s1: Simple Test-Time Scaling
https://arxiv.org/abs/2501.19393
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, Tatsunori Hashimoto | Stanford University, University of Washington | arXiv:2501.19393 | 2025년 1월 | ICML 2025 게재 확정
1. 서론: "가장 단순한 접근법은 무엇인가?"
대규모 언어 모델(Large Language Model, LLM)의 성능 향상은 지난 수년간 주로 훈련 시간 컴퓨팅(train-time compute)의 스케일링에 의존해 왔다. Kaplan 등(2020)이 제시한 스케일링 법칙(scaling law)과 Hoffmann 등(2022)이 제안한 Chinchilla 최적 스케일링은 모델 파라미터 수와 훈련 데이터 양을 함께 증가시킬 때 예측 가능한 성능 향상이 이루어진다는 사실을 실증적으로 보여주었다. 이러한 대규모 자기지도 사전 훈련을 통해 구축된 강력한 기반 모델들은 새로운 스케일링 패러다임의 토대를 마련하였는데, 그것이 바로 테스트 타임 스케일링(test-time scaling)이다.
테스트 타임 스케일링의 핵심 아이디어는 모델의 추론(inference) 단계에서 더 많은 연산을 투입함으로써 최종 출력의 품질을 향상시키는 것이다. 훈련 단계의 비용을 추가로 늘리지 않고도 기존 모델의 잠재력을 최대한 끌어낼 수 있다는 점에서 매우 매력적인 접근법이며, 인간이 어려운 문제에 직면했을 때 더 오래 숙고하고, 여러 접근법을 시도하며, 중간 결과를 검증하는 과정과 유사하다. 2024년 OpenAI가 공개한 o1 모델은 이 패러다임의 실용성을 극적으로 입증하였으며, 테스트 타임에 더 많은 연산을 사용할수록 추론 성능이 일관되게 향상되는 현상을 보여주었다.
그러나 OpenAI는 o1의 구체적인 방법론을 공개하지 않았으며, 단지 대규모 강화학습(reinforcement learning)을 활용했다는 점만 언급하였다. 이로 인해 o1의 성능을 재현하기 위한 다양한 시도가 학계와 산업계에서 동시다발적으로 이루어졌으나, 명확한 테스트 타임 스케일링 행동을 공개적으로 재현한 사례는 없었다. 이러한 배경 속에서 본 논문의 저자들은 근본적인 질문을 던진다:
"테스트 타임 스케일링과 강력한 추론 성능을 동시에 달성하기 위한 가장 단순한(simplest) 접근법은 무엇인가?"
본 논문은 이 질문에 대한 놀라울 정도로 간결한 해답을 제시한다. 저자들이 제안하는 레시피는 세 가지 구성요소로 이루어진다:
- s1K 데이터셋: 난이도(difficulty), 다양성(diversity), 품질(quality)이라는 세 가지 기준에 따라 엄선된 1,000개의 질문-추론 트레이스 쌍
- 지도 미세조정(SFT): Qwen2.5-32B-Instruct 모델에 s1K를 미세조정하는 데 16개의 H100 GPU에서 불과 26분(7 H100 GPU 시간) 소요
- Budget forcing: 모델의 사고 과정을 강제로 종료하거나, "Wait" 문자열을 추가하여 더 깊은 탐색을 유도하는 디코딩 시간 개입
이 간단한 레시피를 통해 구축된 s1-32B 모델은 경쟁 수학 문제에서 OpenAI o1-preview를 최대 27%까지 상회하는 성능을 달성하였으며, budget forcing을 통한 테스트 타임 스케일링으로 AIME24에서 50%에서 57%로 성능을 외삽(extrapolate)하는 것이 가능하였다. DeepSeek-r1의 수천 GPU 시간, OpenAI o1의 추정상 수만 GPU 시간과 비교하면 극적으로 효율적인 자원 활용이라 할 수 있다.

Figure 1: s1-32B의 테스트 타임 스케일링. 추론 집약적 태스크(AIME24, MATH500, GPQA Diamond)에서 s1-32B의 성능을 벤치마크하고 테스트 타임 연산량을 변화시킨 결과이다. 사고 토큰(thinking tokens)의 수가 증가할수록 세 벤치마크 모두에서 성능이 향상되는 명확한 스케일링 경향이 관찰된다.
Figure 1은 s1-32B 모델이 테스트 타임 연산량을 증가시킬수록 추론 집약적 태스크에서 성능이 일관되게 향상됨을 보여주는 핵심적인 실험 결과이다. 가로축은 모델이 생성하는 사고 토큰(thinking tokens)의 수로 측정되는 테스트 타임 연산량을 나타내며, 세로축은 각 벤치마크에서의 정확도를 나타낸다. AIME24, MATH500, GPQA Diamond 세 가지 벤치마크 모두에서 사고 토큰 수가 증가함에 따라 성능이 단조적으로 향상되는 경향이 관찰되는데, 이는 OpenAI가 o1 모델에서 보여준 테스트 타임 스케일링 곡선의 특성을 공개된 방법론으로 처음으로 재현한 것이다. 특히 주목할 만한 점은 이러한 스케일링 행동이 단 1,000개의 샘플로 미세조정된 모델에서 관찰된다는 사실이며, 이는 대규모 강화학습이나 수백만 개의 훈련 샘플 없이도 테스트 타임 스케일링이 가능함을 시사하는 중요한 발견이다.
본 논문의 기여를 정리하면 다음과 같다:
- 샘플 효율적인 추론 데이터셋 구축 방법론: 품질-난이도-다양성 기반의 체계적 큐레이션으로 1,000개의 최적 샘플 선정
- Budget forcing 기법 제안: 단순하면서도 효과적인 테스트 타임 스케일링 기법과 이를 평가하기 위한 정량적 메트릭 체계(Control, Scaling, Performance) 수립
- s1-32B 모델 구축: 두 구성요소를 결합하여 o1-preview와 경쟁 가능한 성능의 완전 공개 모델 구축, 광범위한 어블레이션 실험으로 각 설계 결정의 타당성 검증
- 완전 공개: 모델 가중치, 훈련 데이터(s1K), 코드가 모두 GitHub에서 공개되어 연구의 재현 가능성 보장
2. 배경: 테스트 타임 스케일링 패러다임의 등장
2.1 훈련 시간 스케일링의 한계와 새로운 패러다임
언어 모델의 성능을 향상시키기 위한 전통적인 접근법은 모델 크기를 키우거나, 더 많은 데이터로 더 오래 훈련하거나, 혹은 훈련 알고리즘 자체를 개선하는 것이었다. 이러한 접근법들은 모두 훈련 시간(train-time)에 더 많은 자원을 투입하는 방식이며, 일단 훈련이 완료된 후의 추론 단계에서는 고정된 양의 연산만을 사용한다. 표준적인 언어 모델은 주어진 입력에 대해 하나의 순방향 패스(forward pass) 또는 자기회귀적(autoregressive) 토큰 생성을 수행하며, 문제의 난이도와 무관하게 본질적으로 유사한 양의 연산을 소비한다.
이는 인간의 사고 방식과 극명한 대조를 이루는데, 인간은 어려운 문제에 직면하면 더 오래 생각하고, 여러 접근법을 시도하며, 자신의 답을 검증하는 과정을 거친다. 테스트 타임 스케일링은 이러한 한계를 극복하기 위한 패러다임으로, 추론 단계에서 추가적인 연산을 투입하여 모델의 출력 품질을 향상시키는 것을 목표로 한다.
2.2 테스트 타임 스케일링의 두 가지 범주
테스트 타임 스케일링의 방법론은 크게 두 가지 범주로 나눌 수 있다:
- 순차적 스케일링(sequential scaling): 모델이 하나의 긴 추론 체인(reasoning chain)을 생성하면서 중간 결과를 기반으로 후속 연산을 수행하는 방식이다. OpenAI o1이 채택한 것으로 추정되는 접근법이 이에 해당하며, 모델이 내부적으로 긴 사고 과정(chain of thought)을 생성하고 이를 통해 답에 도달하는 구조이다.
- 병렬 스케일링(parallel scaling): 동일한 문제에 대해 여러 독립적인 답변을 생성한 후 다수결 투표(majority voting)나 보상 모델(reward model) 기반 선택을 통해 최종 답을 결정하는 방식이다.
2.3 선행 연구: o1 이전과 이후
o1 이전에도 테스트 타임에 추가적인 연산을 활용하여 성능을 향상시키려는 다양한 시도가 있었다. Chain-of-Thought(CoT) 프롬프팅(Wei et al., 2023)은 모델에게 "단계별로 생각하라(Let's think step by step)"는 간단한 지시를 추가함으로써 추론 성능을 크게 향상시킬 수 있음을 보여준 선구적 연구이다. Self-Consistency(Wang et al., 2023)는 다수의 독립적인 CoT를 생성하고 다수결 투표로 최종 답을 결정하는 병렬적 접근법이며, Tree-of-Thought(Yao et al., 2023a)는 탐색 트리 구조를 활용하여 여러 추론 경로를 체계적으로 탐색하는 방법이다.
OpenAI o1의 등장 이후, 다양한 o1 재현 시도가 이루어졌으나 대부분 대규모 데이터와 복잡한 학습 파이프라인을 필요로 하였다. 주요 재현 시도들을 정리하면 다음과 같다:
- MCTS 기반 접근(Gao et al., 2024b; Zhang et al., 2024a): Monte Carlo Tree Search를 활용하여 추론 경로를 탐색하는 방식으로, 명확한 테스트 타임 스케일링 곡선을 재현하지는 못하였다.
- 다중 에이전트 방식(Qin et al., 2024): 여러 에이전트의 협업을 통한 추론 향상을 시도하였으나, 역시 체계적인 스케일링 행동을 달성하지 못하였다.
- DeepSeek R1(DeepSeek-AI et al., 2025): 강화학습을 통해 수백만 개의 샘플과 다단계 훈련을 거쳐 o1 수준의 성능을 성공적으로 복제하였으나, 막대한 데이터와 연산 자원을 필요로 하였다.
본 논문은 이러한 배경 속에서 등장하였다. 저자들의 핵심 가설은 현대의 대규모 사전 훈련 모델이 이미 수조(trillion) 단위의 토큰으로 훈련되어 있어 추론 능력의 기초가 이미 모델 내부에 인코딩되어 있다는 것이다. 이 관점에서 소수의 고품질 추론 샘플을 통한 미세조정은 사전 훈련 과정에서 이미 형성된 잠재적 추론 능력을 "활성화(activate)"하는 역할을 하며, 테스트 타임 스케일링 기법은 이 활성화된 능력을 추론 시점에서 최대한 활용하는 수단으로 기능한다. 이는 LIMA(Zhou et al., 2023)에서 제시된 "Superficial Alignment Hypothesis", 즉 1,000개의 예시만으로도 모델을 사용자 선호에 맞게 정렬할 수 있다는 가설과 맥을 같이한다.
3. 추론 데이터 큐레이션: s1K 데이터셋 구축
3.1 초기 59K 샘플 수집
s1K 데이터셋의 구축은 광범위한 초기 데이터 풀(data pool)의 수집에서 시작된다. 저자들은 16개의 서로 다른 출처로부터 총 59,029개의 질문을 수집하였으며, 이 과정에서 세 가지 핵심 원칙을 일관되게 적용하였다:
- 품질(Quality): 수집 대상 데이터셋이 고품질이어야 하며 포맷팅 오류나 품질 저하가 관찰되는 데이터셋은 배제
- 난이도(Difficulty): 수집 대상 문제들이 상당한 추론 노력을 요구하는 도전적인 문제여야 함
- 다양성(Diversity): 다양한 분야의 데이터셋을 포함하여 서로 다른 유형의 추론 태스크를 커버
이 세 가지 원칙은 단순히 초기 수집 단계에서뿐만 아니라 후속 필터링 단계에서도 핵심 기준으로 작용하며, 최종 1,000개 샘플의 선정까지 일관된 설계 철학을 관통한다.
3.2 기존 데이터셋 큐레이션
기존 데이터셋의 큐레이션 과정에서 가장 큰 비중을 차지하는 출처는 NuminaMATH(LI et al., 2024)로, 온라인 웹사이트에서 수집된 30,660개의 수학 문제를 포함한다. 여기에 1983년부터 2021년까지의 역대 AIME 문제가 추가되어 수학 분야의 기초를 형성한다. 주요 데이터 소스의 구성을 정리하면 다음과 같다:
- NuminaMATH: 온라인 수학 문제 30,660개 — 전체 풀의 약 52%를 차지하여 수학 추론의 중심축 형성
- OlympicArena(Huang et al., 2024a): 천문학, 생물학, 화학, 컴퓨터 과학, 지리학, 수학, 물리학 등 다양한 올림피아드 분야의 4,250개 문제
- OmniMath(Gao et al., 2024a): 경시대회 수준의 수학 문제 4,238개
- AGIEval(Zhong et al., 2023): SAT, LSAT 등 표준화된 시험에서 출제된 영어, 법학, 논리학 관련 2,385개 문제
- 기타 추가 출처를 포함하여 총 16개 데이터 소스로 최종 풀 구성
3.3 독자적 데이터셋 구축
기존 데이터셋의 수집에 더하여, 저자들은 정량적 추론(quantitative reasoning) 분야의 두 가지 독자적인 데이터셋을 새롭게 구축하였다.
첫 번째는 s1-prob 데이터셋으로, Stanford University 통계학과 박사 자격시험(PhD Qualifying Exam)의 확률 섹션에서 추출한 182개의 문제로 구성된다. 이 시험은 매년 실시되며 전문가 수준의 수학적 문제 해결 능력을 요구하는데, 어려운 증명 문제들이 포함되어 있어 데이터셋의 난이도를 크게 끌어올리는 역할을 한다. 박사 자격시험 수준의 확률론 문제는 대부분의 공개 데이터셋에서 거의 다루어지지 않는 영역이므로, 이 데이터셋은 기존 공개 데이터의 공백을 보완하는 의미가 있다.
두 번째는 s1-teasers 데이터셋으로, 퀀트 트레이딩(quantitative trading) 포지션 인터뷰에서 흔히 사용되는 23개의 고난이도 두뇌 퍼즐(brain teaser) 문제를 PuzzledQuant 웹사이트에서 수집한 것이다. "Hard" 난이도에 해당하는 문제만을 선별하여 포함하였으며, 수학적 지식뿐만 아니라 창의적인 문제 해결 능력과 패턴 인식 능력을 요구하는 문제들로, 전통적인 수학 경시대회 문제와는 다른 유형의 추론 능력을 평가한다.
3.4 추론 트레이스 생성
수집된 모든 질문에 대해 Google Gemini Flash Thinking API(Google, 2024)를 사용하여 추론 트레이스(reasoning trace)와 솔루션을 생성하였다. 이 과정에서 Gemini 모델의 내부 추론 과정(thinking trace)과 최종 응답(response)을 모두 추출하여, 각 질문에 대해 "질문-추론 트레이스-솔루션"의 삼중 구조(triplet)를 형성하였다. Gemini Flash Thinking을 추론 트레이스 생성의 원천으로 선택한 이유는 해당 모델이 긴 사고 과정을 명시적으로 생성하는 능력을 갖추고 있어, 추론의 중간 단계를 포함한 풍부한 학습 신호를 제공하기 때문이다.
데이터 무결성을 보장하기 위해 저자들은 다음과 같은 전처리를 수행하였다:
- 디컨태미네이션(Decontamination): 평가 벤치마크(MATH500, GPQA Diamond, AIME24)에 대한 8-gram 기반 중복 검출을 수행하여 훈련 데이터와 평가 데이터 사이의 오염 방지
- 중복 제거(Deduplication): 동일하거나 거의 동일한 질문의 중복 포함 방지
3.5 최종 1,000개 샘플 선정: 3단계 체계적 필터링
59K개의 초기 풀에서 최종 1,000개의 샘플을 선정하는 과정은 세 단계의 체계적인 필터링을 통해 이루어진다. 저자들은 59K 전체를 훈련에 사용할 수도 있었으나, "가장 단순하고 최소한의 자원으로 강력한 성능을 달성한다"는 연구 목표에 따라 극도로 효율적인 데이터 선정 전략을 추구하였다.
1단계: 품질 기반 필터링
우선 Gemini API 호출 과정에서 오류가 발생한 샘플을 제거하여 데이터셋을 54,116개로 축소한다. 다음으로 ASCII 아트 다이어그램, 존재하지 않는 이미지 참조, 불일치하는 문제 번호 매김 등 포맷팅 문제가 있는 저품질 예시를 문자열 패턴 매칭을 통해 필터링하여 51,581개로 줄인다. 이 풀에서 저자들이 추가 필터링 없이도 충분히 고품질이라고 판단하는 데이터셋의 샘플 384개를 최종 1,000개에 직접 포함시킨다.
2단계: 난이도 기반 필터링
저자들은 문제의 난이도를 측정하기 위해 두 가지 보완적인 지표를 활용한다:
- 모델 기반 성능 평가: Qwen2.5-7B-Instruct와 Qwen2.5-32B-Instruct 두 모델로 각 질문을 평가하고, Claude 3.5 Sonnet이 정답 여부를 판정한다. 두 모델 중 어느 하나라도 정답을 맞힌 문제는 "너무 쉬운" 문제로 간주하여 제거한다. 두 모델을 동시에 사용하는 이유는 한 모델이 쉬운 문제에서 우연히 오답을 제출하여 필터를 통과하는 경우를 방지하기 위함이다.
- 추론 트레이스의 토큰 길이: 더 어려운 문제일수록 더 많은 사고 토큰이 필요하다는 합리적 가정에 기초한다. Qwen2.5 토크나이저로 토큰 수를 측정한다.
이 난이도 필터링을 통해 데이터셋은 24,496개로 축소된다.
3단계: 다양성 기반 샘플링
다양성을 정량화하기 위해 저자들은 Claude 3.5 Sonnet을 사용하여 각 질문을 미국수학회(AMS)의 수학 주제 분류(Mathematics Subject Classification, MSC) 체계에 따라 도메인으로 분류한다. 최종 샘플 선정은 다음과 같은 반복적 과정으로 이루어진다:
- 하나의 도메인을 균등 분포(uniform distribution)에서 무작위로 선택
- 그 도메인 내에서 더 긴 추론 트레이스를 선호하는 분포에 따라 하나의 문제를 샘플링
- 1,000개의 샘플이 모일 때까지 반복
최종 데이터셋은 50개의 서로 다른 도메인에 걸쳐 있다. 이러한 도메인 균등 샘플링 전략은 특정 분야에 편중되지 않은 균형 잡힌 데이터셋을 생성하는 동시에, 각 도메인 내에서는 난이도가 높은 문제를 우선적으로 선택하여 난이도와 다양성을 동시에 확보한다.
3.6 오류 포함 데이터에 대한 관용적 접근
흥미로운 점은 s1K에 포함된 추론 트레이스 중 상당수가 잘못된 답을 포함하고 있다는 사실이다. 저자들의 자동 채점기에 따르면 s1K 내 추론 트레이스의 53.6%만이 정답으로 판정되었으며, 후속 버전인 s1K-1.1에서도 63.0%에 머물렀다. 그럼에도 저자들은 이러한 오류 포함 데이터를 의도적으로 허용하였는데, 그 이유는 최종 정답의 정확성보다는 추론 과정(reasoning process) 자체를 포착하는 것이 더 중요하다고 판단했기 때문이다. 이는 모델이 올바른 추론 패턴을 학습하는 데 있어 정답 여부보다 사고 과정의 구조적 특성이 더 핵심적인 학습 신호를 제공한다는 실용적 관점을 반영한다.

Figure 2: s1K 데이터셋과 s1-32B 모델. (좌) s1K는 고품질, 다양성, 높은 난이도를 갖춘 1,000개의 질문과 추론 트레이스로 구성된 데이터셋이다. (우) s1K로 미세조정된 32B 파라미터 모델인 s1-32B는 샘플 효율성 프론티어(sample-efficiency frontier)에 위치한다.
Figure 2의 좌측 그래프는 s1K의 도메인 분포를 나타내며, 50개의 서로 다른 수학적 주제 분류에 걸쳐 데이터가 분포되어 있음을 확인할 수 있다. 우측 그래프는 훈련에 사용된 예시 수(x축)와 모델 성능(y축)의 관계를 보여주는데, s1-32B는 단 1,000개의 샘플만을 사용하면서도 17,000개 이상의 샘플을 사용한 Sky-T1이나 Bespoke-32B를 상회하는 성능을 보여주어 샘플 효율성 프론티어에 위치한다. 이는 데이터의 양보다 데이터의 질과 선정 전략이 추론 성능에 더 결정적인 영향을 미친다는 본 논문의 핵심 주장을 뒷받침하는 강력한 실증적 근거이다.
4. 테스트 타임 스케일링 방법론
4.1 순차적 스케일링 vs 병렬 스케일링
저자들은 테스트 타임 스케일링 방법을 순차적 스케일링과 병렬 스케일링이라는 두 가지 범주로 분류한다. 순차적 스케일링은 이전 연산의 결과에 후속 연산이 의존하는 구조로, 긴 추론 트레이스를 생성하는 것이 대표적이다. 모델이 이전 단계에서 도출한 중간 결과를 바탕으로 다음 단계의 추론을 수행하므로 더 깊은 사고와 반복적 개선(iterative refinement)이 가능하다. 병렬 스케일링은 여러 연산이 독립적으로 실행되는 구조로, 다수결 투표가 대표적이다.
저자들은 순차적 스케일링이 직관적으로 더 우수해야 한다고 주장한다. 그 근거는 후속 연산이 중간 결과를 활용할 수 있어 더 깊은 수준의 추론과 자기 수정(self-correction)이 가능하기 때문이다. 이 직관은 이후 실험에서 실증적으로 확인된다.
4.2 Budget Forcing: 사고 과정의 강제 제어
Budget forcing은 본 논문이 제안하는 핵심적인 테스트 타임 스케일링 기법으로, 모델의 사고 토큰 생성을 디코딩 시점에서 직접 개입하여 제어하는 방식이다. 이 방법은 두 가지 상보적인 메커니즘으로 구성된다:
메커니즘 1: 사고 과정의 조기 종료(상한 제어)
모델이 미리 설정된 최대 사고 토큰 수를 초과하면 사고 종료 토큰 구분자(end-of-thinking token delimiter)를 강제로 추가하고, 선택적으로 "Final Answer:"라는 문자열을 덧붙여 모델이 현재까지의 최선의 답변을 제시하도록 유도한다. 이는 모델이 무한 루프에 빠지거나 과도하게 긴 사고를 생성하는 것을 방지하는 상한(upper bound) 제어 역할을 한다.
메커니즘 2: 사고 과정의 연장(하한 제어)
모델이 사고 종료 토큰 구분자를 생성하려 할 때 이를 억제(suppress)하고 대신 "Wait"이라는 문자열을 현재 추론 트레이스에 추가하는 것이다. 이 간단한 개입은 모델이 자신의 현재 생성 결과를 재검토(reflect)하도록 유도하며, 종종 잘못된 추론 단계를 발견하고 수정하는 자기 수정 행동(self-correction behavior)으로 이어진다. "Wait"이라는 단어가 갖는 암시적 의미가 모델로 하여금 "잠깐, 다시 생각해보자"라는 맥락을 형성하게 하여, 기존 답변에 대한 검증과 대안적 접근의 탐색을 촉진한다.

Figure 3: s1-32B에서의 budget forcing 동작 예시. 모델이 "…is 2."라는 답을 내놓고 사고를 종료하려 하지만, 사고 종료 토큰 구분자를 억제하고 대신 "Wait"을 추가한다. 이로 인해 s1-32B는 자신의 답을 재검토하고 올바른 답으로 자기 수정(self-correct)하게 된다.
Figure 3은 budget forcing의 실제 동작을 구체적인 예시를 통해 보여준다. 모델은 처음에 잘못된 답인 "2"를 도출하고 사고를 종료하려 한다. 그러나 budget forcing이 사고 종료 토큰의 생성을 억제하고 "Wait"을 추가함으로써, 모델은 자신의 답변을 되돌아보고 추론 과정에서의 오류를 발견하여 올바른 답으로 수정하게 된다. 이 과정은 추가적인 학습이나 보상 모델 없이 순전히 디코딩 시점의 개입만으로 이루어진다는 점에서 매우 경제적이다. 더욱 주목할 점은 이러한 자기 수정이 단순히 답의 수치를 변경하는 것을 넘어, 추론 과정 자체의 오류를 발견하고 대안적인 풀이 경로를 탐색하는 깊은 수준의 반성(reflection)을 포함한다는 것이다.
Budget forcing의 구현 단순성도 중요한 특징이다. 기존의 자기회귀적 디코딩 파이프라인에 최소한의 수정만으로 통합될 수 있으며, 구체적으로 다음 세 가지 조건부 로직만으로 전체 메커니즘이 구현된다:
- 사고 종료 토큰의 감지
- 해당 토큰의 억제 또는 강제 삽입
- "Wait" 문자열의 추가
보상 모델(reward model)의 훈련, 탐색 트리의 구축, 혹은 다수의 병렬 생성과 같은 추가적인 인프라가 전혀 불필요하다는 점이 budget forcing의 핵심적인 실용적 장점이다.
4.3 베이스라인 방법론
Budget forcing의 효과를 비교 평가하기 위해, 저자들은 다양한 베이스라인 테스트 타임 스케일링 방법을 실험한다. 이 베이스라인은 크게 두 범주로 나뉜다:
범주 1: 조건부 길이 제어(Conditional Length-Control)
프롬프트를 통해 모델에게 사고 길이를 제어하도록 지시하는 방식으로, 세부 입자도(granularity)에 따라 세 가지로 나뉜다:
- 토큰 조건부 제어(Token-Conditional Control, TCC): 프롬프트에 사고 토큰의 상한을 명시적으로 지정
- 단계 조건부 제어(Step-Conditional Control, SCC): 사고 단계의 상한을 지정, 각 단계는 약 100토큰 규모
- 클래스 조건부 제어(Class-Conditional Control, CCC): 모델에게 짧게 또는 길게 생각하라는 일반적인 프롬프트 제공
범주 2: 거부 샘플링(Rejection Sampling, RS)
미리 정해진 연산 예산에 맞는 생성이 나올 때까지 반복적으로 샘플링하는 방식이다. 이는 생성 길이에 조건화된 응답의 사후 분포(posterior distribution)를 포착하는 오라클(oracle) 역할을 한다.
4.4 테스트 타임 스케일링 평가 메트릭
저자들은 테스트 타임 스케일링 방법을 비교하기 위한 세 가지 정량적 메트릭을 수립한다. 각 방법에 대해 일련의 평가 실행 집합 $\mathcal{A}$를 정의하고, 테스트 타임 연산량을 변화시키면서 고정된 벤치마크에서의 성능을 측정하여 연산량(사고 토큰 수, x축)과 정확도(y축)로 이루어진 구간 선형 함수 $f$를 생성한다.
메트릭 1: Control (제어)
$$\text{Control} = \frac{1}{|\mathcal{A}|} \sum_{a \in \mathcal{A}} \mathbb{I}(a_{\text{min}} \leq a \leq a_{\text{max}})$$
지정된 최소-최대 연산량 범위 내에서 실제 생성된 토큰 수가 해당 범위를 준수하는 비율을 측정한다. 0%에서 100% 사이의 값을 가지며, 100%는 완벽한 제어를 의미한다. Budget forcing은 사고 종료 토큰의 강제 삽입이나 억제를 통해 100%의 제어를 달성한다.
메트릭 2: Scaling (스케일링)
$$\text{Scaling} = \frac{1}{\binom{|\mathcal{A}|}{2}} \sum_{\substack{a, b \in \mathcal{A} \\ b > a}} \frac{f(b) - f(a)}{b - a}$$
구간 선형 함수의 평균 기울기(average slope)를 측정한다. 이 값이 양수(positive)여야 유용한 방법이며, 값이 클수록 연산량 증가 대비 성능 향상이 크다는 것을 의미한다.
메트릭 3: Performance (성능)
$$\text{Performance} = \max_{a \in \mathcal{A}} f(a)$$
해당 방법이 벤치마크에서 달성하는 최대 정확도를 나타낸다. 이론적으로 단조 증가하는 스케일링을 보이는 방법은 충분한 연산량이 주어지면 어떤 벤치마크에서든 100%에 도달할 수 있지만, 실제로는 제어 한계나 컨텍스트 윈도우(context window) 제약으로 인해 성능이 평탄해지게 된다.
5. 실험 설정
5.1 훈련 설정
기반 모델로 Qwen2.5-32B-Instruct가 선택되었다. 논문은 이 선택에 대한 명시적 이유를 서술하지 않으나, 몇 가지 합리적 추론이 가능하다. 32B 규모의 모델은 충분한 용량을 갖추면서도 단일 노드의 GPU 클러스터에서 효율적으로 미세조정이 가능한 실용적 크기이며, Qwen2.5 시리즈는 수학적 추론에서 동급 대비 강력한 기본 성능을 보여주는 것으로 알려져 있다. 또한 이미 인스트럭션 튜닝을 거친 모델이므로, 추론 능력의 향상에 집중할 수 있다.
훈련의 핵심 사양은 다음과 같다:
| 항목 | 설정 |
|---|---|
| 기반 모델 | Qwen2.5-32B-Instruct |
| 훈련 방법 | 지도 미세조정(SFT, next-token prediction) |
| 훈련 데이터 | s1K (1,000개 샘플) |
| GPU | 16 × NVIDIA H100 |
| 분산 훈련 | PyTorch FSDP (Fully Sharded Data Parallelism) |
| 훈련 시간 | 26분 (= 7 H100 GPU 시간) |
| 강화학습/DPO | 사용하지 않음 |
특히 주목할 점은 강화학습이나 DPO(Direct Preference Optimization) 같은 선호도 최적화 기법을 전혀 사용하지 않고, 순수한 지도 학습(next-token prediction)만으로 추론 능력의 활성화가 이루어진다는 것이다. 이는 기존의 o1 재현 시도들이 대부분 강화학습을 핵심 구성요소로 포함하는 것과 대조되는 설계 결정이며, "최소한의 접근법"이라는 연구 목표와 일치한다. 59K 전체 데이터셋을 사용한 훈련이 394 H100 GPU 시간을 요구하는 것과 비교하면 약 56배 효율적이다.
5.2 평가 벤치마크
모델의 추론 성능을 평가하기 위해 세 가지 대표적인 벤치마크가 선정되었다:
- AIME24 (American Invitational Mathematics Examination 2024): 2024년 1~2월에 실시된 미국 수학 초청 경시대회의 30개 문제. 산술, 대수, 조합, 기하, 정수론, 확률 등 중등 수학의 다양한 주제를 아우르며, 모든 답은 000~999 사이의 정수이다. 일부 도형 의존 문제는 Asymptote 벡터 그래픽 언어로 기술하여 제공하였다.
- MATH500 (Hendrycks et al., 2021): 다양한 난이도의 경시대회 수학 문제로 구성되며, OpenAI의 선행 연구(Lightman et al., 2023)에서 선정한 동일한 500개 샘플에 대해 평가를 수행한다.
- GPQA Diamond (Rein et al., 2023): 생물학, 화학, 물리학 분야의 198개 박사급 과학 질문. 해당 분야의 박사 학위 보유 전문가들조차 69.7%의 정답률만을 달성할 정도로 매우 높은 난이도를 지닌다.
모든 평가는 lm-evaluation-harness 프레임워크(Gao et al., 2021; Biderman et al., 2024)를 기반으로 수행되며, 별도의 명시가 없는 한 온도(temperature) 0의 그리디(greedy) 디코딩을 사용하여 정확도(pass@1)를 측정한다.
5.3 비교 모델
s1-32B의 성능을 맥락화하기 위해 다양한 범주의 비교 모델이 벤치마크된다:
| 범주 | 모델 | 특징 |
|---|---|---|
| API 전용 (비공개) | OpenAI o1 시리즈 | 테스트 타임 스케일링을 대중화한 모델 |
| Gemini 2.0 Flash Thinking | s1-32B의 증류 원천 API | |
| 공개 가중치 | DeepSeek-r1 | 대규모 RL로 o1 수준 달성, ≫800K 샘플 |
| DeepSeek-r1-distill-32B | r1로부터 800K 샘플 증류 | |
| QwQ-32B-preview | 방법론 비공개 32B 추론 모델 | |
| 공개 가중치 + 공개 데이터 | Sky-T1-32B-Preview | 17K 증류 데이터로 훈련 |
| Bespoke-32B | 17K 증류 데이터로 훈련 |
Gemini 2.0 Flash Thinking의 경우, API의 "recitation error" 문제로 인해 자동화된 평가가 어려웠으며, 저자들은 30개의 AIME24 문제를 수동으로 웹 인터페이스에 입력하여 평가하였다. MATH500(500문제)과 GPQA Diamond(198문제)는 문제 수가 많아 수동 평가가 비현실적이었으므로 해당 벤치마크에서의 점수는 N.A.로 보고된다.
6. 주요 결과
6.1 모델 성능 비교
아래 표는 s1-32B를 다양한 추론 모델과 비교한 주요 성능 결과를 정리한 것이다. "# ex."는 추론 미세조정에 사용된 예시 수를, "BF"는 budget forcing의 적용 여부를 의미한다.
| 모델 | # ex. | AIME 2024 | MATH 500 | GPQA Diamond |
|---|---|---|---|---|
| API 전용 (비공개) | ||||
| o1-preview | N.A. | 44.6 | 85.5 | 73.3 |
| o1-mini | N.A. | 70.0 | 90.0 | 60.0 |
| o1 | N.A. | 74.4 | 94.8 | 77.3 |
| Gemini 2.0 Flash Thinking | N.A. | 60.0 | N.A. | N.A. |
| 공개 가중치 (Open Weights) | ||||
| Qwen2.5-32B-Instruct | N.A. | 26.7 | 84.0 | 49.0 |
| QwQ-32B-preview | N.A. | 50.0 | 90.6 | 54.5 |
| DeepSeek-r1 | ≫800K | 79.8 | 97.3 | 71.5 |
| DeepSeek-r1-distill-32B | 800K | 72.6 | 94.3 | 62.1 |
| 공개 가중치 + 공개 데이터 | ||||
| Sky-T1-32B-Preview | 17K | 43.3 | 82.4 | 56.8 |
| Bespoke-32B | 17K | 63.3 | 93.0 | 58.1 |
| s1-32B (BF 미적용) | 1K | 50.0 | 92.6 | 56.6 |
| s1-32B (BF 적용) | 1K | 56.7 | 93.0 | 59.6 |
이 결과에서 여러 가지 주목할 만한 발견이 드러난다.
첫째, o1-preview를 상회하는 수학 추론 성능. s1-32B(budget forcing 적용)는 AIME24에서 56.7%를 달성하여 o1-preview의 44.6%를 12.1%포인트 상회하며, 이는 비율로 환산하면 약 27%의 성능 향상에 해당한다. MATH500에서도 93.0%로 o1-preview의 85.5%를 7.5%포인트 상회한다. 다만 GPQA Diamond에서는 59.6%로 o1-preview의 73.3%에 미치지 못하는데, 이는 과학적 추론 영역에서 SFT만으로는 달성하기 어려운 수준의 도메인 지식이 필요함을 암시한다.
둘째, budget forcing의 명확한 효과. Budget forcing을 적용하지 않은 s1-32B(50.0%)와 적용한 s1-32B(56.7%) 사이에 AIME24에서 6.7%포인트의 향상이 이루어진다. GPQA Diamond에서도 3.0%포인트의 개선이 관찰된다. 이 향상은 추가적인 훈련이나 데이터 없이 순전히 테스트 타임 개입만으로 달성된다.
셋째, 독보적인 샘플 효율성. 동일하게 공개 데이터를 사용하는 Sky-T1과 Bespoke-32B는 17K개의 훈련 샘플을 사용하는데, s1-32B는 그 17분의 1에 불과한 1K 샘플만으로 이들과 경쟁하거나 상회하는 성능을 보여준다. DeepSeek-r1-distill-32B는 800K 샘플, 즉 s1-32B의 800배에 달하는 데이터로 훈련되었음에도, AIME24에서의 격차는 15.9%포인트에 머문다.
넷째, 증류 원천 모델과의 비교. Gemini 2.0 Flash Thinking이 AIME24에서 60.0%를 달성한 반면 s1-32B(BF 적용)는 56.7%로, 원천 모델 성능의 약 94.5%를 보존하고 있다. 이는 1,000개의 샘플만을 통한 증류로도 교사 모델의 추론 능력을 상당 부분 전이할 수 있음을 시사하는 고무적인 결과이다.
다만 o1이나 DeepSeek-r1과 같이 대규모 강화학습을 거친 최상위 모델들과의 격차는 여전히 존재한다. o1은 GPQA Diamond에서 77.3%, DeepSeek-r1은 AIME24에서 79.8%, MATH500에서 97.3%를 달성하여 s1-32B와의 격차가 적지 않으며, 이는 대규모 RL 훈련이 추론 능력의 상한(ceiling)을 크게 끌어올릴 수 있음을 보여준다.
6.2 테스트 타임 스케일링 성능

Figure 4(a): Budget forcing을 통한 순차적 테스트 타임 스케일링. Budget forcing은 명확한 스케일링 경향을 보이며 어느 정도까지 외삽(extrapolation)이 가능하다. 가장 오른쪽 세 점에서는 모델의 사고 종료를 각각 2회, 4회, 6회 방지하고 매번 "Wait"을 추가하였다.
Figure 4(a)는 AIME24에서 budget forcing을 통한 순차적 스케일링의 상세한 결과를 보여준다. 기본적인 사고 토큰 예산에서 시작하여, 모델의 사고 종료를 2회, 4회, 6회 방지하면서 각 시점에 "Wait"을 추가하는 방식으로 테스트 타임 연산량을 점진적으로 증가시켰다. 그 결과 성능이 50%에서 57%까지 향상되는 명확한 양의 스케일링 경향이 관찰되었다. 이는 budget forcing이 단순히 모델의 기존 답변을 검증하는 것을 넘어, 더 많은 사고 시간이 주어졌을 때 새로운 접근법을 탐색하고 더 나은 답에 도달할 수 있게 해줌을 의미한다.
그러나 사고 종료 억제를 6회 이상으로 늘리면 성능이 평탄해지기 시작하는데, 이는 사고 종료 토큰을 너무 자주 억제하면 모델이 반복적인 루프에 빠져 실질적인 추론 진전 없이 같은 내용을 되풀이하는 현상이 발생하기 때문이라고 논문은 서술한다.

Figure 4(b): 다수결 투표를 통한 병렬 테스트 타임 스케일링. Qwen2.5-32B-Instruct에 대해 온도 1로 각 샘플당 64회의 평가를 수행하고, 2, 4, 8, 16, 32, 64개의 샘플에 대한 다수결 투표 성능을 시각화하였다.
Figure 4(b)는 병렬 스케일링 접근법인 다수결 투표의 결과를 보여준다. Qwen2.5-32B-Instruct 기반 모델에서 온도 1로 각 문제당 64개의 응답을 생성하고, 다수결 투표 성능을 측정하였다. 핵심적인 비교 결과는 다음과 같다:
- 병렬 스케일링: 샘플 수를 2개에서 64개까지 늘려도 성능 향상 속도가 순차적 스케일링에 비해 현저히 느림
- 64개의 샘플을 사용한 다수결 투표조차 s1-32B의 budget forcing 성능에 도달하지 못함
- 순차적 스케일링에서는 중간 결과를 기반으로 한 점진적 개선과 자기 수정이 가능하지만, 병렬 스케일링에서는 각 시도가 독립적이므로 이러한 누적적 학습 효과를 활용할 수 없음
이 결과는 동일한 양의 추가 테스트 타임 연산을 투입하더라도 순차적 스케일링이 병렬 스케일링보다 더 효율적으로 성능을 향상시킬 수 있다는 저자들의 직관을 실증적으로 확인해준다. 다만 병렬 스케일링이 순차적 스케일링의 한계에 도달한 후의 추가적인 성능 향상을 위한 보완적 방법으로 기능할 수 있다는 점도 간과해서는 안 되며, 두 접근법의 최적 결합은 향후 연구의 중요한 주제이다.
6.3 샘플 효율성 분석
s1-32B의 가장 두드러진 특성 중 하나는 극도의 샘플 효율성이다. 기반 모델인 Qwen2.5-32B-Instruct에 단 1,000개의 추가 샘플을 미세조정했을 뿐임에도 불구하고 성능 향상이 극적이다:
| 벤치마크 | Qwen2.5-32B-Instruct | s1-32B (BF) | 향상폭 |
|---|---|---|---|
| AIME24 | 26.7% | 56.7% | +30.0%p |
| MATH500 | 84.0% | 93.0% | +9.0%p |
| GPQA Diamond | 49.0% | 59.6% | +10.6%p |
이러한 대폭적인 성능 향상이 1,000개의 샘플만으로 이루어졌다는 사실은, 사전 훈련된 대규모 모델 내부에 이미 상당한 수준의 추론 능력이 잠재되어 있으며 소규모의 타겟된 미세조정이 이 잠재력을 "활성화"하는 역할을 한다는 가설을 강력히 뒷받침한다. 특히 AIME24에서 30.0%포인트의 향상은 1,000개의 샘플이 제공하는 학습 신호의 가치가 매우 높음을 보여주는데, 이는 단순한 지식 주입이 아니라 추론 형식(reasoning format)의 활성화로 해석되어야 한다.
7. 어블레이션 연구
7.1 데이터 큐레이션 원칙의 어블레이션
저자들은 s1K의 세 가지 핵심 큐레이션 원칙인 품질, 난이도, 다양성의 상대적 중요성을 검증하기 위해 체계적인 어블레이션 실험을 수행한다. 각 원칙을 개별적으로 적용한 변형 데이터셋과 전체 59K 데이터셋을 사용하여 모델을 훈련하고, 동일한 평가 조건에서 성능을 비교한다. 모든 모델에 budget forcing으로 약 30,000 사고 토큰의 상한을 적용하며, 95% 쌍대 부트스트랩 신뢰 구간을 10,000개의 부트스트랩 샘플로 추정하여 통계적 유의성을 검증한다.
| 모델 | AIME 2024 | MATH 500 | GPQA Diamond |
|---|---|---|---|
| 1K-random (품질만) | 36.7 | 90.6 | 52.0 |
| 1K-diverse (다양성만) | 26.7 | 91.2 | 54.6 |
| 1K-longest (난이도만) | 33.3 | 90.4 | 59.6 |
| 59K-full (전체 데이터) | 53.3 | 92.8 | 58.1 |
| s1K (품질+난이도+다양성) | 50.0 | 93.0 | 57.6 |
이 결과에서 도출되는 핵심 발견들을 분석한다.
품질만으로는 불충분하다 (1K-random). Gemini로부터 생성된 고품질 추론 체인에서 무작위로 1,000개를 선택한 1K-random은 AIME24에서 36.7%로 s1K의 50.0%에 비해 13.3%포인트 낮다. 95% 신뢰 구간이 [-26.7%, -3.3%]으로 전체 구간이 음수에 위치하여 성능 차이가 통계적으로 유의하다. 단순히 고품질 추론 체인을 수집하는 것만으로는 충분하지 않으며, 어떤 샘플을 선택하느냐가 최종 성능에 결정적인 영향을 미친다.
다양성만으로도 불충분하다 (1K-diverse). 도메인 간 균등 샘플링을 통해 다양성을 극대화하되 난이도를 고려하지 않은 1K-diverse는 AIME24에서 26.7%라는 가장 낮은 성능을 보여준다. 95% 신뢰 구간 [-40.0%, -10.0%]으로 매우 큰 성능 저하가 통계적으로 확인된다. 다양성만을 극대화하는 전략은 쉬운 문제를 다수 포함하게 되어 모델이 도전적인 추론 패턴을 충분히 학습하지 못하기 때문이다.
난이도만으로는 편향이 발생한다 (1K-longest). 추론 트레이스가 가장 긴 1,000개를 선택한 1K-longest는 GPQA Diamond에서 59.6%로 s1K의 57.6%를 상회하지만, AIME24에서는 33.3%로 상당히 낮다. 특정 도메인에서는 유리할 수 있으나, 전반적인 추론 능력 향상에는 다양성의 결합이 필수적임을 보여준다.
59배 더 많은 데이터도 유의한 차이를 만들지 못한다 (59K-full). 가장 흥미로운 비교 대상인 59K-full은 AIME24에서 53.3%로 s1K의 50.0%를 소폭 상회하지만, 95% 신뢰 구간이 [-13.3%, 20.0%]으로 0을 포함하여 통계적으로 유의한 차이라고 보기 어렵다. 59배 더 많은 데이터와 56배 더 많은 GPU 시간(394 vs 7 H100 GPU 시간)을 소비하더라도 유의한 성능 향상이 없다는 것이다. 이는 "신중한 데이터 선정이 데이터 양보다 중요하다"는 본 논문의 핵심 주장을 가장 직접적으로 뒷받침한다.
7.2 테스트 타임 스케일링 방법 비교
저자들은 앞서 정의한 세 가지 메트릭(Control, Scaling, Performance)을 사용하여 다양한 테스트 타임 스케일링 방법을 AIME24에서 체계적으로 비교한다.
| 방법 | Control | Scaling | Performance | |A| |
|---|---|---|---|---|
| Budget Forcing (BF) | 100% | 15 | 56.7 | 5 |
| TCC (토큰 조건부) | 40% | -24 | 40.0 | 5 |
| TCC + BF | 100% | 13 | 40.0 | 5 |
| SCC (단계 조건부) | 60% | 3 | 36.7 | 5 |
| SCC + BF | 100% | 6 | 36.7 | 5 |
| CCC (클래스 조건부) | 50% | 25 | 36.7 | 2 |
| RS (거부 샘플링) | 100% | -35 | 40.0 | 5 |
이 결과에서 budget forcing이 세 가지 메트릭 모두에서 균형 잡힌 최상의 성능을 달성함이 확인된다. 각 메트릭별로 분석하면 다음과 같다:
- Control: Budget forcing은 100%의 완벽한 제어를 달성하는데, 사고 종료 토큰의 강제 삽입이나 억제가 물리적으로 토큰 생성을 제어하기 때문이다. TCC는 40%, SCC는 60%에 머문다.
- Scaling: Budget forcing은 15의 양의 기울기를 보여 연산량 증가에 따라 성능이 일관되게 향상됨을 나타낸다. 반면 TCC(-24)와 RS(-35)는 역스케일링(inverse scaling)을 보여, 더 많은 연산을 투입할수록 오히려 성능이 하락한다.
- Performance: Budget forcing은 56.7%로 모든 방법 중 가장 높은 최대 성능을 달성하며, 두 번째로 높은 TCC와 RS의 40.0%와 16.7%포인트의 격차를 보인다.
조건부 제어 방법들에 대한 추가 분석에서 세 가지 주목할 만한 발견이 보고된다:
- 토큰 카운팅의 실패: 토큰 조건부 제어(TCC)는 budget forcing 없이는 실패하는데, 모델이 자신이 생성하는 토큰의 수를 실시간으로 추적하고 이에 기반하여 행동을 조절하는 능력이 근본적으로 부족하기 때문이다. 토큰 카운팅을 학습시켜도 이 문제가 해결되지 않았다.
- 단계 제어의 "해킹": 단계 조건부 제어(SCC)에서 모델은 다른 단계 목표를 부여받아도 유사한 총 토큰 수를 생성하는 경향을 보였다. 적은 단계가 목표이면 각 단계에 많은 토큰을 할당하고, 많은 단계가 목표이면 각 단계에 적은 토큰을 할당하는 방식으로 연산 제약을 우회하는 흥미로운 행동이 관찰되었다.
- 클래스 조건부 제어의 가능성: 단순히 "더 오래 생각하라"고 지시하는 것만으로도 테스트 타임 연산량과 성능이 증가할 수 있다는 것은 고무적이나, 제어 가능성(50%)과 최대 성능(36.7%)의 한계가 있다.
7.3 Budget Forcing 외삽 문자열 어블레이션
Budget forcing에서 사고 종료를 억제한 후 추가하는 문자열의 선택이 성능에 미치는 영향을 조사하기 위해, 사고 종료 구분자를 2회 무시하는 조건에서 다양한 문자열 옵션을 비교하는 어블레이션 실험을 수행하였다.
| 설정 | AIME 2024 | MATH 500 | GPQA Diamond |
|---|---|---|---|
| 외삽 없음 (기본) | 50.0 | 93.0 | 57.6 |
| 2회 억제, 문자열 없음 | 50.0 | 90.2 | 55.1 |
| 2회 "Alternatively" | 50.0 | 92.2 | 59.6 |
| 2회 "Hmm" | 50.0 | 93.0 | 59.6 |
| 2회 "Wait" | 53.3 | 93.0 | 59.6 |
이 결과에서 가장 주목할 만한 발견은 다음과 같다:
- 문자열 없이 억제만 하면 오히려 성능이 하락한다: MATH500에서 93.0%→90.2%, GPQA Diamond에서 57.6%→55.1%. 맥락 없는 연속 생성이 품질 저하를 초래함을 시사한다.
- "Wait"이 가장 효과적이다: AIME24에서 유일하게 53.3%로 3.3%포인트의 향상을 달성하면서 다른 벤치마크에서도 최고 수준을 유지한다.
- "Alternatively"와 "Hmm"은 GPQA Diamond에서 효과를 보이지만 AIME24에서는 변화가 없다.
"Wait"이 다른 문자열보다 우수한 이유에 대해 저자들은 이 단어가 모델에게 "잠깐, 다시 확인해보자"라는 자기 검증(self-verification)의 맥락을 가장 자연스럽게 형성하기 때문이라고 추론한다. 훈련 데이터에서 Gemini가 생성한 추론 트레이스에 유사한 자기 검증 패턴이 포함되어 있어, "Wait"이라는 단어가 해당 패턴을 활성화하는 트리거 역할을 할 수 있다는 것이다.
7.4 거부 샘플링의 역스케일링 현상
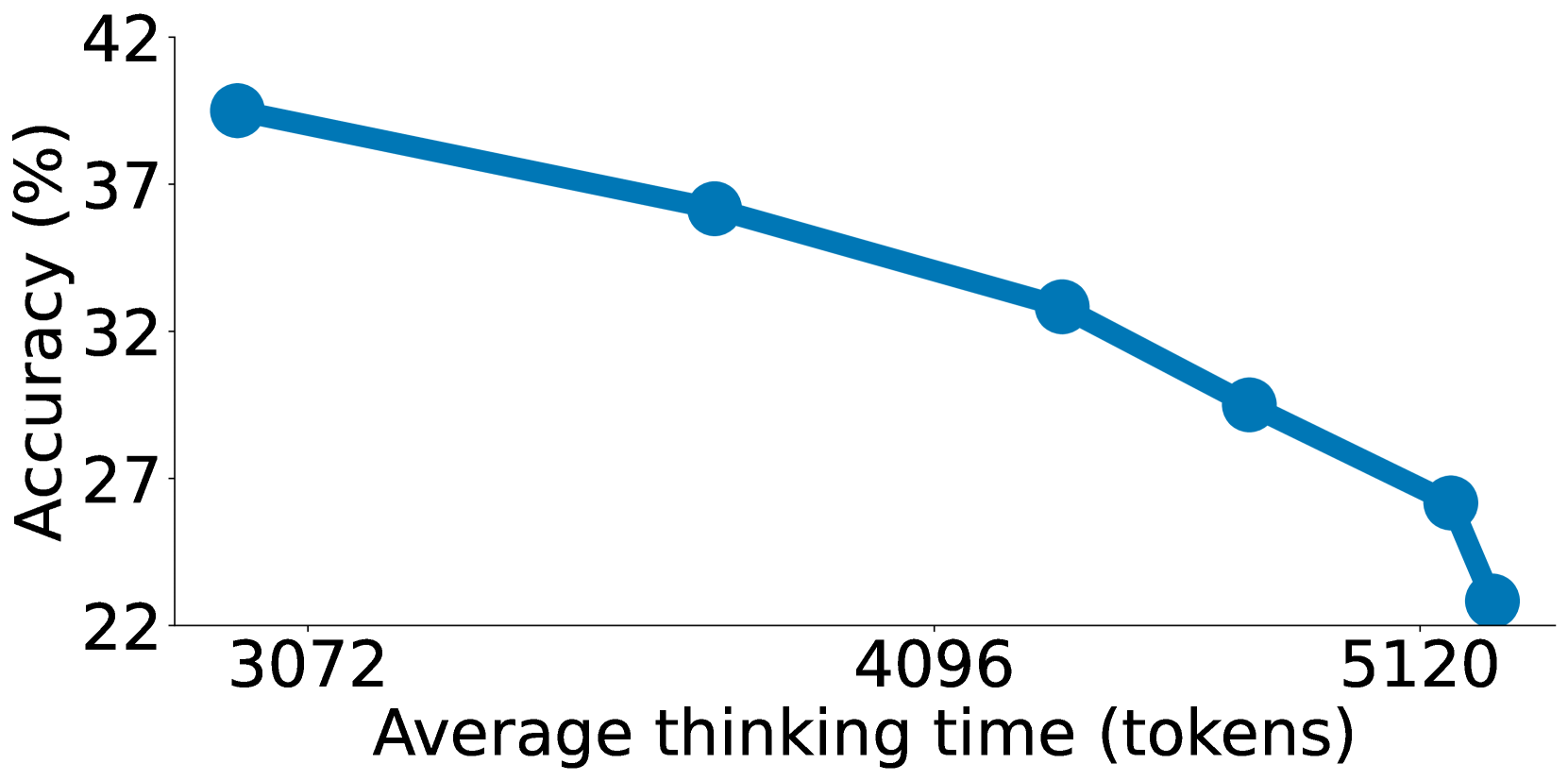
Figure 6: AIME24에서 s1-32B의 거부 샘플링 결과. 온도 1로 샘플링하여 모든 생성이 3,500, 4,000, 5,000, 8,000, 16,000 사고 토큰 이하가 될 때까지 반복하며, 평균적으로 각각 655, 97, 8, 3, 2, 1회의 시도가 필요하였다.
거부 샘플링(rejection sampling) 실험에서 발견된 가장 놀라운 결과는 역스케일링(inverse scaling) 현상이다. Figure 6은 이 현상을 명확히 보여주는데, 사고 토큰의 상한을 높일수록, 즉 더 긴 생성을 허용할수록 오히려 성능이 하락하는 경향이 관찰된다. 3,500 토큰 이하의 생성만을 선택하는 경우가 16,000 토큰 이하의 생성을 선택하는 경우보다 높은 정확도를 보여준다.
저자들은 이 현상에 대해 짧은 생성과 긴 생성 사이에 체계적인 상관관계가 존재한다는 가설을 제시한다:
- 짧은 생성: 모델이 처음부터 올바른 접근법을 취한 경우에 해당하는 경향이 있다. 문제를 정확하게 파악하고 적절한 풀이 전략을 즉시 채택하면 불필요한 탐색이나 역추적(backtracking) 없이 효율적으로 정답에 도달하므로 상대적으로 짧은 추론 트레이스가 생성된다.
- 긴 생성: 모델이 초기에 잘못된 접근을 취하여 반복적으로 역추적하고 자기 의심(self-questioning)을 하는 경우에 해당하는 경향이 있다. 잘못된 중간 단계가 축적되어 최종 답의 정확도가 오히려 낮아진다.
따라서 거부 샘플링으로 짧은 생성만을 선택하면 자연스럽게 "올바른 접근을 취한" 생성이 필터링되어 높은 정확도를 달성하게 된다. 이 발견은 "더 오래 생각한다고 반드시 더 나은 답을 얻는 것은 아니다"라는 중요한 교훈을 제공한다. 다만 이러한 역스케일링은 거부 샘플링이라는 특정 방법에서 관찰되는 현상이며, budget forcing에서는 관찰되지 않는다. Budget forcing은 모델의 기존 사고를 연장하여 자기 수정을 유도하는 반면, 거부 샘플링은 독립적인 새 생성을 반복하므로 두 방법의 동작 메커니즘이 근본적으로 다르기 때문이다.
8. 모델 출력 예시 분석
논문은 s1-32B가 실제로 어떻게 추론하는지를 보여주기 위해 AIME24, MATH500, GPQA Diamond 각 벤치마크에서 하나의 예시를 상세히 제시한다. 모델의 프롬프트(검은색 텍스트), 추론 트레이스(하늘색 텍스트), 최종 답변(파란색 텍스트)으로 구성되며, 세 문제 모두에서 모델이 올바른 답을 생성하였다.
8.1 AIME24 예시: 조합론 게임 이론 문제
AIME24 예시에서 s1-32B는 Alice와 Bob의 토큰 제거 게임에 대한 조합론 문제를 풀어야 한다. 모델의 추론 과정은 다음과 같은 구조화된 접근법을 따른다:
- 형식적 정의: Sprague-Grundy 정리를 활용하여 이기는 위치(winning position)와 지는 위치(losing position)를 체계적으로 분석
- 귀납적 패턴 발견: 작은 값의 $n$에서 시작하여 지는 위치 집합 $L = \{0, 2, 5, 7, 10, 12, \ldots\}$에서 연속항 간의 차이가 $2, 3, 2, 3, \ldots$으로 교대함을 발견
- 일반적 공식 도출: 지는 위치가 $5m$ 또는 $5m+2$ 형태임을 일반화
- 경우 분류를 통한 최종 계산: $1 \leq n \leq 2024$ 범위에서 이러한 형태의 수가 총 809개임을 정확히 계산
이러한 "구체적 사례에서 일반적 패턴으로, 그리고 최종 계산으로"라는 추론 흐름은 경시대회 수학에서 전문가들이 흔히 사용하는 문제 해결 전략과 일치하며, 모델이 s1K의 추론 트레이스로부터 이러한 고수준의 문제 해결 전략을 학습했음을 보여준다. 또한 모델이 중간 결과를 체크포인트처럼 활용하여 단계적으로 확신을 높여가는 패턴이 관찰되는데, 이는 budget forcing을 통한 자기 검증 유도가 효과적인 이유를 설명하는 데 도움이 된다. 모델은 먼저 소규모 사례를 열거하여 직관을 형성하고, 이를 수학적 명제로 정식화한 뒤, 체계적인 경우 분류를 통해 최종 답에 도달하는 과정에서 인간 전문가의 사고 흐름과 유사한 구조화된 접근을 보여준다.
8.2 MATH500 예시: 벡터 사영 문제
MATH500 예시에서는 벡터의 사영(projection) 문제가 제시되며, 모델은 사영 공식을 정확히 적용한다:
$$\text{proj}_\mathbf{b} \mathbf{a} = \frac{\mathbf{a} \cdot \mathbf{b}}{\|\mathbf{b}\|^2} \mathbf{b}$$
주어진 조건 $\mathbf{a} \cdot \mathbf{b} = 8$과 $\mathbf{b} = (2, 6, 3)$으로부터 $\|\mathbf{b}\|^2 = 49$를 계산하고, 스칼라 값 $8/49$를 벡터 $\mathbf{b}$의 각 성분에 곱하여 최종 답 $(16/49, 48/49, 24/49)$를 도출한다. 이 문제는 비교적 단순한 공식 적용이지만, 모델이 수학적 형식을 정확히 따르고 계산 오류 없이 최종 답에 도달한다는 점에서 추론 트레이스 학습의 효과가 확인된다.
8.3 GPQA Diamond 예시: 양자역학 에너지 스펙트럼
GPQA Diamond 예시는 양자역학의 2차원 포텐셜에서의 에너지 스펙트럼을 구하는 박사급 물리학 문제이다. 모델은 극좌표에서 주어진 포텐셜을 데카르트 좌표로 변환하고, 이것이 비등방 2차원 조화 진동자(anisotropic 2D harmonic oscillator)와 동치임을 인식하여 에너지 스펙트럼을 정확히 도출한다:
$$E = \hbar\sqrt{\frac{k}{m}}\left(2n_x + n_y + \frac{3}{2}\right)$$
이 문제에서 모델이 극좌표를 데카르트 좌표로 변환하고, 이를 비등방 조화 진동자 문제로 재정식화하는 과정은 상당한 물리학적 직관과 수학적 변환 능력을 요구하는데, s1-32B가 이를 정확하게 수행한다는 것은 모델이 단순한 패턴 매칭을 넘어 깊은 수준의 수리적 추론을 수행하고 있음을 시사한다. 세 예시는 s1-32B가 조합론, 선형대수, 양자역학 등 매우 다양한 분야에서 깊은 수준의 추론을 수행할 수 있음을 보여주며, 단 1,000개의 샘플로 훈련된 모델이 이러한 수준의 추론 능력을 갖출 수 있다는 사실은 매우 인상적이다.
9. 논의 및 관련 연구
9.1 왜 1,000개의 샘플로 충분한가: 샘플 효율적 추론의 메커니즘
본 논문의 가장 핵심적인 질문 중 하나는 "왜 단 1,000개의 샘플에 대한 지도 미세조정만으로 이렇게 극적인 성능 향상이 가능한가"이다. 저자들은 이에 대해 다음과 같은 가설을 제시한다. 현대의 대규모 사전 훈련 모델은 수조 단위의 토큰으로 구성된 방대한 코퍼스에서 훈련되며, 이 코퍼스에는 수학적 증명, 과학적 추론, 논리적 문제 해결 등 다양한 형태의 추론 과정이 포함되어 있다. 따라서 추론 능력의 기초는 이미 사전 훈련 단계에서 모델 내부에 인코딩되어 있으며, s1K를 통한 미세조정은 이 잠재된 능력을 "활성화"하고 특정 형식으로 발현시키는 역할을 한다.
마치 피아노를 배운 사람이 특정 곡의 악보를 보고 연주 방법을 빠르게 습득하는 것처럼, 추론의 기본 능력을 갖춘 사전 훈련 모델이 소수의 구체적인 추론 예시를 통해 그 능력을 명시적이고 체계적으로 발현하게 되는 것이다. 이 관점에서 s1K의 1,000개 샘플은 새로운 지식을 주입하는 것이 아니라, 모델이 이미 알고 있는 것을 올바른 형식과 깊이로 표현하도록 안내하는 "형식 템플릿(format template)"의 역할을 한다고 볼 수 있다.
이 가설은 LIMA(Zhou et al., 2023)에서 제시된 "Superficial Alignment Hypothesis"와 밀접하게 연관된다. LIMA의 저자들은 1,000개의 고품질 예시만으로도 대규모 언어 모델을 사용자의 선호에 맞게 정렬할 수 있음을 보여주었으며, s1 논문의 결과는 이 가설을 추론(reasoning) 영역으로 확장한 것으로 볼 수 있다.
9.2 증류의 효과성: 왜 오류가 포함된 데이터로도 작동하는가
저자들은 왜 증류(distillation)가 효과적인지에 대한 추가적인 고찰을 제시한다. Gemini Flash Thinking에서 증류된 추론 트레이스에는 단순히 정답으로의 경로만이 아니라, 문제를 분석하고, 가능한 접근법을 탐색하며, 중간 결과를 검증하고, 필요시 방향을 수정하는 풍부한 메타인지적(metacognitive) 패턴이 포함되어 있다. 이러한 패턴을 학습함으로써 학생 모델은 특정 문제의 풀이법 자체가 아니라 "어떻게 효과적으로 생각하는가"라는 더 일반적이고 전이 가능한 능력을 획득하게 된다.
이는 왜 53.6%의 추론 트레이스만이 정답을 포함함에도 불구하고 모델의 성능이 크게 향상되는지를 설명해준다. 학습의 핵심 신호는 정답 여부가 아니라 추론 과정의 구조적 특성, 즉 다음과 같은 패턴들이다:
- 체계적 탐색: 문제를 구조화하고 가능한 접근법을 열거하는 패턴
- 자기 검증: 중간 결과를 되돌아보고 일관성을 확인하는 패턴
- 오류 수정: 잘못된 방향을 인식하고 대안적 경로로 전환하는 패턴
- 단계적 분해: 복잡한 문제를 관리 가능한 하위 문제로 분해하는 패턴
9.3 동시기 연구와의 비교
o1의 성능을 재현하려는 동시기의 연구들은 크게 두 가지 접근법으로 분류된다:
- 강화학습 기반 접근법: DeepSeek-r1(DeepSeek-AI et al., 2025)과 Kimi k1.5(Team et al., 2025)가 대표적이다. 대규모 RL을 통해 높은 성능을 달성하지만 막대한 데이터와 연산 자원을 필요로 한다.
- 지도 미세조정 기반 접근법: Sky-T1(Team, 2025), Bespoke-32B(Labs, 2025) 등이 해당하며, 수만 개의 증류된 추론 예시로 SFT를 수행한다.
s1-32B는 두 번째 범주에 속하지만, 사용하는 데이터 규모가 경쟁 모델들의 17분의 1 이하라는 점에서 독특한 위치를 점한다. Budget forcing과의 결합을 통해 최초로 공개된 방법론으로 테스트 타임 스케일링 곡선을 재현했다는 점도 차별화 요소이다. 본 논문은 학습 기반 방법론과 프롬프팅 기반 방법론의 중간 지점에 위치하면서도 양쪽의 장점을 결합한다. 학습 비용은 프롬프팅 접근법에 가깝게 낮으면서도, 성능 향상의 폭은 학습 기반 방법론에 근접한다는 점에서 실용적으로 매우 매력적인 위치에 있다.
9.4 테스트 타임 스케일링의 방법론적 맥락
본 논문이 제안하는 budget forcing은 기존의 테스트 타임 접근법들과 비교하여 구별되는 특성을 갖는다:
- 극도의 단순성: 모델 자체의 수정 없이 순전히 디코딩 시점의 개입만으로 작동. 보상 모델이나 탐색 알고리즘(MCTS 등)이 불필요.
- 완벽한 제어 가능성: 100%의 제어를 제공하여 실용적 배포 환경에서 연산 예산을 정밀하게 관리 가능
- 양의 스케일링 경향: 추가 연산의 투입이 성능 향상으로 이어짐을 보장
이 세 가지 특성의 조합은 기존의 어떤 방법에서도 동시에 달성되지 않았으며, 이는 budget forcing의 핵심적인 기여이다. Chain-of-Thought 프롬프팅은 단순하지만 체계적인 스케일링 곡선을 제공하지 못하며, Tree-of-Thought는 스케일링이 가능하지만 구현이 복잡하다. Self-Consistency는 병렬 스케일링을 제공하지만 순차적 스케일링보다 비효율적이다. Budget forcing은 이러한 기존 방법들의 한계를 극복하면서도 구현의 단순성을 유지한다는 점에서 의미가 크다.
9.5 추론 능력 강화 패러다임의 스펙트럼
본 논문의 위치를 더 넓은 맥락에서 이해하기 위해, 언어 모델의 추론 능력을 강화하기 위한 기존 패러다임들과의 비교가 필요하다. 첫 번째 패러다임은 사전 훈련 데이터의 확장으로, 수학이나 과학 관련 특화 코퍼스에서의 지속 훈련(continual training)을 통해 추론 능력을 향상시키는 접근법이다. Azerbayev 등(2023)은 수학 특화 코퍼스에서의 추가 사전 훈련이 수학적 추론 성능을 향상시킬 수 있음을 보여주었으며, 이 접근법은 대규모의 도메인 특화 코퍼스와 사전 훈련 수준의 연산 비용이 소요된다.
두 번째 패러다임은 추론 특화 학습 방법론의 개발로, STaR(Zelikman et al., 2022)와 같은 자기 개선(self-improvement) 기법이나 과정 보상 모델(process reward model)을 활용한 강화학습 등이 포함된다. STaR는 모델이 자신의 성공적인 추론 경험으로부터 학습하는 부트스트래핑(bootstrapping) 방식을 제안하였으며, 과정 보상 모델을 활용한 접근법(Lightman et al., 2023)은 추론 과정의 각 단계에 대한 세밀한 보상 신호를 제공하여 모델이 올바른 추론 경로를 학습하도록 유도한다. 이러한 방법론들은 강력한 성능 향상을 달성할 수 있으나 보상 모델의 훈련, 탐색 알고리즘의 구현 등 상당한 기술적 복잡성을 수반한다.
세 번째 패러다임은 프롬프팅 기반 접근법으로, Chain-of-Thought(Wei et al., 2023), Tree-of-Thought(Yao et al., 2023a), Complexity-based prompting(Fu et al., 2023) 등이 해당한다. 이 접근법들은 모델의 파라미터를 수정하지 않고 입력 프롬프트의 설계만으로 추론 성능을 향상시킨다는 장점이 있으나, 개선의 폭이 제한적이다. s1-32B는 이 세 패러다임 중 어디에도 깔끔하게 분류되지 않는 독특한 위치를 점한다. 소규모 SFT를 통해 추론 형식을 활성화하고, budget forcing이라는 디코딩 시점 개입을 통해 테스트 타임에 성능을 스케일링하는 이 접근법은 학습 비용은 프롬프팅 접근법에 가깝게 낮으면서도, 성능 향상의 폭은 학습 기반 방법론에 근접한다는 점에서 실용적으로 매우 매력적인 위치에 있다.
10. s1.1: 개선된 후속 모델
논문의 부록 A에서는 s1-32B의 개선 버전인 s1.1이 소개된다. s1.1은 s1K의 데이터 큐레이션 과정에서 몇 가지 개선을 적용하여 s1K-1.1이라는 업데이트된 데이터셋을 구축하고, 이를 사용하여 훈련된 모델이다. 주요 개선 사항으로는 데이터의 정답률이 53.6%에서 63.0%로 향상된 점이 있으며, 이는 더 정교한 품질 필터링을 통해 달성되었다.
s1.1의 존재는 본 연구의 방법론적 프레임워크가 확장 가능하고 반복적으로 개선 가능함을 보여준다는 점에서 중요하다. 데이터 큐레이션의 세 가지 원칙(품질, 난이도, 다양성)을 유지하면서 각 단계의 구현을 정교화하면 동일한 1,000개 샘플 규모에서도 추가적인 성능 향상이 가능하다는 것이다. 정답률이 53.6%에서 63.0%로 약 10%포인트 향상된 것은, 보다 정교한 품질 필터링과 채점 프로토콜의 개선을 통해 달성된 것으로 보인다. 이는 데이터 큐레이션 파이프라인의 각 구성요소가 독립적으로 개선 가능하며, 이러한 점진적 개선이 최종 모델 성능의 향상으로 직결됨을 보여준다. 향후 연구에서 데이터 큐레이션 알고리즘의 체계적 최적화, 예를 들어 자동화된 품질 평가, 난이도 측정의 정교화, 도메인 커버리지의 최적화 등을 통해 샘플 효율성을 더욱 극대화할 수 있는 가능성을 제시한다.
11. 훈련 세부사항 및 추가 분석
11.1 시퀀스 길이 어블레이션
논문의 부록 D에서는 훈련 시 최대 시퀀스 길이가 모델 성능에 미치는 영향을 조사한다. 추론 트레이스는 수천에서 수만 토큰에 이를 수 있으므로, 충분한 시퀀스 길이를 확보하지 않으면 긴 추론 과정이 절단(truncation)되어 학습 신호가 손실될 수 있다. 저자들은 이러한 시퀀스 길이 설정이 최종 모델 성능에 무시할 수 없는 영향을 미침을 보고하며, 적절한 시퀀스 길이의 선택이 훈련 효율성과 성능 사이의 중요한 교환 관계(trade-off)를 형성함을 지적한다.
11.2 평가 결정론성
부록 B에서는 평가의 결정론성(determinism)에 관한 논의가 이루어진다. 온도 0(그리디 디코딩)으로 평가를 수행하더라도 하드웨어와 소프트웨어 환경에 따라 미세한 수치적 차이가 발생할 수 있으며, 이러한 차이가 누적되어 서로 다른 토큰이 선택될 가능성이 존재한다. 특히 AIME24처럼 문제 수가 30개에 불과한 벤치마크에서는 한 문제의 정답 여부가 전체 정확도에 약 3.3%포인트의 영향을 미치기 때문에 이 문제가 더욱 중요하다. 저자들은 95% 부트스트랩 신뢰 구간을 통해 결과의 통계적 신뢰성을 확보하고자 노력하며, 이러한 투명한 보고는 재현성에 대한 연구 커뮤니티의 우려를 선제적으로 다루고 있다.
11.3 디컨태미네이션 절차
부록 C.5에서는 훈련 데이터와 평가 데이터 사이의 오염을 방지하기 위한 디컨태미네이션 절차가 설명된다. 저자들은 8-gram 기반의 중복 검출을 수행하여, s1K의 각 질문과 평가 벤치마크의 질문 사이에 8개 연속 토큰이 일치하는 경우 해당 샘플을 제거한다. 8-gram이라는 기준은 우연한 일치와 실제 오염을 구분하기 위한 합리적인 임계값으로, 너무 짧은 n-gram은 과도한 거짓 양성(false positive)을 초래하고, 너무 긴 n-gram은 실제 오염을 놓칠 수 있다. 이 절차는 보고된 성능이 진정한 일반화 능력을 반영함을 보장하며, 연구 결과의 신뢰성을 높인다.
12. 순차적 스케일링과 병렬 스케일링의 이론적 비교
논문의 논의 섹션에서는 순차적 스케일링과 병렬 스케일링의 이론적 비교가 심도 있게 다루어진다. 순차적 스케일링에서는 모델이 $T$개의 토큰을 생성할 때, 각 토큰이 이전의 모든 토큰에 조건화(conditioned)되어 있으므로 전체 생성이 하나의 연결된 추론 체인을 형성한다. 이로 인해 초기 단계에서 도출된 중간 결과, 발견된 패턴, 그리고 시도한 접근법의 성공 또는 실패에 대한 정보가 후속 단계의 추론에 활용될 수 있다.
반면 병렬 스케일링에서 $N$개의 독립적인 생성을 수행하는 경우, 각 생성은 다른 생성으로부터 어떠한 정보도 받지 못하므로, 하나의 시도에서 얻은 교훈이 다른 시도에 전혀 활용되지 않는다. 그러나 저자들은 순차적 스케일링의 한계도 명확히 인식한다:
- 컨텍스트 윈도우 제한: 자기회귀적 모델에서 컨텍스트 윈도우의 길이는 유한하며, 사고 과정이 길어질수록 초기 정보에 대한 접근성이 떨어질 수 있다.
- 반복 루프 현상: Budget forcing에서 관찰된 바와 같이, 특정 시점 이후로는 유의미한 새로운 추론을 생성하지 못하고 이미 생성된 내용을 반복하게 될 수 있다.
이러한 한계를 극복하기 위한 전략으로 순차적 스케일링과 병렬 스케일링의 결합이 제안된다. 예를 들어, 먼저 budget forcing을 통해 순차적 스케일링으로 성능을 최대한 끌어올린 후, 이 최적화된 순차적 생성을 여러 번 독립적으로 반복하여 다수결 투표를 적용하는 하이브리드 방식이 가능하다. Snell 등(2024)의 연구에서도 문제의 난이도에 따라 순차적 스케일링과 병렬 스케일링의 최적 비율이 달라질 수 있음이 제시되었으며, 쉬운 문제에서는 병렬 스케일링이, 어려운 문제에서는 순차적 스케일링이 더 효율적일 수 있다는 관찰이 보고되었다.
13. 한계점 및 향후 연구 방향
본 논문의 결과는 인상적이지만, 몇 가지 중요한 한계점이 존재하며 이를 통해 향후 연구 방향이 도출된다.
13.1 순차적 스케일링의 유한한 확장성
Budget forcing을 통한 순차적 스케일링은 무한히 확장되지 않는다. 실험에서 사고 종료 억제를 6회 이상으로 늘리면 성능 향상이 평탄해지며, 이는 모델이 반복적 루프에 빠지는 현상과 컨텍스트 윈도우의 물리적 제한에 기인한다. 이를 극복하기 위해서는 반복 감지(repetition detection) 메커니즘의 통합이나, 사고 과정의 요약(summarization)을 통해 컨텍스트 윈도우를 효율적으로 활용하는 방법이 탐구될 수 있다.
13.2 대규모 RL 모델과의 격차
s1-32B의 성능은 대규모 강화학습을 거친 최상위 모델들(o1, DeepSeek-r1)에 비해 여전히 격차가 있다. 특히 GPQA Diamond에서 s1-32B(59.6%)와 o1(77.3%) 사이의 17.7%포인트 격차는 상당하며, 과학적 추론 영역에서 SFT만으로는 달성하기 어려운 수준의 깊은 도메인 지식과 추론 능력이 필요함을 시사한다. AIME24에서도 DeepSeek-r1(79.8%)과 s1-32B(56.7%) 사이에 23.1%포인트의 격차가 존재하며, MATH500에서는 DeepSeek-r1이 97.3%로 s1-32B의 93.0%를 4.3%포인트 상회한다. 이러한 격차는 대규모 강화학습이 제공하는 추가적인 이점이 분명히 존재함을 보여준다. 1,000개의 샘플만으로 이 격차를 완전히 해소할 수 있는지, 아니면 강화학습을 통한 탐색과 자기 개선이 본질적으로 필요한 수준의 추론 깊이가 존재하는지는 미해결 질문으로 남아 있다. 저자들은 데이터 큐레이션 알고리즘의 추가 개선(s1.1에서 시작한 방향)이 이 격차를 더 줄일 수 있을 것으로 기대하지만, 궁극적으로 SFT만의 한계가 존재할 가능성도 열어둔다.
13.3 모델 규모 및 패밀리 일반화 미검증
본 논문의 실험은 32B 파라미터 규모의 단일 기반 모델(Qwen2.5-32B-Instruct)에 한정되어 있다. 다른 규모(7B, 70B 등)나 다른 모델 패밀리(LLaMA, Mistral 등)에서 동일한 접근법이 유사한 효과를 보일 것인지는 검증되지 않았다. 모델 규모가 작아질 경우 사전 훈련 과정에서 인코딩되는 추론 능력의 수준이 낮아져, 1,000개 샘플만으로는 충분한 활성화가 이루어지지 않을 가능성이 있다. 7B 규모의 모델에서는 사전 훈련 동안 학습된 추론 패턴이 32B 모델에 비해 덜 정교할 수 있으며, 이 경우 소규모 미세조정의 효과가 제한적일 것으로 예상된다. 반대로 70B 이상의 더 큰 모델에서는 이미 더 강한 잠재적 추론 능력이 존재하므로 소수의 샘플이 더 큰 효과를 발휘할 수도 있다. 이러한 모델 규모에 따른 상호작용 효과는 향후 연구에서 체계적으로 탐구할 가치가 있는 중요한 주제이며, 특히 "최소한의 미세조정으로 추론 능력을 활성화할 수 있는 모델 규모의 하한"이 존재하는지를 파악하는 것은 실무적으로도 의미가 크다.
13.4 단일 교사 모델 의존성
s1K의 추론 트레이스가 Gemini Flash Thinking이라는 단일 교사 모델로부터 증류되었다는 점은 잠재적 한계이다. 교사 모델의 편향(bias)이나 특정 추론 스타일이 s1-32B에 전이될 수 있으며, Gemini가 잘 풀지 못하는 유형의 문제에서 학생 모델도 취약해질 가능성이 있다. 또한 교사 모델이 특정 도메인이나 문제 유형에서 보이는 체계적인 오류 패턴이 학생 모델에 그대로 전달될 수도 있다. 이러한 한계를 완화하기 위해 다수의 교사 모델을 활용하여 다양한 추론 스타일의 트레이스를 수집하거나, 인간 전문가가 작성한 고품질 추론 트레이스를 포함시키는 것이 고려될 수 있다. 현재 s1K에서 약 절반(53.6%)의 추론 트레이스만이 정답을 포함한다는 사실도 개선의 여지를 보여주며, 정답률을 높이면서도 추론 과정의 다양성과 풍부함을 유지하는 것이 향후 데이터 큐레이션의 주요 과제이다.
13.5 평가 벤치마크의 제한성
AIME24(30문제), MATH500(500문제), GPQA Diamond(198문제)는 모두 수학과 과학 추론에 특화된 벤치마크이며, 언어적 추론, 상식 추론, 인과 추론, 코딩 등 다른 유형의 추론 태스크에서의 성능은 평가되지 않았다. s1-32B가 수학과 과학 이외의 추론 태스크에서도 유사한 수준의 향상을 보이는지, 아니면 s1K의 수학 중심 구성으로 인해 특정 도메인에 편향된 성능 향상만이 이루어졌는지는 추가적인 실험을 통해 확인해야 할 사항이다. 특히 AIME24의 30문제는 통계적 검정력(statistical power)이 낮아 한 문제의 정답 여부가 약 3.3%포인트의 변동을 초래하므로, 보고된 성능 차이의 일부가 통계적 불확실성 범위 내에 있을 수 있다. 저자들이 95% 부트스트랩 신뢰 구간을 보고하여 이러한 불확실성을 투명하게 다루고 있지만, 더 많은 문제를 포함하는 벤치마크에서의 추가 평가가 결과의 견고성을 높일 것이다.
13.6 유망한 향후 연구 방향
저자들은 다음과 같은 향후 연구 방향을 제안한다:
- 순차적/병렬 스케일링의 하이브리드 결합: 두 패러다임의 장점을 결합하여 더 강력한 테스트 타임 스케일링 달성
- 적응적 연산 할당(adaptive compute allocation): 문제 난이도에 따라 연산량을 동적으로 조절하는 전략
- "Wait" 이외의 효과적인 프롬프팅 문자열 탐색: 문제 유형에 따라 다른 문자열을 적응적으로 선택하는 메커니즘
- 다양한 모델 규모와 패밀리에 대한 일반화 검증
- 데이터 큐레이션 알고리즘의 자동화 및 최적화
궁극적으로, 이 분야의 연구는 "제한된 테스트 타임 연산 예산을 어떻게 최적으로 분배하여 추론 성능을 극대화할 것인가"라는 자원 할당(resource allocation) 문제로 수렴한다. 이는 경제학의 최적 자원 배분 문제와 유사한 구조를 가지며, 이론적으로도 실무적으로도 매우 풍부하고 도전적인 연구 주제를 제공한다. 특히 실시간 서비스 환경에서 문제의 예상 난이도에 따라 연산 예산을 동적으로 조절하는 적응적 전략의 개발은 높은 실무적 가치를 지니며, 이는 추론 AI 서비스의 비용 효율성을 크게 향상시킬 수 있는 핵심 기술이 될 것이다.
14. 연구의 학술적 의의와 실무적 함의
14.1 학술적 의의
본 논문의 학술적 의의는 여러 차원에서 평가할 수 있다:
- 테스트 타임 스케일링의 과학적 이해 확장: 기존에는 OpenAI o1의 비공개 결과만이 이 패러다임의 가능성을 보여주었으나, 본 논문은 완전히 공개된 방법론으로 유사한 스케일링 곡선을 재현하였다.
- 데이터 큐레이션의 중요성 실증: 59K 데이터셋과 1K 데이터셋의 성능이 통계적으로 구분되지 않는다는 발견은 데이터 과학 분야에서의 "less is more" 현상에 대한 강력한 사례를 추가한다.
- 새로운 평가 프레임워크 제안: Budget forcing이라는 새로운 기법과 이를 평가하기 위한 메트릭 체계(Control, Scaling, Performance)를 제안하여 후속 연구의 표준화된 비교 프레임워크를 제공한다.
14.2 실무적 함의
실무적 관점에서 본 논문의 함의는 더욱 직접적이다. 7 H100 GPU 시간이라는 극히 낮은 훈련 비용은 소규모 연구 그룹이나 기업에서도 경쟁력 있는 추론 모델을 개발할 수 있음을 의미한다. 클라우드 컴퓨팅 비용으로 환산하면 수십 달러 수준의 투자로 o1-preview를 상회하는 성능의 모델을 얻을 수 있다는 것이다. 이는 기존에 대형 AI 연구소만이 접근할 수 있었던 추론 모델 개발 영역에 대한 진입 장벽을 극적으로 낮추는 결과이며, 학술 연구실이나 스타트업에서도 실질적으로 의미 있는 추론 모델을 구축할 수 있는 가능성을 열어준다.
Budget forcing의 구현 단순성도 실무적 채택의 장벽을 크게 낮추며, 기존의 추론 파이프라인에 최소한의 수정만으로 통합할 수 있다. 사고 종료 토큰의 감지, 억제, "Wait" 문자열 추가라는 세 가지 조건부 로직만으로 전체 메커니즘이 구현되므로, 별도의 보상 모델 서빙이나 탐색 알고리즘 인프라가 불필요하다. 또한 100%의 제어 가능성은 실제 배포 환경에서 연산 예산과 지연 시간(latency)을 정밀하게 관리해야 하는 요구사항에 부합한다. 예를 들어 쉬운 질문에는 적은 사고 토큰을, 복잡한 질문에는 많은 사고 토큰을 할당하는 적응적 연산 분배 전략과 결합하면, 평균 추론 비용을 최소화하면서도 전체적인 성능을 극대화할 수 있는 효율적인 서비스 구조를 설계할 수 있다. 이러한 실용적 장점들은 budget forcing이 연구 논문의 제안에 머무르지 않고 실제 프로덕션 환경에서 채택될 수 있는 현실적인 기법임을 보여준다.
15. 결론
본 논문은 "테스트 타임 스케일링과 강력한 추론 성능을 동시에 달성하기 위한 가장 단순한 접근법은 무엇인가?"라는 질문에 대해 명쾌한 답을 제시한다. 두 가지 핵심 기여를 요약하면 다음과 같다:
첫째, 체계적인 데이터 큐레이션. 난이도, 다양성, 품질이라는 세 가지 원칙에 기반하여 단 1,000개의 고품질 추론 샘플로 구성된 s1K 데이터셋을 구축하였다. 이 데이터셋으로 Qwen2.5-32B-Instruct를 미세조정하면, 16개 H100 GPU에서 26분(7 GPU 시간)이라는 극히 효율적인 훈련만으로 경쟁 수학에서 o1-preview를 최대 27% 상회하는 추론 모델을 얻을 수 있다. 어블레이션 실험은 세 가지 큐레이션 원칙의 결합이 개별 원칙보다 일관되게 우월하며, 59배 많은 데이터를 사용해도 통계적으로 유의한 추가 성능 향상이 없음을 입증하였다.
둘째, budget forcing 기법. 사고 종료 토큰의 강제 삽입(상한 제어)과 억제 후 "Wait" 추가(하한 제어)라는 두 가지 메커니즘으로 구성된 이 기법은, 추가적인 학습이나 보상 모델 없이 순전히 디코딩 시점의 개입만으로 작동한다. 제어 가능성, 스케일링 경향, 최대 성능이라는 세 가지 차원에서 모든 베이스라인을 상회하며, 특히 100%의 완벽한 제어 가능성과 양의 스케일링 기울기를 동시에 달성한다. AIME24에서 50%에서 57%로의 성능 외삽은 budget forcing이 모델의 기존 성능을 넘어서는 추가적인 잠재력을 이끌어낼 수 있음을 보여준다.
궁극적으로, 본 논문은 AI 연구에서 단순함(simplicity)의 가치를 강력히 옹호한다. 복잡한 강화학습 파이프라인, 수백만 개의 훈련 샘플, 수천 GPU 시간의 연산 없이도, 신중한 데이터 선정과 영리한 테스트 타임 기법의 조합이 놀라운 수준의 추론 성능을 달성할 수 있음을 보여주었다. "What is the simplest approach?"라는 연구 질문에 대한 답은 명확하다: 1,000개의 고품질 샘플, 26분의 미세조정, 그리고 "Wait"이라는 한 단어이다.
모델의 잠재적 추론 능력이 사전 훈련 과정에서 이미 형성되어 있으며, 이를 활성화하고 제어하는 것이 핵심이라는 통찰은 향후 추론 AI 시스템 설계의 방향에 중요한 영향을 미칠 것이다. 이 연구는 대규모 연산 자원에 접근하기 어려운 연구자들에게도 추론 모델 개발에 기여할 수 있는 기회를 제공하며, 추론 모델 개발의 민주화(democratization)에 기여한다. 모델 가중치, 훈련 데이터, 코드가 모두 GitHub 저장소에서 공개되어 있어 연구 커뮤니티가 이 결과를 독립적으로 재현하고, 다양한 변형 실험을 수행하며, 나아가 새로운 방법론을 개발할 수 있는 토대를 제공한다. 특히 OpenAI o1이 방법론을 공개하지 않아 학술적 탐구가 제한되었던 상황에서, s1의 완전 공개는 테스트 타임 스케일링의 원리를 이해하고 이를 발전시키기 위한 공동체적 노력의 토대를 마련한다. 이러한 점들을 종합할 때, 본 논문은 테스트 타임 스케일링 분야의 이정표적 연구로 평가할 수 있다.
본 글은 arXiv 논문 2501.19393 (s1: Simple Test-Time Scaling, Muennighoff et al., 2025)을 기반으로 작성된 상세 리뷰입니다. 이 논문은 ICML 2025에 게재가 확정되었으며, 테스트 타임 스케일링 분야의 주요 참고 문헌으로 자리매김하고 있습니다. 모든 실험 결과, 수치 데이터, 그리고 방법론적 분석은 원 논문에 서술된 내용을 기반으로 하며, 원문은 https://arxiv.org/abs/2501.19393에서, 코드와 데이터는 https://github.com/simplescaling/s1에서 확인할 수 있습니다.