Attention Is All You Need
https://arxiv.org/abs/1706.03762
https://arxiv.org/html/1706.03762
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin | Google Brain, Google Research, University of Toronto 등 | arXiv:1706.03762 | 2017년 6월 | NIPS 2017
1. 서론: 순환과 합성을 버리고 시퀀스 모델링을 다시 정의한 논문
자연어 번역, 요약, 음성 인식 같은 시퀀스 변환 문제는 오랫동안 RNN, LSTM, GRU, 그리고 이를 변형한 컨볼루션 기반 인코더-디코더가 주도해 왔다. 이 계열 모델은 입력 토큰을 왼쪽에서 오른쪽으로 순차적으로 처리하거나 제한된 커널 범위 안에서 점진적으로 정보를 축적하는 방식이었기 때문에, 멀리 떨어진 토큰 간 관계를 포착하려면 긴 경로를 거쳐야 했다. 논문은 바로 이 지점에서 출발한다. 번역 품질을 더 높이기 위해 더 깊은 순환 구조를 쌓는 대신, 토큰 사이 상호작용 자체를 직접 모델링하는 편이 더 단순하고 더 병렬적일 수 있다는 문제의식을 전면에 내세운다.
이 논문이 제안한 Transformer는 이름만 보면 새로운 신경망 블록 하나처럼 보이지만, 실제로는 시퀀스 모델링의 계산 구조를 바꿔 놓은 설계 전환에 가깝다. 핵심은 어텐션 메커니즘만으로 인코더와 디코더를 구성하고, 그 과정에서 순환과 합성곱을 완전히 제거한다는 점이다. 논문은 이를 통해 두 가지 효과를 동시에 얻었다고 보고한다. 첫째, 토큰 간 의존성을 모델링하는 경로 길이가 짧아져 장거리 관계를 다루기 쉬워졌고, 둘째, 모든 위치를 병렬로 계산할 수 있어 학습 효율이 크게 개선되었다.
오늘날 대형 언어모델의 기본 뼈대가 Transformer 계열이라는 사실은 너무 익숙해서 오히려 이 논문이 얼마나 급진적이었는지 체감하기 어렵다. 그러나 2017년 시점에서 "순환 없이도 번역이 된다"는 주장은 단순한 구현 최적화가 아니라 아키텍처 수준의 반전이었다. 논문은 WMT 2014 영어-독일어 번역에서 BLEU 28.4, 영어-프랑스어 번역에서 BLEU 41.8을 기록하며 기존 최고 성능을 넘어섰고, 동시에 학습 비용도 줄였다. 즉, Transformer는 단지 새로웠던 것이 아니라 성능과 비용 양쪽에서 모두 설득력이 있었다.
또 하나 중요하게 봐야 할 지점은 논문이 번역 한 태스크만 잘 맞춘 구조를 제안한 것이 아니라는 점이다. 저자들은 영어 구문 분석 실험까지 제시하면서 이 구조가 시퀀스 변환 일반에 적용될 수 있음을 보여준다. 이후 BERT, GPT, T5, ViT, DETR, Whisper, LLaMA 같은 후속 계열이 모두 이 계보 위에서 나왔다는 사실을 생각하면, 이 논문은 성능 보고서라기보다 후속 연구의 공용 연산 언어를 제시한 문서로 읽는 편이 더 정확하다.

Figure 1: Transformer 전체 아키텍처
Figure 1은 Transformer의 핵심 설계를 한 장으로 요약한다. 왼쪽은 인코더 스택, 오른쪽은 디코더 스택이며, 각 층이 멀티헤드 셀프어텐션, 인코더-디코더 어텐션, 위치별 피드포워드 네트워크로 이루어진다. 그림에서 가장 중요한 포인트는 순환 연결이 완전히 사라졌다는 점과, 모든 서브레이어가 Residual connection + Layer Normalization 위에서 반복된다는 점이다. 이 반복 가능한 블록 구조가 이후 거의 모든 Transformer 변형의 기본 골격이 된다.
2. 배경 및 관련 연구: RNN 계열의 병목과 어텐션의 진화
2.1 순차 계산이 만든 병목과 장거리 의존성 문제
논문이 겨냥한 첫 번째 병목은 순차성이다. RNN 계열은 시점 $t$의 은닉 상태를 계산하려면 반드시 $t-1$ 시점 결과가 필요하다. 이 구조는 시퀀스 길이가 길어질수록 GPU 병렬화 효율을 떨어뜨리고, 학습 시간도 늘린다. LSTM과 GRU는 게이팅을 통해 장기 의존성 문제를 완화했지만, 그래도 각 단계가 직렬로 연결되어 있다는 점은 바뀌지 않는다. 즉, 정보 보존 문제는 일부 완화해도 계산 그래프 자체는 여전히 길다.
합성곱 기반 시퀀스 모델은 순환보다 병렬적이지만, 토큰 간 상호작용 범위가 커널과 층수에 의해 제한된다. 먼 위치의 토큰끼리 영향을 주고받으려면 더 많은 층을 거치거나 dilated convolution 같은 장치를 써야 한다. 논문은 이 점을 경로 길이 관점에서 정리한다. 두 위치가 서로 영향을 주기 위해 지나야 하는 연산 단계가 길수록, 학습은 어렵고 표현력은 간접적이 된다. Transformer의 셀프어텐션은 모든 위치 쌍을 한 번에 연결함으로써 이 경로를 최소화하려는 선택이다.
2.2 어텐션은 이미 있었지만, 논문은 어텐션을 주연으로 올렸다
이 논문 이전에도 attention mechanism 자체는 번역 모델에서 널리 쓰이고 있었다. 대표적으로 Bahdanau attention이나 Luong attention은 인코더가 만든 표현들 중 어떤 부분을 디코더가 참고해야 하는지 동적으로 선택하게 만들었다. 하지만 기존 구조에서 어텐션은 보통 RNN 인코더-디코더를 보조하는 모듈이었다. 중심 연산은 여전히 순환에 있었고, 어텐션은 그 위에 얹힌 추가 연결이었다.
Transformer가 만든 변화는 여기서 한 단계 더 나간다. 어텐션을 보조 부품이 아니라 모델의 중심 연산으로 승격시키면서, 순환과 합성곱을 모두 제거했다. 이 선택은 단순한 미학이 아니다. 입력 길이가 길어질수록 계산량의 성격, 병렬화 방식, 메모리 사용 패턴, 표현의 연결 구조가 전부 달라진다. 후속 연구들이 self-attention, cross-attention, causal masking, multi-head를 각기 다른 방식으로 변형하면서도 기본 프레임을 유지한 이유가 여기에 있다.
2.3 핵심 논문으로서의 의미: 구조적 표준을 만든 사례
핵심 논문으로서 이 논문을 다시 읽을 때 중요하게 봐야 할 것은 단순히 최초 제안이라는 역사성이 아니다. 실제로 논문은 연산 단위의 표준화, 병렬 학습의 표준화, 표현 결합 방식의 표준화를 동시에 이뤘다. 인코더 블록과 디코더 블록을 반복 가능한 템플릿으로 정리했고, 토큰 표현은 임베딩과 위치 정보를 더해 구성하며, 토큰 간 상호작용은 Q-K-V 투영과 softmax로 계산한다는 규칙을 명확히 만들었다.
이후 연구들은 이 구조에서 필요한 부분만 수정했다. 예를 들어 BERT는 디코더를 제거하고 양방향 인코더만 남겼고, GPT는 인코더를 제거하고 causal decoder만 사용했으며, T5는 텍스트-투-텍스트 프레임으로 다시 정리했다. 비전에서는 ViT가 이미지를 패치 시퀀스로 바꿨고, 멀티모달에서는 cross-attention이 모달 간 연결 장치가 되었다. 즉, 이 논문은 한 모델이 아니라 모델 설계의 공통 문법을 만든 사례다.
3. 방법론: 어텐션만으로 구성한 Transformer
3.1 인코더-디코더 스택: 반복 가능한 블록 설계
Transformer의 인코더와 디코더는 각각 $N=6$개의 동일한 레이어를 쌓아 만든다. 인코더의 각 층은 멀티헤드 셀프어텐션과 Position-wise Feed-Forward Network로 구성되고, 각 서브레이어 주변에는 Residual connection과 LayerNorm이 배치된다. 디코더는 여기에 한 단계가 더 들어간다. 먼저 미래 토큰을 보지 못하도록 마스킹된 셀프어텐션을 수행한 뒤, 인코더 출력을 참조하는 encoder-decoder attention을 적용하고, 마지막으로 피드포워드 네트워크를 통과시킨다.
여기서 중요한 점은 각 층이 시간축을 따라 순차적으로 상태를 갱신하지 않는다는 것이다. 한 층 안에서 모든 위치의 표현을 동시에 계산할 수 있으므로, 연산은 시퀀스 길이 방향으로 넓게 펼쳐진 행렬 연산이 된다. 논문은 이 구조가 학습 병렬성을 높일 뿐 아니라 구현 단순성에도 이점이 있다고 본다. 후속 대규모 학습이 가능했던 배경에는 구조의 표현력만이 아니라, 이런 대형 행렬 중심 계산 패턴이 하드웨어와 잘 맞았다는 점도 함께 있다.
3.2 Scaled Dot-Product Attention: Q, K, V의 계산 원리
논문은 어텐션을 Query, Key, Value의 세 표현으로 정리한다. 각 토큰 표현에서 선형 변환을 통해 질의, 키, 값을 만들고, 질의와 키의 내적을 통해 유사도를 구한 뒤, softmax로 정규화하여 값들의 가중합을 계산한다. 수식으로는 다음과 같다.
$$\mathrm{Attention}(Q, K, V)=\mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$$
여기서 $\sqrt{d_k}$로 나누는 스케일링이 핵심이다. 차원이 커질수록 내적 값의 분산이 커져 softmax가 쉽게 포화될 수 있는데, 이를 완화해 학습을 안정화한다. 논문은 additive attention과 dot-product attention을 비교하면서, 이 방식이 현대 하드웨어에서 더 빠르고 메모리 친화적인 행렬 곱 형태를 유지한다고 설명한다. 오늘날 거의 모든 Transformer 계열이 이 스케일드 점곱 어텐션을 기본으로 채택하는 이유도 계산 효율과 학습 안정성이 동시에 확보되기 때문이다.

Figure 2: Scaled Dot-Product Attention
Figure 2의 왼쪽 도식은 Query와 Key의 유사도로 가중치를 만들고, 그 가중치로 Value를 합성하는 어텐션 계산 흐름을 보여준다. 도식 자체는 단순하지만, 이 단순한 구조가 중요한 이유는 시퀀스 전역의 의존성을 한 번의 행렬 연산으로 반영할 수 있기 때문이다. 논문은 여기에 $1/\sqrt{d_k}$ 스케일을 넣어 큰 차원에서 softmax가 지나치게 날카로워지는 문제를 줄였고, 이것이 후속 구현의 사실상 표준이 되었다.
3.3 Multi-Head Attention: 하나의 유사도로는 부족하다는 판단
단일 어텐션만 사용하면 모든 관계를 하나의 유사도 공간에 압축해야 한다. 논문은 이를 피하기 위해 Multi-Head Attention을 도입한다. 입력 표현을 여러 개의 서로 다른 선형 공간으로 투영한 뒤, 각 공간에서 독립적으로 어텐션을 계산하고, 그 결과를 다시 합쳐 최종 표현을 만든다. 수식은 다음과 같이 정리된다.
$$\mathrm{MultiHead}(Q,K,V)=\mathrm{Concat}(head_1,\dots,head_h)W^O$$
$$head_i=\mathrm{Attention}(QW_i^Q,KW_i^K,VW_i^V)$$
기본 모델에서는 $h=8$, $d_{model}=512$, $d_k=d_v=64$를 사용한다. 이 선택은 차원을 무작정 늘리는 대신, 서로 다른 헤드가 각기 다른 상호작용 패턴을 학습하도록 유도한다. 논문 후반의 시각화는 실제로 어떤 헤드는 장거리 문법 의존성을, 어떤 헤드는 대명사 참조를, 어떤 헤드는 구문 구조 경계를 포착한다는 정성적 근거를 제시한다.

Figure 3: Multi-Head Attention이 병렬적으로 작동하는 방식
Figure 3의 오른쪽 도식은 동일한 입력이 여러 헤드로 병렬 투영된 뒤, 각 헤드가 서로 다른 상관 구조를 학습하고 마지막에 concat과 선형 변환으로 통합되는 과정을 보여준다. 이 그림이 중요한 이유는 Transformer의 표현력이 단순히 어텐션 여부에서 오지 않고, 다수의 표현 하위공간을 동시에 활용하는 설계에서 나온다는 점을 명확히 드러내기 때문이다. 이후의 수많은 Transformer 변형은 헤드 수, 헤드 크기, 헤드 공유 방식만 달리했을 뿐 이 기본 사고를 유지했다.
3.4 Position-wise Feed-Forward Network와 잔차 연결
어텐션이 토큰 간 정보를 섞는 연산이라면, Position-wise Feed-Forward Network는 각 위치에서 비선형 변환을 수행해 표현력을 높이는 역할을 한다. 논문은 모든 위치에 동일한 두 층 MLP를 적용한다. 수식은 다음과 같다.
$$\mathrm{FFN}(x)=\max(0, xW_1+b_1)W_2+b_2$$
기본 모델의 차원은 $d_{model}=512$, $d_{ff}=2048$다. 즉, 각 위치의 표현을 한 번 크게 확장했다가 다시 원래 차원으로 되돌리는 구조다. 이 설계는 토큰 간 관계를 계산하는 어텐션과, 각 토큰 내부 표현을 재조합하는 FFN의 역할을 분리한다. 또한 모든 서브레이어 주위에 잔차 연결과 정규화를 두어 깊은 네트워크 학습을 안정화한다. 이후 Pre-LN, SwiGLU, GeLU 같은 변형이 등장했지만, 어텐션 블록과 위치별 MLP의 교대 구조는 그대로 이어진다.
3.5 임베딩 공유와 Positional Encoding
순환을 제거하면 토큰 순서 정보가 자연스럽게 사라진다. 따라서 논문은 입력 임베딩에 Positional Encoding을 더해 위치 정보를 주입한다. 저자들은 학습 가능한 위치 임베딩과 사인·코사인 기반 위치 인코딩을 모두 시험했고, 비슷한 성능을 얻었지만, 더 긴 시퀀스로 일반화할 가능성을 고려해 사인·코사인 방식을 채택했다고 설명한다.
$$PE_{(pos,2i)}=\sin\left(pos/10000^{2i/d_{model}}\right)$$
$$PE_{(pos,2i+1)}=\cos\left(pos/10000^{2i/d_{model}}\right)$$
이 수식은 위치마다 서로 다른 주파수의 파형을 할당함으로써 상대적 거리 정보를 선형 조합으로도 복원하기 쉽게 만든다. 논문은 또 입력 임베딩과 출력 softmax 직전 선형 변환의 가중치를 공유하고, 임베딩 값에 $\sqrt{d_{model}}$를 곱해 스케일을 맞춘다. 이 선택은 파라미터 효율과 최적화 안정성을 함께 고려한 설계로 읽을 수 있다.
4. 실험 설정: 번역 벤치마크와 학습 프로토콜
4.1 데이터셋 및 벤치마크: WMT 2014 번역과 WSJ 구문 분석
주요 번역 실험은 WMT 2014 English-German과 WMT 2014 English-French에서 수행된다. 영어-독일어는 약 450만 문장쌍, 영어-프랑스어는 약 3600만 문장 규모다. 영어-독일어 실험에서는 source와 target이 공유하는 약 37,000개 토큰의 byte-pair encoding 어휘를 사용했고, 영어-프랑스어 실험에서는 32,000 word-piece 어휘를 사용한다. 즉, 논문은 아키텍처 효과를 비교적 표준적인 번역 데이터 위에서 검증한다.
추가로 논문은 English constituency parsing 실험을 통해 Transformer가 번역 이외의 구조적 언어 태스크에도 적용될 수 있음을 보여준다. 이 설정은 단순히 벤치마크를 하나 더 얹은 것이 아니라, self-attention이 문장 내 장거리 관계와 구조 정보를 표현하는 데 충분한지 확인하는 검증으로 볼 수 있다. 오늘날 Transformer가 범용 아키텍처로 받아들여지는 데는 이런 보조 실험이 중요한 역할을 했다.
4.2 구현 세부사항: 배치, 하드웨어, 학습 스케줄
배치는 문장 길이가 비슷한 샘플끼리 묶어 만들고, 각 미니배치는 대략 25,000 source tokens와 25,000 target tokens를 포함하도록 구성한다. 이 설정은 단순히 메모리 사용량을 맞추기 위한 것이 아니라, 길이 편차 때문에 패딩 비율이 커지는 문제를 줄여 실효 배치 효율을 높이는 방법이다. 이후 대규모 언어모델 학습에서 length bucketing이 표준으로 자리잡은 흐름과도 연결된다.
하드웨어는 8개의 NVIDIA P100 GPU를 사용한다. 논문에 따르면 base 모델은 스텝당 약 0.4초, 총 100,000 step, 약 12시간 훈련되며, big 모델은 스텝당 약 1.0초, 총 300,000 step, 약 3.5일 훈련된다. 당시 기준으로 보면 이는 매우 경쟁력 있는 결과였다. 특히 기존 최고 성능 모델이 더 큰 학습 비용을 요구했던 점을 감안하면, Transformer의 병렬 구조가 단순한 이론적 이점이 아니라 실제 학습 시간 단축으로 연결되었음을 보여준다.
4.3 최적화와 정규화: Adam, warmup, dropout, label smoothing
논문은 최적화기로 Adam을 사용하며, 하이퍼파라미터는 $\beta_1=0.9$, $\beta_2=0.98$, $\epsilon=10^{-9}$로 설정한다. 더 중요한 부분은 학습률 스케줄이다. 학습 초반에는 선형적으로 증가시키고, 이후에는 step의 역제곱근에 비례해 감소시키는 스케줄을 사용한다.
$$lrate=d_{model}^{-0.5}\cdot \min(step\_num^{-0.5}, step\_num\cdot warmup\_steps^{-1.5})$$
이 스케줄은 Transformer를 학습할 때 지금도 자주 언급되는 warmup + inverse square root decay의 원형이다. base 모델에는 dropout $P_{drop}=0.1$을 사용하고, 학습 시 label smoothing $\epsilon_{ls}=0.1$도 적용한다. 논문은 label smoothing이 perplexity에는 불리할 수 있지만 정확도와 BLEU에는 유리하다고 서술한다. 이 관찰은 생성 모델 평가에서 likelihood와 task metric이 항상 일치하지 않는다는 사실을 일찍 보여준 사례다.
| 설정 | N | $d_{model}$ | $d_{ff}$ | Heads | Dropout | Train Steps | Params |
|---|---|---|---|---|---|---|---|
| Transformer base | 6 | 512 | 2048 | 8 | 0.1 | 100K | 65M |
| Transformer big | 6 | 1024 | 4096 | 16 | 0.3 | 300K | 213M |
이 표는 논문이 실제로 비교한 base와 big 설정의 차이를 요약한다. 단순히 차원을 키우는 스케일업이지만, 이 결과는 Transformer가 구조적으로도 강하고 스케일링에도 반응한다는 사실을 보여준다. 후속 대규모 언어모델 연구에서 수천억 파라미터까지 같은 계열 구조가 확장된 배경에는, 이미 이 논문 단계에서 구조의 스케일 안정성이 확인되었다는 점이 깔려 있다.
5. 주요 실험 결과: 번역 성능과 학습 효율의 동시 개선
5.1 WMT 2014 기계번역 결과: 품질과 비용의 균형
논문의 가장 직접적인 성과는 WMT 2014 번역 결과다. Transformer base는 영어-독일어에서 BLEU 27.3, 영어-프랑스어에서 BLEU 38.1을 기록한다. Transformer big는 각각 28.4, 41.8까지 올라간다. 이 수치는 당시 강력한 경쟁자였던 GNMT, ConvS2S, Mixture-of-Experts, Deep-Attention 계열을 넘어서는 결과이며, 특히 일부는 ensemble보다도 좋거나 비슷한 수준에 도달한다.
더 중요한 부분은 학습 비용이다. 영어-독일어 기준 base 모델의 학습 비용은 $3.3 \times 10^{18}$ FLOPs, big 모델은 $2.3 \times 10^{19}$ FLOPs로 보고된다. 이는 기존 최고 성능 후보들보다 낮거나 훨씬 효율적인 수준이다. 논문은 고성능이 더 이상 더 복잡한 순차 모델의 전유물이 아니라는 점을 수치로 보여준다. 이후 Transformer가 연구용 모델을 넘어 산업용 대규모 학습의 기본이 된 이유도 바로 이 효율성에 있다.
| 모델 | EN-DE BLEU | EN-FR BLEU | EN-DE 비용 | EN-FR 비용 |
|---|---|---|---|---|
| GNMT + RL | 24.6 | 39.92 | $2.3 \times 10^{19}$ | $1.4 \times 10^{20}$ |
| ConvS2S | 25.16 | 40.46 | $9.6 \times 10^{18}$ | $1.5 \times 10^{20}$ |
| MoE | 26.03 | 40.56 | $2.0 \times 10^{19}$ | $1.2 \times 10^{20}$ |
| Transformer base | 27.3 | 38.1 | $3.3 \times 10^{18}$ | - |
| Transformer big | 28.4 | 41.8 | $2.3 \times 10^{19}$ | - |
표에서 특히 눈에 띄는 부분은 Transformer big가 영어-독일어에서 기존 ensemble 결과를 넘어섰고, 영어-프랑스어에서는 단일 모델 기준 최고 수준을 달성했다는 점이다. 반면 Transformer base는 영어-프랑스어 절대 성능은 다소 낮지만 비용 대비 효율이 매우 뛰어나다. 즉, 논문은 하나의 구조가 고효율 구간과 최고성능 구간을 모두 커버할 수 있음을 보여준다.
5.2 모델 변형 실험: 헤드 수, 차원, 깊이, 정규화의 영향
논문은 Table 3에서 Transformer base를 기준으로 여러 구성 요소를 바꿔가며 검증한다. 이 실험은 단순한 하이퍼파라미터 탐색이 아니라, 어떤 설계가 구조적으로 중요한지 보여주는 역할을 한다. 예를 들어 헤드 수를 1개로 줄이면 BLEU가 24.9까지 떨어지고, 4개는 25.5, 16개는 25.8, 32개는 25.4를 기록한다. 즉, 멀티헤드가 실제로 의미 있고, 동시에 무작정 늘린다고 계속 좋아지지도 않는다는 결론을 얻을 수 있다.
| 변형 A: Head 수 | $h$ | $d_k=d_v$ | Dev PPL | Dev BLEU |
|---|---|---|---|---|
| base | 8 | 64 | 4.92 | 25.8 |
| A1 | 1 | 512 | 5.29 | 24.9 |
| A2 | 4 | 128 | 5.00 | 25.5 |
| A3 | 16 | 32 | 4.91 | 25.8 |
| A4 | 32 | 16 | 5.01 | 25.4 |
헤드 수 실험은 Transformer가 단순히 하나의 강한 어텐션 맵으로 작동하지 않는다는 점을 보여준다. 서로 다른 헤드가 다양한 관계를 나누어 담당할 수 있을 때 성능이 안정적이며, 너무 적은 헤드는 표현 다양성이 부족하고 너무 많은 헤드는 개별 헤드 차원이 너무 작아져 효율이 떨어질 수 있다. 이 분석은 이후 head pruning, multi-query attention, grouped-query attention 같은 연구의 출발점이 된다.
| 변형 C | 설정 | Params | Dev PPL | Dev BLEU |
|---|---|---|---|---|
| base | $N=6, d_{model}=512, d_{ff}=2048$ | 65M | 4.92 | 25.8 |
| C1 | $N=2$ | 36M | 6.11 | 23.7 |
| C2 | $N=4$ | 50M | 5.19 | 25.3 |
| C3 | $N=8$ | 80M | 4.88 | 25.5 |
| C4 | $d_{model}=1024$ | 168M | 4.66 | 26.0 |
| C5 | $d_{ff}=4096$ | 90M | 4.75 | 26.2 |
깊이와 폭을 바꾸는 실험에서 흥미로운 점은, 단순히 레이어 수만 늘리는 것보다 모델 차원과 FFN 차원을 키우는 편이 더 효과적이라는 신호가 보인다는 점이다. 예를 들어 $N=8$은 BLEU 25.5에 머물지만, $d_{model}=1024$는 26.0, $d_{ff}=4096$는 26.2까지 오른다. 이는 self-attention 블록이 어느 정도 깊이 이상에서는 표현 폭의 확장에 더 잘 반응할 수 있음을 시사하며, 이후 스케일링 연구에서도 반복적으로 확인되는 경향과 맞닿아 있다.
5.3 구문 분석 결과: 번역을 넘어선 일반성
영어 constituency parsing 실험에서 4층 Transformer는 WSJ only, discriminative 설정에서 F1 91.3, semi-supervised 설정에서 F1 92.7을 기록한다. 이는 당시 경쟁 모델들과 대등하거나 일부 설정에서 더 나은 결과다. 번역 태스크에만 특화된 구조였다면 이런 확장은 쉽지 않다. 논문은 이 결과를 통해 self-attention이 단순한 정렬 도구가 아니라, 문장 내부 구조 정보를 포착하는 일반적 표현 도구임을 주장한다.
| Parser | Training | WSJ 23 F1 |
|---|---|---|
| Dyer et al. (2016) | WSJ only, discriminative | 91.7 |
| Transformer (4 layers) | WSJ only, discriminative | 91.3 |
| McClosky et al. (2006) | semi-supervised | 92.1 |
| Vinyals & Kaiser et al. (2014) | semi-supervised | 92.1 |
| Transformer (4 layers) | semi-supervised | 92.7 |
| Dyer et al. (2016) | generative | 93.3 |
이 표는 Transformer가 모든 설정에서 절대 최고는 아니더라도, 구조가 완전히 다른 태스크에서도 경쟁력 있게 작동한다는 점을 보여준다. 특히 번역용 인코더-디코더 설계가 구문 구조를 파악하는 데도 충분한 표현력을 가진다는 사실은, 후속 연구가 이 구조를 언어 이해 전반으로 확장하는 근거가 되었다. BERT류 인코더 전용 모델이 등장하기 전 단계에서 이미 구조 일반성이 확인된 셈이다.
6. 추가 분석 및 Ablation Study: 왜 self-attention이 설득력 있었는가
6.1 복잡도와 경로 길이: 연산 비용만으로는 설명이 끝나지 않는다
논문 4절은 결과표만큼이나 중요하다. 저자들은 self-attention, recurrent layer, convolutional layer를 레이어당 계산 복잡도, 순차 연산 수, 최대 경로 길이로 비교한다. 이 비교는 Transformer가 왜 학습 효율과 표현 효율을 동시에 가져갈 수 있었는지를 구조적으로 설명한다. self-attention은 길이 $n$에 대해 $O(n^2 \cdot d)$ 복잡도를 가지므로 긴 시퀀스에서는 부담이 있지만, 순차 연산 수와 최대 경로 길이는 모두 $O(1)$이다.
| Layer Type | Complexity per Layer | Sequential Operations | Maximum Path Length |
|---|---|---|---|
| Self-Attention | $O(n^2 \cdot d)$ | $O(1)$ | $O(1)$ |
| Recurrent | $O(n \cdot d^2)$ | $O(n)$ | $O(n)$ |
| Convolutional | $O(k \cdot n \cdot d^2)$ | $O(1)$ | $O(\log_k n)$ |
| Restricted Self-Attention | $O(r \cdot n \cdot d)$ | $O(1)$ | $O(n/r)$ |
이 비교에서 논문이 강조하는 핵심은, 실제 기계번역에서 관심 있는 시퀀스 길이 구간에서는 self-attention의 계산 비용이 충분히 감당 가능하면서도, 장거리 의존성을 직접 연결할 수 있다는 점이다. 후속 긴 문맥 연구가 sparse attention, local attention, linear attention으로 확장된 것도 같은 맥락이다. 즉, Transformer는 처음부터 모든 길이에서 완벽한 구조라기보다, 실용적인 길이 구간에서 병렬성과 표현력을 가장 잘 절충한 설계였다.
6.2 정규화와 위치 표현에 대한 실험 해석
논문은 dropout과 label smoothing, positional encoding 방식이 성능에 미치는 영향도 비교한다. dropout을 0.0으로 두면 BLEU가 24.6, 0.2에서는 25.5가 나온다. label smoothing을 끄면 BLEU가 25.3, 0.2로 높이면 25.7이 된다. 또한 사인·코사인 대신 학습 가능한 positional embedding을 넣었을 때도 25.7로 큰 차이가 없었다. 즉, 성능 향상의 대부분은 새로운 위치 인코딩 자체보다 어텐션 중심 구조와 학습 프로토콜에서 나온다고 해석할 수 있다.
| 변형 D/E | 설정 | Dev PPL | Dev BLEU |
|---|---|---|---|
| D1 | Dropout = 0.0 | 5.77 | 24.6 |
| D2 | Dropout = 0.2 | 4.95 | 25.5 |
| D3 | Label smoothing = 0.0 | 4.67 | 25.3 |
| D4 | Label smoothing = 0.2 | 5.47 | 25.7 |
| E1 | Learned positional embedding | 4.92 | 25.7 |
이 표는 Transformer의 성공을 한두 개의 트릭으로 환원하기 어렵다는 점을 보여준다. 드롭아웃과 label smoothing은 분명 도움이 되지만, 그것만으로 기존 모델 대비 큰 도약을 설명할 수는 없다. 반대로 positional encoding의 구체적 형태는 그 자체가 결정타라기보다, 순서를 주입하는 최소 장치로 기능한다. 이 균형감은 논문이 후속 연구에서 쉽게 재현되고 변형될 수 있었던 이유이기도 하다.
6.3 어텐션 시각화: 모델이 실제로 무엇을 보는가
논문은 단순한 수치 비교를 넘어, 어텐션 헤드가 어떤 언어 현상을 포착하는지 시각화한다. 이는 Transformer가 블랙박스 행렬곱의 조합이 아니라, 실제로 의미 있는 정렬과 구조 정보를 분해해 학습하고 있음을 보여주는 근거다. 특히 장거리 동사-목적어 의존성, 대명사 참조, 구문 경계 포착 같은 사례는 멀티헤드 구조가 각기 다른 문법 기능을 나눠 담당할 가능성을 보여준다.

Figure 4: 장거리 의존성을 추적하는 인코더 self-attention
Figure 4는 인코더 5층의 일부 헤드가 동사 making과 그 보어 또는 목적 구조를 멀리 떨어진 위치에서도 연결하는 모습을 보여준다. 논문이 강조하는 포인트는 단순히 "어텐션이 멀리 본다"가 아니라, 여러 헤드 중 일부가 장거리 문법 의존성에 특화된 것처럼 보인다는 점이다. 이는 self-attention이 모든 관계를 균일하게 처리하는 것이 아니라, 헤드별로 역할 분화를 학습할 수 있음을 시사한다.

Figure 5: 대명사 참조와 관련된 전체 어텐션 패턴
Figure 5는 동일한 5층의 다른 헤드가 대명사와 선행사를 연결하는 패턴을 가진다는 점을 보여준다. 전체 문장에 대한 어텐션 분포를 보면, 특정 헤드가 모든 토큰을 균일하게 보는 것이 아니라 coreference와 관련된 위치에 선택적으로 집중하는 모습이 드러난다. 이 시각화는 self-attention이 단순한 평균화가 아니라, 문장 내부 지시 관계를 모델링할 수 있는 정렬 메커니즘이라는 해석을 뒷받침한다.
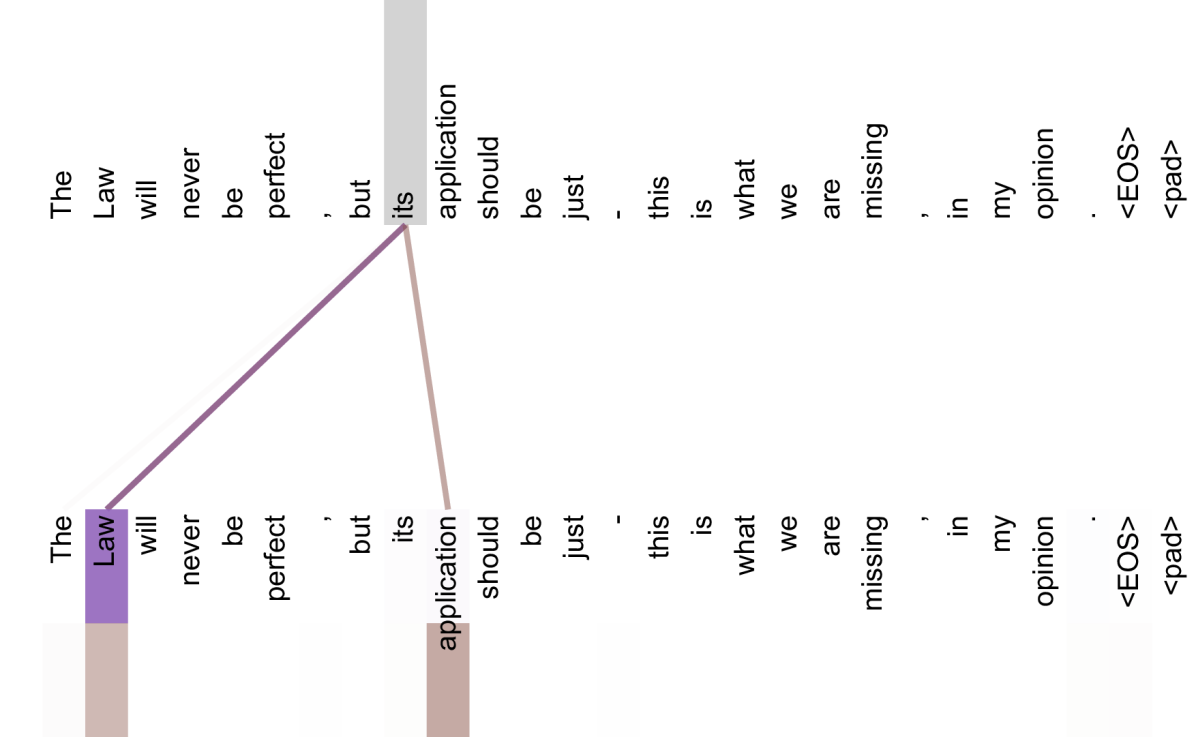
Figure 6: 대명사 'its'를 기준으로 고립해 본 어텐션
Figure 6은 Figure 5의 해석을 더 선명하게 만든다. 특정 단어 its에서 출발한 어텐션만 분리해 보여주면, 서로 다른 헤드가 각기 다른 참조 대상을 선택적으로 가리키는 패턴이 드러난다. 즉, 멀티헤드 구조는 단순한 앙상블이 아니라, 문장 내 관계 유형을 분해하는 기제로 볼 수 있다. 이후 probing 연구와 attention analysis 연구가 이 논문의 시각화 전통을 이어받았다.

Figure 7: 문장 구조와 관련된 self-attention 패턴 사례 1
Figure 7은 일부 헤드가 단순한 단어 정렬을 넘어 구문 경계와 유사한 패턴을 학습한다는 점을 보여준다. 문장 트리 자체를 명시적으로 학습시키지 않았음에도, self-attention이 특정 범주적 경계나 구문 블록을 따라 집중하는 모습이 나타난다. 이것은 Transformer가 기호적 문법 지식을 직접 인코딩했다고 주장하기보다, 최소한 언어 구조와 상관된 표현을 충분히 학습할 수 있음을 시사하는 증거로 읽는 편이 적절하다.

Figure 8: 문장 구조와 관련된 self-attention 패턴 사례 2
Figure 8은 Figure 7과 유사하지만 다른 헤드가 또 다른 구조적 단서를 포착한다는 점을 보여준다. 같은 층 안에서도 헤드별로 보는 관계가 다르기 때문에, Transformer는 한 종류의 문법 힌트에만 의존하지 않는다. 이것이 이후 대규모 모델에서 헤드별 기능 분석이 중요한 연구 주제가 된 이유다. 논문은 정량적 설명보다 정성적 사례를 제시하지만, 그 사례만으로도 멀티헤드의 분업 가능성은 충분히 설득된다.
6.4 인코더와 디코더의 정보 흐름을 어떻게 다시 설계했는가
Transformer를 이해할 때 흔히 어텐션 수식만 기억하고 끝내기 쉽지만, 실제 설계의 힘은 정보 흐름의 재배치에 있다. RNN 기반 인코더-디코더에서는 입력 문장을 순차적으로 압축한 마지막 상태가 디코더의 출발점 역할을 하거나, 어텐션이 있더라도 기본 축은 순차적 상태 갱신에 놓여 있었다. 반면 Transformer 인코더는 각 층에서 모든 위치가 서로를 참조한 뒤, 그 결과를 다시 동일한 차원의 표현으로 유지한다. 이 때문에 상위 층으로 갈수록 어떤 단어가 문장 전체에서 어떤 역할을 하는지가 더 전역적으로 반영된다.
디코더 역시 중요한 차이를 가진다. 첫 번째 서브레이어인 masked self-attention은 생성 중인 접두 문맥만 보게 하여 언어모델 역할을 수행하고, 두 번째 서브레이어인 encoder-decoder attention은 번역 대상 문장에 대한 조건부 참조를 담당한다. 즉, 디코더는 한쪽으로는 자기 자신의 생성 이력에, 다른 한쪽으로는 원문 인코더 표현에 동시에 의존한다. 이 두 종류의 조건부 참조가 분리되어 있기 때문에, Transformer 디코더는 생성 문맥 모델링과 입력 문장 정렬을 서로 다른 서브레이어에서 명확하게 분담한다.
이 분리는 후속 연구에서 결정적으로 중요해졌다. 예를 들어 GPT 계열은 인코더-디코더 어텐션을 제거하고 causal self-attention만 남겨 순수 생성 모델을 만들었고, BERT 계열은 디코더를 제거한 채 양방향 인코더만 남겨 표현 학습에 집중했다. 다시 말해 이 논문은 하나의 구조만 제안한 것이 아니라, 인코더와 디코더를 모듈 단위로 분리해 각각 독립적인 연구 대상이 되게 만들었다. 이후 아키텍처 선택이 훨씬 유연해진 이유가 여기에 있다.
또한 Transformer의 인코더-디코더 정보 흐름은 메모리 접근 방식을 바꿨다. RNN에서는 과거 정보가 은닉 상태 하나에 누적되어 전달되지만, Transformer에서는 현재 위치가 필요할 때마다 모든 과거 또는 모든 입력 위치를 직접 조회한다. 이는 정보가 단일 벡터에 압축되어 사라지는 문제를 줄이고, 디코더가 번역 중 특정 원문 토큰이나 구절을 반복적으로 재참조할 수 있게 만든다. 기계번역뿐 아니라 요약, 질의응답, 코드 생성에서도 이 참조형 메커니즘이 강력했던 이유가 바로 이 직접 조회 구조에 있다.
이 관점에서 보면, Transformer의 혁신은 단순히 "어텐션이 좋다"가 아니라 모델이 정보를 저장하고 꺼내는 방식을 재설계했다는 데 있다. 순환 구조는 정보를 시간축을 따라 전달해야 하지만, 어텐션 구조는 필요할 때 필요한 위치를 바로 읽어올 수 있다. 후속 연구가 retrieval, memory tokens, external memory, KV cache 같은 개념으로 이어진 것도 결국 이 직접 참조 패러다임을 더 멀리 확장한 결과다. 따라서 이 논문은 self-attention을 도입한 논문이면서 동시에 신경망 메모리 접근 모델을 재정의한 논문으로 읽을 수 있다.
6.5 실험 수치를 어떻게 읽어야 하는가: 단순 최고점 이상의 메시지
논문의 수치를 오늘 시점에서 다시 읽을 때 주의할 점은 절대 BLEU 값 자체보다 비교 구도를 보는 것이다. 예를 들어 영어-독일어 BLEU 28.4는 지금 기준으로는 더 이상 높은 숫자가 아니지만, 당시에는 강력한 CNN·RNN 계열과 ensemble을 포함한 최고 성능들을 넘어서는 결과였다. 더구나 그 성능이 복잡한 증강 없이 구조적 단순화로 달성되었다는 점이 중요하다. 논문은 "새로운 보정 기법을 쌓았더니 조금 좋아졌다"는 식이 아니라, 연산 구조를 바꾸자 성능과 효율이 함께 좋아졌다고 보여준다.
base와 big의 대비 역시 의미가 크다. base 모델은 비교적 적은 비용으로도 매우 경쟁력 있는 결과를 내고, big 모델은 더 많은 차원과 더 긴 학습으로 절대 성능을 밀어 올린다. 이는 Transformer가 작아도 강하고 커져도 더 강해지는 구조임을 보여주는 초기 증거다. 후속 스케일링 법칙 연구가 등장하기 훨씬 이전이지만, 이미 이 논문 안에는 구조가 파라미터 확장에 우호적이라는 신호가 들어 있다. 단순히 새로운 블록이 아니라 확장 가능한 기본 아키텍처였다는 점이 핵심이다.
또한 Table 3의 ablation은 성능 수치 이상의 해석을 가능하게 한다. 예를 들어 헤드 수를 1개로 줄이면 성능이 눈에 띄게 하락하지만, 8개에서 16개로 올린다고 크게 좋아지지는 않는다. 이는 표현 공간을 다중화하는 것이 중요하지만, 표현 분할이 지나치면 각 헤드의 유효 용량이 줄 수 있음을 시사한다. 오늘날 LLM에서 head pruning이나 grouped-query attention이 실용적 선택으로 받아들여지는 이유도 결국 이런 균형 위에서 이해할 수 있다.
정규화 실험 역시 흥미롭다. label smoothing을 넣으면 perplexity는 나빠질 수 있지만 BLEU는 개선된다. 즉, 모델이 정답 토큰 하나에 지나치게 확신하지 않게 만드는 것이 번역 품질 평가에는 더 적합할 수 있다는 뜻이다. 이는 언어 생성에서 최적화 목표와 최종 평가 지표 사이의 간극을 보여주는 사례이며, 이후 RLHF나 preference optimization 논의와도 멀리 연결된다. 다시 말해 이 논문은 구조 혁신뿐 아니라, 생성 모델을 어떻게 학습하고 평가할 것인가에 대한 감각도 이미 담고 있다.
결과적으로 이 논문의 실험은 단순한 성능 나열이 아니라, Transformer가 왜 후속 연구의 기본값이 될 수 있었는지를 설명하는 설계 논증에 가깝다. 작동한다, 병렬화된다, 확장된다, 다른 태스크에도 일반화된다라는 네 가지 메시지가 서로 맞물려 있기 때문이다. 핵심 논문으로서의 가치는 바로 여기에 있다. 혁신적 아이디어가 흥미로운 데서 그치지 않고, 연구 커뮤니티가 집단적으로 채택할 만큼 실용적인 근거를 제공했다.
6.6 후속 연구와의 연결: BERT, GPT, ViT로 이어진 구조적 계보
Attention Is All You Need를 다시 읽을 때 가장 인상적인 지점 중 하나는, 후속 대형 모델의 핵심 요소가 이미 거의 모두 씨앗 형태로 들어 있다는 사실이다. encoder-only 방향은 문맥 표현을 깊게 축적하는 데 유리하다는 점에서 BERT류로 이어졌고, decoder-only 방향은 자기회귀 생성에 최적화된 구조라는 점에서 GPT류로 이어졌다. 논문이 인코더와 디코더를 같은 어텐션 블록의 변형으로 구성했기 때문에, 후속 연구는 목적에 맞는 절반만 남기거나 일부만 바꾸는 방식으로 빠르게 확장할 수 있었다.
비전 영역으로의 확장도 이 논문 없이는 설명하기 어렵다. 이미지 패치를 토큰 시퀀스로 보고 self-attention을 적용하는 Vision Transformer는, 사실상 "입력을 시퀀스로 바꿔 토큰 간 관계를 어텐션으로 계산한다"는 이 논문의 일반 공식을 시각 데이터에 적용한 결과다. object detection에서는 DETR가 query 기반 디코더를 도입했고, 멀티모달 모델들은 텍스트 토큰과 이미지 토큰, 오디오 토큰 사이의 cross-attention을 설계했다. 즉, Transformer는 NLP 아키텍처가 아니라 토큰화 가능한 데이터 전반의 공통 연산기가 되었다.
대형 언어모델 학습 인프라 측면에서도 이 논문은 중요한 출발점이다. self-attention은 GPU 친화적인 대형 행렬 곱으로 구현되며, 이는 데이터 병렬, 텐서 병렬, 파이프라인 병렬 같은 후속 분산 학습 전략과 잘 맞는다. RNN이 본질적으로 가지고 있던 시간축 직렬 병목이 줄어들었기 때문에, 모델과 데이터가 동시에 커지는 시대에 훨씬 유리했다. 오늘날 수백억에서 수천억 파라미터 모델이 실용적으로 학습되는 배경에는 알고리즘 혁신뿐 아니라 이런 하드웨어 적합성이 깔려 있다.
또한 KV cache 개념 역시 Transformer의 직접적 부산물이다. 디코더 self-attention은 이미 생성된 토큰들의 key와 value를 재사용할 수 있기 때문에, 자기회귀 추론에서 이전 계산을 저장해 두는 전략이 자연스럽게 등장했다. 이는 오늘날 추론 최적화, long-context serving, speculative decoding, prefix caching 같은 실전 시스템 연구의 핵심이 된다. 다시 말해 이 논문은 학습 아키텍처일 뿐 아니라, 현대 LLM serving 구조의 계산 계약까지 미리 정해 놓은 셈이다.
이런 연결을 종합하면, Transformer의 핵심 가치는 한 논문이 여러 분야에 영향을 주었다는 정도가 아니다. 더 정확히는, 서로 달라 보이는 후속 연구들이 실제로는 같은 기본 계산 패턴을 공유하게 만들었다는 점이다. 언어, 비전, 오디오, 멀티모달, 에이전트, 추천 시스템까지 모두 토큰화와 어텐션이라는 공통 틀 위에서 소통하게 되었고, 연구 커뮤니티는 서로의 기법을 훨씬 쉽게 전이할 수 있게 됐다. 핵심 논문으로서 이 논문이 갖는 장기 영향력은 바로 이 공통 프레임 형성에 있다.
6.7 왜 지금도 다시 읽을 가치가 있는가
오늘날 Transformer는 너무 보편적이어서 오히려 구체적 설계 이유가 잊히기 쉽다. 하지만 이 논문을 다시 읽어 보면, 후속 연구에서 관성처럼 쓰는 선택들이 모두 분명한 문제의식에서 출발했다는 점이 보인다. 왜 멀티헤드인가, 왜 residual과 normalization을 함께 쓰는가, 왜 positional encoding이 필요한가, 왜 warmup이 중요한가, 왜 정규화가 BLEU에는 유리한가 같은 질문이 전부 여기서 구조적으로 정리되어 있다. 최신 모델을 이해하려면 오히려 이 원형 논문을 다시 읽는 편이 빠를 때가 많다.
특히 최근에는 Transformer 이후의 대안으로 Mamba, RWKV, Hyena, 각종 state space model이 주목받고 있다. 이런 흐름을 평가할 때도 기준점은 결국 Transformer다. 왜냐하면 대안 모델이 개선하려는 대상이 대부분 어텐션의 이차 비용, 긴 문맥 비효율, 추론 메모리 병목 같은 Transformer의 한계이기 때문이다. 다시 말해 새로운 구조의 장단점을 읽기 위해서도 Transformer가 무엇을 해결했고 무엇을 남겼는지 정확히 알아야 한다.
교육적인 측면에서도 이 논문은 여전히 강력하다. 복잡한 최신 거대모델 논문과 달리, 핵심 아이디어가 선명하고 ablation이 잘 정리되어 있으며, 시각화와 수치 해석의 균형도 좋다. 그래서 Transformer를 단순히 외우는 것이 아니라 왜 이 구조가 선택되었는지를 이해하는 데 적합하다. 실제로 많은 연구자와 엔지니어가 이 논문을 통해 시퀀스 모델링, 어텐션, 병렬 학습, 구조적 일반화라는 개념을 함께 익힌다.
마지막으로, 이 논문은 AI 연구에서 드문 종류의 전환점을 보여준다. 어떤 아이디어는 특정 벤치마크를 올리고 끝나지만, 어떤 아이디어는 연구자들이 문제를 표현하는 언어 자체를 바꾼다. Transformer는 명백히 후자다. 지금 우리가 context length, attention head, KV cache, encoder-only, decoder-only, cross-attention 같은 말을 너무 자연스럽게 쓰는 이유는, 이 논문이 이미 그 개념적 좌표계를 제공했기 때문이다.
6.8 번역 문제에서 본 self-attention의 구조적 장점
기계번역은 Transformer의 장점을 가장 선명하게 드러내는 태스크였다. 번역에서는 원문 문장의 특정 단어가 목표 문장의 어느 위치와 대응되는지, 그리고 장거리 문법 관계가 어떻게 재배열되는지가 중요하다. RNN 기반 모델은 이 정보를 순차적 은닉 상태에 압축해 전달해야 하므로, 긴 문장에서는 초기 정보가 약해지거나 정렬 오류가 누적되기 쉽다. 반면 self-attention은 각 위치가 입력의 모든 위치를 직접 참조할 수 있기 때문에, 단어 재배치와 장거리 의존성 포착에 본질적으로 유리하다.
예를 들어 독일어와 영어 사이에는 동사 위치, 수식어 배치, 보어 구조에서 차이가 크다. 이런 재배열은 국소 커널이나 직렬 은닉 상태만으로 처리하면 긴 경로를 거쳐야 하지만, self-attention은 관련 토큰을 직접 연결한다. 논문이 Figure 4와 Figure 5에서 보여준 사례는 단지 시각화 예시가 아니라, 번역 품질 향상의 구조적 이유를 정성적으로 보여주는 장면이다. 어떤 헤드는 멀리 떨어진 보어 관계를 따라가고, 어떤 헤드는 대명사와 선행사를 직접 연결하면서 번역에 필요한 정렬 신호를 만든다.
또한 번역에서는 인코더 표현과 디코더 표현이 상호작용하는 방식이 중요하다. Transformer의 encoder-decoder attention은 디코더의 현재 상태가 원문 전체를 바라보면서 필요한 토큰을 선택적으로 참조할 수 있게 한다. 이는 고정 길이 문맥 벡터를 사용하던 초기 seq2seq보다 훨씬 강력한 조건부 생성 메커니즘이다. 즉, Transformer의 성능 향상은 self-attention 하나의 효과가 아니라, 인코더 self-attention + 디코더 masked self-attention + cross-attention이 함께 만든 결과다.
결과적으로 이 논문은 번역을 통해 self-attention이 갖는 두 가지 장점을 동시에 증명했다. 하나는 표현적 장점으로, 먼 위치 관계를 직접 모델링할 수 있다는 점이고, 다른 하나는 계산적 장점으로, 모든 위치를 병렬로 처리할 수 있다는 점이다. 번역은 이 두 요소가 모두 중요한 태스크이기 때문에, Transformer의 설계 우월성이 가장 먼저 크게 드러난 사례가 되었다. 이후 요약, 질의응답, 코드 생성, 대화 모델링으로 일반화된 것도 이 두 장점이 언어 전반에 공통적이었기 때문이다.
6.9 구현 관점에서 본 Transformer의 단순성과 재현 가능성
핵심 논문으로서 이 논문이 특별한 또 하나의 이유는 재현 가능성이 높았다는 점이다. 당시 일부 최고 성능 모델은 복잡한 학습 파이프라인, 특수한 정렬 기법, 깊은 순환 구조 최적화, 여러 단계의 보조 손실을 함께 써야 했다. 반면 Transformer는 상대적으로 짧은 설명으로도 핵심 블록과 학습 규칙을 전달할 수 있었다. 인코더와 디코더가 동일한 모듈의 반복으로 구성되고, 어텐션과 FFN, residual, layer normalization, dropout, Adam, warmup이라는 비교적 명확한 조합으로 정리되기 때문이다.
이 단순성은 연구 커뮤니티의 채택 속도에 직접 영향을 주었다. 새로운 아키텍처가 정말 지배적인 표준이 되려면 단지 성능만 높은 것이 아니라, 다른 연구자가 빠르게 구현하고 수정할 수 있어야 한다. Transformer는 바로 그런 조건을 충족했다. 실제로 논문 발표 이후 짧은 시간 안에 다양한 프레임워크 구현이 등장했고, 연구자들은 쉽게 변형을 실험할 수 있었다. 성능 향상과 구현 단순성이 동시에 주어진 드문 사례였기 때문에, 후속 연구가 급격히 폭발할 수 있었다.
산업적 관점에서도 이 단순성은 중요하다. 대규모 배치 학습, 커스텀 커널 최적화, 분산 학습 스케줄링, 추론 캐시 전략 같은 시스템 최적화는 구조가 반복적일수록 유리하다. Transformer 블록은 동일한 연산 패턴이 층마다 반복되기 때문에, 하드웨어와 컴파일러가 최적화하기 좋은 형태를 가진다. 오늘날 FlashAttention, fused kernel, tensor parallelism, inference engine이 모두 Transformer를 중심으로 발달한 이유는 구조적 수요가 일관되었기 때문이다.
이 점은 논문이 단순히 연구 아이디어 차원에서 성공한 것이 아니라, 생태계 친화적인 표준을 만들었다는 의미를 갖는다. 연구 논문이 산업 구현, 오픈소스 프레임워크, 교육 자료, 추론 엔진까지 동일한 중심 구조를 공유하게 만드는 경우는 흔치 않다. Transformer는 그 드문 예외이며, 그래서 핵심 논문으로서의 가치가 단지 역사성에만 머물지 않는다. 지금도 새로운 모델을 설계할 때 많은 팀이 가장 먼저 묻는 질문은 "기본 Transformer에서 무엇을 바꿀 것인가"이지, 완전히 다른 계산 틀을 처음부터 발명할 것인가가 아니다.
6.10 핵심 논문으로서의 장기 영향력: 왜 Transformer는 하나의 시대를 규정했는가
머신러닝의 핵심 논문이라고 불리는 문서에는 공통점이 있다. 특정 벤치마크를 잘 푸는 데서 끝나지 않고, 이후 연구자들이 문제를 바라보는 좌표계를 바꾼다는 점이다. AlexNet이 대규모 CNN 시대를 열었고, ResNet이 깊은 네트워크 학습의 표준을 만들었듯이, Transformer는 시퀀스 모델링과 생성 모델의 공통 표준을 만들었다. 오늘날 자연어 처리의 많은 논문이 아키텍처 설명을 최소화하고도 통하는 이유는, 기본 전제가 이미 Transformer 계열로 공유되어 있기 때문이다.
장기 영향력은 논문이 영향을 준 후속 모델 이름만 나열해서는 충분히 설명되지 않는다. 더 중요한 것은, 이 논문이 연구비용을 낮췄다는 점이다. 공통의 계산 패턴이 생기면, 새로운 아이디어는 기본 구조 전체를 새로 발명하지 않고도 특정 부분만 바꾸어 실험할 수 있다. positional bias, sparse attention, memory compression, mixture-of-experts, retrieval augmentation, instruction tuning 같은 후속 아이디어가 빠르게 축적될 수 있었던 이유도 Transformer가 튼튼한 기본 베이스라인을 제공했기 때문이다. 즉, 이 논문은 후속 연구를 쉽게 만드는 일종의 플랫폼 역할을 했다.
또한 Transformer는 서로 다른 하위 분야를 같은 언어로 묶어 냈다. 예전에는 번역, 언어모델, 문서 이해, 비전, 음성, 멀티모달이 각각 다른 구조적 전통을 가졌지만, Transformer 이후에는 모두 토큰화와 어텐션, 인코더와 디코더, 사전학습과 미세조정이라는 공통 개념으로 대화하게 되었다. 이는 단순한 유행이 아니라 연구 생산성 자체를 높이는 변화였다. 한 분야의 아이디어가 다른 분야로 이동하는 속도가 빨라졌고, 결과적으로 AI 전반의 진화 속도도 빨라졌다.
이런 이유로 Attention Is All You Need는 "유명한 고전" 정도로만 분류하기 어렵다. 오히려 현재도 진행형으로 영향력을 행사하는 현행 표준의 원문에 가깝다. 최신 LLM 논문을 읽다가 컨텍스트 길이, KV cache, head dimension, RoPE, cross-attention, decoder stack이라는 말을 만났다면, 그 개념적 뿌리는 대부분 이 논문까지 거슬러 올라간다. 핵심 논문 카테고리에서 이 글을 먼저 다루는 선택은, 후속 거의 모든 현대 AI 모델을 이해하는 기반을 먼저 세운다는 의미를 가진다.
6.11 수식 관점에서 다시 보는 Transformer의 표현 능력
수식만 놓고 보면 Transformer는 놀랄 만큼 간결하다. 어텐션은 행렬 곱과 softmax, FFN은 두 층의 선형 변환과 ReLU, 위치 정보는 사인·코사인 함수로 정리된다. 그러나 이 단순한 수식 조합이 강력한 이유는, 각 연산이 서로 다른 역할을 분명하게 담당하기 때문이다. $QK^T$는 토큰 간 관계를 측정하고, softmax는 그 관계를 확률적 가중치로 변환하며, $V$의 가중합은 필요한 정보를 재조합한다. 여기에 FFN이 각 위치 표현을 비선형적으로 재구성하고, residual 경로가 정보 손실을 막는다. 즉, 표현 능력은 복잡한 비선형 하나에서 나오기보다 관계 선택-정보 집계-위치별 변환의 반복 구조에서 나온다.
특히 self-attention의 장점은 입력 길이에 따라 동적으로 다른 계산 그래프를 만들 수 있다는 점이다. RNN은 같은 재귀 연산을 시점마다 반복하고, CNN은 같은 커널을 위치마다 적용하지만, self-attention은 각 입력마다 토큰 간 상관관계가 달라질 수 있다. 다시 말해 attention weight 자체가 입력 의존적 연결 행렬 역할을 한다. 이 때문에 Transformer는 고정된 지역 연결이나 시간 연결에 묶이지 않고, 문장마다 다른 정렬 구조와 의존 구조를 즉석에서 구성할 수 있다.
멀티헤드 구조는 이 연결 행렬을 하나가 아니라 여러 개 동시에 학습한다는 점에서 더 중요하다. 만약 단일 헤드만 있었다면 하나의 유사도 정의가 모든 문법·의미 관계를 동시에 떠안아야 한다. 하지만 여러 헤드는 서로 다른 선형 투영을 거치므로, 어떤 헤드는 주어-동사 관계를, 어떤 헤드는 수식어 정렬을, 어떤 헤드는 장거리 참조를 더 민감하게 볼 수 있다. 논문의 시각화는 이 분업이 완전한 기호 규칙처럼 해석될 수준은 아니더라도, 최소한 기능적 분화가 실제로 학습된다는 강한 힌트를 제공한다.
이러한 관점은 이후 Transformer 이론 연구의 중심 질문으로 이어졌다. self-attention이 어떤 종류의 계산을 근사할 수 있는지, positional encoding이 없으면 어떤 함수를 표현하지 못하는지, depth와 head 수가 표현력에 어떤 영향을 주는지 같은 연구들이 모두 이 논문의 수식적 핵심을 파고든 결과다. 즉, Attention Is All You Need는 실험적으로 큰 성공을 거둔 논문이면서 동시에, 이후 이론적 분석을 촉발한 드문 아키텍처 논문이기도 하다.
6.12 학습 동역학 관점에서 본 warmup과 안정성
Transformer를 실제로 구현해 보면 구조만큼이나 중요한 것이 학습 안정성이다. 논문이 warmup을 넣은 이유는 단순히 경험적으로 좋았기 때문만이 아니다. self-attention과 residual 경로, layer normalization, large-batch parallel training이 결합된 초기 단계에서는, 학습 초반의 큰 업데이트가 표현 스케일을 급격히 흔들 수 있다. warmup은 이 구간에서 학습률을 서서히 올려 모델이 적절한 표현 스케일과 정렬 패턴을 형성하도록 돕는다. 이후 inverse square root decay로 넘어가는 설계는, 초반 탐색과 후반 안정 수렴을 함께 고려한 절충이다.
이 점은 후속 대형 언어모델 학습에서도 반복적으로 확인된다. 세부 스케줄은 cosine decay, linear warmup, constant LR 등으로 바뀌었지만, 학습 초반을 조심스럽게 다뤄야 한다는 감각은 Transformer 계열에서 공통적이다. 특히 잔차 경로를 따라 신호가 깊게 누적되는 구조에서는, 초반 몇 천 스텝의 스케일 관리가 전체 수렴 품질에 큰 영향을 준다. 논문이 learning rate schedule을 별도 식으로 명시한 것은, 아키텍처 자체만큼 최적화 설계도 핵심 구성 요소라는 사실을 분명히 한 선택이다.
dropout과 label smoothing의 조합 역시 같은 맥락에서 읽을 수 있다. dropout은 특정 연결이나 뉴런에 과도하게 의존하는 현상을 줄여 표현을 더 분산시키고, label smoothing은 출력 분포가 지나치게 날카로워지는 것을 막는다. 번역처럼 하나의 정답 문장만이 절대적 답이 아닌 태스크에서는, 모델이 정답 토큰 하나만 과하게 확신하는 것보다 여러 plausible token에 일정 확률 질량을 남기는 편이 일반화에 유리할 수 있다. 논문이 perplexity보다 BLEU를 중시한 것도 생성 태스크의 본질을 잘 짚은 판단이다.
흥미로운 점은, 이런 학습 동역학 설계가 이후 아키텍처 변형과도 긴밀하게 연결되었다는 사실이다. 예를 들어 Pre-LN 구조는 더 깊은 모델의 학습 안정성을 높였고, RMSNorm은 정규화 비용을 줄이면서도 안정성을 유지하려는 시도였다. gated FFN과 더 나은 초기화 전략, 더 정교한 스케줄링도 모두 같은 문제를 다룬다. 따라서 이 논문을 읽을 때는 구조 블록뿐 아니라, Transformer가 왜 이런 방식으로 학습되어야 했는가라는 질문까지 함께 보는 것이 중요하다.
6.13 현재 시점에서 다시 보는 한 문장 평가
이 논문을 한 문장으로 요약하자면, "시퀀스 모델링의 중심 연산을 시간축 재귀에서 토큰 간 전역 참조로 옮긴 논문"이라고 할 수 있다. 이 한 문장은 단순한 수사가 아니라 이후 AI 발전 경로를 실제로 설명한다. 언어모델은 더 이상 과거를 압축한 은닉 상태 하나에 의존하지 않고, 필요한 과거 토큰 표현을 직접 조회한다. 비전 모델은 국소 커널만으로 이미지를 훑지 않고, 패치 간 전역 관계를 본다. 멀티모달 모델은 서로 다른 모달의 토큰들을 같은 표현 공간 안에서 상호참조한다. 이 모든 흐름이 이 논문의 계산 전환과 맞닿아 있다.
또한 이 논문은 모델 설계에서 단순함이 얼마나 강력할 수 있는지를 보여준다. 각 블록은 비교적 이해하기 쉽고 반복 가능하며, 수학적으로도 복잡하지 않다. 그런데 그 조합은 매우 강력한 일반성을 가진다. 이는 좋은 아키텍처가 반드시 복잡한 휴리스틱의 집합이어야 하는 것은 아니라는 점을 보여준다. 오히려 역할이 분명한 소수의 연산을 조합해 넓은 범용성을 확보하는 방식이 더 오래 살아남을 수 있다는 교훈을 준다.
마지막으로, 이 논문은 아직도 끝난 논문이 아니다. 오늘날 우리가 논의하는 긴 문맥, 에이전트 메모리, 외부 도구 사용, 추론 캐시, 멀티모달 정렬 문제는 모두 Transformer의 능력과 한계를 확장하는 과정에서 나온 질문들이다. 따라서 Attention Is All You Need를 읽는 일은 단지 과거를 복습하는 것이 아니라, 현재 AI 연구가 어디에서 출발했고 어디서 계속 갈라지고 있는지를 확인하는 작업에 가깝다. 핵심 논문 카테고리의 첫 축으로서 충분히 상징적이고 실질적인 선택이다.
7. 한계점 및 향후 연구 방향: 2017년의 해법이 남긴 과제들
이 논문은 명백히 기념비적이지만, 동시에 이후 8년 가까운 연구가 해결해 온 문제도 이미 안고 있었다. 가장 대표적인 한계는 시퀀스 길이에 대한 이차 복잡도다. self-attention은 모든 위치 쌍의 상호작용을 계산하므로 길이가 길어질수록 메모리와 계산량이 급격히 증가한다. 논문은 당시 번역 길이 구간에서는 충분히 실용적이라고 보았지만, 문서 전체나 수십만 토큰 문맥을 다루는 오늘날 기준에서는 곧바로 병목이 된다. Longformer, Reformer, Performer, FlashAttention, linear attention, state space model 계열이 등장한 배경이 바로 이 제약이다.
둘째 한계는 위치 정보 주입 방식의 단순함이다. 사인·코사인 positional encoding은 당시에는 충분했지만, 이후 연구는 relative positional bias, RoPE, ALiBi 같은 더 강력한 위치 표현이 긴 문맥 일반화와 extrapolation에 중요하다는 사실을 보여주었다. 즉, 논문은 순환을 제거한 대가로 위치 문제를 외부에서 주입해야 했고, 이 부분은 이후 Transformer 연구의 큰 분기점이 되었다.
셋째는 구조 편향의 부족이다. RNN과 CNN은 각각 시간 순서와 국소성에 대한 강한 inductive bias를 갖는다. 반면 Transformer는 보다 일반적이고 유연하지만, 데이터가 적을 때는 오히려 불리할 수도 있다. 논문이 대규모 번역 데이터와 강한 최적화 전략을 함께 사용한 이유도 여기에 있다. 후속 연구에서 convolutional stem, recurrence hybrid, relative bias, prefix constraint, retrieval augmentation 같은 장치가 다시 도입된 것은, 완전히 중립적인 구조가 항상 최선은 아니라는 점을 보여준다.
그럼에도 향후 연구 방향이라는 관점에서 보면, 이 논문은 문제를 남겼다기보다 연구 지형을 열었다고 보는 편이 맞다. 더 긴 문맥을 어떻게 다룰 것인가, 어텐션 비용을 어떻게 줄일 것인가, 헤드의 역할을 어떻게 이해하고 재설계할 것인가, 위치와 구조 편향을 어떤 방식으로 넣을 것인가, 언어 외 모달로 어떻게 확장할 것인가 같은 질문이 모두 이 논문 이후 본격화됐다. 즉, Transformer는 완성된 답이 아니라, 이후 연구가 공유할 질문의 틀을 만들었다.
7.1 긴 문맥과 메모리 병목: 성공의 반대편에 있던 비용 문제
오늘 시점에서 Transformer의 가장 널리 알려진 약점은 역시 긴 문맥 처리 비용이다. self-attention은 길이 $n$의 시퀀스에 대해 $n \times n$ 상호작용을 계산하므로, 토큰 수가 늘어날수록 메모리 사용량과 연산량이 빠르게 증가한다. 논문이 다루던 번역 문장 길이에서는 충분히 감당할 수 있었지만, 수천·수만 토큰을 다루는 현대 LLM 환경에서는 이 비용이 시스템 설계 전체를 지배할 정도로 커진다. 실제로 긴 문맥 모델을 만들기 위해서는 FlashAttention, paged KV cache, chunked attention, sparse attention 같은 추가 기법이 거의 필수적이다.
흥미로운 점은 이 한계가 Transformer의 성공과 정확히 같은 지점에서 나온다는 사실이다. 모든 위치를 직접 연결하는 능력이 장거리 의존성 모델링을 가능하게 했지만, 바로 그 전역 연결성 때문에 비용이 커진다. 즉, Transformer는 표현력과 비용 사이의 고전적 절충을 새로운 방식으로 재배치한 구조다. 후속 효율화 연구의 대부분은 이 전역성을 완전히 포기하지 않으면서 계산량만 줄이려는 시도로 볼 수 있다. 이는 Transformer가 단순히 불완전한 구조가 아니라, 매우 강력한 기본점 위에 서 있었기 때문에 생긴 후속 문제다.
이 관점에서 긴 문맥 연구를 보면, Transformer 이후의 많은 아이디어는 사실상 원래 논문의 철학을 유지한 채 근사 전략을 설계하는 작업이다. local window를 두거나, 중요한 토큰만 골라 보거나, 저랭크 근사를 쓰거나, recurrent state를 부분적으로 복원하는 방식 모두 self-attention의 전역성에서 어느 부분을 보존할지 결정하는 선택이다. 따라서 긴 문맥 병목은 Transformer의 실패라기보다, 그 구조가 너무 강력해서 더 큰 문제 범위로 확장되며 드러난 자연스러운 한계로 보는 편이 정확하다.
7.2 데이터 규모와 구조 편향: 왜 Transformer는 큰 데이터에서 특히 강했는가
Transformer는 강한 표현력을 제공하지만, 그만큼 명시적 구조 편향은 상대적으로 약하다. RNN은 시간 순서를 따라 상태를 누적하고, CNN은 국소 영역을 반복적으로 합성하기 때문에 각각 자연스러운 inductive bias를 갖는다. 반면 Transformer는 거의 모든 위치 쌍을 동등하게 열어 둔 상태에서 학습을 시작한다. 이 자유도는 충분한 데이터와 계산 자원이 있을 때는 강력한 장점이 되지만, 데이터가 적거나 구조적 제약이 중요한 환경에서는 오히려 비효율적일 수 있다.
실제로 이후 연구에서 소규모 데이터셋이나 특수 도메인에서는 CNN stem, relative bias, locality prior, recurrence hybrid를 다시 넣는 시도가 이어졌다. 이는 Transformer가 잘못되었다는 뜻이 아니라, 강한 범용성은 약한 선행 편향의 대가를 수반한다는 의미다. 논문이 대규모 WMT 번역 데이터를 사용해 설득력 있는 결과를 낸 것도 우연이 아니다. Transformer는 큰 데이터와 큰 배치, 충분한 병렬 연산이 있을 때 구조의 장점이 훨씬 크게 드러난다.
이 사실은 오늘날의 초거대 사전학습 모델 시대에도 그대로 이어진다. Transformer가 LLM의 표준이 된 이유는 구조가 이론적으로 완벽해서가 아니라, 대규모 데이터·대규모 계산·대규모 분산 학습과 만났을 때 가장 강력한 실용적 선택이었기 때문이다. 즉, 이 논문은 좋은 아키텍처를 제안한 동시에, 이후 AI 발전이 어떤 자원 축을 따라 확장될지를 예고한 논문이기도 하다. 데이터와 계산이 커질수록 Transformer의 장점이 더 크게 드러난다는 감각은 여기서 이미 시작된다.
7.3 해석 가능성과 제어 가능성: 어텐션을 본다고 이해가 끝나는 것은 아니다
논문은 attention visualization을 통해 모델이 학습한 관계를 일부 보여주지만, 그것이 곧 완전한 해석 가능성을 의미하는 것은 아니다. 이후 연구는 attention map이 항상 결정 근거와 일치하지 않을 수 있고, 헤드 역할 역시 문맥과 층에 따라 달라질 수 있다는 점을 지적했다. 즉, Transformer는 일부 내부 구조를 시각화하기 쉬운 면이 있지만, 그것만으로 모델의 계산을 완전히 설명할 수는 없다. 해석 가능성은 이 논문이 연 질문 중 하나였고, 아직도 완전히 끝나지 않은 문제다.
그럼에도 어텐션이 제공한 부분적 투명성은 중요했다. 최소한 연구자들은 특정 헤드가 어떤 관계를 보는지, 어떤 층에서 어떤 패턴이 나타나는지, 특정 토큰이 어디를 강하게 참조하는지 관찰할 수 있었다. 이는 RNN 은닉 상태 하나에 모든 정보가 혼합되어 있던 시대보다 분석 가능성이 더 높은 환경을 만들었다. 후속 mechanistic interpretability 연구가 Transformer를 주 대상으로 삼는 이유도 여기에 있다. 구조가 반복적이고, 관계 계산이 명시적 행렬 형태로 드러나기 때문에 실험 설계가 상대적으로 수월하다.
7.4 향후 연구 방향을 오늘 기준으로 다시 쓰면
만약 이 논문의 향후 연구 방향을 오늘 기준에서 다시 쓴다면, 첫 번째 질문은 여전히 전역 참조를 얼마나 효율적으로 유지할 수 있는가일 것이다. 긴 문맥을 다루는 모델은 더 이상 번역 문장 수준이 아니라, 코드 저장소, 장문 문서, 도구 사용 이력, 에이전트 상호작용 로그를 함께 처리해야 한다. 이때 중요한 것은 모든 토큰을 무조건 동일하게 보는 것이 아니라, 어떤 토큰이 실제로 중요한지 동적으로 가려 내는 능력이다. sparse attention, retrieval augmentation, memory compression, hierarchical attention은 모두 이 문제를 각기 다른 방식으로 다룬다.
두 번째 질문은 위치와 구조 정보를 어떻게 더 잘 넣을 것인가다. 사인·코사인 positional encoding은 당시에는 충분했지만, 긴 문맥 일반화와 토큰 외 구조 정보가 중요한 현대 문제에서는 더 정교한 표현이 필요하다. relative bias, RoPE, segment-level recurrence, tree-aware attention, graph transformer 같은 흐름은 모두 같은 질문의 변형이다. 즉, Transformer 이후의 연구는 순환을 버린 뒤 사라진 구조적 힌트를 어떻게 다시, 그러나 더 유연하게 넣을 것인가를 지속적으로 탐색해 왔다.
세 번째 질문은 어텐션이 학습한 기능을 얼마나 분리하고 제어할 수 있는가다. 헤드별 역할이 실제로 얼마나 안정적인지, 어떤 층이 어떤 기능을 담당하는지, 특정 기능만 선택적으로 강화하거나 제거할 수 있는지 같은 문제는 interpretability와 controllability 연구로 이어졌다. 이 질문은 단순한 학술적 호기심을 넘어, 안전성, 정렬, 편향 제어, 도구 사용 신뢰성까지 연결된다. 거대한 Transformer 기반 에이전트를 운영하는 시대에는, 모델이 무엇을 보고 어떤 이유로 행동했는지 파악할 수 있어야 하기 때문이다.
마지막 질문은 Transformer를 기본 계산 단위로 유지한 채 어떤 외부 시스템을 결합할 것인가다. 오늘날 강한 시스템은 순수 파라미터 메모리만으로 작동하지 않고, 검색기, 코드 실행기, 장기 메모리, 플래너, 검증기와 함께 동작한다. 그런데 이런 시스템들의 내부 표현 대부분은 여전히 Transformer 기반 모델에서 생성된다. 즉, 향후 연구 방향은 Transformer를 대체할 것인가의 문제라기보다, Transformer를 중심으로 어떤 외부 모듈과 계약을 설계할 것인가의 문제로 이동하고 있다. 이 관점에서도 Attention Is All You Need는 아직 끝난 출발점이 아니다.
8. 결론: 하나의 모델이 아니라 이후 AI 스택의 공통 기반
Attention Is All You Need의 진짜 성취는 번역 성능 기록만으로는 다 설명되지 않는다. 이 논문은 어텐션을 보조 장치에서 주연 연산으로 끌어올렸고, 시퀀스 모델링을 순차 처리 중심에서 전역 상호작용 중심으로 재구성했다. 그 결과는 번역 BLEU 개선, 학습 시간 단축, 구조 단순화라는 즉각적인 이점으로 나타났고, 이후에는 대규모 언어모델, 비전 Transformer, 멀티모달 모델, 음성 모델, 에이전트 모델의 공통 기반으로 확장되었다.
핵심 논문으로서 이 논문이 여전히 중요하게 읽히는 이유는, 오늘날 너무 익숙해진 설계 선택들이 사실은 모두 여기서 명시적으로 정리되었기 때문이다. Q-K-V 분해, 멀티헤드 병렬화, 잔차 연결과 정규화, 위치 인코딩, warmup 학습률 스케줄, 가중치 공유, 구조적 ablation까지, 이후 수많은 연구가 기본값으로 받아들인 요소들이 이 짧은 논문 안에 압축되어 있다.
물론 지금의 초거대 모델은 이 논문 그대로가 아니다. Pre-LN, RoPE, RMSNorm, SwiGLU, MoE, grouped-query attention, retrieval, tool use, alignment, instruction tuning 같은 수많은 확장이 더해졌다. 그러나 이 모든 변형은 결국 Transformer라는 기본 틀을 어디까지 유지하고 어디를 바꿀 것인가의 문제로 귀결된다. 그런 의미에서 이 논문은 특정 시대의 최고 모델이 아니라, 이후 AI 시스템 설계의 공통 출발점이다.
현대 AI 시스템을 실무 관점에서 바라보더라도 이 논문의 의미는 선명하다. 오늘날 대형 모델 서비스는 학습 단계에서는 대규모 병렬 행렬 연산을, 추론 단계에서는 KV cache를 활용한 반복 참조를, 응용 단계에서는 검색·도구·메모리 모듈과의 결합을 핵심 운영 원리로 삼는다. 이 세 층위 모두가 Transformer의 계산 계약 위에 서 있다. 즉, Attention Is All You Need는 연구 아이디어 차원을 넘어 현대 AI 인프라의 기본 인터페이스를 제공한 논문이기도 하다.
또한 이 논문은 구조 혁신이 반드시 복잡한 이론이나 거대한 휴리스틱 집합에서 나오지 않는다는 점을 보여준다. 오히려 핵심 문제를 정확히 겨냥해 불필요한 요소를 제거하고, 남은 연산을 반복 가능한 블록으로 정리했을 때 더 큰 파급력이 나올 수 있다. 순환과 합성곱을 버리고 어텐션 중심으로 재구성한다는 선택은 당시에 과감했지만, 바로 그 단순화 덕분에 후속 연구자들이 각 블록의 역할을 쉽게 이해하고 확장할 수 있었다. 좋은 핵심 논문은 많은 후속 논문을 낳는데, 이 논문은 그 기준에서 거의 교과서적인 사례다.
결국 Transformer의 위상은 단순히 "지금도 많이 쓰인다"는 수준이 아니다. 현대 AI의 상당수 모델은 구조가 다소 달라 보여도, 입력을 토큰 시퀀스로 만들고, 위치 정보를 주입하고, 전역 또는 준전역 참조를 수행하고, 반복 블록을 쌓아 표현을 심화한다는 공통 흐름을 공유한다. 이 공통 흐름의 원문이 바로 Attention Is All You Need다. 그래서 이 논문은 과거의 전환점이면서 동시에, 현재를 이해하기 위한 가장 직접적인 출발점으로 계속 남아 있다.
핵심 논문을 읽는 목적은 역사 지식을 채우는 데 있지 않다. 오늘의 연구와 시스템을 구성하는 기본 가정이 어디서 왔는지 확인하고, 그 가정이 어떤 문제의식 위에서 만들어졌는지 다시 이해하는 데 있다. 그런 점에서 Attention Is All You Need는 매우 효율적인 텍스트다. 현대 LLM, 멀티모달 모델, 에이전트 시스템을 이해하기 위해 필요한 개념의 상당수가 이 논문 안에서 이미 압축된 형태로 제시되며, 후속 연구의 대부분은 여기에 새로운 데이터 규모, 새로운 모달, 새로운 최적화, 새로운 시스템 제약을 덧붙인 변주로 읽을 수 있다.
또한 이 논문은 모델 설계에서 무엇을 남기고 무엇을 버릴지를 판단하는 기준이 얼마나 중요한지를 보여준다. 저자들은 당시 주류였던 순환과 합성곱을 무조건 계승하지 않고, 실제로 필요한 기능을 더 직접적으로 수행할 수 있는 연산만 남겼다. 토큰 간 상호작용은 어텐션으로, 위치별 비선형 변환은 FFN으로, 깊은 학습 안정성은 residual과 normalization으로 정리하면서 전체 구조를 놀랄 만큼 간결하게 만들었다. 이 압축의 미학이야말로 Transformer가 이후 수많은 변형을 견디며 살아남은 이유 중 하나다.
결과적으로 이 논문을 읽고 남는 가장 중요한 메시지는, 현대 AI의 많은 진전이 더 복잡한 구조를 끝없이 추가하는 방식이 아니라 핵심 계산 단위를 더 일반적이고 병렬적인 형태로 재정의하는 데서 나왔다는 사실이다. Transformer는 바로 그 재정의의 상징이며, 지금도 여전히 새로운 모델과 시스템을 평가하는 기준점 역할을 한다. 그래서 Attention Is All You Need는 과거의 고전이면서 동시에 현재의 실전 문서다.
실제로 이 논문 이후의 발전사를 거꾸로 따라가 보면, Transformer는 단순한 아키텍처 제안이 아니라 연구 커뮤니티 전체의 문제 분해 방식을 바꾸었다. 예전에는 모델 종류가 달라질 때마다 입력 표현, 내부 상태, 출력 정렬 방식이 함께 바뀌는 경우가 많았지만, Transformer 이후에는 동일한 기본 블록을 유지한 채 입력 토큰화 방식이나 학습 목표, 메모리 전략만 바꾸는 식의 발전이 가능해졌다. 이 통일성 덕분에 연구자들은 더 짧은 주기로 아이디어를 검증할 수 있었고, 산업 현장도 연구 결과를 더 빠르게 흡수할 수 있었다.
따라서 Attention Is All You Need를 핵심 논문으로 읽는다는 것은 단지 Transformer의 구조를 복습하는 일이 아니다. 오히려 현대 AI가 왜 이렇게 빠르게 한 방향으로 수렴했는지, 왜 서로 다른 분야의 연구가 같은 연산 언어를 공유하게 되었는지, 왜 하드웨어와 소프트웨어 최적화가 특정 모델 계열에 집중되었는지를 이해하는 일에 가깝다. 이 논문은 한 편의 모델 논문인 동시에, 이후 AI 생태계 전체의 공용 기반 문서를 제공한 논문이다.
무엇보다 중요한 점은, 이 논문이 단일 아키텍처의 승리를 넘어 연구·엔지니어링·서비스 운영이 같은 구조를 공유하는 드문 합의점을 만들었다는 사실이다. 학계는 Transformer를 기준으로 새로운 표현 학습과 정렬 기법을 제안했고, 오픈소스 커뮤니티는 같은 구조를 기반으로 수많은 구현과 최적화를 축적했으며, 산업 현장은 그 결과물을 실제 서비스 스택에 연결했다. 한 논문이 이렇게 긴 시간 동안 동일한 수준의 중심성을 유지하는 경우는 많지 않다. Attention Is All You Need가 핵심 논문인 이유는 성능 숫자 하나가 아니라, 이후 AI 생태계 전체가 이 논문의 계산 언어 위에서 서로 연결되었기 때문이다.
이 점에서 보면 Attention Is All You Need는 과거의 전설적 논문이면서 동시에 현재의 운영 문서다. 최신 모델이 어떤 이름을 달고 나오더라도, 우리는 여전히 attention block의 효율, head 구성, positional scheme, long-context behavior, cache reuse, scaling stability를 묻는다. 질문의 형식 자체가 이미 Transformer 이후의 언어로 바뀐 것이다. 핵심 논문으로서의 가치는 바로 이런 지속성에 있다. 특정 시대를 이끈 데서 끝나지 않고, 다음 시대의 질문 형식까지 규정한 논문은 많지 않다.
따라서 이 논문을 다시 읽는 일은 Transformer를 찬양하기 위한 복습이 아니라, 현대 AI가 어떤 계산 가정 위에 세워졌는지 점검하는 작업이다. 구조를 이해하면 후속 논문이 무엇을 새로 해결했는지, 무엇은 여전히 미해결로 남아 있는지 더 선명하게 보인다. 핵심 논문 카테고리에서 Attention Is All You Need를 우선적으로 다룰 가치가 충분한 이유가 여기에 있다.
그리고 바로 이 이유 때문에, Transformer를 이해하는 것은 특정 모델 계열 하나를 아는 것을 넘어, 현대 AI 연구가 공유하는 기본 연산 철학을 이해하는 일과 거의 같다. 시퀀스를 토큰화하고, 토큰 사이 관계를 직접 계산하며, 반복 블록으로 표현을 심화하는 이 사고방식은 여전히 AI의 중심에 있다.
이런 지속성은 핵심 논문만이 가질 수 있는 성격이다. 한 시대의 최고 성능을 넘어서, 다음 시대의 질문 형식과 구현 관습까지 남긴다는 점에서 이 논문은 여전히 현재형이다.
그래서 Transformer를 이해하는 일은 결국 현대 AI의 공용 문법을 이해하는 일과 다르지 않다.
이 논문의 가치가 시간이 지나도 줄지 않는 이유도 여기에 있다.
따라서 이 논문을 핵심 논문 목록의 앞자리에 두는 이유는 단순한 상징성이 아니다. 실제로 현대 모델이 공유하는 연산 구조, 학습 병렬화 방식, 긴 문맥 처리의 병목, 그리고 후속 아키텍처가 무엇을 계승하고 무엇을 수정했는지를 가장 짧은 거리에서 이해하게 해 주기 때문이다. Attention Is All You Need는 과거의 유명한 출발점이 아니라, 지금의 모델 설계를 읽는 기준 좌표를 제공하는 문서로 남아 있다.
9. 요약 정리
- Transformer는 순환과 합성곱을 제거하고 어텐션만으로 인코더-디코더를 구성한 최초의 대표 논문이다.
- 핵심 연산은 Scaled Dot-Product Attention이며, $\mathrm{softmax}(QK^T/\sqrt{d_k})V$ 형태로 계산된다.
- Multi-Head Attention은 서로 다른 표현 하위공간에서 병렬적으로 관계를 학습하게 해 주며, 헤드 수 ablation으로 그 유효성이 확인된다.
- 기본 모델은 $N=6$, $d_{model}=512$, $d_{ff}=2048$, head 8개로 구성되며, big 모델은 이를 더 크게 확장한다.
- WMT 2014 영어-독일어에서 BLEU 28.4, 영어-프랑스어에서 BLEU 41.8을 달성해 당시 최고 수준 결과를 기록했다.
- 동시에 학습 비용이 낮고 병렬성이 높아, 성능뿐 아니라 실제 학습 효율까지 설득력 있게 개선했다.
- 영어 constituency parsing 결과는 Transformer가 번역 전용 구조가 아니라 범용 시퀀스 표현 구조가 될 수 있음을 보여준다.
- 어텐션 시각화는 일부 헤드가 장거리 의존성, 대명사 참조, 문장 구조와 관련된 패턴을 학습한다는 정성적 근거를 제시한다.
- 한계로는 이차 복잡도와 단순한 위치 표현이 있으며, 이후 긴 문맥·효율적 어텐션 연구가 이 문제를 확장 해결해 왔다.
- 결국 이 논문은 단일 번역 모델의 성공을 넘어, 오늘날 LLM·비전·멀티모달·에이전트 모델의 공통 아키텍처 문법을 만든 핵심 논문으로 평가할 수 있다.