Titans: Learning to Memorize at Test Time
https://arxiv.org/abs/2501.00663
Liang Wang, Haonan Chen, Nan Yang, Xiaolong Huang, Zhicheng Dou, Furu Wei | Microsoft Research, Renmin University of China | arXiv:2501.14342 | 2025년 1월
1. 서론
Retrieval-Augmented Generation(RAG)은 대규모 언어 모델(LLM)의 환각(hallucination) 문제를 해결하고 최신 정보를 반영하기 위한 핵심 기술로 자리잡았다. 기업 환경에서 독점 데이터 소스와 대규모 기반 모델을 통합하여 신뢰성 있는 응답을 생성하는 데 필수적인 역할을 하고 있다. 대규모 언어 모델은 수조 개의 토큰으로 구성된 대규모 데이터셋에서 훈련되지만, 배포 후에는 고정된 상태로 유지된다. 그러나 이러한 모델들은 종종 롱테일 사실적 지식을 기억하는 데 어려움을 겪거나 거짓 주장을 환각하여, 실제 시나리오에서 신뢰할 수 없는 응답을 초래한다.
기존 RAG 시스템은 생성 전 단일 검색 단계만을 수행하는 순차적 파이프라인에 의존하고 있어, 복잡한 쿼리를 처리하는 데 근본적인 한계를 가진다. 현대 RAG 시스템의 효과성은 검색된 정보의 품질에 크게 좌우된다. Dense retriever는 효율성을 위해 bi-encoder 아키텍처를 사용하여 문서와 쿼리를 고정 크기 벡터 표현으로 압축한다. 이러한 아키텍처적 선택은 빠른 근사 최근접 이웃 탐색 알고리즘을 가능하게 하지만, 동시에 복잡한 쿼리를 처리하는 표현력을 제한한다. 특히 multi-hop 추론 태스크에서는 처음에 어떤 정보를 검색해야 하는지 불분명하며, 추론 과정의 진행 상태에 따라 결정이 이루어져야 한다.
Microsoft Research와 중국인민대학교 연구팀은 이러한 한계를 극복하기 위해 CoRAG(Chain-of-Retrieval Augmented Generation)를 제안했다. 이 방법은 현재 상태에 기반하여 관련 정보를 동적으로 검색하고 후속 검색 단계를 계획하는 프레임워크다. 테스트 시점에 검색 단계 수를 조정함으로써 모델은 쿼리의 다양한 측면을 탐색하고, 검색기가 유용한 정보를 반환하지 않을 때 다양한 쿼리 재작성 전략을 실험할 수 있다. 이 패러다임은 복잡한 질문에 답하기 위해 반복적으로 정보를 탐색하는 인간의 문제 해결 과정을 모방한다.
본 논문의 주요 기여는 다음과 같다:
- Rejection sampling을 통한 중간 검색 체인의 자동 생성 - 기존 QA 데이터셋을 활용하면서 검색 체인 학습이 가능
- 다양한 테스트 시점 디코딩 전략 제안 - Greedy decoding, Best-of-N sampling, Tree search
- Multi-hop QA에서 10 EM 점수 이상의 성능 향상 - 강력한 베이스라인 대비 대폭 개선
- KILT 벤치마크에서 새로운 최고 성능 달성 - 다양한 지식 집약적 태스크에서 SOTA
2. 관련 연구
2.1 Retrieval-Augmented Generation (RAG)
RAG는 정보 검색 기술과 생성 모델을 통합하여 생성된 콘텐츠의 품질과 사실적 정확성을 향상시킨다. LLM에 웹 브라우징 기능을 제공함으로써 RAG 시스템은 실시간 데이터에 접근하여 최신이면서 근거 있는 응답을 제공할 수 있다. 검색된 정보의 관련성과 품질은 RAG 시스템의 효과에 핵심적이다. 최근 연구의 상당 부분은 더 나은 범용 텍스트 임베딩 개발에 집중해왔지만, 텍스트 임베딩은 효율성을 위해 고정 크기 벡터 표현에 의존하기 때문에 복잡한 쿼리를 다루는 데 한계가 있다.
이러한 제약을 완화하기 위해 최근 연구는 단일 검색 후 생성의 기존 패러다임을 다단계 반복 검색 및 생성으로 확장했다. FLARE는 LLM이 생성 과정에서 언제, 무엇을 검색할지 능동적으로 결정하도록 프롬프트한다. ITER-RETGEN은 검색 증강 생성과 생성 증강 검색을 교차하여 multi-hop QA 태스크에서 개선을 보여주었다. Self-RAG는 LLM이 자기 성찰을 통해 적응적으로 검색, 생성, 비평하도록 하여 개방형 도메인 QA와 장문 생성 태스크에서 사실적 정확성을 향상시켰다.
2.2 테스트 시점 연산 스케일링
LLM에게 최종 답변을 직접 생성하도록 프롬프트하는 대신, Chain-of-Thought (CoT)는 모델이 단계별로 생각하게 함으로써 수학적 추론 태스크에서 성능을 대폭 향상시킬 수 있음을 보여주었다. Tree-of-Thought (ToT)는 트리 구조를 채택하여 CoT의 아이디어를 확장하여 모델이 탐색 공간을 더 포괄적으로 탐색할 수 있게 한다. OpenAI o1은 대규모 강화학습을 수행하여 고급 추론 데이터셋에서 유망한 테스트 시점 스케일링 동작을 보여주지만, 기술적 세부 사항은 공개되지 않았다.
RAG 영역에서 테스트 시점 연산은 더 많은 문서를 검색하거나 추가 검색 단계를 수행함으로써 증가시킬 수 있다. LongRAG는 장문 컨텍스트 LLM과 더 많은 검색 문서를 통합하여 RAG 성능을 향상시킬 수 있다고 주장한다. IterDRAG는 few-shot 프롬프팅과 최대 55M 토큰까지의 반복 검색을 통해 테스트 시점 스케일링 법칙을 경험적으로 검토한다. Search-o1은 오픈소스 QwQ 모델과 Bing의 능동적 검색을 결합하여 지식 집약적 태스크에서 경쟁력 있는 결과를 달성한다.
3. 문제 정의
3.1 기존 RAG 시스템의 핵심 문제
기존 RAG 시스템의 핵심 문제는 단일 검색 단계의 한계에 있다. 복잡한 multi-hop 질문의 경우, 한 번의 검색으로 필요한 모든 정보를 얻기 어렵다. 예를 들어 "A 감독이 만든 영화에서 주연을 맡은 배우의 출생지는?"과 같은 질문은 여러 단계의 추론과 검색이 필요하다.
수학적으로, 기존 RAG는 쿼리 Q에 대해 문서 D를 검색하고 답변 A = LLM(Q, D)를 생성한다. 그러나 이 접근법은 검색기의 한 번의 시도에 전적으로 의존하므로, 불완전한 검색 결과로 인해 복잡한 쿼리에서 성능이 저하된다.
3.2 검색 체인 개념
CoRAG는 이 문제를 해결하기 위해 검색 체인(retrieval chain) 개념을 도입한다. 각 체인은 일련의 하위 쿼리 Q_{1:L} = {Q_1, Q_2, ..., Q_L}와 해당 하위 답변 A_{1:L}로 구성된다. 하위 쿼리 Q_i = LLM(Q_{<i}, A_{<i}, Q)는 원래 쿼리 Q와 이전의 하위 쿼리 및 답변을 기반으로 LLM을 샘플링하여 생성된다.
4. 제안 방법론

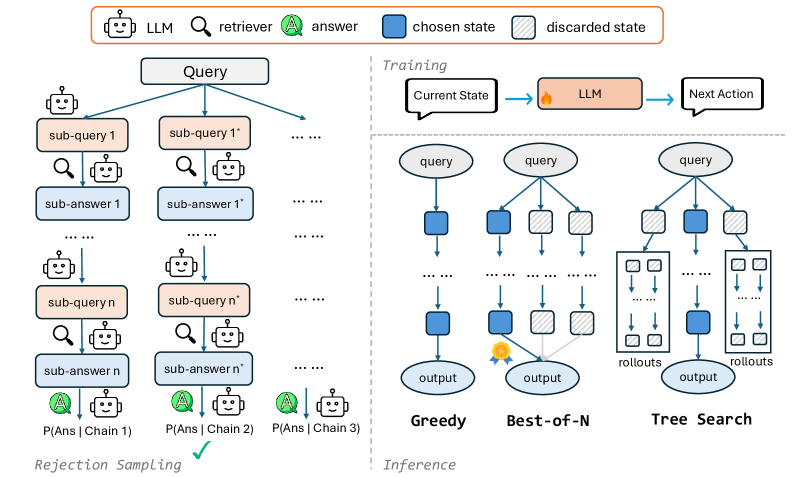
4.1 검색 체인 생성 (Rejection Sampling)
대부분의 RAG 데이터셋은 쿼리 Q와 최종 답변 A만 제공하며, 중간 검색 단계는 포함하지 않는다. CoRAG는 rejection sampling을 통해 검색 체인을 자동으로 생성한다.
생성 과정:
- LLM으로 하위 쿼리 Q_i 생성
- 텍스트 검색기로 상위 k개 관련 문서 D_{1:k}^{(i)} 검색
- LLM으로 하위 답변 A_i = LLM(Q_i, D_{1:k}^{(i)}) 생성
- 체인이 최대 길이 L에 도달하거나 A_i가 정답 A와 일치할 때까지 반복
검색 체인의 품질을 평가하기 위해 체인 정보를 조건으로 한 정답의 log-likelihood log P(A|Q, Q_{1:L}, A_{1:L})를 계산하고, 가장 높은 점수를 받은 체인을 선택하여 원본 QA 데이터셋을 증강한다.
4.2 모델 훈련
증강된 데이터셋의 각 훈련 인스턴스는 (Q, A, Q_{1:L}, A_{1:L}) 튜플로 표현된다. 표준 next-token prediction 목표를 사용하여 통합 멀티태스크 학습 프레임워크에서 LLM을 파인튜닝한다.
모델은 세 가지 태스크에서 동시에 훈련된다:
하위 쿼리 예측:
$$L_{sub_query} = -\log P(Q_i | Q, Q_{<i}, A_{<i}), \quad i \in [1, L]$$
하위 답변 예측:
$$L_{sub_answer} = -\log P(A_i | Q_i, D_{1:k}^{(i)}), \quad i \in [1, L]$$
최종 답변 예측:
$$L_{final_answer} = -\log P(A | Q, Q_{1:L}, A_{1:L}, D_{1:k})$$
cross-entropy 손실은 타겟 출력 토큰에 대해서만 계산된다. 데이터 생성과 모델 훈련에 동일한 프롬프트 템플릿을 재사용하므로, 파인튜닝된 모델을 다음 라운드의 rejection sampling에 반복적으로 활용할 수 있다.
4.3 테스트 시점 스케일링
훈련된 CoRAG 모델에 대해 성능과 테스트 시점 연산 간의 트레이드오프를 제어하기 위한 여러 디코딩 전략을 제안한다. 테스트 시점 연산은 검색 비용을 제외한 총 토큰 소비량으로 측정된다.
Greedy Decoding:
L개의 하위 쿼리와 해당 하위 답변을 순차적으로 생성한다. 최종 답변은 훈련 단계에서 사용된 것과 동일한 프롬프트 템플릿을 사용하여 생성된다.
Best-of-N Sampling:
온도 0.7로 N개의 검색 체인을 샘플링하고, 최적의 체인을 선택하여 최종 답변을 생성한다. 테스트 시점에 정답을 사용할 수 없으므로, "관련 정보를 찾을 수 없음"의 조건부 log-likelihood를 각 체인에 대한 페널티 점수로 계산하여 가장 낮은 페널티 점수를 가진 체인을 선택한다.
Tree Search:
검색 체인 롤아웃을 포함한 너비 우선 탐색(BFS) 변형을 구현한다. 각 단계에서 현재 상태를 여러 하위 쿼리로 확장하고, 평균 페널티 점수가 가장 낮은 상태를 유지한다.
5. 실험 결과
5.1 실험 설정
데이터셋:
- Multi-hop QA 데이터셋: 2WikiMultihopQA, HotpotQA, Bamboogle, MuSiQue
- KILT 벤치마크: NQ, TriviaQA, HotpotQA, FEVER, T-REx, zsRE, WoW 등 다양한 지식 집약적 태스크
모델:
- 베이스 모델: Llama-3.1-8B-Instruct
- 텍스트 검색기: E5-large
- 검색 코퍼스: KILT의 영어 위키피디아 (약 3,600만 passage)
훈련 설정:
- Multi-hop QA 데이터셋: 125k 훈련 인스턴스
- KILT 벤치마크: 660k 인스턴스 (서브샘플링 후)
- 최대 시퀀스 길이: 3k 토큰
- 1 에폭 파인튜닝
5.2 Multi-hop QA 결과
| 모델 | 2WikiMQA | HotpotQA | Bamboogle | MuSiQue |
|---|---|---|---|---|
| Llama-3.1-8B (Few-shot) | 32.8 | 25.2 | 28.8 | 8.5 |
| GPT-4o (Few-shot) | 42.3 | 35.6 | 56.0 | 18.2 |
| Self-RAG-7B | 25.8 | 29.2 | 32.0 | 11.3 |
| ITER-RETGEN | 41.2 | 33.4 | 48.0 | 14.5 |
| IterDRAG (Gemini) | 45.2 | 38.7 | 64.0 | 22.8 |
| Search-o1-32B | 47.6 | 39.8 | 72.0 | 24.1 |
| Fine-tuned Llama-8B | 48.2 | 40.1 | 52.0 | 25.3 |
| CoRAG-8B (L=6) | 58.3 | 48.5 | 68.0 | 35.2 |
CoRAG-8B는 8B 파라미터만으로 대부분의 데이터셋에서 Search-o1-32B를 포함한 모든 베이스라인을 크게 능가했다. 특히 MuSiQue에서 기존 최고 성능 대비 10 EM 점수 이상 향상을 보였다. Bamboogle 데이터셋은 125개 인스턴스만 포함하여 분산이 크며, 일부 질문은 검색에 사용된 위키피디아 덤프보다 최신 지식이 필요하다.
5.3 KILT 벤치마크 결과
| 모델 | NQ | TQA | HoPo | FEVER | T-REx | zsRE | WoW | Avg |
|---|---|---|---|---|---|---|---|---|
| KILT-RAG | 26.7 | 48.5 | 14.4 | 38.1 | 23.7 | 19.7 | 13.1 | 26.3 |
| SEAL | 42.8 | 74.0 | 44.3 | 76.5 | 74.8 | 73.5 | 14.6 | 57.2 |
| Atlas-11B | 64.1 | 80.3 | 51.2 | 91.4 | 81.4 | 90.1 | 24.2 | 68.9 |
| RA-DIT 65B | 66.0 | 82.5 | 52.8 | 91.8 | 83.0 | 91.2 | 25.1 | 70.3 |
| FiD w/ RS | 67.2 | 83.1 | 54.6 | 91.4 | 84.2 | 91.8 | 25.8 | 71.2 |
| CoRAG-8B | 68.2 | 84.1 | 58.9 | 91.6 | 85.3 | 93.4 | 27.8 | 72.8 |
CoRAG-8B는 KILT 벤치마크의 거의 모든 태스크에서 새로운 최고 성능을 달성했다. 8B 파라미터만으로 65B 모델인 RA-DIT를 능가한 점이 주목할 만하다. FEVER에서만 11B 파라미터의 더 큰 모델에 근소하게 뒤처졌다.
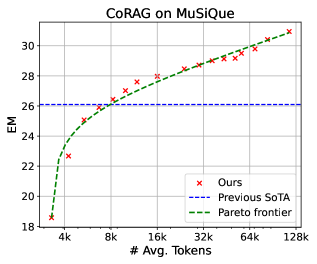
5.4 테스트 시점 연산 스케일링
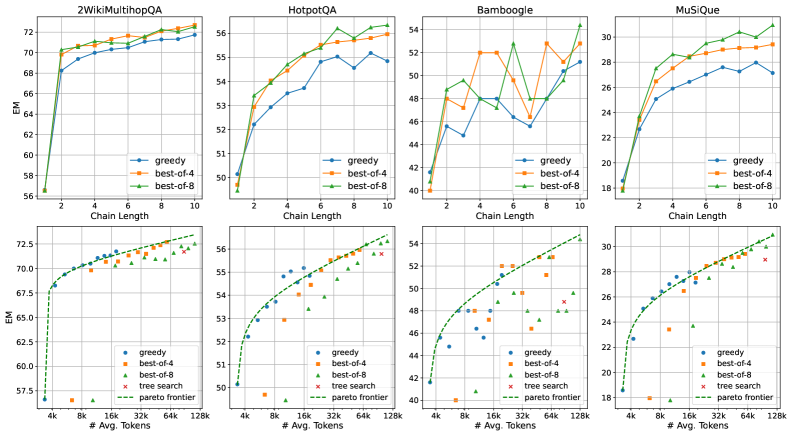
OpenAI o1과 마찬가지로, CoRAG 모델은 모델 가중치를 업데이트하지 않고도 테스트 시점 연산을 스케일링하여 더 나은 성능을 달성할 수 있다. 테스트 시점 연산을 제어하는 여러 방법이 있다:
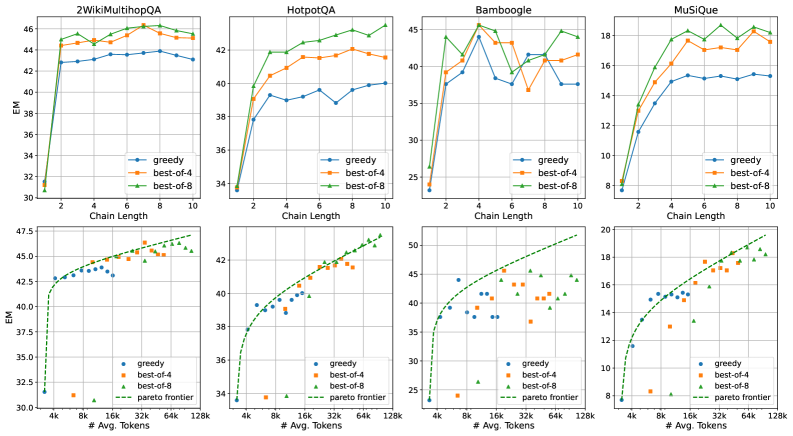
- 검색 체인 길이 L: L이 작을 때 증가시키면 상당한 성능 향상, L이 커지면 이득 감소
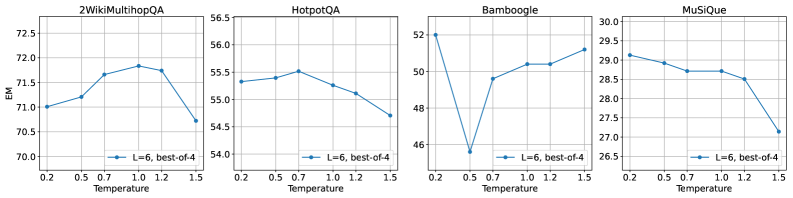
- 샘플링 체인 수 N: Best-of-N 샘플링에서 N을 증가시키면 데이터셋에 따라 효과가 다름
EM 점수와 토큰 소비 사이의 Pareto frontier는 최대 128k 토큰까지 log-linear 관계를 대략적으로 따르지만, 스케일링 동작은 데이터셋마다 다르다.
6. 분석
6.1 반복적 Rejection Sampling
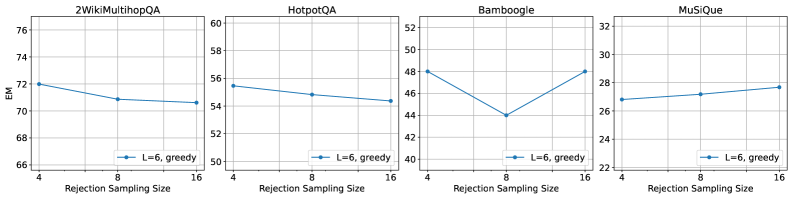
CoRAG 프레임워크는 LLM 후훈련에서 사용되는 반복적 rejection sampling과 유사하게 반복적 훈련을 통한 자기 개선을 가능하게 한다. 결과는 혼합되어 있어, 2WikiMultihopQA 데이터셋에서는 성능 향상을 보이지만 다른 데이터셋에서는 약간의 하락을 보인다. 이는 instruction-tuned LLM이 이미 고품질 검색 체인을 생성하는 강력한 능력을 갖추고 있음을 나타낸다.
6.2 다양한 검색기에 대한 강건성
| 데이터셋 | E5-large | E5-base | BM25 |
|---|---|---|---|
| 2WikiMQA | 58.3 | 52.1 | 48.7 |
| HotpotQA | 48.5 | 43.2 | 39.8 |
| MuSiQue | 35.2 | 30.8 | 27.4 |
E5-large 대신 두 가지 더 약한 대안(E5-base, BM25)으로 교체했을 때, 모든 데이터셋에서 더 많은 테스트 시점 연산 투자 시 일관된 성능 향상을 관찰했다. 더 강한 검색기가 절대적 성능에서는 우수하지만, CoRAG의 반복적 쿼리 재구성이 약한 검색기의 한계를 효과적으로 보완한다.
6.3 Weak-to-Strong 일반화
반복적인 샘플링과 autoregressive 생성이 필요하므로, 검색 체인 생성 과정은 모델 훈련보다 더 많은 GPU 시간이 소요된다. 이 비용을 줄이기 위한 전략으로 약한 LLM으로 검색 체인을 생성하고 이후 강한 LLM을 증강된 데이터셋에서 파인튜닝할 수 있다.
| 체인 생성 모델 | 2WikiMQA | HotpotQA | MuSiQue |
|---|---|---|---|
| Llama-1B | 51.2 | 41.3 | 28.6 |
| Llama-3B | 57.8 | 47.9 | 34.5 |
| Llama-8B | 58.3 | 48.5 | 35.2 |
| GPT-4o | 60.1 | 50.2 | 37.8 |
Llama-3B를 사용하면 8B 모델과 매우 유사한 성능을 달성하는 반면, Llama-1B는 눈에 띄는 성능 하락을 보인다. GPT-4o와 같은 더 강한 모델에서 증류하면 추가적인 성능 향상을 얻을 수 있어, 검색 체인의 품질이 최종 성능에 중요함을 나타낸다.
6.4 검색 품질 향상
| 데이터셋 | Recall@10 (E5) | Recall@10 (CoRAG) | 향상 |
|---|---|---|---|
| 2WikiMQA | 45.2 | 62.8 | +17.6 |
| HotpotQA | 52.3 | 68.5 | +16.2 |
| Bamboogle | 38.7 | 58.2 | +19.5 |
| MuSiQue | 31.2 | 55.6 | +24.4 |
CoRAG는 모든 데이터셋과 recall 임계값에서 일관되게 검색 품질을 향상시켰다. 특히 단일 단계 검색이 가장 어려운 MuSiQue와 Bamboogle에서 개선이 두드러졌다. 이는 CoRAG의 반복적 쿼리 재구성 및 분해 전략이 전통적인 dense retrieval의 한계를 효과적으로 해결함을 나타낸다.
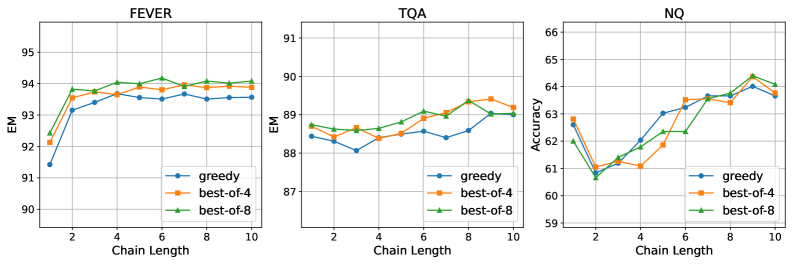
6.5 Chain-of-Retrieval이 항상 도움이 되는가?
Multi-hop QA 데이터셋은 복잡한 추론 능력을 평가하도록 특별히 설계되어 chain-of-retrieval 메커니즘의 혜택을 받을 것으로 예상된다. 반면, 단일 검색 단계로 충분한 태스크에서는 이점이 미미한 경향이 있다. NQ와 TriviaQA 같은 데이터셋은 (대부분) 단일 홉 특성으로 알려져 있다. 이 현상은 디코딩 전략이 쿼리의 복잡성에 따라 적응적이어야 함을 시사한다.
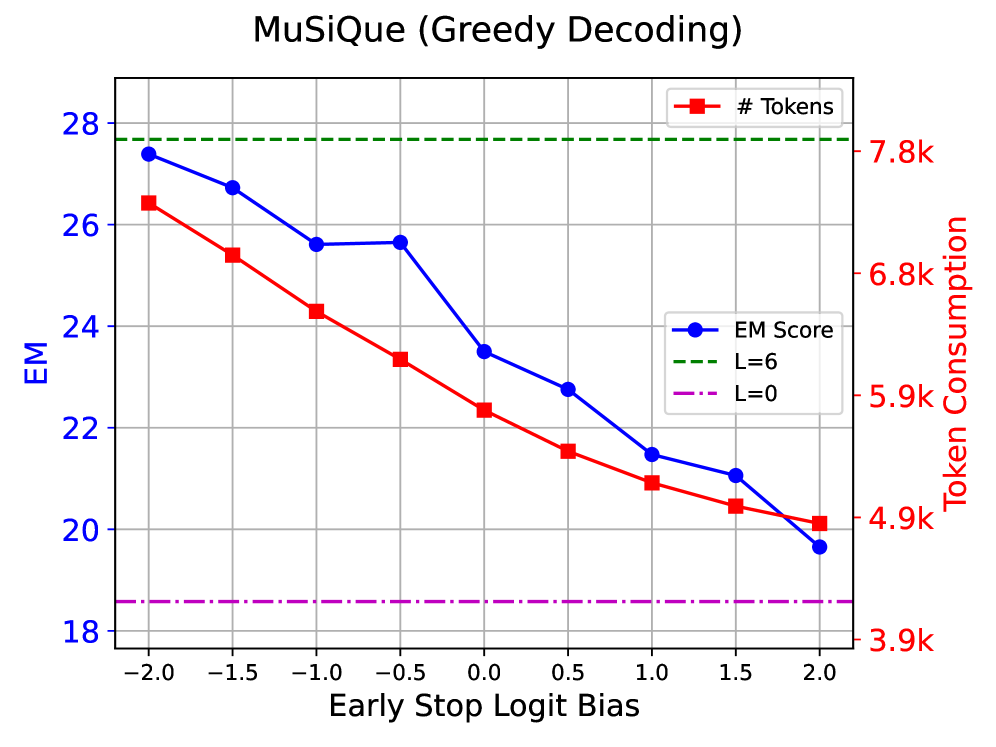
6.6 테스트 시점 조기 중단 학습
항상 L번의 검색 단계를 수행하는 대신, 테스트 시점에 중단하는 방법을 학습하는 모델 변형을 탐색한다. 각 검색 단계 후, 모델은 지금까지 수집된 정보가 쿼리에 답하기에 충분한지 예측하도록 프롬프트된다.
조기 중단은 일정량의 토큰 할당량을 절약할 수 있지만, 성능 저하의 비용이 따른다. 최적의 구성은 데이터셋 특성과 품질 기대치에 따라 달라진다.
7. 핵심 통찰 및 의의
7.1 자동화된 데이터 증강
Rejection sampling을 통해 수동 어노테이션 없이 중간 검색 체인을 자동 생성할 수 있다. 이는 기존 QA 데이터셋을 그대로 활용하면서도 검색 체인 학습이 가능하게 한다. 특히 few-shot 프롬프팅이나 독점 모델로부터의 증류에만 의존하지 않고, LLM을 명시적으로 훈련하여 단계별로 검색하도록 하는 새로운 접근법을 제시한다.
7.2 유연한 테스트 시점 스케일링
OpenAI o1과 유사하게 테스트 시점 연산량을 조절하여 성능과 비용 간의 트레이드오프를 관리할 수 있다. 토큰 소비와 성능 간에 log-linear 관계가 존재함을 실증적으로 보였다. 이 관찰은 실무자가 품질 요구 사항에 따라 테스트 시점 연산 할당에 대한 정보에 입각한 결정을 내리는 데 도움이 된다.
7.3 강건한 일반화
약한 검색기(E5-base, BM25)에서도 일관된 성능 향상을 보였으며, 약한 LLM으로 생성한 체인으로도 강한 LLM을 효과적으로 훈련할 수 있는 weak-to-strong generalization을 확인했다. 텍스트 검색기 품질 향상은 CoRAG의 성능 이득을 더욱 증폭시킬 수 있는 직교 차원을 나타낸다.
7.4 효율적인 모델 크기
8B 파라미터만으로 65B 모델을 능가하는 성능을 달성하여, 반복적 검색 체인 접근법의 효율성을 입증했다. 이는 단순히 모델 크기를 키우는 것보다 검색과 추론의 반복이 더 효과적일 수 있음을 시사한다.
8. 한계점 및 향후 연구
저자들이 언급한 한계점:
- 짧고 검증하기 쉬운 답변을 가진 태스크에 주로 집중 - 장문 생성에 대한 검증 필요
- 현재 연구 환경에서 장문 생성에 대한 강건한 평가 지표의 부재
- 환각 위험이 여전히 존재하므로 실제 배포 시 주의 필요
향후 연구 방향:
- 더 복잡하고 경제적 가치가 높은 RAG 태스크로 확장
- 장문 생성에서의 CoRAG 적용 및 평가
- 쿼리 복잡도에 따른 동적 연산 할당
- Tree search 전략의 추가 탐색
9. 결론
CoRAG는 LLM이 복잡한 쿼리에 답하기 위해 반복적으로 검색하고 추론하도록 훈련하는 프레임워크다. Rejection sampling을 통해 중간 검색 체인을 자동 생성하여 수동 어노테이션의 필요성을 제거했다. 테스트 시점에 다양한 디코딩 전략으로 성능과 연산량 간의 트레이드오프를 관리할 수 있다.
실험 결과, CoRAG-8B는 multi-hop QA 데이터셋과 KILT 벤치마크 모두에서 더 큰 LLM 기반 베이스라인들을 능가하는 최고 성능을 달성했다. 특히 multi-hop 추론이 필요한 태스크에서 10 EM 점수 이상의 향상을 보였다. 포괄적인 분석을 통해 스케일링 동작과 일반화 능력을 이해할 수 있었다.
이 연구는 사실적이고 신뢰할 수 있는 AI 시스템 구축을 향한 중요한 진전을 나타내며, RAG 도메인에서 향후 연구의 유망한 방향을 제시한다.
References
- 논문 원문: https://arxiv.org/abs/2501.14342
- GitHub 코드: https://github.com/microsoft/LMOps/tree/main/corag
- 본 글은 arXiv 논문을 기반으로 작성된 리뷰입니다.
'[논문 리뷰] > [최신 논문]' 카테고리의 다른 글
| [arXiv 2501.13106] VideoLLaMA 3: 비전 중심 설계로 이미지와 비디오 이해의 새 지평 (1) | 2026.02.04 |
|---|---|
| [arXiv 2501.05707] Multiagent Finetuning: 다양한 추론 체인을 통한 자기 개선 (0) | 2026.02.04 |
| [arXiv 2501.14342] CoRAG: 반복적 검색 체인을 통한 RAG 성능 향상 (0) | 2026.02.03 |
| [arXiv 2501.12948] DeepSeek-R1: 순수 강화학습을 통한 LLM 추론 능력 향상 (0) | 2026.02.03 |
| [arXiv 2601.23228] MAPPA: 프로세스 리워드를 활용한 멀티에이전트 시스템 스케일링 (0) | 2026.02.03 |