An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
https://arxiv.org/abs/2010.11929
https://arxiv.org/html/2010.11929
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby | Google Research, Brain Team 등 | arXiv:2010.11929 | 2020년 10월 | ICLR 2021
1. 서론: 이미지 인식의 기본 단위를 합성곱에서 패치 시퀀스로 바꾼 논문
Vision Transformer, 흔히 ViT라고 부르는 이 논문은 컴퓨터 비전에서 오랫동안 당연하게 여겨졌던 전제를 정면으로 다시 묻는다. 이미지 분류를 잘하려면 반드시 CNN의 지역적 수용영역, 가중치 공유, 계층적 다운샘플링 같은 귀납편향이 필요하다는 믿음이 그것이다. 저자들은 이 전제를 유지한 채 attention을 CNN의 일부에 붙이는 대신, 이미지를 일정 크기의 패치로 잘라 하나의 토큰 시퀀스로 바꾸고, 여기에 표준 Transformer encoder를 그대로 적용하는 더 급진적인 경로를 택한다. 핵심은 비전 전용의 복잡한 합성곱 블록을 정교하게 쌓는 대신, 충분히 큰 데이터와 적절한 사전학습이 있다면 순수한 Transformer만으로도 강한 시각 표현을 학습할 수 있다는 점을 실험적으로 입증했다는 데 있다.
이 논문이 발표된 2020년 시점에는 ResNet, EfficientNet, BiT 같은 계열이 이미지 인식의 주류였고, attention은 주로 CNN의 보조 모듈이나 일부 레이어 교체용으로 활용되는 경우가 많았다. 따라서 ViT의 메시지는 단순히 "Transformer를 비전에 썼다"는 수준이 아니다. 오히려 입력 표현, 계산 경로, 스케일링 방식, 사전학습-전이학습의 경제성을 모두 다시 정리하는 제안에 가깝다. 이후 DeiT, Swin Transformer, MAE, CLIP 계열까지 이어지는 거대한 비전 Transformer 흐름이 사실상 이 논문에서 본격적으로 시작됐다는 점에서, ViT는 핵심 논문 카테고리에 매우 잘 들어맞는다.
저자들이 내세운 주장은 명확하다. 작은 데이터에서 학습할 때는 CNN이 가진 강한 귀납편향이 유리할 수 있지만, 대규모 사전학습 데이터가 주어지고 그 표현을 다양한 다운스트림 벤치마크로 전이시키는 설정에서는 순수 Transformer가 더 좋은 확장성과 성능-연산 균형을 보여줄 수 있다는 것이다. 논문은 이를 위해 JFT-300M, ImageNet-21k, ImageNet 사전학습 규모를 체계적으로 비교하고, ImageNet뿐 아니라 CIFAR-10, CIFAR-100, Oxford-IIIT Pets, Oxford Flowers-102, 그리고 VTAB까지 폭넓게 실험한다. 즉, ViT는 특정 벤치마크의 특수한 승리가 아니라, 데이터 스케일이 커질 때 아키텍처의 유불리가 어떻게 바뀌는지를 구조적으로 보여준 논문이다.
오늘 관점에서 이 논문을 다시 읽으면 두 층위가 동시에 보인다. 하나는 이미지 분류 성능 보고서로서의 층위다. 다른 하나는 "이미지를 패치의 언어처럼 다룰 수 있는가"라는 표현 재정의의 층위다. 후자가 더 중요하다. ViT는 이미지의 국소 구조를 convolution kernel 안에 미리 박아 넣지 않고, 패치 단위의 시퀀스로 토큰화한 뒤 전역적 self-attention이 의미 있는 관계를 스스로 조직하도록 만든다. 그 결과 이후 비전 분야는 구조를 CNN에 고정하는 대신, 입력을 시퀀스로 재표현하고 Transformer의 보편적 연산 틀로 문제를 통합하는 방향으로 빠르게 이동했다.
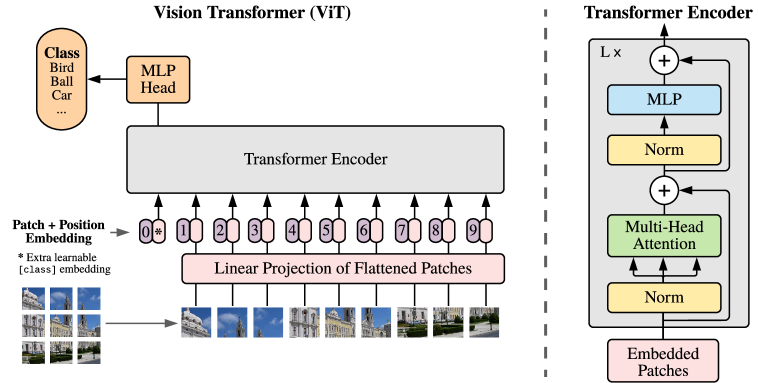
Figure 1: 이미지를 패치 시퀀스로 바꿔 Transformer encoder에 넣는 ViT의 전체 구조
Figure 1은 ViT의 문제 재정의를 가장 직관적으로 보여준다. 입력 이미지는 고정 크기의 patch로 분할되고, 각 패치는 선형 투영을 거쳐 토큰이 되며, 여기에 position embedding과 class token이 더해진 뒤 표준 Transformer encoder로 처리된다. 이 그림의 의미는 비전 전용 블록을 세밀하게 설계하는 대신, 입력 표현 단계만 바꿔서 NLP에서 검증된 encoder 구조를 그대로 가져왔다는 데 있다. 바로 이 단순성이 ViT의 재사용 가능성과 스케일링의 출발점이 된다.
2. 배경 및 관련 연구: CNN의 귀납편향과 Transformer의 보편 연산 사이
2.1 CNN이 강했던 이유와 한계: 지역성, 이동 불변성, 그리고 구조 고정
컴퓨터 비전에서 CNN이 오랫동안 강한 기본값이었던 이유는 분명하다. 이미지의 통계적 구조는 대체로 지역적이며, 가까운 픽셀들 사이의 상관관계가 강하고, 물체의 위치가 조금 달라져도 의미가 크게 바뀌지 않는 경우가 많다. 합성곱은 바로 이 사실을 구조에 내장한다. 작은 커널을 슬라이딩하면서 지역 패턴을 공유 가중치로 탐지하고, 계층을 깊게 쌓으며 점차 더 넓은 수용영역과 추상적 의미를 얻는다. 데이터가 비교적 적을 때 이 귀납편향은 강력한 규제가 되어 안정적인 일반화를 만든다.
하지만 이 장점은 동시에 제약이기도 하다. 합성곱 기반 모델은 초기에 지역성 가정이 강하게 박혀 있으므로, 장거리 의존성이나 전역적 문맥을 표현하려면 깊은 계층적 합성과 다운샘플링을 거쳐야 한다. 물론 ResNet이나 BiT 같은 강한 계열은 이 제약을 상당 부분 완화했지만, 계산 구조 자체는 여전히 시각 패턴을 지역적으로 쌓아 올리는 방식에 가깝다. 저자들이 겨냥한 것은 CNN의 성능 그 자체가 아니라, 구조 수준에서 전역 상호작용을 더 직접적으로 모델링할 수 있는 대안을 찾는 일이었다.
또 다른 배경은 데이터 스케일의 변화다. 초기 비전 모델들은 주로 ImageNet 수준의 데이터에 맞춰 설계되었지만, 산업 연구 환경에서는 그보다 훨씬 큰 JFT-300M 같은 초대규모 사전학습 데이터셋이 가능해졌다. 데이터가 충분히 클 때는 사람이 설계한 귀납편향을 강하게 넣는 것보다, 더 일반적인 함수 클래스에 표현 학습을 맡기는 편이 오히려 유리할 수 있다. ViT는 바로 이 상황에서 "비전에서도 귀납편향을 완화한 구조가 통하는가"를 묻는다. 즉, 이 논문은 CNN을 반박하기보다, 귀납편향과 데이터 규모 사이의 균형점이 어디서 이동하는지를 실험으로 추적한 작업이라고 보는 편이 정확하다.
2.2 NLP에서 검증된 Transformer를 비전으로 옮길 때의 문제와 기회
Transformer는 Attention Is All You Need 이후 자연어 처리에서 사실상의 표준이 되었지만, 비전으로 그대로 가져오는 일은 생각만큼 단순하지 않았다. 자연어는 원래 이산 토큰 시퀀스이지만, 이미지는 2차원 격자 구조와 강한 국소 연속성을 가진다. 따라서 Transformer를 비전에 적용하려면 먼저 연속적인 픽셀 배열을 어떤 방식으로 시퀀스화할지 결정해야 한다. 이전 연구들은 보통 CNN이 만든 feature map 위에 attention을 얹거나, 일부 레이어를 Transformer로 바꾸는 식의 절충을 택했다. ViT의 차별점은 이 절충을 최소화하고 입력 단계부터 Transformer 친화적으로 다시 정의했다는 데 있다.
이때 가장 중요한 발상은 이미지를 $P\times P$ 크기의 패치로 잘라 각 패치를 하나의 토큰으로 보는 것이다. 이는 단순한 구현 편의가 아니다. 패치화는 한편으로 self-attention의 시퀀스 길이를 줄여 계산 가능하게 만들고, 다른 한편으로는 한 패치 내부의 국소 구조는 선형 투영으로 압축하고 패치 간 관계는 attention이 담당하도록 역할을 분리한다. 다시 말해 ViT는 픽셀 수준에서 모든 관계를 직접 다루는 대신, 패치를 비전의 최소 의미 단위로 삼아 Transformer가 처리할 수 있는 표현 공간으로 옮긴다.
관련 연구 관점에서 보면 ViT는 두 계보를 동시에 잇는다. 하나는 NLP 쪽의 class token, position embedding, encoder-only Transformer 설계다. 다른 하나는 비전 쪽의 대규모 사전학습과 전이학습 전통이다. ViT는 이 둘을 결합해, 언어모델처럼 먼저 거대한 데이터에서 일반 표현을 학습한 뒤 다양한 다운스트림 데이터셋에 미세조정하는 비전 파이프라인을 정교하게 밀어붙인다. 이후 self-supervised vision pretraining, multimodal pretraining, masking-based image modeling이 확산되는 출발점이 된 것도 바로 이 결합 때문이다.
3. 방법론: 패치를 토큰으로 바꾸는 순수 Transformer 기반 이미지 분류기
3.1 패치 분할과 입력 표현: 이미지를 문장처럼 직렬화하는 과정
ViT의 입력 구성은 매우 단순하지만, 그 단순성 자체가 핵심이다. 크기 $H\times W\times C$의 이미지를 $P\times P$ 패치들로 나누면 총 패치 수는 $N=HW/P^2$가 된다. 각 패치는 펼쳐진 뒤 선형 투영 행렬을 통과해 차원 $D$의 토큰으로 바뀐다. 여기에 분류용 learnable class token 하나를 맨 앞에 붙이고, 각 위치의 순서를 알려 주기 위해 position embedding을 더한다. 그러면 이제 입력은 더 이상 2차원 이미지가 아니라 $(N+1)$ 길이의 토큰 시퀀스가 된다.
논문은 이 과정을 다음과 같이 정리한다. 먼저 입력 시퀀스는 $$\mathbf{z}_0=[\mathbf{x}_{class};\mathbf{x}_p^1\mathbf{E};\mathbf{x}_p^2\mathbf{E};\cdots;\mathbf{x}_p^N\mathbf{E}] + \mathbf{E}_{pos}$$ 로 표현된다. 여기서 $\mathbf{E}$는 패치 임베딩용 선형 투영 행렬이고, $\mathbf{E}_{pos}$는 위치 임베딩이다. 이 수식이 의미하는 바는 복잡한 공간 연산을 앞단에서 수행하지 않고, 오직 패치 수준의 선형화와 위치 정보 추가만으로 Transformer가 처리할 수 있는 입력 형식을 만든다는 점이다. CNN과 비교하면 초기 표현 단계의 귀납편향이 훨씬 약해지고, 이후의 관계 학습은 대부분 attention과 MLP에 맡겨진다.
이 설계의 장점과 비용은 동시에 분명하다. 장점은 구조가 매우 일반적이라서 이미지 크기, 데이터셋, 다운스트림 태스크에 따라 동일한 encoder 골격을 재사용하기 쉽다는 것이다. 또한 patch size를 조절함으로써 계산량과 세밀함 사이의 균형을 조절할 수 있다. 반면 패치가 너무 크면 지역 세부 정보가 손실되고, 너무 작으면 시퀀스 길이가 급증해 self-attention 계산이 비싸진다. 논문이 ViT-B/16, ViT-B/32, ViT-L/16, ViT-L/32, ViT-H/14 같은 변형을 함께 실험하는 이유도 바로 이 입력 세분성의 영향을 체계적으로 보기 위해서다.
3.2 Transformer encoder 블록: MSA와 MLP의 반복 구조
패치 시퀀스로 바뀐 입력은 표준 Transformer encoder를 통과한다. 각 블록은 Multi-Head Self-Attention과 MLP 서브레이어로 구성되며, 두 서브레이어 앞에는 LayerNorm, 뒤에는 Residual connection이 놓인다. 논문은 각 층의 갱신을 $$\mathbf{z}'_\ell = \mathrm{MSA}(\mathrm{LN}(\mathbf{z}_{\ell-1})) + \mathbf{z}_{\ell-1}$$, $$\mathbf{z}_\ell = \mathrm{MLP}(\mathrm{LN}(\mathbf{z}'_\ell)) + \mathbf{z}'_\ell$$ 로 기술한다. 이는 NLP용 encoder를 사실상 거의 수정 없이 가져온 형태이며, ViT의 중요한 메시지 가운데 하나는 이 정도의 단순 이식만으로도 비전에서 강한 성능이 가능하다는 사실이다.
여기서 self-attention의 역할은 패치 간 관계를 전역적으로 연결하는 것이다. 어떤 패치가 물체의 일부분만 담고 있더라도, attention은 다른 패치들과의 상호작용을 통해 전체 객체나 장면 수준 문맥 안에서 의미를 조정할 수 있다. CNN처럼 수용영역을 여러 층에 걸쳐 점진적으로 늘리지 않아도, 한 층의 attention만으로도 멀리 떨어진 패치가 직접 연결된다는 점이 핵심 차이다. 물론 계산량은 시퀀스 길이의 제곱에 비례하지만, 패치 단위로 시퀀스를 줄임으로써 이 비용을 실용적 범위에 맞춘다.
논문은 또한 encoder 마지막의 class token 출력을 분류기에 사용한다. 이는 BERT의 [CLS]와 유사한 발상으로, 전체 시퀀스를 집약한 대표 토큰이 분류용 정보를 담도록 학습시키는 방식이다. 후속 연구에서는 글로벌 평균 풀링이 때로 더 안정적일 수 있다는 보고도 나오지만, ViT 원 논문 단계에서는 class token 방식이 모델을 자연스럽게 언어 Transformer와 연결하는 역할을 했다. 즉 ViT는 단지 attention을 가져온 것이 아니라, 입력-출력 인터페이스까지 Transformer 계열의 공통 문법으로 맞춘 셈이다.
3.3 모델 변형과 하이브리드 설계: 순수 Transformer와 CNN stem의 비교
논문은 순수 Transformer만 제안하고 끝나지 않는다. 다양한 모델 크기와 함께, CNN의 초기 저수준 특징 추출을 일부 남긴 hybrid 구조도 비교한다. 대표적으로 R50+ViT는 ResNet의 stem 또는 초기 feature extraction을 사용한 뒤 Transformer로 이어지는 형태다. 이는 두 가지 질문을 동시에 시험한다. 첫째, CNN의 귀납편향을 완전히 버리는 것이 항상 좋은가. 둘째, 귀납편향이 필요한 구간을 일부 남기고 상위 표현만 Transformer로 바꾸는 절충이 더 효율적인가.
결과적으로 저자들은 작은 모델이나 상대적으로 제한된 계산 예산에서는 hybrid가 순수 Transformer보다 이점을 보일 수 있지만, 모델 규모와 사전학습 데이터가 충분히 커지면 그 차이가 사라지거나 순수 ViT가 더 유리해진다고 보고한다. 이 관찰은 중요하다. ViT의 메시지는 CNN이 언제나 불필요하다는 선언이 아니라, 데이터와 연산 자원이 충분할수록 사람 손으로 주입한 구조적 가정의 가치가 상대적으로 줄어들 수 있다는 경험적 결과이기 때문이다. 후속 비전 Transformer 연구들이 소규모 데이터용 경량 설계를 따로 고민하고, 초대규모 사전학습용 순수 Transformer 계열을 별도로 발전시킨 이유도 여기에 있다.
논문이 제시한 대표 모델 크기는 다음과 같다. ViT-Base는 12개 레이어, hidden size 768, MLP size 3072, 12 heads, 약 86M 파라미터를 가진다. ViT-Large는 24개 레이어, hidden size 1024, MLP size 4096, 16 heads, 약 307M 파라미터이며, ViT-Huge는 32개 레이어, hidden size 1280, MLP size 5120, 16 heads, 약 632M 파라미터다. 이 스케일링은 이후 거대 비전 모델 설계의 전형이 된다. 다시 말해 ViT는 단지 새로운 블록을 제안한 것이 아니라, 비전 모델도 언어모델처럼 "크기, 데이터, 연산"의 축에서 매끈하게 확장될 수 있다는 신호를 준 논문이다.
| 모델 | 레이어 수 | Hidden size | MLP size | Attention heads | 파라미터 수 |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632M |
이 표는 ViT가 작은 트릭보다 모델 패밀리로 제시되었다는 점을 보여준다. 패치 크기와 레이어 수, hidden size를 조절하면서 서로 다른 계산 예산과 데이터 규모에 대응할 수 있도록 설계되었고, 이는 이후 비전 Transformer 스케일링 연구의 기준 틀이 된다. 특히 Base에서 Huge로 갈수록 성능이 매끈하게 좋아지는 경향은, ViT가 우연한 한 점이 아니라 스케일 친화적 아키텍처라는 논문의 핵심 주장과 직접 연결된다.
3.4 패치 크기와 해상도의 의미: B/16과 B/32가 말해 주는 것
ViT를 이해할 때 자주 간과되는 요소가 patch size다. 논문 제목의 "16x16 words"는 단순한 비유가 아니라, 비전 표현의 최소 단위를 어디에 둘 것인지에 대한 구조적 선언이다. 패치가 작아질수록 더 많은 토큰이 생성되어 이미지의 세밀한 구조를 더 잘 보존할 수 있지만, self-attention 비용은 토큰 수의 제곱에 비례하므로 계산량이 급격히 증가한다. 반대로 패치가 커지면 계산은 줄지만, 초기 입력 단계에서 세부 정보가 더 많이 압축된다. ViT-B/16과 ViT-B/32의 비교는 바로 이 trade-off를 보여 주는 실험적 장치다.
실제 결과를 보면 같은 Base 크기 모델이라도 B/16이 B/32보다 ImageNet, CIFAR, Pets, Flowers 등 여러 벤치마크에서 일관되게 더 강하다. 이는 패치 세분성이 충분하지 않으면 Transformer가 전역 관계를 잘 학습하더라도, 초기에 잃어버린 지역 정보의 손실을 복구하기 어렵다는 뜻으로 읽을 수 있다. 즉 ViT는 "전역 attention이면 모든 것이 해결된다"고 말하지 않는다. 오히려 전역 attention이 제대로 작동하려면 입력 토큰화가 표현력의 병목이 되지 않도록 조정해야 함을 보여 준다.
이 논점은 후속 연구에서도 매우 중요해졌다. 더 작은 패치는 더 강한 성능을 만들 수 있지만 계산량이 빠르게 늘어나므로, 실제 응용에서는 패치 크기, 입력 해상도, 모델 너비를 함께 조절하는 설계가 필요하다. 이후 hierarchical transformer나 windowed attention 계열이 등장한 것도, 패치 세밀함을 유지하면서도 전체 시퀀스 길이 폭증을 제어하려는 시도라고 볼 수 있다. 따라서 ViT 원 논문에서 B/16 대 B/32 비교는 단순한 하이퍼파라미터 탐색이 아니라, 비전 Transformer 설계에서 입력 토큰화가 독립된 핵심 축임을 알려 주는 결과다.
또 하나 흥미로운 지점은, 패치 크기의 차이가 작은 데이터와 큰 데이터에서 서로 다른 양상으로 나타난다는 점이다. 데이터가 작을 때는 작은 패치가 늘어난 표현력보다 과적합 위험과 계산 부담을 더 크게 만들 수 있지만, 데이터가 커질수록 더 풍부한 입력 세분성이 성능 향상으로 이어질 가능성이 커진다. 이는 ViT의 거의 모든 설계 선택이 결국 데이터 스케일과 결합해 해석되어야 한다는 점을 다시 강조한다. ViT를 고정된 구조로 보기보다, 데이터 규모에 따라 최적점이 달라지는 스케일링 가능한 패밀리로 이해해야 하는 이유가 여기에 있다.
| 모델 | 패치 크기 | ImageNet | ImageNet ReaL | CIFAR-100 | Flowers |
|---|---|---|---|---|---|
| ViT-B/32 | 32 | 80.73 | 86.27 | 90.49 | 99.27 |
| ViT-B/16 | 16 | 84.15 | 88.85 | 91.87 | 99.56 |
| ViT-L/32 | 32 | 84.37 | 88.28 | 92.52 | 99.45 |
| ViT-L/16 | 16 | 87.12 | 89.99 | 94.04 | 99.56 |
표에서 패치 크기 16의 이점은 매우 선명하다. 같은 모델 크기에서 더 조밀한 패치 분해가 거의 항상 더 좋은 결과를 준다. 물론 이는 계산량 증가를 전제로 한 성능 이득이지만, ViT가 단순히 더 큰 모델이어서 강한 것이 아니라 입력 세분화 수준을 적절히 선택했을 때 훨씬 더 나은 표현을 만든다는 사실을 보여준다.
4. 실험 설정: 데이터 규모와 전이 성능을 함께 보는 평가 프레임
4.1 데이터셋 및 벤치마크: ImageNet을 넘어 전이학습 전반으로 확장한 평가
ViT의 실험 설계에서 가장 중요한 점은 단일 벤치마크의 점수 경쟁이 아니라, 사전학습 규모와 전이 성능 사이의 관계를 명시적으로 본다는 것이다. 사전학습은 주로 ImageNet, ImageNet-21k, JFT-300M에서 수행되고, 이후 ImageNet, ImageNet ReaL, CIFAR-10, CIFAR-100, Oxford-IIIT Pets, Oxford Flowers-102, 그리고 VTAB로 전이 성능을 평가한다. 이는 모델이 단순히 ImageNet 라벨 분포에 맞춘 것이 아니라, 더 넓은 이미지 인식 태스크에서 얼마나 일반적인 표현을 형성하는지 확인하기 위한 구성이다.
특히 VTAB는 자연 이미지, 특수 도메인 이미지, 구조적 이해 태스크를 함께 담는 벤치마크로, 비전 백본의 전이 범용성을 보기 좋다. ViT는 이 평가에서 자연 태스크뿐 아니라 specialized, structured group까지 폭넓게 강한 성능을 보인다. 이 점은 매우 중요하다. Transformer의 전역적 패치 관계 학습이 단순 분류에만 유효한 것이 아니라, 도메인과 데이터 분포가 바뀌는 상황에서도 표현의 재활용성이 높다는 뜻이기 때문이다.
| 구분 | 주요 데이터셋 | 용도 | 비고 |
|---|---|---|---|
| 사전학습 | ImageNet | 기본 사전학습 | 상대적으로 작은 규모 |
| 사전학습 | ImageNet-21k | 대규모 레이블 사전학습 | 공개 대형 데이터셋 |
| 사전학습 | JFT-300M | 초대규모 사전학습 | ViT 강점이 가장 잘 드러나는 구간 |
| 전이 평가 | ImageNet / ImageNet ReaL | 대규모 일반 이미지 분류 | 대표 메인 벤치마크 |
| 전이 평가 | CIFAR-10 / CIFAR-100 | 중소형 이미지 분류 | 표현 일반화 확인 |
| 전이 평가 | Pets / Flowers / VTAB | 소규모 세분화된 전이 벤치마크 | 도메인 이동에 대한 강건성 평가 |
이 표를 보면 ViT의 검증 전략이 상당히 넓다는 사실을 알 수 있다. 같은 백본이 대규모 일반 이미지 분류, 소규모 세분화 분류, 다양한 도메인 전이까지 얼마나 일관되게 대응하는지를 측정하고 있기 때문이다. 따라서 ViT의 성과는 ImageNet 한 줄 점수보다, 사전학습 규모가 커질수록 여러 다운스트림 태스크에서 동시에 유리해지는 패턴으로 이해하는 편이 더 정확하다.
4.2 구현 세부사항: 배치 크기, warmup, 해상도, 미세조정 규칙
논문은 훈련 설정도 비교적 투명하게 공개한다. 사전학습은 기본적으로 batch size 4096, 10k step warmup을 사용하며, ImageNet에서는 global norm 1 수준의 gradient clipping이 추가로 유리했다고 보고한다. 기본 훈련 해상도는 224이며, 미세조정 단계에서는 해상도를 384로 높이는 구성이 자주 쓰인다. 이는 Transformer 계열이 사전학습 시에는 안정적이고 대규모인 설정을 유지하고, 다운스트림 적응에서는 더 높은 입력 해상도로 세밀함을 회복하는 일반적 패턴과 맞닿아 있다.
미세조정은 batch size 512, cosine learning rate decay, weight decay 없음, 그리고 마찬가지로 grad clipping 1을 사용한다. 데이터셋별로 step 수와 base learning rate grid를 따로 두는 점도 눈에 띈다. 예를 들어 ImageNet은 20,000 step, CIFAR 계열은 10,000 step, Pets와 Flowers는 500 step, VTAB은 2,500 step 정도로 설정된다. 이는 ViT가 강력한 사전학습 표현을 가질 때, 다운스트림에서는 모델 구조를 바꾸기보다 학습률과 적응 스텝을 조절하는 방식으로 충분한 성능을 끌어낼 수 있음을 보여준다.
| 단계 | 주요 설정 | 값 | 의미 |
|---|---|---|---|
| 사전학습 | Batch size | 4096 | 대규모 안정 학습 |
| 사전학습 | Warmup | 10k steps | 초기 최적화 안정화 |
| 사전학습 | 훈련 해상도 | 224 | 기본 입력 크기 |
| 미세조정 | Batch size | 512 | 다운스트림 적응 |
| 미세조정 | LR schedule | Cosine decay | 완만한 적응 |
| 공통 | Gradient clipping | Global norm 1 | 학습 안정성 유지 |
이 구현 세부사항은 ViT의 결과를 이해할 때 빠뜨리기 어렵다. 논문이 주장하는 성능 우위는 단순히 아키텍처 이름 하나에서 나오지 않고, 대규모 배치, 장시간 사전학습, 안정화된 최적화, 그리고 다운스트림별 미세조정 프로토콜이 결합된 결과다. 즉 ViT는 구조의 승리이면서 동시에, 대규모 사전학습 중심 워크플로우가 비전에서도 표준이 될 수 있음을 보여준 사례다.
4.3 베이스라인: ResNet, BiT, Noisy Student, Hybrid Transformer
ViT의 성능을 읽을 때 중요한 것은 비교군의 강도다. 논문은 단순한 얕은 CNN이 아니라 당시 강력한 BiT-L 계열, Noisy Student 기반 EfficientNet-L2, 그리고 여러 크기의 ResNet을 함께 놓는다. 이 비교는 매우 엄격하다. 왜냐하면 ViT가 이겨야 할 대상이 단순한 과거 모델이 아니라, 이미 대규모 사전학습과 강한 최적화로 다듬어진 현대적인 CNN 계열이기 때문이다.
또한 저자들은 ResNet50x1, ResNet50x2, ResNet101x1, ResNet152x1, ResNet152x2, ResNet152x4처럼 다양한 스케일의 CNN을 포함하고, 일부는 Adam과 SGD 차이까지 확인한다. 이는 ViT의 우위가 특정 최적화기 선택 때문인지, 혹은 구조 자체의 특성 때문인지를 분리하기 위한 장치다. 후술하겠지만 결과는 대체로 데이터가 작을수록 CNN이 강하고, 데이터가 커질수록 ViT가 더 빠르게 상승하는 형태를 보인다.
| 비교축 | 대표 모델 | 비교 목적 |
|---|---|---|
| 표준 CNN | ResNet50/101/152 계열 | 전통적 귀납편향과의 비교 |
| 대형 CNN | BiT-L, ResNet152x4 | 대규모 사전학습 CNN과의 비교 |
| 고성능 비전 시스템 | EfficientNet-L2 (Noisy Student) | 당시 SOTA 분류기와의 정면 비교 |
| 절충형 구조 | R50+ViT hybrids | CNN stem이 필요한지 확인 |
이 비교군 구성은 ViT의 결과를 더 설득력 있게 만든다. 순수 Transformer가 성공한 이유가 비교 대상이 약해서가 아니라, 오히려 이미 매우 강한 CNN 파이프라인을 상대로도 대규모 사전학습 조건에서 우위를 만들었기 때문이다. 논문의 메시지가 "새롭다"를 넘어 "실제로 바꿀 가치가 있다"로 읽히는 이유가 바로 여기에 있다.
5. 주요 실험 결과: 데이터가 커질수록 순수 Transformer의 강점이 드러난다
5.1 주요 벤치마크 결과: JFT-300M 사전학습 조건에서 CNN을 넘어선 전이 성능
논문의 핵심 결과는 JFT-300M 사전학습 구간에서 가장 선명하게 나타난다. 대표적으로 ViT-H/14는 ImageNet에서 88.55±0.04, ImageNet ReaL에서 90.72±0.05, CIFAR-10에서 99.50±0.06, CIFAR-100에서 94.55±0.04, Oxford-IIIT Pets에서 97.56±0.03, Flowers에서 99.71±0.02 수준의 성능을 기록한다. 이는 당시 강한 CNN 기준선과 비교해도 매우 경쟁력 있는 결과이며, 단일 데이터셋이 아니라 여러 전이 벤치마크에서 일관되게 높다는 점이 중요하다.
같은 축에서 ViT-L/16도 강하다. JFT-300M 사전학습 시 ImageNet 87.76±0.03, ImageNet ReaL 90.54±0.03, CIFAR-100 93.90±0.05 수준을 기록하며, 공개 데이터 중심의 ImageNet-21k 사전학습만으로도 ImageNet 85.30±0.02를 달성한다. 이는 ViT의 우위가 JFT-300M 같은 초대규모 사설 데이터셋에만 의존하는지에 대한 질문에 부분적인 답을 준다. 물론 데이터 규모가 클수록 더 강해지는 것은 사실이지만, 공개 대형 데이터만으로도 이미 상당한 경쟁력을 확보할 수 있다는 점이 확인된다.
비교표를 읽을 때 흥미로운 점은 ViT가 단순히 최고 정확도만 노리는 모델이 아니라는 점이다. 저자들은 ViT가 사전학습 자원 대비 성능에서도 유리하다고 보고한다. 즉 더 적은 계산 예산으로 같은 수준의 전이 성능을 내거나, 같은 예산에서 더 높은 정확도를 얻는 패턴이 나타난다. 이 결과는 비전에서 Transformer가 실용적이지 않을 것이라는 당시의 회의론에 직접 반박하는 역할을 한다.
| 모델 | 사전학습 데이터 | ImageNet | ImageNet ReaL | CIFAR-100 | Pets | Flowers |
|---|---|---|---|---|---|---|
| ViT-H/14 | JFT-300M | 88.55±0.04 | 90.72±0.05 | 94.55±0.04 | 97.56±0.03 | 99.71±0.02 |
| ViT-L/16 | JFT-300M | 87.76±0.03 | 90.54±0.03 | 93.90±0.05 | 97.32±0.11 | 99.65±0.08 |
| ViT-L/16 | ImageNet-21k | 85.30±0.02 | 88.62±0.05 | 93.25±0.05 | 94.67±0.15 | 99.59±0.05 |
| BiT-L (ResNet152x4) | JFT-300M | 87.54±0.02 | 90.54 | 93.51±0.08 | 96.62±0.18 | 99.63±0.02 |
표의 해석은 간단하지만 함의는 크다. 첫째, 대규모 사전학습 조건에서 ViT는 강한 CNN 기준선과 대등하거나 이를 넘는다. 둘째, 그 우위는 ImageNet 단일 점수에만 머물지 않고 여러 전이 벤치마크에서 동시에 나타난다. 셋째, 공개 데이터 기반 ImageNet-21k 사전학습만으로도 상당한 경쟁력이 확보되어, ViT의 성공이 초거대 비공개 데이터셋에만 묶인 현상은 아니라는 점이 드러난다.
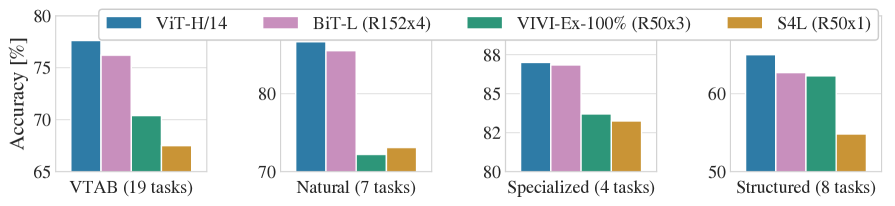
Figure 2: VTAB의 Natural, Specialized, Structured 세 그룹에서 본 ViT 전이 성능 분해
Figure 2는 ViT의 장점이 특정 이미지 분류 데이터셋 하나에 국한되지 않음을 보여준다. 자연 이미지뿐 아니라 도메인 특수성이 큰 specialized 태스크, 구조적 이해가 필요한 structured 태스크에서도 경쟁력 있는 점수가 확인된다. 이는 패치 기반 self-attention이 단순히 질감 분류기에 머물지 않고, 서로 다른 시각 영역 사이의 관계를 범용 표현으로 조직한다는 논문의 주장을 뒷받침한다.
5.2 스케일링 결과: 데이터가 커질수록 ViT가 CNN을 추월하는 방식
ViT 논문의 진짜 핵심은 최고 점수보다 스케일링 곡선에 있다. 저자들은 사전학습 데이터가 작을 때는 대형 ViT가 BiT 계열 ResNet보다 오히려 불리할 수 있음을 숨기지 않는다. 하지만 데이터 규모가 커질수록 상황은 빠르게 바뀐다. 큰 ViT는 작은 데이터에선 귀납편향 부족 때문에 불리하지만, 큰 데이터에서는 그 유연한 표현 공간이 더 높은 상한을 제공한다. 이는 비전 아키텍처 비교를 "누가 항상 더 강한가"가 아니라 "데이터 스케일에 따라 누가 더 빠르게 좋아지는가"로 바꾸는 중요한 관찰이다.
이 관점은 이후 비전 연구 전체에 큰 영향을 미쳤다. CNN이 지배적이던 시절에는 구조적 priors를 얼마나 잘 설계하느냐가 중요했다면, ViT 이후에는 충분한 데이터와 계산이 있을 때 더 일반적인 구조가 더 큰 보상을 줄 수 있다는 사실이 명확해졌다. 즉, 성능 격차는 단순한 architecture leaderboard가 아니라, 데이터-모델-연산의 조합에 의해 달라진다. 오늘날 거대 비전 모델이나 멀티모달 모델이 Transformer 계열을 기본으로 쓰는 이유도 이 스케일링 통찰과 분리하기 어렵다.
저자들은 few-shot 선형평가에서도 유사한 패턴을 보인다. 작은 사전학습 데이터셋에선 ResNet이 더 빨리 성능을 얻지만, 사전학습 데이터가 커질수록 ViT가 더 높게 포화한다. 이는 Transformer가 표현의 초기 형성에는 더 많은 데이터가 필요하지만, 충분한 데이터가 주어지면 더 강한 전이 표현을 만든다는 뜻이다. 다시 말해 ViT의 약점은 작은 데이터 효율이고, 강점은 대규모 사전학습 시대의 확장성이다.
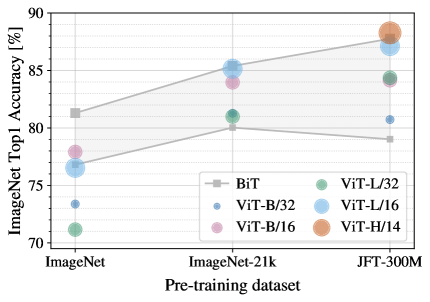
Figure 3: 사전학습 데이터 규모가 증가할수록 ViT와 CNN의 전이 성능 관계가 어떻게 바뀌는지 보여주는 그래프
Figure 3은 ViT 논문의 가장 중요한 메시지 중 하나를 시각적으로 압축한다. 작은 사전학습 구간에서는 CNN 계열이 더 강하지만, 데이터 규모가 커질수록 큰 ViT 변형이 오히려 더 높은 성능으로 올라선다. 이는 Transformer의 약한 귀납편향이 항상 약점인 것이 아니라, 데이터가 충분할 때는 더 높은 표현 상한으로 전환될 수 있음을 보여준다.
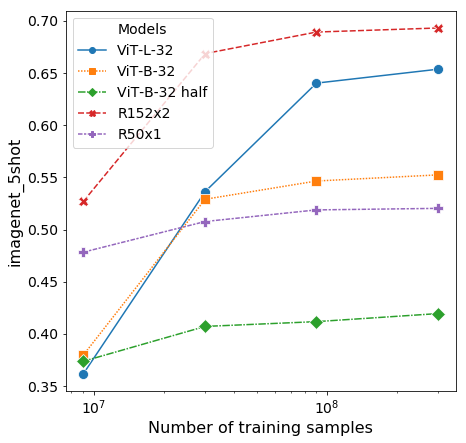
Figure 4: 사전학습 규모에 따른 ImageNet few-shot 선형평가 결과
Figure 4는 선형 few-shot 평가에서도 같은 경향이 반복됨을 보여준다. 적은 사전학습 데이터에선 ResNet이 더 빠르게 좋은 표현을 형성하지만, 더 큰 데이터로 갈수록 ViT의 성장 폭이 더 크고 포화점도 높다. 이는 ViT가 단순히 미세조정에만 의존하는 것이 아니라, 사전학습 표현 자체의 질이 데이터 스케일과 함께 크게 향상된다는 점을 시사한다.
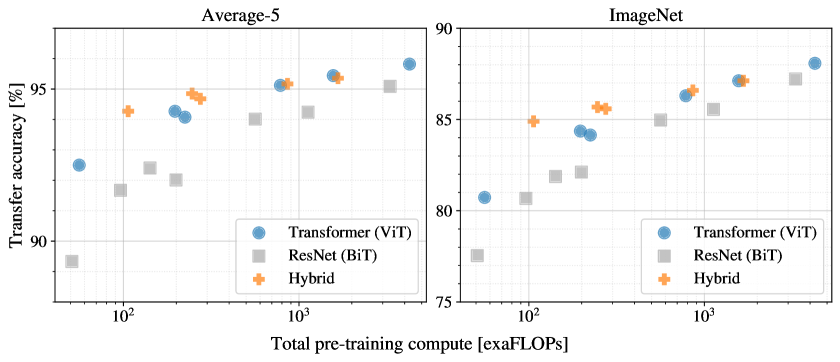
Figure 5: 같은 사전학습 연산량 기준에서 ViT, ResNet, hybrid 구조의 정확도-연산 비교
Figure 5는 구조 비교를 정확도만이 아니라 pre-training compute 축으로 옮긴다. 여기서 ViT는 동일 계산 예산에서 대체로 ResNet보다 더 좋은 위치를 차지하고, 작은 모델 크기에서는 hybrid가 유리할 수 있지만 큰 모델에선 순수 ViT와의 차이가 줄어든다. 이 결과는 ViT가 단지 최고 성능을 위해 비싼 연산을 더 태운 모델이 아니라, 연산 예산 대비 효율성에서도 의미 있는 선택지가 될 수 있음을 보여준다.
| 모델 | 학습 epoch | ImageNet | CIFAR-100 | Flowers | Pre-train compute (exaFLOPs) |
|---|---|---|---|---|---|
| ViT-B/32 | 7 | 80.73 | 90.49 | 99.27 | 55 |
| ViT-B/16 | 7 | 84.15 | 91.87 | 99.56 | 224 |
| ViT-L/16 | 14 | 87.12 | 94.04 | 99.56 | 1567 |
| ViT-H/14 | 14 | 88.08 | 94.71 | 99.71 | 4262 |
| ResNet152x2 | 7 | 84.97 | 92.05 | 98.62 | 563 |
이 표는 계산량과 정확도를 함께 볼 때 ViT가 어떤 위치를 차지하는지 요약한다. 가장 큰 ViT는 물론 연산량도 크지만, 같은 계산 예산 축에서 더 큰 정확도 상승을 만들어 내며, 작은 ViT 변형도 상당히 경쟁력 있는 성능을 보인다. 따라서 논문의 메시지는 단순히 "Transformer가 CNN보다 좋다"가 아니라, 충분한 사전학습 자원이 있을 때 Transformer의 성장 기울기가 더 가파르다는 쪽에 가깝다.
5.3 같은 정확도, 다른 계산 구조: ViT와 CNN의 효율을 어떻게 읽어야 하는가
ViT의 결과를 읽을 때 자주 생기는 오해는, 가장 큰 ViT 모델이 매우 비싼 연산을 사용하므로 구조 자체가 효율적이라고 말하기 어렵다는 주장이다. 그러나 논문이 강조하는 지점은 절대 연산량이 아니라 성능이 개선되는 방식이다. CNN은 초기 구간에서 강하고 작은 데이터에서도 빠르게 좋은 성능을 내지만, 일정 규모 이상에서는 더 큰 모델과 더 많은 데이터가 주어져도 상승 폭이 완만해지는 경향이 있다. 반면 ViT는 작은 데이터에선 불리해도, 데이터와 모델 규모가 커질수록 더 꾸준하게 올라간다. 효율성은 단일 지점의 FLOPs가 아니라, 확장했을 때 얻는 추가 성능의 기울기까지 포함해 읽어야 한다.
또한 논문은 연산뿐 아니라 메모리 사용과 구현 단순성 측면에서도 ViT의 장점을 시사한다. 표준 Transformer encoder 블록은 대규모 행렬 연산 중심이라 현대 가속기와 잘 맞고, 복잡한 stage별 설계나 다양한 커널 크기 조합 없이도 구조를 반복적으로 확장할 수 있다. 이는 곧 엔지니어링 복잡성 감소로 이어진다. CNN 계열은 세밀한 구조 설계가 성능에 큰 영향을 미치기 때문에 backbone을 바꿀 때마다 수많은 세부 결정이 필요하지만, ViT는 상대적으로 더 단순한 설계 축으로 성능 개선을 추적할 수 있다.
이 차이는 대규모 연구 환경에서 특히 중요하다. foundation model 시대의 핵심은 아키텍처를 수십 번 손으로 조정하는 것보다, 큰 데이터와 긴 학습을 일관된 구조 위에 얹을 수 있는가에 가깝다. ViT는 바로 그런 시대적 요구에 맞는 백본이었다. 후속 연구들이 비전뿐 아니라 음성, 비디오, 멀티모달 문제까지 Transformer 계열을 기본으로 삼게 된 것도, 구조의 범용성과 확장 편의성 덕분이다. 따라서 ViT의 효율은 per-step 계산량 하나가 아니라, 대규모 학습 체계에 얼마나 잘 맞는가라는 더 큰 맥락 안에서 봐야 한다.
논문 부록의 timing과 memory 분석 역시 이 맥락을 보완한다. ViT는 입력 크기에 따라 속도와 메모리 특성이 달라지지만, 유사한 정확도 구간에서 비교할 때 충분히 경쟁력 있는 프로파일을 보인다. 특히 단일 구조를 단순 반복하는 방식이기 때문에, 병렬 처리와 하드웨어 최적화 여지가 크다. 이후 FlashAttention, fused MLP, tensor parallelism, sequence parallelism 같은 최적화가 전부 Transformer 계열 위에서 빠르게 발전한 사실을 떠올리면, ViT가 선택한 연산 문법의 장기적 가치가 더 잘 드러난다.
| 비교 관점 | CNN 계열 해석 | ViT 계열 해석 |
|---|---|---|
| 작은 데이터 효율 | 강한 귀납편향으로 유리 | 초기엔 불리할 수 있음 |
| 대규모 사전학습 확장성 | 상승 폭이 점차 완만 | 데이터와 모델이 커질수록 강점 확대 |
| 구조 설계 복잡성 | stage, kernel, width 조합 최적화 필요 | 반복 블록 중심이라 단순 |
| 멀티모달 확장성 | 추가 인터페이스 설계 필요 | 토큰 기반 표현이라 결합이 쉬움 |
이 표는 ViT와 CNN을 단순한 승패 구도로 읽지 말아야 한다는 점을 정리한다. CNN은 작은 데이터와 강한 priors가 필요한 구간에서 여전히 강력하고, ViT는 대규모 사전학습과 범용 백본이라는 조건에서 더 큰 잠재력을 가진다. 그래서 ViT 논문이 남긴 가장 중요한 교훈은 어느 한 구조의 완전한 종말이 아니라, 문제 설정이 바뀌면 좋은 귀납편향의 형태도 바뀐다는 사실이다.
6. 추가 분석 및 Ablation Study: 패치 표현, 위치 임베딩, attention이 실제로 무엇을 학습하는가
6.1 attention 시각화와 표현 분석: 패치 기반 전역 관계가 어떻게 나타나는가
ViT의 설계가 설득력을 가지려면 단순히 정확도만 높은 것이 아니라, 패치 기반 self-attention이 실제로 의미 있는 시각 구조를 형성한다는 정성적 증거도 필요하다. 논문은 이를 위해 출력 class token이 입력 공간의 어느 영역에 주의를 두는지, 초기 패치 임베딩 필터가 어떤 모양을 띠는지, 위치 임베딩이 공간적으로 어떤 유사성 구조를 보이는지, 각 head가 얼마나 넓은 영역을 보는지 등을 시각화한다. 이런 분석은 ViT가 지역 정보를 완전히 잃어버린 무작위 토큰 모델이 아니라, 학습 과정에서 스스로 공간적 조직을 형성한다는 점을 보여주는 보조 근거다.
특히 대표 attention map을 보면, class token이 객체의 의미 있는 부분이나 윤곽, 배경 대비가 큰 영역으로 주의를 집중하는 경향이 관찰된다. 이는 패치 토큰들이 단순한 픽셀 블록이 아니라, 분류에 필요한 구조적 정보를 담는 중간 표현으로 기능하고 있음을 뜻한다. 물론 이 시각화만으로 "ViT가 CNN처럼 국소 구조를 학습한다"고 단정할 수는 없지만, 최소한 attention이 의미 없는 전역 평균에 머물지 않고, 입력 공간에서 선택적 집계를 수행한다는 사실은 확인된다.
또한 논문은 위치 임베딩의 코사인 유사도와 head별 평균 attention distance를 분석해, 일부 head는 국소적 관계를, 일부 head는 더 넓은 전역 관계를 담당하는 경향을 보여준다. 이 점은 중요하다. CNN은 국소성이라는 priors를 고정적으로 넣지만, ViT는 다양한 거리 스케일의 상호작용을 head specialization 형태로 학습적으로 얻는다. 따라서 ViT의 표현력은 단순히 전역 attention 하나가 아니라, 서로 다른 receptive field를 학습적으로 분화시키는 다중 헤드 구조에서 나온다고 해석할 수 있다.

Figure 6: 출력 토큰이 입력 이미지 공간 어디에 주목하는지를 보여주는 attention 예시
Figure 6은 ViT의 class token이 입력 전체를 균일하게 보지 않고, 객체의 의미 있는 부분에 가중치를 두는 패턴을 보여준다. 이는 patch sequence 기반 구조가 분류에 필요한 시각적 근거를 전역 attention으로 선택해 집계할 수 있음을 시사한다. 즉 ViT의 전역성은 무차별적 평균화가 아니라, task-relevant region을 찾아가는 선택적 집계로 작동한다.

Figure 7: ViT-L/32의 초기 패치 임베딩 필터 시각화
Figure 7의 왼쪽 패널은 패치 임베딩 층이 학습한 초기 필터들을 보여준다. 이는 순수 Transformer라고 해서 저수준 시각 구조를 전혀 잡지 못하는 것이 아니라, 선형 패치 투영 단계에서도 색 대비와 간단한 공간 주파수 패턴을 포착할 수 있음을 보여준다. CNN의 커널처럼 명시적 지역 연산을 반복하지 않더라도, 입력 투영 자체가 유의미한 시각 분해를 일부 수행한다는 점이 확인된다.
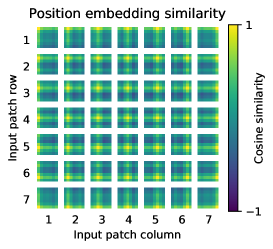
Figure 8: 위치 임베딩의 공간적 유사도 구조
Figure 8은 위치 임베딩이 단순한 인덱스 부호가 아니라, 주변 패치와의 상대적 관계를 어느 정도 반영하는 매끄러운 공간 구조를 학습한다는 점을 보여준다. 이는 2차원 격자라는 비전의 기본 구조가 별도의 convolution 없이도 position embedding과 self-attention 조합 안에서 부분적으로 복원될 수 있음을 의미한다. 다시 말해 ViT는 비전 priors를 완전히 버린 것이 아니라, 더 약한 형태로 학습적으로 재구성한다고 해석할 수 있다.
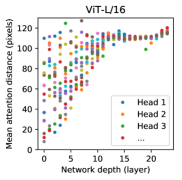
Figure 9: 네트워크 깊이와 head에 따른 평균 attention 거리
Figure 9는 일부 head가 짧은 거리의 국소 관계를, 일부는 먼 거리의 전역 관계를 더 강하게 본다는 사실을 보여준다. 이는 ViT 내부에서 receptive field가 단일한 방식으로 고정되지 않고, 헤드와 층에 따라 서로 다른 상호작용 범위가 형성된다는 뜻이다. CNN이 설계 차원에서 다중 스케일을 구현한다면, ViT는 학습된 attention 패턴 안에서 다중 스케일 관계를 분화시킨다는 차이가 있다.
6.2 Ablation 결과: 모델 크기, 위치 임베딩, 최적화 선택의 영향
논문은 다양한 ablation을 통해 ViT의 성능이 단순한 우연이 아니라는 점을 보인다. 먼저 모델 크기 측면에서, 더 깊고 넓은 모델일수록 사전학습 perplexity에 대응하는 표현 품질이 좋아지고 다운스트림 정확도도 상승한다. 예를 들어 레이어 수와 hidden size, head 수를 키워 갈수록 MNLI와 같은 언어 태스크가 아니라 비전 전이 태스크에서도 성능이 꾸준히 향상되는 구조적 패턴이 나타난다. 이는 Transformer 스케일링의 일반 성질이 비전에서도 재현된다는 뜻이다.
위치 임베딩 관련 ablation도 흥미롭다. 논문은 1-D positional embedding, 2-D positional embedding, relative positional embedding 등을 비교한 결과, 극적인 차이보다는 적절한 위치 부호가 있다는 사실 자체가 중요하다고 보고한다. 이는 ViT의 성능이 특정 positional encoding 기법 하나에만 매달리지 않음을 의미한다. 동시에 완전히 위치 정보를 제거하면 성능이 크게 떨어지므로, 패치 시퀀스화가 가능하더라도 2차원 공간 정보를 어떤 형태로든 모델에 제공해야 한다는 점도 분명해진다.
또한 ResNet을 Adam과 SGD로 각각 사전학습해 비교한 결과는, ViT의 우위가 단순히 최적화기 선택 때문이 아님을 보여준다. CNN도 더 나은 최적화로 개선될 수 있지만, 대규모 사전학습과 전이 설정 전체를 놓고 보면 구조적 차이가 더 큰 영향을 미친다는 것이다. 따라서 ViT 논문은 optimization trick보다 architecture-data scaling law에 더 가까운 메시지를 전달한다.
| 모델 설정 | ImageNet | ImageNet ReaL | CIFAR-10 | CIFAR-100 | exaFLOPs |
|---|---|---|---|---|---|
| ViT-B/16 | 84.15 | 88.85 | 99.00 | 91.87 | 224 |
| ViT-L/16 | 87.12 | 89.99 | 99.38 | 94.04 | 1567 |
| ViT-H/14 | 88.08 | 90.36 | 99.50 | 94.71 | 4262 |
이 표는 ViT 내부의 스케일링이 거의 교과서적인 형태를 보인다는 점을 다시 확인해 준다. 더 큰 모델일수록 연산량이 급증하지만, 동시에 여러 전이 벤치마크에서 꾸준한 향상이 나타난다. 이는 이후 비전 백본 설계가 효율 구간용 소형 모델과 초대규모 사전학습용 대형 모델로 분화되는 배경을 잘 설명한다.
| Positional Embedding 방식 | Default/Stem | Every Layer | Every Layer-Shared |
|---|---|---|---|
| No positional embedding | 0.61382 | N/A | N/A |
| 1-D positional embedding | 0.64206 | 0.63964 | 0.64292 |
| 2-D positional embedding | 0.64001 | 0.64046 | 0.64022 |
| Relative positional embedding | 0.64032 | N/A | N/A |
위치 임베딩 ablation은 극적인 승패를 가르는 요인이 무엇인지보다, 어떤 요소가 반드시 필요한지 보여준다. 완전히 위치 정보를 제거하면 성능이 크게 나빠지고, 여러 positional embedding 변형은 서로 비슷한 수준에서 동작한다. 따라서 ViT의 성공은 특정 위치 부호 공식 하나보다는, 패치 순서를 유지한 채 전역 attention이 공간 구조를 재조립할 수 있게 해 주는 설계 전체에서 나온다고 해석하는 편이 적절하다.
6.3 공개 데이터셋만으로도 충분한가: ImageNet-21k와 JFT-300M의 차이
ViT 논문을 읽을 때 빠지기 쉬운 오해는 "결국 JFT-300M이 있었기 때문에 성공한 것 아닌가"라는 식의 단순한 결론이다. 물론 초대규모 데이터가 ViT의 강점을 가장 크게 드러내는 것은 사실이다. 하지만 논문은 ImageNet-21k만으로도 상당한 경쟁력을 보인다는 점을 함께 보여 준다. 예를 들어 ViT-L/16은 ImageNet-21k 사전학습만으로도 ImageNet 85.30 수준에 도달하고, 여러 전이 벤치마크에서 상당히 강한 수치를 유지한다. 즉 ViT의 메시지는 비공개 초대규모 데이터가 없으면 쓸 수 없다는 것이 아니라, 데이터가 커질수록 상대적 이점이 더 커진다는 쪽이다.
이 차이를 더 정확히 해석하면, ViT는 공개 대형 데이터만으로도 이미 유효한 기본 백본이 될 수 있지만, 초대규모 데이터에서 더 높은 상한을 보여 준다고 말하는 편이 맞다. 이는 이후 공개 커뮤니티에서도 매우 중요한 의미를 가졌다. 왜냐하면 곧바로 수억 장 규모의 비공개 데이터를 재현할 수는 없어도, 더 나은 증강, 더 긴 학습, 더 강한 정규화, 그리고 지식 증류를 결합하면 공개 데이터 기반 ViT도 충분히 실용적이라는 방향이 열렸기 때문이다. 실제로 DeiT와 후속 계열은 이 지점을 정면으로 파고들었다.
또한 JFT-300M 대 ImageNet-21k 비교는 비전에서 사전학습 데이터의 품질과 범위가 얼마나 중요한지 보여 준다. JFT-300M은 훨씬 더 넓은 시각 분포와 더 많은 예시를 제공하므로, ViT처럼 귀납편향이 약한 구조는 여기서 더 큰 이익을 얻는다. 반대로 CNN은 구조 자체의 prior가 강하기 때문에 상대적으로 작은 데이터에서도 견딜 수 있다. 이 차이는 단순한 성능 차이를 넘어, 아키텍처와 데이터 규모가 서로 보완 관계에 있음을 의미한다. ViT의 성공은 Transformer가 무조건 superior하다는 증거라기보다, 약한 priors와 큰 데이터가 잘 맞물렸을 때 얻어지는 결과라고 보는 편이 더 정확하다.
| 모델 | 사전학습 데이터 | CIFAR-10 | CIFAR-100 | ImageNet | Pets |
|---|---|---|---|---|---|
| ViT-B/16 | ImageNet | 98.13 | 87.13 | 77.91 | 93.81 |
| ViT-B/16 | ImageNet-21k | 98.95 | 91.67 | 83.97 | 94.43 |
| ViT-B/16 | JFT-300M | 99.00 | 91.87 | 84.15 | 95.80 |
이 표는 같은 모델이라도 사전학습 데이터 규모가 커질수록 전이 성능이 얼마나 안정적으로 개선되는지 보여 준다. 특히 CIFAR와 Pets 같은 상대적으로 작은 다운스트림 데이터에서도 사전학습 규모의 효과가 분명하게 남는다는 점이 중요하다. 이는 ViT가 전형적인 대규모 사전학습 백본처럼 행동하며, 학습 초기의 데이터 부족을 충분한 사전학습으로 보완할 수 있음을 시사한다.
6.4 왜 이 논문이 후속 연구를 낳았는가: 구조적 질문의 이동
ViT가 큰 영향을 남긴 이유는 한두 개 숫자가 아니라, 후속 연구가 따라갈 수 있는 명확한 질문을 남겼기 때문이다. 예를 들어 작은 데이터에서도 ViT를 강하게 만들려면 무엇이 필요한가, 고해상도 입력에서 self-attention 비용을 낮추려면 어떤 계층 구조가 필요한가, patch token 대신 더 나은 토큰화를 만들 수 있는가, class token 대신 다른 집계 방식이 가능한가 같은 질문이 모두 이 논문에서 직접 이어진다. 즉 ViT는 완성형이라기보다, 이후 연구자들이 세부 설계 축을 체계적으로 탐색할 수 있는 출발점을 제공한 논문이다.
또한 멀티모달 확장성 측면에서도 ViT는 매우 중요한 전환점이다. 이미지를 패치 토큰으로 표현하면, 텍스트 토큰과 동일한 Transformer 공간 안에서 처리하기가 훨씬 쉬워진다. 이는 이후 image-text contrastive learning, multimodal decoder, vision-language instruction tuning 같은 흐름이 빠르게 자리 잡는 토대가 되었다. 다시 말해 ViT는 비전 분야 내부의 논문이면서도, 장기적으로는 멀티모달 foundation model 시대의 핵심 연결고리 역할을 했다.
이런 관점에서 보면 ViT의 핵심 공헌은 두 가지로 압축된다. 첫째, CNN이 사실상 유일한 기본값이던 비전 표현 학습에 대체 가능한 공용 연산 문법을 제시했다. 둘째, 비전도 언어처럼 대규모 사전학습과 전이학습의 스케일 법칙 안에서 이해할 수 있음을 보여 주었다. 그래서 ViT는 단순히 "Transformer for vision"이 아니라, 비전 연구의 조직 원리를 바꾼 논문으로 남는다.
7. 한계점 및 향후 연구 방향: 작은 데이터 효율성과 계산 구조의 문제
ViT는 매우 영향력 있는 논문이지만, 본문이 스스로 드러내는 한계도 분명하다. 첫째는 데이터 효율성이다. 논문이 반복해서 보여주듯, 작은 사전학습 데이터셋에서는 ViT가 CNN보다 불리한 경우가 많다. 이는 순수 Transformer가 비전에서 강한 사전 priors 없이 출발하기 때문에, 같은 수준의 일반화를 얻기 위해 더 많은 학습 신호를 필요로 한다는 뜻이다. 후속 연구들이 DeiT처럼 증류와 강한 데이터 증강을 결합해 소규모 데이터에서도 ViT를 강하게 만들려 한 배경이 바로 여기에 있다.
둘째는 계산 구조다. ViT는 패치 길이에 대해 self-attention 비용이 대략 제곱으로 증가하므로, 고해상도 입력이나 더 세밀한 패치 분할에 곧바로 확장하기 어렵다. 논문 시점에서는 분류 중심 입력 해상도와 패치 크기 조합으로 충분히 실용적이었지만, detection, segmentation, high-resolution dense prediction으로 갈수록 이 제약은 더 크게 드러난다. 이후 Swin Transformer, window attention, hierarchical vision transformer가 등장한 것은, ViT의 기본 철학을 유지하면서도 고해상도에서의 연산 비용을 다루려는 시도라고 볼 수 있다.
셋째는 해석상의 범위다. ViT는 이미지 분류와 전이학습에서 강력한 결과를 보여 주지만, 그것이 곧바로 모든 비전 태스크에서 동일한 우위를 보장하는 것은 아니다. 특히 물체 검출, 세분화, 비디오 이해처럼 공간적 또는 시간적 구조를 더 직접적으로 다뤄야 하는 문제에서는 입력 표현과 attention 범위, 계층 구조를 추가로 설계할 필요가 있다. 그럼에도 이 논문의 가치는 줄어들지 않는다. 오히려 ViT는 "순수 Transformer도 비전 백본이 될 수 있다"는 사실을 먼저 입증했기 때문에, 이후의 모든 변형 연구가 출발할 수 있었다.
향후 연구 방향도 자연스럽다. 하나는 더 나은 데이터 효율을 얻기 위한 self-supervised pretraining과 distillation, aug-reg 전략이다. 다른 하나는 고해상도 입력에 적합한 hierarchical tokenization과 sparse attention 계열의 발전이다. 또 하나는 비전만이 아니라 텍스트, 오디오, 비디오와 결합되는 multimodal transformer로의 확장이다. 실제로 이후 CLIP, Flamingo, PaLI, GPT-4V 같은 계열은 모두 이미지나 비디오를 패치 또는 토큰 시퀀스로 표현하고 Transformer 기반 공통 공간 안에서 결합하는 흐름을 택한다.
7.1 작은 데이터 구간에서 왜 CNN이 여전히 강한가
ViT가 작은 데이터에서 약한 이유를 단순히 "학습이 덜 됐기 때문"으로 보면 부족하다. 더 본질적인 이유는 CNN이 비전 문제에 대해 이미 강한 사전 구조를 품고 있기 때문이다. 합성곱 커널은 지역성, 평행이동 불변성, 다중 스케일 피라미드 형성이라는 세 가지 성질을 거의 공짜에 가깝게 제공한다. 이런 구조는 데이터가 적을 때 특히 큰 힘을 발휘한다. 모델이 모든 관계를 처음부터 학습해야 하는 대신, 처음부터 어느 정도 타당한 편향을 가진 채 출발하기 때문이다.
반면 ViT는 패치 시퀀스와 position embedding만으로 시작하므로, 국소 구조를 어떻게 묶어야 하는지부터 학습적으로 알아내야 한다. 이 과정은 충분히 큰 데이터가 있을 때는 유연성과 높은 표현 상한으로 이어지지만, 데이터가 작을 때는 샘플 효율 측면에서 손해로 돌아오기 쉽다. 그래서 ViT 이후의 중요한 연구 과제 중 하나가 바로 "작은 데이터에서도 Transformer를 강하게 만드는 법"이었다. 증류, 강한 증강, mixup, cutmix, stochastic depth, repeated augmentation 같은 전략이 비전 Transformer와 특히 자주 결합된 이유가 여기에 있다.
이 해석은 실전에서도 중요하다. 모든 환경이 JFT-300M 수준의 대규모 사전학습을 할 수 있는 것은 아니기 때문이다. 데이터 수집 비용이 높거나, 도메인이 좁거나, 레이블이 제한된 환경에서는 CNN 계열이 여전히 더 나은 비용 대비 성능을 낼 수 있다. 따라서 ViT를 읽을 때는 Transformer가 언제나 정답이라는 결론보다, 데이터 규모와 목표 태스크에 따라 적절한 귀납편향의 세기가 달라진다는 교훈을 얻는 편이 더 정확하다.
7.2 고해상도 비전 태스크에서 남는 과제
이미지 분류에서는 패치 수가 상대적으로 제한되므로 self-attention 비용이 감당 가능하지만, 검출과 세분화처럼 더 높은 해상도와 더 촘촘한 공간 출력을 요구하는 태스크에서는 상황이 달라진다. 입력 토큰 수가 조금만 늘어나도 attention 비용이 빠르게 폭증하고, 각 위치에 대한 세밀한 예측까지 요구되면 단순 class token 집계 구조로는 충분하지 않다. ViT 원 논문은 이 문제를 직접 해결하지는 않지만, 오히려 이후 연구에 매우 명확한 출발점을 제공한다. 어떤 형태로든 hierarchical representation과 local attention을 도입해야 한다는 사실이 더 또렷해진 것이다.
실제로 후속 계열은 여러 방향으로 갈라진다. 어떤 연구는 윈도우 기반 attention으로 계산량을 줄였고, 어떤 연구는 피라미드 구조를 도입해 CNN과 유사한 해상도 감소 경로를 다시 만들었다. 또 어떤 연구는 convolution stem을 부분적으로 되살리거나, relative position bias를 정교하게 넣어 고해상도 시각 구조를 더 쉽게 학습하게 했다. 이 흐름을 보면 ViT는 완결된 답이라기보다, 순수 Transformer가 어디까지 통하고 어디서 보완이 필요한지를 드러낸 기준선 역할을 한다고 말할 수 있다.
비디오로 확장할 때도 문제는 더 커진다. 패치 토큰에 시간축까지 추가되면 시퀀스 길이가 훨씬 길어지고, 공간-시간 attention 비용은 빠르게 감당하기 어려운 수준으로 증가한다. 그럼에도 멀티모달과 비디오 연구가 결국 Transformer 계열을 중심으로 발전한 이유는, ViT가 적어도 이미지 축에서는 순수 attention 기반 백본이 충분히 가능하다는 신뢰를 먼저 제공했기 때문이다. 이후 비디오 Transformer와 vision-language model 연구는 이 신뢰 위에서 시간축 압축, 프레임 샘플링, latent bottleneck 같은 보완책을 더했다.
7.3 향후 연구 방향: self-supervision, 멀티모달, 그리고 범용 백본
ViT 이후 가장 자연스럽게 열린 방향은 self-supervised learning이다. 만약 ViT의 약점이 데이터 효율이라면, 라벨 비용이 높은 비전 영역에서 가장 강력한 해법은 더 큰 레이블 데이터셋이 아니라 더 좋은 자기지도학습 전략일 수 있다. 실제로 MAE, DINO, iBOT 계열은 ViT 백본과 결합되며 이미지 마스킹, student-teacher distillation, contrastive learning을 통해 라벨 효율 문제를 크게 완화했다. 이는 ViT가 대규모 레이블 사전학습에만 의존하는 구조가 아니라, 자기지도학습과 매우 잘 맞는 일반 백본이라는 사실을 보여 준다.
둘째 방향은 멀티모달 통합이다. 패치 토큰은 텍스트 토큰과 구조적으로 잘 맞물리기 때문에, 이미지-텍스트 공동 사전학습에서 ViT는 거의 기본값이 되었다. CLIP이 대표적이며, 이후의 vision-language encoder와 multimodal decoder 계열 대부분이 ViT류 이미지 인코더를 출발점으로 삼는다. 이는 ViT의 영향이 비전 분류 논문 범위를 훨씬 넘어선다는 뜻이다. 언어모델이 foundation model의 핵심이 되는 과정에서, ViT는 시각 입력을 foundation model 세계로 가져오는 가장 중요한 인터페이스 가운데 하나가 되었다.
셋째 방향은 범용 백본으로서의 표준화다. CNN 시대에는 태스크마다 다른 backbone과 neck, head 조합을 고안하는 일이 많았지만, ViT 이후에는 하나의 대규모 사전학습 백본을 다양한 태스크에 재사용하려는 흐름이 더 강해졌다. 이 변화는 연구 문화에도 영향을 주었다. 모델 구조의 세밀한 수작업보다, 더 큰 사전학습, 더 나은 미세조정, 더 나은 데이터 큐레이션, 더 나은 instruction tuning이 중요해지는 방향으로 무게중심이 이동한 것이다. 그런 점에서 ViT는 단지 성능 좋은 비전 모델이 아니라, 비전 연구가 foundation model 패러다임에 적응하는 계기를 만든 논문이라고 할 수 있다.
8. 결론: 비전 모델 설계의 기본값을 CNN에서 Transformer로 이동시킨 전환점
ViT 논문의 가장 큰 의미는 이미지 분류 최고점 하나가 아니다. 더 중요한 것은 컴퓨터 비전의 기본 질문을 바꿨다는 점이다. 이전까지는 "CNN을 어떻게 더 잘 만들까"가 중심이었다면, 이 논문 이후에는 "이미지를 어떻게 토큰화하고 Transformer로 더 잘 다룰까"가 새로운 기본 질문이 되었다. 이는 단순한 아키텍처 교체가 아니라, 비전 표현 학습의 인터페이스 자체를 다시 정한 변화다.
논문은 동시에 매우 실용적인 결론도 남긴다. 작은 데이터나 제한된 연산 예산에선 강한 귀납편향을 가진 CNN이 여전히 유리할 수 있지만, 대규모 사전학습과 전이학습이 가능한 환경에서는 순수 Transformer가 더 큰 보상을 줄 수 있다는 것이다. 즉 ViT는 CNN을 완전히 폐기하자는 선언이 아니라, 데이터 스케일이 달라진 시대에 더 적합한 기본 아키텍처를 제안한 것으로 읽는 편이 적절하다. 이 균형 잡힌 메시지가 오히려 더 오래 남았다.
핵심 논문으로서 ViT의 가치는 지금도 분명하다. 이 논문이 없었다면 이후의 수많은 비전 Transformer, 이미지-텍스트 사전학습, 마스킹 기반 이미지 모델링, 멀티모달 foundation model의 발전 속도와 방향은 크게 달라졌을 가능성이 높다. Transformer가 언어에서 공용 연산 언어가 되었듯, ViT는 비전도 동일한 연산 문법 위에서 다시 조직할 수 있음을 보여 주었다. 그 점에서 ViT는 단순한 이미지 분류 논문이 아니라, 비전 분야가 foundation model 시대로 넘어가는 구조적 전환점이었다.
특히 이 논문은 표현의 단위를 바꾸는 일이 곧 연구 패러다임을 바꿀 수 있다는 점을 잘 보여 준다. 이미지가 더 이상 2차원 합성곱 필터의 입력으로만 취급되지 않고, 패치 단위의 토큰 시퀀스로 재정의되자 비전은 곧바로 언어모델 연구와 훨씬 더 가까운 생태계 안으로 이동했다. 사전학습, 미세조정, 토큰화, 클래스 토큰, 스케일링, 멀티모달 통합 같은 언어 연구의 핵심 어휘가 비전에서도 자연스럽게 통용되기 시작한 것이다. ViT의 장기적 영향력은 바로 이 언어-비전 간 공통 문법을 실질적으로 열었다는 데 있다.
또 하나 강조할 점은, ViT가 비전의 모든 문제를 즉시 해결한 논문은 아니라는 사실이다. 작은 데이터 효율, 고해상도 계산 비용, 조밀 예측 태스크로의 직접 확장 같은 문제는 남아 있었다. 그러나 핵심 논문이란 항상 완결된 해답을 뜻하지는 않는다. 오히려 분야 전체가 따라갈 수 있는 좋은 질문을 남겼는지가 더 중요하다. ViT는 정확히 그 역할을 했다. CNN의 귀납편향을 얼마나 줄여도 괜찮은가, 패치 단위 토큰화는 어디까지 유효한가, 대규모 사전학습이 비전의 구조 선택을 어떻게 바꾸는가 같은 질문들이 이 논문 이후 연구 전면으로 올라왔다.
산업적 관점에서도 ViT의 중요성은 크다. 대형 멀티모달 시스템, 검색 기반 이미지 이해, 비디오-언어 모델, 문서 이해 모델, 생성 모델의 시각 인코더 대부분이 결국 Transformer 계열 표현을 공유하는 방향으로 발전했기 때문이다. 백본이 공통화되면 연구 자산과 엔지니어링 자산을 훨씬 넓게 재사용할 수 있고, 텍스트와 시각 사이의 결합도 더 수월해진다. ViT는 바로 그 통합의 초석 역할을 했다. 이는 성능 점수 몇 줄보다 더 오래 남는 가치다.
교육적 의미도 있다. ViT는 핵심 논문을 읽는 독자에게 비전 모델 설계를 결과표가 아니라 귀납편향 대 데이터 스케일의 균형 문제로 보게 만든다. CNN이 왜 강했는지, Transformer가 왜 늦게 들어왔는지, 대규모 사전학습이 왜 구조 선택을 바꾸는지를 한 편의 논문 안에서 비교적 명료하게 보여 주기 때문이다. 그래서 ViT는 단순히 최신 흐름을 따라가기 위한 레퍼런스가 아니라, 오늘의 비전 foundation model을 이해하기 위한 필수적인 역사적 기준점으로 읽을 가치가 있다.
정리하면 ViT는 세 가지 층위에서 중요하다. 첫째, 이미지 분류에서 순수 Transformer가 통할 수 있음을 보였다. 둘째, 데이터 스케일이 커질수록 약한 귀납편향 구조가 더 큰 보상을 줄 수 있음을 실험적으로 입증했다. 셋째, 비전 연구를 멀티모달 foundation model 시대의 공통 연산 문법으로 연결했다. 이 세 층위가 겹치기 때문에, ViT는 오늘도 "한 번쯤 읽어야 할 대표 논문"이 아니라, 지금의 비전 모델 생태계가 왜 이런 형태가 되었는지 설명해 주는 출발점으로 남는다.
8.1 오늘 시점에서 다시 읽는 의미: ViT 이후 무엇이 표준이 되었는가
오늘 시점에서 ViT를 다시 읽으면, 논문이 직접 말하지 않은 영향까지 더 선명하게 보인다. 우선 vision backbone의 표준화가 있다. 예전에는 태스크마다 서로 다른 CNN 패밀리를 고르고, 각 패밀리에 맞는 head와 neck를 별도로 설계하는 일이 흔했다. ViT 이후에는 거대 사전학습 백본 하나를 여러 비전 태스크에 공통으로 재사용하는 흐름이 훨씬 강해졌다. 이는 모델 선택의 기준을 태스크 전용 구조 설계에서 사전학습 표현의 질과 적응 방식으로 옮겼다.
둘째는 멀티모달 정렬의 비용 감소다. 이미지가 토큰 시퀀스로 표현되면, 텍스트와의 결합이 구조적으로 훨씬 자연스러워진다. 이는 이미지-텍스트 대조학습, 비전-언어 instruction tuning, 문서 이해, 차트 이해, 화면 이해 등 다양한 영역에서 매우 큰 실용적 이점을 만든다. CNN feature map을 언어모델과 연결하던 시대에는 전용 브리지 모듈과 복잡한 정렬 설계가 필요했지만, ViT 이후에는 Transformer 기반 공통 공간을 중심으로 모달 간 연결을 구성하기가 한결 쉬워졌다. 결국 ViT는 비전의 문제를 푼 동시에, 텍스트 중심 foundation model 생태계와 비전 생태계를 매끄럽게 접속시킨 논문이기도 하다.
셋째는 연구 평가 방식의 변화다. ViT는 단일 벤치마크 점수만으로 아키텍처를 평가하는 대신, 사전학습 데이터 규모, 연산량, 전이 범위, few-shot 특성, attention 분석까지 함께 보게 만들었다. 이는 이후 foundation model 연구에서 아주 중요한 문화가 되었다. 어떤 모델이 더 좋은지 말하려면, 얼마나 큰 데이터에서 학습했는지, 같은 연산량이면 어떤지, 미세조정 없이 얼마나 강한지, 도메인이 바뀌면 어떠한지까지 함께 봐야 한다는 인식이 넓어졌다. ViT는 비전 분야에 이런 평가 프레임을 본격적으로 밀어 넣은 논문으로도 읽을 수 있다.
넷째는 귀납편향을 설계로 고정할지, 데이터로 학습할지라는 더 큰 질문을 전면화했다는 점이다. CNN은 설계로서의 prior를 강하게 품고 있고, ViT는 그 prior를 상대적으로 약하게 둔 뒤 데이터와 사전학습으로 보완한다. 이 대비는 비전 밖의 영역에도 그대로 확장된다. 음성, 로보틱스, 시계열, 3D 표현에서도 우리는 동일한 질문을 반복해서 묻게 된다. 즉 ViT는 비전 논문이면서도, 데이터가 충분할 때 구조적 편향을 어디까지 완화할 수 있는가라는 머신러닝 일반의 질문을 다시 활성화한 논문이다.
실제로 이 질문은 현재의 생성형 AI와 에이전트 연구에도 닿아 있다. 더 많은 도구, 더 긴 문맥, 더 다양한 모달리티가 결합되는 환경에서는 사람이 세부 구조를 미리 박아 넣는 접근보다, 공통 토큰화와 공통 Transformer 연산 위에 광범위한 사전학습을 얹는 방식이 더 확장 가능할 때가 많다. ViT는 이미지라는 한 도메인에서 이 철학이 실용적으로 통할 수 있음을 먼저 보여 준 사례다. 그래서 이 논문은 비전의 역사적 전환점인 동시에, foundation model 시대를 이해하는 사고 훈련용 텍스트로도 가치가 있다.
한편 ViT 이후의 비전 연구가 모두 순수 Transformer로만 정리된 것은 아니라는 점도 중요하다. 실제로 많은 후속 모델은 윈도우 attention, convolution stem, pyramid hierarchy, relative position bias처럼 CNN 시절의 통찰을 다시 끌어와 Transformer 안에 재배치했다. 이 사실은 ViT의 공헌을 오히려 더 선명하게 만든다. ViT가 없었다면 무엇을 버릴 수 있고 무엇을 다시 가져와야 하는지조차 비교하기 어려웠을 것이다. 다시 말해 후속 모델의 절충은 ViT의 실패가 아니라, ViT가 기준선을 너무 분명하게 제시했기 때문에 가능했던 정교화 과정으로 읽는 편이 맞다.
또 하나의 장기적 의미는 연구 커뮤니티가 백본 설계와 사전학습 전략을 분리해서 사고하게 되었다는 점이다. CNN 시대에는 구조 설계가 곧 성능의 대부분을 좌우한다는 인식이 강했다면, ViT 이후에는 같은 구조 위에 어떤 데이터, 어떤 증강, 어떤 자기지도 목표, 어떤 미세조정 규칙을 얹느냐가 훨씬 더 중요해졌다. 이는 foundation model 시대의 개발 방식과 정확히 맞물린다. 큰 백본 하나를 확보한 뒤, 데이터와 훈련법을 바꿔 범용성을 키우는 전략이 더 중심이 된 것이다. ViT는 비전 분야에서 이 개발 패턴이 가능하다는 사실을 가장 먼저 강하게 보여 준 논문 가운데 하나다.
결국 ViT를 핵심 논문으로 읽는 이유는 한 문장으로 요약할 수 있다. 이 논문은 이미지 분류 성능을 개선한 것에 그치지 않고, 비전을 foundation model의 언어로 번역했다. 이미지가 패치 토큰이 되고, 백본이 Transformer가 되고, 사전학습이 중심이 되고, 다양한 태스크가 공통 표현 위에서 통합되기 시작했다. 이후의 비전 모델이 어떤 형태를 띠든, 이 번역의 흔적을 피하기는 어렵다. 그래서 ViT는 과거의 성과 기록이 아니라, 현재의 비전 모델을 이해하기 위한 기본 문법서에 가깝다.
이 점에서 ViT는 단순히 비전 분야의 기술 진보를 넘어, 모델 아키텍처와 연구 조직 방식이 함께 바뀌는 순간을 보여 준다. 한때는 더 좋은 네트워크를 만들기 위해 사람이 더 많은 구조적 규칙을 설계해야 한다고 생각했지만, ViT는 충분한 데이터와 연산이 주어지면 오히려 더 일반적인 구조가 더 큰 확장성을 가질 수 있음을 보여 주었다. 이후 연구자들은 특정 태스크 전용 모델을 만드는 일보다, 범용 백본과 사전학습 자산을 어떻게 누적할지에 더 많은 관심을 두게 되었다. 그 변화의 상징적 출발점이 바로 ViT다.
또한 ViT를 통해 우리는 표현의 공통화가 왜 중요한지 배운다. 텍스트는 토큰, 이미지는 패치 토큰, 오디오는 프레임 토큰처럼 서로 다른 감각 신호를 결국 유사한 시퀀스 연산 위에 얹을 수 있게 되면, 모달리티 간 전이와 결합의 비용이 급격히 낮아진다. 멀티모달 시스템이 급속히 발전한 데는 큰 언어모델의 진전뿐 아니라, 시각 입력도 같은 토큰 기반 연산 문법으로 다룰 수 있게 된 영향이 크다. ViT는 바로 그 연결을 성립시킨 첫 번째 대형 성공 사례였다.
그래서 오늘 ViT를 다시 읽는 일은 단순한 역사 복기가 아니다. 이 논문은 현재의 비전 모델이 왜 Transformer 중심인지, 왜 사전학습이 핵심 자산이 되었는지, 왜 멀티모달 모델이 빠르게 통합될 수 있었는지를 한 번에 설명해 준다. 핵심 논문 카테고리에서 ViT가 갖는 가치는 여기에 있다. 과거의 대표작이라는 상징성뿐 아니라, 지금의 연구와 제품 설계가 어떤 논리로 이어졌는지 해석하는 기준점으로 계속 기능하기 때문이다.
실무 관점에서 보면 ViT의 교훈은 모델 선택보다 워크플로우 선택에 더 가깝다. 적절한 토큰화, 대규모 사전학습, 단순한 공통 백본, 폭넓은 전이 평가라는 네 요소가 맞물릴 때 구조의 장점이 크게 드러난다. 이는 오늘날 이미지 인코더를 고를 때도 그대로 적용된다. 단일 벤치마크 최고점보다, 어떤 사전학습 자산을 공유할 수 있는지, 텍스트나 비디오와 얼마나 자연스럽게 연결되는지, 미세조정 비용이 얼마나 드는지를 함께 보게 만드는 사고방식이 ViT 이후 표준이 되었다.
이런 이유로 ViT는 한 시대의 끝과 시작을 동시에 상징한다. CNN 중심 비전 연구의 축적을 배경으로 하면서도, 그 위에서 토큰 기반 Transformer 백본이라는 새로운 기본값을 제시했다. 후속 연구가 그 기본값을 수정하든, 지역성 편향을 일부 되살리든, 자기지도학습으로 더 밀어붙이든, 출발점은 여전히 ViT다. 핵심 논문으로서의 가치는 바로 이 지속성에 있다. 한 번의 유행이 아니라, 이후 수년간의 연구 질문과 설계 언어를 규정한 논문이라는 점이 중요하다.
따라서 ViT를 배우는 가장 좋은 방식은 단순히 구조를 외우는 것이 아니다. 왜 CNN이 오랫동안 강했는지, 왜 Transformer가 더 큰 데이터에서 강해졌는지, 왜 패치 토큰이라는 재표현이 멀티모달 확장으로 이어졌는지까지 한 흐름으로 이해해야 한다. 그렇게 읽으면 ViT는 단지 2020년의 한 성과가 아니라, 지금도 계속 반복되는 머신러닝의 핵심 질문들을 한 번에 압축한 논문으로 보인다. 어떤 편향을 미리 넣고, 어떤 부분을 데이터에 맡길 것인가라는 질문이 앞으로도 계속 중요할 것이기 때문이다.
이 점에서 ViT는 핵심 논문 카테고리에 매우 잘 어울린다. Transformer 원 논문이 시퀀스 모델링의 문법을 바꿨다면, ViT는 그 문법이 비전에도 통할 수 있음을 실증했다. 그리고 그 결과는 오늘의 이미지 인코더, 비전-언어 모델, 멀티모달 에이전트, 문서 이해 시스템까지 넓게 이어졌다. 핵심 논문을 다시 읽는 목적이 현재의 연구 생태계를 더 깊게 이해하는 데 있다면, ViT는 그 목적에 가장 직접적으로 부합하는 논문 가운데 하나다.
무엇보다 ViT는 "새로운 블록 하나를 제안했다"는 표현으로는 다 담기지 않는다. 이 논문은 비전 연구가 어떤 방식으로 발전해야 하는지에 대한 우선순위 자체를 재배열했다. 구조의 미세한 수공예보다 더 큰 데이터, 더 강한 사전학습, 더 범용적인 백본, 더 넓은 전이 평가가 중요해지는 시대를 예고했고, 실제로 이후의 주요 성과들이 그 방향을 따라갔다. 그래서 ViT의 영향은 논문 안의 표와 그림을 넘어, 비전 연구자들이 문제를 정의하고 실험을 설계하고 결과를 해석하는 방식 전반에 남아 있다. 이런 이유로 ViT는 지금도 핵심 논문으로 반복해서 읽힐 가치가 충분하다.
마지막으로, ViT는 핵심 논문이 갖춰야 할 세 가지 조건을 모두 만족한다. 기존 지배적 가정을 뒤집는 명확한 문제 제기가 있었고, 단순하지만 재현 가능한 구조적 제안이 있었으며, 이후 수많은 후속 연구가 이를 기준으로 자신을 정의할 만큼 큰 파급력이 있었다. 이런 논문은 시간이 지날수록 개별 수치보다 질문의 가치가 더 커진다. ViT가 바로 그런 사례다. 오늘의 비전과 멀티모달 모델을 이해하려면, 결국 한 번은 이 논문으로 돌아오게 된다.
그리고 그 되돌아봄은 단순한 향수가 아니라 실질적인 해석 도구가 된다. 현재의 비전 foundation model, image encoder, vision-language system을 설계하거나 읽을 때 등장하는 거의 모든 핵심 개념이 이미 ViT 안에서 원형을 갖고 있기 때문이다. 패치 토큰, 대규모 사전학습, 범용 백본, 전이 중심 평가라는 네 축이 지금도 그대로 작동한다는 사실만 봐도, 이 논문의 지속성을 확인할 수 있다.
이처럼 ViT는 성능 수치, 구조적 단순성, 후속 연구에 남긴 질문, 그리고 멀티모달 확장성이라는 네 측면에서 모두 기준점 역할을 한다. 핵심 논문을 읽는 목적이 단순한 연대표 확인이 아니라 현재의 연구 지형을 이해하는 데 있다면, ViT는 그 목적에 거의 교과서적으로 부합하는 사례다.
바로 그 이유 때문에, ViT는 지금도 비전 연구를 시작하거나 멀티모달 모델의 시각 인코더를 이해하려는 사람에게 가장 먼저 권할 수 있는 핵심 논문 가운데 하나로 남아 있다.
비전 모델의 현재를 이해하려면, 결국 ViT가 바꿔 놓은 질문의 틀을 이해해야 한다.
그 점에서 이 논문은 여전히 현재형이다.
오늘의 비전과 멀티모달 모델 대부분은 여전히 ViT가 연 문장 안에서 말하고 있다.
그래서 이 논문은 아직도 돌아와 읽을 이유가 충분하다.
ViT는 과거의 성과가 아니라 현재를 이해하는 기준점이다.
그래서 핵심 논문으로서의 생명력이 길다.
지금 읽어도 배울 것이 많다.
핵심 질문이 여전히 살아 있기 때문이다.
그래서 반복해 읽을 만하다.
후속 비전 Transformer의 설계 어휘가 여전히 이 논문 위에서 정리된다는 사실이 이를 잘 보여 준다. 그 영향 범위는 넓다.
9. 요약 정리
마지막으로 이 논문의 핵심 내용을 짧게 다시 정리하면 아래와 같다. 문제의식, 설계, 실험, 해석이 어떤 흐름으로 이어지는지 빠르게 복기할 수 있도록 정리했다.
- 핵심 문제의식: 이미지 인식에 CNN의 강한 귀납편향이 반드시 필요한지 다시 묻고, 패치 시퀀스를 입력으로 하는 순수 Transformer의 가능성을 시험했다.
- 입력 설계: 이미지를 고정 크기 패치로 분할하고, 각 패치를 선형 투영한 뒤 class token과 position embedding을 더해 Transformer encoder에 입력한다.
- 모델 구조: ViT는 별도의 비전 전용 복잡한 블록 없이 MSA + MLP + residual + layer norm의 표준 Transformer encoder를 거의 그대로 사용한다.
- 스케일링 메시지: 작은 데이터에서는 CNN이 유리할 수 있지만, ImageNet-21k나 JFT-300M 수준의 큰 사전학습 데이터에서는 ViT가 더 높은 성능 상한을 보인다.
- 대표 결과: JFT-300M 사전학습 ViT-H/14는 ImageNet 88.55, ImageNet ReaL 90.72, CIFAR-100 94.55 등 강한 전이 성능을 기록했다.
- 연산 효율 관점: ViT는 같은 사전학습 연산량 대비 강한 CNN 기준선과 경쟁력 있는 위치를 차지하며, 계산 예산이 커질수록 구조적 이점이 더 분명해진다.
- 표현 분석: attention map, 위치 임베딩 유사도, head별 attention distance 분석은 ViT가 전역 관계와 공간 구조를 학습적으로 조직한다는 정성적 근거를 제공한다.
- 한계점: 데이터 효율성과 고해상도 self-attention 비용은 분명한 약점이며, 후속 연구들은 distillation, hierarchical design, sparse attention으로 이를 보완했다.
- 후속 영향: DeiT, Swin, MAE, CLIP, 다양한 멀티모달 foundation model까지 이어지는 비전 Transformer 계열의 출발점 역할을 했다.
- 핵심 논문으로서의 의미: ViT는 이미지 분류 모델 하나를 제안한 것이 아니라, 비전 모델의 기본 연산 문법을 CNN 중심에서 Transformer 중심으로 이동시킨 전환점이다.