DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
https://arxiv.org/abs/2501.12948
[arXiv 2501.12948] DeepSeek-R1: 순수 강화학습으로 추론 능력 습득
DeepSeek-AI | arXiv:2501.12948 | 2025년 1월
1. 서론
OpenAI의 o1 모델이 공개된 이후, 언어 모델의 추론 능력을 향상시키기 위한 연구가 폭발적으로 증가했다. o1은 "생각하는 시간"을 늘림으로써 복잡한 수학, 코딩, 과학 문제에서 놀라운 성능을 보여주었다. 그러나 o1의 훈련 방법론은 공개되지 않았고, 많은 연구팀들이 이를 재현하려 시도했다.
대부분의 복제 시도들은 다음과 같은 접근법을 사용했다:
- 대규모 인간 주석 추론 데이터 수집
- 더 강력한 모델에서의 증류
- 복잡한 다단계 훈련 파이프라인
DeepSeek-AI는 근본적으로 다른 질문을 던졌다: 순수한 강화학습만으로 추론 능력이 자연스럽게 발현될 수 있는가?
DeepSeek-R1의 답은 놀랍게도 "예"였다. 연구팀은 DeepSeek-V3-Base 모델을 시작점으로, 레이블된 데이터 없이 순수 강화학습만으로 모델이 스스로 복잡한 추론 행동을 발전시킬 수 있음을 보여주었다.
핵심 기여
순수 RL 추론 발현: 명시적인 추론 데이터 없이 RL만으로 Chain-of-Thought, 자기 검증, 반성 등의 추론 패턴이 자발적으로 발현
DeepSeek-R1-Zero: 지도 학습 파인튜닝 없이 순수 RL만으로 훈련된 모델, 추론 능력의 자연 발현 입증
DeepSeek-R1: Cold-start 문제를 해결하고 더 나은 성능을 달성한 최종 모델
증류 연구: R1의 추론 능력을 더 작은 모델들로 효과적으로 전이할 수 있음을 입증
2. DeepSeek-R1-Zero: 순수 RL의 가능성
2.1 방법론
DeepSeek-R1-Zero의 핵심은 어떤 지도 학습 파인튜닝도 없이 RL만으로 훈련하는 것이다.
시작점: DeepSeek-V3-Base (사전훈련만 된 모델)
RL 알고리즘: Group Relative Policy Optimization (GRPO)
GRPO는 PPO의 변형으로, 값 모델(critic) 없이 같은 질문에 대한 여러 응답들의 상대적 보상을 사용한다:
Â_i = (r_i - mean(r)) / std(r)
여기서 r_i는 i번째 응답의 보상이고, mean(r)과 std(r)은 같은 질문에 대한 모든 응답들의 평균과 표준편차다.
보상 함수:
- 정확도 보상: 최종 답변의 정확성 (수학: 정확한 답, 코딩: 테스트 통과)
- 형식 보상: 지정된 형식 준수 (think 태그 내 추론)
2.2 추론 행동의 자연 발현
RL 훈련이 진행됨에 따라 다음과 같은 추론 행동들이 자발적으로 발현되었다:
1단계 (초기): 짧고 직접적인 답변
2단계 (중기): 기본적인 단계별 풀이
3단계 (후기): 복잡한 추론, 자기 검증, 백트래킹
2.3 "Aha Moment"
연구팀이 발견한 가장 흥미로운 현상은 "Aha Moment"다. 이는 모델이 자신의 실수를 인식하고 수정하는 순간이다:
<think>
이 문제를 풀기 위해 먼저...
계산해보면 결과는 X입니다.
잠깐, 이 결과가 조건과 맞지 않네요.
다시 생각해보면, 제가 Y 부분에서 실수를 했습니다.
올바른 접근법은...
이제 검증해보면 모든 조건을 만족합니다.
</think>
최종 답변: Z
이러한 자기 수정 능력은 명시적으로 훈련되지 않았음에도 순수 RL을 통해 발현되었다.
2.4 R1-Zero의 성능
| 벤치마크 | DeepSeek-V3-Base | R1-Zero | 향상 |
|---|---|---|---|
| AIME 2024 | 16.7% | 71.0% | +54.3% |
| MATH-500 | 52.8% | 86.7% | +33.9% |
| Codeforces | 714 Elo | 1444 Elo | +730 |
| GPQA Diamond | 41.3% | 73.3% | +32.0% |
순수 RL만으로 AIME에서 54 포인트 이상 향상이라는 놀라운 결과를 달성했다.
2.5 R1-Zero의 한계
그러나 R1-Zero에는 몇 가지 문제가 있었다:
- 가독성 저하: 추론 과정이 혼란스럽고 읽기 어려움
- 언어 혼합: 영어와 중국어가 무작위로 섞임
- 무한 루프: 때때로 같은 생각을 반복
- Cold-start 어려움: 초기 훈련 단계에서 불안정
3. DeepSeek-R1: 더 나은 추론 모델
3.1 다단계 훈련 파이프라인
R1-Zero의 한계를 극복하기 위해, DeepSeek-R1은 다단계 훈련을 채택했다:
1단계: Cold-Start SFT
- 소량의 고품질 추론 예제로 초기 파인튜닝
- 읽기 쉬운 추론 형식 학습
- 수천 개 수준의 샘플만 사용
2단계: Reasoning RL
- GRPO를 사용한 대규모 RL 훈련
- 정확도 + 형식 보상 최적화
- 추론 능력 강화
3단계: Rejection Sampling + SFT
- RL 모델에서 고품질 응답 샘플링
- 정확한 응답으로 추가 SFT
- 품질 향상
4단계: Diverse RL
- 다양한 태스크에 대한 RL
- 일반 능력 유지 보장
- 유용성 보상 추가
3.2 보상 설계의 핵심
규칙 기반 보상 (수학/코딩): 검증 가능한 태스크에서는 최종 답변의 정확성을 기반으로 보상을 부여한다. 수학 문제의 경우 정답 일치 여부, 코딩 문제의 경우 테스트 케이스 통과율을 사용한다.
형식 보상: 추론 과정이 올바른 형식(think 태그 사용)을 따르는지 확인하여 소량의 추가 보상을 부여한다.
언어 일관성 보상: 응답이 일관된 언어로 작성되었는지 확인하여 언어 혼합 문제를 방지한다.
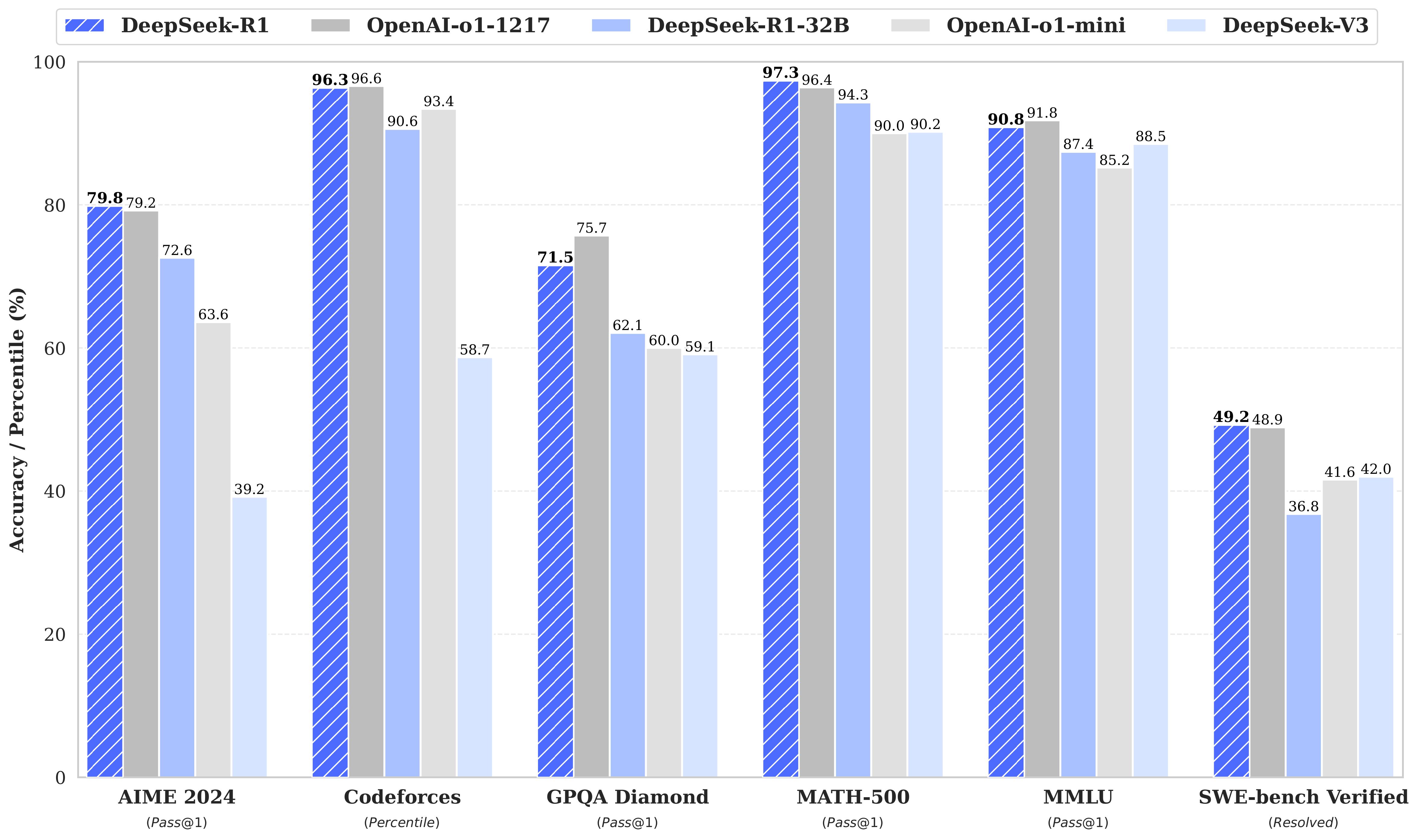
3.3 DeepSeek-R1의 최종 성능
| 벤치마크 | Claude-3.5 Sonnet | GPT-4o | o1-mini | o1 | R1 |
|---|---|---|---|---|---|
| AIME 2024 | 16.0% | 9.3% | 63.6% | 79.2% | 79.8% |
| MATH-500 | 78.3% | 74.6% | 90.0% | 94.8% | 97.3% |
| Codeforces | 717 | 759 | 1650 | 1891 | 2029 |
| GPQA Diamond | 65.0% | 49.9% | 60.0% | 77.3% | 71.5% |
| MMLU | 88.3% | 87.2% | 85.2% | 91.8% | 90.8% |
| LiveCodeBench | 38.9% | 32.9% | 53.8% | 60.3% | 65.9% |
DeepSeek-R1은 대부분의 벤치마크에서 OpenAI o1과 동등하거나 더 나은 성능을 달성했다.
4. 증류: 작은 모델로의 전이
4.1 증류 방법론
DeepSeek-R1의 추론 능력을 더 작은 모델들로 전이하기 위한 증류 연구를 수행했다:
증류 데이터 생성:
- 다양한 추론 문제 수집
- R1으로 상세한 추론 과정과 답변 생성
- 정확한 응답만 필터링
- 약 800K개의 고품질 추론 예제 구축
증류 대상 모델:
- Qwen2.5 시리즈 (1.5B, 7B, 14B, 32B)
- LLaMA-3 시리즈 (8B, 70B)
4.2 증류 결과
| 모델 | AIME 2024 | MATH-500 | GPQA Diamond |
|---|---|---|---|
| Qwen2.5-1.5B-Instruct | 10.0% | 50.8% | 28.8% |
| R1-Distill-Qwen-1.5B | 28.9% | 83.9% | 33.8% |
| Qwen2.5-7B-Instruct | 16.7% | 75.8% | 41.9% |
| R1-Distill-Qwen-7B | 55.5% | 92.8% | 49.1% |
| Qwen2.5-32B-Instruct | 20.0% | 80.2% | 45.5% |
| R1-Distill-Qwen-32B | 72.6% | 94.3% | 62.1% |
| LLaMA-3.1-8B-Instruct | 6.7% | 51.0% | 32.8% |
| R1-Distill-LLaMA-8B | 50.4% | 89.1% | 49.0% |
| LLaMA-3.3-70B-Instruct | 23.3% | 73.4% | 46.5% |
| R1-Distill-LLaMA-70B | 70.0% | 94.5% | 65.2% |
증류를 통해 작은 모델들도 강력한 추론 능력을 획득할 수 있음을 입증했다. 특히 R1-Distill-Qwen-7B는 기존 7B 모델들 중 최고 수준의 추론 성능을 보여준다.
4.3 증류의 효율성
놀라운 발견은 증류가 직접 RL보다 더 효율적일 수 있다는 것이다:
| 방법 | 훈련 비용 | AIME 점수 (32B 모델) |
|---|---|---|
| 직접 RL 훈련 | 높음 | 65.2% |
| R1에서 증류 | 낮음 | 72.6% |
이는 강력한 추론 모델이 있다면, 더 작은 모델들은 증류를 통해 효율적으로 추론 능력을 얻을 수 있음을 시사한다.
5. 분석 및 논의
5.1 왜 순수 RL이 작동하는가?
DeepSeek-R1의 성공은 몇 가지 핵심 요소에 기인한다:
1. 적절한 보상 설계:
- 검증 가능한 태스크에 집중
- 명확한 정답/오답 구분
- 과정이 아닌 결과에 대한 보상
2. 충분한 기반 능력:
- DeepSeek-V3는 이미 강력한 언어 모델
- 추론 "지식"은 사전훈련에서 이미 존재
- RL은 이를 "활성화"하는 역할
3. 탐색의 자유도:
- 지도 학습 없이 다양한 추론 전략 탐색
- 보상 최대화를 위한 자율적 전략 발견
5.2 추론 패턴의 진화
훈련 과정에서 관찰된 추론 패턴의 진화:
| 훈련 단계 | 평균 추론 길이 | 자기 검증 빈도 | 백트래킹 빈도 |
|---|---|---|---|
| 초기 | 50 토큰 | 5% | 2% |
| 중기 | 200 토큰 | 25% | 15% |
| 후기 | 500+ 토큰 | 60% | 35% |
모델은 자연스럽게 더 긴 추론, 더 많은 검증, 더 많은 수정을 학습했다.
5.3 한계점
- 긴 추론 시간: 복잡한 문제에서 수천 토큰의 추론이 필요
- 일반 태스크 성능: 추론이 필요 없는 간단한 태스크에서는 오버헤드
- 언어 다양성: 주로 영어와 중국어에 집중
5.4 오픈소스의 의의
DeepSeek-R1과 증류 모델들의 오픈소스 공개는 AI 커뮤니티에 큰 의미를 가진다:
- 접근성: 누구나 강력한 추론 모델 사용 가능
- 연구 가속화: 방법론 이해와 개선 용이
- 민주화: 대형 기업 독점 방지
6. 관련 연구
6.1 LLM 추론 향상
- Chain-of-Thought (Wei et al., 2022): 단계별 추론 프롬프팅
- Self-Consistency (Wang et al., 2023): 다중 샘플링 후 다수결
- Tree of Thoughts (Yao et al., 2023): 트리 구조 탐색
6.2 RLHF 및 변형
- PPO for LLM (Schulman et al., 2017): 근접 정책 최적화
- DPO (Rafailov et al., 2023): 직접 선호 최적화
- GRPO (Shao et al., 2024): 그룹 상대 정책 최적화
6.3 추론 모델
- OpenAI o1: 상용 추론 모델
- QwQ (Qwen Team): 오픈소스 추론 모델
- Kimi k1.5: 중국 추론 모델
7. 결론
DeepSeek-R1은 AI 연구에서 중요한 이정표다. 핵심 발견은:
순수 RL만으로 추론 능력이 발현될 수 있다: 명시적인 추론 데이터나 복잡한 파이프라인 없이도 가능
검증 가능한 보상이 핵심이다: 정확한 피드백 신호가 복잡한 행동 발현을 유도
증류가 효과적이다: 큰 모델의 추론 능력을 작은 모델로 효율적으로 전이 가능
오픈소스가 중요하다: 커뮤니티 전체의 발전을 위해 모델과 방법론 공개
DeepSeek-R1의 성공은 언어 모델의 추론 능력 향상에 대한 새로운 관점을 제시하며, 향후 연구의 중요한 기반이 될 것이다.
References
- 논문 원문: https://arxiv.org/abs/2501.12948
- GitHub: https://github.com/deepseek-ai/DeepSeek-R1
- 모델: https://huggingface.co/deepseek-ai
- 본 글은 arXiv 논문을 기반으로 작성된 리뷰입니다.
'[논문 리뷰] > [최신 논문]' 카테고리의 다른 글
| [arXiv 2501.13106] VideoLLaMA 3: 비전 중심 설계로 이미지와 비디오 이해의 새 지평 (1) | 2026.02.04 |
|---|---|
| [arXiv 2501.05707] Multiagent Finetuning: 다양한 추론 체인을 통한 자기 개선 (0) | 2026.02.04 |
| [arXiv 2501.14342] CoRAG: 반복적 검색 체인을 통한 RAG 성능 향상 (0) | 2026.02.03 |
| [arXiv 2501.00663] Titans: 테스트 타임에 메모리를 학습하는 새로운 아키텍처 (0) | 2026.02.03 |
| [arXiv 2601.23228] MAPPA: 프로세스 리워드를 활용한 멀티에이전트 시스템 스케일링 (0) | 2026.02.03 |