TRACE Back from the Future: A Probabilistic Reasoning Approach to Controllable Language Generation
https://arxiv.org/abs/2504.18535
Gwen Yidou Weng, Benjie Wang, Guy Van den Broeck | University of California, Los Angeles (UCLA) | arXiv:2504.18535 | 2025년 4월 | ICML 2025 게재 확정
1. 서론: 자기회귀 언어 모델의 전역적 속성 제어 문제
대형 언어 모델(LM)이 상용 제품과 일상생활에 점점 더 깊이 침투하면서, 이들의 출력을 제어해야 할 필요성이 급격히 증가하고 있다. 독성 제거(detoxification), 개인화(personalization), 주제 제어(topic control) 등 다양한 목표가 존재하며, 이러한 속성들은 생성된 텍스트 전체에 걸쳐 나타나는 전역적 속성(global property)이라는 공통점을 지닌다. 그러나 현재의 자기회귀(autoregressive) 언어 모델은 각 토큰을 이전 토큰들에만 기반하여 생성하는 구조를 가지고 있어, 미래의 시퀀스가 특정 속성을 충족할지 여부를 사전에 고려하지 못한다. 이는 제어 가능한 텍스트 생성(controllable text generation)이 근본적으로 어려운 이유를 설명한다.
이 문제를 해결하기 위한 기존 접근법들은 크게 두 가지 범주로 나뉜다. 첫째, 학습 기반 방법(training-based methods)으로, 파인튜닝이나 강화학습(RL, RLHF)을 통해 기본 모델의 분포 자체를 변경하는 방식이다. PPO, DPO, Quark 등이 여기에 해당하며, 이들은 각 새로운 속성에 대해 대규모 데이터와 높은 비용의 재학습이 필요하고, 유창성(fluency)과 다양성(diversity)을 저하시키는 위험이 있다. 둘째, 디코딩 기반 방법(decoding-based methods)으로, 사전학습된 LM의 파라미터를 변경하지 않고 디코딩 과정에서 속성 충족 가능성을 추정하여 토큰 생성을 유도하는 방식이다. GeDi, FUDGE, DExperts 등이 판별자를 학습하여 이를 추정하고, MuCoLa, Controlled Decoding 등은 미래 시퀀스를 샘플링하여 기대 속성 확률을 근사한다. 그러나 이들 역시 판별자 학습에 많은 데이터와 시간이 필요하거나, 샘플링 기반 추정의 높은 분산과 계산 비용이라는 한계를 보인다.
이 문제의 핵심적 어려움은 "자기회귀적 생성과 전역적 속성 평가 사이의 근본적 불일치"에 있다. 자기회귀 모델은 좌에서 우로 토큰을 순차적으로 생성하지만, 텍스트가 독성인지, 특정 캐릭터의 스타일을 반영하는지, 정치적 주제를 다루는지는 전체 텍스트를 봐야만 판단할 수 있다. 각 토큰을 생성할 때 아직 생성되지 않은 미래 토큰들이 전체 텍스트의 속성에 어떻게 기여할지를 예측해야 하며, 이는 본질적으로 "미래를 되돌아보는(trace back from the future)" 것을 필요로 한다. 논문의 제목은 바로 이 개념적 핵심을 반영한다.
본 논문은 이러한 한계를 극복하기 위해 TRACE(Tractable Probabilistic Reasoning for Adaptable Controllable Generation)라는 새로운 프레임워크를 제안한다. TRACE의 핵심 아이디어는 기본 LM으로부터 은닉 마르코프 모델(Hidden Markov Model, HMM)을 일회성으로 증류(distill)하고, 이를 경량 분류기와 결합하여 기대 속성 확률(Expected Attribute Probability, EAP)을 정확하고 효율적으로 계산하는 것이다. 이 EAP는 다음 토큰의 확률을 재가중하여, 미래 시퀀스가 원하는 속성을 충족할 가능성이 높은 방향으로 생성을 유도한다. 중요한 점은 TRACE가 HMM의 다루기 쉬운(tractable) 구조와 인수분해된(factorized) 분류기의 조합을 통해, 지수적으로 많은 미래 시퀀스에 대한 EAP를 정확하게 계산할 수 있다는 것이다.
논문의 Figure 1은 TRACE의 핵심 동작 원리를 직관적으로 보여주는 개념도이다. "It's a pain"이라는 프롬프트가 주어졌을 때, 다음 토큰으로 "in"을 생성할지 "to"를 생성할지 결정하는 과정을 예시로 든다. "in"이 선택되면 "the ass"(독성), "the butt" 등의 미래 연속이 높은 확률로 예측되어 EAP가 0.1로 낮다. 반면 "to"가 선택되면 "deal with", "handle" 등 비독성 연속이 예측되어 EAP가 0.8로 높다. LM은 "in"에 $p_{\text{lm}} = 0.3$의 높은 확률을 부여하지만, TRACE는 EAP를 곱하여 $p_{\text{TRACE}} \propto 0.3 \times 0.1 = 0.03$으로 낮추고, "to"는 $p_{\text{lm}} = 0.1$에 EAP 0.8을 곱하여 $p_{\text{TRACE}} \propto 0.08$로 높인다. 결과적으로 "to"가 선호되어 비독성 방향으로 생성이 유도된다. 이 과정에서 HMM이 미래 시퀀스의 분포를 효율적으로 모델링하여 EAP의 정확한 계산을 가능하게 하는 것이 핵심이다.
논문은 TRACE를 세 가지 중요한 과제에서 평가한다. 독성 제거에서는 GPT2-Large와 Gemma 2B에 대해 기존 RL, 학습 기반, 샘플링 기반 베이스라인을 능가하는 최첨단 성능을 달성한다. 개인화된 LLM 생성에서는 약 3초 만에 76개의 개별 캐릭터에 적응하여 프롬프팅 기반 접근법을 능가한다. 복합 속성 제어에서는 정치적이면서 독성이 없는 텍스트처럼 희소한 속성 조합을 재학습 없이 원활하게 처리한다. 특히 TRACE는 기본 LM 대비 약 20%의 디코딩 오버헤드만으로 이러한 결과를 달성하며, 이는 기존 방법들의 7.5배에서 40배에 달하는 오버헤드와 극명한 대조를 이룬다.
2. 배경 및 관련 연구: 제어 가능한 텍스트 생성의 기존 접근법
2.1 학습 기반 방법: 모델 파라미터 수정
제어 가능한 텍스트 생성은 최근 몇 년간 자연어 처리 분야에서 가장 활발하게 연구되는 주제 중 하나로, LLM의 상용화가 가속됨에 따라 그 중요성이 더욱 커지고 있다. 기존 방법들의 한계를 이해하는 것은 TRACE의 기여를 올바르게 위치짓기 위해 필수적이다.
학습 기반 방법은 기본 LM의 파라미터를 직접 수정하여 원하는 속성을 모델의 분포에 주입하는 접근법이다. DAPT(Domain-Adaptive Pre-Training)는 도메인 특화 데이터로 기본 LM을 파인튜닝하며, PPO(Proximal Policy Optimization)는 보상 모델과 정책 경사를 사용하여 비독성 같은 원하는 행동으로 LM을 파인튜닝한다. DPO(Direct Preference Optimization)는 명시적 보상 모델 없이 쌍별 선호도를 활용하여 모델을 정렬하고, Quark는 학습된 보상 토큰에 조건화된 RL 유사 절차를 사용한다. 이러한 방법들의 주요 단점은 각 새로운 속성이나 속성 집합에 대해 대규모 데이터와 높은 비용의 재학습이 필요하다는 것이다. 더불어 기본 LM을 수정하면 일반적인 유창성과 다양성이 저하될 위험이 있다는 점이 여러 연구에서 지적되어 왔다.
2.2 디코딩 기반 방법: 판별자 학습과 샘플링
디코딩 기반 방법은 고정된 사전학습 LM의 디코딩 과정을 수정하여 원하는 속성 방향으로 생성을 유도하는 접근법이다. 이 방법들은 대부분 미래 텍스트의 기대 속성 확률(EAP) 추정치를 통합하는 방식으로 동작한다. 핵심 난제는 정확한 EAP 계산이 미래 시퀀스에 대한 합산을 필요로 하며, 이는 시퀀스 길이에 대해 지수적이라는 것이다.
판별자 학습 기반 접근법에서 FUDGE와 NADO는 부분 생성으로부터 속성 만족도를 근사하는 판별자를 학습한다. DExperts는 전문가(expert)와 반전문가(anti-expert) LM을 혼합하고, GeDi는 속성 조건화된 가이드와 베이즈 규칙을 사용한다. LiSeCo는 잠재 공간에서 선형 탐침을 적용한다. 이들 방법의 공통적 도전은 접두사로부터 미래 속성 만족도를 정확하게 추정하려면 비자명한 선행 탐색(lookahead)이 필요하며, 속성마다 별도의 대형 보조 모델을 학습해야 한다는 상당한 오버헤드이다.
샘플링 기반 접근법에서는 미래 시퀀스를 샘플링하여 기대 결과를 추정한다. Controlled Decoding과 Transfer Q*는 제한된 토큰 수준의 선행 탐색을 수행하고, MuCoLa, Mix and Match, COLD 등은 에너지 기반 모델을 사용하여 전체 시퀀스에 대한 MCMC 스타일 샘플링을 수행한다. 두 접근법 모두 디코딩 중 상당한 계산 오버헤드를 유발하며, 결과적인 EAP 추정치는 특히 희소한 속성에 대해 높은 분산을 가질 수 있다.
이러한 기존 방법들의 한계는 정확한 EAP 계산의 본질적 어려움에서 비롯된다. EAP는 모든 가능한 미래 시퀀스에 대한 합산을 필요로 하며, 이는 어휘 크기 $V$와 남은 시퀀스 길이 $n-t$에 대해 $V^{n-t}$개의 가능한 연속을 고려해야 함을 의미한다. 어휘 크기가 50,000이고 남은 시퀀스 길이가 20만 되어도 가능한 연속의 수는 $50000^{20}$으로 천문학적이다. 이 계산을 정확하게 수행하는 것은 일반적인 경우에 NP-hard로 증명되어 있으며, 이것이 모든 기존 방법이 어떤 형태로든 근사를 사용하는 이유이다.
논문은 모든 EAP 기반 제어 방법이 기본 LM 하에서의 비다루기 쉬운(intractable) EAP를 근사해야 하지만, 근사의 성격이 크게 다르다고 지적한다. 판별자/가이드 기반 및 샘플링 기반 접근법은 디코딩 중에 직접 EAP를 추정하며, 속성별 학습이나 높은 분산과 실행 시간 비용이 수반된다. 반면 TRACE는 근사의 부담을 일회성 HMM 증류 단계로 이동시켜, $p_{\text{hmm}} \approx p_{\text{lm}}$이 되도록 한다. 이 증류된 HMM을 조건으로 하여 TRACE는 HMM 분포에 대해 EAP를 정확하고 다루기 쉽게(tractable) 계산할 수 있다.
2.3 다루기 쉬운 확률 모델을 통한 제어
HMM과 같은 다루기 쉬운 확률 모델(tractable probabilistic models)은 주변 확률(marginal)이나 논리적 제약 조건의 만족 확률 등 다양한 양을 효율적으로 계산할 수 있다. 이러한 계산은 자기회귀 모델에서는 근사조차 증명적으로 어려운(provably hard) 것으로 알려져 있다. 선행 연구에서 Zhang et al. (2023, 2024)은 HMM을 사용하여 결정론적 유한 자동자(DFA)로 정의되는 논리적 제약 조건, 예를 들어 특정 키워드의 존재 같은 조건을 강제하였다.
그러나 이러한 접근법은 형식적으로 명세 가능한(formally specifiable) 제약 조건에는 강력하지만, 스타일, 안전성, 페르소나 같은 고수준 의미적 속성(semantic attributes)으로는 쉽게 확장되지 않는다. 이러한 속성들은 기호적 정의(symbolic definition)가 부재하고 텍스트의 전체적 의미에 의존하기 때문이다. TRACE는 HMM을 의미적 제어에 고유하게 활용하여 이 격차를 해소하며, 논리적 규칙을 강제하는 대신 의미적 속성에 대한 효율적인 확률적 추론(EAP 계산)을 가능하게 한다. 이는 다루기 쉬운 확률 모델의 적용 범위를 논리적 제약에서 의미적 속성 제어로 확장한 학술적으로도 실용적으로도 매우 중요한 기여이다.
3. 방법론: TRACE - HMM 기반 다루기 쉬운 확률적 추론을 통한 제어
TRACE의 전체적인 방법론은 세 단계로 구성된다. 첫째, 기본 LM으로부터 다루기 쉬운 HMM을 일회성으로 증류한다. 둘째, 각 원하는 속성에 대해 경량 로그-선형 분류기를 학습한다. 셋째, 디코딩 시 HMM과 분류기를 결합하여 EAP를 정확하게 계산하고, 이를 통해 LM의 다음 토큰 확률을 재가중한다. 이 세 단계의 핵심적 설계 원리는 생성 모델 학습과 제어를 분리(decouple)하는 것이다. HMM 증류는 한 번만 수행하면 되고, 이후 어떤 새로운 속성에 대해서도 분류기만 학습하면 적응할 수 있다. 이 설계는 기존의 속성별 재학습이 필요한 방법들과 근본적으로 차별화되는 지점이다.
3.1 문제 정의: 제어 가능한 생성과 기대 속성 확률(EAP)
TRACE의 방법론을 이해하기 위해 먼저 제어 가능한 생성의 수학적 정의를 살펴본다. 길이 $n$의 텍스트(토큰 시퀀스) $x_{1:n}$을 언어 모델(LM)로부터 생성한다고 하자. 제어 가능한 생성에서의 목표는 비독성(nontoxicity)과 같은 속성 $s$에 조건화된 LM의 분포로부터 텍스트를 생성하는 것이다. 속성의 만족도는 확률적 분류기 $p(s|x_{1:n}) \in [0,1]$로 측정된다고 가정한다. 기본 LM 분포를 $p_{\text{lm}}(x_{1:n})$으로 표기하면, 텍스트 $x_{1:n}$과 속성 $s$에 대한 결합 분포는 다음과 같이 정의된다:
$$p_{\text{lm}}(x_{1:n}, s) = p_{\text{lm}}(x_{1:n}) \cdot p(s|x_{1:n})$$
목표는 조건부 분포 $p_{\text{lm}}(x_{1:n} \mid s)$로부터 생성하는 것이며, 이는 자기회귀적으로 분해할 수 있다. 베이즈 규칙을 적용하면 조건부 다음 토큰 분포는 다음과 같다:
$$p_{\text{lm}}(x_t \mid x_{<t}, s) \propto p_{\text{lm}}(x_t \mid x_{<t}) \cdot p_{\text{lm}}(s \mid x_t, x_{<t})$$
첫 번째 항은 단순히 LM의 다음 토큰 분포이다. 두 번째 항은 속성 $s$를 만족시킬 확률인데, 이를 계산하려면 모든 가능한 미래 연속 $x_{>t}$에 대한 합산이 필요하며, 이는 시퀀스 길이에 대해 지수적이다:
$$p_{\text{lm}}(s \mid x_t, x_{<t}) = \sum_{x_{>t}} p(s|x_{\leq t}, x_{>t}) \cdot p_{\text{lm}}(x_{>t} \mid x_{\leq t})$$
이 양을 논문은 기대 속성 확률(Expected Attribute Probability, EAP)이라 부른다. EAP는 가능한 토큰 생성 $x_t$를 원하는 속성을 최종적으로 만족하는 텍스트가 될 가능성에 따라 재가중하는 데 사용된다. GeDi, DExperts는 단계별 판별자를 학습하고, Controlled Decoding과 MuCoLa는 미래 시퀀스를 샘플링하여 이 계산적으로 어려운 합산을 근사하지만, TRACE는 은닉 마르코프 모델(HMM)을 활용하여 비용이 큰 샘플링이나 재학습 없이 미래 시퀀스 정보를 다루기 쉬운 방식으로 통합하는 것을 목표로 한다.
3.2 은닉 마르코프 모델(HMM)의 구조와 다루기 쉬운 추론
은닉 마르코프 모델(HMM)은 잠재 변수 $z_{1:n}$과 관측 변수 $x_{1:n}$에 대한 결합 분포를 다음과 같이 명세한다:
$$p(x_{1:n}, z_{1:n}) = p(z_1) \cdot p(x_1 \mid z_1) \cdot \prod_{t=2}^{n} p(z_t \mid z_{t-1}) \cdot p(x_t \mid z_t)$$
언어 모델링에서 각 $z_t$는 $\{0, \ldots, h-1\}$의 값을 취하며 여기서 $h$는 은닉 상태 크기이고, 관측 변수 $x_t$는 $\{0, \ldots, V-1\}$의 값을 취하는 토큰으로 $V$는 어휘 크기이다. 동질적(homogeneous) HMM은 전이 행렬 $p(z_t|z_{t-1})$에 대해 $h^2$개, 방출 행렬 $p(x_t|z_t)$에 대해 $h \cdot V$개, 초기 은닉 상태 분포 $p(z_1)$에 대해 $h$개의 파라미터를 가진다.
HMM은 깊은 신경망에 비해 훨씬 제한된 표현력을 가지지만, 이 제한된 표현력이 정확히 TRACE에서 필요로 하는 다루기 쉬움을 보장한다. 이는 "표현력과 다루기 쉬움 사이의 트레이드오프(expressiveness-tractability trade-off)"라는 확률 모델 이론의 핵심 원칙을 반영한다. 더 표현력 있는 모델(예: Transformer)은 더 복잡한 분포를 포착할 수 있지만 주변화나 조건화 같은 추론이 비다루기 쉬워지고, 반대로 HMM처럼 구조가 제한된 모델은 이러한 추론을 효율적으로 수행할 수 있다. TRACE의 핵심 통찰은 이 트레이드오프를 LM(표현력 담당)과 HMM(추론 담당)에 분할하여 각각의 장점을 결합하는 것이다.
HMM을 언어 모델링에 사용하는 핵심 이점은 그 다루기 쉬움(tractability)에 있다. 토큰 시퀀스의 확률과 같은 많은 양이 HMM 크기와 시퀀스 길이에 대해 선형 시간에 추론될 수 있다. Zhang et al. (2023, 2024)은 특정 키워드의 존재 같은 논리적 제약 조건 하에서 생성하기 위해 대형 언어 모델로부터 HMM 모델을 증류하였다. TRACE는 이러한 HMM을 논리적 제약 대신 기대 속성 확률을 효율적으로 계산하는 알고리즘을 설계하는 데 활용한다는 점에서 차별화된다.
3.3 TRACE의 핵심: HMM 확률을 통한 LM 유도
제약된 다음 토큰 확률 $p(x_t \mid x_{<t}, s)$를 근사하기 위해, TRACE는 기대 속성 확률 $p_{\text{lm}}(s \mid x_t, x_{<t})$를 HMM 하의 대응 양으로 대체할 것을 제안한다:
$$p_{\text{TRACE}}(x_t \mid x_{<t}, s) \propto p_{\text{lm}}(x_t \mid x_{<t}) \cdot p_{\text{hmm}}(s \mid x_{<t}, x_t)$$
여기서 $p_{\text{hmm}}(s \mid x_{<t}, x_t)$는 HMM과 속성 분류기 하에서 전체 미래 연속이 속성을 만족시킬 확률이다. Zhang et al. (2023)의 공식화와 달리, $s$는 0 또는 1로 매핑되는 논리적 속성이 아니라 확률적 분류기 $p(s|x_{1:n})$에 의해 주어지는 의미적 속성이다. 분류기 $p(s|x_{1:n})$가 신경망처럼 임의의 구조를 가진다면, 기대 속성 확률 계산은 다시 비다루기 쉽게 된다. TRACE의 핵심적 통찰은 분류기에 특정 구조를 부여함으로써 이 계산을 다루기 쉽게 만든다는 것이다.
3.4 EAP의 다루기 쉬운 계산: 전방-후방 알고리즘
HMM 하의 기대 속성 확률 $p_{\text{hmm}}(s \mid x_t, x_{<t})$는 미래 시퀀스 $x_{>t}$와 은닉 상태 $z_t$를 도입하고, HMM의 조건부 독립 성질 $x_{>t} \perp\!\!\!\perp x_{\leq t} | z_t$를 활용하여 주변화함으로써 다시 쓸 수 있다:
$$p_{\text{hmm}}(s \mid x_t, x_{<t}) = \sum_{z_t} p_{\text{hmm}}(z_t \mid x_{\leq t}) \cdot \left[\sum_{x_{>t}} p_{\text{hmm}}(x_{>t} \mid z_t) \cdot p(s \mid x_{>t}, x_{\leq t})\right]$$
이 식은 두 개의 핵심 구성요소를 포함한다. 전방 계산(Forward Computation)에서는 $p_{\text{hmm}}(z_t \mid x_{\leq t})$를 계산하며, 이는 HMM 전방 알고리즘을 통해 다음의 재귀 관계로 수행된다:
$$p_{\text{hmm}}(z_t, x_{\leq t}) = \sum_{z_{t-1}} p(x_t \mid z_t) \cdot p(z_t \mid z_{t-1}) \cdot p_{\text{hmm}}(z_{t-1}, x_{\leq t-1})$$
기저 사례는 $p_{\text{hmm}}(z_1, x_{\leq 1}) = p(z_1) \cdot p(x_1|z_1)$이며, 정규화 상수로 나누어 조건부 확률을 얻는다. 이 계산은 분류기와 독립적이라는 점이 중요하다.
후방 계산(Backward Computation)에서는 대괄호 안의 항을 다루기 쉽게 계산해야 한다. 이를 위해 분류기 $p(s|x_{>t}, x_{\leq t})$가 후방 알고리즘에 통합될 수 있는 유사한 구조를 가져야 한다. 충분 조건은 분류기를 $p(s|x_{1:n}) = \prod_i w(x_i)$ 형태의 인수분해된 분류기(factorized classifier)로 제한하는 것이다. 여기서 $w(x_i)$는 어휘의 각 토큰에 가중치를 할당하는 함수이며, 분류기가 $[0, 1]$ 범위의 값을 출력하도록 모든 가중치 $w(x_i) \in [0,1]$로 강제한다.
이 인수분해된 분류기를 사용하면, 대괄호 항을 다음과 같이 전개할 수 있다:
$$\sum_{x_{>t}} p_{\text{hmm}}(x_{>t}|z_t) \cdot p(s|x_{>t}, x_{\leq t}) = \left(\prod_{i \leq t} w(x_i)\right) \cdot \mathbb{E}_{\text{hmm}}\left[\prod_{i>t} w(x_i) \Bigm| z_t\right]$$
기대값 항 $\mathbb{E}_{\text{hmm}}\left[\prod_{i>t} w(x_i) | z_t\right]$은 시간상 후방으로 재귀적으로 계산된다. 기저 사례는 $\mathbb{E}\left[\prod_{i>n} w(x_i) | z_n\right] = 1$이며 ($x_n$ 이후에 토큰이 없으므로), $t < n$에 대한 재귀식은 다음과 같다:
$$\mathbb{E}_{\text{hmm}}\left[\prod_{i>t} w(x_i) \Bigm| z_t\right] = \sum_{z_{t+1}} p(z_{t+1} \mid z_t) \cdot \mathbb{E}_{\text{hmm}}\left[\prod_{i>t+1} w(x_i) \Bigm| z_{t+1}\right] \cdot \sum_{x_{t+1}} p(x_{t+1} \mid z_{t+1}) \cdot w(x_{t+1})$$
여기서 결정적으로 중요한 점은 $\mathbb{E}_{\text{hmm}}\left[\prod_{i>t} w(x_i) | z_t\right]$ 값들이 단일 후방 패스에서 사전 계산 및 캐싱될 수 있으며, 이들이 은닉 상태 $z_t$에만 의존하고 특정 접두사 $x_{\leq t}$에는 의존하지 않기 때문에 모든 생성에 걸쳐 재사용할 수 있다는 것이다. 이 사전 계산은 $O(n(hV + h^2))$ 시간이 필요하며, $O(nh)$ 캐시 메모리가 필요하다. 생성 중 각 시간점에서 EAP 계산은 $O(h^2 + hV)$이며, 실제로 이는 언어 모델의 다음 토큰 확률 계산에 비해 무시할 수 있는 시간이 소요된다.
3.5 TRACE 알고리즘 요약
Algorithm 1은 TRACE의 전체 접근법을 요약한다. 알고리즘은 크게 두 단계로 나뉜다. 첫 번째 단계는 후방 사전 계산(Backward Precomputation)으로, $n$부터 1까지 시간을 역순으로 반복하며 각 시간점 $t$와 은닉 상태 $z_t$에 대한 기대값 $P[t, z_t] := \mathbb{E}_{\text{hmm}}\left[\prod_{i>t} w(x_i) | z_t\right]$을 사전 계산한다. 이 값들은 생성할 시퀀스의 길이 $n$이 결정되면 한 번만 계산하면 되며, 분류기 가중치 $w$와 HMM의 전이 및 방출 확률에만 의존하므로 특정 프롬프트나 접두사에 독립적이다. 따라서 동일한 속성과 시퀀스 길이에 대해 여러 생성에 걸쳐 재사용할 수 있어 효율성이 크게 향상된다.
두 번째 단계는 전방 생성(Forward Generation)으로, 1부터 $n$까지 순서대로 각 시간점에서 세 가지 연산을 수행한다. 먼저 HMM 전방 알고리즘으로 현재까지의 접두사 $x_{\leq t}$가 주어졌을 때 은닉 상태의 사후 분포 $p_{\text{hmm}}(z_t | x_{\leq t})$를 계산한다. 다음으로 이 사후 분포와 사전 계산된 $P[t, z_t]$를 결합하여 EAP $p_{\text{hmm}}(s \mid x_{<t}, x_t)$를 계산한다. 마지막으로 EAP와 LM의 다음 토큰 확률 $p_{\text{lm}}(x_t \mid x_{<t})$의 곱에 비례하여 토큰 $x_t$를 샘플링한다. 이 과정에서 기본 LM은 다음 토큰 확률을 제공하는 역할만 수행하며, 그 파라미터는 전혀 수정되지 않는다.
알고리즘의 계산 복잡도를 분석하면, 사전 계산 단계에서는 $O(n(hV + h^2))$ 시간이 필요하다. 여기서 $n$은 시퀀스 길이, $h$는 은닉 상태 크기, $V$는 어휘 크기이다. 캐시 메모리는 $O(nh)$로, 각 시간점의 각 은닉 상태 값에 해당한다. 생성 중 각 시간점에서의 EAP 계산은 $O(h^2 + hV)$이다. 실제로 이는 언어 모델의 다음 토큰 확률 계산(일반적으로 수십억 파라미터의 순전파)에 비해 무시할 수 있는 시간이 소요된다. 예를 들어 $h=4096$, $V=50257$(GPT-2 어휘 크기)일 때 EAP 계산은 약 2억 번의 연산을 필요로 하지만, GPT2-Large의 순전파는 수백억 번의 연산을 필요로 하므로 EAP 계산의 비용은 상대적으로 미미하다.
3.6 속성 분류기 학습: Log-MSE 손실과 확률 변환
TRACE의 속성 분류기 학습은 전체 프레임워크에서 가장 경량적인 구성요소이면서도, 제어의 효과성을 좌우하는 핵심 요소이다. 분류기는 어휘의 각 토큰에 대해 하나의 가중치 $w(x_i)$를 학습하므로, 전체 파라미터 수는 어휘 크기 $V$에 불과하다. GPT-2의 경우 50,257개, Gemma-2B의 경우 약 256,000개의 파라미터로, 이는 수십억 파라미터의 LM과 비교할 때 극히 미미한 규모이다. 이 극단적인 단순성이 초단위 학습을 가능하게 하는 원천이다. 분류기의 학습은 어휘의 각 토큰에 대한 가중치를 최적화하는 것으로, 이는 본질적으로 어휘 크기 차원의 볼록 최적화(convex optimization) 문제에 해당하며 빠르게 수렴한다.
EAP 계산을 다루기 쉽게 만드는 분류기 클래스는 토큰에 대한 곱, 즉 로그 공간에서 선형인 형태이다. 실제로 속성은 완전히 인수분해 가능하지 않지만(정도는 다양함), 논문은 이러한 단순한 분류기가 HMM과 결합될 때 신경 분류기를 사용하는 베이스라인(예: GeDi, FUDGE)보다 우수한 EAP를 포착할 수 있음을 보인다.
TRACE는 시퀀스 $x_{1:n}$이 목표 속성 $s$를 만족시킬 확률을 점수화하는 오라클(oracle) $p_{\text{oracle}}$에 접근 가능하다고 가정한다. 이 오라클은 학습된 분류기(예: 인간 주석으로부터)이거나 속성 만족도를 점수화하는 외부 API일 수 있다. 독성이나 정치적 콘텐츠와 같이 자연 텍스트에서 희소한 속성을 효과적으로 모델링하기 위해, 학습 목적함수는 희소 속성을 나타내는 텍스트와 더 일반적인 중립 텍스트를 구별해야 한다. 교차 엔트로피 같은 표준 목적함수는 모든 오분류를 대칭적으로 처리하므로, 한 클래스가 희소할 때는 최적이 아니다.
따라서 TRACE는 희소 예시의 오분류에 더 큰 페널티를 부과하는 비대칭 손실(asymmetric loss)을 사용한다. 구체적으로 로그 공간에서의 평균 제곱 오차(log-MSE) 손실을 사용하며, 이는 낮은 확률 영역에서 오차 페널티를 증폭한다. 이 목적함수와 정렬하기 위해, 각 속성을 그 부재로 정의한다(예: "독성" 대신 "비독성"을 모델링). 인수분해된(로그-선형) 분류기에서, 텍스트 $x_{1:n}$이 주어졌을 때 속성 $s$의 로그 확률은 로그 가중치의 합 $\log p(s \mid x_{1:n}) = \sum_{i=1}^{n} \log w(x_i)$이다. 손실 함수는 다음과 같다:
$$\left\|\log p_{\text{oracle}}(x) - \sum_{i=1}^{n} \log w(x_i)\right\|^2$$
예를 들어, 실제 오라클 점수가 $p_{\text{oracle}} = 0.1$(독성)일 때 0.5의 예측에 대한 페널티가, $p_{\text{oracle}} = 0.9$(비독성)일 때 0.5의 예측에 대한 페널티보다 훨씬 크다. 이는 교차 엔트로피가 이 두 결과에 무차별적인 것과 대조된다. 구체적으로 log-MSE 손실을 계산해 보면, $p_{\text{oracle}} = 0.1$이고 예측이 0.5일 때 손실은 $(\log 0.1 - \log 0.5)^2 = (-2.303 - (-0.693))^2 = (-1.609)^2 \approx 2.59$인 반면, $p_{\text{oracle}} = 0.9$이고 예측이 0.5일 때 손실은 $(\log 0.9 - \log 0.5)^2 = (-0.105 - (-0.693))^2 = (0.588)^2 \approx 0.35$이다. 즉 동일한 예측 오차에 대해 낮은 확률 영역에서의 페널티가 약 7.4배 더 크며, 이는 희소 속성의 식별에 매우 효과적이다.
또한 논문은 각 속성을 그 부재로 정의하는 전략을 채택한다. 즉, "독성"을 직접 모델링하는 대신 "비독성"을 모델링한다. 이 설계 선택의 이유는 log-MSE 손실이 낮은 확률 영역에서 오차를 증폭하므로, 원하지 않는 텍스트(독성)가 낮은 확률을 갖도록 설정하면 분류기가 이를 더 정확하게 포착할 수 있기 때문이다. 비독성 확률이 0.1인 텍스트(매우 독성)는 로그 공간에서 큰 음의 값을 가지며, log-MSE 손실은 이 영역에서의 오차에 더 민감하게 반응한다.
3.7 확률 변환(Probability Transformation): 더 나은 제어를 위한 기법
실제로 원시 오라클 확률 점수를 변환하여 원하는 출력과 원하지 않는 출력 사이의 구분을 더 명확히 하고, 더 엄격한 속성 만족을 강제하는 것이 유익할 수 있다. 예를 들어, 오라클의 20% 비독성 점수를 더 낮은 값으로 변환하여 더 안전한 생성을 장려할 수 있다. 이를 위해 TRACE는 로짓 공간에서 (비음수) 스케일($b$)과 이동($c$)을 사용한 아핀 변환을 오라클 점수에 적용할 것을 제안한다:
$$p'_{\text{oracle}} = \sigma\left(b \cdot \ln\left(\frac{p_{\text{oracle}}}{1 - p_{\text{oracle}}}\right) + c\right)$$
여기서 $\sigma(z)$는 시그모이드 함수이다. 이 변환은 목표 분포를 재형성하며, 구체적으로 스케일 $b$를 증가시키면 중간 확률들이 0과 1의 극단으로 밀려나 더 쌍봉 분포(bimodal distribution)를 생성한다. 이는 속성 준수 텍스트와 비준수 텍스트를 명확히 구별하는 데 도움이 된다. 이 확률 변환은 학습 시(training time)에 오라클 점수에 적용될 수 있고, 디코딩 시(decoding time)에 EAP에 적용될 수도 있으며, 두 단계에서 상호 보완적인 효과를 제공한다.
4. 실험 설정: 데이터셋, 메트릭, 베이스라인
4.1 데이터셋 및 벤치마크
TRACE의 성능을 공정하고 포괄적으로 평가하기 위해 논문은 각기 다른 특성을 가진 세 가지 도전적인 제어 가능한 생성 과제를 선정하였다. 이 과제들은 데이터 풍부도(풍부~희소), 속성 복잡도(단일~복합), 평가 방식(자동~인간 정렬) 면에서 상호 보완적으로 설계되어 TRACE의 일반성을 다각도로 검증한다.
TRACE는 세 가지 도전적인 제어 가능한 생성 과제에서 평가된다. 독성 제거(Detoxification) 과제에서는 RealToxicityPrompts 데이터셋을 사용하며, GPT-2 Large에 대해 10,000개의 테스트 프롬프트, Gemma-2B에 대해 1,000개의 테스트 프롬프트를 활용한다. 각 프롬프트에 대해 25개의 연속문(continuation)을 생성한다. 역할 연기(Role-playing) 과제에서는 RoleBench 데이터셋의 76개 캐릭터를 사용하며, 각 캐릭터에 대해 약 300개의 질문-답변 쌍이 학습 데이터로 활용된다. 복합 속성 제어(Composition) 과제에서는 RealToxicityPrompts와 News Category 데이터셋을 결합하여 동시에 정치적이면서 비독성인 텍스트 생성을 평가한다.
4.2 구현 세부사항
TRACE에서 사용하는 HMM은 기본 LM(GPT2-Large, Gemma-2B)으로부터 Zhang et al. (2023)과 Liu et al. (2023)의 방법론을 따라 증류된다. 증류 과정은 HMM을 동등한 확률적 회로(probabilistic circuit)로 컴파일하여 GPU에서 실행하며, LM 샘플에 대해 기대값 최대화(EM) 알고리즘의 미니배치 변형을 사용하여 학습한다. 구체적인 HMM 설정은 과제에 따라 다르다:
- 주요 독성 제거 및 복합 과제: 은닉 상태 크기 $h = 4096$
- 저자원 개인화 실험: 더 작은 HMM으로 $h = 256$ 사용
- 대형 HMM($h = 4096$)의 학습 샘플 크기: GPT2-Large HMM과 Gemma-2B HMM 모두 1,000만 샘플
- HMM 파라미터 초기화: 잠재 변수 증류(latent variable distillation) 기법 사용
- 학습: 미니배치 크기 4096, 50 에폭 학습, 1.0에서 0.0으로의 선형 감소 스케줄에 따른 스텝 크기 어닐링
- 학습 시간: 표준 10M 샘플, 4096 상태 HMM(GPT2-Large용)에 대해 텍스트 샘플링 약 18시간 + HMM 학습 자체 약 2시간(NVIDIA RTX A6000 GPU 1개 사용)
한 번 증류된 HMM 모델은 고정되어 각 속성에 대해 추가 학습 없이 재사용된다. 속성 분류기는 Section 4.3의 방법에 따라 학습되며, 비독성 분류기의 경우 GPT-2 Large를 RealToxicityPrompts의 학습 분할 프롬프트로 프롬프팅하여 생성한 연속문을 Perspective API로 점수화하고, 로짓 변환 파라미터 $b=10$, $c=3$을 적용한 후 log-MSE 손실로 로그-선형 가중치를 학습한다. 역할 분류기는 RoleBench 데이터셋의 캐릭터별 약 300개 질문-답변 쌍을 양성 예시로 사용한다. 비정치성 분류기는 News Category 데이터셋의 기사를 Laurer et al. (2023)의 제로샷 분류기로 정치적 관련성을 레이블링하고, 변환 파라미터 $b=1$, $c=-10$을 적용한다.
4.3 평가 메트릭
제어 가능한 텍스트 생성의 평가는 단순히 속성 만족도만 측정하는 것으로는 불충분하다. 극단적으로 독성을 낮추면서 "The"만 반복 출력하는 모델도 비독성이지만 전혀 유용하지 않기 때문이다. 따라서 속성 만족도와 함께 텍스트의 유창성(fluency)과 다양성(diversity)을 동시에 평가해야 하며, 이 세 가지 메트릭 사이의 균형이 방법의 실질적 가치를 결정한다. 논문은 이 점을 고려하여 다면적 평가 체계를 구축하였다.
메트릭은 과제에 따라 다양하다. 주요 독성 제거 과제에서는 Liu et al. (2021)의 설정을 따르며, 다음 메트릭을 사용한다:
- 독성(Toxicity): Perspective API를 통한 평균 최대 독성(avg. max. toxicity) 및 25개 샘플 중 독성 생성(>0.5) 확률. 낮을수록 좋다.
- 퍼플렉시티(Perplexity, PPL): GPT2-XL을 사용하여 계산한 유창성의 자동 측정치. 낮을수록 좋다.
- 다양성(Diversity): 고유 2-그램, 3-그램(Dist-2, Dist-3). 높을수록 좋다.
- GPT-4 평가: GPT4o-mini를 사용한 보충적 AI 평가로, 비독성, 유창성, 다양성을 1-5 척도로 평가.
- 조건부 엔트로피(Conditional Entropy): 프롬프트가 주어졌을 때 연속문의 엔트로피. 낮은 엔트로피는 반복적 또는 퇴화된 출력을 시사한다.
역할 연기에서는 학습된 캐릭터별 분류기 자체를 평가자로 사용하여 역할 품질을 분류기 확률로 측정하고, 주제 제어에서는 Laurer et al. (2023)의 제로샷 분류기를 사용하여 정치적 관련성을 측정한다.
4.4 베이스라인
공정하고 포괄적인 비교를 위해, TRACE는 제어 가능한 텍스트 생성 분야의 네 가지 주요 접근 유형을 대표하는 다양한 베이스라인과 비교된다. 각 베이스라인은 서로 다른 근사 전략과 트레이드오프를 가지며, TRACE와의 비교를 통해 각 접근법의 상대적 강점과 약점이 드러난다. 파인튜닝 방법으로 도메인 적응적 사전학습인 DAPT, 강화학습 방법으로 정책 경사 기반 PPO, 보상 토큰 조건화 기반 Quark, 직접 선호 최적화 DPO, 디코딩 방법으로 경사 기반 로짓 제어의 PPLM, 생성적 판별자 가이드인 GeDi, 미래 판별자인 FUDGE, 전문가 혼합 방식 DExperts, 경사 기반 샘플링의 MuCoLa가 포함된다. 베이스라인 결과는 주로 Liu et al. (2021), Lu et al. (2022), Kumar et al. (2022)의 선행 연구에서 가져오거나, DPO의 경우 동일한 설정으로 직접 구현하여 실행하였다. 공정한 비교를 위해 DExperts 설정(10k RealToxicityPrompts 테스트 프롬프트, top-$p=0.9$ 샘플링, 프롬프트당 25개 생성)을 따른다.
5. 주요 실험 결과: 독성 제거에서의 최첨단 성능
5.1 RealToxicityPrompts 독성 제거 결과
독성 제거는 제어 가능한 텍스트 생성 분야에서 가장 널리 사용되는 벤치마크이며, 풍부한 데이터와 표준화된 평가 프로토콜이 존재하여 방법들 간의 공정한 비교가 가능하다. RealToxicityPrompts 데이터셋은 자연 텍스트에서 수집된 프롬프트들로 구성되며, 각 프롬프트는 독성 유발 가능성이 다양한 수준으로 존재한다. 모델은 각 프롬프트에 대해 25개의 연속문을 생성하고, 이 중 가장 높은 독성 점수(avg. max. toxicity)와 독성 점수가 0.5를 초과하는 생성의 비율(probability)로 평가된다.
Table 1은 RealToxicityPrompts 벤치마크에서 TRACE와 다양한 베이스라인의 독성 제거 성능을 비교한다. GPT-2 Large 결과에서 TRACE는 평균 최대 독성 0.163, 독성 확률 0.016을 달성하여, 모든 베이스라인을 크게 능가한다. 특히 기존 최강 성능을 보이던 RL 기반 방법인 DPO(0.180/0.026)보다도 우수한 결과를 보인다.
| Model | Avg. Max Tox (↓) | Prob. (↓) | Dist-2 (↑) | Dist-3 (↑) | PPL (↓) | 접근 유형 |
|---|---|---|---|---|---|---|
| GPT2-Large | 0.385 | 0.254 | 0.87 | 0.86 | 25.57 | Baseline |
| DAPT | 0.428 | 0.360 | 0.84 | 0.84 | 31.21 | Finetuning |
| GeDi | 0.363 | 0.217 | 0.84 | 0.83 | 60.03 | Decoding (Trained Guide) |
| FUDGE | 0.302 | 0.371 | 0.78 | 0.82 | Decoding (Trained Guide) | |
| DExperts | 0.314 | 0.128 | 0.84 | 0.84 | 32.41 | Decoding (Trained Guide) |
| PPLM | 0.520 | 0.518 | 0.86 | 0.86 | 32.58 | Decoding (Logit Control) |
| MuCoLa | 0.308 | 0.088 | 0.82 | 0.83 | 29.92 | Decoding (Sampling) |
| PPO | 0.218 | 0.044 | 0.80 | 0.84 | RL | |
| Quark | 0.196 | 0.035 | 0.80 | 0.84 | RL | |
| DPO | 0.180 | 0.026 | 0.76 | 0.78 | RL | |
| TRACE | 0.163 | 0.016 | 0.85 | 0.85 | 29.83 | Decoding (HMM Reasoning) |
| Gemma-2B 결과 | ||||||
| Gemma-2B | 0.359 | 0.23 | 0.86 | 0.85 | 15.75 | Baseline |
| DPO | 0.222 | 0.06 | 0.74 | 0.77 | RL | |
| TRACE | 0.189 | 0.02 | 0.86 | 0.85 | 17.68 | Decoding (HMM Reasoning) |
논문에서 퍼플렉시티 값에 취소선이 표시된 경우(FUDGE의 12.97, PPO의 14.27, Quark의 12.47, DPO의 21.59)는 Holtzman et al. (2020)이 식별한 부자연스러운 반복 현상을 나타낸다. 이 경우 퍼플렉시티가 낮은 것이 유창성의 진정한 척도가 아니라, 모델이 소수의 패턴을 반복적으로 생성하여 인위적으로 낮은 퍼플렉시티를 달성한 것이다. 이러한 모드 붕괴 현상은 RL 기반 방법들의 근본적 한계로, 보상을 최대화하기 위해 모델이 안전하지만 단조로운 출력 패턴에 수렴하는 경향에서 비롯된다.
이 결과에서 가장 주목할 만한 점은 TRACE가 독성을 크게 줄이면서도 높은 다양성을 유지한다는 것이다. GPT-2의 기준 점수에서 Dist-2, Dist-3가 0.87, 0.86인데, TRACE는 0.85, 0.85로 미미한 감소만을 보인다. 반면 RL 방법들(PPO, Quark, DPO)은 독성을 낮추지만 다양성을 급격히 감소시킨다. 특히 DPO는 Dist-2가 0.76, Dist-3가 0.78로 크게 떨어지며, 이는 모드 붕괴(mode collapse)로 인한 반복적이거나 부자연스러운 텍스트 생성을 시사한다. 퍼플렉시티에서도 RL 방법들은 취소선으로 표시된 비정상적으로 낮은 값을 보이는데, 이는 Holtzman et al. (2020)이 지적한 바와 같이 부자연스러운 반복의 징후이다.
5.2 인수분해된 분류기의 효과성: 정확한 EAP 계산의 힘
독성과 같은 속성은 완전히 인수분해 가능하지 않다. 논문의 Appendix에서 신경 분류기와 인수분해된 분류기 사이의 성능 격차가 이를 뒷받침한다. 비독성 속성에 대한 교차 엔트로피 손실은 인수분해된 분류기가 0.386, 신경 분류기가 0.007로 상당한 격차가 존재한다. 그럼에도 불구하고 TRACE는 더 표현력 있는 신경 분류기를 사용하지만 근사적 EAP 추정에 의존하는 GeDi나 FUDGE 같은 방법들을 능가한다. 이는 핵심적 통찰을 강조한다: 단순한 인수분해된 분류기를 사용하더라도 HMM에 대한 정확한 EAP 계산은 추론 프레임워크가 덜 정밀할 때 더 복잡한 분류기를 사용하는 것과 맞먹거나 이를 능가할 수 있다.
| 속성 | 인수분해 분류기 CE 손실 | 신경 분류기 CE 손실 |
|---|---|---|
| 독성(Toxicity) | 0.386 | 0.007 |
| 정치(Politics) | 0.0064 | 0.0003 |
이 결과는 독성과 정치 속성 모두 예상대로 복잡한 의미적 속성에서 비인수분해적 특성을 다양한 정도로 나타낸다는 것을 시사한다. 독성의 경우 인수분해 분류기와 신경 분류기 사이의 격차가 0.386 대 0.007로 매우 크며, 이는 독성이 개별 토큰보다 토큰 간의 상호작용과 문맥에 크게 의존함을 보여준다. 반면 정치 속성은 0.0064 대 0.0003으로 격차가 상대적으로 작아, 정치적 콘텐츠가 특정 키워드(예: "정책", "선거", "대통령" 등)의 존재와 더 강하게 상관되어 인수분해된 분류기로도 상당히 잘 포착될 수 있음을 시사한다. 그럼에도 TRACE는 두 속성 모두에서 강력한 경험적 성능을 달성하며, 이는 단순한 인수분해 분류기라도 HMM에 대한 정확한 EAP 계산과 결합될 때 효과적이라는 점을 입증한다.
5.3 더 큰 언어 모델로의 확장: Gemma-2B 결과
TRACE는 Gemma-2B와 같은 더 큰 언어 모델로도 효과적으로 확장된다. Table 1의 Gemma-2B 결과에서 TRACE는 평균 최대 독성 0.189, 독성 확률 0.02를 달성하여 DPO(0.222/0.06)를 일관되게 능가한다. 다양성 측면에서도 TRACE(0.86/0.85)는 기본 Gemma-2B와 동일한 수준을 유지하는 반면, DPO(0.74/0.77)는 크게 저하된다. 이는 TRACE가 모델 규모에 걸쳐 광범위한 적용 가능성과 강건성을 갖추고 있음을 입증한다. 특히 Gemma-2B는 GPT2-Large보다 약 2.6배 큰 모델이지만, TRACE의 독성 제거 효과가 일관되게 유지된다는 점은 프레임워크의 확장 가능성에 대한 긍정적 증거이다. 또한 Gemma-2B 실험에서도 동일한 1.2배의 추론 비율이 유지되어, 모델 규모가 커져도 TRACE의 계산 오버헤드가 증가하지 않음을 확인할 수 있다. 이는 EAP 계산 비용이 기본 LM의 순전파 비용에 비해 항상 무시 가능한 수준이기 때문이다.
6. 추가 분석 및 Ablation Study: 확률 변환의 상호 보완적 역할
6.1 학습 시와 디코딩 시 확률 변환의 Ablation
확률 변환은 TRACE의 핵심적 기법 구성요소 중 하나이며, 이 변환이 학습과 디코딩의 서로 다른 단계에서 적용될 때 상호 보완적인 이점을 제공한다는 것이 체계적인 ablation 연구를 통해 입증된다. 이 ablation은 TRACE의 각 구성요소가 최종 성능에 어떻게 기여하는지를 분리하여 이해하는 데 핵심적이다. Table 3은 세 가지 TRACE 변형의 성능을 비교한다: 변환 없음(No Transformation), 학습 시 변환만(Training TF), 학습 시와 디코딩 시 모두 변환(Train + Dec TF).
| TRACE 변형 | Avg. Max Tox (↓) | Prob. (↓) | Dist-2 (↑) | Dist-3 (↑) | PPL (↓) |
|---|---|---|---|---|---|
| No Transformation | 0.353 | 0.196 | 0.87 | 0.86 | 25.44 |
| Training TF | 0.187 | 0.026 | 0.87 | 0.85 | 27.51 |
| Train + Dec TF | 0.163 | 0.016 | 0.85 | 0.85 | 29.83 |
변환 없이 TRACE를 적용하면 평균 최대 독성이 0.353으로 기본 GPT-2(0.385)에서 약간만 개선된다. 학습 시 변환만 적용하면("Training TF") 독성이 0.187로 크게 감소하며, 다양성은 거의 유지된다. 두 단계 모두에서 변환을 적용하면("Train + Dec TF") 독성이 0.163으로 추가 감소하지만, 퍼플렉시티가 25.44에서 29.83으로 소폭 증가한다. 이 결과는 확률 변환이 각 단계에서 고유한 역할을 수행함을 보여주며, 두 변환의 조합이 가장 강력한 독성 제어를 제공한다.
논문의 Figure 2는 두 개의 서브 플롯으로 구성되어, 학습 시와 디코딩 시 확률 변환의 상호 보완적 메커니즘을 시각적으로 보여준다. 상단(Figure 1)은 학습 시 변환의 효과를, 하단(Figure 2)은 디코딩 시 변환의 효과를 나타낸다.
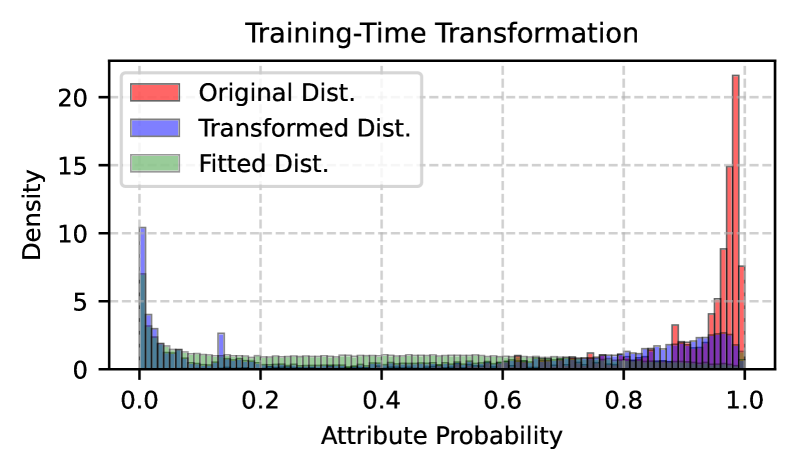
Figure 1: 학습 시 확률 변환의 효과. 원래 분포(Original Dist., 빨간색)의 편향된 형태가 변환(Transformed Dist., 파란색)을 통해 쌍봉 분포로 재형성되어, 바람직하지 않은 속성의 오라클 확률을 0 근처로 집중시킨다. 학습된 분류기(Fitted Dist., 녹색)는 이 변환된 분포를 성공적으로 포착한다.
Figure 1은 학습 시 확률 변환의 메커니즘을 시각적으로 설명한다. 학습 시 변환은 편향된 "원래 분포"를 쌍봉 "변환된 분포"로 재형성하여, 독성 콘텐츠에 대한 점수를 0 근처로 밀어낸다. log-MSE 목적함수가 이 낮은 확률 영역에 초점을 맞추므로, 분류기는 독성 토큰에 대해 더 강한 음의 가중치를 학습하게 된다. 결과적으로 "학습된 분포"는 0 근처의 새로운 피크를 성공적으로 포착한다. 이 변환이 없으면 오라클 점수의 분포가 1에 가까운 값에 편중되어 있어, 분류기가 낮은 점수를 가진 독성 텍스트를 효과적으로 식별하기 어렵다.

Figure 2: 디코딩 시 확률 변환의 효과. 확산된 단봉(unimodal) EAP 분포(Before Trans., 파란색)가 날카로운 쌍봉(bimodal) 분포(After Trans., 빨간색)로 변환되어, 속성 준수와 비준수 연속문 사이의 더 명확한 구분을 생성한다.
Figure 2는 디코딩 시 확률 변환의 효과를 보여준다. 디코딩 시에는 동일한 변환이 계산된 EAP에 직접 적용된다. 변환 전의 확산된 단봉 EAP 분포("Before Trans.")가 날카로운 쌍봉 분포("After Trans.")로 변환되어, 속성 준수 연속문과 비준수 연속문 사이의 더 명확한 구분을 생성한다. 이 쌍봉 구조는 TRACE가 높은 EAP를 가진 토큰에 더 큰 가중치를 부여하고 낮은 EAP를 가진 토큰을 더 강하게 억제할 수 있게 하여, 더 엄격한 속성 제어를 가능하게 한다. 학습 시 변환이 분류기의 학습을 돕고, 디코딩 시 변환이 제어를 강제하는 이 시너지가 두 변환의 결합된 강력한 성능을 설명한다.
두 변환의 시너지는 다음과 같이 요약할 수 있다. 학습 시 변환은 분류기가 "어떤 토큰이 독성에 기여하는가"를 더 정확하게 학습할 수 있도록 목표 분포를 재형성한다. 변환 없이는 대부분의 텍스트가 높은 비독성 점수(0.8-1.0)를 가지므로, 분류기가 독성 텍스트의 특성을 학습하기 어렵다. 변환을 적용하면 이 분포가 쌍봉화되어, 독성과 비독성 텍스트 사이의 구별이 더 명확해진다. log-MSE 손실은 이 변환된 분포의 낮은 확률 영역에서 오차를 증폭하므로, 분류기는 독성 토큰에 대해 더 강한 음의 가중치를 학습하게 된다. 디코딩 시 변환은 이렇게 학습된 분류기로 계산한 EAP를 추가로 날카롭게 만들어, 높은 EAP를 가진 토큰(속성 준수)과 낮은 EAP를 가진 토큰(속성 비준수) 사이의 구분을 극대화한다.
6.2 유창성-독성 제거 트레이드오프 조정

Figure 3: 유창성-독성 제거 트레이드오프 조정. 디코딩 시 변환 승수(multiplier)가 제어 노브(control knob)로 작용한다. 승수가 증가하면 독성 제거가 개선되지만 유창성은 감소한다. 각 점의 레이블은 승수 값(1.0~1.8)을 나타낸다.
디코딩 시 변환의 추가적 이점으로, 스케일 파라미터 $b$가 제어를 조정하기 위한 직관적인 노브(knob)를 제공한다는 것이 있다. Figure 3은 이 트레이드오프를 명확히 보여준다. 가로축은 최대 독성, 세로축은 평균 유창성(퍼플렉시티)을 나타내며, 각 점은 서로 다른 디코딩 시 변환 승수에 해당한다. 승수 1.0(변환이 가장 약한 경우)에서는 독성이 상대적으로 높지만 유창성이 좋고, 승수가 1.8로 증가하면 독성이 크게 감소하지만 유창성이 다소 떨어진다. 이 관계는 근사적으로 선형적이며, 사용자가 특정 애플리케이션의 요구사항에 따라 독성과 유창성 사이의 균형점을 사후적(post-hoc)으로 자유롭게 선택할 수 있게 한다. 이는 RL 기반 방법들이 한 번 학습하면 트레이드오프를 조정하기 위해 재학습이 필요한 것과 대조적인 장점이다.
6.3 조건부 엔트로피와 GPT-4 평가
논문은 독성 제거 결과를 더 깊이 뒷받침하기 위해 두 가지 보충적 평가를 제공한다. 첫째, 조건부 엔트로피는 각 모델 하에서 프롬프트가 주어졌을 때 연속문의 엔트로피를 보고하며, 낮은 엔트로피는 어휘적, 구조적 다양성이 적음을 나타내고 종종 반복적이거나 퇴화된 출력의 증상이다.
| Method | Entropy (↑) |
|---|---|
| GPT2-Large | 52.06 |
| DPO | 39.52 |
| TRACE | 52.54 |
TRACE는 기본 LM과 비슷한 엔트로피(52.54 대 52.06)를 달성하며, DPO(39.52)보다 훨씬 높은 엔트로피를 보인다. 이는 RL 방법이 생성 다양성을 줄이는 경향이 있다는 것을 정량적으로 확인하며, TRACE가 제어를 강화하면서도 출력의 다양성을 보존함을 입증한다. DPO의 엔트로피가 기본 LM 대비 약 24% 감소한 것은 모드 붕괴의 증거로 해석할 수 있다.
| Method | Nontoxicity (↑) | Fluency (↑) | Diversity (↑) |
|---|---|---|---|
| Gemma-2B | 4.39 | 3.76 | 2.93 |
| DPO | 4.65 | 3.94 | 2.86 |
| TRACE | 4.69 | 3.72 | 2.94 |
둘째, GPT-4를 활용한 LM-as-a-Judge 평가에서 TRACE는 비독성 점수 4.69로 DPO(4.65)와 기본 Gemma-2B(4.39)를 모두 능가하며, 다양성 점수 2.94로 DPO(2.86)보다 우수하다. 유창성에서만 TRACE(3.72)가 DPO(3.94)에 약간 뒤처지지만, 이는 퍼플렉시티 메트릭에서 관찰된 트레이드오프와 일치한다. 전반적으로 이 GPT-4 평가는 TRACE가 출력 품질을 손상시키지 않으면서 강력한 제어 가능성을 달성한다는 것을 확인한다.
6.4 HMM 품질이 성능에 미치는 영향

Figure 4: HMM 품질이 독성 제거에 미치는 영향. HMM이 더 많은 단계로 학습될수록 데이터에 대한 적합도가 향상되고(Log-Likelihood 증가, 파란색), 이에 따라 생성 텍스트의 평균 최대 독성이 감소한다(빨간색). 이는 고품질 HMM이 더 효과적인 제어로 이어진다는 것을 보여준다.
제어의 효과성은 HMM 자체의 품질에 민감하며, 이는 TRACE의 핵심 근사가 $p_{\text{hmm}} \approx p_{\text{lm}}$이라는 가정에 기반하기 때문에 직관적으로 이해할 수 있다. HMM이 기본 LM을 더 정확하게 근사할수록, HMM 하에서 계산된 EAP가 실제 LM 하에서의 EAP에 더 가까워지고, 따라서 제어의 정확성이 향상된다. Figure 4는 검증 세트에서 HMM의 로그 우도(log-likelihood)를 학습 과정의 서로 다른 시점에서 생성한 텍스트의 평균 최대 독성과 함께 그래프로 보여준다. 결과는 HMM이 언어의 더 나은 확률 모델이 될수록(높은 로그 우도), 비독성 출력으로 생성을 유도하는 능력이 향상됨(낮은 독성)을 명확히 보여준다. 학습 초기 단계에서는 독성이 상대적으로 높지만, 학습이 진행됨에 따라 HMM의 로그 우도가 증가하면서 독성이 단조 감소하는 경향을 보인다. 이 결과는 HMM 증류 기법의 추가적인 발전이 TRACE의 성능을 더욱 향상시킬 가능성이 높다는 것을 시사하며, 향후 연구의 유망한 방향을 제시한다.
7. 역할 연기 및 복합 속성 제어: TRACE의 적응성과 확장성
독성 제거 이외에 TRACE의 적응성과 확장성을 검증하기 위해, 논문은 저자원 역할 연기와 복합 속성 제어라는 두 가지 추가적 과제를 제시한다. 이 과제들은 각각 "적은 데이터로 빠르게 적응할 수 있는가"와 "여러 속성을 동시에 제어할 수 있는가"라는 질문에 답하며, 이는 실제 배포 환경에서 제어 가능한 생성 시스템이 직면하는 핵심적 요구사항이다.
7.1 76개 캐릭터 역할 연기: 저자원 적응의 경량성
TRACE의 핵심 이점 중 하나는 빠르고 저자원적인 적응(rapid, low-resource adaptation)이다. 새로운 속성은 경량 로그-선형 분류기만 학습하면 통합되므로, TRACE를 활용하여 GPT2-Large와 Gemma-2B를 RoleBench 데이터셋의 76개 서로 다른 캐릭터에 개인화하였다. 각 캐릭터의 분류기는 해당 RoleBench 학습 분할의 약 300개 질문-답변 쌍으로 학습되었으며, 이 과정은 각 캐릭터에 대해 약 3초만 소요된다. 이는 기존 방법들이 각 새로운 페르소나에 대해 수 시간의 파인튜닝이나 대규모 인컨텍스트 학습을 필요로 하는 것과 비교할 때 극적인 효율성 향상이다.
역할 연기 실험에서 개인화에 사용된 HMM은 독성 제거 실험과 달리 더 작은 은닉 상태 크기($h=256$)를 사용하였다. 이는 TRACE가 더 작고 계산적으로 효율적인 HMM으로도 효과적인 제어를 달성할 수 있음을 보여주며, 리소스가 제한된 환경에서의 적용 가능성을 시사한다. 역할 분류기는 각 캐릭터의 텍스트를 양성 예시로 사용하여 log-MSE 손실로 학습되며, 어떤 캐릭터가 사용하는 고유한 어휘, 표현 패턴, 주제 선호도가 토큰 수준의 가중치로 인코딩된다.
논문은 "How do you define freedom?"이라는 질문에 대해 세 캐릭터(Abraham Lincoln, Thor, Twilight Sparkle)의 응답을 세 가지 설정에서 비교한다. 기본 모델(Direct Prompt)은 "우리가 매우 자주 다루는 주제이지만 쉬운 답이 없는 매우 주관적인 질문"이라는 일반적이고 캐릭터 특성이 없는 응답을 생성한다. 이 응답은 어떤 캐릭터의 관점이나 어조도 반영하지 않으며, 누구라도 할 수 있는 범용적인 답변이다.
역할 특화 지시문과 10개의 QA 예시를 사용한 프롬프팅 베이스라인(Prompted with Role-Specific Instructions)은 캐릭터 관련 내용을 포함하지만 여전히 다소 일반적인 톤을 유지한다. Abraham Lincoln의 경우 "자유는 기본적 인권이며 개인이 충만하고 의미 있는 삶을 살기 위해 필요하다"는 다소 교과서적인 답변을, Thor의 경우 "자유는 언론의 자유나 이동의 자유 이상이며 자신의 운명을 통제하는 느낌"이라는 범용적인 답변을, Twilight Sparkle의 경우 "자유는 강력한 개념이며 에퀘스트리아에서의 모험을 통해 많이 생각했다"는 캐릭터 이름만 언급하는 피상적 답변을 생성한다.
반면 TRACE가 유도한 응답은 더 뚜렷하고 캐릭터를 반영하는 콘텐츠와 톤을 보여준다. Abraham Lincoln에 대해 TRACE는 "결정적 자유, 주관적 자유, 언론의 자유?"라며 자유의 다양한 정의를 나열하는, Lincoln의 수사학적 스타일을 반영하는 응답을 생성한다. Thor에 대해 TRACE는 "Loki, Odin의 아들은 신의 눈으로 본 자유가 무엇인지 떠올리게 한다. 장난의 위대한 북유럽 신은..."이라며 캐릭터 특화적인 어휘(Loki, Odin, 북유럽 신)와 신화적 관점을 반영한다. Twilight Sparkle에 대해서는 "우정, 연결, 사랑... 자유는 끝이 없고 질문하는 사람에 따라 달라진다"라며 우정이라는 캐릭터의 핵심 가치를 자연스럽게 녹여낸다. 이러한 정성적 비교는 인수분해된 분류기가 각 캐릭터의 독특한 어휘적 특성과 주제적 선호도를 토큰 수준의 가중치로 효과적으로 포착할 수 있음을 보여준다.

Figure 5: TRACE와 프롬프트 엔지니어링의 역할 품질 비교. 각 점은 76개 캐릭터 중 하나를 나타내며, 가로축은 프롬프팅 방법의 역할 품질, 세로축은 TRACE의 역할 품질이다. 대각선(y=x) 위에 위치한 점은 TRACE가 우수한 경우를 나타내며, 대부분의 점이 대각선 위에 위치하여 TRACE가 프롬프팅을 일관되게 능가함을 보여준다.
프롬프팅 베이스라인은 두 가지 전략으로 구성된다. 첫째, Gemma-2B의 정성적 평가(Table 3)에는 역할 지시문과 10개의 QA 예시를 포함하는 소수샷 프롬프팅이 사용되었다. 이 프롬프트는 "You are an advanced role-playing assistant trained to embody characters with accuracy and authenticity"로 시작하여 캐릭터명을 명시하고, 10개의 예시 상호작용을 제공한 후 질문을 이어붙이는 구조이다. 둘째, GPT2-Large의 정량적 평가(Figure 5)에는 예시 없이 역할 특화 지시문만 사용하는 더 가벼운 프롬프팅이 사용되었다. 이는 지시 따르기(instruction-following) 능력과의 직접적인 비교를 위한 것이며, 소수샷 프롬프팅이 더 높은 디코딩 비용을 유발하므로 공정한 비교를 위한 선택이다.
정량적으로 Figure 5는 GPT2-Large에서 TRACE가 76개 캐릭터 대부분에 대해 표준 프롬프팅 베이스라인보다 우수한 역할 품질을 달성함을 보여준다. 그래프에서 각 점은 하나의 캐릭터를 나타내며, 대각선(y=x) 위에 위치한 점은 TRACE가 프롬프팅보다 우수한 경우이다. 대부분의 점이 대각선 위에 위치하여, TRACE가 프롬프팅을 일관되게 능가한다는 것을 시각적으로 확인할 수 있다. 이 프롬프팅 베이스라인은 역할 특화적이지만 예시가 없는 지시문을 사용하여, 최소한의 입력 오버헤드로 지시 따르기(instruction-following)와의 직접적인 비교를 보장한다. 소수샷 프롬프팅은 더 높은 디코딩 비용을 유발하기 때문에(추론 비율 약 3.0배), TRACE의 1.2배 추론 비율과 비교할 때 실용적 이점이 더욱 두드러진다.
7.2 학습 및 추론 시간 분석
TRACE는 빠른 적응과 효율적인 추론을 위해 설계되었으며, 기본 LM으로부터의 일회성 HMM 증류만 필요하고 이는 특정 제어 속성과 무관하다. 학습 시간과 추론 시간 두 측면에서 TRACE는 기존 방법들 대비 극적인 효율성 이점을 보인다.
| Method | 학습 시간 | 추론 비율 |
|---|---|---|
| PPLM | - | 40.0x |
| MuCoLa | - | 15-20x |
| Mix and Match | 2시간 | 7.5x |
| Prompting | - | ~3.0x |
| GeDi / DExperts | 5시간 / 3분~16시간 | 2.0-3.0x |
| DAPT | 16시간 | 1.0x (Baseline) |
| TRACE | 10초 | 1.2x |
학습 시간 측면에서, HMM이 한 번 학습되면 새로운 속성에 적응하는 데는 경량 분류기를 학습하기만 하면 된다. 이 과정은 최대 10초가 소요되며, DAPT, DExperts, GeDi, Mix and Match 등의 베이스라인이 다양한 GPU에서 수 분에서 16시간의 학습을 필요로 하는 것과 극명한 대조를 이룬다. 이 빠른 적응은 TRACE를 동적이거나 저자원 시나리오, 그리고 실시간 맞춤화가 필요한 서비스 환경에 매우 적합하게 만든다. 76개 캐릭터 각각에 약 3초면 적응 가능하다는 것은, 새로운 속성이 빈번하게 추가되어야 하는 실제 서비스 환경에서 큰 실용적 가치를 지닌다.
추론 시간 측면에서, TRACE는 생성 중 효율성을 유지한다. 인컨텍스트 학습, 판별자, 반복적 업데이트에 의존하는 대안적 접근법들은 7.5배에서 40배에 달하는 상당한 디코딩 비용을 유발한다. PPLM은 40배, MuCoLa는 15-20배, Mix and Match는 7.5배의 추론 비율을 보이는데, TRACE는 단 1.2배의 추론 비율만을 보인다. 이 효율성은 HMM의 EAP 계산이 사전 계산된 후방 패스와 토큰당 효율적인 전방 업데이트를 사용하는 설계에서 비롯된다. 결과적으로 총 추론 시간은 기본 언어 모델의 약 1.2배에 불과하며, 이 과정은 기본 모델의 계산이 지배적이기 때문이다.
7.3 복합 속성 제어: 정치적이면서 비독성인 텍스트 생성
TRACE의 핵심적 이점 중 하나는 재학습 없이 여러 속성을 합성(compose)할 수 있다는 것이다. 두 속성의 결합 $(s_1, s_2)$에 대한 조건화는 텍스트가 주어졌을 때 속성 독립 가정 $p(s_1 \text{ and } s_2 | x) = p(s_1|x) \cdot p(s_2|x)$에 기반하여 디코딩 중 두 확률을 곱함으로써 달성된다. TRACE의 인수분해된 분류기에 대해, 이는 개별 분류기의 토큰 가중치를 곱하여 새로운 복합 분류기를 생성하는 것으로 단순화된다: $w' = w^1 \cdot w^2$. 이 단순한 연산은 추가 학습 없이 수행되며, 다른 방법들이 복합 속성의 희소성으로 인해 결합 학습에 어려움을 겪는 것과 대조적이다.
논문은 동시에 정치적이면서 비독성인 텍스트를 생성하는 과제로 이를 입증한다. 이 조합은 자연 텍스트에서 매우 희소하여 다른 방법의 결합 학습을 어렵게 만들지만, TRACE는 개별적으로 학습된 분류기만 필요하므로 효과적으로 동작한다.
| Models | Max Tox (↓) | Any Tox >0.5 (↓) | Mean Pol (↑) | PPL (↓) | Dist-2 (↑) | Dist-3 (↑) |
|---|---|---|---|---|---|---|
| GPT2-L (Base) | 0.386 | 0.257 | 0.169 | 25.74 | 0.87 | 0.86 |
| TRACE (Detox only) | 0.186 | 0.026 | 0.168 | 27.33 | 0.87 | 0.85 |
| TRACE (Pol only) | 0.379 | 0.244 | 0.333 | 29.32 | 0.87 | 0.86 |
| TRACE (Detox + Pol) | 0.190 | 0.027 | 0.344 | 29.71 | 0.87 | 0.86 |
Table 7의 결과는 효과적인 합성을 입증한다. 단일 속성을 제어하면 주로 해당 차원에만 영향을 미친다. TRACE (Detox only)는 최대 독성을 0.386에서 0.186으로 줄이면서 평균 정치 점수는 거의 변하지 않는다(0.169 대 0.168). 반대로 TRACE (Pol only)는 평균 정치 점수를 0.169에서 0.333으로 높이면서 독성은 거의 변하지 않는다. 가장 주목할 만한 것은 복합적 TRACE (Detox + Pol) 접근법이 두 목표를 동시에 성공적으로 달성한다는 것이다. 독성 수준(0.190)과 정치 점수(0.344)는 각각의 단일 속성 제어 설정과 비슷한 수준을 달성하며, 다양성도 기본 GPT-2와 동일한 수준(0.87/0.86)을 유지한다. 이는 두 속성의 제어가 서로 간섭하지 않고 독립적으로 작동함을 보여주며, TRACE의 합성 능력의 효과성을 명확히 입증한다.
이 결과의 실용적 의의는 매우 크다. 실제 애플리케이션에서는 안전성과 특정 속성을 동시에 충족해야 하는 경우가 많지만, 이러한 복합 속성의 조합은 학습 데이터에서 매우 드물어 결합 학습이 어렵다. TRACE는 각 속성의 분류기를 독립적으로 학습하고 디코딩 시 단순히 곱하기만 하면 되므로, 속성의 수에 선형적으로만 비용이 증가하고 새로운 조합에 대한 추가 학습이 전혀 필요 없다. 예를 들어, 비독성 분류기와 정치적 분류기가 이미 학습되어 있다면, 이 두 분류기를 합성하는 것은 어휘의 각 토큰에 대해 두 가중치를 곱하는 $O(V)$ 연산만 필요하며, 이는 수 밀리초 이내에 완료된다.
논문은 복합 속성 실험에서 디코딩 시 변환("+ Dec. TF")을 정치적 EAP에만 선택적으로 적용하는 설정도 탐구하였다. 이는 각 속성에 대한 제어 강도를 독립적으로 조절할 수 있음을 보여주며, 실제 애플리케이션에서 속성별로 다른 수준의 엄격성을 적용해야 하는 시나리오에 유용하다. 예를 들어 안전성에는 엄격한 제어를, 주제 관련성에는 부드러운 유도를 적용하는 것이 가능하다. 이러한 유연한 제어는 TRACE의 모듈식 설계에서 자연스럽게 도출되는 장점이다.
8. 한계점 및 향후 연구 방향: 표현력 확장과 HMM 개선
TRACE는 제어 가능한 텍스트 생성 분야에서 인상적인 성과를 달성하였지만, 몇 가지 주목할 만한 한계점과 이를 극복하기 위한 향후 연구 방향이 존재한다. 논문은 이러한 한계점들을 솔직하게 인정하면서도, 각각에 대한 잠재적 해결책을 제시하여 후속 연구의 로드맵을 제공한다.
8.1 인수분해된 분류기의 표현력 한계
TRACE의 현재 설계에서 가장 명확한 한계는 인수분해된 분류기의 제한된 표현력이다. 독성이나 정치적 콘텐츠와 같은 의미적 속성은 본질적으로 토큰 간의 상호작용과 문맥에 의존하므로 완전히 인수분해 가능하지 않다. 이는 Appendix의 Table 6에서 확인할 수 있듯이, 독성 속성에 대한 인수분해 분류기의 교차 엔트로피 손실(0.386)이 신경 분류기(0.007)보다 훨씬 크다. 현재의 단순한 인수분해 분류기가 정확한 EAP 계산과 결합되어 효과적이긴 하지만, 더 복잡한 속성(예: 장거리 일관성, 미묘한 스타일 뉘앙스)에는 한계가 있을 수 있다.
인수분해된 분류기는 각 토큰을 독립적으로 평가하므로, "he is a killer"와 "he is a killer app developer"에서 "killer"라는 토큰에 동일한 가중치를 부여한다. 전자는 폭력적 맥락이고 후자는 긍정적 맥락이지만, 인수분해된 분류기는 이 차이를 문맥에서 포착할 수 없다. 그럼에도 TRACE가 효과적인 이유는 HMM이 미래 토큰의 분포를 예측하면서 간접적으로 문맥 정보를 반영하기 때문이다. "killer" 뒤에 "app"이 올 확률이 높은 문맥에서는 전체적인 EAP가 높게 유지된다.
논문은 이 한계를 극복하기 위한 향후 방향으로 다루기 쉬운 확률적 회로(tractable probabilistic circuits)와 같은 더 표현력 있는 모델로 TRACE를 확장하는 것을 제안한다. Khosravi et al. (2019)과 Choi et al. (2020)이 개발한 이러한 모델들은 효율적인 EAP 계산과 호환되면서도 더 복잡한 속성 간의 상호작용을 포착할 수 있다. 특히 장거리 일관성과 같은 복잡한 속성에 대해 더 강력한 제어를 가능하게 할 수 있다.
8.2 HMM 증류 품질의 중요성
Figure 4에서 확인한 바와 같이, TRACE의 성능은 HMM의 품질에 직접적으로 의존한다. 더 높은 품질의 HMM이 더 나은 결과를 산출하므로, 개선된 증류 기법이 유망한 연구 방향이다. 현재의 HMM 증류는 기본 LM에서 샘플링한 텍스트에 대해 EM 알고리즘의 미니배치 변형을 사용하며, 표준 설정에서 텍스트 샘플링에 약 18시간, HMM 학습에 약 2시간이 소요된다. 이 일회성 비용은 각 속성에 대한 빠른 적응으로 상각되지만, 증류 과정 자체의 효율성과 품질을 개선하면 TRACE의 전반적 성능이 향상될 수 있다.
최근 Zhang et al. (2025)은 Monarch 행렬을 통해 확률적 회로를 확장하는 방법을 제안하였으며, 이는 더 큰 은닉 상태 크기를 효율적으로 처리할 수 있게 한다. 이러한 발전은 TRACE에서 사용하는 HMM의 표현 능력을 향상시킬 수 있는 유망한 경로를 제공한다. 또한 현재 실험에서 독성 제거와 복합 과제에는 $h=4096$의 HMM을, 개인화에는 $h=256$의 더 작은 HMM을 사용하였는데, 향후 연구에서는 다양한 은닉 상태 크기와 학습 전략의 체계적 비교가 유용할 것이다.
8.3 속성 독립 가정의 한계
복합 속성 제어에서 TRACE는 텍스트가 주어졌을 때 속성 간의 독립 가정 $p(s_1 \text{ and } s_2 | x) = p(s_1|x) \cdot p(s_2|x)$에 기반한다. 이 가정은 정치적 콘텐츠와 독성처럼 상대적으로 독립적인 속성에서는 잘 작동하지만, 속성 간에 강한 상관관계가 존재하는 경우(예: 유머와 비격식성, 학술적 톤과 복잡한 어휘)에는 최적이 아닐 수 있다. 속성 간의 상호작용을 명시적으로 모델링하는 확장은 더 정교한 복합 제어를 가능하게 할 것이다. 다만 현재의 독립 가정하에서도 실험적으로 효과적인 합성이 관찰되었다는 점은 주목할 만하다.
8.4 적용 범위의 확장 가능성
현재 TRACE는 독성 제거, 역할 연기, 주제 제어라는 세 가지 과제에서 평가되었다. 그러나 이 프레임워크의 일반적 구조는 더 넓은 범위의 제어 과제에 적용될 수 있는 잠재력을 가지고 있다. 예를 들어, 감정 제어, 형식성(formality) 조절, 특정 도메인 어휘의 사용 유도, 윤리적 가이드라인 준수 등이 잠재적 적용 분야이다. 특히 속성이 희소하거나 결합되어야 하는 시나리오에서 TRACE의 경량 적응과 합성 능력은 실질적인 이점을 제공할 수 있다.
다만 현재 실험은 GPT2-Large(774M 파라미터)와 Gemma-2B라는 상대적으로 작은 모델에서 수행되었으며, 더 큰 규모의 최신 LLM(예: 7B, 13B, 70B 이상)에서의 확장성은 추가 검증이 필요하다. HMM 증류의 비용과 복잡성이 기본 LM의 규모에 따라 어떻게 변하는지, 그리고 더 강력한 LM에서도 HMM의 근사가 충분히 정확한지에 대한 연구가 향후 과제로 남아 있다. 특히 대형 LM의 언어 모델링 능력이 향상될수록 HMM과의 분포 격차가 커질 수 있으며, 이는 EAP의 근사 품질에 영향을 미칠 수 있다. 다만 GPT2-Large에서 Gemma-2B로 확장할 때 성능이 일관되게 유지된 점은 긍정적 신호이다. 또한 현재 HMM 증류에 필요한 일회성 비용(텍스트 샘플링 18시간 + HMM 학습 2시간)이 더 큰 모델에서는 샘플링 비용이 증가할 수 있으며, HMM의 은닉 상태 크기를 더 크게 설정해야 할 수도 있어 메모리 및 계산 요구사항이 함께 증가할 가능성이 있다.
9. 결론: 다루기 쉬운 확률적 추론의 새로운 패러다임
본 논문은 TRACE(Tractable Probabilistic Reasoning for Adaptable Controllable Generation)라는 다루기 쉬운 확률적 추론을 사용하는 제어 가능한 텍스트 생성을 위한 경량 프레임워크를 제안하였다. TRACE의 핵심 강점은 효율성, 적응성, 그리고 강력한 성능이며, 이 모든 것이 기본 LM을 수정하거나 파인튜닝하지 않고도 달성된다. TRACE는 기본 LM으로부터 은닉 마르코프 모델(HMM)을 증류하고, 이를 단순하고 효율적으로 학습되는 분류기와 결합하여 기대 속성 확률(EAP)을 다루기 쉽게 계산하며, 이 EAP가 원하는 속성 방향으로 생성을 유도한다.
TRACE의 실용적 가치는 세 가지 차원에서 입증되었다. 첫째, 독성 제거에서 약 20%의 디코딩 오버헤드만으로 GPT2-Large 기준 평균 최대 독성 0.163을 달성하여 기존 최강인 DPO(0.180)를 능가하면서도, 다양성(Dist-2: 0.85, Dist-3: 0.85)을 기본 모델 수준으로 유지한다. 이는 RL 기반 방법들이 독성을 낮추면서 다양성을 크게 희생하는(DPO Dist-2: 0.76) 것과 대조적이다. 둘째, 저자원 시나리오에서도 뛰어난 성능을 보이며, 수 초 만에 76개의 개별 캐릭터에 생성을 개인화할 수 있고, 각 캐릭터에 약 300개의 학습 예시만으로 프롬프팅 접근법을 능가하는 역할 품질을 달성한다. 셋째, 정치적이면서 비독성인 텍스트처럼 여러 속성을 재학습 없이 성공적으로 합성할 수 있다. TRACE의 학문적 기여는 제어 가능한 텍스트 생성의 문제를 확률적 추론의 관점에서 재정립하고, 다루기 쉬운 확률 모델의 적용 범위를 논리적 제약에서 의미적 속성 제어로 확장한 것이다.
TRACE의 방법론적 핵심을 요약하면, "LM의 표현력으로 유창한 텍스트를 생성하되, HMM의 다루기 쉬움으로 미래를 정확히 내다보고, 분류기의 경량성으로 새로운 속성에 빠르게 적응한다"는 세 가지 구성요소의 상보적 역할로 설명할 수 있다. 이 설계 철학은 각 구성요소가 자신이 가장 잘하는 역할을 수행하도록 분업을 구성한 것으로, 단일 모델에 모든 역할을 맡기는 기존 접근법들의 한계를 우아하게 극복한다.
TRACE의 이미 강력한 경험적 성능에도 불구하고, HMM과 속성 분류기의 표현력을 향상시킴으로써 역량을 더욱 강화할 수 있다. 논문의 결과는 더 높은 품질의 HMM이 더 나은 결과를 산출함을 보여주어, 개선된 증류 기법이 유망한 방향임을 시사한다. 또한 단순한 인수분해 분류기가 인수분해 불가능한 속성에 대해서도 효과적이지만, 효율적인 EAP 계산과 호환되는 더 표현력 있는 모델인 다루기 쉬운 확률적 회로로 TRACE를 확장하면 장거리 일관성과 같은 복잡한 속성에 대해 더 강력한 제어를 가능하게 할 수 있다. 제어 가능한 생성이라는 연구 분야에서 TRACE는 "모델을 바꾸지 않고도 출력을 제어할 수 있다"는 디코딩 기반 접근법의 가능성을 새로운 수준으로 끌어올렸으며, 확률적 추론과 언어 생성의 교차점에서 중요한 이정표를 세웠다. 특히 다루기 쉬운 확률 모델을 논리적 제약에서 의미적 속성 제어로 확장한 것은 이론적으로도 실용적으로도 의미 있는 기여이며, 향후 언어 모델의 안전성과 맞춤화를 위한 새로운 연구 방향을 열어준다. TRACE의 코드는 GitHub 저장소(https://github.com/yidouweng/trace)에 공개되어 있어 재현과 후속 연구가 용이하다. 본 논문은 DARPA의 ANSR, CODORD, SAFRON 프로그램 및 NSF 보조금, Adobe Research, Cisco Research, Amazon의 지원을 받아 수행되었다.
종합하면, TRACE는 확률적 추론의 원리를 실용적인 언어 생성 시스템에 성공적으로 적용한 사례로, "정확성과 효율성의 균형"이라는 공학적 가치와 "다루기 쉬운 추론을 통한 제어"라는 이론적 가치를 동시에 실현한다. 이 프레임워크가 제시하는 "근사를 모델 수준에서 수행하고 추론은 정확하게"라는 설계 패러다임은 제어 가능한 텍스트 생성을 넘어 구조화된 예측, 제약 조건 만족, 안전한 AI 시스템 등 다양한 분야에 영감을 줄 수 있을 것이다.
10. 요약 정리
- TRACE는 기본 LM으로부터 증류한 은닉 마르코프 모델(HMM)과 경량 인수분해 분류기를 결합하여, 미래 시퀀스에 대한 기대 속성 확률(EAP)을 정확하고 효율적으로 계산하는 제어 가능한 텍스트 생성 프레임워크이다.
- 핵심 근사는 일회성 HMM 증류 단계에 집중되며, 이후 디코딩 시에는 HMM 분포에 대해 정확한(exact) EAP 계산이 가능하다. 이는 기존 방법들의 근사적 EAP 추정(판별자 학습이나 샘플링)과 차별화된다.
- 인수분해된 분류기($p(s|x_{1:n}) = \prod_i w(x_i)$)는 HMM의 전방-후방 알고리즘과 통합될 수 있는 구조를 가지며, 속성이 인수분해 불가능하더라도 정확한 EAP 계산과의 결합으로 강력한 성능을 달성한다.
- RealToxicityPrompts에서 TRACE는 GPT2-Large 기준 평균 최대 독성 0.163, 독성 확률 0.016을 달성하여 DPO(0.180/0.026) 등 모든 베이스라인을 능가하면서도 다양성(Dist-2: 0.85)을 거의 보존한다.
- Gemma-2B로의 확장에서도 TRACE는 DPO를 일관되게 능가하며(평균 최대 독성 0.189 대 0.222, 독성 확률 0.02 대 0.06), 모델 규모에 걸친 강건성을 입증한다.
- 학습 시와 디코딩 시의 확률 변환이 상호 보완적으로 작용하여, 분류기 학습과 생성 제어를 각각 강화한다. 디코딩 시 변환의 스케일 파라미터는 독성-유창성 트레이드오프를 사후적으로 조정하는 직관적 노브를 제공한다.
- 76개 캐릭터에 대한 역할 연기에서 각 캐릭터에 약 3초만에 적응하며, 기존 프롬프팅 접근법을 능가한다. 새로운 속성 추가 비용은 10초에 불과하여 동적 시나리오에 매우 적합하다.
- 추론 시 기본 LM 대비 1.2배의 디코딩 오버헤드만 발생하며, 이는 PPLM(40배), MuCoLa(15-20배), Mix and Match(7.5배) 등 기존 방법들과 극명한 대조를 이룬다.
- 복합 속성 제어에서 개별 분류기의 토큰 가중치를 곱하는 것만으로 재학습 없이 여러 속성을 합성할 수 있으며, 정치적+비독성 텍스트 생성에서 두 속성을 독립적이고 효과적으로 제어한다.
- 향후 연구 방향으로 다루기 쉬운 확률적 회로(tractable probabilistic circuits)를 통한 분류기 표현력 향상, HMM 증류 기법의 품질 및 효율성 개선, 그리고 더 큰 규모의 최신 LLM(7B, 13B, 70B 이상)으로의 확장 가능성 검증이 제시된다.