VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
https://arxiv.org/abs/2501.13106
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, Peng Jin, Wenqi Zhang, Fan Wang, Lidong Bing, Deli Zhao | Alibaba DAMO Academy, Hupan Lab | arXiv:2501.13106 | 2025년 1월
1. 서론
최근 대규모 언어 모델(LLM)의 급속한 성장은 자연어 처리와 이해 분야에 혁신을 가져왔다. GPT-4, Claude 3, Gemini, LLaMA-3, Qwen2 등의 모델들은 언어 수준에서의 지능을 크게 향상시켰다. 그러나 세상 자체가 본질적으로 다중 모달이기 때문에, 진정한 지능은 언어를 넘어 정적 장면과 동적 환경 모두를 인식할 수 있어야 한다. 이는 이미지와 비디오를 이해하는 능력을 필요로 한다.
LLM의 성공을 바탕으로, Qwen2-VL, InternVL, DeepSeek-VL 등 다중 모달 LLM(MLLM)이 다중 모달 이해를 위해 제안되었다. 기존 MLLM들은 다중 모달 이해에서 상당한 발전을 이루었다.
이미지 중심 MLLM들은 수집과 큐레이션이 더 쉬운 고품질 이미지-텍스트 데이터셋을 활용하여 시각적 질문 응답, OCR, 문서 이해 등에서 강력한 성능을 보여주고 있다.
비디오 중심 MLLM들은 이미지와 같은 정적 콘텐츠를 넘어 시간적 차원 모델링이라는 추가적인 복잡성과 함께, 주석 달기 어렵고 품질이 낮은 대규모 비디오-텍스트 데이터셋의 필요성으로 인해 더 큰 도전에 직면한다. 이러한 시간적 복잡성은 동적 콘텐츠를 처리하고 프레임 간 의존성을 포착해야 하는 필요성과 결합되어 비디오 MLLM을 더욱 어렵게 만든다.
이러한 도전 과제는 이미지 이해를 비디오 이해의 기반으로 활용하는 접근법의 장점을 강조한다. 이미지 MLLM의 강력한 시각적 능력을 확장함으로써, 비디오 모델은 시간적 및 동적 콘텐츠 모델링의 고유한 도전에 집중하고 더 잘 해결할 수 있다.
Alibaba DAMO Academy 연구팀은 VideoLLaMA와 VideoLLaMA2를 계승한 VideoLLaMA 3를 제안한다. 이 모델은 이미지와 비디오 이해 모두를 위한 더욱 발전된 다중 모달 기반 모델이다. VideoLLaMA3의 핵심 설계 철학은 비전 중심(vision-centric)이다. "비전 중심"의 의미는 두 가지다:
- 비전 중심 훈련 패러다임: 고품질 이미지-텍스트 데이터가 이미지와 비디오 이해 모두에 중요하다는 핵심 통찰. 대규모 비디오-텍스트 데이터셋을 준비하는 대신 대규모 고품질 이미지-텍스트 데이터셋 구축에 집중
- 비전 중심 프레임워크 설계: 이미지의 세밀한 디테일을 더 잘 포착하기 위해 사전 훈련된 비전 인코더를 가변 크기의 이미지를 해당 수의 비전 토큰으로 인코딩하도록 적응. 비디오 입력의 경우 유사성에 따라 비전 토큰 수를 줄여 비디오 표현을 더 정확하고 컴팩트하게 만듦
주요 기여
- VideoLLaMA3 제안: 이미지와 비디오 이해를 위한 더욱 발전된 다중 모달 기반 모델. 대부분의 이미지 및 비디오 이해 벤치마크에서 state-of-the-art 성능 달성. VideoLLaMA의 이전 버전에 비해 현저한 개선
- 비전 중심 훈련 패러다임 제안: 대규모 이미지 이해 사전 훈련을 통해 비디오 이해 능력 향상
- 두 가지 비전 중심 프레임워크 설계 제안: 이미지와 비디오를 더 잘 표현하기 위한 비전 인코더 적응
2. 방법론

모델 측면에서 VideoLLaMA3는 두 가지 핵심 기술 포인트로 구성된다: (1) Any-resolution Vision Tokenization (AVT)과 (2) Differential Frame Pruner (DiffFP). 데이터 측면에서는 이미지 이해 능력을 기반으로 비디오 이해 능력을 향상시키기 때문에 고품질 re-captioned 이미지 데이터셋을 구축하기 위한 파이프라인도 개발했다.
2.1 Any-resolution Vision Tokenization (AVT)
MLLM에서 시각적 입력은 다중 모달 이해를 위해 비전 토큰으로 추출된다. 일반적인 관행은 사전 훈련된 ViT 기반 비전 인코더로 시각적 입력을 추출하는 것이다. 그러나 사전 훈련된 비전 인코더는 고정 해상도의 이미지만 받아들여 정보 손실이 발생한다.
정보 손실을 완화하기 위해 AnyRes 기술이 이미지를 고정 해상도 패치로 분할하는 방식으로 제안되었다. AnyRes 기술은 비전 토큰 수를 증가시키지만, 여전히 유연하지 못하고 비전 토큰 추출 시 이미지 내 위치 관계를 무시한다.
VideoLLaMA3에서는 모든 해상도의 이미지와 비디오를 동적으로 처리하기 위해 Any-resolution Vision Tokenization (AVT) 아이디어를 채택한다. 구체적으로, 사전 훈련된 비전 인코더(ViT 기반 아키텍처)가 가변 해상도를 처리할 수 있도록 ViT의 절대 위치 임베딩을 2D-RoPE로 대체하는 전략을 사용한다.
AVT를 통해 다양한 해상도의 이미지와 비디오가 비전 토큰에 더 많은 세부 정보를 포함하여 더 잘 표현된다. 비전 인코더가 AVT와 호환되도록 Vision Encoder Adaptation 단계(Figure 2의 1단계)에서 장면 이미지, 문서 데이터, 텍스트가 포함된 장면 이미지를 사용하여 비전 인코더와 프로젝터를 미세조정한다.
AVT의 핵심 장점:
- 고해상도 이미지의 세부 정보 보존
- 비정상적인 종횡비 이미지 처리 가능
- 정보 손실 최소화
- 자연스러운 위치 관계 유지
2.2 Differential Frame Pruner (DiffFP)

비디오의 경우, 토큰화 후 입력이 이미지 입력보다 훨씬 더 많은 토큰을 가진다. 비디오의 연산 요구를 줄이기 위해 프레임당 2×2 공간 다운샘플링을 bilinear interpolation으로 적용하여 컨텍스트 길이를 특정 범위 내로 제한한다.
또한, 비디오가 중복 콘텐츠가 있는 프레임으로 구성되어 있다는 점을 고려하여, 각 프레임의 비전 토큰을 스택하여 비디오를 표현하면 길고 중복된 토큰이 생성된다. 비디오의 토큰 수를 더욱 줄이기 위해 Differential Frame Pruner (DiffFP)를 제안한다.
RLT에서 영감을 받아, 픽셀 공간 내에서 시간적으로 연속적인 패치 간의 1-norm 거리를 비교한다. 더 작은 거리를 가진 시간적으로 연속적인 패치는 중복으로 간주되며, 나중 패치를 프루닝할 수 있다. 기본 임계값은 0.1로 설정한다.
DiffFP의 장점:
- 비디오의 동적 부분에 집중 가능
- 중복 정보 제거로 연산 효율성 향상
- 훈련 및 추론 시 연산 요구량 절감
- 더 정확하고 컴팩트한 비디오 표현
2.3 고품질 이미지 Re-Caption 데이터셋 구축
VideoLLaMA3를 훈련하기 위해 고품질 이미지 re-caption 데이터셋 VL3-Syn7M을 구축했다. 모든 이미지는 COYO-700M에서 소싱되었으며 다음 클리닝 파이프라인을 사용하여 처리:
1) 종횡비 필터링 (Aspect Ratio Filtering)
- 극단적인 종횡비를 가진 이미지 제거
- 일반적인 종횡비를 가진 이미지만 포함하여 특징 추출 중 잠재적 편향 방지
- 과도하게 길거나 넓은 이미지는 비정상적인 형태로 인해 모델 해석을 왜곡할 수 있음
2) 미적 점수 필터링 (Aesthetic Score Filtering)
- 미적 점수 모델을 적용하여 이미지의 시각적 품질 평가
- 낮은 미적 등급의 이미지 제거
- 시각적으로 불량하거나 구성이 좋지 않은 이미지 제거로 노이즈 감소
3) 텍스트-이미지 유사성 계산 (Text-Image Similarity with Coarse Captioning)
- BLIP2 모델로 초기 캡션 생성
- CLIP 모델로 텍스트-이미지 유사성 계산
- 유사성이 낮은 이미지 제외 (간결하게 설명하기 어려운 콘텐츠 포함 가능성)
- 남은 이미지가 설명적이고 해석 가능하도록 보장
4) 시각적 특징 클러스터링 (Visual Feature Clustering)
- CLIP 비전 모델로 시각적 특징 추출
- k-Nearest-Neighbors (KNN) 알고리즘으로 클러스터링
- 시각적 특징 공간에서 클러스터 중심 식별
- 각 클러스터에서 고정 수의 이미지 선택
- 의미 범주의 균형 잡힌 분포 유지로 다양한 시각적 콘텐츠에 대한 일반화 능력 향상
5) 이미지 Re-caption
- InternVL2-8B로 간략한 캡션 생성 (VL3-Syn7M-short)
- InternVL2-26B로 상세한 캡션 생성 (VL3-Syn7M-detailed)
- 두 종류의 캡션을 훈련의 다른 단계에서 다양한 필요에 따라 활용
이 과정을 통해 700만 개의 이미지-캡션 쌍으로 구성된 VL3-Syn7M 데이터셋을 생성했다. 이 고품질 데이터셋은 모델 훈련의 중요한 구성 요소로, 다양한 시각적 태스크에서 강력한 성능을 지원하는 풍부하고 다양한 이미지와 주석 세트를 제공한다.
3. 훈련
VideoLLaMA3는 네 가지 핵심 구성 요소로 이루어진다: 비전 인코더, 비디오 압축기, 프로젝터, 대규모 언어 모델(LLM). 비전 인코더는 시각적 토큰을 추출하며 사전 훈련된 SigLIP으로 초기화된다. 비디오를 표현하는 비전 토큰 수를 줄이기 위해 비디오 압축기를 사용한다. 프로젝터는 비전 인코더와 LLM 간의 특징을 연결한다. LLM은 Qwen2.5 모델을 활용한다.
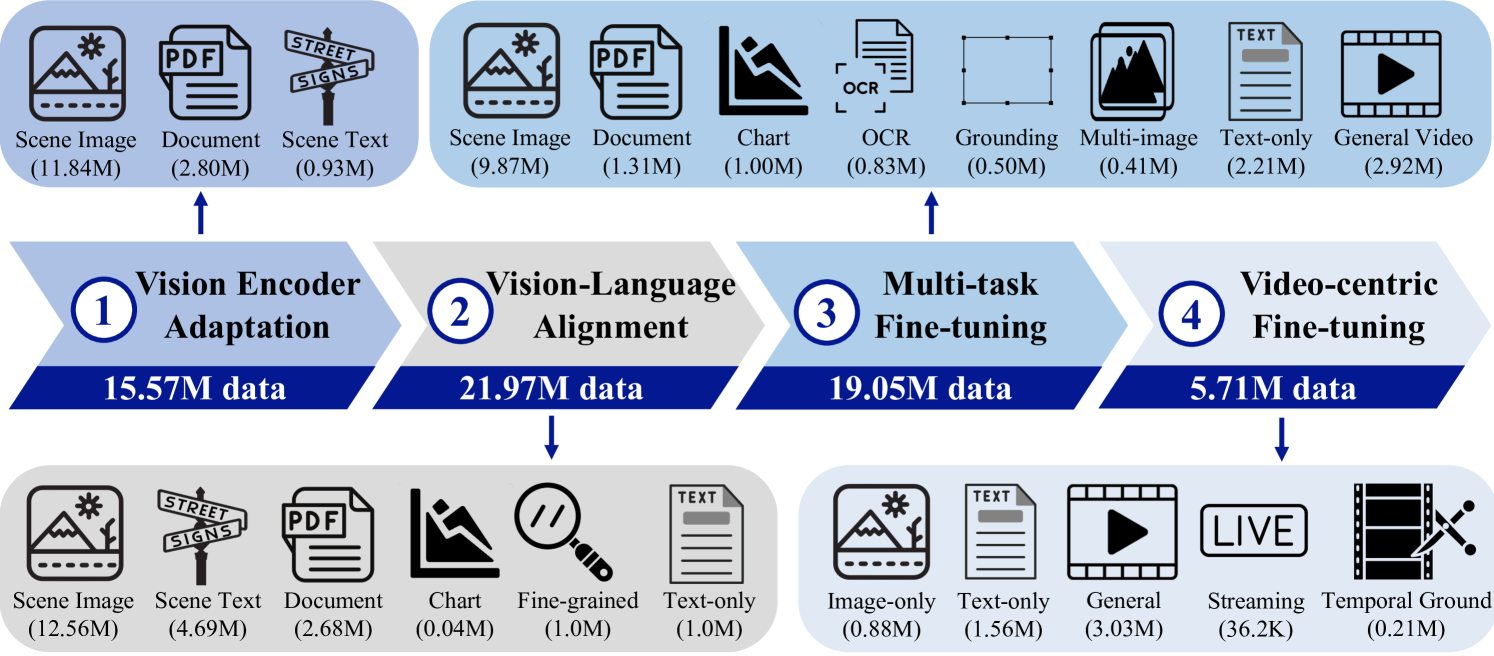
강력한 이미지 이해 기반 위에 비디오 이해 능력을 개발하기 위해 VideoLLaMA3의 훈련은 네 단계로 구성된다.
3.1 Vision Encoder Adaptation 단계
이 단계에서는 사전 훈련된 SigLIP으로 초기화된 비전 인코더를 대규모 이미지 데이터셋에서 미세조정한다. 비전 인코더는 훈련 가능하게 설정되고 언어 디코더는 동결된다. 이 미세조정은 인코더를 동적 해상도 프로세서로 변환하여 다양한 해상도의 이미지를 처리하는 능력을 향상시킨다.
데이터 구성:
| 태스크 | 데이터셋 | 수량 |
|---|---|---|
| 장면 이미지 | VL3-Syn7M-short, LLaVA-Pretrain-558k, Objects365-Recap, SA-1B-Recap | 11.84M |
| 장면 텍스트 이미지 | BLIP3-OCR-Recap | 0.93M |
| 문서 | pdfa-eng-wds, idl-wds | 2.80M |
3.2 Vision-Language Alignment 단계
이 단계는 주로 모델에 다중 모달 지식을 도입하는 데 초점을 맞춘다. 이 단계에서는 모든 파라미터가 훈련 가능하게 설정되어 LLM과 비전 인코더 모두가 다중 모달 지식 통합을 위해 미세조정된다.
데이터 구성:
| 태스크 | 데이터셋 | 수량 |
|---|---|---|
| 장면 이미지 | VL3-Syn7M-detailed, Objects365-Recap, SA-1B-Recap, 등 | 12.56M |
| 장면 텍스트 이미지 | Laion-OCR, COCO-Text, TextOCR, 등 | 4.69M |
| 문서 | SynthDoG-EN/ZH, UReader-TR, FUNSD, 등 | 2.68M |
| 차트 | Chart-to-Text | 0.04M |
| 세밀한 이미지 | Osprey-724K, MDVP-Data, ADE20K-Recap, 등 | 1.00M |
| 텍스트 전용 | Evol-Instruct-143K, Infinity-Instruct | 6.25M |
3.3 Multi-task Fine-tuning 단계
이 단계에서는 인터랙티브 질문 응답 등 다운스트림 태스크를 위해 모델을 미세조정한다. 질문과 답변이 포함된 이미지-텍스트 데이터와 함께 일반 비디오 캡션 데이터를 사용하여 모델이 비디오 인식을 준비하도록 한다.
데이터 구성:
| 태스크 | 수량 |
|---|---|
| 일반 | 9.87M |
| 문서 | 1.31M |
| 차트/그림 | 1.00M |
| OCR | 0.83M |
| 그라운딩 | 0.50M |
| 다중 이미지 | 0.41M |
| 텍스트 전용 | 2.21M |
| 비디오 | 2.92M |
3.4 Video-centric Fine-tuning 단계
이 단계는 모델의 비디오 이해 및 비디오 질문 응답 성능을 향상시키는 데 초점을 맞춘다.
데이터 구성:
| 태스크 | 수량 |
|---|---|
| 일반 비디오 | 3.03M |
| 스트리밍 비디오 | 36.2K |
| 시간적 그라운딩 | 0.21M |
| 이미지 전용 | 0.88M |
| 텍스트 전용 | 1.56M |
3.5 데이터 포맷
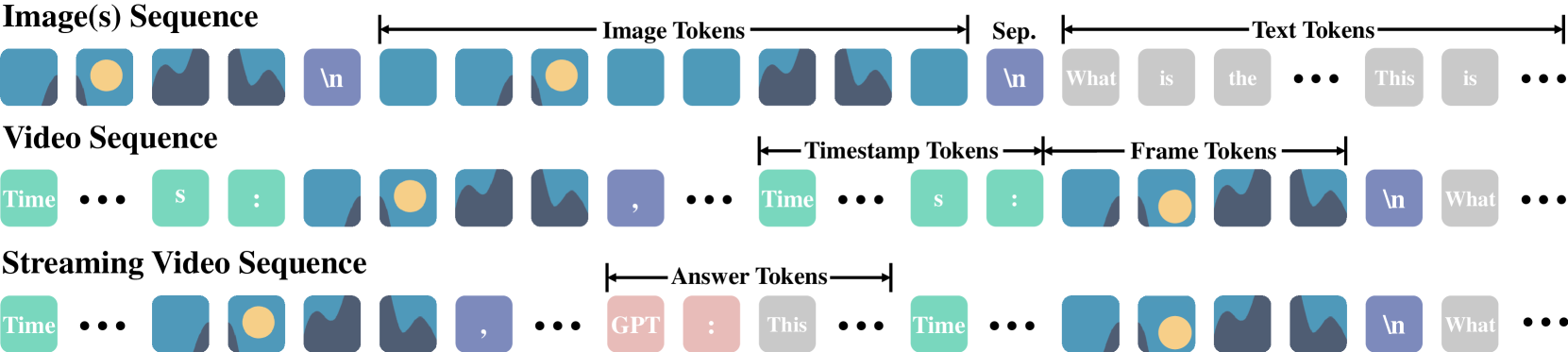
이미지 시퀀스: 이미지는 이미지 토큰이라고 하는 토큰 시퀀스로 표현된다. "\n" 문자는 다른 이미지의 토큰을 분리하는 데 사용된다.
비디오 시퀀스: 비디오 시퀀스의 프레임은 프레임 토큰으로 표현된다. 각 프레임의 토큰 앞에 "Time: xxs" 형식의 타임스탬프 토큰이 삽입되어 해당 프레임에 대응하는 시간을 나타낸다.
스트리밍 비디오 시퀀스: 스트리밍 비디오 데이터의 경우 비디오와 텍스트 토큰이 시퀀스에 인터리브된다.
4. 실험 결과
4.1 이미지 기반 평가
2B 모델 결과:
| 벤치마크 | SmolVLM 2B | InternVL2.5 2B | Qwen2-VL 2B | VideoLLaMA3 2B |
|---|---|---|---|---|
| ChartQA | 65.3 | 79.2 | 73.5 | 79.8 |
| DocVQA | 81.6 | 88.7 | 90.1 | 91.9 |
| InfoVQA | - | 60.9 | 65.5 | 69.4 |
| MathVista | 44.6 | 51.3 | 43.0 | 59.2 |
| MMMU | 38.8 | 43.6 | 41.1 | 45.3 |
| RealWorldQA | 48.8 | 60.1 | 62.9 | 67.3 |
| AI2D | 62.1 | 74.9 | 69.9 | 78.2 |
7B 모델 결과:
| 벤치마크 | Molmo-7B | InternVL2.5 8B | Qwen2-VL 8B | VideoLLaMA3 7B |
|---|---|---|---|---|
| ChartQA | 84.1 | 84.8 | 83.0 | 86.3 |
| DocVQA | 92.2 | 93.0 | 94.5 | 94.9 |
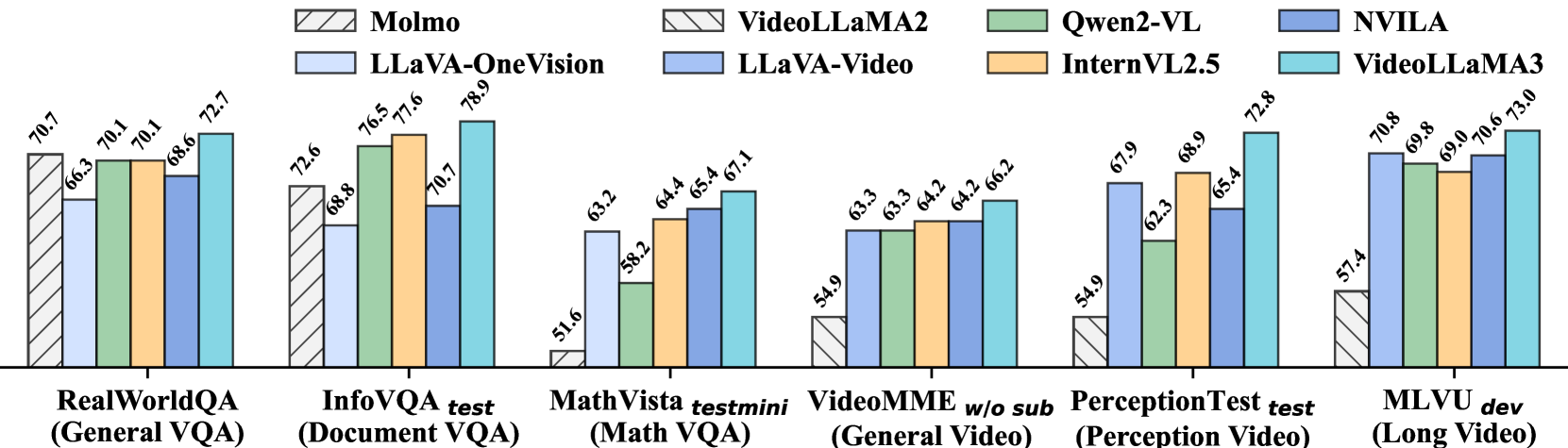
| InfoVQA | 72.6 | 77.6 | 76.5 | 78.9 |
| MathVista | 51.6 | 64.4 | 58.2 | 67.1 |
| MathVision | - | 19.7 | 16.3 | 26.2 |
| RealWorldQA | 70.7 | 70.1 | 70.1 | 72.7 |
핵심 관찰:
- MathVision에서 이전 최고 대비 6.5% 향상: 수학적 추론에서 특히 뛰어남
- 차트 이해 (InfoVQA)에서 1.3% 성능 향상
- RealWorldQA에서 2.0% 성능 향상: 일반 추론 태스크에서 우수
4.2 비디오 기반 평가
7B 모델 결과:
| 벤치마크 | Qwen2-VL 7B | InternVL2.5 8B | LLaVA-Video 7B | VideoLLaMA3 7B |
|---|---|---|---|---|
| VideoMME w/o sub | 63.3 | 64.2 | 63.3 | 66.2 |
| VideoMME w/ sub | 69.0 | 66.9 | 69.7 | 70.3 |
| MMVU | 42.1 | 41.1 | 42.4 | 44.1 |
| PerceptionTest | 62.3 | 68.9 | 67.9 | 72.8 |
| ActivityNet-QA | 57.4 | 58.9 | 56.5 | 61.3 |
| MLVU | 69.8 | 69.0 | 70.8 | 73.0 |
| LVBench | 44.2 | 41.5 | 40.3 | 43.7 |
| NextQA | 81.2 | 85.0 | 83.2 | 84.5 |
| Charades-STA | - | - | - | 60.7 |
핵심 관찰:
- VideoMME에서 state-of-the-art 달성 (자막 없이 66.2%, 자막 포함 70.3%)
- PerceptionTest에서 72.8%로 다른 모델들을 크게 능가
- MLVU에서 73.0%로 장시간 비디오 이해에서 최고 성능
- Charades-STA에서 60.7%로 시간적 그라운딩 능력 입증
4.3 시간적 그라운딩 성능
시간적 그라운딩은 자연어 쿼리가 주어졌을 때 비디오에서 해당 시간 구간을 찾는 태스크다:
| 모델 | Charades-STA R@0.3 | Charades-STA R@0.5 |
|---|---|---|
| VTimeLLM | 27.5 | 11.4 |
| TimeChat | 32.2 | 13.4 |
| VTG-LLM | 35.3 | 16.1 |
| VideoLLaMA3-7B | 52.8 | 30.5 |
VideoLLaMA3는 시간적 그라운딩 태스크에서 이전 모델들을 현저하게 능가한다.
5. 사례 연구
5.1 차트 이미지 이해

5.2 OCR 및 문서 이해

5.3 다중 이미지 이해

5.4 일반 이미지 및 비디오 이해


5.5 장시간 비디오 이해, 시간적 그라운딩, 비디오-이미지 공동 이해

6. 핵심 통찰 및 의의
6.1 비전 중심 패러다임의 효과
VideoLLaMA3의 핵심 통찰은 고품질 이미지-텍스트 데이터가 이미지와 비디오 이해 모두에 중요하다는 것이다. 비디오는 본질적으로 시간적으로 상관된 이미지들의 시퀀스이므로, 강력한 이미지 이해 능력이 비디오 이해의 기초가 된다.
이 접근법의 장점:
- 데이터 품질: 이미지-텍스트 데이터는 비디오-텍스트 데이터보다 수집과 큐레이션이 쉽고 품질이 높다
- 전이 학습: 이미지 이해에서 학습된 시각적 표현이 비디오 이해로 자연스럽게 전이
- 효율성: 대규모 비디오 데이터셋 구축 없이도 우수한 비디오 이해 성능 달성
6.2 Dynamic Resolution의 중요성
AVT를 통한 동적 해상도 처리는 다음과 같은 이점을 제공한다:
- 고해상도 이미지의 세부 정보 보존
- 비정상적인 종횡비 이미지 처리 가능
- 정보 손실 최소화
- 자연스러운 위치 관계 유지
6.3 효율적인 비디오 표현
DiffFP를 통한 비디오 토큰 압축은:
- 비디오의 동적 부분에 집중
- 중복 정보 제거로 연산 효율성 향상
- 훈련 및 추론 시 연산 요구량 절감
- 더 정확하고 컴팩트한 비디오 표현
7. 한계점 및 향후 연구
7.1 현재 한계
- 긴 비디오 처리: 매우 긴 비디오(수 시간)에 대한 처리는 여전히 도전적
- 실시간 처리: 실시간 비디오 스트림 처리에는 추가적인 최적화 필요
- 오디오 통합: 현재 모델은 시각적 정보에 집중하며 오디오는 포함하지 않음
- 메모리 효율성: 장시간 비디오의 경우 메모리 사용량이 여전히 높음
7.2 향후 연구 방향
- 더 긴 비디오 컨텍스트 처리를 위한 효율적인 메모리 메커니즘
- 오디오-비주얼 다중 모달 통합
- 실시간 비디오 이해 및 상호작용
- 더 효율적인 비디오 토큰 압축 기법
- 에이전트 기반 비디오 이해 시스템
8. 결론
VideoLLaMA3는 비전 중심 설계 철학을 통해 이미지와 비디오 이해 모두에서 state-of-the-art 성능을 달성했다. 핵심 혁신인 Any-resolution Vision Tokenization과 Differential Frame Pruner는 효율적이면서도 정확한 시각적 표현을 가능하게 한다.
4단계 훈련 패러다임은 이미지 이해를 기반으로 비디오 이해 능력을 체계적으로 구축하며, 이는 다중 모달 AI 시스템 설계에 대한 중요한 통찰을 제공한다:
- 품질 우선: 대량의 저품질 데이터보다 소량의 고품질 데이터가 더 효과적
- 기초부터 확장: 이미지 이해의 강력한 기초 위에 비디오 이해 구축
- 효율적 표현: 중복 제거와 동적 해상도로 효율성과 성능 동시 달성
- 체계적 훈련: 단계별 훈련으로 각 능력을 순차적으로 구축
VideoLLaMA3의 성공은 고품질 데이터와 신중한 아키텍처 설계의 조합이 대규모 데이터셋보다 더 효과적일 수 있음을 보여준다. 이 연구는 다중 모달 AI의 발전에 중요한 방향을 제시하며, 특히 비디오 이해 분야에서 새로운 기준을 수립했다.
References
- 논문 원문: https://arxiv.org/abs/2501.13106
- GitHub 코드: https://github.com/DAMO-NLP-SG/VideoLLaMA3
- VL3-Syn7M 데이터셋: Alibaba DAMO에서 공개 예정
본 글은 arXiv 논문을 기반으로 작성된 리뷰입니다.
'[논문 리뷰] > [최신 논문]' 카테고리의 다른 글
| [arXiv 2501.19393] s1: 단순한 테스트 시점 스케일링으로 o1-preview를 능가하는 추론 모델 (0) | 2026.02.04 |
|---|---|
| [arXiv 2501.03262] REINFORCE++: 전역 어드밴티지 정규화로 Critic-Free RLHF의 안정성과 효율성을 동시에 잡다 (0) | 2026.02.04 |
| [arXiv 2501.05707] Multiagent Finetuning: 다양한 추론 체인을 통한 자기 개선 (0) | 2026.02.04 |
| [arXiv 2501.14342] CoRAG: 반복적 검색 체인을 통한 RAG 성능 향상 (0) | 2026.02.03 |
| [arXiv 2501.00663] Titans: 테스트 타임에 메모리를 학습하는 새로운 아키텍처 (0) | 2026.02.03 |