merced | arXiv:2507.04504 | 2025년 7월 | ICLR 2026 게재 확정
1. 서론: 구조화된 출력 생성의 새로운 패러다임을 향하여
대규모 언어 모델(LLM)의 시대에서 제어 가능한 생성(Controllable Generation)은 핵심적인 과제 중 하나로 자리 잡고 있다. 이는 단순한 자연어 텍스트 생성을 넘어서, 안정적인 도구 사용(tool use), 에이전트 간 통신(agentic communication), 그리고 기존 애플리케이션 프로그래밍 인터페이스(API)와의 상호작용을 위한 기반을 제공한다. 특히 JSON, XML, 코드 등의 구조화된 출력(Structured Output)을 안정적으로 생성하는 능력은 현대 AI 시스템의 실용적 배포에 있어 필수적인 요건이 되었다. 함수 호출(function calling)부터 에이전트 파이프라인의 중간 출력까지, 구조화된 형식의 신뢰성 있는 생성은 전체 시스템의 안정성을 좌우하는 결정적 요소라 할 수 있다.
그러나 논문은 최신의 자기회귀(Autoregressive, AR) 기반 대규모 언어 모델조차도 구조화된 출력을 생성할 때 불안정한 성능을 보인다는 점을 지적한다. 기존의 접근법들은 문법 기반 유한 상태 오토마타(FSA)와 제약 디코딩을 결합하거나, 정교한 프롬프트 엔지니어링 휴리스틱에 의존하는 방식으로 이 문제를 해결하려 시도해 왔다. 하지만 이러한 방법들은 모두 자기회귀 모델의 내재적 능력에만 의존하며, 생성 궤적을 안내하는 추가적인 메커니즘이 부재하다는 근본적인 한계를 공유하고 있다.
이러한 배경에서 본 논문은 디퓨전 기반 대규모 언어 모델(diffusion-based Large Language Model, dLLM)이라는 새로운 패러다임에 주목한다. dLLM의 아키텍처적 차이점, 특히 전역 정보 공유 메커니즘(global information-sharing mechanism)이 차세대 제어 가능한 생성을 실현하는 열쇠가 될 수 있다는 통찰을 제시한다. 이를 구체화하기 위해 논문은 Self-adaptive Schema Scaffolding($S^3$)이라는 새로운 프레임워크를 제안한다. $S^3$는 dLLM의 내재된 역방향 추론 능력과 전역 문맥 인식을 활용하여, 학습 없이(training-free) JSON과 같은 신뢰할 수 있는 구조화된 출력을 안정적으로 생성할 수 있게 한다. 이 방법은 복잡한 프롬프트 최적화 대신 출력 컨텍스트에 직접 스키마 템플릿을 초기 상태로 삽입함으로써, 보다 강건하고 일반적인 접근법을 제공한다.
더 나아가, 본 논문의 문제 의식은 현재의 LLM 생태계에서 점점 더 중요해지고 있는 구조화된 출력의 신뢰성 문제와 직결된다. 최근 에이전트 프레임워크(LangChain, AutoGen 등)에서 LLM의 출력을 파싱하여 다음 행동을 결정하는 파이프라인이 보편화되면서, 구조적으로 유효하지 않은 출력이 전체 시스템의 실패를 야기하는 사례가 빈번히 보고되고 있다. JSON 파싱 오류, 필수 필드 누락, 데이터 타입 불일치 등은 에이전트의 도구 호출 실패로 이어지며, 이를 재시도하는 과정에서 추가적인 계산 비용과 지연이 발생한다. 본 논문이 제시하는 dLLM 기반 접근법은 이러한 구조적 신뢰성 문제에 대한 근본적으로 다른 해결 방향을 탐색한다는 점에서, 자기회귀 모델의 기존 방법들(JSON mode, constrained decoding 등)에 대한 보완적 대안으로서의 가치를 지닌다.
논문의 주요 기여는 세 가지로 요약된다. 첫째, 제어 가능한 생성을 위한 dLLM과 AR 모델의 아키텍처적 장점을 분석하여, dLLM의 전역 어텐션 메커니즘과 반복적 정제 능력에 초점을 맞춘다. 둘째, 학습이 필요 없으면서도 더 적은 디노이징 단계로 높은 구조적 출력 성능을 달성하는 $S^3$ 방법을 제안한다. 셋째, 구조적 준수(Structural Adherence), 콘텐츠 충실도(Content Fidelity), 사실 충실도(Faithfulness)의 세 차원으로 구성된 포괄적인 구조화된 출력 평가 프레임워크를 확립한다.
2. 배경 및 관련 연구: 자기회귀 모델의 한계와 디퓨전 언어 모델의 부상
2.1 구조화된 출력(Structured Output) 문제의 본질
구조화된 출력이란 모델이 사전 정의된 형식(코드, JSON, XML, 테이블 등)으로 텍스트를 생성하는 것을 의미하며, 개체 추출(entity extraction), 분류(classification), 상관관계 예측(correlation prediction) 등의 다양한 태스크를 지원한다. 이 문제의 핵심적 어려움은 모델이 의미적으로 올바른 내용을 생성하는 동시에, 엄격한 구조적 제약 조건을 만족시켜야 한다는 이중적 요구사항에 있다. 단순히 "그럴듯한" 텍스트를 생성하는 것을 넘어, 괄호의 정확한 쌍 맞춤, 필수 필드의 완전한 포함, 올바른 데이터 타입 준수 등 형식적 정확성이 동시에 보장되어야 한다.
기존의 접근법들은 크게 두 가지 방향으로 전개되어 왔다. 첫 번째는 문법 제약 디코딩(Grammar-Constrained Decoding) 방식으로, 문맥 자유 문법이나 타입 시스템에 기반하여 다음 토큰 확률을 조정함으로써 태스크별 미세 조정 없이 구조적 준수를 강제하는 방법이다. 두 번째는 계획 기반 또는 2단계 전략으로, 먼저 추상 구문 트리와 같은 중간 구조를 예측한 후 최종 출력을 실현하는 방식이다. 그러나 이들 접근법 대부분은 자기회귀 LLM에 의존하며, 디퓨전 기반 모델에 대한 탐색은 아직 초기 단계에 머물러 있다는 점을 논문은 지적한다.
2.2 자기회귀 대규모 언어 모델의 구조적 한계
자기회귀 LLM은 더 긴 문맥 창(context window), 멀티모달 통합, 테스트 타임 스케일링 등의 발전에 힘입어 NLP 전반에 걸친 범용적 해결책으로 자리 잡았다. MMLU, WebArena, AIME 등의 벤치마크에서 최첨단 성능을 달성하고 있지만, 환각(hallucination)과 제어 가능성(controllability)이라는 지속적인 과제에 직면해 있다. 논문은 자기회귀 모델이 구조화된 출력에서 근본적인 한계를 가지는 세 가지 아키텍처적 제약을 분석한다.
- 좌에서 우로의 순차 생성(Left-to-Right Generation): 초기 토큰이 전체 시퀀스에 대한 완전한 지식 없이 생성되므로, 전역적 구조 일관성을 확보하기 어렵다. 예를 들어 JSON의 닫는 괄호가 필요한지 여부를 열린 괄호를 생성하는 시점에 정확히 계획하기 어렵다.
- 이전 토큰에 대한 비가역적 커밋(Commitment to Previous Tokens): 이미 생성된 토큰을 수정할 수 없기 때문에, 구조적 위반이 발생했을 때 역추적(backtracking)이 제한적이다. 한번 잘못된 경로로 진입하면 이를 되돌릴 수 있는 메커니즘이 부재하다.
- 순차적 의존성으로 인한 병렬 제약 만족 불가(Sequential Dependencies): 여러 제약 조건을 동시에 만족시키는 것이 어렵다. 서로 떨어진 위치에 있는 토큰들이 상호 의존적인 구조적 관계를 가질 때, 이를 순차적 생성으로 올바르게 처리하는 것은 본질적으로 난제이다.
효과적인 구조화된 생성을 위해서는 전역 시퀀스 계획(global sequence planning), 반복적 정제(iterative refinement), 병렬 제약 만족(parallel constraint satisfaction)이 필요한데, 이는 자기회귀 아키텍처가 본질적으로 부족한 능력이라고 논문은 주장한다. 이 분석은 특히 최근의 LLM 에이전트 생태계에서 구조화된 출력의 중요성이 급증하고 있는 현 시점에서 매우 시의적절하다. OpenAI의 GPT-4o나 Anthropic의 Claude 등이 JSON mode를 지원하지만, 이는 본질적으로 프롬프트 레벨의 제약에 의존하며 구조적 보장을 완전히 제공하지는 못한다. dLLM 기반의 접근법은 이 문제에 대한 아키텍처 레벨의 해결책을 제시한다는 점에서 차별화된다.
2.3 디퓨전 기반 언어 모델의 등장과 가능성
디퓨전 모델은 원래 DDPM(Denoising Diffusion Probabilistic Models) 등의 프레임워크를 통해 연속적인 이미지 생성을 위해 개발되었으나, Austin et al. (2021)의 D3PM(Structured Denoising Diffusion Models in Discrete State-Spaces) 등을 시작으로 최근 이산 텍스트 영역으로 확장되어 자기회귀 생성의 대안으로 부상하고 있다. 이산 스코어 기반 프로세스, 정제된 노이즈 스케줄, 더 빠른 샘플링 방법 등의 연구가 효율성과 출력 품질 개선을 위해 진행되어 왔다. 이러한 발전을 기반으로 LLaDA(Large Language Diffusion with mAsking), LLaDA 1.5(분산 감소 선호도 최적화 적용 버전), Dream 7B 등의 대규모 디퓨전 언어 모델이 등장하여 강력한 명령 따르기(instruction following) 능력을 보여주고 있다. 특히 Mercury는 디퓨전 기반의 초고속 언어 모델로, 추론 속도에서 경쟁력 있는 성능을 보여주고 있다.
그러나 현재의 오픈소스 명령 조정(instruction-tuned) dLLM들은 여전히 잘 구조화된 출력을 생성하지 못하며, 환각된 콘텐츠를 생성하거나 구조적 제약을 깨뜨리는 문제를 보인다. 또한 추론 속도도 여전히 제한적이다. 논문의 분석에 따르면, 기존의 반자기회귀(semi-autoregressive) 방식 등의 구현이 dLLM의 전역 인식 및 병렬 생성 장점을 체계적으로 약화시키고 있다고 지적한다. 이러한 한계를 극복하고 dLLM의 잠재력을 온전히 발휘하기 위해, 논문은 구조화된 출력이라는 설정에서 디퓨전 모델이 자신의 아키텍처를 더 잘 활용할 수 있다고 보고, 생성을 가속화하는 추론 파이프라인을 제안한다.
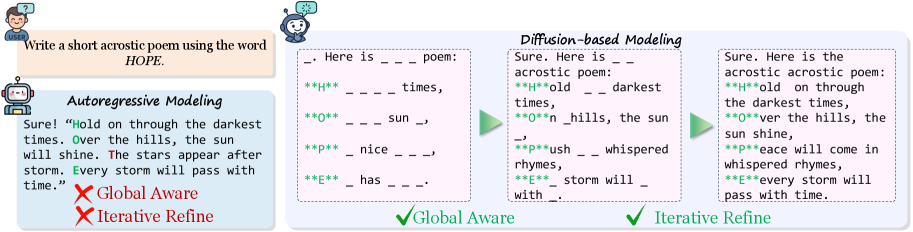
Figure 1: 자기회귀 모델과 디퓨전 기반 언어 모델의 비교. 'HOPE'라는 단어를 사용한 두운시(acrostic poem) 작성 태스크에서, 자기회귀 모델은 좌에서 우로 순차 생성하며 전역 구조 제약을 위반하는 반면(P 줄이 T로 시작), 디퓨전 모델은 구조적 제약(H, O, P, E 위치)을 초기 상태에서부터 고정하고 점진적으로 내용을 채워나가 올바른 결과를 생성한다.
구체적으로, dLLM이 자기회귀 모델 대비 구조화된 출력에서 잠재적 우위를 가지는 이유를 더 자세히 분석해 보면, 이는 크게 세 가지 측면에서 설명된다. 첫째, dLLM의 전역 문맥 인식은 출력 시퀀스의 모든 위치를 동시에 고려할 수 있어, 구조적 일관성을 자연스럽게 유지한다. JSON의 열린 중괄호와 닫힌 중괄호, 배열의 시작과 끝, 필드 간의 쉼표 배치 등은 시퀀스의 서로 다른 위치에 있는 토큰들 간의 장거리 의존성을 요구하는데, dLLM은 이를 한 번의 어텐션 연산으로 처리할 수 있다. 둘째, 반복적 정제는 첫 번째 예측이 완벽하지 않더라도 후속 디노이징 단계에서 수정할 기회를 제공한다. 자기회귀 모델이 한 번 생성한 토큰을 되돌릴 수 없는 것과 달리, dLLM은 낮은 신뢰도의 토큰을 리마스킹하고 재예측하는 "자기 수정" 메커니즘을 내재적으로 지원한다. 셋째, 병렬 토큰 생성은 구조적으로 독립적인 필드들(예: "이름"과 "국적")을 동시에 생성할 수 있게 하여, 순차적 생성에서 발생할 수 있는 오류 전파를 방지한다.
Figure 1은 이 차이를 직관적으로 보여준다. 자기회귀 모델은 좌에서 우로 순차적으로 토큰을 생성하면서, 전역적 구조 제약(각 행의 첫 글자가 H-O-P-E여야 함)을 충족하지 못하는 출력을 만들어낸다. 이에 반해 디퓨전 기반 모델은 세 단계의 점진적 디노이징을 거치면서, 구조적 제약 글자를 처음부터 올바른 위치에 배치하고 나머지 내용을 반복적으로 채워 넣는다. 이는 dLLM이 전역 인식(Global Awareness)과 반복적 정제(Iterative Refinement)를 본질적으로 지원한다는 점을 시각적으로 증명하며, 구조화된 출력 생성에 있어 자기회귀 모델 대비 근본적인 이점을 가질 수 있음을 시사한다.
2.4 자기회귀 모델과 디퓨전 모델의 구조적 출력 접근법 비교
논문의 관련 연구 분석을 기반으로, 자기회귀 모델과 디퓨전 모델이 구조화된 출력 생성에 접근하는 방식의 근본적 차이를 정리하면 다음과 같다. 자기회귀 모델에서는 constrained decoding 방식이 주류를 이루고 있다. 이 접근법은 각 디코딩 단계에서 문법에 맞지 않는 토큰의 확률을 0으로 설정하여, 생성 과정 중 구조적 제약을 실시간으로 강제한다. 대표적으로 Koo et al. (2024)의 오토마타 기반 제약이나 Geng et al. (2023)의 문법 제약 디코딩이 이에 해당한다. 그러나 이 방법은 문법 규칙을 만족하는 토큰이 없을 때 모든 빔이 가지치기되어 생성이 중단되는 문제가 발생할 수 있다.
반면, 디퓨전 모델에서는 완전히 다른 패러다임이 가능하다. 전체 출력 시퀀스를 한 번에 "보면서" 디노이징하는 dLLM의 특성상, 구조적 제약을 사후 수정(post-hoc correction)이 아닌 사전 조건(pre-condition)으로 설정할 수 있다. 즉, 구조적 토큰을 디노이징의 시작점에 미리 배치하고, 모델이 나머지 내용만 채우는 방식이다. 이는 constrained decoding의 "필터링" 접근법과 대비되는 "가이딩" 접근법으로, 모델의 자연스러운 생성 분포를 덜 왜곡시킬 가능성이 있다.
또한 Wang et al. (2025)이 제안한 SLOT 방법은 자기회귀 모델에서 2단계 전략(먼저 구조를 예측하고, 그 다음 내용을 채우는 방식)을 사용하는데, 이는 개념적으로 본 논문의 스캐폴딩 접근법과 유사한 동기를 공유한다. 다만 SLOT은 자기회귀 모델의 순차적 한계 안에서 작동하므로, 두 단계 간의 정보 전달에서 손실이 발생할 수 있다. 반면 $S^3$는 dLLM의 전역 어텐션을 통해 구조와 내용을 동시에 처리할 수 있어, 이론적으로 더 강력한 구조-내용 일관성을 확보할 수 있다.
3. 예비 지식: 자기회귀 vs 디퓨전 언어 모델링의 수학적 기초
3.1 자기회귀 언어 모델링
자기회귀 대규모 언어 모델은 다음 토큰을 예측하는 방식으로 텍스트를 생성한다. 추론 시, 명령 조정된 모델은 쿼리 $Q$에 대한 응답 $A$를 다음의 조건부 분포로부터 샘플링하여 생성한다.
$$\log P_\theta(A|Q) = \sum_{t=1}^{|A|} \log P_\theta(a_t | a_{<t}, Q)$$
여기서 $A = (a_1, \ldots, a_{|A|})$이고, $a_t$는 위치 $t$의 토큰, $a_{<t}$는 이전 토큰들, $|A|$는 시퀀스 길이, $\theta$는 모델 파라미터를 나타낸다. 이 수식에서 핵심적으로 주목할 점은 각 토큰 $a_t$의 생성이 오직 이전 토큰들 $a_{<t}$에만 조건부라는 것이다. 이는 두 가지 체계적 한계로 이어진다. 모델이 생성 중에 미래 토큰 정보에 직접 접근할 수 없다는 점과, 이미 생성된 토큰을 수정할 수 없다는 점이다. 이러한 제약은 미리보기 계획(lookahead planning)이나 반복적 정제가 유리한 태스크에서 모델 성능을 제한할 수 있다. 구체적인 예를 들면, JSON 문자열 내에서 가변 길이 값을 생성할 때, 값의 끝에 올바른 따옴표와 쉼표를 배치하려면 현재 값이 언제 끝날지를 미리 알아야 하지만, 자기회귀 모델은 이를 순차적 예측에 의존할 수밖에 없다. 마찬가지로, 총 7개의 필드를 가진 JSON 객체에서 마지막 필드 뒤에는 쉼표를 넣지 않아야 하는데, 모델이 현재 생성 중인 필드가 마지막인지 여부를 정확히 판단하려면 전체 구조에 대한 전역적 인식이 필요하다.
3.2 디퓨전 언어 모델링
디퓨전 기반 언어 모델은 자기회귀 생성과 근본적으로 다른 접근 방식을 취한다. 이 모델은 두 가지 핵심 프로세스, 즉 순방향 노이징 프로세스(forward noising process)와 역방향 디노이징 프로세스(reverse denoising process)로 구성된다. 토큰화된 시퀀스 $\mathbf{x}_0$가 주어지면, 순방향 프로세스는 토큰을 마스킹하여 시퀀스를 점진적으로 손상시키며, $t \in [0, 1]$에 대해 점점 더 노이즈가 많은 시퀀스 $\mathbf{x}_t$를 생성한다. $t$가 1에 가까워질수록 더 많은 토큰이 마스킹되어, $x_1$은 완전히 마스킹된 시퀀스가 된다.
역방향 프로세스는 $t \in (0, 1]$에 대해 $x_t$ 내의 마스킹된 위치에서 원래 토큰을 예측하도록 신경망을 학습시킨다. 사전 학습 목적 함수는 다음과 같이 정식화된다.
$$\min_\phi - \mathbb{E}_{t, x_0, x_t} \left[ \frac{1}{t} \sum_{i=1}^{L} \mathbf{1}[x_t^i = \mathbf{M}] \log P_\phi(x_0^i | x_t) \right]$$
여기서 $\mathbf{M}$은 마스크 토큰, $L$은 시퀀스 길이, $\phi$는 모델 파라미터를 나타낸다. 이 목적 함수의 핵심은 마스킹된 위치 $x_t^i = \mathbf{M}$에서만 원래 토큰 $x_0^i$를 예측하는 로그 확률을 최대화한다는 점이다. 비율 $1/t$는 마스킹 비율이 높은(즉, 더 어려운) 시점에서의 기여도를 조정하는 역할을 한다.
최근 연구에 따르면, dLLM은 사용자 명령 $Q$를 고정 접두사로 연결($\oplus$)하고 마스킹된 타겟 시퀀스 $\mathbf{A}_t$ ($t=1$, 초기에 모두 마스킹됨)를 붙여 명령 미세 조정이 가능하다. 추론 시 dLLM이 수행하는 단일 디노이징 단계는 다음과 같이 분해될 수 있다.
$$\log P_\phi(Q \oplus A) = \sum_{i=1}^{|A|} \mathbf{1}[a_i = \mathbf{M}] \log P_\phi(a_i | Q \oplus A_t)$$
AR 모델과 비교했을 때, 이 다단계 생성 프로세스는 반복적 토큰 편집과 정제를 위해 잠재적으로 확장될 수 있다. 더욱 흥미로운 점은 dLLM의 전역 어텐션 메커니즘이 전역 문맥 인식을 크게 향상시킬 수 있으며, 심지어 미래 토큰 계획까지 포함할 수 있다는 것이다. 각 디노이징 단계에서 모델은 입력 컨텍스트의 모든 위치(마스킹된 위치와 마스킹되지 않은 위치 모두)에 대해 어텐션을 수행하므로, 시퀀스의 전역적 구조를 파악하면서 동시에 여러 위치의 토큰을 결정할 수 있다.
4. 방법론: Self-adaptive Schema Scaffolding ($S^3$)
4.1 구조화된 출력 생성의 형식적 정의
논문은 구조화된 출력 생성 태스크를 엄밀하게 정의한다. 사용자 쿼리 $Q$와 구조적 사양(structural specification) $S$가 주어졌을 때, 목표는 $Q$의 의미적 요구사항과 $S$에 의해 정의된 구조적 제약 조건을 모두 만족하는 응답 $A$를 생성하는 것이다. 구조적 사양 $S$는 JSON 스키마, XML DTD, 정규 표현식 등의 스키마 기반 구조, 형식 제약, 합성 구조, 도메인 특화 형식 등 매우 다양한 형태를 취할 수 있다. 이 태스크는 수학적으로 의미적 요구사항의 최적화와 구조적 제약 만족을 동시에 추구하는 제약 최적화 문제로 정식화된다.
$$A^* = \arg\max_{A \in \mathcal{A}(S)} P_{\text{LM}}(A | Q, S)$$
여기서 $\mathcal{A}(S)$는 구조 $S$에 부합하는 모든 유효한 출력의 공간을 나타내고, $P_{\text{LM}}$은 조건부 언어 모델이다. 실제로 전체 $\mathcal{A}(S)$를 탐색하는 것은 토큰 공간의 조합적 폭발(combinatorial explosion)로 인한 복잡성 때문에 계산적으로 불가능하다(intractable). 이 형식화의 의의는 구조화된 출력 생성이 단순한 조건부 텍스트 생성이 아니라, 허용 가능한 출력 공간 $\mathcal{A}(S)$ 내에서의 최적화 문제임을 명확히 한다는 점이다. 이러한 관점에서 dLLM의 전역적 탐색 능력이 왜 유리한지를 이론적으로 뒷받침할 수 있다.
4.2 Schema Scaffolding ($S^2$): 구조적 스캐폴드 기반 생성
구조화된 출력 생성에서 자기회귀 모델과 디퓨전 모델의 접근 방식은 근본적으로 다르다. 자기회귀 모델이 좌에서 우로 토큰을 생성하면서 각 단계에서 구조적 제약을 확인하는 반응적(reactive) 방식이라면, $S^2$는 디퓨전 모델의 특성을 활용하여 구조적 제약을 생성의 출발점으로 삼는 선제적(proactive) 방식을 취한다. 이러한 패러다임 전환의 핵심 통찰은, dLLM의 디노이징 프로세스가 부분적으로 알려진 정보가 존재하는 상태에서 나머지를 복원하는 데 본질적으로 적합하다는 점에 있다.
논문은 먼저 Schema Scaffolding($S^2$)을 제안한다. 이는 구조적 제약을 생성 컨텍스트에 구조적 템플릿을 사전 배치(pre-populating)함으로써 명시적으로 통합하는 학습 없는(training-free) 접근법이다. "학습 없는"이라는 특성이 특히 중요한 이유는, 새로운 스키마나 도메인에 대해 미세 조정을 수행할 필요 없이 즉시 적용할 수 있다는 실용적 이점을 제공하기 때문이다. 새로운 API가 추가되거나 데이터 스키마가 변경될 때마다 모델을 재학습시키는 것은 비용과 시간 측면에서 비실용적이므로, 학습 없는 접근법은 배포 유연성을 크게 향상시킨다. 이 방법의 핵심 아이디어는 제약 없는 생성을 구조화된 빈칸 채우기(fill-in-the-blank) 태스크로 변환하는 것이다.

Figure 2: 제안된 방법론의 파이프라인 개요. 원래 태스크 명령을 문제 설명과 구조적 제약의 두 구성요소로 분해한 후, 제약을 스키마로 컴파일하고 마스크 토큰이 자리표시자로 기능하는 노이즈 스캐폴드를 초기화한다. dLLM은 문제 설명을 컨텍스트로 사용하여 마스킹된 토큰을 예측함으로써 구조화된 출력을 생성하며, 선택적 리마스킹 전략을 통해 반복적으로 예측을 정제한다.
Figure 2에서 보이는 바와 같이, 구체적으로 이 방법은 구조적 사양 $S$를 파싱하여 불변 구조적 요소(괄호, 구분자, 필드 이름 등)를 식별하고, 가변적 내용 위치를 마스크 토큰 $\mathbf{M}$으로 대체하는 방식으로 작동한다. 이렇게 생성된 구조적 스캐폴드 $A_s$는 모델의 생성 공간을 제약하면서도 의미적 유연성을 보존한다. 예를 들어, JSON 출력을 생성해야 하는 경우, 중괄호, 콜론, 쉼표, 필드 이름 등은 고정된 구조적 토큰으로 미리 배치되고, 각 필드의 값 부분만 마스크 토큰으로 채워진다. 이후 dLLM은 이 마스킹된 위치에서만 적절한 값을 생성하면 된다.
구체적인 예를 들어보면, 사용자가 인물의 전기 텍스트에서 구조화된 정보를 JSON으로 추출하고자 할 때, 스캐폴드는 다음과 같은 형태를 가진다. 중괄호 {와 }, 각 필드의 키 이름("name", "birth_date" 등), 콜론, 쉼표 등의 구조적 토큰은 고정되고, 각 키에 대응하는 값 부분만 마스크 토큰 $\mathbf{M}$으로 채워진다. dLLM은 이 부분적으로 채워진 시퀀스에 대해 디노이징을 수행하므로, JSON의 구문 구조는 처음부터 보장되면서 모델은 의미적으로 적절한 값만 생성하면 된다. 이는 자기회귀 모델이 {부터 시작하여 모든 토큰을 순차적으로 생성해야 하는 것과 대비되는 근본적 차이이다.
이 접근법이 디퓨전 모델에서 효과적인 이유를 형식화하기 위해, 논문은 정리 4.1 (Scaffold-Guided Denoising Convergence)을 확립한다. 이 정리는 구조적 스캐폴드 $\mathcal{S}$로 디노이징 프로세스를 초기화하면 기대 디노이징 오차가 감소함을 보인다.
$$\mathbb{E}[\|\hat{\mathbf{x}}_0 - \mathbf{x}_0\|_\mathcal{M}] \leq \mathbb{E}[\|\tilde{\mathbf{x}}_0 - \mathbf{x}_0\|_\mathcal{M}] \cdot \left(1 - \frac{|\mathcal{S}|}{L}\right)$$
여기서 $\hat{\mathbf{x}}_0$는 스캐폴딩을 사용하여 생성된 시퀀스, $\tilde{\mathbf{x}}_0$는 스캐폴딩 없이 생성된 시퀀스, $\|\cdot\|_\mathcal{M}$은 마스킹된 위치에 대한 오차, $|\mathcal{S}|/L$은 스캐폴드 커버리지 비율을 나타낸다. 이 결과는 스캐폴딩이 디노이징 프로세스를 안내하는 원리적인 방법을 제공하며, 오차 감소가 스캐폴드 커버리지에 비례한다는 것을 확인한다. 또한 최소한의 스캐폴딩으로도 거의 완벽한 구조적 준수를 달성할 수 있다는 이후의 실증적 발견을 이론적으로 뒷받침한다.
이 정리의 증명은 부록 D.1에 수록되어 있으며, 핵심 논증 구조는 다음과 같다. 디퓨전 모델은 각 마스킹된 위치 $i$에서 $p_\phi(x_0^i | x_t)$를 예측하도록 학습된다. 구조적 스캐폴딩을 사용하면, 위치는 고정된 스캐폴드 위치 $\mathcal{S} = \{i : x_t^i \neq \mathbf{M}\}$와 가변 위치 $\mathcal{V} = \{i : x_t^i = \mathbf{M}\}$로 분할된다. 스캐폴딩을 사용한 컨텍스트에는 위치 $\mathcal{S}$에 올바른 구조적 토큰이 포함되어, 더 강한 신호를 제공한다. 스캐폴드 토큰은 설계상 올바르므로(타겟 구조와 일치하므로), 조건부 분포의 불확실성을 감소시킨다. 각 마스킹된 위치에서의 기대 오차와 스캐폴드 사이의 상호 정보 $I(\mathcal{S}; x_0^i)$의 관계를 집계하면 위의 부등식이 도출된다. 등호는 스캐폴드와 내용이 독립적일 때 성립하는데, 이는 구조화된 생성에서 거의 발생하지 않는다(예: 필드 이름은 값의 타입을 강하게 예측한다).
형식적으로, Schema Scaffolding의 구조화된 생성 목적 함수는 다음과 같이 정식화된다.
$$A^* = \arg\max_{A \in \mathcal{A}(S)} P_{\text{LM}}(A|Q, S) \approx \arg\max_{A_s \in \mathcal{SC}} P_\phi(A_s | Q) = \arg\max_{A_s \in \mathcal{SC}} \sum_{a_i \in A_s} \mathbf{1}[a_i = \mathbf{M}] \log P_\phi(a_i | Q, A_s)$$
여기서 $\mathcal{SC} \subset \mathcal{A}(S)$는 $S$로부터 도출된 구조적 템플릿을 공유하는 출력의 제약된 부분공간을 나타내고, $A_s$는 위치 $i$를 제외한 모든 비마스킹 토큰이 고정된 스캐폴드를 나타낸다. 핵심은 원래의 전체 탐색 공간 $\mathcal{A}(S)$를 구조적으로 호환되는 더 작은 부분공간 $\mathcal{SC}$로 축소함으로써, 계산적으로 다루기 쉬운 최적화 문제로 변환한다는 점이다.
4.3 Self-adaptive Schema Scaffolding ($S^3$): 적응적 길이 관리
Schema Scaffolding은 dLLM 생성을 제약하여 구조적 준수를 향상시키지만, 각 가변 콘텐츠 위치에 적절한 수의 마스크 토큰을 결정하는 방법이라는 새로운 도전 과제를 도입한다. 구조화된 빈칸 채우기 템플릿을 사전에 구축할 수 있지만, 타겟 콘텐츠에 대한 사전 지식 없이 각 가변 필드에 필요한 길이를 예측하는 것은 본질적으로 문제적이다.
논문은 직관적인 해결책인 각 가변 위치에 충분한 마스크 토큰을 할당하는 방법을 분석하였으나, dLLM이 시퀀스 길이에 민감하다는 것을 발견하였다. 더 긴 스캐폴드는 선택적 사용을 가능하게 하는 대신 생성 품질을 왜곡하여, 과소 활용(under-utilization)이나 환각된 콘텐츠(hallucinated content)를 야기한다. 미세 조정을 통해 특수 패딩 토큰을 도입하는 옵션도 있지만, 이는 학습 없는 목표를 위반하며 데이터셋 특화 편향을 내재화하여 새로운 도메인에 대한 일반화를 해칠 위험이 있다.
이러한 분석은 가변 길이 문제가 단순한 엔지니어링적 불편함이 아니라, dLLM의 생성 품질에 직접적으로 영향을 미치는 근본적 도전임을 보여준다. 예를 들어, 어떤 인물의 사망일 필드에 10개의 마스크 토큰을 할당했는데 실제로는 "null"(4개 토큰) 또는 "1990-01-15"(10개 토큰)처럼 가변적인 길이의 값이 필요한 경우, 과도하게 할당된 마스크 토큰은 모델에 혼란을 야기한다. 모델은 남은 마스크 토큰을 채우기 위해 불필요한 토큰을 생성하게 되며, 이는 환각이나 형식 오류로 이어질 수 있다.
이러한 통찰에 기반하여, 논문은 의미적 토큰 null을 자리표시자(placeholder)로 활용하는 개선된 방법을 제안한다. 이 접근법은 학습 없는 속성을 보존하면서, dLLM이 부재하거나 가변 길이의 콘텐츠를 null 토큰으로 자연스럽게 표현하도록 유도한다. 핵심 아이디어는 dLLM이 이미 사전 학습 과정에서 "null"이라는 토큰의 의미를 학습했기 때문에, 별도의 학습 없이도 이 토큰을 사용하여 빈 슬롯이나 불필요한 위치를 채울 수 있다는 것이다.
형식적으로, 적응적 길이 관리를 통합한 스캐폴딩 프레임워크의 확장은 다음과 같다.
$$A^* \approx \arg\max_{A_s \in \mathcal{SC}} \sum_{a_i \in A_s} \mathbf{1}[a_i = \mathbf{M}] \log P_\phi(a_i | Q^+, A_s)$$
여기서 $Q^+$는 모델이 부재 값을 나타내기 위해 null 토큰을 채택하도록 안내하는 증강된 프롬프트(augmented prompt)를 나타낸다. $S^2$의 원래 프롬프트 $Q$와 비교했을 때, $Q^+$는 "정보가 문서에서 사용할 수 없으면 해당 필드에 null을 사용하라"는 명시적 지시를 포함한다. 이렇게 함으로써 고정 길이 스캐폴딩 문제를 dLLM이 가변 길이 필드와 누락된 값을 자연스럽게 처리할 수 있는 적응적 생성 태스크로 변환한다. 이는 특히 선택적 필드나 가변 길이 콘텐츠가 포함된 시나리오에서 전체적인 구조화된 출력 품질을 현저히 향상시킨다.
4.4 리마스킹 전략: Top-K 선택적 리마스킹
dLLM은 기본적으로 단일 추론 단계에서 전체 컨텍스트 내의 모든 토큰을 병렬로 생성할 수 있다. 그러나 많은 일반적인 NLP 태스크에서 이 전략은 종종 최적에 미치지 못한다. 예를 들어, 수학 문제의 완전한 풀이를 구성하는 모든 토큰을 동시에 생성하는 것은 자기회귀 접근법을 통해 점진적으로 수행하는 것보다 현저히 어렵다. 이 문제를 해결하기 위해 선행 연구들은 다양한 리마스킹 전략(remasking strategy)을 탐색해 왔다.
논문은 기존의 두 가지 주요 리마스킹 전략과 제안된 전략을 다음과 같이 비교 분석한다.
- 블록 단위 마스킹(Block-wise Masking): 슬라이딩 윈도우 메커니즘을 사용하여, 각 반복에서 현재 윈도우 내의 토큰만 고려하고 이후 블록의 토큰은 미래 재생성을 위해 리마스킹한다. 이 전략은 반자기회귀적으로 간주되며, 경험적으로 블록 크기 1(완전 자기회귀 프로세스로 회귀)이 최상의 성능을 보여, 디퓨전 기반 모델의 병렬성 장점을 대부분 제거한다.
- 저신뢰도 리마스킹(Low-Confidence Remasking): 현재 반복에서 낮은 로그 확률이나 높은 엔트로피와 같은 낮은 신뢰도 점수를 가진 토큰을 선택적으로 폐기한다. 이 프로세스는 모든 토큰이 확정될 때까지 반복되어, 더 적응적인 반복 횟수를 허용한다.
- 제안된 Top-K 리마스크 전략: $S^3$는 $K = O/n$인 간단하면서도 효과적인 Top-K 리마스크 전략을 채택한다. 여기서 $O$는 생성할 전체 토큰 수, $n$은 조정 가능한 디노이징 단계 수이다. 블록 단위 리마스킹과 비교하여 이 방법은 현저히 더 효율적이며, 생성 반복 횟수를 사전 정의하여 속도와 출력 품질 간의 실용적 균형을 제공하는 추가적인 제어 가능성을 도입한다.
Top-K 전략의 핵심 장점은 각 디노이징 단계에서 모델이 가장 확신하는 상위 $K$개의 토큰만 확정하고 나머지를 다시 마스킹하여, 후속 단계에서 더 많은 컨텍스트 정보를 활용해 정제할 수 있게 한다는 점이다. 이는 전체 시퀀스에 대한 병렬 어텐션이라는 dLLM의 구조적 장점을 유지하면서도, 자기회귀 모델의 점진적 정제 능력을 일정 부분 확보하는 절충점을 제공한다.
이 Top-K 전략이 블록 단위 마스킹보다 구조화된 출력 생성에 더 적합한 이유를 구체적으로 분석하면 다음과 같다. 블록 단위 마스킹은 시퀀스를 고정된 블록으로 분할하고 좌에서 우로 순차적으로 처리하므로, JSON 구조에서 서로 멀리 떨어진 위치에 있는 상호 의존적 토큰들(예: 열린 중괄호와 닫힌 중괄호, 또는 앞쪽 필드의 값과 뒤쪽 필드의 값 간의 일관성)을 동시에 고려하지 못한다. 반면 Top-K 전략에서는 각 단계에서 전체 시퀀스에 대한 전역 어텐션이 수행되므로, 위치에 관계없이 가장 확실한 토큰들이 먼저 확정되고, 불확실한 토큰들은 주변의 확정된 토큰으로부터 더 강한 컨텍스트 신호를 받아 후속 단계에서 정제된다.
예를 들어, $O = 128$개의 토큰을 생성해야 하고 $n = 8$단계를 사용한다면, 각 단계에서 $K = 128/8 = 16$개의 가장 높은 신뢰도를 가진 토큰이 확정된다. 첫 번째 단계에서는 구조적으로 명확한 토큰(예: null 값을 가진 필드, 문맥에서 명백히 추론 가능한 이름 등)이 먼저 확정되고, 이후 단계에서는 이미 확정된 토큰들이 제공하는 추가적 컨텍스트를 활용하여 더 어려운 토큰들(예: 정확한 날짜, 모호한 지명 등)이 정제된다. 이 과정은 마치 인간이 양식을 작성할 때 확실한 정보를 먼저 기입하고, 애매한 부분은 나중에 전체 맥락을 보면서 채우는 것과 유사한 방식이다.
5. 실험 설정: WikiBio 기반 구조화된 출력 생성 평가
5.1 데이터셋 및 벤치마크
논문은 WikiBio 데이터셋을 주요 벤치마크 데이터셋으로 사용한다. WikiBio는 위키피디아의 전기 도메인에서 구조화된 데이터로부터 텍스트를 생성하는 태스크를 위해 설계된 데이터셋이다. 이 데이터셋은 이름(name), 생년월일(birth_date), 출생지(birth_place), 사망일(death_date), 사망지(death_place), 국적(nationality), 직업(occupation) 등의 정형화된 필드를 가지고 있어, 구조화된 출력 생성 능력을 체계적으로 평가하기에 적합하다. 입력으로 비정형 전기 텍스트가 주어지고, 모델은 이로부터 사전 정의된 JSON 스키마에 맞춘 구조화된 정보를 추출하여 출력해야 한다.
5.2 평가 프레임워크
논문은 구조화된 출력 생성의 고유한 특성을 감안하여, 전통적인 정확도 기반 메트릭만으로는 모델 성능의 전체 스펙트럼을 포착하기에 부적절하다고 주장한다. 따라서 구조적 준수(Structural Adherence), 콘텐츠 충실도(Content Fidelity), 사실 충실도(Faithfulness)의 세 가지 핵심 차원에 걸쳐 출력을 평가하는 포괄적인 평가 프레임워크를 제안한다.
| 평가 차원 | 메트릭 | 약어 | 방향 | 측정 내용 |
|---|---|---|---|---|
| 구조적 준수 | Structure Validity | SV | 높을수록 좋음 | 구문적으로 유효하고 오류 없이 파싱되는 출력 비율 |
| Field Completeness | FC | 높을수록 좋음 | 올바르게 채워진 필수 필드의 비율 | |
| Schema Compliance | SC | 높을수록 좋음 | 데이터 타입, 값 제약, 중첩 구조를 포함한 완전한 스키마 준수 비율 | |
| 콘텐츠 충실도 | Precision | PR | 높을수록 좋음 | 개별 필드 유형별 산출 정밀도 |
| Recall | RE | 높을수록 좋음 | 개별 필드 유형별 재현율 | |
| F1 Score | F1 | 높을수록 좋음 | 필드 수준 정밀도와 재현율의 조화 평균 (정확 일치 및 퍼지 일치 모두 지원) | |
| 사실 충실도 | Hallucination Rate | HR | 낮을수록 좋음 | 소스 텍스트에 없거나 합리적으로 추론할 수 없는 정보를 포함한 출력 필드 비율 |
구조적 준수(Structural Adherence)는 생성된 출력이 대상 스키마에 얼마나 잘 부합하는지를 측정한다. Structure Validity(SV)는 가장 기본적인 수준으로 출력이 구문적으로 유효하고 파싱 오류 없이 처리되는지를 확인한다. Field Completeness(FC)는 필수 필드가 올바르게 포함되었는지를 나타내며, Schema Compliance(SC)는 올바른 데이터 타입, 값 제약, 중첩 구조를 포함하여 사전 정의된 스키마에 완전히 부합하는 비율을 측정하는 가장 엄격한 구조적 메트릭이다.
콘텐츠 충실도(Content Fidelity)는 구조적으로 유효한 출력 내에서 정보의 의미적 정확성을 평가한다. 필드 수준의 정밀도와 재현율, 그리고 이들의 조화 평균인 F1 점수를 포함하며, 의미적 의미를 보존하는 사소한 텍스트 변이를 수용하기 위해 정확 일치와 퍼지 일치 전략 모두를 사용하여 계산된다.
사실 충실도(Faithfulness)는 생성된 콘텐츠가 소스 입력에 얼마나 충실하게 근거하는지를 평가하며, 특히 추출 설정에서 매우 중요하다. 환각률(Hallucination Rate, HR)은 소스 텍스트에 존재하지 않거나 합리적으로 추론할 수 없는 정보를 포함하는 출력 필드의 비율을 직접적으로 반영한다. 이 세 차원의 메트릭은 함께 모델 간 체계적 비교를 지원하고, 구조화된 출력 생성에서 개선이 필요한 특정 영역을 조명한다.
5.3 구현 세부사항
논문은 주요 dLLM으로 GSAI-ML/LLaDA-1.5 디퓨전 대규모 언어 모델을 사용한다. 이 모델은 HuggingFace 공식 저장소에서 bfloat16 정밀도로 로드되어 최적의 메모리 효율성과 성능을 달성한다. 모든 실험은 단일 NVIDIA RTX 4090 GPU(24GB VRAM)에서 수행되었으며, 이는 비교적 접근 가능한 하드웨어 환경에서도 본 방법을 실행할 수 있음을 보여준다. 실험 결과의 재현성과 결정론적 비교를 보장하기 위해 디코딩 온도는 0으로 설정되었으며, 최대 새 토큰 수(max_new_tokens)는 128로 설정되어 WikiBio 데이터셋의 모든 구조화된 출력 태스크에 충분한 용량을 제공하며, 이는 7개 필드의 JSON 출력에 적합한 크기이다.
| 항목 | 세부사항 |
|---|---|
| 모델 | GSAI-ML/LLaDA-1.5 (디퓨전 기반 대규모 언어 모델) |
| 정밀도 | bfloat16 |
| 하드웨어 | 단일 NVIDIA RTX 4090 GPU |
| 최대 새 토큰 수 | 128 |
| 온도 | 0 (결정론적 생성) |
| 데이터셋 | WikiBio (전기 도메인 구조화 데이터 생성) |
| 디노이징 단계 | 8, 16, 32 단계 비교 평가 |
5.4 베이스라인 및 비교 방법
논문은 dLLM의 구조화된 출력 성능을 체계적으로 평가하기 위해 다양한 베이스라인과 비교 방법을 설정한다. 이 비교 방법론의 설계는 프롬프트 수준의 개선에서 스캐폴딩 수준의 개선까지 점진적으로 발전하는 구조를 가지고 있어, 각 기법의 기여도를 명확히 분리하여 분석할 수 있다. 비교 방법들의 구체적 설정은 다음과 같다.
논문은 다음과 같은 방법들을 비교 대상으로 설정한다. Baseline은 상세한 프롬프트를 통해 원하는 출력 구조를 명시적으로 지정하는 직접 프롬프팅 방법이다. 이 프롬프트에는 완전한 JSON 스키마가 포함되어 모델이 텍스트 지시사항에만 기반하여 스키마 제약을 이해하고 준수하도록 요구한다. 추가적으로 Few-shot Learning(3개의 예시 사용), Template-as-Guidance(완전한 스키마를 명령에 확장), 그리고 제안된 Schema Scaffolding($S^2$)과 Self-adaptive Schema Scaffolding($S^3$)이 비교된다.
- Baseline (직접 프롬프팅): 완전한 JSON 스키마를 포함하는 상세한 프롬프트를 사용. 각 필드의 타입, 설명, 형식 요구사항을 텍스트로 명시하여 모델이 이를 이해하고 준수하도록 요구한다.
- Few-shot Learning: 베이스라인 프롬프트에 3개의 입출력 예시를 추가. 모델이 예시의 패턴을 학습하여 구조적 출력을 생성하도록 유도한다.
- Template-as-Guidance: Wang et al. (2025)의 SLOT 방법을 따라, 완전한 스키마를 명령에 확장하여 안내로 제공. 구조적 정보를 프롬프트 내에 더 풍부하게 포함한다.
- Schema Scaffolding ($S^2$): 구조적 템플릿을 출력 컨텍스트에 직접 배치하고, 가변 위치를 마스크 토큰으로 대체. 구조적 요소를 프롬프트가 아닌 스캐폴드로 시행한다.
- Self-adaptive Schema Scaffolding ($S^3$): $S^2$에 null 토큰 기반 적응적 길이 관리를 추가. 증강된 프롬프트 $Q^+$를 사용하여 모델이 누락 정보를 null로 표시하도록 안내한다.
주목할 만한 점은, $S^3$의 프롬프트가 베이스라인에 비해 현저히 간결하다는 것이다. 베이스라인 프롬프트는 완전한 JSON 스키마 정의를 포함하는 긴 명령을 사용하는 반면, $S^3$는 명시적인 구조적 정보를 프롬프트에서 생략한다. 대신 스캐폴딩 메커니즘에 의해 시행되는 내재적 구조 제약에 의존하며, 단순히 "문서에서 정보를 추출하고 JSON 응답만 반환하라. 문서에서 사용할 수 없는 정보는 null을 사용하라"는 간결한 지시만 포함한다. 이는 $S^3$의 토큰 효율성과 명확성을 보여준다.
6. 주요 실험 결과: 세 차원에서의 체계적 평가
이 섹션에서는 논문이 수행한 체계적 평가의 결과를 세 가지 핵심 차원에 걸쳐 상세히 분석한다. 논문의 실험 설계는 동일한 모델(LLaDA-1.5)과 동일한 데이터셋(WikiBio)에서 다양한 방법을 비교하되, 디노이징 단계(8, 16, 32)를 달리하여 계산 예산에 따른 성능 변화를 체계적으로 추적한다는 점에서 잘 구성되어 있다. 이를 통해 각 방법이 단순히 더 많은 계산을 통해 성능을 개선하는 것인지, 아니면 근본적으로 다른 메커니즘에 의해 성능을 향상시키는 것인지를 분리하여 분석할 수 있다.
6.1 구조적 준수(Structural Adherence) 결과
구조적 준수는 구조화된 출력 생성에서 가장 기본적이면서도 가장 중요한 요구사항이다. 아무리 내용이 정확하더라도 구문적으로 유효하지 않은 JSON은 파서에 의해 거부되어 완전히 사용할 수 없게 되기 때문이다. 이 차원에서의 평가 결과는 제안된 방법의 가장 인상적인 성과를 보여준다. 구조적 준수 평가에서 dLLM에 대한 직접 프롬프팅은 구조적 제약에 대해 부적절한 것으로 나타났다. 베이스라인 평가 결과, Structure Validity, Field Completeness, Schema Compliance의 모든 구조적 메트릭에서 성능이 일관되게 65% 미만을 기록하였다. 심지어 32 디노이징 단계에서도 이 세 가지 핵심 메트릭 중 최대 점수가 87%를 상회하는 수준에 그쳐, 현실적인 유용성에 대한 기대에 크게 미치지 못한다.
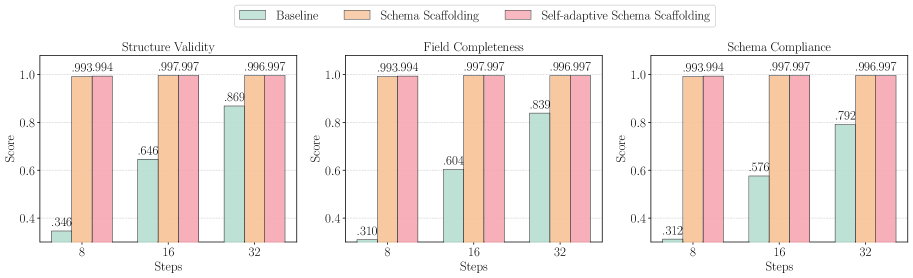
Figure 3: 디노이징 단계 및 방법별 구조적 준수 비교. 제안된 스키마 스캐폴딩 접근법을 사용했을 때 모든 메트릭에서 일관된 개선을 보이며, 더 적은 단계에서 거의 완벽한 성능을 달성한다.
Figure 3에서 보이는 바와 같이, 제안된 스키마 스캐폴딩 방법들은 구조적 준수 측면에서 베이스라인을 크게 능가한다. 바닐라 및 자기적응 변형 모두 8 디노이징 단계만으로도 거의 완벽한 구조적 준수를 달성하며, 16 단계에서 성능 포화에 도달한다. 다음 표는 Figure 3에서 추출한 구체적인 수치를 정리한 것이다.
| 메트릭 | 단계 | Baseline | Schema Scaffolding ($S^2$) | Self-adaptive ($S^3$) |
|---|---|---|---|---|
| Structure Validity | 8 | 0.346 | 0.993 | 0.994 |
| 16 | 0.646 | 0.997 | 0.997 | |
| 32 | 0.869 | 0.996 | 0.997 | |
| Field Completeness | 8 | 0.310 | 0.993 | 0.994 |
| 16 | 0.604 | 0.997 | 0.997 | |
| 32 | 0.839 | 0.996 | 0.997 | |
| Schema Compliance | 8 | 0.312 | 0.993 | 0.994 |
| 16 | 0.576 | 0.997 | 0.997 | |
| 32 | 0.792 | 0.996 | 0.997 |
이 결과에서 특히 주목할 만한 점은 $S^2$와 $S^3$가 구조적 준수 측면에서 거의 동일한 성능을 보인다는 것이다. 이는 구조적 준수가 주로 스캐폴드 자체의 존재 여부에 의해 결정되며, null 토큰 메커니즘은 구조적 준수보다는 콘텐츠 충실도와 환각 방지에 주로 기여함을 시사한다. 또한 베이스라인에서 디노이징 단계를 8에서 32로 4배 증가시키면 SV가 0.346에서 0.869로 크게 개선되지만, 이는 여전히 스캐폴딩 방법의 8단계 성능(0.993~0.994)에 미치지 못한다. 이는 단순히 더 많은 계산을 투입하는 것보다 올바른 초기 조건을 설정하는 것이 훨씬 효과적임을 보여주는 결과이다. 이 관찰은 디퓨전 모델 분야의 더 넓은 맥락에서도 의미가 있다. 이미지 생성 분야의 디퓨전 모델에서도 초기 노이즈의 품질이 최종 생성물의 품질에 결정적인 영향을 미친다는 것이 널리 알려져 있다. 이와 유사하게, 텍스트 디퓨전 모델에서도 초기 상태의 구조적 품질이 최종 출력의 구조적 품질을 크게 좌우한다는 것을 본 논문의 결과가 실증적으로 보여주고 있다. 이러한 초기 조건의 중요성은 향후 dLLM 연구에서 더 정교한 초기화 전략을 개발하는 데 중요한 이론적 근거를 제공한다.
이 극적인 개선은 정확도를 넘어선 실질적인 의의를 가진다. 디퓨전 모델의 추론은 디노이징 단계에 선형적으로 비례하므로, 제안된 접근법은 구조적 품질을 향상시키면서 동시에 생성 지연 시간을 줄이는 효과를 가져온다. 이는 통상적으로 성능과 효율성 사이에 트레이드오프가 존재하는 딥러닝 분야에서 매우 드문 "두 마리 토끼를 모두 잡는" 결과로, 제안된 접근법의 설계가 문제의 본질에 잘 맞춰져 있음을 보여주는 강력한 근거이다. 구체적으로, 32단계 베이스라인의 계산 비용으로도 SC 0.792밖에 달성하지 못하는 반면, 8단계 $S^3$는 1/4의 계산 비용으로 SC 0.994를 달성한다. 이는 약 4배의 추론 속도 향상과 함께 약 27% 포인트의 성능 향상을 동시에 달성하는 놀라운 결과이다. 8단계에서 베이스라인이 약 31-35% 수준에 머무르는 반면, 스캐폴딩 방법들은 99%를 상회하는 압도적인 격차를 보인다. 이는 스키마 스캐폴딩이 디퓨전 기반 언어 모델을 구조화된 출력 생성에 배포하는 데 있어 근본적인 장벽을 해결하며, 이들을 비실용적인 수준에서 실세계 응용에 매우 효과적인 수준으로 격상시킨다는 것을 의미한다.
6.2 콘텐츠 충실도(Content Fidelity) 결과
콘텐츠 충실도에 대한 평가에서는 추가적인 디노이징 단계가 직관과 반대로 콘텐츠 정확도의 개선을 보장하지 않으며, 오히려 성능이 때로는 확장된 반복으로 저하되는 것이 관찰되었다. 논문은 이 패턴을 디퓨전 모델이 확장된 반복적 역과정 중에 최적 해로부터 이탈할 수 있는 현상, 즉 "과사고(overthinking)" 현상이라고 명명한다. 이는 추론 시간을 늘린다고 항상 더 나은 결과를 얻는 것은 아니라는 중요한 통찰을 제공한다.
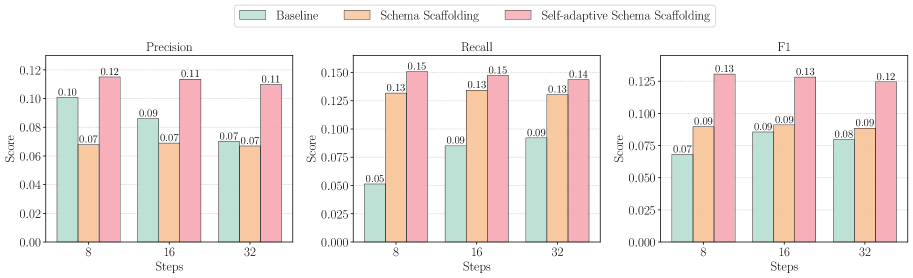
Figure 4: 디노이징 단계 및 방법별 콘텐츠 충실도 비교. Self-adaptive Schema Scaffolding이 모든 설정에서 가장 높은 정밀도, 재현율, F1 점수를 일관되게 달성한다.
Figure 4에서 확인할 수 있듯이, 바닐라 Schema Scaffolding($S^2$)은 베이스라인 대비 재현율과 F1 점수에서 명확한 개선을 보여, 관련 콘텐츠의 향상된 커버리지를 나타낸다. 그러나 정밀도는 모든 디노이징 구성에서 현저하게 저하된다. 이러한 트레이드오프는 모델의 보상적 행동에서 발생한다. 엄격한 스키마 요구사항에 의해 제약받을 때, 모델은 모든 예약된 슬롯을 채우기 위해 과도하게 토큰을 생성하는데, 이는 콘텐츠 길이가 예제 간에 크게 다를 때 특히 문제적이다.
| 메트릭 | 단계 | Baseline | $S^2$ | $S^3$ |
|---|---|---|---|---|
| Precision | 8 | 0.101 | 0.070 | 0.115 |
| 16 | 0.086 | 0.070 | 0.113 | |
| 32 | 0.070 | 0.070 | 0.110 | |
| Recall | 8 | 0.051 | 0.130 | 0.151 |
| 16 | 0.085 | 0.130 | 0.147 | |
| 32 | 0.092 | 0.130 | 0.144 | |
| F1 | 8 | 0.068 | 0.090 | 0.130 |
| 16 | 0.086 | 0.090 | 0.128 | |
| 32 | 0.080 | 0.090 | 0.125 |
$S^3$는 이 까다로운 상황을 해결한다. 잉여 슬롯에 적응적 null 토큰을 통합함으로써, 과도한 생성을 방지하면서도 포괄적인 커버리지를 유지한다. 이 간단하면서도 효과적인 처방은 세 가지 메트릭 모두에서 실질적인 개선을 달성하여, 구조적 준수를 희생하지 않으면서 견고한 콘텐츠 충실도를 확립한다. 특히 F1 점수에서 $S^3$는 8단계에서 0.130, 16단계에서 0.128, 32단계에서 0.125를 달성하여, 베이스라인(0.068~0.086) 및 $S^2$(0.090)를 현저히 능가한다.
$S^2$의 정밀도가 베이스라인보다 오히려 낮은 현상(8단계: 0.070 vs 0.101)은 흥미로운 관찰이다. 이는 고정 길이 스캐폴드가 모든 예약된 슬롯을 반드시 채우도록 모델에 압력을 가하기 때문이다. 예를 들어, 특정 인물의 사망일이 소스 텍스트에 없는 경우에도, 스캐폴드의 해당 필드에 마스크 토큰이 할당되어 있으므로 모델은 어떤 값이든 생성해야 한다. 이 과정에서 모델이 그럴듯하지만 사실이 아닌 날짜를 생성하게 되어 정밀도가 하락한다. $S^3$는 이러한 경우에 모델이 null을 생성할 수 있도록 허용함으로써, 불필요한 과생성을 방지하고 정밀도를 회복시킨다.
또한 디노이징 단계 증가에 따른 "과사고" 현상은 dLLM의 추론 스케일링에 대한 중요한 시사점을 제공한다. 자기회귀 모델에서는 test-time compute를 늘리면 일반적으로 성능이 향상되는 경향이 있지만(예: OpenAI o1의 추론 체인), dLLM에서는 디노이징 단계를 과도하게 늘리면 오히려 모델이 최적 해에서 벗어나는 현상이 발생할 수 있다. 이는 디퓨전 프로세스의 반복적 특성상, 올바른 토큰이 이미 결정된 후에도 추가 디노이징이 이를 불안정하게 만들 수 있기 때문이다.
주목할 만한 점은 전반적인 콘텐츠 충실도 점수가 모두 0.15 이하로 비교적 낮다는 것이다. 이는 WikiBio 데이터셋에서의 구조화된 정보 추출이 본질적으로 도전적인 태스크임을 시사한다. 비정형 전기 텍스트에서 정확한 날짜, 장소, 국적 등을 추출하는 것은 텍스트의 다양한 표현 방식과 정보의 암묵적 표현으로 인해 높은 정밀도를 달성하기 어려운 태스크이다. 특히 날짜의 경우 "early 1950s", "around the turn of the century" 등의 모호한 표현을 ISO 형식의 정확한 날짜로 변환해야 하고, 장소의 경우 역사적 지명 변경이나 다양한 표기법을 처리해야 하는 난이도가 있다. 또한 LLaDA-1.5가 8B 파라미터 규모의 상대적으로 작은 dLLM이라는 점도 절대적 성능에 영향을 미쳤을 가능성이 있다. 더 큰 규모의 dLLM이 개발되면 동일한 $S^3$ 프레임워크에서 절대적 성능의 상당한 향상을 기대할 수 있을 것이다. 그럼에도 불구하고 $S^3$가 모든 설정에서 일관되게 최고 성능을 보인다는 점은, 이 방법론이 모델 규모와 독립적으로 효과적인 범용적 프레임워크임을 시사하는 의미 있는 결과이다.
6.3 사실 충실도(Faithfulness) 결과
사실 충실도 평가에서 $S^3$는 모든 디노이징 단계에 걸쳐 일관되게 가장 낮은 환각률을 달성하여 우수한 사실 충실도 성능을 보여준다. 이 명확한 우위는 구조화된 출력을 생성하면서 사실적 근거를 유지하는 데 있어 제안된 방법의 우수성을 확립한다.
| 방법 | 8 Steps | 16 Steps | 32 Steps |
|---|---|---|---|
| Baseline | 0.404 | 0.403 | 0.409 |
| Schema Scaffolding ($S^2$) | 0.465 | 0.463 | 0.463 |
| $S^3$ (Ours) | 0.340 | 0.331 | 0.331 |
흥미롭게도, 바닐라 Schema Scaffolding($S^2$)은 베이스라인보다 더 높은 환각률을 나타낸다. 사실 충실도에서의 이러한 악화된 성능은 Schema Scaffolding 접근법의 원래 설계에 도전하는 치명적 약점을 드러낸다. 논문의 분석에 따르면, 이 환각 문제는 부과된 구조적 제약에 의해 도입된 분포 이동(distributional shift)에서 비롯된다. 이 분포 이동은 모델의 사전 학습 역과정에서 벗어나는 토큰 분포를 생성한다.
구체적으로, 엄격한 스키마는 디퓨전 언어 모델의 학습된 디노이징 프로세스와 정렬되지 않은 구조적 사전(structural prior)으로 작용한다. 이 분포적 불일치는 모델을 최적이 아닌 디노이징 궤적으로 몰아넣는다. 구조적 사전이 소스 텍스트에 근거할 수 없는 범위를 넘어선 콘텐츠 생성을 요구할 때, 모델은 스키마 요구사항을 충족시키기 위해 그럴듯한 토큰을 날조하는 방식으로 기본 작동하게 되는데, 이는 충실한 재구성이라는 학습 목표에 모순되는 행동이다.
이러한 분포 이동 문제는 디퓨전 모델의 근본적 작동 원리를 이해하면 더 잘 파악할 수 있다. dLLM은 사전 학습 과정에서 "완전히 마스킹된 상태에서 원래 시퀀스를 복원"하는 분포를 학습한다. 그런데 스캐폴딩은 부분적으로 채워진 상태에서 나머지를 복원하도록 하므로, 이는 학습 시의 분포와 다른 조건을 만들어낸다. 특히 바닐라 $S^2$에서는 빈 슬롯에 마스크 토큰만 존재하므로, 모델은 "이 위치에 반드시 어떤 의미 있는 토큰이 있어야 한다"는 강한 압력을 받는다. 이 압력이 소스 텍스트에 근거가 없는 정보까지 생성하게 만드는 것이다. 이는 자기회귀 모델에서도 관찰되는 "빈칸 채우기 편향(fill-in-the-blank bias)"과 유사한 현상이라 할 수 있다.
$S^3$의 자기적응적 접근법은 이 근본적 충돌을 완화한다. 모델이 null 토큰을 통해 누락된 정보를 인정할 수 있도록 허용함으로써, 구조적 제약을 준수하면서도 사전 학습된 디노이징 능력과의 정렬을 유지한다. 이는 $S^2$에서 $S^3$로의 핵심적 개선점이며, null 토큰이라는 간단한 의미적 장치가 환각률을 0.465에서 0.340으로 크게 낮출 수 있음을 보여주는 인상적인 결과이다.
7. 추가 분석 및 Ablation Study: $S^3$의 효과 분해
7.1 Ablation Study: 기법별 효과 분석
논문은 제안된 방법의 효과를 입증하기 위해, 다양한 기법으로 점진적으로 강화된 베이스라인 모델과의 비교 ablation 연구를 수행한다. 비교 대상은 베이스라인, 퓨샷 학습(3개 예시)을 추가한 베이스라인, 완전한 스키마를 안내로 확장한 템플릿 방식, 그리고 제안된 $S^3$이다. 이 ablation 연구의 핵심 목적은 $S^3$의 성능 향상이 단순히 더 많은 정보를 프롬프트에 포함한 것이 아니라, 스캐폴딩이라는 근본적으로 다른 접근 방식에서 비롯된 것임을 보이는 데 있다.
| 실험 구성 | 구조적 준수 | 콘텐츠 충실도 | 사실 충실도 | ||||
|---|---|---|---|---|---|---|---|
| SV | FC | SC | PR | RE | F1 | HR | |
| 8 Steps | |||||||
| Baseline | 0.346 | 0.310 | 0.312 | 0.101 | 0.051 | 0.068 | 0.404 |
| + Few-shots (3예시) | 0.471 | 0.447 | 0.443 | 0.086 | 0.056 | 0.068 | 0.366 |
| + Template 안내 | 0.475 | 0.432 | 0.431 | 0.088 | 0.081 | 0.084 | 0.388 |
| $S^3$ (Ours) | 0.994 | 0.994 | 0.994 | 0.115 | 0.151 | 0.130 | 0.340 |
| 16 Steps | |||||||
| Baseline | 0.646 | 0.604 | 0.576 | 0.086 | 0.085 | 0.086 | 0.403 |
| + Few-shots (3예시) | 0.735 | 0.713 | 0.674 | 0.084 | 0.087 | 0.085 | 0.371 |
| + Template 안내 | 0.794 | 0.734 | 0.738 | 0.091 | 0.139 | 0.110 | 0.390 |
| $S^3$ (Ours) | 0.997 | 0.997 | 0.997 | 0.113 | 0.147 | 0.128 | 0.331 |
| 32 Steps | |||||||
| Baseline | 0.869 | 0.839 | 0.792 | 0.070 | 0.092 | 0.080 | 0.409 |
| + Few-shots (3예시) | 0.890 | 0.870 | 0.824 | 0.092 | 0.114 | 0.101 | 0.358 |
| + Template 안내 | 0.909 | 0.886 | 0.882 | 0.091 | 0.160 | 0.116 | 0.384 |
| $S^3$ (Ours) | 0.997 | 0.997 | 0.997 | 0.110 | 0.144 | 0.125 | 0.331 |
위 표에서 확인할 수 있는 핵심 관찰은 다음과 같다. 퓨샷 학습과 템플릿 안내 방식은 dLLM의 구조적 준수와 사실 충실도를 어느 정도 개선하지만, 콘텐츠 충실도에 대한 성능은 일관되지 않으며 제한적인 향상만을 보인다. 예를 들어 8단계에서 퓨샷 학습은 SV를 0.346에서 0.471로 개선하지만, 이는 여전히 $S^3$의 0.994에 크게 미치지 못한다. 또한 베이스라인 대비 퓨샷의 F1 점수 변화(0.068에서 0.068)는 사실상 개선이 없음을 보여준다.
이 ablation 결과에서 특히 주목할 만한 패턴은 디노이징 단계 증가에 따른 각 방법의 반응 차이이다. 베이스라인 및 프롬프트 기반 방법들(few-shots, template)은 단계 수를 8에서 32로 증가시킬 때 구조적 준수에서 상당한 개선을 보인다(예: 베이스라인 SV: 0.346 → 0.869). 그러나 이들 방법의 개선은 점진적이고 불완전하여, 32단계에서도 90%를 넘기기 어렵다. 이에 반해 $S^3$는 8단계에서 이미 99.4%에 도달하여 추가 단계가 거의 필요 없다. 이는 $S^3$의 성능 향상이 단순히 더 많은 계산을 투입하여 얻어지는 것이 아니라, 문제를 근본적으로 다른 방식으로 접근한 결과임을 확인시켜 준다.
이에 반해 $S^3$는 제로샷(zero-shot) 방법임에도 불구하고 우월한 데이터 효율성과 계산 효율성을 달성한다. 더 적은 디노이징 단계를 필요로 하면서도, $S^3$는 놀라울 정도로 안정적인 구조적 준수를 제공하며, 충실도와 사실 충실도 모두에서 한계적이지만 일관된 개선을 보인다. 특히 32단계에서 유일하게 $S^3$보다 높은 재현율을 보이는 경우는 Template 안내 방식(RE: 0.160 vs 0.144)뿐이지만, 이마저도 정밀도(0.091 vs 0.110)와 환각률(0.384 vs 0.331)에서 $S^3$에 크게 뒤처진다.
7.2 프롬프트 설계 비교 분석
논문은 부록 C에서 베이스라인 방법과 $S^3$에서 사용되는 프롬프트의 상세한 비교를 제공한다. 이 비교는 $S^3$의 설계 철학을 이해하는 데 핵심적인 단서를 제공한다. 베이스라인 프롬프트는 완전한 JSON 스키마 정의를 포함하며, 각 필드의 이름, 데이터 타입(string 또는 null), 설명(예: "Full name of the person", "Birth date in ISO format"), 필수 필드 목록(required 배열)을 모두 텍스트로 명시한다. 이 프롬프트의 길이는 수백 토큰에 달하며, 모델이 이 복잡한 스키마 정의를 텍스트로 이해하고 이를 구조화된 출력으로 변환해야 한다.
반면 $S^3$의 프롬프트는 단 두 문장으로 구성된다. "Extract information from the provided document and return only a JSON response with no additional text or explanation. If any information is not available in the document, use null for that field." 이 간결한 프롬프트가 가능한 이유는 구조적 제약이 스캐폴드 메커니즘에 의해 이미 시행되고 있기 때문이다. 모델은 JSON의 구문 구조를 텍스트 명령에서 학습할 필요 없이, 스캐폴드에 미리 배치된 구조적 토큰을 따르기만 하면 된다. 이러한 프롬프트 효율성은 dLLM의 컨텍스트 길이 제한을 더 효율적으로 사용할 수 있게 하며, 긴 프롬프트에 의한 주의력 분산(attention dilution) 문제도 완화한다.
이러한 프롬프트 설계의 차이는 더 근본적인 인사이트를 제공한다. 자기회귀 모델에서는 구조적 제약을 전달하는 유일한 채널이 프롬프트 텍스트이므로, 프롬프트에 최대한 상세한 스키마 정보를 포함해야 한다. 그러나 dLLM에서는 출력 시퀀스의 초기 상태가 추가적인 정보 채널로 활용될 수 있으므로, 구조적 정보를 프롬프트가 아닌 스캐폴드로 전달하는 것이 가능하다. 이는 프롬프트 엔지니어링의 부담을 크게 줄이며, 다양한 구조에 대한 일반화를 촉진한다.
7.3 환각 현상에 대한 강건성 분석
자기회귀 언어 모델과 유사하게, dLLM도 환각(hallucination), 즉 사실이 아닌 콘텐츠, 결함 있는 추론, 근거 없는 결론을 생성하는 문제를 겪는다. 개방형 대화나 창작 텍스트 생성과 달리, 구조화된 출력에서의 환각은 특히 해로운데, 이는 출력의 신뢰성과 신뢰 가능성을 직접적으로 훼손하기 때문이다. 이 두 속성은 구조화된 출력 태스크의 핵심이다.
논문은 바닐라 Schema Scaffolding이 강력한 구조적 제약을 시행하면서, 이것이 불가피하게 dLLM의 자연스러운 생성 궤적을 간섭한다는 점을 분석한다. 결과적으로 발생하는 환각을 완화하기 위해, 논문은 익숙하지 않은 테스트 시나리오를 익숙한 학습 시 사례로 변환하는 것이 가능하다는 관찰에 기반한 해결책을 제시한다. 이를 위해 특수 토큰 null을 유연한 자리표시자로 도입하는 개념을 소개한다.
모델이 이 관례를 채택하면, 명시적으로 패딩 토큰을 사용하도록 학습받지 않았음에도 불구하고, 비어 있는 슬롯을 날조된 콘텐츠에 의존하지 않고 채울 수 있다. 이 메커니즘의 작동 원리를 더 상세히 분석하면, null 토큰의 효과는 두 가지 측면에서 발생한다. 첫째, 프롬프트 $Q^+$에 "사용할 수 없는 정보에는 null을 사용하라"는 명시적 지시가 포함됨으로써, 모델에게 "정보가 없으면 생성하지 않아도 된다"는 허가(permission)를 부여한다. 이는 dLLM이 스캐폴드의 모든 마스크 위치를 반드시 의미 있는 토큰으로 채워야 한다는 암묵적 압력을 해소한다. 둘째, "null"이라는 토큰 자체가 사전 학습 코퍼스에서 JSON의 null 값으로 빈번하게 등장하므로, 모델이 이 토큰의 의미와 사용 맥락을 이미 학습하고 있다. 따라서 별도의 미세 조정 없이도 모델은 null을 적절한 맥락에서 자연스럽게 생성할 수 있다. 이는 dLLM이 이미 사전 학습 과정에서 "null"이라는 의미적 토큰의 의미를 이해하고 있기 때문에 가능하다. 이 간단하면서도 효과적인 사전 안내는 dLLM이 환각을 실질적으로 줄일 수 있게 하며, 이것이 개선된 $S^3$ 방법의 공식화에 영감을 주었다고 논문은 서술한다. 이러한 접근의 우아함은 새로운 학습을 필요로 하지 않으면서도, 모델의 기존 어휘에 존재하는 의미적 토큰을 활용한다는 점에 있다. 흥미롭게도, 이 접근법은 자기회귀 모델에서 환각을 줄이기 위해 사용되는 "모르면 모른다고 답하라"는 지시와 유사한 메커니즘을 dLLM의 맥락에 맞게 변환한 것으로 이해할 수 있다. 자기회귀 모델에서는 이러한 지시가 프롬프트 수준에서만 작동하여 효과가 불완전할 수 있지만, dLLM에서는 null 토큰이 스캐폴드 내에서 실제로 특정 위치의 값을 대체하는 구체적인 메커니즘으로 작동하므로, 보다 체계적이고 신뢰할 수 있는 환각 방지 효과를 기대할 수 있다.
7.4 계산 복잡도 분석
dLLM의 기존 병목 중 하나는 추론 속도에 있다. 경험적으로, 다단계 디노이징 프로세스는 디퓨전 단계 수에 비례하여 증가하는 지연 시간을 도입한다. 각 단계 내에서 전역 어텐션 계산은 전체 컨텍스트 길이 $L$에 대해 이차적 비용을 발생시킨다. 결과적으로 역과정의 전체 계산 복잡도는 $\mathcal{O}(L^3)$으로 스케일링된다.
이 $\mathcal{O}(L^3)$ 복잡도는 실용적 배포에서 심각한 장벽이 된다. 예를 들어, 출력 길이가 128 토큰이고 각 어텐션 연산의 기본 비용이 일정하다고 가정하면, 전체 역과정의 비용은 $128^3 \approx 200$만 단위에 달한다. 이 비용을 완화하기 위해, 일부 구현은 블록 단위 KV-캐싱을 사용한 반자기회귀 디코딩 방식을 채택하여 계산 부담을 부분적으로 줄인다. 그러나 이 설계는 여전히 디퓨전 기반 디코딩의 핵심적 병렬성 장점을 타협한다. 논문은 이 접근이 dLLM의 본질적 강점을 훼손한다고 지적한다.
출력 구조가 알려져 있거나 근사할 수 있는 구조화된 생성 태스크의 경우, 제안된 $S^3$는 완전히 무작위 상태 대신 부분적으로 디노이징된 상태에서 역과정을 초기화하는 대안적 관점을 도입한다. 이 웜스타트 초기화(warm-start initialization)는 구조적 사전(structural prior)으로 기능하여, 생성을 가속화하고 제어 가능성을 향상시키는 언어 스캐폴드를 효과적으로 제공한다.
| 방법 | 디코딩 복잡도 | 병렬성 보존 | 구조 인식 | 비고 |
|---|---|---|---|---|
| 표준 dLLM (전체 디노이징) | $\mathcal{O}(L^3)$ | 예 | 아니오 | 완전 마스킹에서 시작 |
| 반자기회귀 디코딩 | 부분 감소 | 부분적 | 아니오 | 블록 단위 KV-캐싱 |
| $S^3$ (제안) | $\mathcal{O}(nL^2)$ | 예 | 예 | $n \ll L$, 웜스타트 초기화 |
점근적으로, $S^3$는 디코딩 복잡도를 $\mathcal{O}(nL^2)$으로 줄인다. 여기서 $n$은 실제로 $L$보다 현저히 작은 조정 가능한 하이퍼파라미터이다. 이러한 복잡도 감소의 핵심 원리는 다음과 같다. 표준 dLLM에서는 $L$번의 디노이징 단계가 필요하고 각 단계마다 $O(L^2)$의 어텐션 비용이 발생하여 전체 $O(L^3)$이 되지만, $S^3$에서는 스캐폴드가 이미 상당 부분의 토큰을 확정하므로 필요한 디노이징 단계가 $n$으로 대폭 줄어든다. 실제 실험에서 8~16 단계만으로도 거의 완벽한 성능에 도달하는 것이 이를 실증적으로 뒷받침한다.
8. 한계점 및 향후 연구 방향: 디퓨전 언어 모델의 미래 가능성
본 논문이 dLLM의 구조화된 출력 생성에 대한 잠재력을 설득력 있게 보여주지만, 몇 가지 중요한 한계점이 존재한다. 이러한 한계점들은 향후 연구의 방향성을 제시하는 데 있어 귀중한 참고점이 된다.
첫째, 실험 범위의 제한성이 지적될 수 있다. 논문은 단일 데이터셋(WikiBio)과 단일 dLLM(LLaDA-1.5)만을 사용하여 실험을 수행하였다. WikiBio는 전기 도메인의 비교적 단순한 구조화된 출력(7개의 평탄한 JSON 필드)을 다루고 있어, 더 복잡한 중첩 구조, 배열, 조건부 필드 등을 포함하는 실세계 JSON 스키마에 대한 일반화 가능성이 검증되지 않았다. 또한 코드 생성, XML, 마크다운 테이블 등 다른 형태의 구조화된 출력에 대한 실험이 부재하다. 향후 연구에서는 더 다양한 도메인과 복잡도를 가진 벤치마크에서의 평가가 필요할 것이다.
둘째, 자기회귀 모델과의 직접 비교 부재가 아쉬운 점으로 남는다. 논문은 dLLM의 잠재력을 보여주는 데 초점을 맞추고 있지만, 동일한 규모의 자기회귀 모델(예: LLaMA, Mistral 등)과의 직접적인 성능 비교가 포함되어 있지 않다. 구조화된 출력 생성에서 dLLM이 AR 모델의 실질적인 대안이 될 수 있는지를 판단하려면, 동등한 조건에서의 비교가 필수적이다. 특히 constrained decoding이나 JSON mode를 지원하는 최신 AR 모델들과의 비교는 제안된 접근법의 상대적 위치를 더 명확히 할 수 있을 것이다.
셋째, 절대적 콘텐츠 충실도의 낮은 수준이 주목할 만하다. 실험에서 모든 방법의 정밀도, 재현율, F1 점수가 0.15 이하로 매우 낮은 수준에 머물러 있다. $S^3$가 상대적으로 우수한 성능을 보이지만, 절대적 관점에서 이 수치는 실용적 배포에 충분하지 않을 수 있다. 이는 현재 dLLM(LLaDA-1.5)의 근본적인 언어 이해 능력의 한계를 반영할 수 있으며, 더 큰 모델이나 더 나은 사전 학습을 통해 개선될 여지가 있다.
넷째, 스키마 사전 지식의 필요성이 실용적 제약으로 작용할 수 있다. $S^3$는 출력 구조가 사전에 알려져 있어야 스캐폴드를 구성할 수 있다. 이는 JSON 스키마가 명확히 정의된 API 호출이나 데이터 추출 태스크에는 적합하지만, 구조가 동적으로 결정되거나 사전에 알 수 없는 시나리오에는 적용이 어려울 수 있다. 향후 연구에서는 스키마를 자동으로 추론하거나, 부분적인 구조 정보만으로도 효과적인 스캐폴딩이 가능한 방법을 탐색할 필요가 있다.
다섯째, 논문이 제시한 정리 4.1의 이론적 보장의 강건성에 대한 추가 검증이 필요하다. 현재의 증명은 스캐폴드 토큰과 내용 토큰 간의 상호 정보(mutual information)에 대한 가정에 의존하고 있으며, 이 가정이 다양한 실제 시나리오에서 얼마나 잘 성립하는지에 대한 실증적 검증이 부족하다. 또한 스캐폴드 커버리지 비율 $|\mathcal{S}|/L$에 따른 오차 감소의 선형적 상한이 실제로 얼마나 긴밀한(tight) 것인지에 대한 분석도 흥미로운 연구 방향이 될 것이다.
여섯째, 다중 모달리티 확장의 가능성도 탐색할 가치가 있다. 최근 LLaDA-V와 같은 시각 명령 조정 dLLM이 등장하고 있어, 이미지 입력에 기반한 구조화된 출력 생성(예: 이미지에서 메타데이터 추출, 시각적 질문 응답의 구조화된 형식화 등)에 $S^3$를 적용하는 것이 가능한지 검증할 필요가 있다.
향후 연구 방향으로는 다양한 dLLM 아키텍처(Dream, Mercury 등)에 대한 $S^3$의 적용 및 일반화, 더 복잡한 구조화된 출력 형식(중첩 JSON, GraphQL, SQL 등)에 대한 확장, 학습 기반 접근법과의 결합(스캐폴드 구조를 자동으로 학습하는 메타러닝 등), 그리고 에이전트 시스템에서의 실제 배포(함수 호출, API 인터페이싱 등)가 유망한 방향으로 제시될 수 있다.
8.1 실험적 한계의 상세 분석
앞서 언급한 한계점들을 보다 구체적으로 분석하면, 실험의 제한된 범위는 여러 측면에서 결과의 해석에 주의를 요한다. WikiBio 데이터셋의 JSON 스키마는 7개의 평탄한(flat) 필드만을 포함하며, 모든 필드가 문자열 또는 null 타입이라는 단순한 구조를 가진다. 실세계의 API 스키마나 데이터 추출 태스크에서는 중첩된 객체(nested objects), 배열(arrays), 열거형(enums), 조건부 필드(conditional fields), 참조(references) 등 훨씬 복잡한 구조가 일반적이다. 예를 들어, OpenAPI 스키마를 준수하는 JSON 출력을 생성하거나, 여러 레벨의 중첩을 가진 GraphQL 응답을 구성하는 태스크에서 $S^3$가 어떤 성능을 보일지는 추가 검증이 필요하다.
또한 max_new_tokens가 128로 설정되어 있어, 이는 상대적으로 짧은 구조화된 출력에 해당한다. 수백 또는 수천 개의 토큰을 포함하는 긴 구조화된 출력(예: 대규모 테이블 데이터의 JSON 변환, 복잡한 함수 호출 체인)에서 스캐폴딩 접근법이 어떻게 스케일링되는지도 중요한 연구 질문이다. 디노이징 단계 수와 출력 길이 간의 최적 비율은 태스크에 따라 달라질 수 있으며, 이에 대한 체계적 분석이 향후 필요할 것이다.
8.2 실용적 적용 시나리오와 전망
논문의 결과를 실용적 맥락에서 바라보면, $S^3$가 가장 큰 가치를 발휘할 수 있는 시나리오는 구조가 사전에 명확히 정의된 반복적 태스크이다. 예를 들어, 특정 API의 함수 호출을 위해 정해진 JSON 스키마에 맞춰 입력을 구성하는 태스크, 데이터베이스 레코드를 표준화된 형식으로 변환하는 태스크, 또는 규격화된 보고서를 생성하는 태스크 등이 이에 해당한다. 이러한 시나리오에서는 스키마가 고정되어 있으므로 스캐폴드를 미리 준비해 둘 수 있고, 반복적 사용을 통해 스캐폴딩 구성 비용을 상쇄할 수 있다.
반면, LLM 에이전트가 다양한 도구를 동적으로 선택하고 호출하는 시나리오에서는 각 도구마다 다른 스키마에 대한 스캐폴드를 실시간으로 구성해야 하므로, 스캐폴드 생성 과정 자체의 효율성이 중요해진다. 이 경우 스키마 파싱과 스캐폴드 초기화를 자동화하는 전처리 파이프라인의 개발이 실용화의 핵심이 될 것이다. 또한 dLLM의 추론 속도가 AR 모델에 비해 여전히 느린 현 시점에서, $S^3$가 디노이징 단계를 줄여 추론을 가속한다는 점은 dLLM의 실용화 가능성을 높이는 중요한 기여이다.
더 넓은 관점에서, 본 논문은 dLLM의 연구가 아직 초기 단계에 있으며, 자기회귀 모델이 오랜 기간에 걸쳐 축적한 기술적 발전(RLHF, constrained decoding, 함수 호출 미세 조정 등)이 dLLM에도 유사하게 적용될 수 있는지에 대한 탐색이 필요함을 시사한다. $S^3$는 dLLM의 고유한 강점을 활용하는 최초의 체계적 시도 중 하나로서, 이후의 연구가 이 방향을 더욱 발전시킬 수 있는 기반을 마련하였다고 평가할 수 있다.
9. 결론: dLLM을 위한 새로운 실용적 경로
본 논문은 디퓨전 대규모 언어 모델의 전역 인식 능력을 구조화된 출력의 제어 가능한 생성에 활용하는 가능성을 탐구하였다. 논문이 제안한 Self-adaptive Schema Scaffolding($S^3$)은 역과정을 조작하고 내재된 전역 어텐션 메커니즘을 활용하여, dLLM이 완전히 제어 가능한 구조화된 출력을 적응적으로 생성하도록 안내하는 새로운 방법이다.
이 연구의 핵심적 가치는 dLLM이라는 새로운 아키텍처 패밀리에 대해, 그 고유한 강점을 식별하고 이를 실용적 태스크에 연결하는 방법론적 다리를 놓았다는 점에 있다. 자기회귀 모델이 순차적 생성의 자연스러운 특성을 활용하여 대화, 추론, 창작 등에서 뛰어난 성능을 보이는 것처럼, dLLM은 전역적 정보 접근과 반복적 정제라는 자신만의 아키텍처적 강점을 가지고 있으며, 구조화된 출력 생성이 바로 이러한 강점이 가장 잘 발현될 수 있는 태스크임을 본 논문이 설득력 있게 보여주고 있다.
포괄적인 평가 프레임워크를 통해, $S^3$가 우수한 구조적 준수(8 디노이징 단계에서 SV/FC/SC 모두 99.4%), 향상된 콘텐츠 충실도(모든 설정에서 최고 F1 점수), 그리고 감소된 환각률(최저 33.1%)을 달성함이 입증되었다. 복잡도 분석을 통해 제안된 접근법이 더 높은 수준의 제어 가능성과 환각 통제를 가능하게 하면서도 계산 효율성($\mathcal{O}(nL^2)$)을 유지함이 보여졌다.
특히 $S^3$가 디노이징 단계 수에 대해 보이는 안정성은 실용적 관점에서 매우 중요한 특성이다. 베이스라인 방법은 8단계에서 32단계로 갈수록 성능이 크게 변화하여, 각 태스크마다 최적의 단계 수를 찾아야 하는 추가적인 하이퍼파라미터 튜닝 부담이 있다. 반면 $S^3$는 8단계에서 이미 거의 최적의 성능에 도달하므로, 실무자가 계산 예산과 무관하게 일관된 품질을 기대할 수 있다. 이는 배포 시나리오에서 예측 가능한 성능 보장이라는 중요한 실용적 이점을 제공한다.
$S^3$의 방법론적 기여는 크게 두 가지 차원에서 의미가 있다. 첫째, 구조화된 출력 생성 문제를 "빈칸 채우기"로 재정식화하여, dLLM의 아키텍처적 강점(전역 어텐션, 반복적 정제, 병렬 생성)을 자연스럽게 활용하는 방법을 제시하였다. 둘째, null 토큰이라는 간단한 의미적 장치를 통해 가변 길이 필드와 누락 정보의 문제를 학습 없이 해결하는 우아한 접근법을 보여주었다. 논문은 이러한 발견들이 dLLM을 제어 가능한 생성 태스크를 위한 유망한 대안으로 확립한다고 결론짓는다. 특히 본 연구가 ICLR 2026에 게재된다는 점은, dLLM 연구가 학계에서 주요 연구 방향으로 인정받고 있음을 보여주는 의미 있는 신호이다. LLaDA, Dream, Mercury 등의 최근 dLLM들이 빠르게 발전하고 있는 상황에서, $S^3$와 같은 추론 시간 기법(inference-time technique)은 이러한 모델들의 실용적 가치를 크게 높일 수 있는 핵심 요소가 될 것이다.
종합적으로, 본 논문은 디퓨전 언어 모델이 단순히 자기회귀 모델의 대안이 아니라, 특정 태스크(특히 구조화된 출력 생성)에서 고유한 아키텍처적 강점을 발휘할 수 있는 차별화된 도구임을 설득력 있게 보여준다. 자기회귀 모델과 디퓨전 모델이 각자의 강점을 활용하여 상호 보완적으로 활용되는 미래의 하이브리드 AI 시스템을 향한 중요한 첫걸음이라고 평가할 수 있다.
10. 요약 정리
- 연구 동기: 자기회귀 LLM은 좌에서 우로의 순차 생성, 비가역적 토큰 커밋, 순차적 의존성이라는 아키텍처적 한계로 인해 구조화된 출력(JSON, XML 등) 생성에서 불안정한 성능을 보인다.
- 핵심 통찰: 디퓨전 기반 대규모 언어 모델(dLLM)의 전역 어텐션 메커니즘과 반복적 정제 능력이 구조화된 출력 생성에 본질적으로 유리한 아키텍처적 이점을 제공한다.
- Schema Scaffolding ($S^2$): 구조적 사양을 파싱하여 불변 요소를 고정하고 가변 위치를 마스크 토큰으로 대체하는 스캐폴드를 구성, 제약 없는 생성을 구조화된 빈칸 채우기로 변환한다.
- Self-adaptive Schema Scaffolding ($S^3$): null 토큰을 의미적 자리표시자로 활용하여 가변 길이 필드와 누락 정보를 학습 없이 처리하는 적응적 확장 방법으로, $S^2$의 환각 문제를 해결한다.
- 이론적 보장: 정리 4.1을 통해 스캐폴딩이 스캐폴드 커버리지 비율에 비례하여 기대 디노이징 오차를 감소시킴을 수학적으로 증명하였다.
- 구조적 준수 결과: $S^3$는 8 디노이징 단계에서 SV/FC/SC 모두 99.4%를 달성하여, 베이스라인(31~35%)을 압도적으로 능가한다.
- 콘텐츠 충실도 결과: 모든 디노이징 설정에서 최고 F1 점수를 달성하며, "과사고(overthinking)" 현상 없이 안정적인 성능을 유지한다.
- 사실 충실도 결과: 환각률을 베이스라인 대비 약 18% 감소시키며(0.404 → 0.331), 바닐라 $S^2$의 환각 증가 문제(0.465)를 효과적으로 해결한다.
- 계산 효율성: 디코딩 복잡도를 $\mathcal{O}(L^3)$에서 $\mathcal{O}(nL^2)$으로 감소시키며, $n \ll L$이므로 실질적인 추론 가속을 달성한다.
- 의의: dLLM을 제어 가능한 생성 태스크의 유망한 대안으로 확립하며, 구조적 준수, 콘텐츠 충실도, 사실 충실도를 포괄하는 새로운 3차원 평가 프레임워크를 제시한다.