d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning
https://arxiv.org/abs/2504.12216
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, Aditya Grover | UCLA, Meta AI | arXiv:2504.12216 | 2025년 4월 | NeurIPS 2025
1. 서론: 확산 언어 모델에 강화학습 기반 추론을 도입하다
최근 대형 언어 모델(LLM) 분야에서 가장 주목받는 발전 중 하나는 강화학습(Reinforcement Learning, RL)을 통해 모델의 추론 능력을 비약적으로 향상시킨 것이다. DeepSeek-R1, OpenAI o1, Kimi K1.5 등의 모델은 온라인 강화학습을 적용하여 수학적 추론, 코딩, 논리적 문제 해결 등에서 놀라운 성과를 보여주었다. 그러나 이러한 RL 기반 추론 능력의 향상은 지금까지 자기회귀(Autoregressive, AR) 생성 패러다임에만 국한되어 왔다. AR 모델은 왼쪽에서 오른쪽으로 토큰을 순차적으로 생성하는 방식으로, 시퀀스 로그 확률을 체인 룰(chain rule)을 통해 자연스럽게 분해할 수 있어 GRPO나 PPO와 같은 정책 경사(policy gradient) 알고리즘의 적용이 비교적 용이했다.
한편, 확산 기반 대형 언어 모델(Diffusion Large Language Models, dLLMs)은 텍스트 생성의 비자기회귀적 대안으로 부상하고 있다. dLLM은 완전히 마스킹된 시퀀스에서 시작하여 반복적인 디노이징(denoising) 과정을 통해 텍스트를 점진적으로 생성하며, 양방향 어텐션(bidirectional attention)을 활용하여 과거와 미래 문맥을 동시에 참조할 수 있다는 구조적 장점을 가지고 있다. LLaDA, Dream, Mercury 등 최근의 dLLM은 유사한 크기의 AR 모델과 경쟁할 수 있는 언어 모델링 성능을 입증했지만, RL 기반 사후 훈련(post-training)은 아직 탐구되지 않은 영역으로 남아 있었다. 이러한 상황은 중요한 연구 질문을 제기한다. 비자기회귀적 생성 패러다임에서도 RL을 통한 추론 능력 향상이 가능한가?
이 질문에 대한 답은 학술적 호기심을 넘어 실용적 중요성을 가진다. dLLM은 양방향 어텐션을 통한 전역적 문맥 활용, 병렬 디코딩 가능성, 코드-파인(coarse-to-fine) 생성 등 AR 모델과는 근본적으로 다른 특성을 가지며, 이러한 특성이 특정 유형의 추론 과제에서 이점을 제공할 수 있기 때문이다. UCLA와 Meta AI의 연구진은 이 질문에 답하기 위해 d1이라는 프레임워크를 제안한다. d1은 사전 훈련된 마스크 기반 dLLM을 추론 모델로 변환하기 위한 2단계 사후 훈련 파이프라인으로, (1) 고품질 추론 트레이스에 대한 마스크 지도 미세조정(Masked SFT)과 (2) 마스크 dLLM을 위한 새로운 정책 경사 기반 RL 알고리즘인 diffu-GRPO를 순차적으로 적용한다. diffu-GRPO는 dLLM에 정책 경사 방법론을 통합한 최초의 시도로, 마스크 dLLM의 시퀀스 로그 확률을 효율적으로 추정하기 위한 평균장 근사(mean-field approximation)와 1단계 토큰별 로그 확률 추정(one-step per-token log probability estimation)이라는 핵심 기술적 기여를 포함한다. 논문은 LLaDA-8B-Instruct 모델에 d1을 적용하여 수학 및 계획 벤치마크에서 일관된 성능 향상을 달성했음을 보여준다.
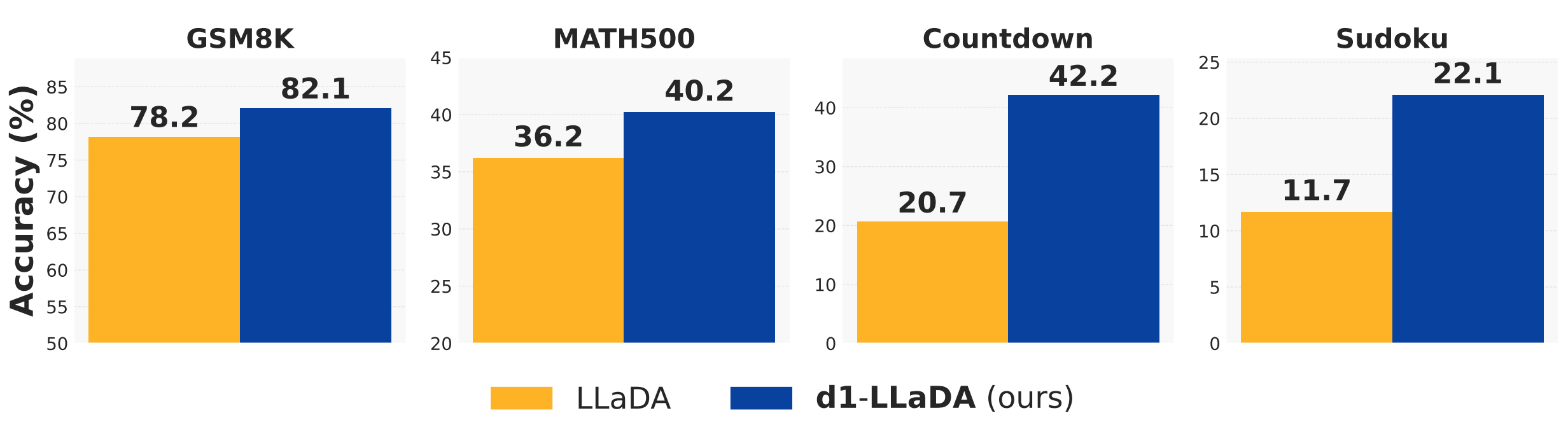
Figure 1: 네 가지 수학 및 계획 과제에서 d1-LLaDA(SFT + diffu-GRPO)가 기본 LLaDA-8B-Instruct 모델을 일관되게 능가한다. GSM8K에서 78.2%→82.1%, MATH500에서 36.2%→40.2%, Countdown에서 20.7%→42.2%(2배 이상), Sudoku에서 11.7%→22.1%(약 2배)의 성능 향상을 달성했다.
Figure 1은 d1 프레임워크의 핵심 결과를 시각적으로 보여준다. 네 가지 벤치마크 모두에서 d1-LLaDA가 기본 LLaDA-8B-Instruct 모델 대비 유의미한 성능 향상을 달성했으며, 특히 계획(planning) 과제인 Countdown과 Sudoku에서는 거의 2배에 가까운 성능 향상을 기록했다. 이 결과는 강화학습 기반 추론 향상이 자기회귀 모델에만 국한되지 않으며, 확산 언어 모델에서도 효과적으로 작동할 수 있음을 최초로 실증적으로 입증한 것이다.
2. 배경 및 관련 연구: 확산 언어 모델과 LLM 추론의 교차점
d1의 기술적 기여를 이해하기 위해서는 두 가지 연구 흐름의 교차점을 파악할 필요가 있다. 하나는 확산 기반 언어 모델링의 발전이고, 다른 하나는 강화학습을 통한 LLM 추론 능력 향상이다. 전통적으로 이 두 연구 흐름은 독립적으로 발전해 왔으며, AR 패러다임의 지배적 위치로 인해 RL 기반 추론 기법은 주로 AR 모델에 맞추어 설계되어 왔다. d1은 이 두 흐름을 최초로 결합하는 시도로서, 각 배경에 대한 깊이 있는 이해가 d1의 기술적 기여를 올바르게 평가하기 위해 필수적이다.
2.1 마스크 확산 대형 언어 모델(Masked dLLMs)
마스크 확산 언어 모델은 이산 확산(discrete diffusion)의 한 형태로, 토큰 시퀀스를 점진적으로 마스크 토큰으로 손상시키는 순방향 과정(forward process)과 이를 역으로 복원하는 역방향 과정(reverse process)으로 구성된다. 시간 $t \in [0, 1]$로 인덱싱되는 순방향 과정에서, 시퀀스 $x_t$의 각 토큰이 마스킹되지 않을 확률은 $\alpha_t$로 정의되며, $\alpha_t$는 $t$에 대해 단조 감소한다. $t = 0$에서는 모든 토큰이 원본 상태이고, $t = 1$에서는 모든 토큰이 마스킹된 상태가 된다. 각 토큰의 조건부 분포는 다음과 같이 정의된다:
$$q_{t|0}(x_t^i | x_0^i) = \begin{cases} 1 - \alpha_t, & x_t^i = \text{mask} \\ \alpha_t, & x_t^i = x_0^i \end{cases}$$
모델 $f_\theta$는 양방향 언마스킹 예측기(bidirectional unmasking predictor)로 파라미터화되어, 마스킹된 토큰을 원본 토큰으로 복원하는 방법을 학습한다. 학습 목표 함수는 음의 증거 하한(Negative Evidence Lower Bound, NELBO)으로, 이는 음의 로그 가능도(NLL)의 상한이다. 특히 본 논문에서 사용하는 LLaDA 모델은 선형 노이즈 스케줄 $\alpha_t = 1 - t$를 채택하여, NELBO가 다음과 같은 가중 NLL로 단순화된다:
$$-\mathbb{E}_{t \sim \mathcal{U}[0,1), \, x_0 \sim p_{\text{data}}, \, x_t \sim q_{t|0}(x_t|x_0)} \left[ \frac{1}{t} \sum_{k=1}^{|x_t|} \mathbf{1}[x_t^k = \text{mask}] \log f_\theta(x_0^k | x_t) \right]$$
이 손실 함수에서 핵심적인 점은 마스킹된 토큰에 대해서만 손실이 계산된다는 것이다. BERT와의 핵심 차이점은 마스킹 비율에 있다. BERT는 고정된 마스킹 비율(15%)을 사용하고 단일 단계 인필링(infilling)으로 디코딩하는 반면, 마스크 dLLM은 시간에 따라 변하는 마스킹 비율을 사용하고 순수 노이즈(전체 마스킹)에서 시작하는 다단계 디코딩 과정을 거치므로 진정한 생성 모델이 된다. 역방향 과정에서 시간 $t$에서 $s$ ($0 \le s < t \le 1$)로의 전이 확률은 마스킹된 토큰과 마스킹되지 않은 토큰에 대해 각각 다른 규칙을 따른다. 이 전이 확률은 다음과 같이 정의된다:
$$q_{s|t}(x_s^i | x_t) = \begin{cases} 1, & x_t^i \neq \text{mask},\; x_s^i = x_t^i \\ \frac{1 - \alpha_s}{1 - \alpha_t}, & x_t^i = \text{mask},\; x_s^i = \text{mask} \\ \frac{\alpha_s - \alpha_t}{1 - \alpha_t} q_{0|t}(x_s^i | x_t), & x_t^i = \text{mask},\; x_s^i \neq \text{mask} \\ 0, & \text{otherwise} \end{cases}$$
이 전이 확률에서 중요한 속성은, 한 번 마스킹된 토큰은 마스킹 상태를 유지하거나 원래 토큰으로 복원될 수 있지만, 마스킹되지 않은 토큰은 변하지 않는다는 것이다. $q_{0|t}(x_s^i | x_t)$ 함수가 바로 언어 모델이 추정하는 대상으로, 마스킹된 토큰이 주어진 문맥에서 원래 어떤 토큰이었는지를 예측한다. 선행 연구에서는 모델이 시간 단계 $t$를 명시적 입력으로 받을 필요가 없음을 발견했는데, 이는 마스크 토큰의 수가 암묵적으로 시간 정보를 제공하기 때문이다.
2.2 그룹 상대 정책 최적화(GRPO)와 AR 모델의 강화학습
정책 경사 방법론은 LLM의 사후 훈련 단계에서 성능을 향상시키기 위해 널리 채택되어 왔다. 근접 정책 최적화(Proximal Policy Optimization, PPO)가 온라인 RL의 주된 접근법이었지만, 상태 가치 함수 $V$를 공동으로 훈련해야 하므로 계산 비용이 증가하는 단점이 있었다. 그룹 상대 정책 최적화(Group Relative Policy Optimization, GRPO)는 그룹 통계를 활용하여 어드밴티지를 추정함으로써 비평가 모델(critic model) 없이도 효율적인 훈련을 가능하게 하는 대안이다.
GRPO의 핵심 아이디어는 각 질문 $q$에 대해 이전 정책 $\pi_{\theta_{\text{old}}}$에서 $G$개의 응답 $\{o_1, o_2, \ldots, o_G\}$를 샘플링한 후, 정규화된 보상을 어드밴티지로 사용하는 것이다. 구체적으로, 각 응답 $o_i$의 모든 토큰 $k$에 대한 비정규화 어드밴티지(unnormalized advantage)는 다음과 같이 정의된다:
$$A_i^k(\pi) = r_i(\pi) - \text{mean}(\{r_j(\pi)\}_{j=1}^G), \quad 1 \le k \le |o_i|$$
여기서 $\text{mean}(\{r_j\}_{j=1}^G)$는 가치 함수 $V(q)$의 $G$-샘플 몬테카를로 추정으로 해석될 수 있으며, 희소 보상 $r_i$는 (비할인) 상태-행동 가치 $Q(q, o_i)$로 볼 수 있다. GRPO의 목적 함수는 PPO와 유사한 클리핑 메커니즘으로 정책 업데이트를 조절하고, 참조 정책과의 과도한 이탈을 방지하기 위한 역 KL 페널티를 포함한다:
$$\mathcal{L}_{\text{GRPO}}(\theta) = \mathbb{E}_{q \sim \mathcal{D}, \, o_1,...,o_G \sim \pi_\theta(\cdot|q)} \left[ \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|o_i|} \sum_{k=1}^{|o_i|} \min\left(\rho_i^k A_i^k, \text{clip}(\rho_i^k, 1-\varepsilon, 1+\varepsilon) A_i^k\right) - \beta D_{\text{KL}}[\pi_\theta(\cdot|q) \| \pi_{\text{ref}}(\cdot|q)] \right]$$
이 목적 함수에서 $\rho_i^k = \frac{\pi_\theta(o_i^k | q, o_{<k}^i)}{\pi_{\theta_{\text{old}}}(o_i^k | q, o_{<k}^i)}$는 중요도 비율(importance ratio)이며, 이를 계산하려면 토큰 수준의 로그 확률이 필요하다. AR 모델에서는 이를 순차적 분해(sequential factorization)를 통해 단일 순방향 패스로 쉽게 계산할 수 있다: $\log \pi_{\text{AR}}(o|q) = \sum_{k=1}^{|o|} \log \pi_{\text{AR}}(o^k | q, o_{<k})$. 그러나 dLLM은 이러한 순차적 분해를 따르지 않으며, 디코딩 과정이 언마스킹 예측기 $f_\theta$를 여러 번 호출하므로 토큰별 로그 확률 계산도 비용이 크다. 이것이 바로 d1이 해결해야 하는 핵심 기술적 도전이다. 기존의 RL 기법을 dLLM에 적용하려면, 이 로그 확률 계산의 병목을 효율적으로 해결하는 새로운 추정 기법이 반드시 필요하며, 이것이 d1의 핵심적인 기술적 기여 영역이 된다.
2.3 확산 언어 모델 연구의 흐름
확산 모델은 시각적 영역에서 큰 성공을 거두었지만, 텍스트의 이산적 특성으로 인해 언어에의 적용은 제한적이었다. 초기 접근법은 텍스트 잠재 변수(latent)에 대한 연속 확산 모델을 학습하려 했으나 확장성과 이산화 문제에 직면했다. 마스크 확산은 이산 확산의 효과적인 변형으로 확립되었으며, DiffuLLaMA는 사전 훈련된 LLaMA 가중치를 활용하여 이 접근법을 대규모로 확장했다. Ye 등의 연구는 확산 언어 모델에서 연쇄적 사고(Chain-of-Thought, CoT) 추론을 생성하는 방법을 탐구했고, Block Diffusion은 시퀀스를 블록 단위로 모델링하면서 각 블록 내에서 확산을 적용하는 하이브리드 접근법을 제안했다. 최근 LLaDA와 Dream은 대규모 dLLM이 유사한 크기의 AR 모델과 경쟁할 수 있음을 보여주었지만, RL을 통한 추론 능력 강화는 아직 탐구되지 않은 영역이었다.
LLM의 추론 능력을 향상시키는 접근법은 크게 두 범주로 나뉜다. 하나는 고품질 추론 트레이스에 대한 지도 미세조정(SFT)이며, 다른 하나는 강화학습(RL)이다. Chu 등의 연구는 SFT 기반 추론이 암기(memorization)에 의존하는 경향이 있는 반면, RL 방법이 새로운 시나리오로의 전이(transfer)에서 더 나은 일반화를 달성한다는 것을 보여주었다. DeepSeek-R1-Zero는 SFT 없이 RL만으로도 강력한 추론 능력이 출현할 수 있음을 입증했다. 이산 확산 모델에서의 이전 RL 연구로는 Zekri와 Boullé의 작업이 있지만, 이는 구체적 점수 매칭(concrete score matching)에 기반하며 마스크 목적 함수를 대상으로 하지 않았다. 본 논문의 d1은 대규모 마스크 dLLM에 정책 경사 RL을 적용한 최초의 연구라는 점에서 차별화된다.
3. 방법론: d1 — 마스크 dLLM을 추론 모델로 변환하는 2단계 프레임워크
d1은 사전 훈련된 마스크 dLLM의 추론 성능을 향상시키기 위해 SFT와 온라인 RL을 순차적으로 결합하는 2단계 프레임워크이다. 이 설계는 AR 모델에서 입증된 "SFT로 기초 능력 함양 후 RL로 일반화 강화"라는 패러다임을 dLLM에 처음으로 적용한 것이다. 그러나 이 과정에서 AR 모델과 dLLM의 근본적인 구조적 차이를 극복해야 하는 기술적 도전이 존재한다. 그러나 AR 모델에서 성공적으로 적용된 GRPO의 학습 공식화가 dLLM에 직접 일반화되지 않는다는 근본적인 도전이 존재한다. GRPO 목적 함수는 토큰 수준과 시퀀스 수준 모두에서 $\pi_\theta$와 $\pi_{\theta_{\text{old}}}$의 (로그-)가능도 비율 계산을 요구하는데, dLLM은 AR 분해를 따르지 않기 때문이다. 이 문제를 해결하기 위해 d1은 세 가지 핵심 구성 요소를 제안한다: (1) 효율적인 로그 확률 추정, (2) diffu-GRPO 알고리즘, (3) 마스크 SFT 레시피이다.
3.1 마스크 dLLM을 위한 효율적 로그 확률 추정
d1의 첫 번째 핵심 기술적 기여는 마스크 dLLM에서 시퀀스 수준과 토큰 수준의 로그 확률을 효율적으로 추정하는 방법이다. AR 모델과 달리 dLLM은 토큰 시퀀스를 전체적으로 처리하므로, 시퀀스 수준 로그 확률에 대한 AR 분해가 존재하지 않는다. 기존 LLaDA의 로그 확률 추정 방법은 몬테카를로 샘플 크기 128을 사용하는 근사법으로, 수백 번의 순방향 패스가 필요한 거대한 계산 그래프를 생성하여 정책 최적화가 비효율적이고 메모리 사용량이 과도해지는 문제가 있었다. d1은 이 문제를 두 가지 핵심 기법으로 해결한다.
시퀀스 로그 확률의 평균장 근사(Mean-Field Approximation)는 dLLM의 시퀀스 수준 로그 확률을 독립적인 토큰별 로그 확률의 합으로 분해하는 방법이다. 구체적으로, 시퀀스 로그 확률 $\log \pi_\theta(o|q)$를 다음과 같이 근사한다:
$$\log \pi_\theta(o|q) \approx \sum_{k=1}^{|o|} \log \pi_\theta(o^k | q)$$
이 근사는 각 토큰의 생성이 다른 토큰과 독립적이라고 가정하는 평균장 분해(mean-field decomposition)에 기반한다. AR 모델의 체인 룰 분해가 조건부 확률을 정확히 계산하는 것과 달리, 이 근사는 토큰 간 의존성을 무시하지만, dLLM의 반복적 디노이징 과정에서 직접적인 순차적 분해가 불가능한 상황에서 계산 가능한 대안을 제공한다. 이 평균장 근사가 성공적으로 작동하는 것은 마스크 dLLM의 각 디노이징 단계에서 토큰별 예측이 이미 상당한 수준의 독립성을 가지기 때문으로 해석할 수 있다. 물론 이 근사는 토큰 간 상호 의존성을 무시하는 편향(bias)을 도입하지만, 정책 경사 추정의 맥락에서 이 편향은 분산(variance)의 감소와 계산 효율의 향상으로 보상된다. 이는 강화학습에서 흔히 관찰되는 편향-분산 트레이드오프(bias-variance tradeoff)의 전형적인 예시이다.
기존 LLaDA 논문에서 제안된 로그 확률 추정 방법과의 비교를 통해 d1의 접근법이 가지는 이점을 더 명확히 이해할 수 있다. LLaDA의 Algorithm 3에서는 128개의 몬테카를로 샘플을 사용하여 로그 확률을 추정하는데, 이는 128번의 순방향 패스에 해당하는 거대한 계산 그래프를 생성한다. 이 방법은 추정의 정확도는 높을 수 있지만, 온라인 RL에서의 반복적인 정책 업데이트에 적용하기에는 메모리 사용량과 계산 시간 면에서 실행 불가능한 수준이다. d1의 1단계 추정은 이를 단일 순방향 패스로 대체함으로써, 정확도를 약간 희생하는 대신 RL 훈련을 현실적으로 가능하게 만든다.
프롬프트 마스킹을 통한 1단계 토큰별 로그 확률 추정(One-Step Per-Token Log Probability Estimation with Prompt Masking)은 $f_\theta$를 단 한 번만 호출하여 토큰별 로그 확률을 추정하는 방법이다. 프롬프트 $q$가 주어지면, 디코딩 과정은 $q \oplus \text{mask} \oplus \cdots \oplus \text{mask}$에서 시작한다. 완성(completion) $o$의 로그 확률을 계산하기 위해, 프롬프트 $q$의 각 토큰을 확률 $p_{\text{mask}}$로 무작위 마스킹하여 새로운 프롬프트 $q'$를 생성한다. 그런 다음 1단계 언마스킹을 수행하여 $\log f_\theta(o^k | q' \oplus \text{mask} \cdots \oplus \text{mask})$를 얻고, 이를 $\log \pi_\theta(o^k | q)$의 추정값으로 사용한다. 이 접근법의 핵심적인 이점은 기존 LLaDA의 128회 몬테카를로 샘플링 대신 단일 순방향 패스만으로 추정이 가능하다는 것이다.
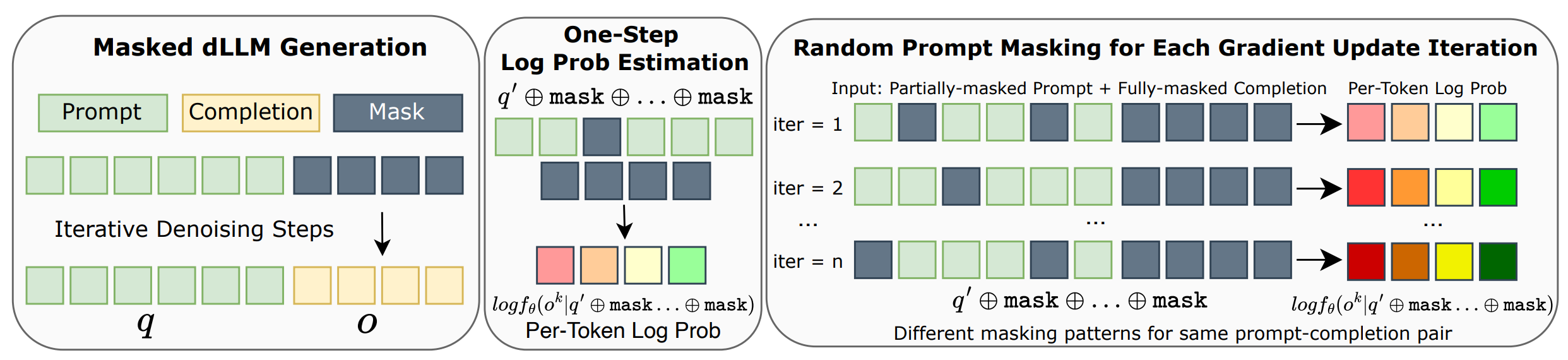
Figure 2: diffu-GRPO에서의 로그 확률 추정. 전체 확산 디노이징으로 완성 o를 생성한 후(왼쪽), 마스킹 패턴당 단일 순방향 패스로 토큰별 로그 확률을 계산하고(중앙), 각 경사 업데이트 반복마다 프롬프트에 무작위 마스킹 패턴을 적용하여 다양한 추정값을 생성한다(오른쪽). 색상의 그라디언트는 각 마스킹 패턴이 서로 다른 토큰별 로그 확률 추정값을 산출함을 보여준다.
Figure 2는 diffu-GRPO의 로그 확률 추정 과정을 세 단계로 시각화한다. 왼쪽 패널은 마스크 dLLM이 부분적으로 마스킹된 프롬프트와 완전히 마스킹된 완성 영역에서 시작하여 반복적 디노이징을 통해 완성 텍스트를 생성하는 과정을 보여준다. 중앙 패널은 생성된 완성에 대한 토큰별 로그 확률을 단일 순방향 패스로 추정하는 방법을 보여주며, 오른쪽 패널은 각 경사 업데이트 반복(iter = 1, 2, ..., n)마다 프롬프트에 서로 다른 무작위 마스킹 패턴을 적용하여 동일한 (프롬프트, 완성) 쌍에서 다양한 로그 확률 추정값을 생성하는 과정을 보여준다. 이러한 확률적 마스킹은 정책 최적화를 위한 정규화(regularization) 효과를 제공하며, 배치당 더 많은 경사 업데이트를 가능하게 하여 온라인 생성 횟수를 줄이는 효과를 가진다.
3.2 diffu-GRPO: 마스크 dLLM을 위한 정책 경사 최적화
3.1절에서 제안한 로그 확률 추정기를 사용하여, 논문은 GRPO를 마스크 dLLM으로 확장한 diffu-GRPO를 도입한다. 이 추정 기법은 PPO나 REINFORCE 등 다른 정책 경사 방법에도 널리 적용할 수 있지만, 본 논문에서는 GRPO 기반 확장에 초점을 맞춘다. $\phi_{\pi_\theta}(o^k | q')$와 $\phi_{\pi_\theta}(o | q')$를 각각 $\pi_\theta$에 대한 추정된 토큰별 및 시퀀스 확률이라 하면, diffu-GRPO의 손실 함수는 다음과 같이 정의된다:
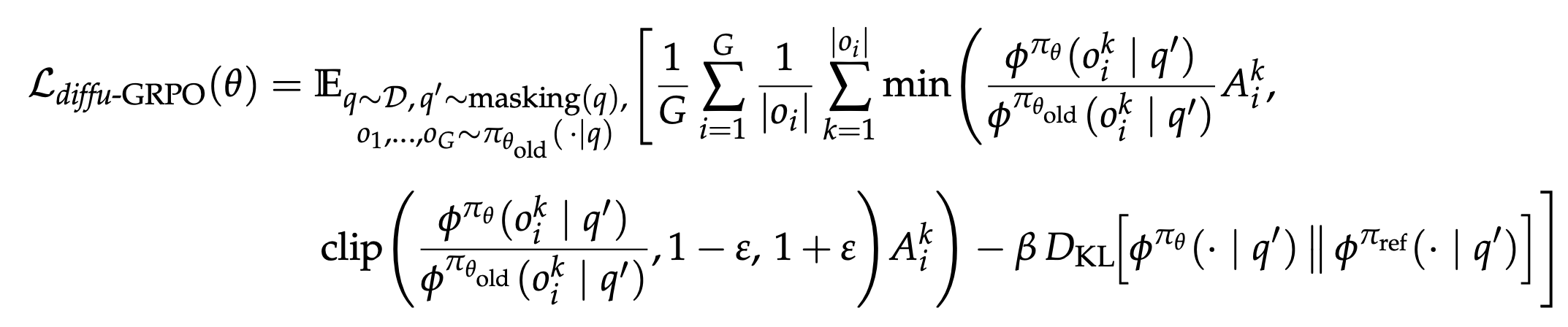
Figure 3: diffu-GRPO의 손실 함수. GRPO를 마스크 dLLM에 적용하기 위해, AR 모델의 정확한 로그 확률 대신 평균장 근사와 1단계 추정에 기반한 $\phi$ 함수를 사용하며, 무작위 마스킹된 프롬프트 $q'$에 대해 기대값을 취한다.
diffu-GRPO 손실 함수는 원래 GRPO의 구조를 유지하면서, AR 모델의 정확한 토큰 수준 로그 확률을 마스킹 기반 추정 함수 $\phi$로 대체한 것이다. 기대값은 데이터 분포 $\mathcal{D}$에서 샘플링된 프롬프트 $q$, 마스킹 함수로 생성된 $q'$, 그리고 이전 정책에서 샘플링된 $G$개의 완성에 대해 취해진다. PPO 스타일의 클리핑된 대리 목적 함수(clipped surrogate objective)는 중요도 비율 $\frac{\phi_{\pi_\theta}(o_i^k | q')}{\phi_{\pi_{\theta_{\text{old}}}}(o_i^k | q')}$와 어드밴티지 $A_i^k$의 곱에 적용되며, 클리핑 파라미터 $\varepsilon$로 정책 업데이트의 크기를 제한한다. KL 발산 페널티 항은 가중치 $\beta$로 현재 정책과 참조 정책 간의 이탈을 제어한다. 여기서 $\varepsilon$은 클리핑 파라미터로 정책 업데이트의 안정성을 보장하며, $\beta$는 KL 발산 정규화의 강도를 결정한다. 원래 GRPO와의 핵심적 차이점은 AR 모델의 정확한 토큰 수준 조건부 확률 대신 마스킹 기반 추정 함수 $\phi$를 사용한다는 것과, 기대값이 마스킹 함수에서 생성된 $q'$에 대해서도 취해진다는 것이다. 이 두 가지 수정은 dLLM의 비자기회귀적 특성에 맞춰 GRPO를 적응시키기 위한 핵심적 변화이다.

Figure 4: Algorithm 1 — diffu-GRPO의 전체 알고리즘. 참조 모델에서 초기화 후, 반복적으로 프롬프트를 샘플링하고, G개의 완성을 생성하며, 보상과 어드밴티지를 계산한 뒤, $\mu$번의 내부 경사 업데이트를 수행한다. 각 업데이트마다 프롬프트에 무작위 마스킹을 적용하여 다양한 관점을 생성한다.
Algorithm 1은 diffu-GRPO의 전체 절차를 보여준다. 알고리즘은 참조 모델 $\pi_{\text{ref}}$에서 초기화한 후, 수렴할 때까지 다음 과정을 반복한다: (1) 이전 정책을 저장하고, (2) 프롬프트를 샘플링하며, (3) $G$개의 완성을 생성하고, (4) 각 완성에 대해 보상과 어드밴티지를 계산한 뒤, (5) $\mu$번의 경사 업데이트 반복을 수행한다. 각 경사 업데이트 반복에서는 프롬프트를 확률 $p_{\text{mask}}$로 무작위 마스킹하고, 마스킹된 프롬프트에 대해 로그 확률을 추정하여 diffu-GRPO 목적 함수를 계산하고 경사 하강법으로 정책을 업데이트한다.
온라인 RL에서 배치당 경사 업데이트 횟수 $\mu$를 결정하는 것은 핵심적인 설계 선택이다. 기존 PPO나 GRPO에서는 $\mu$가 너무 높으면 배치 내 과적합(overfitting)이 발생하고, 너무 낮으면 수렴이 느려진다. diffu-GRPO의 로그 확률 추정기는 이 딜레마에 대한 고유한 해결책을 제공한다. 각 경사 업데이트 단계에서 프롬프트 $q$를 무작위로 $q'$로 마스킹하여 로그 확률을 추정하므로, 이 확률적 마스킹은 동일한 (프롬프트, 완성) 쌍에 대한 섭동된 관점(perturbed views)을 생성하여 정책 최적화의 정규화 역할을 한다. 이는 데이터 증강(data augmentation)의 한 형태로도 볼 수 있으며, 동일한 데이터에서 더 많은 학습 신호를 추출할 수 있게 한다. 실험적으로 이 접근법은 마스크 확산 모델에 고유한 장점으로, $\mu$를 훨씬 더 높은 값(12 또는 24)으로 확장하면서도 안정적인 학습 역학을 유지할 수 있게 하며, 이는 수렴에 필요한 외부 배치 반복 횟수와 온라인 생성 횟수를 줄여 계산 비용을 크게 감소시킨다.
3.3 추론 데이터에 대한 마스크 지도 미세조정(Masked SFT)
d1의 첫 번째 단계는 LLaDA 모델을 s1K 데이터셋에 대해 지도 미세조정하는 것이다. s1K는 Muennighoff 등이 제안한 "s1: Simple test-time scaling" 연구에서 도입된 데이터셋으로, 단 1,000개의 고품질 추론 질문만으로도 효과적인 추론 능력 향상이 가능함을 보여준 바 있다. 이 데이터셋의 추론 트레이스는 상세한 단계별 문제 해결 과정을 보여주며, 특히 중간 결과에 대한 자기 검증(self-verification)과 오류 발견 시 이전 단계로 돌아가는 백트래킹(backtracking) 행동을 명시적으로 포함한다. 이러한 메타인지적 추론 패턴이 SFT를 통해 dLLM에도 전이될 수 있다는 점이 d1의 핵심 가설 중 하나이다. SFT 알고리즘은 마스크 dLLM의 학습 과정을 따르되, 훈련 중에 토큰을 시간에 따라 변하는 스케줄에 의해 무작위로 마스킹하고, 모델이 문맥이 주어졌을 때 원래 토큰을 예측하도록 최적화한다.

Figure 5: Algorithm 2 — LLaDA의 지도 미세조정(SFT). 언마스킹 예측기 $f_\theta$를 데이터 분포에서 샘플링한 프롬프트-응답 쌍과 무작위 시간 단계를 사용하여, 부분적으로 마스킹된 응답에서 원본 토큰을 예측하도록 훈련한다. 손실은 마스킹된 토큰에 대해서만 계산된다.
Algorithm 2에서 보이는 바와 같이, SFT 과정은 다음과 같이 진행된다. 먼저 데이터 분포에서 프롬프트-응답 쌍 $(p_0, r_0)$과 균일 분포에서 시간 단계 $t$를 샘플링한다. 그런 다음 순방향 과정 $q_{t|0}$에 따라 응답을 부분적으로 마스킹하여 $r_t$를 생성한다. 손실 함수는 마스킹된 위치에서만 계산되며, 모델이 프롬프트 $p_0$과 부분적으로 마스킹된 응답 $r_t$의 연결(concatenation)이 주어졌을 때 원본 토큰을 예측하도록 한다:
$$\mathcal{L}(\theta) = -\frac{1}{t \cdot |r_0|} \sum_{i=1}^{|r_0|} \mathbf{1}[r_t^i = \text{mask}] \log f_\theta(r_0^i | p_0 \oplus r_t)$$
논문은 SFT가 실질적으로 효과적으로 작동하기 위해 여러 설계 선택이 신중하게 고려되어야 한다고 서술한다. 특히 LLaDA-Instruct가 최대 4,096 토큰의 시퀀스에 대해 사전 훈련되었기 때문에 s1K의 긴 시퀀스를 4,096 토큰으로 잘라야 했으며, 이러한 잘린 시퀀스(truncated sequences)의 처리가 중요한 실용적 고려사항이었다. 또한 PAD 토큰에 대한 손실 계산도 중요한 설계 요소로, LLaDA가 생성을 효과적으로 종료하기 위해서는 PAD 토큰에 대한 손실을 포함해야 한다. GPU 제약 환경에서 작은 배치 크기를 사용할 때는 배치 내 가장 긴 시퀀스 길이가 아닌 모델의 최대 길이로 패딩하는 것이 더 나은 성능을 보였는데, 이는 충분한 수의 PAD 토큰이 손실에 고려되어야 하기 때문이다. 데이터셋 난이도 또한 중요한 요소로, 약한 모델에는 쉬운 문제와 어려운 문제의 적절한 조합이 필요하며, 지나치게 어려운 데이터셋을 사용하면 과적합으로 인해 성능이 저하되는 현상이 관찰되었다.
4. 실험 설정: 모델, 과제, 훈련 구성
d1의 실험은 마스크 dLLM에서의 추론 능력 확장을 종합적으로 이해하기 위해 설계되었다. 논문은 세 가지 핵심 연구 질문에 답하고자 한다: (1) 추론 트레이스에 대한 SFT와 diffu-GRPO의 적용이 각각 독립적으로 LLaDA의 추론 능력을 어떻게 향상시키는가? (2) SFT와 diffu-GRPO를 결합하여 d1-LLaDA를 만들면 어떤 추가적인 이득을 얻을 수 있는가? (3) diffu-GRPO에서 제안된 무작위 마스킹 기반 로그 확률 추정과 마스킹 확률 $p_{\text{mask}}$가 훈련 효율성과 안정성에 어떤 영향을 미치는가? 이러한 질문에 체계적으로 답하기 위해 다양한 과제, 시퀀스 길이, 훈련 레시피에 걸친 포괄적인 실험을 수행한다.
4.1 데이터셋 및 벤치마크
논문은 세 가지 범주에 걸친 총 6개의 추론 과제에서 실험을 수행한다. 수학적 추론 범주에서는 GSM8K(다단계 초등학교 수학 문제)와 MATH500(MATH 데이터셋에서 추출한 500개 문제로 구성된 고등학교 수학 경시 문제)을 사용한다. GSM8K는 일상적인 수학적 추론 능력을 평가하는 표준 벤치마크로, 문제를 풀기 위해 여러 단계의 산술 연산과 논리적 추론이 필요하다. MATH500은 대수, 기하, 확률, 정수론 등 다양한 수학 분야를 포함하는 보다 도전적인 벤치마크이다.
계획(planning) 범주에서는 4x4 Sudoku와 Countdown(3개 숫자)을 사용한다. 4x4 Sudoku는 제약 조건 만족과 체계적 소거를 요구하는 퍼즐 과제로, 격자를 숫자로 채워야 한다. Countdown은 조합적 산술 게임으로, 주어진 숫자 세트에서 기본 산술 연산을 사용하여 목표 숫자에 도달해야 한다. 이 두 과제는 수학적 계산보다는 구조적 제약 조건 만족 패턴을 포함하므로, 모델의 추론 능력을 다른 각도에서 평가할 수 있다.
코딩 범주에서는 HumanEval(164개의 수작업 Python 알고리즘 프로그래밍 문제)과 MBPP(257개의 크라우드소싱 Python 과제)를 사용한다. 코딩 과제에 대한 diffu-GRPO 훈련에는 일반적인 코딩 과제와 합성 단위 테스트에 의해 검증된 솔루션이 포함된 KodCode-Light-RL-10K 데이터셋을 사용한다.
4.2 구현 세부사항
논문의 실험은 LLaDA-8B-Instruct를 주요 실험 대상 및 베이스라인으로 사용한다. LLaDA-8B-Instruct는 RL 사후 훈련을 거치지 않은 최신 오픈 소스 dLLM으로, d1의 효과를 검증하기에 적합한 테스트베드이다. 세 가지 사후 훈련 레시피를 적용한다: (a) SFT만 적용(LLaDA+SFT), (b) diffu-GRPO만 적용(LLaDA+diffu-GRPO), (c) SFT 후 diffu-GRPO 적용(d1-LLaDA).
diffu-GRPO 훈련의 경우, LoRA(Low-Rank Adaptation)를 사용하며 랭크 $r = 128$, 스케일링 팩터 $\alpha = 64$로 설정한다. GSM8K, MATH, Countdown, Sudoku 과제에 대한 훈련은 8개의 NVIDIA A100-80G GPU에서 수행되었으며, 시퀀스 길이 256, GPU당 배치 크기 6, 경사 누적 2단계를 사용한다. AdamW 옵티마이저를 사용하며 $\beta_1 = 0.9$, $\beta_2 = 0.99$, 가중치 감쇠 0.1, 학습률 $3 \times 10^{-6}$, 경사 클리핑 0.2로 설정한다. 계산 효율을 위해 Flash Attention 2와 4-bit 양자화를 활용한다. 프롬프트 마스킹 확률은 $p_{\text{mask}} = 0.15$로 설정한다. 각 과제별 훈련 단계 수는 GSM8K 7,700단계, MATH500 6,600단계, Countdown 5,000단계, Sudoku 3,800단계이다.
SFT의 경우 동일하게 LoRA를 사용하되 랭크 $r = 128$, 스케일링 팩터 $\alpha = 256$으로 설정한다. 시퀀스 길이 4,096에서 2개의 A6000 GPU를 사용하며, 경사 누적 4단계, GPU당 배치 크기 1로 유효 배치 크기 8을 달성한다. 학습률 $1 \times 10^{-5}$, 경사 클리핑 1.0을 사용하며, s1K 데이터셋에 대해 20 에포크(2,460단계) 훈련한다. 선형 학습률 감쇠 스케줄을 사용하며 워밍업은 적용하지 않는다. 코딩 과제에 대한 diffu-GRPO 훈련은 4개의 NVIDIA RTX A5000 GPU에서 수행되었으며, 기본 모델 + diffu-GRPO의 경우 7,500단계, SFT 모델 + diffu-GRPO의 경우 9,000단계 훈련한다. GPU당 배치 크기 2와 경사 누적 4단계를 사용하며, 나머지 하이퍼파라미터는 다른 과제와 동일하게 유지한다.
디코딩(추론) 시에는 $N$개의 토큰을 디코딩하기 위해 $\frac{N}{2}$번의 디노이징 단계를 수행하며, 각 단계에서 2개의 토큰을 언마스킹한다. 시퀀스를 32 토큰 블록으로 나누고, 각 단계에서 현재 블록 내에서 가장 높은 신뢰도를 가진 2개의 토큰을 위치에 관계없이 언마스킹하는 반자기회귀(semi-autoregressive) 디코딩 전략을 사용한다. 현재 블록의 모든 토큰이 언마스킹되면 다음 블록으로 이동한다. 이 디코딩 전략은 완전 병렬 디코딩(모든 토큰을 동시에 결정)과 완전 순차 디코딩(한 번에 하나의 토큰만 결정) 사이의 절충점을 제공한다. 왼쪽에서 오른쪽으로의 블록 순서는 자연어의 순차적 특성을 존중하면서도, 블록 내에서의 신뢰도 기반 언마스킹은 dLLM의 양방향 문맥 활용 능력을 살린다.
훈련과 평가의 하이퍼파라미터를 종합적으로 정리하면 다음과 같다:
| 하이퍼파라미터 | diffu-GRPO (수학/계획) | diffu-GRPO (코딩) | SFT |
|---|---|---|---|
| GPU | 8x A100-80G | 4x RTX A5000 | 2x A6000 |
| LoRA rank / alpha | 128 / 64 | 128 / 64 | 128 / 256 |
| 시퀀스 길이 | 256 | 256 | 4,096 |
| 학습률 | $3 \times 10^{-6}$ | $3 \times 10^{-6}$ | $1 \times 10^{-5}$ |
| $p_{\text{mask}}$ | 0.15 | 0.15 | N/A |
| 경사 클리핑 | 0.2 | 0.2 | 1.0 |
| 양자화 | 4-bit | 4-bit | N/A |
Table 5: diffu-GRPO 및 SFT의 핵심 하이퍼파라미터 비교. diffu-GRPO는 RL 특성에 맞춰 더 작은 학습률과 더 공격적인 경사 클리핑을 사용하며, 4-bit 양자화를 통해 메모리 효율을 확보한다.
4.3 보상 함수 설계
각 과제에 대해 형식 정확성과 내용 정확성을 모두 고려하는 복합 보상 함수를 설계했다. GSM8K의 경우 5가지 구성 요소로 이루어진 복합 보상 함수를 사용한다. XML 구조 보상은 추론 및 답변 태그의 올바른 배치에 대해 태그당 +0.125점을 부여하고, 닫는 태그 이후 불필요한 내용에 대해 소폭의 패널티를 부과한다. 소프트 형식 보상은 지정된 패턴(...(content)......(content)...)과의 일치에 대해 0.5점을 부여한다. 엄격한 형식 보상은 적절한 줄바꿈을 포함한 정확한 형식 준수에 대해 0.5점을 부여한다. 정수 답변 보상은 추출된 답이 유효한 정수일 경우 0.5점을 부여하며, 정확성 보상은 정답과 정확히 일치할 경우 2.0점을 부여한다.
Countdown 과제의 보상 함수는 주어진 숫자로 구성된 산술 식이 목표 값에 도달하는지 확인한다. 식이 목표 값에 정확히 도달하고 정확히 사용 가능한 숫자를 사용하면 1.0점, 올바른 숫자를 사용하지만 목표에 도달하지 못하면 0.1점, 그 외에는 0점을 부여한다. Sudoku 과제의 보상은 원래 퍼즐에서 비어 있던 셀 중 올바르게 채워진 셀의 비율로 계산되어, 모델의 문제 해결 능력에 초점을 맞춘다. MATH500은 GSM8K와 유사한 복합 보상 함수를 사용하되, 형식 보상은 answer 태그와 \boxed의 존재 여부에 따라 0.25~1.0점의 차등 보상을 부여하며, 정확성 보상은 \boxed{} 내에 정답이 있으면 2.0점을 부여한다.
코딩 과제의 보상 함수는 XML 구조 보상에 더해 '''python''' 래핑 여부 확인, 단위 테스트 통과 비율을 기반으로 한 정확성 점수, 그리고 os, sys, subprocess 등의 차단 모듈 사용 시 보상을 0으로 설정하는 안전 코드 점수로 구성된다.
4.4 베이스라인 모델
주요 비교 대상은 LLaDA-8B-Instruct 기본 모델이며, 이에 SFT, diffu-GRPO, 그리고 d1(SFT + diffu-GRPO)을 각각 적용한 변형 모델과 비교한다. 추가적으로 유사한 크기의 다른 모델과의 비교도 수행하는데, 이에는 AR 모델인 Deepseek 7B, Mistral 7B, LLaMA3 8B, Qwen2.5 7B와 dLLM인 Dream 7B가 포함된다. 모든 벤치마크에서 LLaDA-8B-Instruct와 LLaDA+SFT는 최종 체크포인트에서 평가하고, diffu-GRPO가 포함된 모델은 600단계부터 100단계 간격으로 평가하여 최상의 결과를 보고한다. 모든 평가는 0-shot 프롬프팅과 탐욕 디코딩(greedy decoding)으로 수행되며, 생성 길이 128, 256, 512에서 각각 평가한다.
5. 주요 실험 결과: 다양한 추론 과제에서의 성능 분석
이 섹션에서는 d1의 핵심 실험 결과를 다각도로 분석한다. 주요 벤치마크에서의 정량적 결과, 최신 모델과의 비교, 다중 과제 설정에서의 확장성, 코딩 도메인으로의 일반화, 그리고 시퀀스 길이에 따른 스케일링 특성을 순차적으로 살펴본다. 모든 평가는 0-shot 프롬프팅과 탐욕 디코딩을 사용하며, 생성 길이 128, 256, 512에서 각각 수행되었다.
5.1 수학 및 계획 벤치마크 결과
Table 1은 네 가지 과제에 대한 주요 실험 결과를 보여준다. 각 과제에 대해 세 가지 생성 시퀀스 길이(128, 256, 512)에서의 정확도를 보고하며, diffu-GRPO 모델은 각 과제에 대해 개별적으로 훈련된 것이다.
| Model / Seq Len | GSM8K | MATH500 | Countdown | Sudoku | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 128 | 256 | 512 | 128 | 256 | 512 | 128 | 256 | 512 | 128 | 256 | 512 | |
| LLaDA-8B-Instruct | 68.7 | 76.7 | 78.2 | 26.0 | 32.4 | 36.2 | 20.7 | 19.5 | 16.0 | 11.7 | 6.7 | 5.5 |
| + SFT | 66.5 | 78.8 | 81.1 | 26.2 | 32.6 | 34.8 | 20.3 | 14.5 | 23.8 | 16.5 | 8.5 | 4.6 |
| + diffu-GRPO | 72.6 | 79.8 | 81.9 | 33.2 | 37.2 | 39.2 | 33.2 | 31.3 | 37.1 | 18.4 | 12.9 | 11.0 |
| + SFT + diffu-GRPO (d1-LLaDA) | 73.2 | 81.1 | 82.1 | 33.8 | 38.6 | 40.2 | 34.8 | 32.0 | 42.2 | 22.1 | 16.7 | 9.5 |
Table 1: 수학 및 계획 벤치마크에서의 모델 성능. 녹색 값은 최고 성능, 파란색 값은 차선 성능을 나타낸다. d1-LLaDA가 일관되게 다른 모델을 능가하며, diffu-GRPO는 시작 체크포인트에 관계없이 일관된 성능 향상을 제공한다.
Table 1의 결과에서 여러 중요한 발견이 도출된다. 첫째, diffu-GRPO와 SFT 모두 LLaDA-8B-Instruct 베이스라인 대비 향상을 제공하지만, diffu-GRPO가 일관되게 더 큰 개선을 보인다. 구체적으로, diffu-GRPO는 12개 전체 설정에서 LLaDA-8B-Instruct와 SFT를 모두 능가하는 반면, SFT는 12개 중 7개에서만 베이스라인을 초과한다. 이는 diffu-GRPO가 SFT보다 전반적으로 더 강력한 성능을 달성함을 의미한다.
이 결과는 SFT와 RL의 상대적 효과에 대한 최근의 연구 동향과도 일맥상통한다. Chu 등의 연구가 SFT는 암기에 기반하는 경향이 있고 RL은 보다 나은 일반화를 달성한다고 보고한 것처럼, diffu-GRPO가 SFT보다 더 넓은 범위의 설정에서 안정적인 향상을 보이는 것은 RL의 탐색(exploration) 메커니즘이 dLLM에서도 동일하게 작동함을 시사한다. 특히 SFT는 12개 설정 중 5개에서 베이스라인보다 낮은 성능을 보이는 반면, diffu-GRPO는 단 하나의 설정에서도 성능이 하락하지 않는다는 점이 인상적이다.
둘째, diffu-GRPO는 초기화 지점에 관계없이 일관된 성능 향상을 제공한다. LLaDA+diffu-GRPO는 기본 LLaDA-8B-Instruct 모델을 모든 설정에서 능가하고, d1-LLaDA는 LLaDA+SFT를 모든 경우에서 초과한다. 이는 diffu-GRPO가 사전 훈련된 모델이든 SFT 적응 체크포인트이든 안정적인 성능 향상을 제공함을 시사한다.
셋째, d1 레시피(SFT + diffu-GRPO)가 최대 성능을 달성한다. d1-LLaDA는 12개 중 11개 설정에서 순수 diffu-GRPO를 능가하며, 이는 두 훈련 단계 간의 시너지 효과를 나타낸다. 과제별로 보면, GSM8K(3.9%)와 MATH500(4.0%)에서는 비교적 완만한 향상을 보이지만, Countdown(26.2%)과 Sudoku(10.0%)에서는 훨씬 더 큰 향상을 보인다. 논문은 이러한 차이가 기본 모델이 수학 과제에서는 이미 상당한 수준에 도달하여 개선 여지가 적은 반면, 구조적 제약 조건 만족 패턴을 포함하는 계획 벤치마크에서는 더 많은 개선 공간이 있기 때문이라고 추론한다. 이러한 성능 포화(saturation) 가설은 합리적인데, LLaDA-8B-Instruct가 이미 GSM8K에서 78.2%에 도달한 상태에서 추가적인 향상의 여지가 제한적인 반면, Countdown(20.7%)과 Sudoku(11.7%)에서는 기본 성능이 상대적으로 낮아 개선 공간이 더 크기 때문이다. 또한 계획 과제가 수학 과제와는 다른 유형의 추론(제약 조건 전파, 체계적 탐색)을 요구한다는 점에서, diffu-GRPO의 온라인 탐색이 이러한 유형의 추론에 특히 효과적일 수 있다는 해석도 가능하다.
5.2 최신 dLLM 및 AR LLM과의 비교
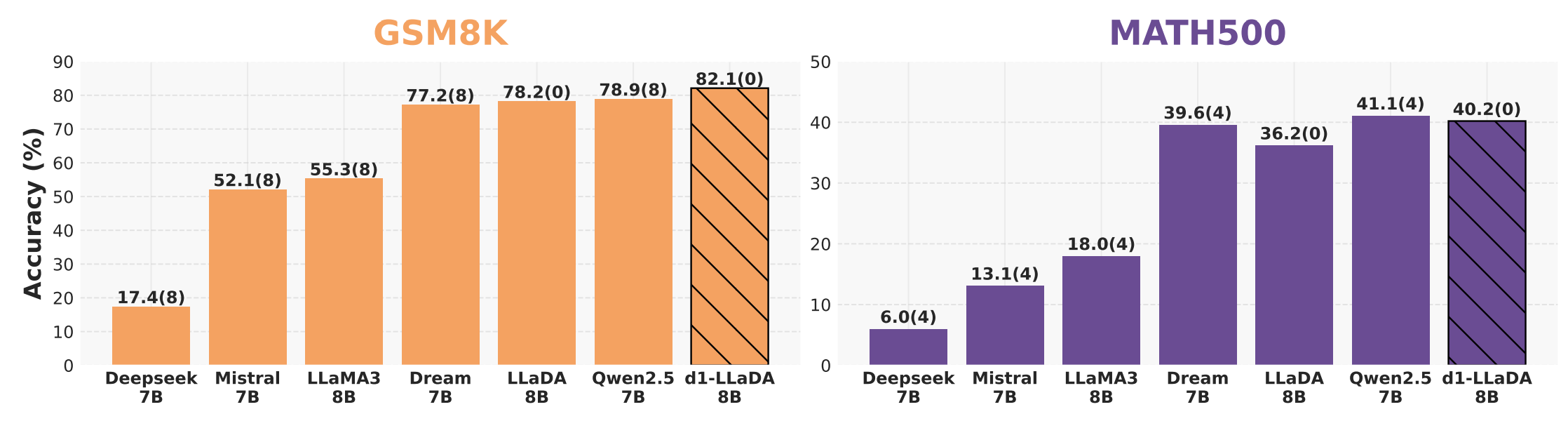
Figure 6: 유사한 크기의 최신 dLLM 및 AR LLM과의 비교. d1-LLaDA는 GSM8K에서 최고 점수(82.1%)를 달성하고, MATH500에서는 두 번째로 높은 점수(40.2%)를 기록한다. LLaDA 결과는 0-shot 평가이며, 다른 모델의 점수는 Dream 논문에서 인용(GSM8K 8-shot, MATH500 4-shot)한 것이다.
d1의 성능을 보다 넓은 맥락에서 평가하기 위해, 논문은 유사한 크기(7~8B 파라미터)의 다양한 최신 모델과의 비교를 수행한다. 이 비교에는 AR 기반 LLM인 Deepseek 7B, Mistral 7B, LLaMA3 8B, Qwen2.5 7B와 확산 기반 LLM인 Dream 7B가 포함되며, 평가 조건의 차이(shot 수)를 고려하여 해석해야 한다.
Figure 6는 d1-LLaDA를 유사한 크기(7~8B)의 다양한 AR 모델 및 dLLM과 비교한 결과를 보여준다. GSM8K에서 d1-LLaDA는 82.1%의 정확도로 모든 비교 대상 중 최고 성능을 달성했으며, 이는 AR 모델인 Qwen2.5 7B(78.9%)와 dLLM인 Dream 7B(77.2%)를 모두 능가하는 결과이다. MATH500에서는 40.2%로 Qwen2.5 7B(41.1%)에 이어 두 번째로 높은 성능을 기록했다. 주목할 점은 d1-LLaDA의 결과가 0-shot 평가인 반면, 다른 모델들은 8-shot(GSM8K) 또는 4-shot(MATH500) 프롬프팅으로 평가되었다는 것이다. 이는 d1 프레임워크가 dLLM의 추론 능력을 경쟁력 있는 AR 모델 수준까지 끌어올릴 수 있음을 시사하는 고무적인 결과이다. 특히 Deepseek 7B(GSM8K: 17.4%)와 Mistral 7B(52.1%)와 같은 초기 세대 모델과의 격차가 매우 크며, 최신 AR 모델인 Qwen2.5 7B와도 경쟁할 수 있다는 점은 dLLM이 단순한 학술적 대안이 아니라 실용적 성능을 달성할 수 있는 모델 패러다임임을 입증한다. MATH500에서 Qwen2.5 7B에 약 1% 미달하는 것은 평가 조건의 차이(0-shot vs 4-shot)를 고려하면 실질적으로 대등한 성능으로 해석할 수 있다.
5.3 통합 모델의 다중 과제 성능
논문은 과제별로 개별 모델을 훈련하는 것뿐만 아니라, GSM8K, MATH500, Countdown, Sudoku의 결합 데이터셋에서 단일 모델을 훈련하는 실험도 수행한다. 균형 잡힌 훈련을 위해 각 과제의 훈련 예제 수가 동일하도록 서브샘플링한다. 이는 다중 과제 학습에서 흔히 발생하는 과제 간 데이터 불균형 문제를 방지하기 위한 것으로, 특정 과제에 편향되지 않는 균형 잡힌 모델 학습을 목표로 한다. 서브샘플링으로 인해 개별 과제의 훈련 데이터 양이 줄어들지만, 이로 인한 성능 저하 없이 오히려 과제 간 지식 전이의 이점을 누릴 수 있는지가 핵심 검증 포인트이다.
| Model / Seq Len | GSM8K | MATH500 | Countdown | Sudoku | ||||
|---|---|---|---|---|---|---|---|---|
| 128 | 256 | 128 | 256 | 128 | 256 | 128 | 256 | |
| LLaDA-8B-Instruct | 68.7 | 76.7 | 26.0 | 32.4 | 20.7 | 19.5 | 11.7 | 6.7 |
| + SFT (s1k) | 66.5 | 78.8 | 26.2 | 32.6 | 20.3 | 14.5 | 16.5 | 8.5 |
| + combined diffu-GRPO | 72.4 | 78.2 | 30.2 | 36.6 | 27.7 | 19.5 | 22.9 | 15.7 |
| combined d1-LLaDA | 75.1 | 81.1 | 29.8 | 35.4 | 30.1 | 32.8 | 21.9 | 15.4 |
Table 2: 통합 모델의 다중 추론 과제 성능. diffu-GRPO와 d1-LLaDA 변형에서 단일 모델이 GSM8K, MATH500, Countdown, Sudoku의 결합 데이터셋으로 훈련되었다. 서브샘플링에도 불구하고 과제별 결과(Table 1)와 비교하여 정확도를 희생하지 않는다.
Table 2의 결과는 diffu-GRPO가 다중 과제 설정으로 확장해도 성능이 유지됨을 보여준다. 서브샘플링으로 인해 각 과제의 훈련 데이터가 줄어들었음에도 불구하고, 통합 모델은 Table 1의 과제별 결과와 비교하여 경쟁력 있는 성능을 보인다. 특히 combined d1-LLaDA는 GSM8K(75.1/81.1)와 Countdown(30.1/32.8)에서 강한 성능을 보이며, Sudoku에서도 통합 diffu-GRPO 모델이 22.9(128)를 기록하여 과제별 모델의 22.1과 비슷한 수준을 유지한다. 이 결과는 diffu-GRPO가 단일 과제뿐만 아니라 다중 과제 학습에서도 효과적으로 작동함을 입증한다. 특히 주목할 점은 combined d1-LLaDA가 Countdown 256에서 32.8%를 달성하여, 과제별 모델의 32.0%(Table 1)를 오히려 초과한다는 것이다. 이는 다중 과제 학습에서의 상호 보완적 학습 효과를 시사하며, 다양한 유형의 추론 과제를 동시에 학습하는 것이 각 과제의 성능을 해치지 않을 뿐만 아니라 경우에 따라서는 오히려 긍정적 전이(positive transfer)를 제공할 수 있음을 보여준다.
5.4 코딩 벤치마크에서의 diffu-GRPO 효과
| Model / Seq Len | HumanEval | MBPP | ||||
|---|---|---|---|---|---|---|
| 128 | 256 | 512 | 128 | 256 | 512 | |
| LLaDA-8B-Instruct | 27.4 | 35.3 | 37.8 | 36.2 | 41.2 | 40.4 |
| + diffu-GRPO | 29.3 | 39.0 | 34.8 | 42.0 | 45.5 | 41.6 |
| diffu-GRPO 향상 | +1.9 | +3.7 | -3.0 | +5.8 | +4.3 | +1.2 |
| LLaDA-8B-Instruct + SFT (s1k) | 21.3 | 32.3 | 32.9 | 40.1 | 39.7 | 41.2 |
| + diffu-GRPO | 31.1 | 32.9 | 37.8 | 40.5 | 44.7 | 42.8 |
| diffu-GRPO 향상 | +9.8 | +0.6 | +4.9 | +0.4 | +5.0 | +1.6 |
Table 3: 코딩 벤치마크에서의 diffu-GRPO 효과. HumanEval과 MBPP에서 diffu-GRPO는 초기화 체크포인트에 관계없이 일관되게 성능을 향상시킨다.
Table 3은 diffu-GRPO를 코딩 과제에 확장한 결과를 보여준다. KodCode-Light-RL-10K 데이터셋으로 훈련한 결과, diffu-GRPO는 초기화 지점에 관계없이 대부분의 설정에서 일관된 성능 향상을 제공한다. 기본 LLaDA-8B-Instruct에 diffu-GRPO를 적용하면 HumanEval 256에서 +3.7, MBPP 128에서 +5.8의 향상을 보이고, SFT 후 diffu-GRPO를 적용하면 HumanEval 128에서 +9.8이라는 큰 향상을 보인다. 흥미로운 발견은 s1K가 코딩에는 적합하지 않다는 것인데, s1K에 코드 관련 데이터 포인트가 부족하기 때문이다. SFT 체크포인트에서 시작하면 일부 설정(HumanEval 256: 32.3→32.9, MBPP 128: 40.1→40.5)에서 개선폭이 작지만, 전반적으로 diffu-GRPO의 도메인 일반성을 확인할 수 있다. 코딩 과제에서의 보상 함수는 수학/계획 과제와 상당히 다른 구조를 가진다는 점도 주목해야 한다. 단위 테스트 통과 비율이라는 보다 세밀한 피드백 신호를 활용하며, 안전 코드 검증까지 포함하는 복합적인 보상 체계이다. diffu-GRPO가 이처럼 다양한 보상 구조에서도 일관되게 작동한다는 것은 알고리즘의 견고성을 시사한다.
5.5 생성 시퀀스 길이에 따른 순차적 스케일링
diffu-GRPO 훈련은 256 토큰의 고정 시퀀스 길이로 수행되지만, 논문의 주요 발견 중 하나는 diffu-GRPO가 훈련 시퀀스 길이를 넘어서도 추론 능력을 향상시킨다는 것이다. 이는 RL 기반 훈련의 일반화 능력에 대한 중요한 관찰이며, 모델이 특정 생성 길이에 과적합되지 않았음을 보여주는 핵심 증거이다. 128과 512 시퀀스 길이에서도 성능 향상이 관찰되며, 이는 모델이 특정 길이에 과적합되지 않고 보다 일반적인 추론 전략을 학습했음을 시사한다. GSM8K와 MATH500에서는 시퀀스 길이 증가에 따라 모든 모델 변형이 향상된 성능을 보이며, 128에서 256으로의 점프(약 7.1%)가 256에서 512로의 점프(약 2.5%)보다 크다. 이러한 "체감하는 수익(diminishing returns)" 패턴은 AR 모델의 테스트 시간 컴퓨팅 스케일링과 유사한 경향을 보이며, 더 긴 생성이 일정 수준 이후에는 추가적인 이점을 점차 줄어들게 한다는 것을 나타낸다.
그러나 Countdown과 Sudoku에서는 혼합된 스케일링 경향이 관찰된다. Sudoku의 경우 모든 모델에서 시퀀스 길이가 증가함에 따라 오히려 성능이 감소한다. Countdown에서는 LLaDA-8B-Instruct가 시퀀스 길이에 따라 단조적으로 감소하는 반면, SFT, diffu-GRPO, d1-LLaDA는 512에서 최고 성능에 도달한다. 이 혼합된 스케일링 경향은 dLLM의 추론 특성에 대한 중요한 통찰을 제공한다. Sudoku에서 시퀀스 길이 증가에 따른 성능 감소는 dLLM의 고정 길이 생성 특성과 관련될 수 있다. 더 긴 시퀀스에서 모델이 패딩 토큰이나 무관한 토큰을 생성하여 실제 해답의 품질이 저하될 가능성이 있으며, 이는 AR 모델에서 더 긴 CoT가 자동으로 더 깊은 추론으로 이어지는 것과는 대조적이다. 논문은 이러한 현상이 LLaDA-8B-Instruct의 능력을 넘어서는 광범위한 탐색 요구사항에 기인하며, 보다 강력한 기본 dLLM이 등장하면 유리한 순차적 스케일링이 강화될 것으로 추론한다. DeepSeek R1과 같은 AR 모델과 달리, RL 훈련 후 유의미한 CoT 길이 증가가 관찰되지 않으며, 이는 LLaDA-8B-Instruct가 최대 4,096 토큰의 시퀀스에 대해 사전 훈련되었기 때문이다. 더 큰 생성 길이로 확장하려면 RL 훈련 중 더 긴 생성 길이가 필요하지만, 현재의 느린 생성 속도로 인해 이는 실행 불가능한 상태이다.
6. 추가 분석 및 Ablation Study: diffu-GRPO의 설계 선택
diffu-GRPO의 성능은 여러 핵심 설계 선택에 의해 결정된다. 이 섹션에서는 무작위 마스킹 대 고정 마스킹의 효과, 프롬프트 마스킹 확률의 영향, RL 훈련 역학, 그리고 모델이 보이는 질적 행동 변화를 심층적으로 분석한다. 이러한 ablation 연구는 d1의 각 구성 요소가 최종 성능에 어떻게 기여하는지를 이해하는 데 필수적이며, 향후 dLLM의 RL 훈련을 위한 실용적인 지침을 제공한다.
6.1 무작위 마스킹 vs 고정 마스킹: 암묵적 정규화 효과
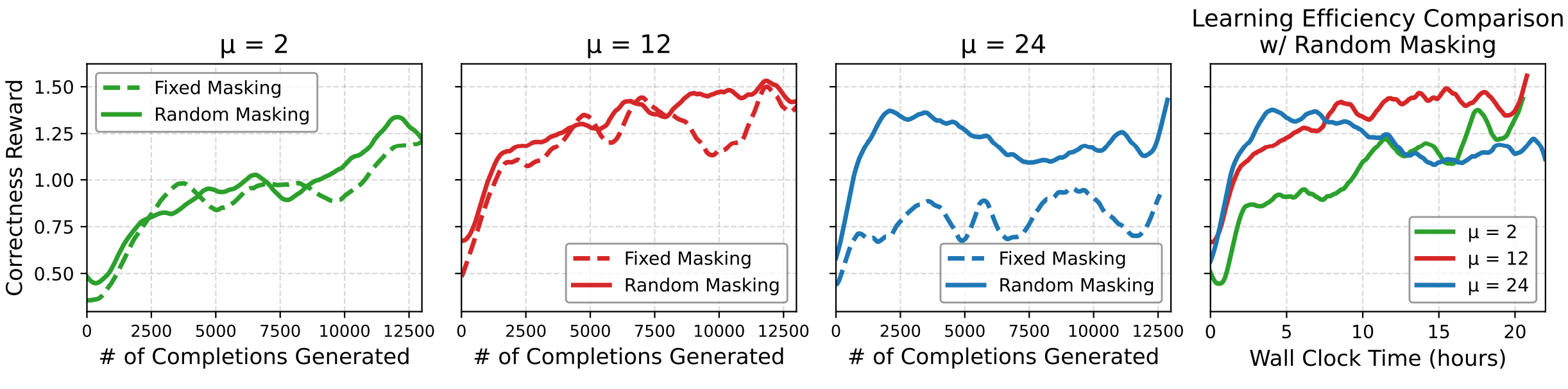
Figure 7: 서로 다른 정책 최적화 업데이트 값($\mu$)에서의 고정 마스킹 대 무작위 마스킹 비교. 처음 세 그래프는 서로 다른 $\mu$ 값에서 RL 훈련 중 생성된 완성 수 대비 GSM8K 정확성 보상을 보여준다. 무작위 마스킹이 일관되게 고정 마스킹을 능가한다. 맨 오른쪽 패널은 무작위 마스킹을 적용한 세 가지 $\mu$ 값의 벽시계 시간 대비 효율성을 비교하며, $\mu$ 값이 높을수록 더 높은 효율성을 보인다.
Figure 7은 diffu-GRPO의 핵심 설계 선택인 무작위 마스킹(random masking)과 고정 마스킹(fixed masking)의 성능 차이를 분석한다. 처음 세 패널은 정책 최적화 업데이트 횟수 $\mu = 2, 12, 24$에서 각각 GSM8K 정확성 보상을 생성된 완성 수에 대해 비교한다. 모든 $\mu$ 값에서 무작위 마스킹이 고정 마스킹을 일관되게 능가하며, 이 차이는 $\mu$가 커질수록 더욱 두드러진다. 기존 접근법에서는 일반적으로 수확 체감(diminishing returns)과 과적합 위험으로 인해 $\mu$를 2로 제한하지만, d1의 무작위 마스킹 접근법은 $\mu$를 12 또는 심지어 24까지 확장하면서도 성능을 유지하거나 향상시킬 수 있다.
맨 오른쪽 패널은 실질적인 효율성 측면에서의 이점을 보여준다. 무작위 마스킹을 적용한 세 가지 $\mu$ 값($\mu = 2, 12, 24$)을 벽시계 시간(wall clock time)에 대해 비교하면, $\mu$ 값이 높을수록 더 적은 시간에 더 높은 보상을 달성한다. 이는 $\mu$가 높을수록 외부 배치 반복 횟수가 줄어들고, 따라서 온라인 생성 횟수가 감소하여 계산 비용이 크게 절감되기 때문이다. 이러한 효율성 향상은 각 최적화 단계에서 입력 데이터의 다양한 관점을 생성함으로써 배치 내 과적합을 방지하고 각 생성에서 더 많은 학습 신호를 추출할 수 있기 때문에 가능하다. 이는 마스크 확산 모델에 고유한 장점으로, AR 모델에서는 구현할 수 없는 메커니즘이다. AR 모델에서는 프롬프트의 토큰을 마스킹하면 생성 과정 자체가 의미를 잃게 되지만, dLLM에서는 마스킹이 디노이징 과정의 자연스러운 일부이므로 프롬프트 마스킹이 유효한 데이터 증강 전략이 된다. 이러한 관찰은 dLLM이 AR 모델과 비교하여 RL 훈련에서 고유한 계산 효율성 이점을 가질 수 있음을 시사하며, 이는 향후 dLLM의 RL 훈련 확장에 중요한 통찰이 된다.
6.2 프롬프트 마스킹 확률의 영향
논문은 프롬프트 마스킹 확률 $p_{\text{mask}}$가 diffu-GRPO 훈련에 미치는 영향을 체계적으로 분석한다. $p_{\text{mask}} \in \{0.0, 0.1, 0.3, 0.5, 0.7\}$의 다섯 가지 값에 대해 GSM8K에서 실험을 수행한 결과, 다음과 같은 경향이 관찰된다.
| $p_{\text{mask}}$ | 훈련 안정성 | 최종 성능 | 특이 사항 |
|---|---|---|---|
| 0.0 | 안정적 | 약간 낮음 | 변동성 없지만 정규화 효과 부재 |
| 0.1 | 가장 안정적 | 최고 | 정규화 효과와 문맥 보존의 최적 균형 |
| 0.3 | 안정적 | 우수 | $p_{\text{mask}} = 0.1$과 유사한 수준 |
| 0.5 | 불안정 발생 | 중간 | 후반 훈련 단계에서 불안정성 발현 |
| 0.7 | 심각한 불안정 | 급격한 저하 | 3,000단계 이후 급격한 성능 저하 발생 |
Table 4: 프롬프트 마스킹 확률($p_{\text{mask}}$)에 따른 훈련 안정성 및 성능 비교 요약. 낮은 마스킹 확률(0.1, 0.3)이 최적의 성능을 제공한다.
낮은 마스킹 확률(0.1, 0.3)은 마스킹 없이 더 많은 문맥 토큰을 보존함으로써 더 안정적인 훈련과 더 나은 최종 성능을 제공한다. 반면 높은 마스킹 확률(0.5, 0.7)은 훈련 후반 단계에서 불안정성을 도입하며, 특히 $p_{\text{mask}} = 0.7$은 3,000단계 이후 급격한 성능 저하를 초래한다. $p_{\text{mask}} = 0.0$(마스킹 없음)은 변동성을 피하지만, 약간 낮은 성능을 보여 무작위 마스킹의 정규화 효과를 확인시켜 준다. 이러한 결과는 3.2절에서 논의한 정규화 이점과 일치하며, 특히 큰 정책 반복 횟수($\mu = 12$)에서 이 효과가 유익하다는 것을 보여준다. 실제 구현에서는 $p_{\text{mask}} = 0.15$가 사용되었는데, 이는 BERT의 마스킹 비율과 유사한 값으로 문맥 보존과 정규화 효과 사이의 실용적인 절충점을 나타낸다. 이 결과는 dLLM의 사전 훈련 과정에서 사용된 마스킹 전략과 RL 훈련 시의 마스킹 전략 사이의 일관성이 중요할 수 있음을 암시한다. LLaDA가 선형 노이즈 스케줄($\alpha_t = 1 - t$)로 사전 훈련되었으므로, 평균적인 마스킹 비율이 0.5인 상태에서 학습된 모델에 낮은 마스킹 확률(0.1~0.3)을 적용하면, 모델이 대부분의 프롬프트 문맥을 활용할 수 있으면서도 적절한 수준의 노이즈에 의한 정규화를 받는 최적의 조건이 형성된다고 해석할 수 있다.
6.3 RL 훈련 역학 분석
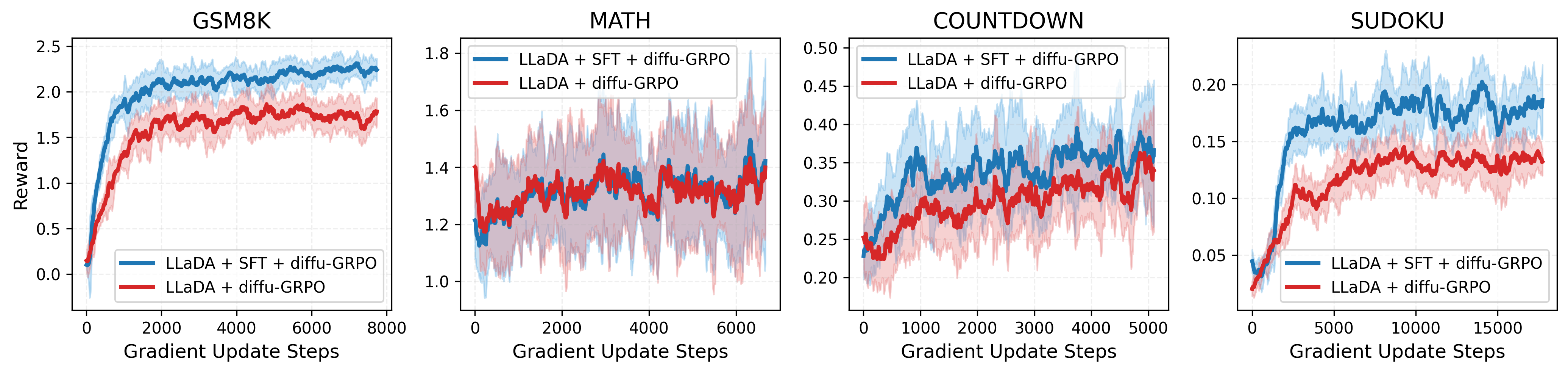
Figure 8: Table 1의 모델에 대한 네 가지 추론 과제별 RL 훈련 보상 곡선. LLaDA+diffu-GRPO(빨간색)와 d1-LLaDA(SFT + diffu-GRPO, 파란색)를 비교한다. d1-LLaDA가 일관되게 더 높거나 유사한 보상 궤적을 달성한다.
Figure 8은 네 가지 추론 과제에 대한 RL 훈련 과정에서의 보상 곡선을 보여준다. 파란색 선은 d1-LLaDA(SFT + diffu-GRPO)를, 빨간색 선은 LLaDA+diffu-GRPO(RL만)를 나타낸다. 모든 과제에서 SFT 사전 훈련이 더 높은 초기 보상과 더 빠른 학습을 가능하게 한다는 것이 명확하게 관찰된다. GSM8K에서 d1-LLaDA는 약 2.0의 보상에 도달하는 반면 diffu-GRPO만으로는 약 1.7에 머문다. MATH에서는 두 방법 모두 노이즈가 높은 점진적 향상을 보이지만, d1-LLaDA가 약간 더 높은 값(1.5~1.6 vs 1.3~1.5)을 달성한다. Countdown에서는 d1-LLaDA가 약 0.40으로 diffu-GRPO의 약 0.30을 크게 앞서며, Sudoku에서는 훈련이 더 길고 노이즈가 많지만 d1-LLaDA(약 0.20)가 diffu-GRPO(약 0.15)를 일관되게 초과한다. 이러한 보상 곡선은 SFT가 RL에 더 좋은 초기화를 제공하며, 두 방법의 결합이 시너지를 발휘한다는 주장을 뒷받침한다. 특히 GSM8K에서의 초기 학습 속도 차이가 뚜렷한데, d1-LLaDA는 약 2,000단계에서 이미 높은 보상에 도달하는 반면, diffu-GRPO만 적용한 모델은 유사한 수준에 도달하는 데 약 4,000단계 이상이 필요하다. 이는 SFT 단계에서 습득한 추론 패턴이 RL의 초기 탐색 효율을 크게 향상시키며, RL이 제로 상태에서 추론을 학습하는 것보다 이미 기초적인 추론 능력을 갖춘 상태에서 이를 정제하는 것이 더 효율적임을 보여준다. Sudoku에서는 두 변형 모두 훈련 후반부에서 노이즈가 증가하는 경향이 관찰되는데, 이는 해당 과제의 높은 난이도와 보상 신호의 희소성에 기인할 수 있으며, 보다 세밀한 보상 설계나 커리큘럼 학습 전략이 이 문제를 완화할 수 있을 것으로 전망된다.
6.4 질적 분석: "유레카 순간(Aha Moments)"의 출현

Figure 9: d1-LLaDA의 질적 예시. 모델이 수학 문제를 풀면서 중간 결과를 검증하고 오류를 발견했을 때 자기 수정하는 "유레카 순간"을 보여준다(주황색 하이라이트). 최종 답변 35%에 정확히 도달한다.
논문은 시퀀스 길이 512에서 SFT와 d1-LLaDA 모델의 생성에서 "유레카 순간(aha moments)"이 관찰된다고 보고한다. 이는 모델이 자기 수정(self-correction)과 백트래킹(backtracking) 행동을 보이는 것으로, DeepSeek-R1과 같은 AR 추론 모델에서 관찰되는 현상과 유사하다. Figure 9는 이러한 행동의 구체적인 예시를 보여주는데, d1-LLaDA가 강아지의 반점 비율을 계산하는 문제에서 중간 계산을 수행한 후 "Let's recheck the steps(단계를 다시 확인하자)"라는 자기 검증 단계를 거쳐 최종 답에 도달한다. 주황색으로 강조된 부분이 바로 이 자기 수정 과정으로, 7/20 × 100의 계산을 반복 검증하여 35%라는 정확한 답에 도달한다.
논문은 시퀀스 길이 128과 256에서는 SFT, diffu-GRPO, d1의 생성 추론 트레이스에 기본 LLaDA-8B-Instruct와 비교하여 질적으로 유의미한 차이가 관찰되지 않지만, 512 토큰 길이에서 비로소 자기 검증과 자기 수정 행동이 출현한다고 서술한다. 이 관찰은 모델이 s1K의 추론 트레이스에서 중간 결과 검증과 백트래킹 같은 행동을 SFT 단계에서 내재화했다는 해석을 뒷받침한다. 512 토큰의 더 긴 생성 길이가 이러한 행동이 표현될 수 있는 충분한 공간을 제공하는 것으로 보인다. 이 관찰은 dLLM에서의 추론 능력 발현이 AR 모델과 유사한 메커니즘을 따를 수 있음을 시사한다. AR 추론 모델에서도 "유레카 순간"은 충분한 생성 길이가 주어질 때 출현하며, 이는 모델이 해답에 대한 확신이 부족할 때 다른 접근법을 시도하거나 이전 단계를 재검토하는 행동으로 나타난다. dLLM에서 이러한 행동의 출현은 비자기회귀적 생성 패러다임에서도 메타인지적 추론 행동이 가능함을 보여주는 흥미로운 발견이다.
논문의 부록에서는 동일한 GSM8K 문제에 대한 각 모델 변형의 생성을 비교하여 이 현상을 상세히 분석한다. 예를 들어, "76개 별이 있는 깃발" 문제에서 LLaDA-8B-Instruct(128 토큰)는 단순하고 압축적인 추론을 보이지만, d1-LLaDA(512 토큰)는 각 단계를 상세히 나열하고 중간 계산을 검증하는 더 정교한 추론 과정을 보여준다. 특히 "빵집 생산" 문제에서 SFT 모델은 자기 수정을 시도하지만 잘못된 수정으로 오답에 도달하는 반면, d1-LLaDA는 올바른 자기 수정을 통해 정답에 도달하는 대조적인 예시가 주목할 만하다. 이는 SFT만으로는 자기 수정 행동의 형태는 학습하지만 그 정확성은 보장하지 못하며, RL을 통한 추가 최적화가 자기 수정의 질을 향상시킨다는 것을 시사한다.
6.5 유효 토큰 사용량 분석
유효 토큰 사용량 분석은 dLLM의 고정 길이 생성 특성을 이해하는 데 핵심적인 정보를 제공한다. dLLM은 사전 정의된 길이의 시퀀스를 생성하며, 실제 내용이 차지하는 부분 이외는 패딩 토큰이나 EOS 토큰으로 채워진다. 따라서 유효 토큰 수는 모델이 실제로 의미 있는 텍스트를 얼마나 생성하는지를 나타내는 지표이다. 논문은 각 모델 변형의 유효 토큰 사용량(비패딩, 비EOS 토큰의 평균 수)을 분석한다. 생성 길이가 증가함에 따라 유효 토큰 수도 증가하며, MATH500, Countdown, Sudoku에서는 모든 방법에 대해 비슷한 수준을 유지한다. 이는 모델이 주어진 생성 공간을 효과적으로 활용하고 있으며, 128 토큰에서의 절단(truncation)이 발생하지 않고 512 토큰에서는 토큰 활용도가 증가한다는 것을 보여준다. 특히 diffu-GRPO 훈련이 256 토큰의 고정 시퀀스 길이로 수행되었음에도 다른 길이에서 성능이 향상되는 것은, 모델이 특정 길이에 과적합되지 않고 일반화된 추론 전략을 학습했음을 나타내는 핵심 증거이다.
7. 한계점 및 향후 연구 방향: 확산 추론 모델의 미래
d1은 dLLM에 RL 기반 추론 향상을 적용한 선구적 연구로서 중요한 성과를 달성했지만, 동시에 여러 중요한 한계점과 향후 탐구 방향을 제시한다. 이 섹션에서는 논문이 직접 언급한 제한사항과 실험 결과에서 도출할 수 있는 추가적인 고려사항을 종합적으로 분석한다. 이러한 한계점의 이해는 향후 dLLM 추론 연구의 발전 방향을 설정하는 데 핵심적이다.
7.1 고정 길이 생성의 제약
d1의 가장 근본적인 한계는 LLaDA의 고정 길이 생성 요구사항에서 비롯된다. diffu-GRPO 훈련이 사전 정의된 시퀀스 길이(256)로 수행되므로, 모델이 최적의 추론 경로를 발견하는 데 제약이 있다. DeepSeek-R1과 같은 AR 모델에서 관찰되는 것처럼, 간결한 해답이나 확장된 연쇄적 사고 트레이스 모두 고정 길이 체계 내에서는 자유롭게 탐색될 수 없다. 논문은 이 한계에 대한 해결책으로 Block Diffusion과 같은 가변 길이 생성을 지원하는 모델에 diffu-GRPO를 적용하는 방향을 제안하며, 이를 통해 확장 가능한 장문맥 RL 훈련이 가능할 것으로 전망한다.
7.2 CoT 길이 증가의 부재
AR 모델 기반의 RL 훈련(예: DeepSeek-R1)에서는 RL 후 CoT 길이가 자연스럽게 증가하여 모델이 더 길고 깊은 추론을 수행하게 되는 현상이 관찰된다. 그러나 d1에서는 RL 훈련 후에도 유의미한 CoT 길이 증가가 관찰되지 않는다. 이는 LLaDA-8B-Instruct가 최대 4,096 토큰에 대해 사전 훈련되었고, 생성 길이가 고정되어 있기 때문이다. 더 긴 생성을 통한 추론 확장은 RL 훈련 중 더 큰 생성 길이를 사용해야 하지만, dLLM의 현재 느린 생성 속도(반복적 디노이징의 순차적 특성)로 인해 이는 계산적으로 실행 불가능한 상태이다.
7.3 평균장 근사의 이론적 한계
d1의 로그 확률 추정에서 사용되는 평균장 근사는 각 토큰의 생성이 독립적이라고 가정하는데, 실제 dLLM의 생성 과정에서는 토큰 간 의존성이 존재한다. 이 근사의 정확성과 그 편향이 정책 최적화에 미치는 영향에 대한 이론적 분석은 아직 충분히 제공되지 않았다. 비록 실험적으로 효과적으로 작동하지만, 근사의 질이 시퀀스 길이, 모델 크기, 과제 복잡도 등에 따라 어떻게 변화하는지에 대한 체계적인 연구가 필요하다. 특히 토큰 간 강한 의존성이 존재하는 과제(예: 코딩에서의 구문 구조)에서는 평균장 근사의 편향이 더 크게 작용할 수 있으며, 이는 Table 3에서 일부 코딩 설정에서 관찰되는 비일관적인 결과와 관련될 수 있다.
7.4 SFT 데이터셋의 도메인 특화성
현재 d1의 SFT 단계에서 사용하는 s1K 데이터셋은 수학적 추론 문제에 특화되어 있어, 코딩과 같은 다른 도메인에서는 오히려 성능을 저하시킬 수 있다. Table 3에서 관찰된 바와 같이, s1K로 SFT를 수행한 후 HumanEval에서의 성능(21.3/32.3/32.9)은 기본 모델(27.4/35.3/37.8)보다 낮아지는 현상이 나타난다. 이는 수학 추론에 특화된 SFT가 코딩 능력을 해칠 수 있음을 시사하며, 도메인별 최적 SFT 데이터셋 탐색이 향후 연구 과제로 남아 있다. 범용적인 추론 능력을 함양할 수 있는 다양한 도메인의 고품질 추론 트레이스를 포함하는 데이터셋의 개발이 dLLM의 범용 추론 모델로의 발전에 핵심적일 것이다.
7.5 효율적 디코딩 전략의 필요성
d1의 향후 발전에서 가장 시급한 과제 중 하나는 dLLM의 추론 속도 향상이다. 현재 마스크 dLLM의 디코딩은 $\frac{N}{2}$번의 디노이징 단계를 요구하며, 각 단계에서 전체 시퀀스에 대한 순방향 패스가 필요하다. 이는 AR 모델의 단일 패스 생성에 비해 상당한 계산 오버헤드를 부과한다. 온라인 RL 훈련에서는 많은 수의 완성을 생성해야 하므로, 이 속도 제약이 RL 훈련의 확장성을 직접적으로 제한한다. 논문은 효율적인 디코딩 전략의 개발이 dLLM RL 훈련의 확장에서 핵심적인 미래 연구 방향임을 강조한다. Mercury와 같은 연구에서 보여준 dLLM의 추론 효율성 향상이 이 방향에서 유망한 출발점이 될 수 있다. Mercury는 확산 기반 언어 모델에서 초고속 추론을 달성한 사례로, 이러한 효율적 추론 기법과 d1의 RL 훈련을 결합할 수 있다면 dLLM의 실용적 RL 확장에 큰 진전을 이룰 수 있을 것이다. 또한 적응적 디노이징 단계 수를 사용하여 간단한 토큰은 적은 단계로, 복잡한 토큰은 더 많은 단계로 디노이징하는 전략도 생성 효율을 향상시키는 유망한 방향이다.
7.6 단일 기반 모델에 대한 검증의 한계
d1의 실험은 LLaDA-8B-Instruct라는 단일 기반 모델에서만 수행되었다. 따라서 d1 프레임워크의 일반성, 즉 다른 dLLM(Dream, Mercury 등)이나 다른 크기의 모델에서도 유사한 효과를 보일지는 아직 검증되지 않았다. 더 크거나 더 작은 dLLM에서의 RL 기반 추론 향상의 스케일링 법칙, 다른 마스킹 전략이나 노이즈 스케줄을 사용하는 dLLM에서의 diffu-GRPO 적용 가능성 등은 향후 연구에서 탐구해야 할 중요한 질문이다. 특히 Dream과 같은 최신 dLLM이 LLaDA와는 다른 학습 목적 함수와 디코딩 전략을 사용하므로, diffu-GRPO의 적용이 추가적인 수정을 요구할 수 있다. 논문이 제안하는 로그 확률 추정 기법이 PPO, REINFORCE 등 다른 정책 경사 방법에도 적용 가능하다고 서술하는 만큼, 다양한 RL 알고리즘과 다양한 dLLM 아키텍처의 조합을 체계적으로 평가하는 대규모 벤치마킹 연구가 향후 필요할 것이다.
7.7 AR 모델 대비 dLLM 추론의 구조적 특성
dLLM의 추론 과정은 AR 모델과 근본적으로 다른 특성을 가진다. AR 모델은 토큰을 순차적으로 생성하므로 이전 토큰에 기반한 점진적 추론이 자연스럽게 이루어진다. 반면 dLLM은 전체 시퀀스를 동시에 생성하는 과정에서 양방향 문맥을 활용하므로, 추론의 형태가 "순차적 단계 쌓기"보다는 "전체 구조의 점진적 정제"에 가깝다. 이러한 근본적 차이가 추론 과제에서 어떤 고유한 장점이나 단점을 제공하는지는 아직 충분히 탐구되지 않았다. 예를 들어 dLLM은 전체 해답의 구조를 한 번에 생성하므로, 해답의 전역적 일관성(global coherence)을 유지하는 데 유리할 수 있지만, 반면 중간 단계의 결과에 의존하는 점진적 추론에서는 불리할 수 있다. 예를 들어, dLLM의 양방향 어텐션은 해답의 전체 구조를 더 일관되게 유지하는 데 유리할 수 있지만, 반면에 순차적 의존성이 강한 추론 과정(예: 수학적 증명의 각 단계가 이전 단계에 의존하는 경우)에서는 불리할 수 있다. d1의 실험에서 수학 과제보다 계획 과제에서 더 큰 향상이 관찰된 것은 이러한 구조적 특성과 관련될 수 있으며, 향후 연구에서 이 가설을 체계적으로 검증할 필요가 있다.
또한 dLLM의 반자기회귀(semi-autoregressive) 디코딩 전략이 추론 성능에 미치는 영향도 흥미로운 연구 주제이다. 현재 d1에서 사용하는 디코딩 전략은 시퀀스를 32 토큰 블록으로 나누어 왼쪽에서 오른쪽으로 디코딩하며, 각 블록 내에서는 신뢰도가 높은 토큰부터 언마스킹한다. 이 전략은 완전 병렬 디코딩과 완전 순차 디코딩 사이의 절충점이며, 블록 크기, 토큰 선택 기준, 디코딩 순서 등이 모두 추론 성능에 영향을 미칠 수 있다. 특히 RL 훈련 중의 디코딩 전략과 평가 시의 디코딩 전략의 일관성이 성능에 어떤 영향을 미치는지는 추가 연구가 필요한 영역이다.
8. 결론: 확산 언어 모델 추론의 새로운 지평
d1은 확산 대형 언어 모델(dLLM)에 강화학습 기반 추론 향상을 최초로 성공적으로 적용한 프레임워크이다. 이 연구의 핵심 기여는 세 가지로 요약된다. 첫째, 마스크 dLLM의 시퀀스 로그 확률을 평균장 근사와 1단계 토큰별 로그 확률 추정으로 효율적으로 계산하는 방법을 제안했다. 둘째, 이 추정기를 기반으로 마스크 dLLM에 정책 경사 방법을 적용하는 최초의 알고리즘인 diffu-GRPO를 도입했으며, 프롬프트의 무작위 마스킹이 정책 최적화의 암묵적 정규화 역할을 하여 내부 업데이트 횟수를 크게 확장할 수 있음을 보여주었다. 셋째, SFT와 diffu-GRPO를 결합한 d1 레시피가 어느 한 방법만 사용하는 것보다 일관되게 우수한 성능을 달성함을 입증했다.
실험 결과는 d1이 수학적 추론(GSM8K, MATH500)과 계획(Countdown, Sudoku) 벤치마크 모두에서 기본 LLaDA-8B-Instruct 모델 대비 유의미한 성능 향상을 달성하며, 특히 계획 과제에서는 거의 2배에 가까운 향상을 보인다는 것을 보여준다. 코딩 도메인으로의 확장에서도 일관된 개선이 관찰되어, diffu-GRPO의 도메인 일반성이 확인된다. d1-LLaDA는 유사한 크기의 AR 모델과 비교하여 경쟁력 있는 성능을 달성하며, GSM8K에서는 최고 성능을 기록한다.
이 연구는 강화학습 기반 추론 향상이 자기회귀 모델에만 국한되지 않으며, 확산 기반 비자기회귀 모델에서도 효과적으로 작동할 수 있음을 최초로 실증적으로 입증했다는 점에서 중요한 의의를 가진다. dLLM은 양방향 어텐션, 병렬 디코딩 가능성, 코드-파인(coarse-to-fine) 생성 등 AR 모델과는 근본적으로 다른 특성을 가지고 있으며, 이러한 특성이 추론 과제에서 어떤 고유한 장점을 제공할 수 있는지는 아직 충분히 탐구되지 않았다. d1은 확산 언어 모델의 추론 능력 확장이라는 탐구의 중요한 첫 걸음으로, 향후 효율적인 디코딩 전략 개발, 가변 길이 생성 지원, 더 다양한 기반 모델에서의 검증 등을 통해 확산 추론 모델의 잠재력이 더욱 발현될 것으로 기대된다. 특히 dLLM의 양방향 어텐션과 병렬 디코딩 특성은 특정 유형의 추론 과제(구조적 제약 만족, 전역적 일관성이 중요한 과제)에서 AR 모델 대비 고유한 장점을 제공할 수 있으며, d1의 diffu-GRPO와 같은 RL 기법이 이러한 장점을 더욱 증폭시킬 수 있는 가능성을 열어준다.
방법론적 관점에서, d1이 제안한 평균장 근사 기반 로그 확률 추정과 프롬프트 무작위 마스킹의 정규화 효과는 마스크 dLLM에 국한되지 않는 보다 일반적인 원리를 담고 있다. 확률적 섭동을 통한 정규화, 단일 패스 근사에 의한 계산 효율화, 데이터 증강을 통한 학습 신호 확대 등의 개념은 다른 비자기회귀 모델이나 이산 확산 모델에도 적용 가능할 수 있다. 이러한 원리의 보편성을 검증하는 것 또한 매우 흥미로운 후속 연구 방향이 될 것이다. 궁극적으로 d1은 "RL을 통한 추론 향상은 AR 모델의 전유물이 아니다"라는 핵심 메시지를 전달하며, 다양한 생성 패러다임에서의 추론 능력 연구에 새로운 가능성을 제시한다. dLLM 연구 커뮤니티가 빠르게 성장하고 있는 현 시점에서, d1이 제시한 방법론과 실험적 통찰은 후속 연구의 중요한 기초와 출발점이 될 것으로 기대된다. 특히 LLaDA, Dream, Mercury 등 다양한 dLLM 아키텍처가 계속 등장하고 있으며, 이들 각각의 아키텍처적 특성에 최적화된 RL 기법의 체계적 개발이 dLLM 생태계의 추론 능력을 전반적으로 끌어올리는 데 핵심적으로 기여할 것이다.
9. 요약 정리
- d1 프레임워크: 사전 훈련된 마스크 기반 확산 대형 언어 모델(dLLM)을 추론 모델로 변환하기 위한 2단계 사후 훈련 파이프라인(SFT + diffu-GRPO)을 제안한다.
- diffu-GRPO: 마스크 dLLM에 정책 경사 방법을 적용한 최초의 강화학습 알고리즘으로, 평균장 근사와 1단계 토큰별 로그 확률 추정을 핵심 기술로 사용한다.
- 프롬프트 무작위 마스킹의 정규화 효과: 각 경사 업데이트마다 프롬프트에 서로 다른 마스킹 패턴을 적용하여, 내부 업데이트 횟수($\mu$)를 12~24까지 확장하면서도 안정적 학습을 유지하고 계산 비용을 크게 절감한다.
- d1 레시피의 시너지: SFT 후 diffu-GRPO를 적용하는 d1 조합이 어느 한 방법만 사용하는 것보다 12개 중 11개 설정에서 우수한 성능을 달성하며, 계획 과제에서 최대 26.2%(Countdown)의 향상을 보인다.
- 경쟁력 있는 성능: d1-LLaDA는 GSM8K에서 82.1%로 유사 크기의 AR 모델(Qwen2.5 7B: 78.9%)과 dLLM(Dream 7B: 77.2%)을 모두 능가하는 최고 성능을 달성한다.
- 다중 과제 확장성: 4개 과제의 결합 데이터셋으로 훈련한 단일 통합 모델도 과제별 모델과 비슷한 수준의 성능을 유지하며, diffu-GRPO의 다중 과제 학습 효과를 입증한다.
- 코딩 도메인 확장: HumanEval과 MBPP에서 diffu-GRPO는 초기화 지점에 관계없이 대부분의 설정에서 일관된 성능 향상을 제공하여 도메인 일반성을 확인한다.
- 유레카 순간의 출현: SFT와 d1-LLaDA 모델에서 512 토큰 생성 시 자기 검증 및 자기 수정 행동("유레카 순간")이 관찰되며, 이는 s1K 추론 트레이스에서 내재화된 능력이다.
- 최적 마스킹 확률: $p_{\text{mask}} = 0.1 \sim 0.3$이 훈련 안정성과 최종 성능 모두에서 최적이며, 높은 마스킹 확률(0.5+)은 훈련 후반부에서 불안정성을 초래한다.
- 향후 과제: 고정 길이 생성 제약 극복, dLLM의 효율적 디코딩 전략 개발, 가변 길이 생성 모델(Block Diffusion 등)에의 적용, 다양한 기반 모델에서의 검증이 핵심 미래 연구 방향이다.