OmniThink: Expanding Knowledge Boundaries in Machine Writing through Thinking
https://arxiv.org/abs/2501.09751 | PDF | GitHub
Zekun Xi, Wenbiao Yin, Jizhan Fang, Jialong Wu, Runnan Fang, Yong Jiang, Pengjun Xie, Fei Huang, Huajun Chen, Ningyu Zhang | Zhejiang University, Tongyi Lab (Alibaba Group) | arXiv:2501.09751v5 | 2025년 1월 | EMNLP 2025 게재 확정
1. 서론
글쓰기란 단순히 문자를 나열하는 행위가 아니라, 정보를 수집하고 사고를 반복하며 지식을 구조화하는 연속적인 인지 과정이다. 인간 작가는 특정 주제에 대해 글을 쓸 때 자료를 조사하고, 수집한 정보를 반추하며, 자신의 인지 체계를 갱신하고, 다시 새로운 방향으로 탐색을 확장하는 과정을 자연스럽게 수행한다. 이러한 반복적 사고 과정은 인지과학에서 반성적 실천(reflective practice)이라는 개념으로 설명되며, 인간이 피상적이고 반복적인 서술을 피하고 깊이 있고 독창적인 내용을 생산할 수 있게 하는 핵심 메커니즘이다. 최근 대규모 언어 모델(Large Language Model, LLM)의 비약적 발전은 기계 작문(machine writing) 분야에서 괄목할 만한 진전을 이끌어냈으나, 현재의 LLM 기반 자동 작문 시스템은 이러한 인간의 반복적 사고 과정을 충분히 모사하지 못하고 있다는 근본적인 한계를 안고 있다.
대규모 언어 모델을 활용한 기계 작문에서 가장 널리 채택되는 접근법은 검색 증강 생성(Retrieval-Augmented Generation, RAG)이다. RAG는 주어진 주제에 대해 검색 엔진을 통해 관련 정보를 수집한 후, 이를 바탕으로 글을 생성하는 파이프라인을 따른다. 그러나 기본적인 RAG 파이프라인은 고정된 검색 전략에 의존하기 때문에 주제에 대한 탐색이 제한적이며, 수집되는 정보의 다양성과 깊이가 부족하다는 문제를 지닌다. 이러한 한계를 극복하기 위해 STORM과 Co-STORM 같은 후속 연구들이 역할극(role-playing) 기반의 다중 관점 정보 수집 방식을 제안하였으나, 이들 역시 각 역할의 사전 정의된 지식 범위 내에서만 사고하기 때문에 자신의 지식 경계를 돌파하는 데 어려움이 있다.
기존 방법론들이 생성하는 글에서 반복적으로 관찰되는 핵심 문제는 다음과 같다.
- 정보의 중복(Redundancy): 동일한 사실이 글 전체에서 여러 차례 반복적으로 등장하여 독자 경험을 저하시킨다.
- 깊이의 부족(Lack of Depth): 주제의 표면적 정보에만 머무르며, 심층적인 분석이나 세부 맥락이 결여된다.
- 독창성의 결핍(Lack of Novelty): 검색 결과에 이미 포함된 잘 알려진 정보만 반복하며, 새로운 관점이나 통찰이 부재하다.
이러한 배경과 문제 인식에서 출발하여, 저장대학교(Zhejiang University)와 알리바바 그룹의 통이 랩(Tongyi Lab) 공동 연구팀은 OmniThink라는 새로운 기계 작문 프레임워크를 제안한다. OmniThink의 핵심 아이디어는 학습자가 복잡한 주제에 대해 점진적으로 이해를 심화해 나가는 인간의 느린 사고(slow thinking) 과정을 시뮬레이션하는 것이다. 구체적으로, OmniThink는 정보 트리(Information Tree)와 개념 풀(Conceptual Pool)이라는 두 가지 혁신적 구성요소를 도입하여, 인간이 반복적 학습 과정에서 정보를 수집하고 인지를 구조화하는 메커니즘을 모사한다.
본 논문의 주요 기여는 다음 세 가지로 요약된다.
- 인간의 느린 사고 과정을 모사하는 새로운 작문 프레임워크인 OmniThink를 제안한다.
- 글에서 유용한 정보의 비율을 측정하는 새로운 평가 지표인 지식 밀도(Knowledge Density, KD)를 제안한다.
- 현재 장문 생성 방법론의 도전 과제를 지식 경계(knowledge boundary)라는 새로운 관점에서 분석하고, OmniThink의 효과에 기여하는 요인을 탐구하며, 향후 연구 방향을 제시한다.
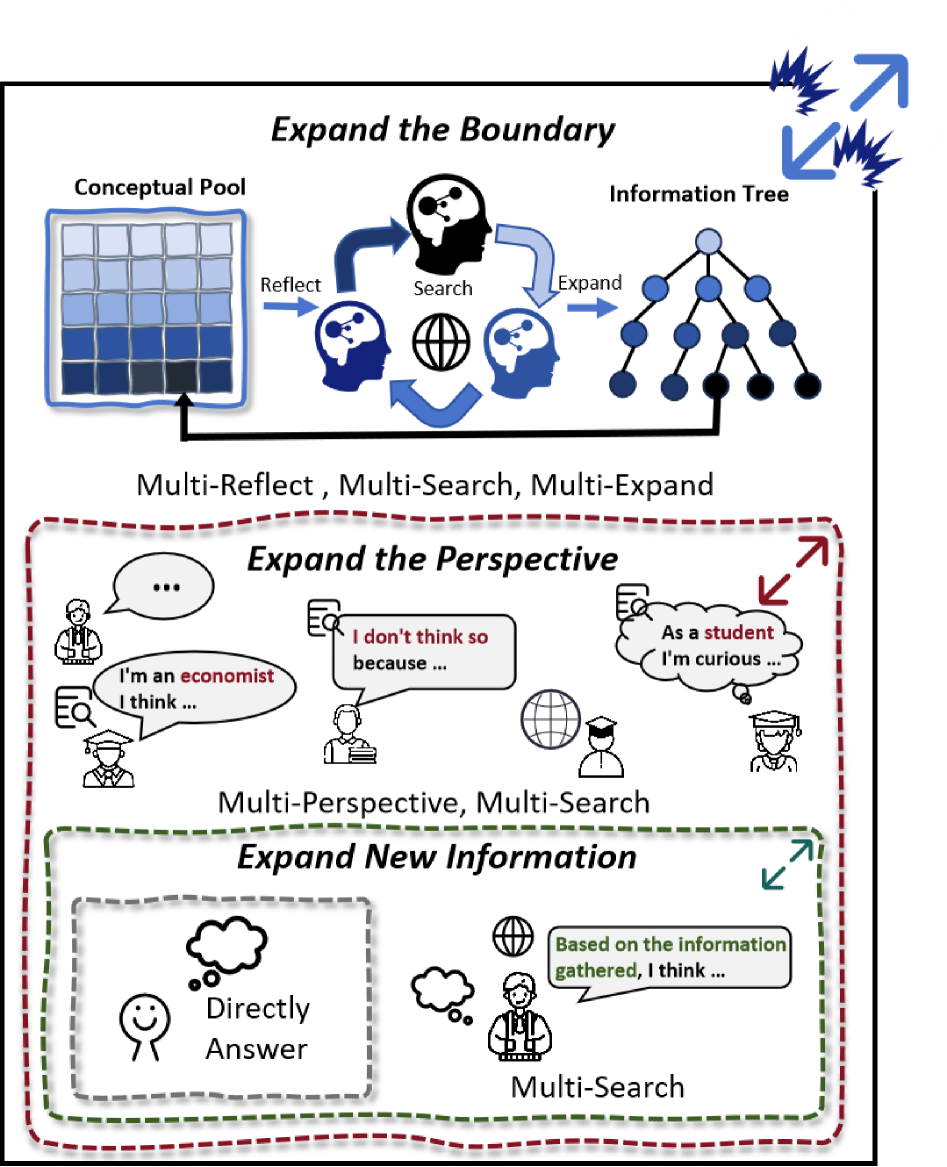
Figure 1: 기존 기계 작문 접근법과 OmniThink의 비교. 기존 방법론은 RAG와 역할극을 통해 새로운 정보나 관점만을 확장하는 반면, OmniThink는 지속적인 반성과 탐색을 통해 지식 경계를 확장하며, 지식을 정보 트리에 부착하고 이를 개념 풀로 추출하여 이해를 심화하고 더 깊이 있는 콘텐츠를 발굴한다.
Figure 1은 기존 기계 작문 접근법과 OmniThink의 근본적인 차이를 시각적으로 보여준다. 왼쪽에 도시된 기존 접근법들은 RAG를 통한 단순 정보 검색이나 역할극을 통한 관점 확장에 머물러 있어, 수집되는 정보의 범위와 깊이가 사전에 정의된 역할의 지식 범위에 의해 제한된다. 반면 오른쪽에 도시된 OmniThink는 정보 트리를 통해 계층적으로 지식을 축적하고, 개념 풀을 통해 축적된 지식을 반추하고 구조화하는 과정을 반복함으로써, 초기 검색으로는 도달할 수 없었던 깊이 있는 지식 영역까지 탐색을 확장한다. 이 그림은 OmniThink가 기존 방법론의 "얕은 검색-생성" 패러다임에서 벗어나, "반복적 탐색-반성-심화"라는 새로운 패러다임을 구현하고 있음을 명확하게 보여준다.
2. 연구 동기 및 인지과학적 배경
OmniThink의 연구 동기를 이해하기 위해서는 먼저 인간의 글쓰기 과정이 어떻게 이루어지는지, 그리고 현재의 기계 작문 시스템이 이 과정의 어떤 부분을 놓치고 있는지를 살펴볼 필요가 있다. 인지과학의 반성적 실천(reflective practice) 이론에 따르면, 인간 작가는 글을 쓰는 과정에서 단순히 이미 알고 있는 정보를 나열하는 것이 아니라, 이전에 수집한 정보와 개인적 경험을 지속적으로 반추하면서 자신의 인지 프레임워크를 재조직하고, 필터링하며, 정제하는 과정을 거친다. 이 이론은 교육학에서 Karen Osterman이 1990년에 체계화한 것으로, 학습과 전문성 개발에서 반성의 역할을 강조한다.
인간 작가의 글쓰기 인지 과정을 분해하면 다음과 같은 반복적 사이클로 구성된다.
- 정보 수집: 주제에 관련된 자료를 탐색하고 수집한다.
- 반추 및 소화: 수집한 정보를 기존 지식과 연결하고, 핵심 개념을 추출한다.
- 인지 갱신: 새로 얻은 통찰을 바탕으로 자신의 이해 체계를 재구성한다.
- 방향 조정: 갱신된 이해를 바탕으로 후속 탐색의 방향과 깊이를 재설정한다.
- 심화 탐색: 새로운 방향으로 더 깊이 있는 정보를 탐색한다.
현재의 LLM 기반 기계 작문 시스템은 이러한 인간의 반성적 사고 과정을 거의 모사하지 못하고 있다. 대부분의 시스템은 "검색 후 생성(retrieve-then-generate)"이라는 단방향 파이프라인을 따르며, 한 번 검색된 정보는 그대로 생성 단계에 전달될 뿐, 검색 결과에 대한 반성이나 이를 바탕으로 한 후속 검색의 방향 조정이 이루어지지 않는다. STORM과 Co-STORM은 역할극을 통해 다양한 관점에서 정보를 수집함으로써 이 문제를 부분적으로 완화하였으나, 각 역할이 자신의 사전 정의된 전문 분야 내에서만 질문하고 답하기 때문에, 역할 간의 교차적 통찰이나 예상치 못한 연결고리의 발견은 제한적이다.
OmniThink의 설계에서 특히 주목할 만한 점은, 인지과학에서의 느린 사고(slow thinking)와 빠른 사고(fast thinking)의 이분법을 기계 작문에 적용했다는 것이다. Daniel Kahneman의 이중 처리 이론(dual process theory)에서 시스템 1(빠른, 직관적 사고)과 시스템 2(느린, 분석적 사고)를 구분하듯이, 기존의 RAG 기반 기계 작문은 검색 결과를 즉각적으로 활용하는 시스템 1적 접근에 해당하는 반면, OmniThink는 검색 결과를 반성하고, 개념을 추출하며, 이를 바탕으로 새로운 탐색 방향을 설정하는 시스템 2적 접근을 구현한다. 최근 O1이나 DeepSeek-R1 같은 추론 특화 모델의 성공이 보여주듯이, 느린 사고를 통한 품질 향상은 AI 시스템 설계에서 점점 더 중요한 트렌드로 자리잡고 있으며, OmniThink는 이 트렌드를 기계 작문 분야에 선제적으로 적용한 사례라 할 수 있다.
3. 배경 및 문제 정의
3.1 오픈 도메인 장문 생성 과제 정의
OmniThink가 다루는 과제는 오픈 도메인 장문 생성(open-domain long-form generation)으로, 이는 개방된 도메인에서 정보를 검색하고 이를 하나의 일관된 글로 합성하는 작업을 의미한다. 현재 표준적인 접근법은 두 가지 주요 단계로 구성된다.
- 정보 검색: 검색 엔진 $\mathcal{S}$를 사용하여 주제 $\mathrm{T}$와 관련된 정보 $\mathcal{I} = \mathcal{S}(\mathrm{T})$를 검색한다.
- 아웃라인 및 글 생성: 검색된 정보 $\mathcal{I}$와 입력 주제 $\mathrm{T}$를 바탕으로 아웃라인 $O = \text{Generate}(\mathcal{I}, \mathrm{T})$를 생성하고, 최종적으로 글 $\mathcal{A} = \text{Generate}(O, \mathcal{I})$를 생성한다.
오픈 도메인 장문 생성은 단순한 질의응답이나 요약과는 본질적으로 다른 특성을 지닌다. 질의응답 시스템이 특정 질문에 대한 정확한 답변을 제공하는 데 초점을 맞추는 반면, 장문 생성은 주제에 대한 포괄적이고 깊이 있는 서술을 요구한다. 이는 단일 정보 소스에 의존하는 것이 아니라 다양한 출처에서 수집된 정보를 종합하고, 이를 논리적으로 구조화하며, 중복을 제거하고, 일관된 서사 흐름을 유지해야 한다는 것을 의미한다. 특히 위키피디아와 같은 백과사전적 글이나 특정 주제에 대한 보고서를 자동으로 생성하는 과제에서는, 생성된 글이 사실적 정확성뿐만 아니라 정보의 폭(breadth)과 깊이(depth), 그리고 독창성(novelty)까지 갖추어야 한다는 높은 수준의 요구사항이 부과된다.
3.2 기존 방법론 재검토
오픈 도메인 장문 생성의 품질을 향상시키기 위한 다양한 선행 연구가 진행되어 왔다. 대표적으로 STORM은 질문 메커니즘을 제안하여 생성되는 아웃라인의 품질과 관련성을 개선하였으며, Co-STORM은 사용자 참여형 라운드테이블 토론을 검색 단계에 도입하여 수집되는 정보의 다양성을 높이고자 하였다. 이들 방법론은 각각 아웃라인 생성과 정보 검색 단계에서 의미 있는 개선을 이루었으나, 생성된 콘텐츠에서 반복적으로 나타나는 중복성과 독창성 부족이라는 근본적인 문제를 완전히 해결하지는 못하였다.
Figure 2: STORM이 GPT-4o를 사용하여 AlphaFold 주제에 대해 생성한 글의 사례. "AlphaFold is developed by DeepMind"라는 잘 알려진 사실이 글 전체에서 반복적으로 등장하는 것을 빨간색으로 표시하였다.
Figure 2는 STORM의 구조적 한계를 매우 직관적으로 보여주는 사례이다. 이 글에서 "AlphaFold was developed by DeepMind"라는 문구가 여러 차례 반복되는데, 이는 인간 작가라면 최초 언급 시 한 번만 서술하고 이후에는 생략하거나 다른 표현으로 대체할 내용이다. 이러한 중복은 검색된 여러 웹 페이지에서 동일한 기본 사실이 반복적으로 포함되어 있고, 생성 모델이 이를 독립적으로 처리하면서 중복을 효과적으로 제거하지 못하기 때문에 발생한다. 이 사례는 기존 기계 작문 시스템이 수집된 정보를 인간처럼 통합적으로 관리하고 구조화하는 인지적 능력이 근본적으로 부족하다는 것을 보여주며, OmniThink가 개념 풀을 통해 해결하고자 하는 핵심 문제점 중 하나이다. 논문의 저자들은 이 사례를 통해 단순히 더 많은 정보를 검색하거나 더 다양한 관점을 수집하는 것만으로는 고품질의 장문 생성이 불가능하며, 수집된 정보를 효과적으로 조직하고 활용하는 인지적 메커니즘이 필요하다는 핵심 논점을 설득력 있게 전달하고 있다.
3.3 지식 경계 관점에서의 한계 분석
논문은 오픈 도메인 장문 생성에서 나타나는 문제점들을 "지식 경계(knowledge boundary)"라는 새로운 관점에서 분석한다. 이 분석 프레임워크는 장문 생성의 도전 과제를 두 가지 근본적인 경계 문제로 추상화한다.
- 지식 정보 경계(Knowledge Information Boundary): 시스템이 접근할 수 있는 외부 정보의 범위와 깊이에 의해 결정되는 한계이다. 검색 전략과 검색 엔진의 능력에 의해 제한되며, 기본 RAG에서는 초기 주제에서 직접 파생되는 쿼리만 사용하므로 정보 경계가 좁다.
- 지식 인지 경계(Knowledge Cognition Boundary): 모델이 수집된 정보를 이해하고 조직하며 활용할 수 있는 인지적 능력의 한계이다. 같은 양의 정보가 주어지더라도, 이를 체계적으로 정리하고 핵심 통찰을 추출할 수 있는 모델은 더 높은 품질의 글을 생성할 수 있다.
이 관점에 따르면, 생성된 글의 중복성은 두 가지 측면에서 설명될 수 있다. 첫째, 검색된 콘텐츠에 포함된 사실적 지식의 양이 제한적일 때, 글 생성에 활용할 수 있는 정보 자체가 부족하여 동일한 내용이 반복될 수밖에 없다. 이는 정보의 양적 한계에서 비롯되는 문제이다. 둘째, 비중복적인 사실적 지식이 충분히 검색되었더라도, 모델이 이를 인간처럼 조직하고 구조화하여 효과적으로 활용할 수 없기 때문에 사용 가능한 정보의 양이 제한되고, 결과적으로 중복이 발생한다. 이는 모델의 인지적 능력의 한계에서 비롯되는 문제이다.
이러한 분석은 매우 중요한 통찰을 제공한다. 기존 연구들이 주로 "더 많은 정보를 검색하면 더 나은 글을 생성할 수 있다"는 암묵적 가정에 기반하고 있었던 반면, 이 분석은 정보의 양 자체보다 정보의 활용 능력이 더 근본적인 제한 요인일 수 있음을 제시하기 때문이다. 마찬가지로, 독창성의 부족도 두 가지 원인으로 귀결된다. 하나는 새로운 지식을 수집하는 데 실패하는 것이고(정보 경계의 한계), 다른 하나는 수집된 새로운 지식을 효과적으로 활용하지 못하는 것이다(인지 경계의 한계). 이러한 분리는 각 한계에 대한 맞춤형 해결책을 설계할 수 있게 해준다. 정보 경계를 확장하기 위해서는 더 다양하고 깊이 있는 검색 전략이 필요하며, 인지 경계를 확장하기 위해서는 수집된 정보를 분석하고 통합하는 반성적 사고 메커니즘이 필요하다. OmniThink는 정보 트리를 통해 정보 경계를, 개념 풀을 통해 인지 경계를 각각 확장하는 것을 목표로 하며, 이 경계 기반 분석 프레임워크는 기존 연구에서 단편적으로 다루어지던 문제들을 통합적으로 이해할 수 있는 이론적 기반을 제공한다.
4. OmniThink 프레임워크
OmniThink는 인간의 느린 사고(slow thinking) 과정을 모사하는 기계 작문 프레임워크로서, 크게 세 가지 단계로 구성된다.
- 정보 획득(Information Acquisition): 정보 트리와 개념 풀을 반복적으로 확장하고 반성하여 주제에 대한 포괄적이고 깊이 있는 지식 기반을 구축한다.
- 개념 기반 아웃라인 구조화(Concept-guided Outline Structuring): 구축된 개념 풀을 활용하여 논리적으로 일관되고 포괄적인 글의 뼈대를 설계한다.
- 글 작성(Article Composition): 완성된 아웃라인과 정보 트리의 풍부한 자료를 활용하여 각 섹션을 병렬적으로 작성한 후, 전체적인 수정과 중복 제거를 거쳐 최종 글을 완성한다.
기존의 기계 작문 시스템들이 주로 아웃라인 생성과 글 작성 단계의 개선에 초점을 맞추었던 것과 달리, OmniThink는 첫 번째 단계인 정보 획득의 질적 변환을 통해 전체 파이프라인의 성능을 끌어올리는 전략을 채택하였다. 이는 "쓰레기가 들어가면 쓰레기가 나온다(garbage in, garbage out)"라는 원칙에 기반한 것으로, 아무리 정교한 아웃라인 구조화와 글 작성 메커니즘을 갖추더라도, 입력되는 정보의 품질과 조직도가 낮으면 최종 글의 품질도 제한될 수밖에 없다는 인식을 반영한다.

Figure 3: OmniThink의 전체 개요. 왼쪽 다이어그램은 (a) 정보 획득, (b) 아웃라인 구조화, (c) 글 작성의 세 단계를 보여준다. 오른쪽 다이어그램은 정보 획득 단계의 구체적인 연산을 보여주며, (①-②)는 초기화, (②-③)은 반성, (③-④)은 확장에 해당한다.
Figure 3은 OmniThink 프레임워크의 전체 구조를 상세하게 보여주는 핵심 다이어그램이다. 왼쪽 부분은 세 가지 주요 단계의 순차적 흐름을 보여주며, 정보 획득 단계에서 충분한 지식이 축적된 후에야 아웃라인 구조화와 글 작성 단계로 진행됨을 알 수 있다. 오른쪽 부분은 정보 획득 단계의 내부 동작을 더 상세히 도시하고 있는데, 초기화(①-②), 반성(②-③), 확장(③-④)이 교대로 반복되는 사이클이 OmniThink의 핵심이며, 사이클이 반복될수록 정보 경계와 인지 경계가 점진적으로 확장되는 효과를 가져온다.
OmniThink와 기존 방법론의 핵심 특성 비교는 Table 1에 정리되어 있다. OmniThink가 동적 검색, 구조화된 메모리, 반성적 사고라는 세 가지 특성을 모두 갖추고 있는 유일한 프레임워크임을 확인할 수 있다.
| 특성 (Feature) | STORM | Co-STORM | OmniThink |
|---|---|---|---|
| 동적 검색 (Dynamic Retrieval) | ✗ | ✗ | ✓ |
| 구조화된 메모리 (Structured Memory) | ✗ | ✓ | ✓ |
| 반성적 사고 (Reflective Thinking) | ✗ | ✗ | ✓ |
Table 1에서 확인할 수 있듯이, STORM은 세 가지 특성 중 어떤 것도 갖추고 있지 않은 반면, Co-STORM은 구조화된 메모리만을 부분적으로 도입하고 있다. 각 특성의 의미를 정리하면 다음과 같다.
- 동적 검색: 이전에 수집한 정보와 현재의 인지 상태를 바탕으로 후속 검색의 방향과 깊이를 동적으로 조정하는 능력이다. OmniThink는 개념 풀의 안내를 받아 정보 트리의 리프 노드를 선택적으로 확장함으로써 이를 구현한다.
- 구조화된 메모리: 수집된 정보를 단순한 문서 목록이 아닌 계층적 구조로 조직하는 능력이다. OmniThink의 정보 트리가 이에 해당한다.
- 반성적 사고: 수집된 정보를 분석하고 핵심 통찰을 추출하여 자신의 인지 체계를 갱신하는 능력이다. OmniThink의 개념 풀 반성 메커니즘이 이를 담당한다.
4.1 정보 획득 (Information Acquisition)
정보 획득 단계는 OmniThink의 가장 핵심적인 단계로서, 정보 트리(Information Tree) $\mathcal{T}$와 개념 풀(Conceptual Pool) $\mathcal{P}$라는 두 가지 혁신적 구성요소를 통해 인간의 지식 획득 및 인지 프레임워크 갱신 과정을 시뮬레이션한다. LLM은 훈련을 통해 방대한 양의 인간 지식을 학습하였으나, 인간이 새로운 지식을 학습할 때 유용한 정보를 자발적으로 조직하고 인지 프레임워크를 갱신하는 과정을 포착하는 데에는 어려움을 겪는다. 이는 LLM의 추론 과정이 기본적으로 입력-출력 매핑에 기반하며, 중간 상태를 명시적으로 유지하고 갱신하는 메커니즘이 부재하기 때문이다. OmniThink는 정보 트리와 개념 풀을 외부 메모리(external memory) 구조로 도입함으로써 이 한계를 극복하고, 반복적인 확장과 반성을 통해 이 두 구성요소를 지속적으로 풍부하게 만들어 나간다.
정보 트리와 개념 풀의 역할을 직관적으로 이해하기 위해, 인간 학습자의 비유를 들어보자. 정보 트리는 학습자가 노트에 정리하는 체계적인 학습 자료에 해당한다. 초기에는 주제에 대한 개괄적인 내용만 기록되어 있지만, 학습이 진행됨에 따라 각 주제 하위에 더 상세한 내용이 추가되면서 노트가 점점 풍부해진다. 개념 풀은 학습자의 머릿속 개념 지도(concept map)에 해당한다. 노트에 기록된 개별 사실들로부터 핵심 개념과 관계를 추출하여 자신만의 이해 체계를 형성하는 것이다. 이 개념 지도가 풍부해질수록, 학습자는 다음에 어떤 방향으로 더 깊이 공부해야 하는지를 더 정확하게 판단할 수 있게 된다.
4.1.1 초기화 (Initialization)
정보 획득 과정은 초기화로 시작된다. 입력 주제 $\mathrm{T}$가 주어지면, OmniThink는 다음과 같은 순서로 초기 상태를 구성한다.
- Google이나 Bing과 같은 검색 엔진을 활용하여 주제와 관련된 정보를 검색한다.
- 검색된 정보를 정보 트리의 초기 루트 노드 $N_r$로 구성한다.
- 루트 노드에 포함된 초기 정보를 분석하고 추출하여 예비 개념 풀 $\mathcal{P}_0$을 형성한다.
이 예비 개념 풀은 OmniThink가 해당 주제에 대해 갖는 기초적인 인지 상태를 나타내며, 이후의 확장 과정을 안내하는 출발점으로 기능한다. 초기화 단계는 인간 학습자가 새로운 주제를 처음 접할 때 개괄적인 자료를 훑어보며 기본적인 이해를 형성하는 과정과 유사하다. 이 단계에서 형성된 기초적 인지는 이후 어떤 방향으로 더 깊이 탐구해야 하는지, 어떤 하위 주제가 중요한지를 판단하는 기준이 된다.
4.1.2 정보 트리의 확장 (Expansion of Information Tree)
정보 트리의 확장은 OmniThink가 정보 경계(Information Boundary)를 넓히는 핵심 메커니즘이다. 시간 단계(time step) $m$에서의 확장 과정은 다음과 같이 진행된다.
- 현재 정보 트리 $\mathcal{T}_m$의 모든 리프 노드 $L_m = \{N_0, N_1, \ldots, N_n\}$을 분석한다.
- 확장이 필요한 노드에 대해, 현재 개념 풀 $\mathcal{P}_m$을 참조하여 더 깊은 확장이 필요한 영역이나 적절한 확장 방향을 식별한다.
- 각 리프 노드 $N_i$에 대해 $k_{N_i}$개의 하위 노드 $\text{SUB}(N_i) = \{S_0, S_1, \ldots, S_{k_{N_i}}\}$를 생성한다.
- 생성된 각 하위 노드에 대해 관련 정보를 검색하고 노드 내에 저장한다.
- 하위 노드를 업데이트된 정보 트리에 추가한다.
이 확장 과정은 수식적으로 다음과 같이 표현된다.
$$\mathcal{T}_{m+1} = \text{Combine}(\mathcal{T}_m, \text{SUB}(N_0), \ldots, \text{SUB}(N_n))$$
이 과정에서 개념 풀은 일종의 나침반 역할을 수행하여, 단순히 임의의 방향으로 검색을 확장하는 것이 아니라 현재의 인지 상태를 고려한 목적 지향적 확장을 가능하게 한다. 예를 들어, 만약 주제가 "AlphaFold"이고 초기 검색을 통해 단백질 구조 예측이라는 기본적인 개념이 개념 풀에 포함되어 있다면, 확장 단계에서는 "단백질 구조 예측의 역사적 발전", "AlphaFold2의 아키텍처적 혁신", "구조 생물학에서의 실제 응용 사례" 등 더 구체적이고 깊이 있는 방향으로 탐색이 진행될 수 있다.
정보 트리의 확장이 단순한 검색 횟수의 증가와 본질적으로 다른 점은, 각 확장 단계에서 이전에 축적된 지식과 인지 상태가 새로운 검색의 방향을 결정한다는 것이다. 기존의 RAG 시스템에서는 초기 주제에서 파생된 고정된 쿼리 집합으로 검색을 수행하기 때문에, 검색의 깊이와 범위가 초기 쿼리의 품질에 의해 제한된다. 반면 OmniThink의 정보 트리 확장에서는, 이전 단계에서 수집된 정보를 통해 학습한 새로운 개념이나 관점이 다음 단계의 검색 쿼리를 형성하기 때문에, 초기에는 접근할 수 없었던 깊이 있는 정보 영역까지 점진적으로 도달할 수 있다. 이는 인간 연구자가 문헌 조사를 할 때 초기 논문에서 발견한 참고문헌을 추적하여 점점 더 전문적인 자료에 접근하는 과정과 유사한 메커니즘이다. 트리 구조를 채택한 것은 중요한 설계 결정인데, 이는 주제의 자연스러운 계층적 구조(상위 개념에서 하위 세부사항으로의 분해)를 반영하며, 동시에 각 노드가 자신의 상위 노드로부터의 맥락 정보를 유지할 수 있게 해주기 때문이다. 이러한 맥락 보존은 각 확장 단계에서 생성되는 쿼리가 단순히 키워드 수준이 아니라 주제의 전체적인 맥락 내에서 의미 있는 탐색 방향을 나타낼 수 있도록 보장한다. 이후 반성을 통해 새로운 개념이 추출되면, 다음 확장에서는 더 전문적이고 구체적인 방향으로 탐색이 확장될 수 있으며, 이처럼 개념 풀의 안내를 받는 확장은 각 사이클마다 점진적으로 더 깊고 더 전문적인 정보 영역으로 진입하는 것을 가능하게 한다.
4.1.3 개념 풀의 반성 (Reflection of Conceptual Pool)
개념 풀의 반성은 OmniThink가 인지 경계(Cognition Boundary)를 확장하는 핵심 메커니즘이다. 이 단계에서 OmniThink는 새로 검색된 정보가 포함된 모든 리프 노드 $L_{m+1} = \{N_0, \ldots, N_n\}$을 반성하여 개념 풀을 갱신한다. 반성 과정은 다음과 같은 단계로 구성된다.
- 분석(Analysis): 리프 노드에 포함된 원시 정보를 체계적으로 분석한다.
- 필터링(Filtering): 중요하지 않거나 중복되는 정보를 걸러낸다.
- 종합(Synthesis): 필터링된 정보를 핵심 통찰 $I_{m+1} = \{\text{INS}_0, \ldots, \text{INS}_n\}$으로 증류한다.
- 통합(Integration): 증류된 통찰을 기존 개념 풀에 통합한다.
이 갱신 과정은 수식적으로 다음과 같이 표현된다.
$$\mathcal{P}_{m+1} = \text{Merge}(I_{m+1}, \mathcal{P}_m)$$
이 갱신 과정은 단순한 정보의 추가가 아니라, 기존 인지 체계와 새로운 통찰을 통합적으로 재구조화하는 과정이다. 개념 풀의 반성 과정이 수행하는 역할은 인간의 메타인지(metacognition)와 유사하다. 인간 학습자는 새로운 정보를 접했을 때 이를 단순히 기억하는 것이 아니라, 기존에 알고 있던 것과 연결하고, 모순되는 부분을 식별하며, 더 높은 수준의 추상화를 통해 자신의 이해 체계를 재구성한다. 갱신된 개념 풀 $\mathcal{P}_{m+1}$은 LLM의 확장된 인지 경계를 나타내며, 이를 바탕으로 정보 트리의 리프 노드를 다시 반복적으로 확장한다.
4.1.4 확장-반성의 반복적 상호작용과 종료 조건
확장과 반성이 번갈아 수행되는 이 반복적 구조의 핵심적인 장점은, 각 사이클에서 이전 사이클의 결과가 다음 사이클의 입력으로 활용된다는 점이다. 이러한 양의 피드백 루프(positive feedback loop)를 통해, OmniThink는 각 사이클마다 정보 경계와 인지 경계를 동시에 확장하는 효과를 달성한다. 각 사이클의 정보 흐름은 다음과 같다.
- 현재 개념 풀 $\mathcal{P}_m$의 내용이 정보 트리의 리프 노드 분석에 활용되어, 탐색 방향이 판단된다.
- 판단된 방향을 바탕으로 하위 노드들이 생성되고, 새로운 정보가 검색되어 수집된다.
- 새로 추가된 리프 노드의 정보가 반성 과정을 통해 핵심 통찰로 증류되어 개념 풀에 통합된다.
- 풍부해진 개념 풀이 다음 확장 사이클에서 더 정교한 검색 방향을 설정한다.
이 반복 과정은 두 가지 조건 중 하나가 만족될 때 종료된다. 첫 번째 조건은 OmniThink가 충분한 정보가 수집되었다고 판단하는 것이며, 두 번째 조건은 사전 정의된 최대 검색 깊이 $K$에 도달하는 것이다. 첫 번째 조건은 탐색의 수확 체감 현상을 반영하며, 두 번째 조건은 실용적인 계산 자원의 제한을 반영하는 안전장치 역할을 한다. 이러한 반복적 구조의 계산 비용에 대해서도 고려할 필요가 있다. 각 확장-반성 사이클은 검색 엔진 API 호출, LLM 추론, 그리고 임베딩 계산 등의 비용을 수반하며, 깊이 $K$가 증가할수록 총 비용은 트리의 분기 계수에 따라 증가할 수 있다.
4.2 개념 기반 아웃라인 구조화 (Concept-guided Outline Structuring)
아웃라인은 글의 내용 방향, 구조적 계층, 그리고 논리적 전개를 결정하는 핵심 요소이다. OmniThink는 정보 획득 단계에서 구축한 개념 풀이 본질적으로 LLM의 인지 경계를 나타낸다는 점을 활용하여, 아웃라인 생성 과정에 개념 풀을 적극적으로 활용한다. 아웃라인 구조화는 다음의 이중 단계로 수행된다.
- 초안 아웃라인 생성: 주제와 수집된 정보를 바탕으로 초안 아웃라인 $O_D$를 생성한다.
- 개념 풀 기반 정제: LLM에게 개념 풀 $\mathcal{P}$의 내용을 참조하여 초안을 다듬고 연결하도록 요청하여 최종 아웃라인 $O = \text{Polish}(O_D, \mathcal{P})$를 형성한다.
이 접근법이 기존 방법론과 차별화되는 핵심적인 점은, 아웃라인 생성 시 단순히 검색된 원시 문서를 참조하는 것이 아니라, 반복적인 탐색과 반성을 통해 정제된 개념적 이해를 참조한다는 것이다. 기존 방법론에서는 검색된 문서의 표면적 내용에 기반하여 아웃라인을 구성하기 때문에, 문서에 명시적으로 언급된 주제만 다루는 경향이 있다. 반면 OmniThink에서는 개념 풀이 원시 문서에서 추출되고 통합된 고수준의 개념과 관계를 포함하고 있으므로, 아웃라인이 더 깊이 있고 다양한 측면을 포괄할 수 있다. 이는 인간 작가가 충분한 사전 조사와 사고를 거친 후에 글의 구조를 설계할 때 더 완성도 높은 결과물을 산출하는 것과 동일한 원리이다.
4.3 글 작성 (Article Composition)
아웃라인이 완성되면, OmniThink는 글 작성 단계에 진입한다. 이 단계의 구체적인 과정은 다음과 같다.
- 관련 정보 검색: 각 섹션 $S$의 제목과 계층적 하위 섹션 제목을 사용하여, Sentence-BERT 임베딩 기반의 코사인 유사도 계산을 통해 정보 트리에서 가장 관련성 높은 $K$개의 문서를 검색한다.
- 섹션 병렬 생성: LLM이 각 섹션에 대해 병렬적으로 인용(citation)을 포함한 내용을 생성한다.
- 초안 결합: 생성된 모든 섹션을 하나의 완전한 초안 글 $\mathcal{A}_D = \{S_1, \ldots, S_n\}$으로 결합한다.
- 후처리(Polishing): 결합된 글에서 중복 정보를 제거하고 전체적인 일관성을 확보하여 최종 글 $\mathcal{A} = \{S'_1, \ldots, S'_n\}$을 형성한다.
후처리 단계는 인간 작가가 초고를 완성한 후 전체를 통독하며 수정하는 퇴고 과정과 유사한 기능을 수행한다. 각 섹션이 병렬적으로 생성되었기 때문에, 작성 시점에서 다른 섹션의 구체적인 내용이 아직 확정되지 않은 상태이며, 이로 인해 섹션 간에 내용의 중복이나 논리적 불일치가 발생할 수 있다. 후처리 과정에서 LLM은 전체 글을 통독하면서 섹션 간에 중복되는 내용을 식별하여 제거하고, 섹션 간의 전환이 자연스러운지 확인하며, 전체적인 서사 흐름의 일관성을 점검한다. 이 단계가 없으면, 병렬 생성의 특성상 서로 다른 섹션에서 동일한 배경 설명이나 정의가 반복적으로 등장하는 문제가 발생할 수 있으며, 이는 앞서 Figure 2에서 확인한 STORM의 중복 문제와 유사한 양상을 보일 수 있다.
글 작성 단계에서 정보 트리가 핵심적인 역할을 수행하는 이유는, 정보 획득 단계를 통해 정보 트리에 축적된 풍부하고 계층적으로 조직된 정보가 각 섹션의 작성에 직접적인 자료를 제공하기 때문이다. 정보 트리의 계층적 구조는 상위 노드에서 하위 노드로의 정보 맥락 전달을 자연스럽게 지원하므로, 검색 결과가 단순한 문서 목록이 아니라 주제의 맥락 내에서 적절한 위치를 가진 지식 조각으로서 제공되며, 이는 생성된 글의 논리적 일관성과 서술의 자연스러움을 향상시킨다.
5. 실험 설정
5.1 데이터셋
OmniThink의 효과를 검증하기 위해, 논문은 Co-STORM의 선행 연구를 따라 WildSeek 데이터셋을 평가 데이터셋으로 사용한다. WildSeek의 주요 특성은 다음과 같다.
- 규모: 100개의 데이터 포인트
- 도메인 다양성: 24개의 서로 다른 도메인(과학, 기술, 역사, 문화, 예술, 사회, 경제, 법률 등)
- 데이터 구성: 각 데이터 포인트는 특정 주제와 사용자의 의도로 구성
- 과제 유형: 단순 정보 요약뿐만 아니라 비교 분석, 역사적 맥락 제시, 미래 전망 등 다양한 유형의 글쓰기 과제 포함
5.2 베이스라인
비교를 위한 대표적인 베이스라인으로는 네 가지 방법론이 선택되었으며, 이들의 특성은 다음과 같다.
- RAG: 가장 기본적인 검색 증강 생성 파이프라인으로, 주제에 대해 검색 엔진으로 관련 문서를 검색한 후 이를 바탕으로 글을 생성한다.
- oRAG: RAG의 변형으로, 검색된 정보를 바탕으로 먼저 아웃라인을 생성하고 이를 활용하여 글을 작성하는 두 단계 파이프라인이다.
- STORM: 위키피디아 스타일의 글을 처음부터 작성하기 위해 역할극 기반의 질문-답변 방식을 도입한 시스템이다.
- Co-STORM: 사용자 참여형 정보 검색 패러다임을 제안한 후속 연구이다. 다만 본 실험에서는 공정한 비교를 위해 인간 참여 단계를 제거하고 에이전트가 이를 대체하는 설정을 사용하였다.
논문은 네 가지 서로 다른 백본 모델을 사용하여 실험을 수행함으로써, OmniThink의 모델 불가지론적(model-agnostic) 특성을 검증한다. 사용된 모델은 다음과 같다.
- 대화형 모델(Conversational Models): GPT-4o, Qwen-Plus
- 추론 모델(Reasoning Models): O1-preview, DeepSeek-R1
5.3 지식 밀도 메트릭 (Knowledge Density Metric)
논문은 생성된 글에 대한 지식 밀도(Knowledge Density, KD) 지표를 도입한다. 지식 밀도는 텍스트의 전체 분량 대비 의미 있는 콘텐츠의 비율로 정의되며, 수식적으로 다음과 같이 표현된다.
$$KD = \frac{\sum_{i=1}^{N} \mathcal{U}(k_i)}{L}$$
여기서 각 기호의 의미는 다음과 같다.
- $N$: 문서 내에서 식별된 원자적 지식 단위(atomic knowledge unit)의 총 수
- $\mathcal{U}(k_i)$: $i$번째 단위 정보 $k_i$가 고유한지(unique) 여부를 나타내는 함수
- $L$: 텍스트의 전체 길이
이 지표의 핵심적인 특징은 단순히 글에 포함된 정보의 양을 측정하는 것이 아니라, 중복을 제거한 후의 고유한 정보만을 계산한다는 점이다. 따라서 같은 사실을 여러 번 반복하는 글은 비록 총 정보량은 많을 수 있으나 지식 밀도는 낮게 평가되며, 반대로 각 문장이 새로운 정보를 제공하는 간결하고 밀도 높은 글은 높은 지식 밀도를 기록한다. 논문은 부록 H에서 KD 메트릭의 유효성을 실증적으로 검증하며, 낮은 KD의 콘텐츠를 접하는 독자가 피로감과 좌절감을 경험하는 반면, 높은 KD의 콘텐츠는 효율적인 지식 전달 경험을 제공한다는 것을 보여준다.
5.4 평가 설정
자동 평가를 위해 논문은 Prometheus2 모델을 사용하여 글을 0점에서 5점 사이의 척도로 채점한다. 평가 기준은 네 가지 루브릭으로 구성되어 있다.
- 관련성(Relevance): 생성된 글이 주어진 주제와 얼마나 밀접하게 관련되어 있는지를 평가한다.
- 폭(Breadth): 주제의 다양한 측면이 얼마나 포괄적으로 다루어졌는지를 측정한다.
- 깊이(Depth): 각 측면이 얼마나 심층적으로 탐구되었는지를 평가한다.
- 독창성(Novelty): 글에 새로운 관점이나 잘 알려지지 않은 정보가 얼마나 포함되어 있는지를 측정한다.
루브릭 채점 외에도 정보 다양성(Information Diversity)과 지식 밀도(Knowledge Density)를 추가적으로 측정한다. 정보 다양성은 Co-STORM의 방법론을 따라, 검색된 웹 페이지 간의 코사인 유사도 차이를 계산하여 수집된 정보의 다양성을 정량화한다. Prometheus2 모델의 제한된 컨텍스트 윈도우로 인해, 평가 시 참고문헌 섹션은 제외되고 입력 텍스트는 2000단어 이하로 트리밍되었다.
5.5 구현 세부사항
OmniThink의 구현에 관한 핵심 설정은 다음과 같다.
| 항목 | 설정 |
|---|---|
| 기반 프레임워크 | DSPy (Stanford) |
| 생성 Temperature | 1.0 |
| Top-p | 0.9 |
| 검색 엔진 | Bing API |
| 쿼리당 반환 웹 페이지 수 | 5개 |
| 섹션별 검색 문서 수 | 3개 (Sentence-BERT 코사인 유사도 기반) |
| KD 계산 백본 | GPT-4o-08-06 (FActScore 프레임워크 활용) |
| 프롬프팅 방식 | 제로샷 프롬프팅 |
DSPy는 Omar Khattab 등이 제안한 프레임워크로, 선언적 언어 모델 호출을 자기 개선 파이프라인으로 컴파일하는 것을 목표로 한다. 기존의 프롬프트 엔지니어링이 수동으로 프롬프트를 작성하고 조정하는 과정을 필요로 하는 반면, DSPy는 모듈화된 언어 모델 호출을 정의하고 이를 자동으로 최적화하는 체계적인 접근법을 제공한다. OmniThink에서 DSPy를 채택한 것은, 확장, 반성, 아웃라인 작성, 글 작성, 글 다듬기 등 여러 단계의 LLM 호출이 복잡하게 연쇄되는 파이프라인을 체계적으로 관리하기 위한 선택으로 이해할 수 있다. 전체 프롬프트는 부록에 상세히 수록되어 있으며, 확장, 반성, 아웃라인 작성, 글 작성, 그리고 글 다듬기의 각 단계에 대한 프롬프트가 포함되어 있다.
지식 밀도 계산 과정은 크게 두 단계로 구성된다. 첫 번째 단계에서는 FActScore 프레임워크를 사용하여 생성된 글을 원자적 지식 단위(atomic knowledge unit)로 분해한다. 원자적 지식 단위란, 독립적으로 참/거짓을 판단할 수 있는 최소 단위의 사실적 주장을 의미한다. 예를 들어, "AlphaFold는 DeepMind가 개발한 단백질 구조 예측 AI 시스템이다"라는 문장은 "AlphaFold는 DeepMind가 개발하였다", "AlphaFold는 AI 시스템이다", "AlphaFold는 단백질 구조를 예측한다" 등의 여러 원자적 지식 단위로 분해될 수 있다. 두 번째 단계에서는 분해된 원자적 지식 단위들 중 중복되는 것을 식별하고 제거한다. 두 단계 모두 GPT-4o-08-06이 백본으로 사용되었으며, 이는 원자적 지식 분해와 중복 판단 모두 상당한 수준의 언어 이해 능력을 요구하는 작업이기 때문이다.
6. 주요 실험 결과
6.1 글 생성 결과
Table 2는 WildSeek 데이터셋에서의 글 품질 평가 결과를 종합적으로 보여준다. 네 가지 루브릭 채점 기준, 정보 다양성, 그리고 지식 밀도를 포함하는 여섯 가지 지표에 대해, 네 가지 백본 모델을 사용한 다섯 가지 방법론의 결과가 체계적으로 정리되어 있다.
| 백본 | 방법 | Rubric Grading | 정보 다양성 | 지식 밀도 | |||
|---|---|---|---|---|---|---|---|
| Rel. | Brd. | Dep. | Nov. | ||||
| GPT-4o | RAG | 4.65 | 4.55 | 4.59 | 4.22 | 0.1042 | 22.11 |
| oRAG | 2.38 | 3.63 | 2.56 | 2.27 | 0.0963 | 19.70 | |
| STORM | 4.34 | 4.21 | 4.21 | 3.80 | 0.6342 | 19.33 | |
| Co-STORM* | 4.37 | 4.66 | 4.65 | 3.89 | 0.6285 | 19.53 | |
| OmniThink | 4.77 | 4.71 | 4.66 | 4.31 | 0.6642 | 22.31 | |
| Qwen-Plus | RAG | 2.63 | 2.82 | 2.93 | 2.21 | 0.0927 | 10.32 |
| oRAG | 2.42 | 2.52 | 2.66 | 2.22 | 0.1032 | 11.31 | |
| STORM | 2.72 | 2.81 | 3.00 | 2.72 | 0.6417 | 10.28 | |
| Co-STORM* | 3.26 | 3.10 | 3.07 | 2.73 | 0.5332 | 11.52 | |
| OmniThink | 4.00 | 3.92 | 4.06 | 3.38 | 0.7230 | 11.66 | |
| O1-preview | RAG | 3.99 | 4.13 | 4.02 | 3.44 | 0.1065 | 10.49 |
| oRAG | 2.49 | 3.03 | 2.89 | 2.55 | 0.1222 | 10.51 | |
| STORM | 3.26 | 3.22 | 3.44 | 2.56 | 0.6121 | 10.82 | |
| Co-STORM* | 3.41 | 3.29 | 3.23 | 2.97 | 0.6347 | 10.33 | |
| OmniThink | 4.20 | 4.20 | 4.32 | 3.60 | 0.6752 | 10.87 | |
| DeepSeek-R1 | RAG | 4.12 | 4.33 | 4.55 | 4.44 | 0.1044 | 11.32 |
| oRAG | 4.56 | 4.49 | 4.39 | 4.37 | 0.1123 | 10.44 | |
| STORM | 2.42 | 2.93 | 3.14 | 2.86 | 0.6640 | 11.57 | |
| Co-STORM* | 4.62 | 4.54 | 4.78 | 4.47 | 0.5332 | 11.66 | |
| OmniThink | 4.70 | 4.78 | 4.78 | 4.59 | 0.6653 | 11.72 | |
Table 2의 결과에서 도출되는 핵심 관찰은 다음과 같다.
GPT-4o 백본에서 OmniThink는 네 가지 루브릭 기준 모두에서 최고 점수를 기록하였다. 특히 관련성(4.77)과 독창성(4.31)에서 차별화된 성능을 보여주었으며, 지식 밀도(22.31) 역시 모든 방법론 중 최고치를 달성하였다. 이는 RAG의 지식 밀도(22.11)와 유사한 수준이면서도, 정보 다양성(0.6642)에서는 RAG(0.1042)를 크게 앞서고 있어, OmniThink가 다양하고 풍부한 정보를 수집하면서도 높은 지식 밀도를 유지할 수 있음을 보여준다.
Qwen-Plus 백본에서는 OmniThink의 개선 효과가 더욱 극적으로 나타난다. 기본 RAG에서 관련성 2.63, 깊이 2.93이었던 것이 OmniThink에서는 각각 4.00과 4.06으로 크게 향상되었다. 이 정도의 성능 차이는 상대적으로 약한 모델에서 OmniThink의 구조적 이점이 더 크게 발현됨을 의미한다. 또한 정보 다양성에서 0.7230이라는 모든 실험 중 가장 높은 값을 기록하여, 반복적 탐색 메커니즘이 약한 모델에서도 효과적으로 정보 경계를 확장할 수 있음을 입증하였다.
추론 모델 측면에서는, O1-preview와 DeepSeek-R1 모두에서 OmniThink가 일관되게 최고 성능을 달성하였다. 특히 DeepSeek-R1과 결합한 경우에는 폭(4.78)과 깊이(4.78)에서 전체 실험 중 최고 점수를 기록하여, 강력한 추론 능력을 갖춘 모델과 OmniThink의 구조적 이점이 시너지 효과를 내는 것으로 관찰된다.
모델별 결과에서 도출되는 주요 통찰을 정리하면 다음과 같다.
- 이퀄라이저 효과: 상대적으로 약한 모델일수록 OmniThink의 구조적 보조가 더 큰 효과를 발휘한다. Qwen-Plus에서는 관련성 1.37점, 독창성 1.17점의 개선이 관찰된 반면, GPT-4o에서는 각각 0.12점, 0.09점의 개선에 그쳤다.
- 정보 다양성-지식 밀도 역설: RAG는 낮은 정보 다양성(0.1042)에도 불구하고 높은 지식 밀도(22.11)를 기록하는 반면, STORM은 높은 정보 다양성(0.6342)에도 상대적으로 낮은 지식 밀도(19.33)를 보인다. OmniThink는 높은 정보 다양성(0.6642)과 높은 지식 밀도(22.31)를 동시에 달성한 유일한 방법론이다.
- oRAG의 역설적 결과: GPT-4o에서 oRAG의 관련성은 2.38로 RAG(4.65)에 비해 크게 낮다. 이는 불충분한 정보를 바탕으로 생성된 아웃라인이 글의 방향을 잘못 설정할 수 있음을 시사하며, 아웃라인의 품질이 최종 글의 품질에 결정적인 영향을 미친다는 것을 보여준다.
6.2 아웃라인 생성 결과
글 품질 평가에 이어, 논문은 아웃라인의 품질도 별도로 평가한다. 아웃라인 평가는 내용 안내성(Content Guidance), 계층적 명확성(Hierarchical Clarity), 그리고 논리적 일관성(Logical Coherence)의 세 가지 관점에서 수행되었다. 평가에는 Prometheus2 프레임워크를 사용하되, 기본 평가 모델을 GPT-4o-08-06으로 교체하여 더 정확한 평가를 수행하였다.
| 방법 (Method) | Content Guidance | Hierarchical Clarity | Logical Coherence |
|---|---|---|---|
| oRAG | 3.93 | 3.95 | 3.97 |
| STORM | 3.92 | 3.99 | 3.99 |
| Co-STORM* | 3.45 | 3.27 | 3.41 |
| OmniThink | 4.00 | 4.02 | 3.99 |
Table 3의 결과에서 OmniThink는 세 가지 아웃라인 품질 지표 모두에서 우수한 성능을 달성하였다. 내용 안내성(4.00)과 계층적 명확성(4.02)에서 최고 점수를 기록하였으며, 논리적 일관성(3.99)에서도 STORM과 동률의 최고 수준을 유지하였다. 이러한 개선은 OmniThink의 개념 풀이 아웃라인 생성 시 LLM에게 주제에 대한 포괄적이고 다양한 이해를 제공함으로써, 더 완전하고 체계적인 아웃라인을 구성할 수 있게 한다는 설계 의도가 실제로 효과적임을 입증한다.
반면 Co-STORM은 세 가지 지표 모두에서 상대적으로 낮은 점수를 기록하였는데, 이는 Co-STORM에 중간 아웃라인 생성 단계가 없어 최종 글에서 아웃라인을 역으로 추출해야 했기 때문일 수 있다고 논문은 설명한다. 이 결과는 명시적인 아웃라인 구조화 단계가 글의 전체적인 품질에 중요한 역할을 한다는 점을 시사한다.
아웃라인 품질과 최종 글 품질 사이의 관계를 좀 더 심층적으로 고찰하면, 아웃라인이 글 생성 과정에서 수행하는 역할의 중요성이 더욱 부각된다. 아웃라인은 단순히 글의 목차를 나열하는 것이 아니라, 각 섹션에서 다루어야 할 내용의 방향과 범위를 설정하고, 섹션 간의 논리적 흐름을 결정하며, 주제의 어떤 측면에 더 깊이 있는 서술이 필요한지를 안내하는 청사진 역할을 수행한다. 따라서 아웃라인의 품질이 낮으면, 아무리 풍부한 정보가 수집되어 있더라도 최종 글의 구조가 불완전하거나 논리적으로 일관되지 않을 수 있다. OmniThink의 개념 기반 아웃라인 구조화는 이 점에서 결정적인 장점을 지니는데, 반복적인 탐색과 반성을 통해 축적된 개념적 이해가 아웃라인에 직접 반영됨으로써, 주제의 핵심 포인트를 놓치지 않고 포괄적으로 다룰 수 있는 구조를 설계할 수 있다.
7. 심층 분석
7.1 Ablation Study
OmniThink의 각 구성요소가 전체 성능에 기여하는 정도를 정량적으로 검증하기 위해, 논문은 세 가지 ablation 실험을 수행한다.
- 정보 트리 Ablation (w/o Information Tree): 계층적 구조를 제거하고, OmniThink가 모든 검색된 콘텐츠를 직접 반성한 후 다시 검색하도록 변경한다.
- 개념 풀 Ablation (w/o Conceptual Pool): 반성 기능을 비활성화하고, 정보 트리가 최대 깊이에 도달할 때까지 계속 성장하도록 허용한다.
- 확장-반성 전체 Ablation (w/o E&R): 확장과 반성을 모두 구현하지 않는 간소화된 버전과 비교한다.
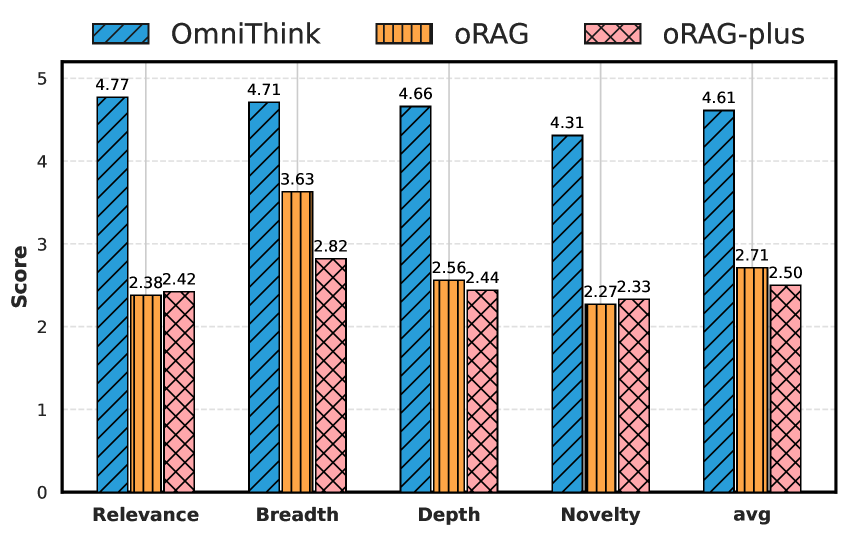
Figure 4: Ablation 실험 종합 결과. (a) 개념 풀의 Ablation; (b) 정보 트리의 Ablation; (c) 확장과 반성 전체 Ablation; (d) 확장과 반성이 다양한 지표에 미치는 영향 비교 (OmniThink 7B_Reflect는 반성에 Qwen2.5-7b-instruct를 사용한 결과); (e) 깊이 분석 결과.
Figure 4는 ablation 실험의 종합적인 결과를 다섯 개의 서브 플롯으로 보여준다. 각 ablation 결과의 핵심 관찰을 정리하면 다음과 같다.
- 개념 풀 제거 시 (Figure 4a): 반성 없이 정보 트리만 성장시켰을 때 성능이 저하되며, 이는 반성 메커니즘이 수집된 정보를 효과적으로 활용하는 데 핵심적인 역할을 한다는 것을 보여준다.
- 정보 트리 제거 시 (Figure 4b): 정보의 계층적 구조를 제거했을 때 유사한 성능 저하가 관찰되며, 이는 정보의 계층적 조직이 검색의 깊이와 품질에 중요하다는 것을 시사한다.
- 확장-반성 모두 제거 시 (Figure 4c): w/o E&R 버전이 모든 지표에서 완전한 시스템보다 낮은 성능을 보이며, 특히 정보 다양성과 독창성에서의 저하가 두드러진다.
이 결과들을 종합하면, 정보 트리와 개념 풀은 각각 독립적으로 중요한 기여를 하며, 이 둘의 상호작용(확장-반성 사이클)이 OmniThink의 성능을 극대화하는 데 필수적임을 알 수 있다. 정보 트리의 계층적 구조는 주제의 다양한 측면과 깊이 수준에 따라 정보를 체계적으로 조직하는 역할을 수행한다. 이 구조가 제거되면, 모든 검색 결과가 평면적으로 축적되어 특정 하위 주제에 대한 깊이 있는 탐색이 어려워진다. 개념 풀의 반성 메커니즘이 비활성화되면, 정보 트리가 성장하더라도 각 확장 단계에서의 방향 설정이 무작위적이 되어, 탐색의 효율성이 크게 저하된다.
7.2 정보 경계 분석 (Information Boundary Analysis)
OmniThink가 실제로 정보 경계를 확장하는지 검증하기 위해, 논문은 OmniThink, STORM, Co-STORM, 그리고 oRAG의 검색 정보를 2차원 평면에 매핑하여 각 시스템의 정보 범위를 시각화하는 실험을 수행한다. 이 시각화는 검색된 문서의 임베딩을 차원 축소하여 각 시스템이 접근하는 정보의 공간적 범위를 직관적으로 비교할 수 있게 해준다.
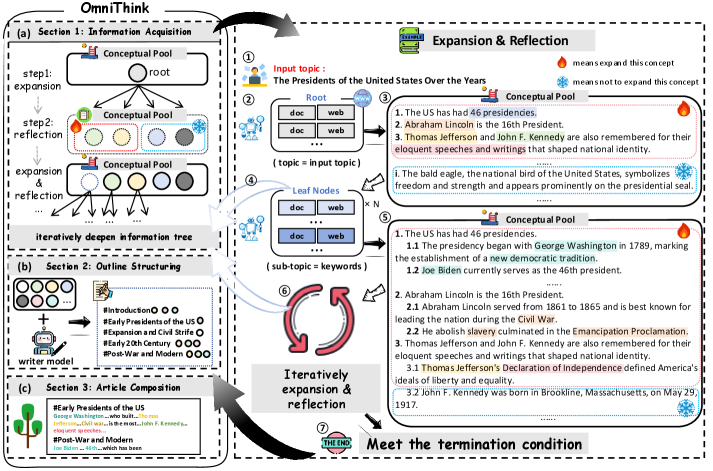
Figure 5: OmniThink, Co-STORM, STORM, oRAG의 정보 범위 시각화. OmniThink가 가장 넓은 검색 범위를 보유하고 있음을 확인할 수 있다.
Figure 5의 시각화 결과는 OmniThink가 네 가지 방법론 중 가장 넓은 검색 범위를 보유하고 있음을 명확하게 보여준다. 각 방법론의 정보 범위 특성을 비교하면 다음과 같다.
- oRAG: 가장 좁은 범위의 정보에만 접근하며, 단일 쿼리 기반의 검색 전략이 정보 탐색의 깊이와 범위를 심각하게 제한한다.
- STORM / Co-STORM: 역할극을 통한 다중 관점 검색 덕분에 oRAG보다 넓은 범위의 정보에 접근하지만, 여전히 OmniThink에 비해서는 제한적이다.
- OmniThink: 반복적인 확장-반성 사이클을 통해 초기 검색에서는 접근할 수 없었던 심층적인 정보 영역까지 점진적으로 탐색이 확장된다.
이 결과는 OmniThink의 정보 트리와 개념 풀이 실제로 정보 경계를 효과적으로 확장한다는 이론적 주장을 실증적으로 뒷받침하며, Table 2에서 관찰된 높은 정보 다양성 수치와도 일관된다.
7.3 인지 경계 분석 (Cognition Boundary Analysis)
인지 경계의 확장 효과를 검증하기 위해, 논문은 매우 흥미로운 실험 설계를 채택한다. 확장과 반성은 본질적으로 분리할 수 없는 과정이므로, 인지 경계의 효과를 독립적으로 측정하기 위한 별도의 베이스라인이 필요하다. 이를 위해 oRAG-Plus라는 새로운 베이스라인을 설정하는데, oRAG-Plus는 oRAG가 검색하는 웹 페이지의 수를 OmniThink와 동일한 수준으로 증가시킨 버전이다.
이 실험 설계의 핵심 논리는 다음과 같다.
- oRAG-Plus와 OmniThink가 접근하는 정보의 총량은 동일하다.
- oRAG-Plus는 개념 풀을 통한 인지적 처리 없이 원시 정보를 직접 사용한다.
- OmniThink는 반성을 통해 정보를 인지적으로 처리한 후 사용한다.
- 따라서 두 시스템 간의 성능 차이는 인지 경계의 확장 효과에 기인한다고 해석할 수 있다.
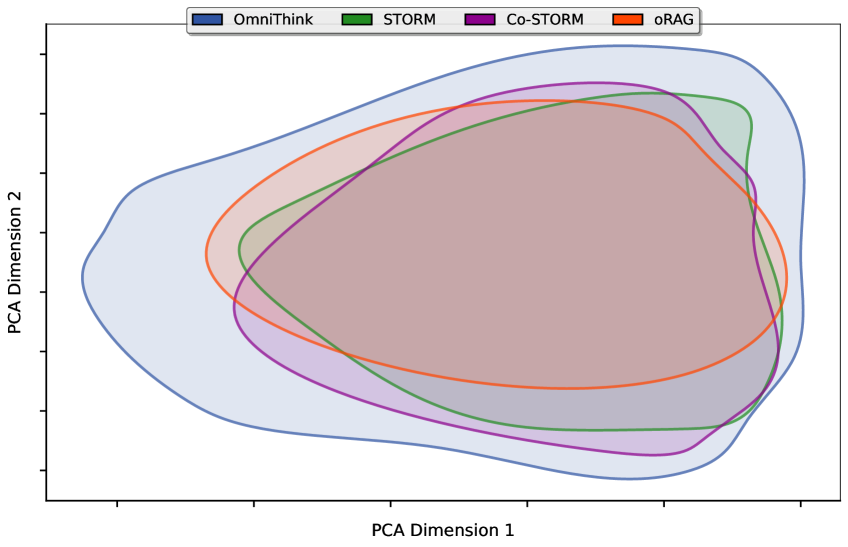
Figure 6: OmniThink, oRAG, oRAG-Plus의 결과 비교. 개념 풀의 안내 없이는 대량의 정보가 주어져도 LLM이 이를 효과적으로 활용하지 못하며, 오히려 과도한 웹 콘텐츠가 노이즈로 작용할 수 있음을 보여준다.
Figure 6의 결과는 매우 시사적이다. 개념 풀의 안내가 없는 oRAG-Plus는 OmniThink와 동일한 양의 정보에 접근함에도 불구하고, OmniThink에 비해 현저히 낮은 성능을 보인다. 더욱 흥미로운 것은, oRAG-Plus의 일부 결과가 원래의 oRAG보다도 낮다는 점이다. 이는 충분한 인지적 처리 능력 없이 과도한 양의 웹 콘텐츠가 주어지면, 이 콘텐츠가 유용한 정보가 아니라 오히려 모델에 대한 노이즈로 작용할 수 있음을 시사한다.
이 관찰은 "더 많은 정보가 반드시 더 나은 결과로 이어지는 것은 아니다"라는 직관에 반하는 중요한 발견이며, 정보의 양뿐만 아니라 정보를 처리하고 활용하는 인지적 능력이 장문 생성의 품질에 결정적인 역할을 한다는 OmniThink의 핵심 주장을 강력하게 뒷받침한다. 이 결과는 단순히 검색 결과를 프롬프트에 삽입하는 기존 RAG 패러다임의 근본적 한계를 지적하는 것이기도 하다. LLM의 컨텍스트 윈도우에 검색된 문서를 무작정 쌓아 넣는 것은 오히려 모델의 주의력(attention)을 분산시키고, 핵심 정보를 노이즈 속에서 구별하기 어렵게 만들 수 있다. OmniThink의 개념 풀은 이러한 문제를 원시 정보를 인지적으로 처리하여 핵심 통찰만을 추출하고 구조화하는 방식으로 해결하며, 이는 인간이 방대한 자료를 읽을 때 모든 내용을 기억하는 것이 아니라 핵심 개념과 관계만을 추출하여 자신의 이해 체계에 통합하는 과정과 정확히 일치한다.
7.4 확장 및 반성의 역할 분석
확장과 반성 과정이 최종 글의 다양한 측면에 어떻게 영향을 미치는지 더 세밀하게 분석하기 위해, 논문은 간접적이면서도 독창적인 실험을 설계한다. 구체적으로, 확장과 반성 과정에 성능이 낮은 모델(Qwen2.5-7b-instruct)을 사용하고, 각 지표의 하락 정도를 통해 해당 과정이 각 지표에 미치는 영향의 크기를 간접적으로 추정한다. 이 실험에서 도출된 두 가지 핵심 발견은 다음과 같다.
발견 1: 인지 경계가 혁신의 잠재력을 주로 제약한다. 반성 과정이 독창성(Novelty) 지표에 특히 중요한 것으로 관찰되었다. 반성은 모델에게 기존 지식을 재평가하고 내성적으로 고려할 뿐만 아니라, 이 정보를 더 다양하고 확장적인 아이디어의 출현을 촉진하는 방식으로 통합하는 능력을 부여한다. 이 발견은 단순히 더 많은 정보를 수집하는 것만으로는 독창적인 글을 생성할 수 없으며, 수집된 정보에 대한 깊이 있는 반성적 사고가 필수적이라는 중요한 통찰을 제공한다.
발견 2: 정보 경계가 정보의 효과적인 조직을 주로 제한한다. 확장 과정이 지식 밀도(Knowledge Density), 폭(Breadth), 깊이(Depth) 지표에서 반성보다 더 중요한 것으로 관찰되었다. 확장은 본질적으로 모델의 후속 정보 검색의 궤적을 설정하며, 확장 과정에서 모델의 검색 방향이 더 정확하고 효과적으로 설정될수록, 검색된 정보를 활용하여 정보 경계를 넓히는 데 더 능숙해진다.
이 두 가지 발견을 종합하면, OmniThink의 확장과 반성 메커니즘은 각각 글의 서로 다른 측면을 개선하는 상보적인 역할을 수행함을 알 수 있다.
- 확장(Expansion): 주로 글의 내용적 측면(폭, 깊이, 지식 밀도)에 기여한다.
- 반성(Reflection): 주로 글의 창의적 측면(독창성)에 기여한다.
이러한 상보적 관계는 인간의 글쓰기 과정에서도 정보 수집(확장에 해당)과 사고 정리(반성에 해당)가 상보적으로 작용하여 고품질의 글을 생산하는 것과 유사한 구조이다. 특히 이 실험은 "확장과 반성이 모두 중요하다"는 피상적인 결론을 넘어, 각 메커니즘이 구체적으로 어떤 품질 차원에 기여하는지를 정량적으로 분리하여 보여줌으로써, 향후 프레임워크 개선 시 어떤 구성요소를 우선적으로 강화해야 하는지에 대한 구체적인 지침을 제공한다.
7.5 깊이 분석 및 경계의 한계
앞선 실험들은 확장과 반성이 각각 정보 경계와 인지 경계를 확장하여 글의 품질을 향상시킨다는 것을 보여주었다. 그렇다면 이 확장-반성 사이클의 깊이를 무한히 증가시키면 글의 품질도 무한히 향상되는가? 이 질문에 답하기 위해, 논문은 확장과 반성의 깊이를 점진적으로 증가시키면서 지식 밀도와 정보 다양성의 변화를 관찰하는 깊이 분석(depth analysis) 실험을 수행한다.
Figure 4(e)에 제시된 깊이 분석 결과에서 도출되는 핵심 관찰은 다음과 같다.
- 깊이가 증가함에 따라 지식 밀도와 정보 다양성의 성장률이 현저히 둔화된다.
- 이는 정보 경계와 인지 경계가 일정 수준 이상으로 확장된 후에는 더 이상 글 품질의 주요 제한 요인이 아님을 시사한다.
- 아직 식별되지 않은 다른 종류의 경계가 존재할 수 있으며, 이를 발견하고 정의하는 것이 향후 연구의 중요한 과제이다.
이 발견은 이론적으로 매우 중요한 함의를 지닌다. 현재 OmniThink가 식별하고 확장하는 두 가지 경계, 즉 정보 경계와 인지 경계는 장문 생성 품질에 영향을 미치는 여러 경계 중 일부에 불과할 수 있다는 것이다. 예를 들어, 생성된 텍스트의 문체적 일관성, 논리적 추론의 깊이, 또는 독자의 배경 지식에 맞춘 적응적 서술 능력 등이 아직 탐구되지 않은 경계 유형으로 고려될 수 있다. 이러한 한계는 깊이를 증가시키는 것만으로는 극복할 수 없으며, 전혀 다른 종류의 메커니즘이 필요할 수 있다. 이 분석은 OmniThink가 중요한 첫 걸음을 내딛었지만, 기계 작문의 완전한 해결에는 아직 더 많은 연구가 필요하다는 솔직한 자기 평가를 보여준다.
8. 인간 평가
자동 평가의 결과를 보완하고 그 신뢰성을 검증하기 위해, 논문은 상세한 인간 평가를 수행한다. 인간 평가의 구체적인 설계는 다음과 같다.
- 주제 선정: 100개의 주제 중 20개를 무작위로 선택
- 비교 대상: OmniThink vs. Co-STORM (자동 평가에서 종합적으로 가장 우수한 성능의 베이스라인)
- 평가 기준: 자동 평가와 동일한 네 가지 측면(관련성, 폭, 깊이, 독창성)
- 평가 방식: 비교 평가(pairwise comparison) — 각 평가자에게 두 편의 글을 제공하여 상대적 우열 판단
- 평가자 자격: 모든 평가자가 학사 학위 이상, 53%가 석사 학위 보유
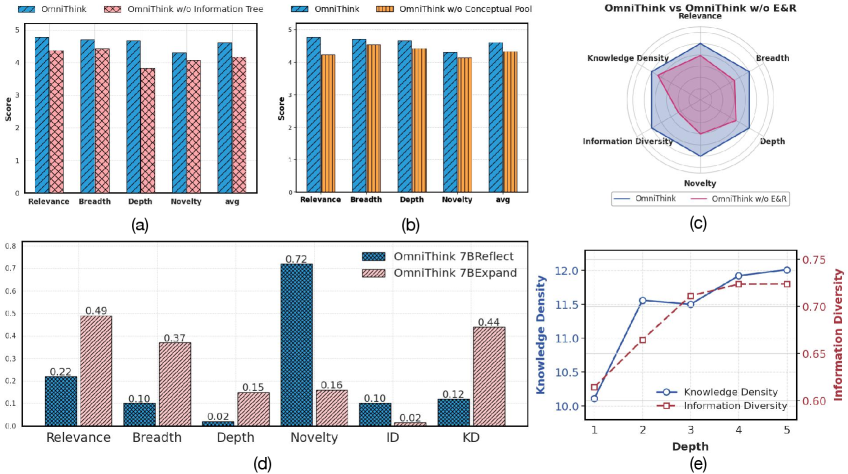
Figure 7: 인간 평가에 참여한 평가자들의 최종 학력 분포. 모든 평가자가 학사 이상의 학력을 보유하고 있으며, 과반수가 대학원 학위를 보유하고 있다.
Figure 7은 인간 평가에 참여한 평가자들의 학력 분포를 보여주는 파이 차트이다. 평가자들의 과반수 이상이 대학원 수준의 교육을 받은 전문가로 구성되어 있다는 점은, 인간 평가 결과의 전문성과 신뢰성을 뒷받침하는 중요한 요소이다. 특히 장문 글의 품질을 평가하는 작업은 상당한 수준의 독해력과 비판적 사고를 요구하므로, 평가자의 학문적 배경은 평가 결과의 타당성에 직접적인 영향을 미친다. 비교 평가(pairwise comparison) 방식은 평가자가 두 대안 간의 상대적 우열만을 판단하면 되므로 절대 평가보다 평가자 간의 일관성이 높은 것으로 알려져 있으며, 두 글 간의 상대적 우열을 판단하는 것이 절대적 점수를 부여하는 것보다 인지적으로 덜 부담스럽기 때문이다.
논문은 인간 평가 결과가 자동 평가 결과와 전반적으로 일치하며, OmniThink가 Co-STORM에 비해 더 깊이 있고 독창적인 글을 생성한다는 것이 인간 평가자들에 의해서도 확인되었다고 보고한다. 네 가지 평가 기준 모두에서 OmniThink가 Co-STORM보다 우세한 것으로 평가되었으며, 이는 자동 평가 결과와 일관된 방향성을 보여준다. 자동 평가와 인간 평가의 이러한 일관성은 본 연구에서 사용된 자동 평가 지표들의 타당성을 간접적으로 검증하는 역할도 수행한다.
9. 평가 분산 분석
자동 평가의 안정성과 재현성을 검증하기 위해, 논문은 Prometheus-7B-v2.0을 사용한 세 차례의 평가 실행에 대한 분산(variance)을 보고한다.
| 방법 (Method) | Rel. 분산 | Brd. 분산 | Dep. 분산 | Nov. 분산 |
|---|---|---|---|---|
| RAG | 0.0027 | 0.0060 | 0.0092 | 0.0073 |
| oRAG | 0.0043 | 0.0071 | 0.0111 | 0.0132 |
| STORM | 0.0027 | 0.0052 | 0.0021 | 0.0085 |
| Co-STORM | 0.0032 | 0.0066 | 0.0036 | 0.0106 |
| OmniThink | 0.0011 | 0.0027 | 0.0042 | 0.0095 |
Table 4의 분산 분석 결과에서 도출되는 핵심 관찰은 다음과 같다.
- 모든 방법론에 대한 분산이 0.02 미만으로 상대적으로 작아, 자동 평가 결과의 안정성과 재현성이 확보되어 있다.
- OmniThink는 관련성(0.0011)과 폭(0.0027)에서 모든 방법론 중 가장 낮은 분산을 기록하여, 생성하는 글의 품질이 가장 일관적이다.
- oRAG는 깊이(0.0111)와 독창성(0.0132)에서 상대적으로 높은 분산을 보이는데, 이는 아웃라인 기반 접근법에서 아웃라인의 품질이 불안정할 경우 최종 글의 품질도 크게 변동할 수 있음을 반영한다.
10. WildSeek 데이터셋의 특성과 평가 방법론의 타당성
OmniThink의 평가에 사용된 WildSeek 데이터셋의 특성을 좀 더 상세히 분석하면, 실험 결과의 일반화 가능성에 대한 더 깊은 이해를 얻을 수 있다. WildSeek는 24개의 서로 다른 도메인에 걸쳐 100개의 데이터 포인트를 포함하고 있으며, 이 데이터셋의 강점은 도메인의 다양성에 있다. 과학, 기술, 역사, 문화, 예술, 사회 등 폭넓은 분야를 포괄함으로써, 특정 도메인에 편향된 평가를 피하고 시스템의 범용적인 장문 생성 능력을 평가할 수 있다. 그러나 100개라는 데이터 포인트의 수가 통계적으로 충분한지에 대해서는 논의의 여지가 있을 수 있으며, 각 도메인당 평균 약 4개의 주제만 포함된다는 점에서 도메인별 세밀한 분석에는 한계가 있을 수 있다.
평가 방법론의 타당성과 관련하여, Prometheus2 모델을 사용한 자동 평가의 특성도 고려할 필요가 있다. Prometheus2는 다른 언어 모델의 출력을 평가하기 위해 특화된 오픈소스 모델로, 사용자 정의 루브릭에 따라 텍스트를 0-5점 척도로 채점하는 능력을 갖추고 있다. 이 모델의 제한된 컨텍스트 윈도우로 인해, 평가 시 참고문헌 섹션이 제외되고 입력 텍스트가 2000단어 이하로 트리밍된다는 점은 평가의 한계로 지적될 수 있다. 장문 글의 특성상, 전체 글의 구조적 일관성이나 후반부의 내용 품질이 이 트리밍 과정에서 반영되지 않을 수 있기 때문이다. 그럼에도 불구하고 이 방법론은 STORM의 원래 평가 방식과 일치하며, 세 차례의 반복 실행에서 낮은 분산을 보여 안정적인 평가 결과를 제공한다는 점에서 그 타당성이 확보된다.
11. 관련 연구
10.1 NLP에서의 정보 탐색
정보 탐색(information seeking)에 대한 기존 연구는 주로 질의응답(QA) 시스템의 설계에 초점을 맞추어 왔다. 초기의 오픈 도메인 QA 방법론들은 사용자가 단일 쿼리를 통해 정보 요구를 충족할 수 있다는 가정 하에 설계되었다. 그러나 후속 연구들은 실제 시나리오에서 사용자가 단일 쿼리만으로 정보 요구를 충족하기 어려운 경우가 많다는 것을 인식하게 되었으며, 이에 따라 단일 쿼리를 여러 하위 쿼리로 분해하여 서로 다른 정보 조각을 검색하는 다중 하위 쿼리 검색 방법이 탐구되었다.
정보 탐색 연구의 발전 흐름을 정리하면 다음과 같다.
- 초기 단일 쿼리 방식: DrQA(Chen et al., 2017)와 같이 위키피디아를 지식 소스로 활용하여 단일 질문에 대한 답변 문단을 검색하는 방식
- 다중 하위 쿼리 방식: 복잡한 질문을 여러 하위 쿼리로 분해하여 검색하고 종합하는 방식(Peng et al., 2019; Chen et al., 2011)
- 검색 피드백 기반 방식: RaFe(Mao et al., 2024)와 같이 순위 피드백을 통해 RAG에서의 쿼리 리라이팅을 개선하는 방식
- 장문 질의응답: ELI5(Fan et al., 2019)와 같이 설명적 답변의 생성을 요구하는 벤치마크
OmniThink는 이러한 정보 탐색 연구의 맥락에서 중요한 진전을 나타낸다. 기존의 다중 하위 쿼리 방식이 검색 단계에서의 다양성을 높이는 데 초점을 맞추었다면, OmniThink는 검색된 정보에 대한 반성적 사고를 통해 후속 검색의 방향을 동적으로 조정한다는 점에서 차별화된다. 이는 단순히 더 많은 쿼리를 생성하는 것이 아니라, 이전 검색 결과에 대한 인지적 처리를 바탕으로 더 정교하고 목적 지향적인 쿼리를 생성하는 것을 의미한다. 이러한 접근법은 인간 연구자가 문헌 조사를 수행할 때 초기 자료에서 발견한 새로운 개념이나 참고문헌을 추적하여 점진적으로 더 깊은 수준의 지식에 접근하는 과정을 모사한다. 따라서 OmniThink는 정보 탐색의 단순한 자동화를 넘어, 탐색 과정 자체를 지능화하는 방향으로의 연구 흐름을 대표한다고 할 수 있다.
10.2 기계 작문
수동 작문에 수반되는 높은 비용으로 인해, 기계 작문은 최근 몇 년간 상당한 연구 관심을 받아 왔다. LLM과 RAG의 등장은 자동화된 작문에 새로운 가능성을 열었으며, 이 분야에서 다양한 접근법이 제안되었다. 대표적인 기계 작문 연구들을 분류하면 다음과 같다.
- 백과사전 스타일 생성: STORM(역할극 기반 위키피디아 글 작성), Co-STORM(사용자 참여형 정보 검색)
- 장문 대화형 생성: RecurrentGPT(RNN 개념을 LLM에 적용한 임의 길이 텍스트 생성)
- 다중 제약 생성: Suri(문체, 길이, 내용 포함 여부 등 다수의 제약 조건을 동시 충족)
- 전문 문서 생성: AutoPatent(특허 문서 자동 생성을 위한 다중 에이전트 프레임워크)
- 창작 글쓰기: Weaver(소설이나 시와 같은 문학적 텍스트의 자동 생성)
- 학술 서베이 생성: AutoSurvey(특정 연구 주제에 대한 서베이 논문 자동 작성)
이러한 다양한 기계 작문 연구들 중에서 OmniThink가 차지하는 독특한 위치는, 단순한 생성 파이프라인의 개선을 넘어 인지적 과정의 시뮬레이션을 도입했다는 점에 있다. 기존 연구들이 주로 "어떻게 더 잘 생성할 것인가"라는 생성 품질의 문제에 초점을 맞추었다면, OmniThink는 "어떻게 더 잘 사고할 것인가"라는 인지적 과정의 문제를 다룬다. 기계 작문의 발전 경로를 거시적으로 조망하면, 초기의 템플릿 기반 생성에서 통계적 언어 모델 기반 생성으로, 다시 신경망 기반 생성으로, 그리고 현재의 LLM + RAG 기반 생성으로 진화해 왔다. OmniThink가 제안하는 "사고 시뮬레이션 기반 생성"은 이 진화의 다음 단계로 볼 수 있으며, 단순한 패턴 매칭이나 정보 조합을 넘어 인지적 과정을 명시적으로 모델링하는 방향으로의 전환을 대표한다. 특히 최근 O1이나 DeepSeek-R1과 같은 추론 특화 모델의 등장과 맞물려, 사고 과정을 명시적으로 모델링하는 OmniThink의 접근법은 더욱 시의적절하며 향후 추론 모델과의 결합을 통한 추가적인 성능 향상의 가능성을 내포하고 있다.
10.3 검색 증강 생성(RAG)과의 관계
OmniThink는 넓은 의미에서 RAG 패러다임의 확장으로 볼 수 있으나, 기존 RAG와는 몇 가지 본질적인 차이를 지닌다. 기본적인 RAG와 발전적 RAG, 그리고 OmniThink의 핵심적 차이점을 비교하면 다음과 같다.
- 기본 RAG: 검색-생성의 단방향 흐름. 검색 결과에 대한 피드백 루프가 존재하지 않는다.
- Self-RAG: 모델이 검색의 필요성을 스스로 판단하고, 검색된 문서의 관련성을 평가하며, 최종 응답의 사실성을 자기 반성을 통해 검증한다.
- CRAG (Corrective RAG): 검색 결과의 품질을 평가하고 필요한 경우 검색을 수정하는 보정적 메커니즘을 추가한다.
- Graph RAG: 검색된 정보를 그래프 구조로 조직하여 더 효과적인 정보 활용을 가능하게 한다.
- OmniThink: 검색-반성-재검색의 반복적 사이클을 구현하며, 개념 풀이라는 외부 인지 구조를 활용하여 검색의 방향성과 깊이를 체계적으로 관리한다.
OmniThink의 정보 트리는 Graph RAG의 구조화된 정보 저장과 유사한 점이 있으나, 정보의 조직이 정적으로 이루어지는 것이 아니라 반복적인 확장 과정을 통해 동적으로 성장한다는 점에서 차별화된다. 또한 OmniThink의 개념 풀은 검색된 정보에 대한 메타 수준의 인지적 표현을 유지한다는 점에서, 단순한 정보 저장소를 넘어 인지적 도구로서의 역할을 수행한다. 이러한 구조적 혁신은 RAG 패러다임이 단순한 "외부 메모리 접근"에서 "외부 인지 프로세스"로 진화할 수 있는 가능성을 보여준다. 나아가, OmniThink의 정보 트리는 지식 그래프(knowledge graph)와의 통합을 통해 더욱 강력한 정보 관리 도구로 발전할 잠재력이 있으며, 개념 풀의 반성 메커니즘은 최근 주목받고 있는 체인 오브 씽킹(chain-of-thought) 프롬프팅이나 트리 오브 씽킹(tree-of-thought) 등의 구조화된 추론 기법과 결합하여, 더 정교한 인지적 처리를 가능하게 할 수 있다.
11. 한계점 및 향후 연구
OmniThink가 자동 평가와 인간 평가 모두에서 그 장점을 입증하였음에도 불구하고, 몇 가지 중요한 한계점이 존재한다. 논문이 직접 언급한 한계점과 이에 대한 향후 연구 방향을 정리하면 다음과 같다.
한계 1: 다중 모달 정보 미활용. 현재의 OmniThink는 검색과 텍스트 생성에만 국한되어 있으며, 오픈 도메인에 존재하는 방대한 양의 다중 모달 정보(이미지, 비디오, 오디오, 표, 그래프 등)는 활용되지 않고 있다. 실제 세계의 정보는 텍스트뿐만 아니라 다양한 모달리티로 존재하며, 이러한 다중 모달 정보를 효과적으로 활용할 수 있다면 생성되는 글의 품질과 풍부함이 크게 향상될 것으로 기대된다. 향후 연구에서는 다중 모달 정보를 정보 트리에 통합하고, 개념 풀의 반성 과정에서 다중 모달 통찰을 추출하는 방향으로의 확장이 필요하다.
한계 2: 개인화된 언어 스타일 미지원. OmniThink는 텍스트 생성에서 개인화된 언어 스타일을 고려하지 않는다. 현재 생성되는 텍스트는 학술적 성격이 강하며, 이는 일반 사용자의 읽기 선호도에 부적합할 수 있다. 기계 작문의 응용 분야는 블로그 포스트, 뉴스 기사, 교육 자료, 마케팅 콘텐츠 등 다양한 형태를 포함하며, 각각의 형태는 고유한 문체적 특성과 어조를 요구한다. 향후 연구에서는 사용자의 선호나 목표 독자층에 맞추어 글의 스타일을 조정할 수 있는 개인화 메커니즘의 도입이 고려될 수 있다.
한계 3: 검색 엔진 의존성. OmniThink는 검색 엔진의 품질과 가용성에 상당히 의존하고 있다. 검색 엔진의 색인 범위, 순위 알고리즘, 그리고 시간에 따른 변화 등이 OmniThink의 성능에 영향을 미칠 수 있다. 특히 특정 도메인(최신 과학 연구, 소규모 언어 커뮤니티의 주제 등)에서는 검색 엔진이 충분한 양의 관련 정보를 반환하지 못할 수 있다. 또한 검색 엔진 API의 호출 비용과 속도 제한도 실용적인 배포에서 고려해야 할 사항이며, 검색 결과의 시간적 변동성은 실험 재현성에도 영향을 줄 수 있다.
한계 4: 계산 비용. 반복적 확장-반성 사이클은 상당한 계산 비용을 수반한다. 각 사이클에서 여러 차례의 LLM 추론과 검색 엔진 호출이 필요하며, 깊이가 증가할수록 비용은 기하급수적으로 증가할 수 있다. 적절한 깊이를 자동으로 결정하는 적응적 종료 조건의 설계가 향후 연구에서 다루어져야 할 것이다.
한계 5: 미발견 지식 경계의 존재. 깊이 분석에서 관찰된 바와 같이, 정보 경계와 인지 경계 외에 아직 식별되지 않은 다른 종류의 지식 경계가 존재할 가능성이 있으며, 이를 식별하고 정의하는 것은 기계 작문의 품질을 한 단계 더 끌어올리기 위한 중요한 연구 방향이다.
논문이 제시한 향후 연구 방향은 더 심층적인 추론과 인간-컴퓨터 상호작용을 결합한 더 발전된 기계 작문 방법론의 탐구이다. 예를 들어, OmniThink의 확장-반성 사이클에서 특정 시점에 인간 전문가의 피드백을 수용하여 탐색 방향을 조정하는 인간 참여형 OmniThink를 구상해볼 수 있다. OmniThink의 모델 불가지론적 특성을 활용하여, 향후 더 강력한 LLM이 등장할 때 이를 즉시 통합하여 성능을 향상시킬 수 있다는 확장성도 중요한 장점이다. 특히 추론 능력이 강화된 차세대 모델들이 OmniThink의 반성 과정에서 더 깊이 있는 통찰을 추출할 수 있을 것으로 기대되며, 이는 인지 경계의 추가적인 확장을 가능하게 할 것이다.
12. OmniThink의 실용적 함의와 응용 전망
OmniThink의 연구 결과가 실용적인 응용 분야에 미치는 함의를 살펴보면, 여러 가지 유망한 응용 시나리오를 식별할 수 있다.
- 자동화된 백과사전 글 작성: 기존 STORM이 이 분야에서 선구적인 역할을 하였으나, OmniThink의 반복적 탐색-반성 메커니즘은 더 깊이 있고 중복이 적은 글을 생성할 수 있다.
- 학술 서베이 논문 자동 작성: 서베이 논문은 특정 연구 분야의 다양한 논문을 수집, 분석, 종합하는 과정을 필요로 하며, 이는 OmniThink의 정보 트리 확장과 개념 풀 반성 과정과 매우 유사하다.
- 기업 보고서 자동 생성: 다양한 전문적 글쓰기 과제에서 OmniThink의 프레임워크가 적용될 수 있다.
- 교육 콘텐츠 개발: 학습자 수준에 맞춘 깊이 있는 교육 자료의 자동 생성에 활용될 수 있다.
OmniThink의 모델 불가지론적 특성은 실용적 배포에서 특히 중요한 장점이다. 실험 결과에서 확인한 바와 같이, OmniThink는 GPT-4o와 같은 강력한 상업 모델뿐만 아니라 Qwen-Plus와 같은 상대적으로 약한 모델에서도 효과적으로 작동하며, 특히 약한 모델에서의 성능 향상 폭이 더 크다. 이는 고비용의 최신 모델에 접근하기 어려운 조직이나 개인도 OmniThink 프레임워크를 통해 높은 품질의 장문 글을 생성할 수 있음을 의미한다. 또한 향후 더 강력한 모델이 출시될 때, OmniThink 프레임워크에 새로운 모델을 단순히 플러그인하는 것만으로도 성능 향상을 기대할 수 있다.
다만 반복적인 확장-반성 사이클에 수반되는 계산 비용과 지연 시간은 실시간 또는 준실시간 응답이 필요한 응용에서는 제약이 될 수 있으며, 이를 최적화하기 위한 병렬화 전략이나 캐싱 메커니즘의 설계가 향후 공학적 과제로 남는다.
OmniThink가 제안한 지식 경계의 개념적 프레임워크는 기계 작문을 넘어 다양한 LLM 응용 분야에 적용될 수 있는 잠재력을 지니고 있다. 예를 들어, 과학적 가설 생성, 복잡한 의사결정 지원, 교육 콘텐츠 생성, 법률 문서 분석 등 깊이 있는 사고와 포괄적인 정보 수집이 요구되는 과제에서, 정보 경계와 인지 경계의 개념을 적용하여 시스템의 한계를 진단하고 맞춤형 해결책을 설계할 수 있다. 정보 경계의 확장이 필요한 과제에는 OmniThink의 정보 트리 확장 메커니즘을, 인지 경계의 확장이 필요한 과제에는 개념 풀의 반성 메커니즘을 각각 적용하거나, 두 메커니즘을 조합하여 활용할 수 있을 것이다. 이러한 범용적 적용 가능성은 OmniThink의 연구가 기계 작문이라는 특정 과제를 넘어 LLM 시스템 설계의 일반적인 원칙에 기여하는 것으로 평가할 수 있게 해준다.
14. 결론
본 논문은 인간의 반복적 확장과 반성의 느린 사고 과정을 모사하는 기계 작문 프레임워크인 OmniThink를 제안하였다. OmniThink의 핵심 혁신은 정보 트리와 개념 풀이라는 두 가지 구성요소를 통해 LLM의 정보 경계와 인지 경계를 동시에 확장하는 메커니즘에 있다. 정보 트리는 주제에 대한 지식을 계층적으로 조직하여 정보의 범위와 깊이를 확장하며, 개념 풀은 수집된 정보에 대한 반성적 사고를 통해 핵심 통찰을 추출하고 인지 체계를 갱신함으로써 인지 경계를 확장한다.
실험 결과의 핵심적인 발견을 정리하면 다음과 같다.
- OmniThink는 네 가지 백본 모델(GPT-4o, Qwen-Plus, O1-preview, DeepSeek-R1) 모두에서 기존 방법론(RAG, oRAG, STORM, Co-STORM)을 상회하는 성능을 달성하였다.
- 특히 독창성(Novelty)과 지식 밀도(Knowledge Density)에서의 개선이 두드러졌다.
- 상대적으로 약한 모델에서 OmniThink의 성능 향상 폭이 더 크게 나타나, "이퀄라이저" 역할을 수행한다.
- OmniThink는 높은 정보 다양성과 높은 지식 밀도를 동시에 달성한 유일한 방법론이다.
- 확장(Expansion)은 주로 내용적 측면(폭, 깊이, 지식 밀도)에, 반성(Reflection)은 주로 창의적 측면(독창성)에 상보적으로 기여한다.
- 인간 평가에서도 자동 평가와 일관된 결과가 확인되었다.
지식 경계라는 관점에서의 문제 분석 역시 본 연구의 중요한 기여이다. 기존에 단편적으로 다루어지던 장문 생성의 도전 과제들을 정보 경계와 인지 경계라는 두 가지 축으로 체계적으로 분류함으로써, 각 문제에 대한 맞춤형 해결책을 설계할 수 있는 이론적 프레임워크를 제공하였다. 깊이 분석을 통해 이 두 경계 외에 아직 식별되지 않은 추가적인 경계가 존재할 수 있음을 발견한 것은, 기계 작문 분야의 새로운 연구 방향을 제시하는 중요한 통찰이다.
OmniThink의 연구 결과가 갖는 더 넓은 의미를 고려해보면, 이 연구는 LLM 기반 시스템 설계에서 "생성 품질의 향상"이라는 목표를 달성하기 위한 두 가지 상보적 경로를 제시한다. 첫 번째 경로는 모델 자체의 능력을 향상시키는 것으로, 더 큰 파라미터, 더 나은 훈련 데이터, 더 정교한 정렬 기법 등을 통해 달성할 수 있다. 두 번째 경로는 모델을 둘러싼 시스템 아키텍처를 개선하는 것으로, OmniThink가 채택한 접근법이 바로 이에 해당한다. Qwen-Plus와 같은 약한 모델이 OmniThink를 통해 GPT-4o의 기본 RAG에 근접하는 성능을 달성한 것은, 시스템 수준의 혁신이 모델 수준의 한계를 상당 부분 보완할 수 있음을 실증적으로 보여준다.
또한 OmniThink가 제안한 지식 밀도(KD) 지표는 생성된 글의 중복성을 정량적으로 평가할 수 있는 새로운 도구를 제공하며, 이 지표는 향후 장문 생성 연구에서 표준적인 평가 지표로 널리 활용될 수 있을 것으로 기대된다. 기존의 평가 지표들이 주로 관련성과 정확성에 초점을 맞추어 왔던 반면, KD 지표는 중복 제거 후의 고유 정보 밀도를 직접 측정함으로써, 인간 독자의 경험과 더 밀접하게 관련된 품질 차원을 포착한다.
종합적으로, OmniThink는 기계 작문 분야에서 "더 많이 검색하기"에서 "더 깊이 사고하기"로의 패러다임 전환을 구현한 의미 있는 연구이다. 인간의 반성적 실천이론에서 영감을 받은 이 접근법은, LLM이 단순한 정보 처리 도구를 넘어 사고하는 주체로서 기능할 수 있는 가능성을 보여준다. 정보 수집의 체계화, 인지적 처리의 명시화, 그리고 반복적 사고의 구현이라는 OmniThink의 세 가지 핵심 혁신은 각각 독립적으로도 의미가 있지만, 이 세 요소가 유기적으로 결합되어 시너지를 발휘한다는 점이 OmniThink의 진정한 가치이다. 향후 다중 모달 정보의 통합, 개인화된 스타일 적응, 인간-AI 협업 메커니즘의 도입, 그리고 미발견 지식 경계의 식별 등의 연구가 진행됨에 따라, OmniThink의 기본 프레임워크 위에 더욱 강력하고 유연한 기계 작문 시스템이 구축될 것으로 기대된다. 기계 작문의 궁극적인 목표는 인간 전문가 수준의 글을 자동으로 생성하는 것이며, OmniThink는 이 목표를 향한 여정에서 정보 수집의 체계화, 인지적 처리의 명시화, 그리고 반복적 사고의 구현이라는 중요한 이정표를 세운 것으로 평가할 수 있다.