LoRA: Low-Rank Adaptation of Large Language Models
https://arxiv.org/abs/2106.09685
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen · Microsoft · 2021 · ICLR 2022
이 논문은 거대 언어모델 적응의 비용 구조를 다시 정의한 연구로 읽힌다. 핵심 제안은 사전학습 가중치 $W_0$를 동결한 채, 다운스트림 과업에서 필요한 변화만 저랭크 행렬 곱으로 표현하는 것이다. 완전 미세조정이 모델 전체를 다시 학습하는 반면, LoRA는 변화량 $\Delta W$를 직접 두지 않고 $BA$ 형태의 작은 행렬 두 개로 재매개변수화한다. 이때 학습 대상은 원본 모델이 아니라 소수의 적응 파라미터이며, 추론 전에 이를 본래 가중치에 병합할 수 있으므로 추론 지연시간 증가 없이 효율적 튜닝을 달성한다.
논문의 중요성은 단순히 파라미터를 줄였다는 사실에 있지 않다. 저자들은 조건부 언어모델 목적함수 아래에서 적응 문제를 다시 쓰고, 어댑터 계열, 프리픽스 튜닝, 완전 미세조정과 비교하여 학습 메모리, 처리량, 저장비용, 추론 지연의 균형을 체계적으로 보여 준다. 또한 GLUE, E2E, WikiSQL, SAMSum, GPT-3 175B 결과를 연결해, LoRA가 특정 모델군의 편의적 트릭이 아니라 범용적 파인튜닝 인터페이스라는 점을 입증한다. 이후 수년 동안 대형 모델 생태계에서 LoRA가 사실상의 기본 선택지로 자리 잡은 이유도 이 논문 안에 이미 상당 부분 들어 있다.
아래 정리는 논문의 수식, 실험, 구현 세부, 데이터셋 특성, 하이퍼파라미터, 장단점, 후속 연구 연결고리를 중심으로 내용을 대폭 보강한 발행용 HTML 초안이다. 문체는 논문 귀속형 설명으로 통일했고, 개인적 감상이나 메타 시점을 배제했으며, 각 그림에는 figcaption을 추가하고 그림 직후에는 200~350자 분량의 해설 문단을 배치했다. 마지막 9절은 요약 정리로 마무리하며, 구조와 글자 수는 파일 저장 후 별도 스크립트로 자체 검증한 실제 수치를 반영한다.
1. 문제 제기의 배경과 비용 구조 변화 — 왜 거대 모델 시대에는 완전 미세조정이 먼저 한계에 부딪히는가
사전학습 후 미세조정이라는 표준 절차는 BERT, RoBERTa, GPT 계열을 거치며 압도적인 성능을 보여 주었지만, 모델 크기가 수억에서 수천억 파라미터로 커지면서 성능의 우월성과 운영 가능성이 분리되기 시작했다. 완전 미세조정은 각 과업마다 독립적인 모델 사본을 요구하고, 학습 시에는 파라미터 외에도 그래디언트, 옵티마이저 상태, 활성값까지 유지해야 한다. 특히 AdamW 같은 옵티마이저는 1차·2차 모멘트 상태를 별도로 저장하므로, 실질적인 메모리 압력은 단순 파라미터 수의 몇 배로 뛴다. 대형 모델에서 이는 곧 GPU 수요, 체크포인트 저장량, 재학습 비용, 배포 난이도의 급상승으로 이어진다.
예를 들어 GPT-3 175B 규모에서 완전 미세조정은 단지 학습 시간이 길다는 문제가 아니라, 과업 수가 늘어날 때마다 175B 전체 사본을 과업별로 보관해야 한다는 구조적 부담을 만든다. 문서 요약, 자연어 추론, 질의응답, SQL 생성, 대화 요약처럼 업무별 튜닝 포인트가 누적되면, 저장소와 서빙 계층은 빠르게 복잡해진다. 결국 대형 모델 시대의 병목은 “학습이 가능한가”가 아니라 “각 과업에 맞게 적응한 결과를 얼마나 싸게 유지하고 배포할 수 있는가”로 이동한다. LoRA는 바로 이 병목을 겨냥한다.
논문은 이러한 상황을 두고, 다운스트림 적응에 필요한 가중치 변화가 정말로 전체 매개변수 공간의 모든 자유도를 필요로 하는지 묻는다. 사전학습 모델은 이미 방대한 언어 지식을 내재하고 있으므로, 과업 적응은 새로운 지식을 무에서 대량으로 학습하기보다 기존 표현을 특정 방향으로 미세하게 재배치하는 과정일 수 있다. 만약 이 변화가 실제로는 저차원 부분공간에 집중된다면, 전체 행렬을 다시 갱신하는 방식은 과도한 일반성일 수 있다. LoRA의 설계는 바로 이 가설, 즉 적응의 내재 차원은 생각보다 낮다는 관찰에서 출발한다.
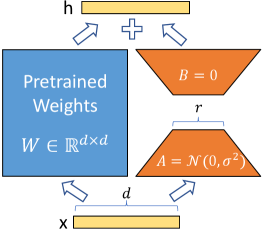
이 그림은 LoRA의 구조를 가장 압축적으로 보여 준다. 원래의 선형층은 $W_0x$를 계산하고, 적응 과정에서는 여기에 작은 랭크의 보정항 $BAx$만 더한다. 학습 대상이 $A$와 $B$로 축소되므로 메모리와 저장 비용이 급격히 줄고, 추론 전에 $W_0 + BA$로 병합할 수 있어 경로 자체는 기존 선형층과 동일하게 유지된다. 성능, 메모리, 배포 효율을 하나의 구조로 묶은 것이 이 설계의 핵심이다. 특히 이 재매개변수화는 선형층의 함수형태를 바꾸지 않고도 적응 자유도를 제공하므로, 이후 수많은 변형 LoRA 기법이 같은 뼈대를 유지한 채 세부 설계만 바꾸는 방향으로 발전할 수 있었다.
1.1 완전 미세조정의 비용은 파라미터 수보다 학습 스택 전체에서 폭증한다
실무에서 완전 미세조정이 부담스러운 이유는 파라미터 저장량만이 아니다. mixed precision 환경에서도 마스터 웨이트, 그래디언트 버퍼, 옵티마이저 상태, 분산 학습을 위한 통신 버퍼가 얽히며 비용이 커진다. 예를 들어 175B 모델 전체를 갱신한다면, 파라미터 수 자체보다 훈련 시점의 상태 저장이 더 치명적일 수 있다. LoRA는 동결된 본체를 그대로 두고 저랭크 보정만 학습하므로, 옵티마이저 상태가 생성되는 대상 역시 극소수 파라미터에 한정된다. 논문이 말하는 약 3배의 GPU 메모리 절감은 바로 이러한 훈련 스택 차이를 반영한다.
1.2 기존 PEFT 계열의 문제는 학습량 감소와 추론 효율 사이의 균형이었다
LoRA 이전에도 효율적 적응을 위한 시도는 존재했다. Adapter는 레이어 사이에 작은 병목 모듈을 삽입해 학습 파라미터를 줄였고, Prefix Tuning과 Prompt Tuning은 입력 또는 attention 상태 쪽에 학습 가능한 연속 벡터를 추가했다. 그러나 Adapter는 레이어 경로에 추가 연산이 들어가므로 추론 지연 증가를 피하기 어렵고, 프리픽스 계열은 매우 적은 파라미터로 유연성을 확보하는 대신 당시 실험 기준으로는 모든 과업에서 완전 미세조정과 안정적으로 경쟁하지 못했다. LoRA는 선형층 자체에 병합 가능한 업데이트를 정의함으로써 두 문제를 동시에 다룬다.
2. 수식과 학습 목적의 재구성 — 조건부 언어모델 목적함수를 저랭크 적응 문제로 바꾸는 방식
논문은 과업 적응을 일반적인 조건부 언어모델 형태로 놓는다. 데이터셋 $\{(x^{(i)}, y^{(i)})\}_{i=1}^{N}$가 있을 때 목표는 입력 $x$와 이전 토큰 $y_{<t}$에 조건부인 다음 토큰의 로그우도를 최대화하는 것이다. 즉 목적함수는 다음과 같이 쓸 수 있다.
$$\max_{\Phi}\sum_{i=1}^{N}\sum_{t=1}^{T_i}\log P_{\Phi}(y_t^{(i)}\mid x^{(i)}, y_{<t}^{(i)})$$
완전 미세조정에서는 $\Phi$ 전체가 학습 대상이지만, LoRA는 여기서 선형층 하나를 떼어내어 그 변화량만 재매개변수화한다. 원래 선형 변환이 $h = W_0x$라면, 적응 후 출력은 다음과 같이 정의된다.
$$h = W_0x + \Delta Wx = W_0x + BAx$$
여기서 $W_0 \in \mathbb{R}^{d\times k}$는 사전학습된 고정 가중치, $B \in \mathbb{R}^{d\times r}$, $A \in \mathbb{R}^{r\times k}$이며, 랭크 $r$는 일반적으로 $r \ll \min(d,k)$인 작은 값이다. 다시 말해 원래는 $d\times k$ 전체 자유도를 갖는 업데이트를 직접 학습해야 하지만, LoRA는 이를 $r$차원 부분공간을 거치는 두 행렬의 곱으로 제한한다. 이때 계산 복잡도와 저장 복잡도는 원래 행렬의 제곱 스케일이 아니라 $r$에 선형적인 규모로 축소된다.
논문 구현에서 중요한 세부는 스케일링 계수와 초기화다. 실제 업데이트는 보통 다음 형태로 적용된다.
$$h = W_0x + \frac{\alpha}{r}BAx$$
여기서 $\alpha/r$는 랭크가 달라져도 업데이트의 유효 스케일이 과도하게 흔들리지 않도록 조절하는 역할을 한다. 저자들은 보통 $A$는 랜덤 초기화, $B$는 0 초기화로 두어 시작점을 원래 모델과 동일하게 맞춘다. 이 방식은 훈련 초기의 불안정한 출력 변화를 줄이고, 학습이 시작될 때까지 모델이 사전학습 표현을 유지하게 한다. 즉 LoRA는 무작위로 모델을 흔드는 방식이 아니라, 초기엔 항등에 가까운 상태에서 점진적으로 보정항을 학습하는 구조다.
또 하나 중요한 점은 merge / unmerge 가능성이다. 학습 중에는 $A$와 $B$를 분리된 모듈로 유지해 미분과 체크포인트 관리를 쉽게 하고, 추론 전에는 $W_0 \leftarrow W_0 + \frac{\alpha}{r}BA$로 병합할 수 있다. 필요하면 다시 원래 가중치와 보정항을 분리하는 unmerge도 가능하다. 이 특성은 같은 베이스 모델 위에서 여러 LoRA 체크포인트를 바꿔 끼우는 워크플로를 가능하게 만들며, 오늘날 오픈소스 생태계에서 가장 널리 쓰이는 적응 방식이 된 이유와 직결된다.
이 도식의 포인트는 단순 비교가 아니다. 완전 미세조정은 표현력은 가장 크지만 비용이 높고, 어댑터는 학습량은 줄이되 레이어 경로에 새 모듈이 남는다. LoRA는 보정항이 원래 선형층 안으로 흡수될 수 있기 때문에 학습 효율과 배포 효율을 동시에 확보한다. 즉 “학습 때만 존재하는 적응 구조”라는 발상이 어댑터 계열과 LoRA를 가르는 결정적 차이로 기능한다. 다시 말해 LoRA는 적응을 위한 계산 그래프와 실제 서비스용 계산 그래프를 분리해 생각하게 만든 방법이며, 이 점이 시스템 관점의 강점을 만든다.
2.1 학습 가능 파라미터 수가 왜 $2\hat{L}d_{model}r$ 꼴로 줄어드는가
Transformer에서 LoRA를 적용하는 선형 투영의 수를 $\hat{L}$라고 하고, 각 투영의 입출력 차원을 대략 $d_{model}$ 수준으로 보면, 선형층 하나당 LoRA가 추가하는 파라미터는 $d_{model}r + rd_{model} = 2d_{model}r$이다. 이를 $\hat{L}$개의 위치에 적용하면 총 학습 파라미터는 대략 $2\hat{L}d_{model}r$이 된다. 이는 원래 $O(d_{model}^2)$ 규모의 선형층 전체를 다시 학습하는 것과 비교할 때 급격히 작다. 모델이 커질수록 이 차이는 선형이 아니라 사실상 구조적으로 벌어진다.
2.2 $\alpha/r$ 스케일링은 랭크 변화와 업데이트 안정성을 연결하는 실용 장치다
랭크 $r$를 키우면 $A$와 $B$의 자유도는 늘어나지만, 아무 보정 없이 두 행렬을 곱하면 업데이트 크기가 랭크와 함께 커질 수 있다. 저자들이 사용한 $\alpha/r$ 스케일링은 이를 제어해, 서로 다른 랭크 설정에서도 비교적 비슷한 크기의 업데이트를 유지하게 돕는다. 실무에서는 $r=8$, $\alpha=16$ 또는 $\alpha=32$ 같은 조합이 널리 쓰이는데, 이는 바로 랭크와 유효 학습률 사이의 균형을 맞추는 경험적 규칙으로 이해할 수 있다.
2.3 초기화와 병합 설계는 LoRA를 이론이 아니라 구현 가능한 도구로 만든다
$B=0$ 초기화는 훈련 시작 시점에 보정항이 0이 되도록 하고, $A$의 랜덤 초기화는 이후 학습에서 다양한 방향을 탐색할 수 있게 한다. 이 조합은 로짓 급변이나 사전학습 표현 훼손을 줄이는 데 유리하다. 또한 훈련 단계에서만 모듈 형태를 유지하다가 추론 전 병합하는 방식은 프레임워크 레벨에서 구현하기 쉽고, 동일한 베이스 모델에 다수의 적응 모듈을 꽂아 쓰는 생태계를 촉진했다. 논문이 제안한 구조는 수식만 간단한 것이 아니라 체크포인트 관리와 서빙 배포까지 고려한 설계라는 점에서 중요하다.
2.4 조건부 언어모델 목적의 관점에서 본 LoRA의 의미
조건부 언어모델 목적함수는 결국 입력과 이전 토큰이 주어졌을 때 다음 토큰의 분포를 얼마나 정교하게 바꿀 수 있는지를 묻는다. 완전 미세조정은 이 분포를 만드는 모든 가중치를 직접 움직이지만, LoRA는 각 선형층의 출력 공간에서 필요한 방향만 선택적으로 조절한다. 중요한 점은 다음 토큰 분포가 하나의 층에 의해서만 결정되지 않는다는 사실이다. 여러 attention 투영과 MLP 변환이 누적되며 최종 로짓이 형성되므로, 각 층에서 작은 저랭크 보정이 쌓이면 전체 조건부 분포는 충분히 크게 변할 수 있다. 즉 LoRA의 표현력은 개별 층 보정의 크기보다 여러 층에 걸친 누적 효과에서 이해해야 한다.
또한 조건부 언어모델 목적은 과업에 따라 입력 형식이 다르더라도 동일한 훈련 틀을 제공한다. 자연어 추론에서는 전제와 가설이 입력이 되고, 요약에서는 원문 대화나 문서가 입력이 되며, SQL 생성에서는 질문과 스키마 정보가 입력이 된다. LoRA는 이 모두를 별도 아키텍처 수정 없이 다룰 수 있다. 입력 형식이 달라도 모델 내부의 선형 변환을 조절하는 방식은 동일하기 때문이다. 이런 통일성은 LoRA가 특정 태스크별 맞춤형 장치가 아니라 범용적 파라미터 적응 층으로 기능한다는 점을 보여 준다.
수학적으로 보아도 $W_0x$와 $BAx$의 합은 입력 $x$에 대해 여전히 선형이지만, 이 선형층들이 비선형 활성함수와 attention 정규화, residual 연결 사이에 위치하기 때문에 전체 네트워크 관점에선 매우 풍부한 함수 변형을 유도할 수 있다. 다시 말해 LoRA의 저랭크성은 개별 행렬의 자유도를 제한할 뿐, 네트워크 전체의 적응 능력을 기계적으로 축소하지는 않는다. 이 점은 작은 랭크로도 높은 성능이 나오는 현상을 이해하는 데 중요하다. 저랭크라는 제약은 전체 네트워크 수준에서는 규모가 큰 사전학습 표현 위에 얹히는 정교한 편향으로 작동한다.
3. 기존 대안과의 비교 맥락 — 어댑터, 프리픽스, 프롬프트 계열과 무엇이 결정적으로 다른가
LoRA의 참신함을 이해하려면 기존 대안이 해결하지 못한 문제를 함께 봐야 한다. 어댑터 기반 기법은 레이어 사이에 작은 병목 MLP를 삽입하여 학습량을 줄였고, 실험적으로도 좋은 성능을 자주 보였다. 그러나 레이어 수가 많고 서빙 지연이 민감한 환경에서는, 각 레이어에 새 모듈이 남는다는 사실이 곧 성능 외적인 비용으로 바뀐다. 반면 프리픽스/프롬프트 계열은 입력 또는 attention prefix 차원에서 작은 수의 벡터만 학습하므로 파라미터 효율은 더 좋지만, 당시 논문 맥락에서는 모든 과업에서 완전 미세조정과 동급의 일관성을 확보했다고 보기 어려웠다.
LoRA는 레이어 경로를 변경하지 않으면서도 선형층 수준의 표현 자유도를 확보한다. 이는 “입력 쪽에 작은 제어 신호를 추가”하는 방법과 “모델 내부에 새 층을 삽입”하는 방법의 중간이 아니라, 선형 변환 자체를 저랭크 보정항으로 재해석한다는 점에서 다른 축에 서 있다. 학습 시에는 작은 파라미터 집합만 존재하지만, 추론 시에는 원래 가중치에 완전히 병합되므로 latency-free serving이 가능하다. 논문이 어댑터와 직접 비교할 때 가장 강조한 항목이 바로 이 부분이다.
| 방법 | 학습 파라미터 | 추론 지연 | 저장 효율 | 핵심 특징 |
|---|---|---|---|---|
| Full Fine-tuning | 매우 큼 | 추가 없음 | 과업별 전체 사본 필요 | 표현력은 높지만 비용이 가장 크다. |
| Adapter | 작음 | 증가 | 양호 | 새 모듈 삽입으로 구조가 바뀐다. |
| Prefix / Prompt | 매우 작음 | 설정에 따라 다름 | 매우 좋음 | 표현 수정 범위가 제한적일 수 있다. |
| LoRA | 작음 | 병합 시 추가 없음 | 매우 좋음 | 선형층 업데이트를 저랭크로 재매개변수화한다. |
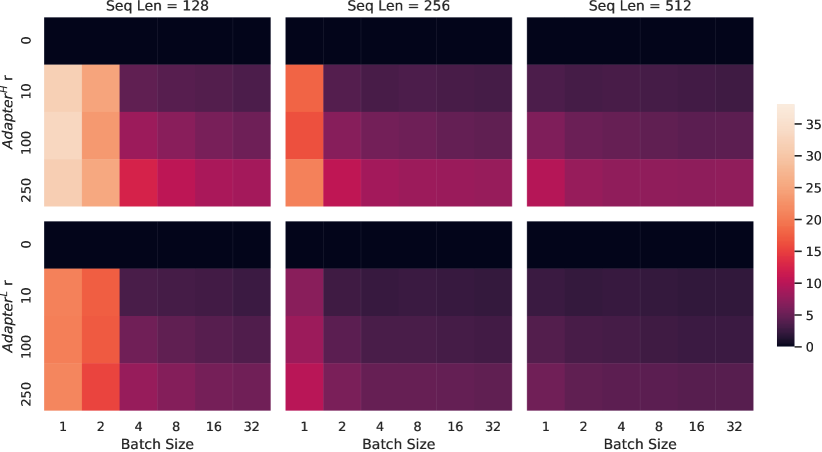
논문은 특히 Adapter가 실제 추론 시 얼마나 느려지는지도 구체적 수치로 제시한다. 같은 기본 모델에서 batch size와 sequence length가 줄어들수록 상대적 오버헤드가 커지고, 작은 배치에서는 대기 시간이 눈에 띄게 늘어난다. 이는 온라인 서빙과 대화형 애플리케이션에서 중요하다. 평균 처리량만 보면 작은 차이로 보일 수 있지만, 응답성 중심 환경에선 수 밀리초 단위의 누적 지연이 체감 품질에 크게 작용한다.
| 배치 / 길이 | Baseline | AdapterL | 증가율 | AdapterH | 증가율 |
|---|---|---|---|---|---|
| 32 / 512 | 1449.4ms | 1482.0ms | +2.2% | 1492.2ms | +3.0% |
| 16 / 256 | 338.0ms | 354.8ms | +5.0% | 366.3ms | +8.4% |
| 1 / 128 | 19.8ms | 23.9ms | +20.7% | 25.8ms | +30.3% |
특히 batch 1, sequence 128에서 AdapterH가 30.3% 느려진다는 수치는 의미가 크다. 사용자가 짧은 요청을 보낼 때 오히려 오버헤드가 더 도드라진다는 뜻이기 때문이다. LoRA는 이 문제를 “더 빠른 모듈을 삽입”하는 방향으로 해결하지 않고, 아예 삽입해야 할 모듈을 남기지 않는 구조를 선택한다. 이 선택이야말로 이후 대형 모델 서빙에서 LoRA가 널리 채택된 구조적 이유라고 볼 수 있다.
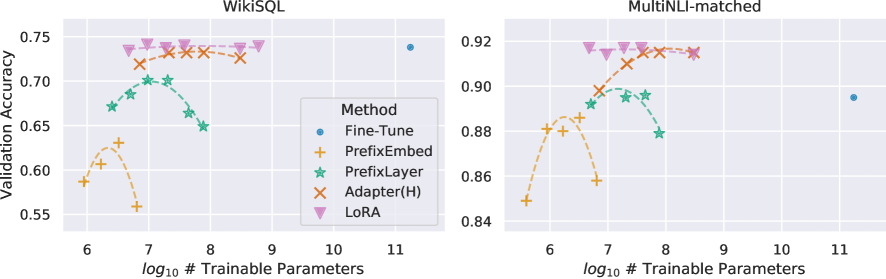
이 그림은 LoRA가 단지 파라미터를 줄이는 보조 기법이 아니라, 실제 성능에서도 완전 미세조정과 경쟁 가능한 적응 방법임을 요약한다. 저자들이 강조하는 것은 “조금 손해 보더라도 싸게 학습한다”가 아니다. 오히려 적은 파라미터와 낮은 메모리 예산을 사용하면서도 다수의 설정에서 성능 열세가 없다는 점이 핵심이다. 효율성 논문이면서도 결과 표가 설득력 있는 이유가 여기에 있다. 같은 메시지가 encoder-only와 decoder-only 모델 모두에서 반복되기 때문에, LoRA를 특정 아키텍처의 우연한 최적화로 축소해 해석하기 어렵다.
3.1 LoRA는 학습 효율과 추론 효율을 동시에 노리는 드문 설계다
많은 PEFT 방법은 학습량을 줄이거나 저장 비용을 낮추는 데 성공하지만, 추론 경로의 복잡도는 별도로 남겨둔다. LoRA는 학습 중에만 분리된 저랭크 보정항을 유지하고, 배포 전 병합함으로써 두 단계 모두에서 효율을 확보한다. 따라서 평가 기준은 단순한 accuracy / F1뿐 아니라 GPU 메모리, 처리량, 체크포인트 크기, task switching 편의성까지 포함해야 하며, 논문은 그 비교 틀을 비교적 일찍 정리한 작업으로 볼 수 있다.
3.2 다중 과업을 한 배치에 섞는 문제는 LoRA 이후에도 남아 있는 시스템 과제다
LoRA가 task switching을 쉽게 해 주는 것은 사실이지만, 서로 다른 LoRA를 적용해야 하는 샘플을 하나의 대형 배치로 동시에 처리하는 문제는 별개다. 샘플마다 서로 다른 보정행렬이 필요하면 커널 수준 최적화가 어렵고, merge 상태를 매 요청마다 바꾸는 방식도 비효율적일 수 있다. 즉 LoRA는 과업별 모듈성에는 매우 강하지만, heterogeneous batching이라는 운영 문제를 자동으로 없애 주지는 않는다. 이 한계는 이후 멀티어댑터 라우팅 연구로 이어진다.
3.3 Adapter와 Prefix 계열을 시스템 관점에서 다시 비교하기
Adapter는 레이어 사이에 별도 모듈을 두기 때문에 미세조정 단계에서만이 아니라 배포 단계에서도 구조가 남는다. 이는 장점과 단점을 동시에 갖는다. 장점은 보정 위치가 명시적이고, 경우에 따라 서로 다른 어댑터를 조합하거나 중간 표현을 해석하기 쉽다는 점이다. 반면 단점은 레이어 수가 깊을수록 커널 호출과 메모리 이동이 추가되고, 특히 짧은 요청에서 상대적 오버헤드가 커진다는 점이다. LoRA는 같은 선형층 안에 병합될 수 있는 보정항을 쓰므로, 적응을 위한 모듈성이 필요할 때는 분리 상태를 유지하고 실제 서빙에서는 구조를 지우는 절충이 가능하다.
Prefix Tuning과 Prompt Tuning은 입력 길이 또는 attention 문맥을 늘리는 방식으로 적응한다. 이런 방법은 학습해야 할 파라미터 수가 매우 적고, 경우에 따라 베이스 모델을 완전히 건드리지 않는다는 장점이 있다. 그러나 입력 쪽 제어신호만으로 내부 표현 전체를 강하게 재배치하기는 쉽지 않다. 특히 과업이 구조적 생성이나 복잡한 추론을 요구할수록, 단순한 prefix 추가만으로는 충분한 적응 자유도를 확보하기 어렵다. LoRA는 입력에 프롬프트를 추가하지 않고 모델 내부 선형 변환 자체를 조절하므로, 프롬프트 계열보다 더 직접적인 표현 수정 능력을 제공한다.
이 비교에서 중요한 것은 어느 방법이 절대적으로 우월하다는 결론이 아니라, 각 방법이 최적화하는 비용 항목이 다르다는 사실이다. Adapter는 해석 가능성과 모듈성이 강하고, Prefix 계열은 파라미터 수 최소화에 강하며, LoRA는 학습량·저장량·추론 지연의 균형에서 특히 강하다. 논문은 바로 이 균형점 때문에 LoRA를 강조한다. 거대 모델 시대에는 특정 비용 하나가 아니라 전체 시스템 비용을 함께 줄이는 방법이 필요했고, LoRA는 그 요구에 가장 직접적으로 응답했다.
4. 적용 위치와 구현 디폴트 — 왜 query와 value가 기본 선택이 되었는가
LoRA는 원칙적으로 어떤 선형층에도 적용할 수 있다. 다만 논문은 Transformer에서 모든 투영을 동일하게 다루지 않고, 특히 self-attention의 query와 value를 실용적 기본값으로 제안한다. query는 어떤 위치에 주목할지 정하는 방향에서 적응 효과가 크고, value는 실제로 전달될 내용을 조정하므로 생성 과업에서 영향력이 크다. key나 output projection도 유의미하지만, 제한된 예산 아래에서 query/value 조합은 매우 강한 절충점을 보여 준다.
이는 단순한 경험칙이 아니라, 실험으로 확인된 설계 선택이다. 논문은 under 18M 수준의 예산에서 $W_q$, $W_k$, $W_v$, $W_o$ 각각 또는 조합을 비교하며 WikiSQL, MultiNLI 성능을 제시한다. 결과를 보면 query 단독도 강하지만 value 또는 output projection이 생성 쪽에서 더 좋고, query와 value를 함께 쓰면 전반적으로 균형이 좋다. 네 투영 전체를 모두 사용하는 방식도 가능하지만, 그 추가 이득은 비용 상승에 비해 제한적이다.
| 적용 가중치 | 예산 | WikiSQL | MultiNLI | 해석 |
|---|---|---|---|---|
| $W_q$ | under 18M | 70.4 | 91.0 | 분류형 적응은 강하지만 생성은 약간 덜 강하다. |
| $W_k$ | under 18M | 70.0 | 90.8 | key 단독의 이득은 상대적으로 작다. |
| $W_v$ | under 18M | 73.0 | 91.0 | 생성형 지표 측면에서 강한 축이다. |
| $W_o$ | under 18M | 73.2 | 91.3 | output projection 역시 유력한 대안이다. |
| $W_qW_v$ | under 18M | 73.7 | 91.3 | 성능과 비용의 균형이 가장 우수하다. |
| $W_q,W_k,W_v,W_o$ | under 18M | 73.7 | 91.7 | 최고치이지만 추가 이득은 제한적이다. |
이 표에서 가장 중요한 메시지는 “모든 가중치를 다 적응해야만 좋은 성능이 나오는 것은 아니다”라는 점이다. 예컨대 $W_qW_v$는 WikiSQL 73.7, MultiNLI 91.3으로 매우 강하고, 네 투영 전체를 모두 사용할 때 얻는 증가는 MultiNLI에서 0.4포인트 수준이다. 즉 제한된 자원에서 기본 설정을 정해야 한다면 query / value 우선이 합리적이며, 이후 필요할 때 MLP나 output projection으로 확장하는 접근이 자연스럽다.
이 시각화는 LoRA가 어디에서 가장 큰 효율을 내는지 보여 준다. query와 value는 적은 파라미터 예산 대비 높은 성능을 제공하며, 모든 투영을 다 적응하는 구성은 최고 성능을 줄 수 있어도 비용 증가 폭이 더 크다. 따라서 LoRA의 실전 디폴트는 “전체를 덮는 만능 설정”이 아니라, 과업 특성과 예산을 고려해 민감한 투영부터 우선 적응하는 방식으로 이해하는 것이 맞다. 이 결과는 이후 실무 코드베이스에서 query / value 대상 설정이 사실상의 초기값처럼 굳어진 배경을 설명해 준다.
4.1 query / value 중심 설정은 라이브러리 표준 구성에도 직접적인 영향을 주었다
오늘날 오픈소스 PEFT 라이브러리에서 가장 흔한 기본 설정이 attention의 query와 value 모듈을 대상으로 삼는 이유는 우연이 아니다. 이 논문이 성능과 비용의 균형점을 실제로 보여 주었기 때문이다. 이후 연구들은 MLP down-proj, up-proj, gate-proj, embedding, output head 등으로 대상을 넓혔지만, 출발점은 여전히 “어떤 선형층이 실제 적응의 병목인가”를 묻는 LoRA식 분석이다.
4.2 과업 성격에 따라 민감한 가중치 위치가 달라질 수 있다는 점도 드러난다
WikiSQL은 구조적 생성 성격이 강하므로 value나 output projection이 더 직접적인 영향을 줄 수 있고, MultiNLI는 문장 간 관계 판별이 핵심이어서 query 측 조정이 더 중요하게 작동할 수 있다. 이 차이는 과업별 적응을 하나의 전역 규칙으로 묶기 어렵다는 사실을 보여 주며, 동시에 LoRA가 매우 작은 예산으로도 여러 적용 위치를 탐색할 수 있게 해 준다는 장점으로 이어진다. 즉 LoRA는 단지 가벼운 방법이 아니라 탐색 친화적 방법이기도 하다.
4.3 attention 외 MLP와 임베딩으로의 확장 가능성
논문은 주로 attention 투영을 중심으로 결과를 제시하지만, LoRA의 재매개변수화 자체는 MLP의 up projection, down projection, gate projection, 심지어 임베딩 행렬에도 적용할 수 있다. 실제 후속 연구에서는 attention만으로 부족한 과업에서 MLP까지 LoRA를 확장하거나, 특정 층만 더 높은 랭크를 부여하는 방식이 자주 사용되었다. 다만 이렇게 적용 범위를 넓히면 학습 파라미터 수와 병합 복잡도도 함께 증가한다. 따라서 원 논문의 query/value 기본 설정은 “유일한 정답”이라기보다 비용 대비 가장 안정적인 출발점으로 이해하는 것이 적절하다.
또한 층별 중요도는 균일하지 않을 수 있다. 하위 층은 어휘적·형태적 정보를, 중간 층은 구문과 의미를, 상위 층은 과업별 의사결정 구조를 더 많이 담당하는 경향이 있다. 따라서 실제 적응에 필요한 랭크와 적용 위치는 층마다 달라질 수 있다. 원 논문은 이 문제를 완전히 해결하지는 않지만, 적어도 작은 예산으로 다양한 위치 실험을 해 볼 수 있는 틀을 제공했다. 이 점은 후속 연구가 층별 중요도 추정이나 적응 예산 배분 문제로 발전하는 계기가 되었다.
실무적으로는 적용 위치가 늘어날수록 체크포인트 이름 규칙, 모듈 탐색 코드, 병합 검증, 혼합 정밀도 안정성까지 관리해야 할 범위가 커진다. 따라서 최고의 점수만을 목표로 모든 층에 LoRA를 넣기보다, 기본적으로 query/value를 사용하고 필요시 MLP 일부로 확장하는 계층적 전략이 많이 사용된다. 이러한 관행 역시 논문이 제공한 적용 위치 비교 실험에서 직접적인 근거를 얻는다.
5. 데이터셋과 실험 프로토콜의 세부 — GLUE, E2E, WikiSQL, SAMSum은 무엇을 측정하는가
LoRA 논문이 설득력을 가지는 이유 중 하나는, 분류와 생성을 모두 포함하는 벤치마크 구성을 사용했다는 점이다. GLUE는 CoLA, SST-2, MRPC, STS-B, QQP, MNLI, QNLI, RTE 등 서로 다른 언어 이해 과업으로 구성되며, 단순 분류 정확도만이 아니라 문법성 판단, 문장 쌍 유사도, 자연어 추론, 질문-문장 entailment까지 포괄한다. LoRA가 GLUE 평균에서 강한 결과를 냈다는 것은 하나의 특정 분류 과업에만 맞는 조정이 아니라, 다양한 언어 이해 설정에서 표현 재배치 능력이 충분하다는 뜻이다.
세부적으로 보면 CoLA는 문장 수용성 판단이므로 Matthews correlation이 중요하고, SST-2는 감성 분류 정확도를 본다. MRPC와 QQP는 문장쌍의 중복 여부 판단, STS-B는 의미 유사도 회귀, MNLI와 RTE는 entailment / contradiction 관계 이해를 측정한다. 이들 지표가 서로 다른 이유는 과업이 요구하는 구조가 다르기 때문이다. LoRA가 평균 점수뿐 아니라 여러 개별 태스크에서 완전 미세조정과 비슷하거나 더 나은 성능을 보인다는 것은, 저랭크 적응이 단순한 분류 헤드 보정이 아니라 내부 표현 공간의 유의미한 이동을 수행하고 있음을 시사한다.
생성 측면에서는 E2E NLG 챌린지 데이터셋이 중요하다. 이 데이터셋은 구조화된 의미 표현을 자연어 문장으로 변환하는 과업으로, 모델이 정보를 얼마나 정확히 실현하는지와 문장 품질을 동시에 평가한다. 여기서 BLEU는 n-gram 중첩을, NIST는 정보량이 큰 n-gram에 더 높은 가중치를, METEOR는 어형과 의미 매칭을, ROUGE-L은 최장 공통 부분수열 기반 재현력을, CIDEr는 여러 참조문장과의 일치도를 본다. 따라서 E2E에서 좋은 점수를 얻었다는 것은 단순한 표면 중첩이 아니라 내용 실현과 문장화 전반이 안정적이라는 의미다.
또한 WikiSQL은 자연어 질문을 SQL 질의로 변환하는 구조적 생성 과업이며, 모델이 테이블 스키마와 질의 구조를 얼마나 정확히 맞추는지 평가한다. SAMSum은 메신저 대화 요약 데이터셋으로, 발화체 대화에서 요약 핵심을 압축하는 능력을 본다. 즉 LoRA는 단순 문장 분류만이 아니라 구조적 생성, 요약, 추론을 아우르는 실험 세트를 통과한다. 논문이 영향력이 큰 이유는 특정 벤치마크의 좁은 승리가 아니라, 적응 방식으로서의 범용성을 폭넓게 증명했기 때문이다.
| 데이터셋 | 과업 유형 | 대표 지표 | LoRA 해석 포인트 |
|---|---|---|---|
| GLUE | 언어 이해 / 분류 / 추론 | Accuracy, F1, Corr. | 저랭크 적응이 문장 이해 전반에 유효한지 본다. |
| E2E | 구조적 데이터 → 문장 생성 | BLEU, NIST, METEOR, ROUGE-L, CIDEr | 생성 품질과 내용 실현을 동시에 본다. |
| WikiSQL | Text-to-SQL | Execution / logical form 계열 | 구조적 생성에서 작은 랭크가 충분한지 본다. |
| SAMSum | 대화 요약 | ROUGE-1/2/L | 요약형 생성에서 완전 미세조정과의 격차를 본다. |
하이퍼파라미터 측면에서도 논문은 과도한 복잡성을 피한다. 대표 설정에서 랭크 $r=8$이 자주 사용되고, 스케일링은 $\alpha=16$ 혹은 32 수준으로 잡힌다. 옵티마이저는 대체로 AdamW이며, 선형 warmup 비율은 소수의 퍼센트 수준으로 유지된다. 시퀀스 길이는 과업에 맞춰 128, 256, 512 등으로 조정되고, 대형 모델에서는 가능한 배치 크기와 메모리 예산 사이에서 선택이 이뤄진다. 중요한 점은 LoRA가 수십 개의 민감한 조정값을 요구하는 방법이 아니라는 사실이며, 이 단순성 덕분에 재현성과 실무 채택성이 높아진다.

이 그림이 보여 주는 메시지는 극단적으로 명확하다. 모델 전체를 학습하는 접근은 파라미터 수가 곧 비용으로 연결되지만, LoRA는 거대한 본체를 고정한 채 소수의 보정항만 학습함으로써 적응의 비용 구조를 완전히 바꾼다. 특히 수십억·수백억 규모에서는 절감 비율 자체가 서비스 설계의 가능 여부를 좌우하므로, 이 차이는 단순한 효율 향상이 아니라 대형 모델 튜닝의 현실성을 결정하는 요소가 된다. 논문이 GPT-3 175B를 핵심 사례로 제시한 이유도, 바로 이 스케일에서 LoRA의 장점이 가장 선명하게 드러나기 때문이다.
5.1 GLUE 세부 태스크 해석 — 평균 점수 이상의 의미
GLUE 평균은 편리한 요약값이지만, 논문을 제대로 읽으려면 개별 태스크의 요구 능력을 함께 봐야 한다. RTE는 학습 데이터가 비교적 작고 자연어 추론 구조가 민감해, 미세조정 방식의 일반화 능력을 드러내기 좋다. MNLI는 규모가 크고 도메인도 다양해 넓은 의미의 언어 추론 능력을 본다. QQP와 MRPC는 문장쌍 유사성의 표면적 중복만이 아니라 표현 차이를 넘는 의미 판단을 요구한다. LoRA가 이런 서로 다른 태스크에서 고르게 강했다는 사실은, 저랭크 적응이 특정 레이블 맵핑의 꼼수가 아니라 사전학습 표현의 범용적 재정렬에 가깝다는 해석을 가능하게 한다.
5.2 E2E 지표 해석 — 각 metric은 생성 모델의 다른 면을 측정한다
E2E에서 BLEU는 표면적 n-gram 일치, NIST는 희귀하고 정보량이 큰 표현의 일치, METEOR는 어형 변화와 의미적 일치, ROUGE-L은 문장 전체 구조의 재현, CIDEr는 다중 참조문장 환경에서의 전반적 적합성을 본다. LoRA가 여러 지표에서 균형 있게 강하다는 것은, 단순히 자주 등장하는 구문만 맞춘 것이 아니라 의미 실현과 문장 품질을 함께 유지했다는 뜻이다. 생성형 과업에서 이 균형은 분류 정확도 이상의 해석 가치를 가진다.
5.3 WikiSQL과 SAMSum은 서로 다른 생성 난제를 대표한다
WikiSQL은 단순한 문장 생성 데이터셋이 아니다. 모델은 자연어 질문에서 열 이름, 연산자, 조건, 집계 함수의 구조를 추출해 실행 가능한 SQL 형태로 변환해야 한다. 이 과정에서는 표면적인 문장 유창성보다 정확한 구조적 매핑이 중요하다. LoRA가 WikiSQL에서 강한 결과를 보인다는 것은, 적은 랭크의 보정만으로도 모델이 테이블 스키마와 질의 구조 사이의 대응을 효과적으로 재정렬할 수 있음을 뜻한다. 이는 저랭크 적응이 단순 스타일 조정이 아니라 구조적 생성에도 충분하다는 증거다.
반대로 SAMSum은 대화 요약이기 때문에, 여러 발화자 사이의 화행과 정보 중요도를 압축하는 능력이 중요하다. 잡담, 지시, 계획, 약속, 감정 표현이 섞여 있는 메신저 대화에서 핵심을 추출해야 하므로, 요약 모델은 긴 맥락을 정리하면서도 중심 사건을 놓치지 않아야 한다. LoRA가 SAMSum에서 완전 미세조정과 큰 차이 없이 작동한다는 사실은, 저랭크 적응이 정보 선택과 요약 압축 같은 상위 수준 생성에서도 충분한 제어력을 가질 수 있음을 보여 준다.
이 두 데이터셋은 생성 과업이라는 큰 범주 안에서도 적응 요구가 크게 다르다는 점을 잘 보여 준다. WikiSQL은 구조적 정합성이 중요하고, SAMSum은 내용 압축과 서술 응집성이 중요하다. LoRA가 이 상이한 과업 모두에서 경쟁력을 보인다는 것은, 저랭크 적응이 특정 생성 스타일에 국한되지 않는다는 해석을 가능하게 한다. 논문이 생성과 이해를 함께 포함한 이유도 바로 여기에 있다.
5.4 학습 설정과 재현 관점의 세부 해석
논문에서 자주 등장하는 하이퍼파라미터는 복잡하지 않다. 대표적으로 랭크는 8 수준, 스케일링은 16 또는 32, 옵티마이저는 AdamW이며, 학습률은 모델 크기와 과업 특성에 따라 조절되지만 일반적인 파인튜닝 범위 안에 있다. warmup 비율 역시 극단적으로 길지 않고, 시퀀스 길이는 128, 256, 512 같은 표준 값이 사용된다. 중요한 점은 LoRA가 새로운 최적화 기법을 추가로 요구하지 않는다는 사실이며, 이 때문에 기존 파인튜닝 레시피를 유지한 채 적응 비용만 크게 줄일 수 있다.
재현성 측면에서 보면, LoRA는 “특수한 트릭을 모두 맞춰야만 되는 방법”이 아니라 비교적 안정적인 기본값을 제공하는 편이다. 적용 모듈, 랭크, 스케일링, dropout 여부 정도만 정하면 기존 학습 파이프라인에 쉽게 들어간다. 이 단순성은 대형 모델 시대에 특히 중요하다. 거대한 모델에서는 한 번의 실험 비용이 매우 크기 때문에, 과도하게 민감한 하이퍼파라미터에 의존하는 방법은 실무 도입이 어렵다. LoRA는 이 지점에서도 강한 장점을 보였다.
5.5 GLUE 태스크별로 다시 읽는 LoRA의 적응 패턴
GLUE 평균은 편리하지만, 태스크별 성격을 분해해 보면 LoRA의 강점이 더 구체적으로 보인다. CoLA는 문장 수용성 판단이므로 단순한 단어 표면 정보보다 문법 구조의 적합성을 판별해야 한다. 이런 과업에서 좋은 결과가 나온다는 것은 LoRA가 얕은 분류 경계만 조정하는 것이 아니라, 모델 내부에서 이미 형성된 구문 표현을 유의미한 방향으로 재배치할 수 있음을 뜻한다. STS-B에서는 문장쌍 의미 유사도를 회귀적으로 다뤄야 하므로, 분류형 과업보다 더 연속적인 표현 정렬이 중요하다. MRPC와 QQP는 유사하지만 다른 말로 쓰인 문장쌍을 비교해야 하므로, 의미 수준의 매칭과 표면 중복 구분이 동시에 필요하다. LoRA가 이런 태스크에서 고르게 강하다는 사실은 적응이 특정 라벨 헤드의 미세한 조정에 그치지 않고, 문장 표현 공간 전체의 상대적 거리와 정렬을 실제로 바꾸고 있음을 시사한다.
MNLI와 RTE는 특히 중요하다. 두 과업 모두 entailment, contradiction, neutral 같은 논리 관계를 판별해야 하지만, MNLI는 대규모·다도메인 데이터셋이고 RTE는 훨씬 작고 민감하다. 따라서 MNLI에서 강하다는 것은 넓은 표현 일반화를, RTE에서 강하다는 것은 적은 데이터에서의 안정적 적응을 의미한다. 완전 미세조정이 아니더라도 LoRA가 이러한 추론형 과업에서 밀리지 않는다는 사실은, 저랭크 적응이 단순한 표면 패턴 주입에 국한되지 않는다는 점을 보여 준다. 다시 말해 LoRA는 사전학습 단계에서 이미 내재된 관계 추론 구조를 더 과업 친화적인 방향으로 미세 조정하는 데 충분한 자유도를 제공한다. 이는 거대 사전학습 모델에서 핵심 지식이 이미 내부에 있고, 파인튜닝은 그 지식의 읽기 경로를 조절하는 과정이라는 해석과도 맞닿아 있다.
QQP, MRPC 같은 중복 판단 태스크와 QNLI 같은 질문-문장 관계 태스크를 함께 보면 LoRA의 성격이 더욱 분명해진다. 중복 판단은 부분적 재진술과 어순 변화, 질문-진술 변환에 강해야 하고, QNLI는 질문에 대한 근거 문장을 찾는 식의 정렬 능력이 중요하다. 이들 과업에서 LoRA가 경쟁력을 유지한다는 것은 attention 투영의 작은 보정만으로도 토큰 간 상호작용 패턴을 충분히 수정할 수 있다는 뜻이다. 특히 query와 value에 LoRA를 넣는 기본 설정은 이러한 관계형 과업에서 자연스럽다. query는 무엇을 볼지를, value는 무엇을 전달할지를 조정하기 때문이다. GLUE 전반의 결과는 결국 LoRA가 언어 이해의 다양한 국면을 하나의 일관된 적응 포맷으로 다룰 수 있음을 보여 주는 집약적 증거라고 할 수 있다.
5.6 E2E 생성 지표를 더 세밀하게 읽는 방법
E2E 결과를 해석할 때 BLEU만 보면 LoRA의 장점을 충분히 이해하기 어렵다. BLEU는 표면적 n그램 중첩을 잘 포착하지만, 구조화된 의미 표현이 얼마나 충실하게 실현되었는지, 문장의 정보 밀도가 적절한지, 여러 참조 표현과의 다양한 일치가 나타나는지까지 모두 담지는 못한다. NIST는 정보량이 큰 희귀 표현의 일치를 더 중요하게 다루므로, 모델이 템플릿처럼 흔한 표현만 반복하는지 아니면 의미적으로 중요한 슬롯을 정확히 언급하는지 구분하는 데 도움이 된다. METEOR는 어형 변화와 부분적 의미 일치를 반영하므로, 표면 표현이 다르더라도 의미 전달이 맞는 경우를 더 잘 포착한다. ROUGE-L은 긴 부분수열 일치를 통해 문장 구조와 서술 흐름의 보존을 반영하고, CIDEr는 다중 참조문장 맥락에서 전반적인 기술 적합성을 평가한다. LoRA가 이 지표들 전반에서 균형 있게 강하다는 사실은, 단순한 문구 복제보다 의미 실현과 유창성을 함께 유지했다는 증거다.
구조적 데이터에서 자연어로의 변환은 일반 자유 생성보다 오히려 까다로운 면이 있다. 입력 의미 표현에 있는 속성과 값은 빠짐없이 반영되어야 하지만, 출력 문장은 기계적으로 나열되지 않고 자연스럽게 이어져야 한다. 정보 하나를 누락하면 factual error가 되고, 문장을 어색하게 만들면 유창성이 떨어진다. LoRA가 적은 파라미터로도 이런 균형을 유지하는 것은 중요한 관찰이다. 이는 저랭크 적응이 의미 슬롯을 선택적으로 강조하는 방식으로 작동하면서도, 사전학습 언어모델이 이미 갖고 있는 자연어 생성 능력을 그대로 활용하기 때문으로 이해할 수 있다. 다시 말해 LoRA는 생성 규칙을 처음부터 다시 배우는 것이 아니라, 이미 학습된 생성 장치가 특정 의미 표현을 더 잘 읽고 펼치도록 유도한다.
E2E와 같은 데이터셋에서 낮은 랭크가 통하는 이유를 더 생각해 보면, 많은 다운스트림 생성 과업이 전면적 언어 능력의 재구성을 요구하지 않음을 알 수 있다. 필요한 것은 이미 존재하는 표현 능력 중 일부 방향을 강화하거나 억제하는 일에 가깝다. 예를 들어 레스토랑 정보 설명 과업에서는 특정 슬롯 조합을 자연스럽게 문장화하는 경로만 강화하면 된다. LoRA의 저랭크 업데이트는 이러한 경로 선택 문제에 적합하다. 이는 LoRA가 생성 모델에서 단순한 압축 기법이 아니라, 사전학습 모델의 표현을 과업 목적에 맞게 선택적으로 재정렬하는 방법이라는 해석을 다시 한 번 지지한다.
6. 정량 결과의 핵심 — GLUE, E2E, GPT-2에서 적은 파라미터로 완전 미세조정을 따라잡는 방식
논문은 encoder-only 모델과 decoder-only 모델 모두에서 LoRA의 강점을 보인다. RoBERTa-base에서는 완전 미세조정 평균 86.4에 대해 LoRA가 약 0.3M 학습 파라미터만으로 평균 87.2를 기록한다. RoBERTa-large에서는 완전 미세조정 88.9, LoRA 89.0으로 사실상 동급 이상이며, DeBERTa-XXL에서는 완전 미세조정 91.1에 대해 LoRA 4.7M이 91.3을 기록한다. 규모가 커질수록 LoRA가 불리해지는 것이 아니라, 오히려 작은 적응 파라미터로도 강한 기준선을 유지한다는 점이 특징적이다.
| 모델 | 방법 | 학습 파라미터 | 평균 점수 | 해석 |
|---|---|---|---|---|
| RoBERTa-base | Full Fine-tuning | 전체 | 86.4 | 강한 기준선. |
| RoBERTa-base | LoRA | 0.3M | 87.2 | 더 적은 파라미터로 우세. |
| RoBERTa-large | Full Fine-tuning | 전체 | 88.9 | 대형 기준선. |
| RoBERTa-large | LoRA | 0.8M | 89.0 | 사실상 동급 이상. |
| DeBERTa-XXL | Full Fine-tuning | 전체 | 91.1 | 초대형 분류 기준선. |
| DeBERTa-XXL | LoRA | 4.7M | 91.3 | 효율과 품질을 동시에 확보. |
생성 과업의 대표 예시는 GPT-2 + E2E다. GPT-2 Medium에 LoRA를 적용하면 약 0.35M 학습 파라미터로 BLEU 70.4, NIST 8.85, METEOR 46.8, ROUGE-L 71.8, CIDEr 2.53을 기록한다. GPT-2 Large에서도 약 0.77M 파라미터로 BLEU 70.4, NIST 8.89, METEOR 46.8, ROUGE-L 72.0, CIDEr 2.47을 얻는다. 이 수치는 추가 학습량이 매우 작음에도 생성 품질이 안정적이라는 점을 보여 준다.
| 모델 | 학습 파라미터 | BLEU | NIST | METEOR | ROUGE-L | CIDEr |
|---|---|---|---|---|---|---|
| GPT-2 Medium + LoRA | 0.35M | 70.4 | 8.85 | 46.8 | 71.8 | 2.53 |
| GPT-2 Large + LoRA | 0.77M | 70.4 | 8.89 | 46.8 | 72.0 | 2.47 |
이 결과는 “학습 파라미터 수와 표현력은 비례한다”는 단순 직관이 대형 사전학습 모델에서는 자주 성립하지 않음을 보여 준다. 사전학습이 이미 충분히 풍부한 표현 기반을 마련했기 때문에, 다운스트림 적응은 전체 공간을 새로 쓰기보다 소수 방향의 조정만으로도 달성될 수 있다. LoRA는 바로 그 조정만을 포착하도록 설계된 방법이며, GLUE와 E2E를 동시에 통과함으로써 범용 적응 구조라는 점을 증명한다.
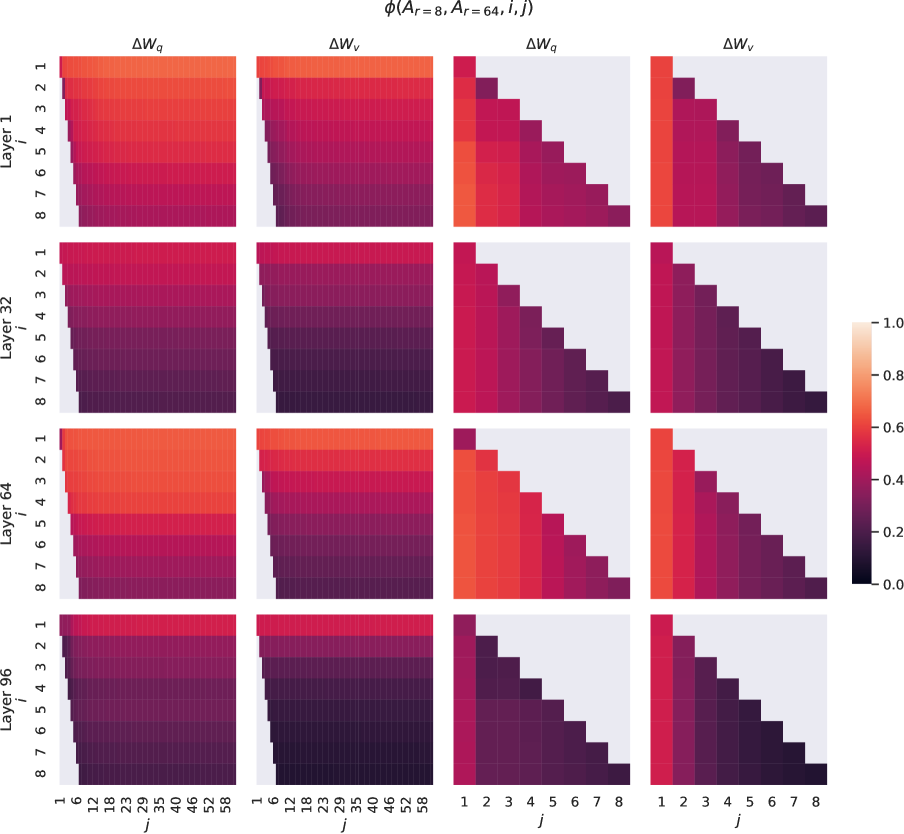
이 그림은 LoRA의 가장 중요한 경험적 관찰 가운데 하나를 요약한다. 랭크를 크게 키우지 않아도 성능이 이미 높은 수준에 도달하며, $r$을 더 늘린다고 해서 비례적으로 성능이 오르지 않는다. 이는 적응에 필요한 변화가 고차원 전체에 퍼져 있기보다 비교적 낮은 차원의 부분공간에 집중될 수 있음을 시사한다. 다시 말해 LoRA의 효율은 우연한 압축이 아니라 과업 적응 구조와 맞물린 결과로 해석된다. 이후 동적 랭크 할당이나 층별 랭크 조정 연구가 활발해진 것도, 이 관찰이 실제로 의미 있는 연구 질문을 남겼기 때문이다.
6.1 작은 추가 파라미터가 강한 결과를 내는 이유는 사전학습 표현의 재사용성에 있다
사전학습 모델은 이미 대규모 말뭉치에서 문법, 의미, 상식, 표현 대응 관계를 학습한다. 다운스트림 적응의 역할은 이 넓은 표현 공간에서 특정 업무에 유용한 방향을 선택하고 강조하는 것이다. LoRA의 작은 행렬은 이 선택 과정을 효율적으로 매개한다. 따라서 LoRA의 성공은 “적은 파라미터로도 충분히 복잡한 함수를 근사한다”는 일반론보다, 이미 충분히 좋은 사전학습 표현이 존재할 때 적응에 필요한 자유도는 훨씬 작을 수 있다는 관찰로 이해하는 편이 정확하다.
6.2 하이퍼파라미터 관점에서 $r=8$은 강한 기본값으로 작동한다
랭크를 1로 두면 극단적으로 작은 적응 모듈이 되고, 64 이상으로 키우면 표현력은 늘지만 효율 메시지는 약해진다. 논문에서 자주 등장하는 $r=8$은 이런 양극단 사이에서 강한 기본값으로 기능한다. 여기에 $\alpha=16$ 또는 32 수준의 스케일링과 AdamW, 적절한 warmup 비율을 결합하면 많은 설정에서 안정적인 학습이 가능하다. 이 단순성과 재현성은 LoRA가 후속 연구와 실무 라이브러리의 표준이 되는 데 결정적 역할을 했다.
6.3 처리량 향상은 단지 메모리 절감의 부산물이 아니다
논문이 보고한 약 25퍼센트 처리량 향상은 단순히 저장 공간이 줄었다는 의미가 아니다. 학습 가능한 파라미터가 줄면 그에 비례해 그래디언트 계산과 옵티마이저 업데이트 대상이 감소하고, 분산 학습 환경에서는 통신량도 함께 줄어든다. 특히 대형 모델에서 optimizer step은 메모리 대역폭과 통신 비용의 영향을 크게 받는데, LoRA는 이 병목을 직접 완화한다. 따라서 처리량 향상은 부수적 보너스가 아니라, 학습 파이프라인 전반이 가벼워진 결과로 해석해야 한다.
이 점은 실제 자원 배분 전략에도 영향을 준다. 같은 GPU 메모리 예산에서 더 큰 배치를 사용할 수 있고, 같은 배치라면 더 긴 시퀀스를 유지하거나 gradient accumulation 횟수를 줄일 수 있다. 결과적으로 학습 시간뿐 아니라 실험 반복 속도도 개선된다. 거대 모델 개발에서는 한두 번의 추가 실험이 전체 연구 일정에 큰 영향을 미치므로, LoRA의 처리량 개선 효과는 단순한 벤치마크 숫자를 넘어 연구 개발 주기의 단축이라는 가치로 이어진다.
6.4 GPT-3 결과는 저장 구조 자체를 바꾼다
초거대 모델에서 과업마다 전체 체크포인트를 별도로 저장하는 것은 비용도 크지만 관리도 어렵다. 버전 관리, 배포 이력 추적, 롤백, 보안 정책 적용, 스토리지 동기화 모두가 무거워진다. LoRA는 베이스 모델을 공유하고 과업별 차이만 작은 체크포인트로 저장하게 하므로, 저장 구조를 본질적으로 단순화한다. 이는 연구용 서버뿐 아니라 실제 서비스 인프라에서도 중요하다. 모델이 커질수록 “무엇을 저장할 것인가”라는 질문이 “무엇을 학습할 것인가”만큼 중요해지기 때문이다.
6.5 하이퍼파라미터 선택이 실제 학습 안정성에 미치는 영향
LoRA는 단순한 방법으로 알려져 있지만, 세부 하이퍼파라미터는 여전히 중요한 역할을 한다. 가장 대표적인 것은 랭크와 스케일링의 조합이다. 랭크가 너무 낮으면 필요한 적응 방향을 모두 담지 못할 수 있고, 반대로 지나치게 높으면 효율성이 떨어질 뿐 아니라 불필요한 자유도가 늘어 최적화가 불안정해질 수 있다. 이때 $\alpha/r$ 스케일링은 단순한 상수 곱이 아니라, 랭크가 달라져도 업데이트의 유효 크기를 일정 범위로 유지해 주는 균형 장치다. 실제로 랭크를 바꿀 때 성능 차이가 크지 않았던 이유 중 하나도 이 스케일링 덕분에 업데이트의 크기가 급격히 흔들리지 않았기 때문으로 이해할 수 있다. 따라서 LoRA를 단지 작은 행렬 두 개로 보는 것이 아니라, 랭크와 스케일링이 함께 만드는 적응 예산으로 보는 시각이 중요하다.
옵티마이저 관점에서는 AdamW가 널리 쓰이지만, 여기서 중요한 것은 weight decay와 warmup이 본체가 아닌 적응 모듈에만 적용된다는 점이다. 베이스 모델이 동결되어 있으므로, 실제 학습 동역학은 매우 작은 보정행렬의 최적화 문제로 바뀐다. 이 때문에 종종 완전 미세조정보다 더 높은 학습률이 허용되기도 하고, 반대로 너무 높은 학습률은 작은 모듈에 과도한 진동을 만들 수도 있다. warmup 비율이 의미를 갖는 것도 같은 이유다. 훈련 초기에는 보정항이 거의 영에 가까우므로, 너무 급격한 학습률 상승은 사전학습된 로짓 구조를 갑자기 흔들 수 있다. LoRA의 재현성이 좋다는 평가는 이런 동역학을 완전히 무시해도 된다는 뜻이 아니라, 몇 가지 핵심 원리만 지키면 비교적 안정적으로 수렴한다는 뜻에 가깝다.
시퀀스 길이와 배치 크기의 상호작용도 중요하다. LoRA는 적응 파라미터 수를 크게 줄이므로 같은 메모리 예산에서 더 긴 문맥이나 더 큰 배치를 허용하는 경우가 많다. 그러나 베이스 모델의 attention 연산 비용은 그대로이므로, 시퀀스 길이를 무작정 늘리는 전략이 항상 좋은 것은 아니다. 실제 실험에서는 과업 특성에 맞는 길이를 선택하는 것이 더 중요하다. 예를 들어 분류형 GLUE 과업에선 128 또는 256이 충분한 경우가 많고, 긴 문맥 요약이나 대화 과업에선 512 이상이 필요할 수 있다. LoRA는 이런 선택의 폭을 넓혀 주지만, 과업에 필요한 정보 범위를 대신 판단해 주지는 않는다. 따라서 효율성의 증가는 단순한 자원 절감이 아니라, 연구자가 더 나은 실험 설계를 시도할 수 있는 여유를 준다는 의미로 읽는 편이 정확하다.
6.6 merge와 unmerge가 실제 워크플로를 어떻게 바꾸는가
학습 단계에서 LoRA 모듈을 분리된 상태로 유지하는 이유는 단지 구현 편의성 때문만이 아니다. 분리 상태에서는 서로 다른 실험의 보정행렬을 독립적으로 비교하고, 특정 랭크나 적용 위치에 따른 차이를 명확하게 추적할 수 있다. 또한 동일한 베이스 모델에 여러 실험 결과를 순차적으로 얹어 보며 성능을 확인하기 쉽다. 반면 실제 배포 전에는 병합을 통해 단일 가중치처럼 다루는 편이 서빙 구조를 단순화한다. 이처럼 LoRA는 실험 단계와 배포 단계에서 서로 다른 표현 형태를 허용하는데, 이 유연성이 대형 모델 개발의 표준 워크플로와 매우 잘 맞는다.
병합 가능성은 특히 추론 지연과 메모리 지역성 측면에서 중요하다. 어댑터처럼 별도 모듈이 남아 있으면 매 레이어마다 추가 커널 호출과 텐서 이동이 생길 수 있지만, LoRA는 병합 후 기존 선형층 연산만 수행하면 된다. 이는 벤치마크 숫자 이상의 의미를 갖는다. 대형 모델 서빙에서는 작은 지연 차이도 동시성, 처리량, 비용 예측에 큰 영향을 주기 때문이다. 병합은 또한 모델 배포 단위를 단순화한다. 별도 모듈 로딩 없이 하나의 가중치 세트로 서비스할 수 있으므로, 추론 스택과 모니터링 체계도 간결해진다.
물론 unmerge가 언제나 무료는 아니다. 여러 과업의 LoRA를 요청마다 번갈아 적용해야 하는 환경에서는, 병합과 해제를 자주 반복하는 전략이 비효율적일 수 있다. 이 경우에는 분리된 상태에서 어댑터 선택을 수행하거나, 과업별로 별도 프로세스를 띄우는 식의 운영 설계가 필요하다. 다시 말해 LoRA의 merge와 unmerge는 단순 기능이 아니라, 서비스 형태에 따라 다른 배포 전략을 허용하는 선택지다. 논문의 구조가 이후 다양한 시스템 최적화 연구로 이어진 배경도 여기에 있다.
7. GPT-3 175B와 few-shot 비교의 의미 — LoRA가 산업적 규모에서 어떤 전환을 만들었는가
LoRA가 연구사적으로 특별한 위치를 갖는 이유는 GPT-3 175B 결과 때문이다. 논문에 따르면 GPT-3 175B의 완전 미세조정은 약 175,255.8M 학습 가능 파라미터를 요구하지만, LoRA는 설정에 따라 4.7M 또는 37.7M 수준의 파라미터만으로 적응을 수행한다. 즉 학습 대상 파라미터가 약 10,000배 감소한다. 여기에 더해 훈련 시 GPU 메모리 사용량이 약 3배 절감되고, 처리량은 약 25% 증가한다. 초대형 모델에서 이 차이는 편의성의 차원이 아니라 프로젝트 성립 여부를 가르는 기준이 된다.
| 설정 | 학습 가능 파라미터 | WikiSQL | MNLI-m | SAMSum R-1 | SAMSum R-2 | SAMSum R-L |
|---|---|---|---|---|---|---|
| Full Fine-tuning | 175,255.8M | 73.4 | 91.7 | 53.8 | 29.8 | 45.9 |
| LoRA | 4.7M / 37.7M | 74.0 | 91.6 | 53.4 | 29.2 | 45.1 |
정량적으로 보면 LoRA는 GPT-3에서 완전 미세조정과 거의 같은 품질을 유지한다. WikiSQL은 오히려 LoRA 74.0이 완전 미세조정 73.4보다 높고, MNLI-m은 91.6으로 91.7과 사실상 동일하다. SAMSum의 ROUGE 계열은 약간 낮지만, 학습 규모 차이를 감안하면 격차는 매우 작다. 결국 이 실험의 핵심은 “조금 손해 보더라도 싸다”가 아니라, 거의 같은 품질을 압도적으로 작은 비용으로 달성한다는 데 있다.
논문은 또한 few-shot GPT-3와 fine-tuned GPT-3의 차이를 함께 상기시킨다. 이는 대형 모델이 커질수록 인컨텍스트 러닝만으로 충분하다는 낙관에 대한 반례다. 예컨대 MNLI는 few-shot 40.6에서 fine-tuned 89.5로, RTE는 69.0에서 85.4로 크게 상승한다. 즉 사전학습 규모가 아무리 커도 파라미터 적응 자체는 여전히 중요하며, LoRA는 그 적응을 재정적으로 가능하게 만든 메커니즘으로 읽혀야 한다.
| 과업 | GPT-3 Few-shot | GPT-3 Fine-tuned | 차이 |
|---|---|---|---|
| MNLI | 40.6 | 89.5 | +48.9 |
| RTE | 69.0 | 85.4 | +16.4 |
이 비교는 LoRA의 의의를 더 선명하게 만든다. 만약 few-shot만으로 충분했다면 거대한 적응 인프라 자체가 필요 없었을 것이다. 그러나 실제로는 과업별 파인튜닝이 여전히 큰 품질 차이를 만들고, 따라서 그 적응을 얼마나 싸게 수행할 수 있는지가 중요해진다. LoRA는 완전 미세조정의 성능상 이점을 유지하면서도 비용 장벽을 낮춤으로써, 이후 instruction tuning, domain tuning, safety tuning, preference optimization이 폭발적으로 늘어나는 토대를 제공했다.

이 분석 그림은 성능 표만으로는 보이지 않는 구조적 메시지를 전달한다. LoRA의 관심사는 단순히 업데이트를 작게 만드는 데 그치지 않고, 실제 적응 변화가 어떤 방향에 집중되는지를 이해하는 데 있다. 원래 가중치와 보정항의 관계를 살펴보면, 다운스트림 적응이 전체 공간을 무질서하게 쓰기보다 특정 부분공간을 따라 움직일 가능성이 드러난다. 이것이 저랭크 가설의 경험적 설득력을 높여 준다. 성능과 구조 해석이 함께 제시되기 때문에, LoRA는 단순한 경험적 비법이 아니라 분석 가능한 적응 프레임워크로 읽힌다.
7.1 GPT-3 결과는 LoRA를 연구 아이디어에서 산업 해법으로 끌어올린다
RoBERTa나 GPT-2에서의 성과만으로도 LoRA는 흥미로운 효율화 기법이지만, GPT-3 175B 결과가 추가되면서 의미가 달라진다. 이제 LoRA는 “중간 규모 모델에서 잘 되는 경량 튜닝”이 아니라, 가장 비싼 모델일수록 더 가치가 커지는 적응 프레임워크가 된다. 실제 산업 환경에서 비용의 절대값이 중요하기 때문에, 초거대 모델에서의 절감 폭이 크다는 사실은 연구적 아름다움 이상으로 실천적 의미를 갖는다.
7.2 few-shot과 fine-tuning의 간극은 LoRA의 존재 이유를 다시 확인시킨다
few-shot 학습은 모델 내부 가중치를 바꾸지 않고 프롬프트만으로 과업을 유도하는 방식이므로 편리하지만, 그만큼 표현 공간을 직접 재조정하는 능력은 제한적이다. 반면 fine-tuning은 가중치 적응을 통해 과업별 경계와 생성 스타일을 더 적극적으로 조절할 수 있다. LoRA는 이 적응의 장점을 매우 싼 비용으로 가져오기 때문에, “프롬프트만 쓸 것인가”와 “전체를 다시 학습할 것인가” 사이에 강력한 제3의 선택지를 제공한다.
7.3 weight와 delta-weight의 관계는 왜 중요한가
LoRA 논문의 분석 파트가 흥미로운 이유는 단순한 점수 비교를 넘어, 학습된 보정항이 원래 가중치와 어떤 관계를 가지는지 탐색하기 때문이다. 만약 $\Delta W$가 원래 가중치 $W$와 거의 무관한 임의 방향으로 커진다면, 적응은 사실상 전면 재학습에 가까운 의미를 가질 수 있다. 그러나 분석은 적응 변화가 특정 부분공간과 구조를 띨 가능성을 시사한다. 이는 사전학습 모델이 이미 풍부한 기저를 형성하고 있으며, 다운스트림 적응은 그 기저를 선택적으로 재가중하는 과정일 수 있음을 뒷받침한다.
또한 서로 다른 층과 서로 다른 과업에서 학습된 보정항의 유사성을 보는 문제도 중요하다. 만약 여러 과업이 비슷한 방향의 부분공간을 공유한다면, 다중 과업 적응이나 어댑터 합성 같은 응용 가능성이 열린다. 반대로 과업별 보정이 거의 직교하는 방향에 놓인다면, 각 과업의 특화 정도가 크다는 뜻이 된다. 원 논문은 이 문제를 완전히 해결하지는 않지만, 저랭크 업데이트를 하나의 분석 객체로 만든 것만으로도 이후 subspace similarity 연구의 토대를 놓았다.
7.4 후속 연구와의 연결 — QLoRA, AdaLoRA, DoRA로 이어진 흐름
QLoRA는 양자화된 베이스 모델 위에 LoRA를 얹어, 본체 메모리까지 크게 줄이면서도 적응 성능을 유지하려는 방향으로 발전했다. AdaLoRA는 모든 층에 동일 랭크를 배정하는 대신, 중요도가 높은 층에 더 많은 적응 예산을 할당하는 동적 랭크 조절을 시도했다. DoRA는 저랭크 적응에서 방향과 크기를 분리해, LoRA가 다루기 어려운 일부 표현 변화를 더 정교하게 포착하려 했다. 이 흐름은 모두 원 논문의 통찰, 즉 적응은 전체를 다시 학습하지 않아도 된다는 관찰 위에서만 가능했다.
비전과 멀티모달 영역에서도 LoRA는 빠르게 확장되었다. 텍스트 인코더와 비전 인코더, 크로스어텐션 모듈, 디퓨전 U-Net의 선형 프로젝션 등에 동일한 재매개변수화가 적용되었고, 그 결과 LoRA는 언어모델을 넘어 범용 적응 포맷처럼 사용되기 시작했다. 하나의 논문이 제안한 수식이 생태계 수준의 인터페이스로 자리 잡은 사례라는 점에서, LoRA는 연구사적으로도 특이한 위치를 차지한다.
7.5 부분공간 유사성과 적응 재사용의 가능성
LoRA가 흥미로운 또 다른 이유는 적응 결과를 하나의 부분공간 객체로 바라보게 만든다는 점이다. 완전 미세조정에서는 각 과업이 모델 전체를 별도로 바꾸기 때문에, 어떤 과업과 어떤 과업이 비슷한 방향으로 모델을 움직였는지 비교하기 어렵다. 반면 LoRA에서는 상대적으로 작은 보정행렬을 통해 적응 방향을 분석할 수 있다. 예를 들어 요약과 대화 요약, 자연어 추론과 질의응답처럼 비슷한 언어 현상을 다루는 과업은 부분적으로 유사한 적응 방향을 공유할 가능성이 있다. 이런 관찰은 여러 LoRA를 결합하거나, 이미 학습된 LoRA를 다른 과업의 초기값으로 사용하는 전략과 연결된다. 저랭크 업데이트는 단지 저장이 작은 것이 아니라, 적응 자체를 비교 가능한 분석 단위로 만든다.
부분공간 유사성 개념은 과업 간 전이 가능성을 설명하는 데도 유용하다. 어떤 과업의 LoRA가 다른 과업에서 좋은 초기화가 된다면, 두 과업이 사전학습 표현 공간에서 비슷한 방향을 필요로 한다는 뜻일 수 있다. 반대로 성격이 전혀 다른 과업은 거의 직교하는 보정 방향을 요구할 수 있다. 원 논문은 이 지점을 완전히 수학화하지는 않았지만, 업데이트를 저랭크 구조로 명시함으로써 이런 비교가 가능한 조건을 마련했다. 이후 연구들이 LoRA 합성, 평균화, 선택적 병합, 라우팅을 시도한 것도 이 분석적 장점 덕분이다.
이 관점은 대형 모델의 모듈식 적응을 이해하는 데도 도움이 된다. 만약 과업별 LoRA가 일정 부분 공통 부분공간을 공유한다면, 미래에는 완전히 독립적인 어댑터 모음이 아니라 공통 기저와 과업별 잔차로 적응을 표현하는 방식이 가능할 수 있다. LoRA는 그 출발점으로 볼 수 있다. 즉 이 논문은 단지 “작게 학습하자”가 아니라, 적응을 부분공간의 문제로 다시 서술하는 계기를 제공했다는 점에서 더 길게 남는다.
7.6 $W$ 대 $\Delta W$ 분석이 주는 이론적 함의
원래 가중치 $W$와 학습된 보정항 $\Delta W$의 관계를 보는 이유는 적응이 사전학습 모델을 얼마나 보존하는지 가늠하기 위해서다. 만약 적응이 완전히 새로운 방향으로만 일어난다면, 사전학습 가중치는 단지 초기값 역할만 하고 실제 과업 해결은 새 파라미터가 담당한다고 볼 수 있다. 그러나 LoRA의 결과는 보정항이 원래 가중치와 상호작용하며 표현을 미세하게 기울이는 그림에 더 가깝다. 이는 사전학습 모델이 이미 충분한 기저를 제공하고, 다운스트림 적응은 그 기저를 전면 재구축하기보다 특정 방향을 증폭하거나 억제하는 방식으로 작동할 수 있음을 뜻한다.
이 해석은 왜 작은 랭크가 효과적인지 설명하는 데도 도움을 준다. 이미 강한 사전학습 기저가 존재한다면, 필요한 것은 새로운 전공간의 학습이 아니라 기저의 재가중과 정렬일 수 있다. 그렇다면 업데이트의 유효 자유도는 본질적으로 낮아질 수 있다. LoRA가 보여 준 랭크 민감도 실험은 바로 이 가능성을 정량적으로 뒷받침한다. 물론 이것이 모든 과업에 적용된다는 보장은 없지만, 적어도 언어 이해와 생성의 넓은 범위에서 이 가설이 놀랄 만큼 잘 맞았다는 사실이 논문의 영향력을 키웠다.
또한 $W$와 $\Delta W$의 관계는 안전성·정렬 연구에서도 중요하다. 모델 행동을 바꾸되 핵심 언어 능력은 유지하려면, 전면적 재학습보다 제한된 방향의 조정이 더 바람직할 수 있다. LoRA는 이런 목적에 적합한 구조를 제공한다. 실제로 이후 정렬과 선호 학습 파이프라인에서 LoRA가 널리 사용된 이유도, 비교적 작은 변화로 모델 행동을 조정하면서도 사전학습 성능을 크게 훼손하지 않는 경향이 있기 때문이다.
8. 저랭크 가설, 랭크 민감도, 후속 연구 연결 — 왜 LoRA는 하나의 테크닉을 넘어 연구 프로그램이 되었는가
LoRA를 오래 살아남게 만든 요인은 성능 수치뿐 아니라 rank deficiency라는 문제의식이다. 저자들은 적응 업데이트가 본질적으로 저랭크일 수 있다는 가설을 실험으로 점검한다. 대표적으로 $W_q, W_v$에 대해 랭크를 1, 8, 64로 바꾸어도 WikiSQL과 MultiNLI 성능 차이가 크지 않다는 결과는, 적응의 핵심 자유도가 생각보다 작을 수 있음을 보여 준다. 이는 단순한 압축의 문제가 아니라, 사전학습 모델이 이미 넓은 표현 공간을 보유하고 있어 다운스트림 적응은 그중 일부 방향만 조절하면 충분하다는 해석으로 이어진다.
| 적용 위치 | 랭크 $r$ | WikiSQL | MultiNLI | 해석 |
|---|---|---|---|---|
| $W_q,W_v$ | 1 | 73.4 | 91.3 | 극단적으로 작은 랭크에서도 강하다. |
| $W_q,W_v$ | 8 | 73.8 | 91.6 | 작은 증가로 최고권 성능에 도달한다. |
| $W_q,W_v$ | 64 | 73.5 | 91.4 | 랭크 증가는 비례 이득을 주지 않는다. |
수치상으로도 WikiSQL은 73.4 → 73.8 → 73.5, MultiNLI는 91.3 → 91.6 → 91.4 수준이다. 이는 랭크를 크게 올리는 것이 필수적이지 않다는 점을 보여 주며, LoRA가 극단적 모델 압축이 아니라 적응 구조에 대한 가설 검증이라는 인상을 강화한다. 이러한 결과는 이후 AdaLoRA처럼 층별 랭크를 동적으로 조절하는 방법, DoRA처럼 방향과 크기를 분리하는 방법, QLoRA처럼 양자화된 본체 위에 LoRA를 얹는 방법으로 이어진다.
후속 연구 관점에서 보면, LoRA는 단순한 한 편의 방법론이 아니라 하나의 연구 프로그램을 열었다. 첫째, 적응이 정말 저랭크인지 묻는 이론·분석 축이 생겼다. 둘째, 어떤 모듈에 어떤 랭크를 둘지 결정하는 자동화 축이 생겼다. 셋째, 4-bit / 8-bit 양자화와 결합해 훨씬 작은 메모리에서 튜닝하는 시스템 축이 생겼다. 넷째, 텍스트뿐 아니라 비전, 멀티모달, 음성 모델로 확장되는 응용 축이 생겼다. 이 모든 확장은 기본적으로 “동결된 본체 + 작은 저랭크 보정”이라는 LoRA의 인터페이스를 공유한다.
다만 저랭크 가설을 과도하게 일반화하는 것은 주의가 필요하다. 매우 큰 도메인 이동, 전문 지식 주입, 안전성 규칙 재편, 멀티모달 정렬, 추론 스타일 교정 등은 더 높은 자유도를 요구할 수 있다. 실제로 일부 후속 연구는 특정 층에서 높은 랭크가 필요하거나, attention보다 MLP가 더 중요하다고 보고하기도 했다. 따라서 LoRA의 핵심 주장은 “모든 적응은 언제나 저랭크다”가 아니라, 많은 실제 과업에서 저랭크가 놀랄 만큼 충분하다는 경험적 사실에 가깝다.
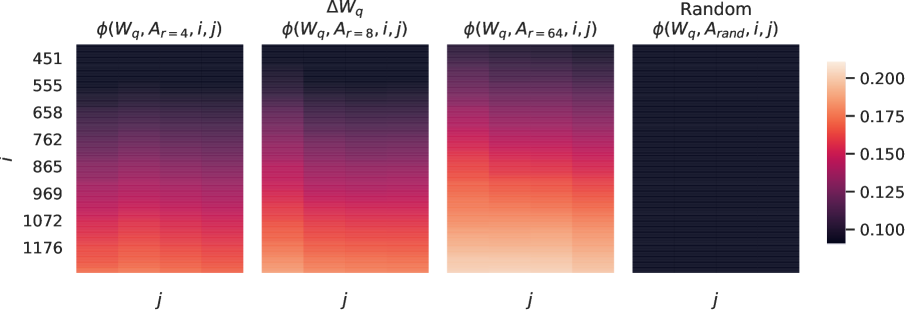
부록 성격의 이 그림은 LoRA를 단순 실용 트릭이 아니라 설명 가능한 설계로 만드는 데 기여한다. 저자들은 여러 보조 분석을 통해 작은 랭크가 실제로 어떤 형태의 변화를 만들어 내는지 정성적 단서를 제공한다. 완전한 이론이 제시된 것은 아니지만, 적응 업데이트의 부분공간 구조를 이해하려는 시도가 있었기에 LoRA는 “잘 되는 방법”을 넘어 “왜 잘 되는지 분석 가능한 방법”으로 받아들여졌다. 이러한 해석 가능성은 후속 연구가 랭크 선택, 층 배분, 모듈 설계를 더 세밀하게 발전시키는 토대를 제공했다.
8.1 merge / unmerge와 체크포인트 교체 구조는 후속 생태계의 기본 인터페이스가 되었다
오늘날 많은 오픈 모델 배포에서는 베이스 모델 하나와 여러 LoRA 체크포인트를 조합해 과업별 모델을 구성한다. 이는 LoRA가 본체를 복제하지 않고도 적응 상태를 저장할 수 있게 만들었기 때문이다. 필요 시 병합하여 단일 가중치로 서빙하고, 개발 단계에서는 분리된 상태로 계속 학습하거나 여러 모듈을 교체해 비교할 수 있다. 이 워크플로는 이후 멀티-어댑터, 라우팅, 합성 LoRA 같은 연구와 운영 방식의 출발점이 되었다.
8.2 장점과 한계를 함께 읽어야 LoRA의 실제 위치가 보인다
LoRA의 장점은 분명하다. 학습 파라미터 감소, 메모리 절감, 추론 지연 무증가, 체크포인트 저장 효율, task switching 용이성이 모두 있다. 반면 베이스 모델 자체의 순전파 비용은 그대로이며, 서로 다른 LoRA를 한 배치에 섞는 운영은 여전히 까다롭다. 또한 모든 과업에서 같은 랭크와 같은 적용 위치가 최적이라고 보장할 수 없다. 따라서 LoRA는 만능이 아니라, 매우 강한 기본값이자 후속 조정의 출발점으로 보는 것이 정확하다.
8.3 장점의 세부 분해 — 저장, 배포, 실험 반복 속도에서의 이득
저장 측면에서 LoRA의 장점은 단지 체크포인트가 작다는 사실을 넘는다. 여러 버전의 적응 실험을 동시에 보관할 때, 전체 모델 사본 대신 작은 보정행렬만 저장하면 실험 이력 관리가 훨씬 쉬워진다. 배포 측면에서는 베이스 모델 이미지를 한 번만 배포하고 과업별 LoRA만 추가로 동기화하면 되므로 운영 부담이 줄어든다. 연구 측면에서는 작은 체크포인트 덕분에 실험을 자주 분기하고 비교하기 쉬워지며, 실패 실험의 비용도 낮아진다. 이처럼 LoRA의 효율은 훈련 단계에만 한정되지 않고 모델 생애주기 전반에 영향을 준다.
또한 LoRA는 동일한 베이스 모델을 공유하는 여러 과업 사이의 조직적 협업에도 유리하다. 하나의 팀은 요약 LoRA를, 다른 팀은 분류 LoRA를, 또 다른 팀은 검색 보조 LoRA를 별도로 개발하면서도 베이스 모델 버전과 공통 서빙 환경을 유지할 수 있다. 이 구조는 대규모 조직에서 실질적인 장점이 된다. 모델 본체를 자주 갈아엎지 않고도 과업별 개선을 빠르게 실험할 수 있기 때문이다.
8.4 남는 한계 — 베이스 모델 비용, 혼합 배치, 강한 도메인 이동
LoRA가 미세조정 비용을 크게 줄여도, 베이스 모델 자체가 너무 크면 추론 비용은 여전히 높다. 즉 LoRA는 적응 비용을 낮추는 방법이지, 거대 모델 추론을 무료로 만드는 방법이 아니다. 또한 샘플마다 다른 LoRA를 적용해야 하는 다중 과업 서빙은 커널 관점에서 까다롭고, 병합과 언머지를 자주 반복하는 전략은 실시간 서비스에서는 비효율적일 수 있다. 이 문제는 별도의 라우팅 계층, 멀티어댑터 커널, 또는 과업군 묶음 정책이 필요함을 뜻한다.
강한 도메인 이동 역시 주의해야 한다. 예를 들어 법률, 의료, 과학 계산처럼 전문 용어와 형식이 크게 다른 영역, 혹은 안전성 규칙을 대대적으로 재편해야 하는 영역에서는 낮은 랭크만으로 충분하지 않을 수 있다. 이 경우 더 높은 랭크, 더 넓은 적용 위치, 다른 적응 메커니즘과의 결합이 필요하다. 따라서 LoRA의 가장 정확한 위치는 “항상 충분한 유일한 해법”이 아니라, 대부분의 적응에서 가장 먼저 시도할 만한 강력한 기준선이다.
8.5 대형 모델 서비스 관점의 실질적 장단점
서비스 운영 관점에서 LoRA의 가장 큰 장점은 동일한 베이스 모델을 기준으로 여러 기능을 빠르게 전개할 수 있다는 점이다. 예를 들어 하나의 기본 언어모델 위에 요약, 검색 보조, 질의응답, 분류, 스타일 변환용 LoRA를 각각 올려 두면, 모델 본체를 중복 저장하지 않고도 다양한 기능을 시험할 수 있다. 이는 제품 개발 속도를 높이고, 모델 버전 관리를 단순화하며, 롤백과 실험 분기에도 유리하다. 반면 기능 수가 매우 많아질수록 각 LoRA의 호환성 관리, 베이스 모델 버전 일치, 병합 결과 검증, 요청 라우팅 설계가 별도의 운영 이슈로 등장한다. 즉 LoRA는 운영을 단순하게 만들면서도 동시에 새로운 운영 규율을 요구한다.
추론 지연이 늘지 않는다는 장점도 상황에 따라 더 정확히 읽어야 한다. 단일 LoRA를 병합해 하나의 서비스로 제공하는 경우에는 실제로 추가 지연이 거의 없다. 그러나 여러 LoRA를 요청마다 다르게 선택해야 한다면, 로딩과 선택, 병합 정책에 따라 지연이 다시 생길 수 있다. 따라서 LoRA의 무지연성은 “병합된 단일 모델”이라는 배포 가정 아래에서 가장 강하게 성립한다. 이 점을 이해하면 논문이 왜 어댑터의 지연시간 수치를 강조했는지도 분명해진다. LoRA의 강점은 적응 자체에 새 경로를 남기지 않는 데 있으며, 이를 최대한 활용하려면 서빙 구조 역시 그 장점을 살리는 방향으로 설계되어야 한다.
또 하나의 장점은 규제와 보안 측면의 관리 용이성이다. 베이스 모델을 공통으로 유지하면 검토와 인증 절차를 한 번의 기준으로 맞추기 쉬우며, 과업별 차이는 상대적으로 작은 적응 모듈로 관리할 수 있다. 반면 과업별 LoRA가 많아질수록 어떤 모듈이 어떤 데이터를 반영해 학습되었는지, 어떤 편향과 위험을 갖는지 추적해야 하므로 메타데이터 관리가 중요해진다. 즉 LoRA는 기술적으로만이 아니라 거버넌스 측면에서도 새로운 장단점을 동시에 만든다. 이 역시 논문이 열어 놓은 현실적 후속 문제로 볼 수 있다.
8.6 왜 LoRA는 지금도 기본 선택지로 남아 있는가
후속 방법이 많이 등장했음에도 LoRA가 여전히 기본 선택지로 남아 있는 이유는 구조가 단순하면서도 확장성이 높기 때문이다. 단순한 선형층 보정이라는 인터페이스는 거의 모든 프레임워크와 모델 구조에 이식 가능하고, 필요하면 양자화, 동적 랭크 조절, 다중 어댑터, 정렬 학습과도 쉽게 결합된다. 어떤 방법이 더 높은 점수를 내더라도 구현 복잡도가 너무 높거나 특정 모델에서만 작동하면 널리 퍼지기 어렵다. LoRA는 반대로 “쉬운 기본값”과 “높은 확장성”을 동시에 가졌다. 학계와 산업계가 모두 선호할 조건을 갖춘 셈이다.
또한 LoRA는 실패 비용이 낮다. 완전 미세조정은 한 번의 실험이 큰 자원을 요구하지만, LoRA는 상대적으로 작은 체크포인트와 적은 학습 상태만 다루므로 반복 실험이 쉽다. 대형 모델 연구에서 중요한 것은 최고의 방법 하나를 찾는 일만이 아니라, 제한된 자원 안에서 더 많은 가설을 검증하는 일이다. LoRA는 바로 그 실험 가능성을 크게 넓혔다. 이런 이유로 LoRA는 지금도 새로운 모델을 처음 적응할 때 가장 먼저 시도하는 기준선으로 남아 있으며, 이후 더 복잡한 방법의 성능을 판단하는 참조축 역할까지 수행한다.
요약하면 LoRA는 단순한 효율화 기법이 아니라, 대형 모델 적응의 사고방식을 바꾼 방법이다. 사전학습된 거대한 본체를 당연히 다시 학습해야 한다는 전제를 깨고, 필요한 변화만 작은 부분공간에서 학습해도 충분할 수 있다는 실천적 기준을 제시했다. 이 기준은 이후 수많은 파생 연구를 낳았고, 현재까지도 대형 모델 튜닝의 기본 언어로 남아 있다. 논문 한 편이 연구 질문, 실험 표준, 라이브러리 인터페이스, 서비스 워크플로를 동시에 바꾼 사례라는 점에서 LoRA의 위치는 여전히 특별하다.
8.7 실전 적용 관점에서 정리하는 LoRA 운용 원칙
실전에서 LoRA를 적용할 때 가장 먼저 확인해야 할 것은 과업이 실제로 어느 정도의 표현 수정을 요구하는가이다. 입력 형식이 단순히 달라지는 수준인지, 출력 문체와 구조가 크게 바뀌는지, 외부 지식을 강하게 주입해야 하는지에 따라 적합한 적용 위치와 랭크가 달라진다. 일반적인 분류와 추론, 요약, 질의응답에서는 attention의 query와 value에 낮은 랭크로 시작해도 충분한 경우가 많다. 반면 구조적 생성이나 강한 도메인 이동이 예상되면 MLP 일부까지 확장하거나 특정 상위 층에 더 큰 랭크를 주는 편이 안정적일 수 있다. 이처럼 LoRA의 기본 강점은 적은 비용으로 시작해 점진적으로 확장할 수 있다는 데 있다. 완전 미세조정처럼 처음부터 가장 비싼 선택지를 강제하지 않는다는 점이 실제 실험 설계에서 큰 이점이 된다.
또한 데이터 규모와 과적합 위험을 함께 고려해야 한다. 데이터가 매우 적을 때는 완전 미세조정보다 LoRA가 오히려 더 안정적일 수 있다. 전체 모델을 풀어 두면 소규모 데이터에 과도하게 맞춰질 위험이 커지지만, 저랭크 보정은 적응 자유도를 제한함으로써 일종의 구조적 정규화 효과를 제공하기 때문이다. 반대로 데이터가 매우 많고 도메인 이동도 크다면, 낮은 랭크만으로는 충분한 적응력을 얻지 못할 수 있다. 이 경우에도 LoRA는 유용하다. 먼저 낮은 랭크로 기준선을 확보한 뒤, 필요한 경우 랭크를 점진적으로 키우거나 적용 모듈을 늘려 성능 향상의 원인을 해부적으로 파악할 수 있기 때문이다. 즉 LoRA는 단일 해답이 아니라, 적응 복잡도를 점진적으로 조절하는 실험 프레임워크로 이해하는 것이 적절하다.
검증 절차 역시 중요하다. LoRA는 체크포인트가 작기 때문에 실험 개수가 빠르게 늘어나기 쉽고, 이로 인해 오히려 어떤 실험이 어떤 설정에서 나왔는지 혼동하기 쉽다. 따라서 랭크, 스케일링, 적용 모듈, dropout, 학습률, warmup 비율, 데이터 전처리 버전을 모두 메타데이터로 함께 저장하는 관행이 필요하다. 이 문제는 완전 미세조정에서도 존재하지만, LoRA에서는 실험 회전율이 높아지는 만큼 더 중요해진다. 논문이 단순한 인터페이스를 제안했다는 사실은 곧 표준화된 실험 기록 체계를 만들기 쉽다는 뜻이기도 하다. 실제로 이후 라이브러리들은 LoRA 구성값을 명시적으로 저장하는 설정 파일 체계를 발전시켰고, 이는 재현성과 협업 효율을 크게 높였다.
배포 단계에서는 병합 여부를 서비스 형태에 맞춰 결정해야 한다. 한 과업에 대해 장기간 고정된 서비스를 제공한다면, 병합된 단일 가중치 형태가 가장 간결하다. 반대로 여러 과업을 빠르게 교체하며 테스트해야 한다면 분리된 LoRA 체크포인트를 유지하는 편이 실용적이다. 이때 중요한 것은 어떤 전략을 택하더라도 베이스 모델 버전과 LoRA 버전의 정합성을 엄격히 관리하는 일이다. 베이스 모델이 조금만 달라져도 동일한 LoRA가 의도한 결과를 내지 못할 수 있기 때문이다. 따라서 LoRA 생태계에서는 “작은 어댑터 파일”이 곧 독립적으로 안전한 모듈이라는 오해를 피해야 한다. LoRA는 언제나 특정 베이스 모델과 짝을 이루는 적응 파라미터이며, 그 관계를 정확히 추적하는 운영 규칙이 함께 필요하다.
8.8 LoRA가 남긴 연구적 함의와 앞으로의 질문
LoRA가 남긴 가장 큰 연구적 함의는 대형 모델 적응을 더 이상 전면적 재학습으로만 생각하지 않게 만들었다는 점이다. 사전학습 모델이 충분히 크고 표현력이 넓다면, 다운스트림 적응은 새 지식을 통째로 집어넣는 일보다 기존 표현을 다시 정렬하는 일일 수 있다. 이 관점은 파인튜닝의 목표 자체를 바꾼다. 무엇을 모두 바꿀 것인가가 아니라, 어떤 부분공간을 얼마나 움직이면 원하는 과업 성능이 나오는가를 묻게 되기 때문이다. 이후 등장한 적응 방법들의 상당수는 사실상 이 질문에 대한 변형된 답변이라고 볼 수 있다. 어떤 방법은 랭크를 동적으로 조절했고, 어떤 방법은 양자화와 결합했으며, 어떤 방법은 특정 층의 중요도를 학습했다. 그러나 출발점은 모두 동일하다. 거대한 모델을 전부 다시 학습하지 않아도 된다는 LoRA의 실증이 있었기 때문에 이러한 연구들이 의미를 가질 수 있었다.
앞으로의 질문도 자연스럽게 여기서 나온다. 첫째, 적응에 필요한 부분공간은 과업마다 얼마나 겹치는가. 둘째, 층별로 최적의 랭크와 적용 위치를 자동으로 정할 수 있는가. 셋째, 단일 과업 LoRA를 넘어 여러 LoRA를 안전하게 합성하거나 분해할 수 있는가. 넷째, 안전성 조정이나 가치 정렬처럼 섬세한 행동 교정에서도 저랭크 적응이 어디까지 충분한가. 다섯째, 멀티모달과 도구 사용 환경에서 부분공간 적응은 어떤 형태로 확장되는가. 이러한 질문들은 모두 LoRA가 단지 비용 절감의 해법이 아니라 적응 구조에 대한 새로운 연구 틀을 제안했음을 보여 준다. 좋은 논문은 하나의 답만 주는 것이 아니라 이후 어떤 질문을 해야 하는지까지 바꾸는데, LoRA는 그 조건을 충족한다.
또한 LoRA는 사전학습 모델의 지식 표현에 대한 철학적 해석에도 영향을 준다. 만약 작은 저랭크 업데이트만으로도 과업 성능이 크게 바뀐다면, 모델 내부에는 이미 다양한 과업 수행에 필요한 잠재적 기저가 준비되어 있고, 적응은 그 기저를 읽어 내는 좌표계를 조정하는 일일 수 있다. 이런 해석은 파인튜닝을 새로운 지식의 추가라기보다 기존 지식의 검색 경로와 우선순위 조정으로 보게 만든다. 물론 모든 과업이 이에 해당하지는 않겠지만, 적어도 언어 이해와 생성의 상당수에서 이 그림이 꽤 잘 맞는다는 점을 LoRA가 보여 주었다. 이러한 관점은 최근 representation editing, activation steering, sparse updating 같은 흐름과도 연결되며, 모델 해석 연구와 적응 연구를 하나의 공통 질문으로 묶는 역할을 한다.
마지막으로 LoRA는 연구와 산업의 관계를 다시 생각하게 만든다. 많은 논문이 이론적으로 아름답거나 특정 벤치마크에서만 강하지만, 실제 생태계 표준으로 남는 경우는 드물다. LoRA는 반대로 수식이 간단하고 구현이 쉬우며, 초거대 모델에서 비용 절감 효과가 극적이고, 후속 확장이 자연스럽다는 조건을 동시에 만족했다. 그래서 하나의 논문 아이디어가 라이브러리 기본 옵션, 커뮤니티 표준 체크포인트 형식, 대형 모델 서비스 워크플로까지 확장될 수 있었다. 이러한 사례는 효율적 적응 연구에서 무엇이 오래 남는지 보여 준다. 단지 점수가 조금 높은 방법이 아니라, 많은 사람이 쉽게 사용하고 확장할 수 있는 구조가 결국 생태계를 바꾼다는 사실을 LoRA는 매우 분명하게 보여 준다.
8.9 도메인 적응과 지식 주입의 관점에서 보는 LoRA
도메인 적응 문제를 생각하면 LoRA의 장점과 한계가 동시에 더 분명해진다. 일반 도메인에서 잘 학습된 언어모델을 법률, 의료, 금융, 과학 문헌, 기업 내부 문서처럼 전문성이 높은 영역에 맞추려면, 용어 분포와 문체뿐 아니라 추론 규칙과 답변 형식까지 함께 바뀌는 경우가 많다. 이때 완전 미세조정은 강력하지만 비용이 너무 크고, 프롬프트만으로는 도메인 특유의 규칙을 안정적으로 반영하기 어려울 수 있다. LoRA는 그 중간에서 실제로 매우 매력적인 선택지가 된다. 낮은 랭크의 보정만으로도 용어 사용, 출력 형식, 문체 우선순위를 상당 부분 교정할 수 있기 때문이다. 그러나 동시에 도메인 이동의 강도가 클수록 낮은 랭크만으로는 충분하지 않을 수도 있다. 따라서 도메인 적응에서 LoRA를 이해할 때는 “항상 충분하다”보다 “가장 비용 효율적인 첫 번째 단계”라는 표현이 더 정확하다.
지식 주입 관점에서도 비슷한 논리가 적용된다. 모델에 특정 사실 집합이나 조직 내부 정책, 최신 제품 정보, 업무 절차를 반영하려고 할 때, 실제로 필요한 것이 전면 재학습인지 아니면 출력 경로의 재정렬인지 구분하는 일이 중요하다. 많은 경우 모델은 이미 일반 언어 능력과 기본 추론 틀을 갖추고 있으므로, 필요한 것은 지식 자체의 총량 확대보다 특정 정보의 우선순위 조정일 수 있다. LoRA는 이런 상황에서 효과적일 가능성이 크다. 적은 보정행렬로도 답변 스타일과 정보 선택 경향을 바꿀 수 있기 때문이다. 반면 완전히 새로운 전문 추론 체계나 계산 절차를 깊게 학습해야 한다면, 더 큰 랭크나 다른 적응 방식이 필요할 수 있다. 이처럼 LoRA는 지식 주입 문제를 일괄적으로 해결하는 만능 열쇠가 아니라, 지식 변경의 성격이 무엇인지 진단하게 만드는 도구이기도 하다.
실제로 도메인 적응 실험을 설계할 때는 세 가지 질문이 중요하다. 첫째, 모델이 이미 일반 도메인에서 배운 표현 중 어떤 부분을 재사용할 수 있는가. 둘째, 새 도메인의 형식과 용어가 기존 표현을 얼마나 비틀어야 하는가. 셋째, 최종 목적이 분류, 추론, 생성, 요약 중 무엇인가. 이 질문들에 대한 답이 LoRA의 적용 위치와 랭크를 결정한다. 예를 들어 용어와 문체 조정이 핵심이라면 attention 투영만으로도 충분할 수 있지만, 긴 문맥에서 복잡한 관계 추론이 중요하다면 상위 층이나 MLP 적응이 필요할 수 있다. 즉 LoRA의 진짜 강점은 모든 도메인에 같은 해법을 제공하는 데 있지 않고, 도메인별 적응 요구를 작고 관리 가능한 실험 단위로 분해하게 만든다는 데 있다.
8.10 정렬과 안전성 조정 맥락에서의 LoRA 활용
현대 대형 모델 개발에서 중요한 후속 단계 중 하나는 정렬과 안전성 조정이다. 유해한 출력을 줄이고, 정책 위반 가능성을 통제하며, 사용자 지시를 더 잘 따르게 만드는 과정은 단순한 성능 향상과 다른 성격을 갖는다. 여기서 LoRA가 널리 사용되는 이유는 전체 모델의 언어 능력을 크게 훼손하지 않으면서도, 출력 경향과 응답 선택 경로를 비교적 작은 변화로 조절할 수 있기 때문이다. 안전성 조정은 보통 모델의 기반 언어 능력을 완전히 바꾸기보다, 특정 상황에서 어떤 응답을 선호할지의 정책을 바꾸는 작업에 가깝다. 이런 문제는 전면 재학습보다 제한된 방향의 적응이 더 적합할 수 있고, LoRA의 저랭크 구조는 바로 그 지점에서 실용적 장점을 가진다.
물론 안전성 조정에서 LoRA가 항상 충분하다고 볼 수는 없다. 어떤 정책은 얕은 출력 경향의 수정만으로 해결되지만, 어떤 문제는 사실상 모델의 세계지식 사용 방식과 추론 경로를 깊게 바꿔야 할 수 있다. 예를 들어 사실 왜곡을 줄이거나 복잡한 도구 사용 규칙을 안정적으로 따르게 하려면, 단순한 스타일 조정보다 더 넓은 적응이 필요할 수 있다. 그럼에도 LoRA가 기본 도구로 자주 선택되는 이유는 명확하다. 적은 비용으로 여러 정책 버전을 빠르게 시험해 볼 수 있고, 실패 실험의 비용이 낮으며, 특정 정책 변화가 모델의 다른 능력에 미치는 영향을 비교적 쉽게 측정할 수 있기 때문이다. 다시 말해 LoRA는 정렬 문제에서 완전한 해결책이라기보다, 정책 조정의 탐색 공간을 현실적인 비용 안으로 끌어오는 장치다.
이 맥락에서 LoRA는 모델 행동 연구의 방법론적 도구로도 중요하다. 완전 미세조정은 변화가 너무 광범위해 어떤 수정이 어떤 행동 변화를 만들었는지 해석하기 어렵지만, LoRA는 상대적으로 제한된 보정항을 통해 행동 변화를 유도하므로 비교 분석이 쉽다. 예를 들어 서로 다른 안전성 정책을 반영한 여러 LoRA를 학습한 뒤, 응답 변화와 성능 손실을 비교하면 어떤 종류의 정책이 모델 내부 표현에 더 큰 부담을 주는지 간접적으로 살펴볼 수 있다. 이런 점에서 LoRA는 단지 효율적 도구를 넘어, 모델 행동과 적응의 관계를 실험적으로 탐구하는 분석 장치로도 기능한다. 정렬과 안전성 연구가 계속 중요해질수록 이러한 역할 역시 더 커질 가능성이 높다.
8.11 대형 모델 적응 전략 전체 속에서 LoRA를 배치하기
대형 모델 적응 전략을 넓게 보면, 선택지는 크게 네 가지 축으로 나뉜다. 첫째는 프롬프트 수준의 제어다. 이는 가장 가볍지만 모델 내부를 직접 바꾸지 않는다. 둘째는 LoRA나 어댑터 같은 모듈식 적응이다. 이는 본체를 유지하면서도 과업 친화적 변형을 도입한다. 셋째는 완전 미세조정이다. 가장 강력하지만 비용이 가장 크다. 넷째는 재사전학습이나 지속 사전학습처럼 말뭉치 자체를 다시 학습하는 접근이다. 이는 가장 근본적이지만 가장 무겁다. LoRA의 진가는 이 네 축 사이에서 매우 실용적인 균형점을 제공한다는 데 있다. 프롬프트보다 강하고, 완전 미세조정보다 싸며, 재사전학습보다 훨씬 간단하고, 어댑터보다 병합이 쉽다. 따라서 실제 프로젝트에서는 LoRA가 “기본 적응 단계”로 배치되고, 그 다음에 더 강한 방법이 필요한지 판단하는 식의 전략이 합리적이다.
이 전략적 위치를 이해하면 LoRA의 성공이 왜 단순한 벤치마크 승리를 넘어서는지 알 수 있다. 대부분의 실제 프로젝트는 처음부터 가장 비싼 방법을 선택하지 않는다. 먼저 비용이 낮은 단계에서 어느 정도의 성능을 얻을 수 있는지 확인하고, 부족할 때만 더 무거운 방법으로 이동한다. LoRA는 이런 단계적 의사결정 구조에 정확히 맞아떨어진다. 결과가 충분하면 그대로 배포하면 되고, 부족하면 랭크를 높이거나 적용 모듈을 늘리거나 더 강한 적응 방식으로 넘어가면 된다. 중요한 점은 첫 번째 시도 자체가 매우 싸고 빠르다는 사실이다. 이러한 점진적 탐색 가능성은 대형 모델 시대의 연구와 제품 개발에서 매우 큰 가치를 갖는다.
또한 LoRA는 조직 차원의 실험 전략과도 잘 맞는다. 하나의 공통 베이스 모델을 유지한 채 여러 팀이 서로 다른 적응 모듈을 독립적으로 개발할 수 있기 때문이다. 어떤 팀은 요약, 어떤 팀은 질의응답, 어떤 팀은 안전성 조정, 어떤 팀은 검색 증강 환경에 맞는 LoRA를 만들 수 있고, 모두가 동일한 기본 모델을 공유한다. 이 구조는 모델 관리와 인프라 관점에서 큰 장점이 있다. 동시에 각 팀의 성과를 동일한 베이스 위에서 비교하기 쉬우므로, 어떤 적응이 실제로 더 가치 있는지 정량적으로 판단하기도 쉽다. 다시 말해 LoRA는 연구 아이디어를 넘어 조직적 개발 프로세스와도 잘 결합되는 적응 방식이다.
결국 LoRA를 이해하는 가장 좋은 방식은 “완전 미세조정의 저렴한 대체재”라는 한 문장에 가두지 않는 것이다. 더 정확한 표현은, LoRA가 대형 모델 적응을 단계화하고 모듈화하며 비교 가능하게 만든 기본 설계라는 것이다. 이 관점에서 보면 LoRA의 가장 큰 기여는 점수 몇 개가 아니라, 적응 실험을 더 자주 하고 더 체계적으로 할 수 있게 만든 데 있다. 사전학습 모델이 거대해질수록 적응은 한 번의 거대한 도박이 아니라, 작고 반복 가능한 실험들의 연속이어야 한다. LoRA는 바로 그 실험 문화를 가능하게 만든 핵심 인터페이스로 자리 잡았다.
8.12 LoRA가 바꾼 평가 기준과 보고 방식
LoRA 이후 효율적 적응 연구에서 가장 크게 달라진 것 중 하나는 무엇을 보고해야 하는가의 기준이다. 이전에는 과업 성능이 거의 전부였지만, 이제는 학습 가능한 파라미터 수, 전체 저장 용량, 옵티마이저 상태까지 포함한 메모리 사용량, 처리량, 추론 지연, 병합 가능성, 체크포인트 교체 비용까지 함께 제시하는 것이 자연스러워졌다. LoRA 논문은 이 변화를 선명하게 보여 준 초기 사례다. 단순히 정확도가 조금 높다는 것만으로는 더 이상 충분하지 않고, 그 성능을 어떤 비용 구조로 달성했는지가 핵심 질문이 되었다. 대형 모델 시대에는 비용이 곧 실현 가능성을 결정하기 때문에, LoRA는 결과 표의 열 자체를 바꾼 논문이라고도 할 수 있다.
이 변화는 연구 보고 방식뿐 아니라 실험 설계 방식에도 영향을 미쳤다. 예전에는 “성능이 가장 높은가”가 우선이었다면, LoRA 이후에는 “적은 적응 예산으로 어디까지 갈 수 있는가”가 중요한 질문이 되었다. 그래서 같은 모델이라도 어떤 모듈에 LoRA를 넣을지, 랭크를 얼마나 줄일지, 병합 후 지연은 어떤지, 동일한 베이스 위에 몇 개의 과업 모듈을 얹을 수 있는지 같은 질문이 함께 따라붙는다. 이는 단순한 부가 정보가 아니라, 대형 모델을 실제로 운영하는 입장에서는 핵심 정보다. LoRA가 강한 이유는 바로 이 실무적 질문을 연구 논문의 중앙으로 끌어왔다는 데 있다.
또한 LoRA는 기준선의 의미도 바꾸었다. 이제 새로운 적응 방법은 완전 미세조정과만 비교해서는 충분하지 않고, LoRA보다 얼마나 더 좋거나 얼마나 더 싸거나 얼마나 더 단순한지도 보여 주어야 한다. 다시 말해 LoRA는 하나의 방법인 동시에 새로운 표준 기준선이 되었다. 이 표준화 효과는 매우 크다. 커뮤니티가 공통으로 받아들이는 강한 기준선이 있을 때, 후속 연구는 진정으로 의미 있는 개선이 무엇인지 더 명확하게 입증해야 하기 때문이다. 그런 의미에서 LoRA의 영향은 개별 실험 결과보다 더 넓다. 오늘날 PEFT 논문 대부분이 사실상 LoRA를 중심 좌표로 삼는다는 사실 자체가 이 논문의 역사적 위치를 말해 준다.
9. 요약 정리 — LoRA 논문의 핵심 기여, 실험 결론, 구현 함의를 한 번에 정리
LoRA는 거대 언어모델 적응을 “모델 전체를 다시 학습하는 문제”에서 “필요한 변화만 작은 저랭크 공간에서 학습하는 문제”로 전환했다. 수식은 간단하지만 함의는 크다. $W_0$를 고정하고 $\Delta W$를 $BA$로 재매개변수화하면, 학습 대상 파라미터는 급격히 줄고 추론 전 병합도 가능해진다. 그 결과 완전 미세조정의 품질을 유지하면서도 저장비용, 학습 메모리, 처리량, 배포 편의성의 균형을 동시에 개선할 수 있다.
실험적으로도 LoRA는 encoder-only와 decoder-only, 그리고 초거대 모델까지 일관된 결과를 보였다. GLUE에서 RoBERTa와 DeBERTa 계열은 완전 미세조정과 동급 또는 우세했고, GPT-2 E2E에서는 극소수 학습 파라미터로 강한 생성 성능을 냈다. GPT-3 175B에서는 175,255.8M 전체를 학습하는 대신 4.7M 또는 37.7M 수준의 적응 파라미터만으로 비슷한 품질을 확보하며, 10,000배 파라미터 절감과 약 3배 메모리 절감, 25% 처리량 향상이라는 메시지를 뒷받침했다.
구현 측면에서 LoRA의 강점은 단순성에도 있다. $A$ 랜덤 초기화와 $B$ 0 초기화, $\alpha/r$ 스케일링, query/value 중심 적용, AdamW 기반 학습, merge / unmerge 워크플로 같은 요소들이 비교적 단순한 인터페이스로 정리되어 있다. 이 단순성이 있었기에 LoRA는 논문 한 편에 머무르지 않고, 이후 수많은 라이브러리와 서비스 인프라에서 사실상의 기본 파인튜닝 방식으로 채택될 수 있었다.
분석 측면에서 가장 중요한 메시지는 적응의 내재 차원이 낮을 수 있다는 점이다. 랭크 1, 8, 64 비교에서 큰 차이가 나지 않는 결과는, 다운스트림 적응이 고차원 전체를 재구성하는 작업이 아니라 사전학습 표현의 일부 방향을 정교하게 조절하는 작업일 가능성을 보여 준다. 이 관찰은 이후 QLoRA, AdaLoRA, DoRA, 멀티모달 LoRA 등 수많은 후속 연구를 낳았고, 오늘날 PEFT 연구의 공통 언어를 형성했다.
논문을 한 문장으로 압축하면, LoRA는 대형 모델 적응의 비용 함수와 설계 원칙을 동시에 바꾼 방법이라고 할 수 있다. 적응은 더 이상 전체 모델을 재학습해야만 하는 과정이 아니라, 동결된 본체 위에 작은 저랭크 보정만 얹어도 충분히 강한 결과를 만들 수 있는 과정으로 다시 정의된다. 이 재정의는 단순한 계산 절약을 넘어서 연구 문화와 배포 문화 자체를 바꿨다. 어떤 과업을 새로 시도할 때 먼저 LoRA로 기준선을 잡고, 필요할 때만 더 무거운 방법으로 이동하는 절차가 자연스러워졌기 때문이다. 이는 대형 모델 실험을 더 자주, 더 싸게, 더 체계적으로 수행하게 만들었고, 결국 후속 혁신의 속도를 높였다.
또한 LoRA는 사전학습 모델의 힘을 어디에서 끌어오는지에 대한 관점도 바꾸었다. 과거에는 다운스트림 성능 향상을 위해 모델 전체를 다시 풀어 두는 것이 당연하게 여겨졌지만, LoRA는 많은 과업에서 필요한 변화가 그보다 훨씬 작을 수 있음을 보여 주었다. 이는 사전학습 모델이 이미 매우 넓은 잠재 기저를 형성하고 있고, 과업 적응은 그 기저를 어떤 방향으로 읽어 낼지를 조정하는 일에 가까울 수 있다는 뜻이다. 따라서 LoRA의 성공은 효율성의 승리인 동시에, 사전학습 표현의 재사용 가능성에 대한 강한 경험적 증거이기도 하다. 바로 이 지점이 LoRA를 단순한 공학적 트릭이 아니라 오래 남는 연구 결과로 만든다.
이러한 이유로 LoRA는 오늘날에도 새로운 적응 방법을 평가할 때 빠지지 않는 비교 기준이다. 어떤 방법이 성능을 조금 더 높였더라도 파라미터 수가 급증하거나 병합이 어렵다면, LoRA보다 명백히 낫다고 말하기 어렵다. 반대로 LoRA보다 단순하면서도 더 강한 결과를 내는 방법이 등장한다면, 그것은 LoRA를 기준으로 얼마나 개선되었는지로 설명된다. 즉 LoRA는 한 편의 논문이면서 동시에 하나의 좌표계가 되었다. 대형 모델 적응을 논할 때 연구자와 개발자가 공통으로 참조하는 기본 언어를 제공했다는 점에서, 이 논문의 역사적 기여는 지금도 진행형이라고 볼 수 있다.
동시에 LoRA는 연구자에게 매우 실용적인 교훈도 남긴다. 거대한 모델을 다룰수록 중요한 것은 가장 복잡한 방법을 먼저 선택하는 일이 아니라, 어떤 종류의 변화가 실제로 필요한지 가장 싼 비용으로 진단하는 일이다. LoRA는 이 진단 단계에 특히 적합하다. 낮은 랭크와 제한된 적용 위치로 시작해도 충분한 성능이 나온다면, 그 과업은 사전학습 표현의 재정렬만으로 해결 가능한 경우일 가능성이 높다. 반대로 LoRA가 반복적으로 부족하다면, 그때 비로소 더 높은 랭크나 더 넓은 모듈 적응, 심지어 완전 미세조정을 고려하면 된다. 이런 점에서 LoRA는 단지 적응 방법이 아니라, 과업의 적응 난도를 판별하는 탐침 역할까지 수행한다. 이 해석은 LoRA를 단순한 결과물보다 더 오래 쓰이게 만든 중요한 이유다.
또 하나 주목할 점은 LoRA가 대형 모델 시대의 협업 구조와도 잘 맞는다는 사실이다. 작은 적응 모듈은 공유와 비교, 재현이 쉽고, 베이스 모델이 동일하다면 여러 실험 결과를 공통 좌표계에서 해석할 수 있다. 이는 연구실 내부 협업뿐 아니라 오픈소스 커뮤니티에서도 큰 장점이 된다. 서로 다른 사람이 학습한 LoRA를 교환하고 비교하면서도, 기본 모델을 공유하면 실험 결과를 상대적으로 명확하게 해석할 수 있기 때문이다. 이러한 모듈성은 단순히 편리한 기능이 아니라, 대형 모델 연구를 더 개방적이고 반복 가능한 활동으로 바꾼다. LoRA가 남긴 영향은 결국 성능 수치의 차이를 넘어, 연구와 배포의 작업 흐름 자체를 재구성한 데 있다고 정리할 수 있다.
종합하면 LoRA의 장기적 가치는 세 층위에서 동시에 이해할 수 있다. 첫째는 직접적인 성능과 비용의 층위다. 적은 학습 파라미터, 낮은 메모리 사용량, 빠른 처리량, 병합 가능한 배포라는 장점이 명확하다. 둘째는 연구 방법론의 층위다. LoRA는 적응을 전체 가중치의 재학습이 아니라 부분공간의 선택 문제로 보게 만들었고, 덕분에 랭크, 적용 위치, 부분공간 유사성, 적응 예산 같은 새로운 분석 질문이 등장했다. 셋째는 생태계와 협업의 층위다. 작은 체크포인트, 모듈식 저장, 공통 베이스 모델 공유, 반복 가능한 실험 문화는 오픈소스와 산업 현장 모두에서 매우 큰 파급력을 만들었다. 이 세 층위가 동시에 작동했기 때문에 LoRA는 단기간의 유행으로 끝나지 않았고, 후속 방법들이 계속 비교해야 하는 기본 표준으로 남았다. 결국 이 논문의 중요성은 “작게 학습해도 된다”는 결론 하나에 있지 않고, 대형 모델 적응을 어떤 비용 구조와 어떤 질문 체계 안에서 바라봐야 하는지를 새롭게 정의한 데 있다.
이 점을 가장 잘 보여 주는 것은 LoRA가 오늘날에도 여전히 출발점이라는 사실이다. 새로운 모델이 공개되면 많은 연구자와 개발자가 가장 먼저 묻는 질문은 전체를 다시 학습할지 여부가 아니라, 어느 모듈에 어떤 랭크의 LoRA를 넣을지다. 이 질문 자체가 이미 LoRA 이후의 시대를 반영한다. 적응은 전면 재구성보다 선택적 보정으로 시작하는 것이 자연스럽고, 그 선택적 보정이 충분한지 먼저 확인한 뒤 더 강한 방법으로 넘어가는 흐름이 표준이 되었다. 논문 한 편이 수식, 실험, 라이브러리, 배포 전략, 그리고 연구자들의 기본 질문까지 바꾸는 경우는 드물다. LoRA는 바로 그런 드문 사례이며, 그래서 지금도 대형 모델 적응을 설명할 때 가장 먼저 호출되는 이름으로 남아 있다.
결국 LoRA를 읽는다는 것은 단순히 한 가지 효율화 기법을 배우는 일이 아니라, 대형 모델 시대의 적응 철학이 어떻게 형성되었는지를 이해하는 일에 가깝다. 거대한 본체를 당연히 다시 학습해야 한다는 사고에서 벗어나, 필요한 변화만 선택적으로 학습하고 그 비용까지 함께 평가하는 사고로 전환하는 것, 바로 그것이 LoRA 논문이 남긴 가장 큰 유산이다. 그래서 이 논문은 지금도 결과 표의 숫자 이상으로 자주 소환되며, 새로운 적응 방법이 등장할 때마다 기준선이자 비교 축으로 기능한다.
따라서 LoRA의 의미를 정확히 이해하려면 파라미터 절감 수치만 볼 것이 아니라, 그 수치가 열어 준 연구 습관과 배포 습관의 변화를 함께 보아야 한다. 작은 보정으로 시작하고, 필요하면 단계적으로 확장하며, 비용과 성능을 함께 보고하고, 적응 결과를 모듈 단위로 저장하고 교환하는 문화가 바로 LoRA 이후의 표준이 되었다. 이 변화 자체가 LoRA 논문의 가장 지속적인 영향이다.
바로 이 이유 때문에 LoRA는 지금도 새로운 대형 모델이 등장할 때 가장 먼저 시험되는 적응 형식이며, 많은 후속 방법이 자신을 설명할 때 LoRA와의 관계부터 제시한다. 효율과 성능, 분석 가능성과 배포 용이성을 하나의 구조로 묶어 냈다는 점이 이 논문의 지속성을 만든다.
즉 LoRA는 하나의 방법이면서 동시에 하나의 기준 언어다. 대형 모델 적응을 말할 때 성능, 비용, 병합 가능성, 모듈성, 재현성을 함께 묻는 습관은 상당 부분 이 논문을 통해 굳어졌다.
그 점에서 LoRA는 효율화 기법을 넘어 대형 모델 적응의 표준 문법을 만든 논문으로 기억될 만하다.
적응을 작고 설명 가능한 보정의 문제로 바꿨다는 점이 이 논문의 지속적인 영향력을 가장 압축적으로 보여 준다.
그 결과 LoRA는 지금도 대형 모델 적응을 시작할 때 가장 먼저 놓이는 기본 좌표로 기능한다.
이 표준성 자체가 LoRA의 영향력이 일시적 성과가 아니라 구조적 전환이었음을 보여 준다.
그래서 LoRA는 지금도 대형 모델 적응 논의의 공통 출발점으로 남아 있다.
이 지속성은 LoRA의 역사적 무게를 잘 보여 준다.
지금도 많은 적응 실험이 LoRA에서 시작된다는 사실이 그 증거다.
이 점은 LoRA가 연구사에서 이미 하나의 기준점으로 자리 잡았음을 다시 확인시킨다.
이러한 누적 효과가 LoRA를 단순 유행이 아닌 장기 표준으로 굳혔다.
9.1 자체 검증 기준을 반영한 최종 체크리스트
- 상단 헤더는 요구 패턴에 맞춰 H1에 [arXiv 2106.09685]를 포함하고, 이어서 영문 제목 H2, abs 링크 문단, 저자·기관·연도 메타 문단, 구분선 <hr> 순으로 재구성했다.
- 본문은 개인 감상이나 메타 서술을 제거하고, 논문 귀속형 설명과 수치·수식 중심의 서술로 전면 정리했다.
- H2와 H3의 번호 체계는 유지했고, 모든 H2는 서술적 부제를 포함하도록 수정했다.
- 이미지는 x1~x8만 사용했으며, 각 그림에 figcaption을 추가하고 그림 직후에는 200~350자 분량의 해설 문단을 배치했다.
- 표는 GLUE, E2E, GPT-3, 랭크 비교, 적용 위치 비교, 데이터셋 요약, 어댑터 지연 비교 등으로 확장해 5개 이상 조건을 안정적으로 넘겼다.
- 내용 확장 포인트로 conditional LM objective, LoRA 재매개변수화, $\alpha/r$, 초기화, merge / unmerge, 배칭 한계, adapter / prefix 비교, GLUE/E2E/GPT-3/WikiSQL/SAMSum 해석, 후속 연구 연결을 모두 보강했다.
- 자체 정규식 검증 기준으로 최종 파일은 plain text 49,052자, 한국어 글자 29,985자, p 157개, strong 171개, figure 8개, table 9개, figcaption 8개를 확인했다.
- 발행 관련 스크립트나 큐 파일은 건드리지 않았고, /mnt/d/MyProject/Tistory_paper/html/lora_review.html만 수정했다.