AgentTTS: Large Language Model Agent for Test-time Compute-optimal Scaling Strategy in Complex Tasks
https://arxiv.org/abs/2508.00890
Fali Wang, Hui Liu, Zhenwei Dai, Jingying Zeng, Zhiwei Zhang, Zongyu Wu, Chen Luo, Zhen Li, Xianfeng Tang, Qi He, Suhang Wang | The Pennsylvania State University, Amazon | arXiv:2508.00890 | 2025년 7월 | NeurIPS 2025 게재 확정
1. 서론: 다단계 복합 태스크에서 테스트 타임 연산 최적화의 필요성
테스트 타임 스케일링(Test-time Scaling, TTS)은 대규모 언어 모델(LLM)의 추론 단계에서 추가적인 연산 자원을 할당하여 성능을 향상시키는 기법으로, 최근 LLM 연구에서 매우 주목받는 패러다임이다. 예를 들어, Brown 등의 연구에서는 반복 샘플링을 통해 후보 솔루션을 생성하고 검증기로 최선의 예측을 선택함으로써, 약한 소형 모델이 단일 샘플 기반 최신 대형 모델을 능가할 수 있음을 보여주었다. 이러한 접근법은 추론 시점에 더 많은 연산을 투입하면 모델 크기의 한계를 상당 부분 극복할 수 있다는 가능성을 열어주었다.
그러나 기존의 테스트 타임 스케일링 연구는 대부분 단일 단계 태스크(single-stage task)에 초점을 맞추어 왔다. 수학 문제 풀이나 코드 생성처럼 모델이 하나의 기능만 수행하는 상황에서의 연산 최적화가 주된 연구 대상이었던 것이다. 하지만 현실 세계의 많은 응용은 다단계 복합 태스크(multi-stage complex task)로 구성되며, 각 단계의 서브태스크가 서로 다른 유형의 역량을 요구한다. 대표적인 예로 검색-생성 방식의 질의응답 시스템, 요구사항 분석부터 테스트까지를 포괄하는 폭포수 소프트웨어 개발, 그리고 태스크 분해와 도구 선택 및 파라미터 예측으로 이어지는 멀티 에이전트 태스크 자동화 등이 있다.
논문은 이러한 다단계 복합 태스크에서의 테스트 타임 연산 최적 스케일링이라는 새로운 문제를 형식화하고 연구한다. 핵심 목표는 순차적으로 구성된 복수의 서브태스크에 대해, 주어진 총 연산 예산 내에서 각 서브태스크에 적절한 모델을 선택하고 예산을 할당하여 전체 태스크 성능을 극대화하는 것이다. 이 문제가 기존의 단일 단계 테스트 타임 스케일링과 근본적으로 다른 점은, 단일 단계에서는 "주어진 예산 내에서 어떤 모델을 몇 번 샘플링할 것인가"라는 상대적으로 단순한 1차원적 최적화 문제인 반면, 다단계에서는 "여러 서브태스크에 걸쳐 예산을 어떻게 분배하고 각각 어떤 모델을 선택할 것인가"라는 고차원적 조합 최적화 문제라는 점이다.
이 문제는 두 가지 근본적 도전을 제기한다. 첫째, 모델 선택과 예산 할당의 조합적 탐색 공간이 극도로 크다. 예를 들어 세 개의 서브태스크에 각각 두 가지 모델 옵션(3B와 70B)이 있고 각 서브태스크의 샘플 수를 1에서 100까지 선택할 수 있는 소프트웨어 개발 시나리오에서, 가능한 구성의 수는 $10^6$에 달한다. 각 구성의 추론에는 수 시간이 소요될 수 있어 무차별 대입 탐색이 비현실적이다. 둘째, 서브태스크 간의 예산 할당이 상호의존적이다. 한 서브태스크에 대한 연산 할당이 다른 서브태스크의 성능과 예산 요구사항에 영향을 미치므로 최적 구성 탐색의 복잡도가 크게 증가한다. 예를 들어, 검색 서브태스크에 많은 예산을 투입하여 고품질 검색 결과를 얻으면, 후속 QA 서브태스크에서는 소형 모델로도 충분한 성능을 달성할 수 있지만, 검색 품질이 낮으면 QA에 대형 모델과 더 많은 샘플이 필요해진다.
이러한 도전에 대응하기 위해, 논문은 먼저 네 가지 태스크 유형과 여섯 개의 데이터셋에 걸쳐 광범위한 사전 실험을 수행하여 다단계 태스크에서 LLM의 행동을 특징짓는 세 가지 경험적 인사이트를 도출한다. 이후 이 인사이트를 기반으로 AgentTTS라는 LLM 에이전트 기반 프레임워크를 제안하며, 이 프레임워크는 실행 환경과의 반복적인 피드백 기반 상호작용을 통해 연산 최적 할당을 자율적으로 탐색한다. 실험 결과는 AgentTTS가 기존의 전통적 방법과 다른 LLM 기반 베이스라인을 탐색 효율성에서 유의미하게 능가하며, 다양한 학습 세트 크기에 대한 강건성과 해석 가능성에서도 개선된 성능을 보임을 입증한다.
논문의 핵심 기여는 세 가지로 요약된다. 첫째, 다단계 복합 태스크에서의 테스트 타임 연산 최적 스케일링이라는 새로운 문제를 형식화한다. 둘째, 다단계 태스크에서 테스트 타임 스케일링의 근본적 패턴을 밝히는 세 가지 핵심 인사이트를 식별하고, 이를 기반으로 효율적인 LLM 에이전트 기반 프레임워크인 AgentTTS를 설계한다. 셋째, 여섯 개 데이터셋에 걸친 포괄적 평가를 통해 AgentTTS가 강력한 탐색 효율성, 투명한 해석 가능성, 비매끄러운 탐색 지형에 대한 강건성을 달성함을 실증한다. 이러한 기여는 기존에 주로 단일 단계 태스크에 국한되었던 테스트 타임 스케일링 연구를 현실 세계의 복잡한 다단계 시나리오로 확장한다는 점에서 학술적 의의가 크다.
2. 배경 및 관련 연구: 테스트 타임 스케일링과 LLM 기반 최적화
2.1 테스트 타임 스케일링의 기존 접근법
테스트 타임 스케일링(TTS)은 LLM의 추론 시 추가 연산을 할당하여 성능을 향상시키는 기법으로, 크게 순차적 스케일링(sequential scaling)과 병렬 스케일링(parallel scaling)의 두 범주로 나뉜다. 순차적 스케일링은 출력을 반복적으로 정제하는 방식으로, Self-Refine이나 CRITIC과 같은 방법이 대표적이다. Self-Refine은 모델 자체의 피드백을 활용하여 반복적으로 응답을 개선하는 방식을 채택하며, CRITIC은 도구 상호작용을 통한 비평 과정을 통해 출력 품질을 향상시킨다. 그러나 이 방식은 초기 응답의 품질에 크게 의존하는 한계가 있으며, 초기 응답이 열악한 경우 반복적 정제로도 충분한 품질 향상을 달성하기 어렵다.
반면 병렬 스케일링은 여러 출력을 동시에 생성한 뒤 보상 기반 선택을 통해 이를 집계하는 방식으로, 반복 샘플링(repeated sampling), Best-of-N, 트리 탐색(tree search) 등이 포함된다. 반복 샘플링은 동일한 입력에 대해 여러 번 독립적으로 샘플링하여 다양한 후보 솔루션을 생성하는 방법이고, Best-of-N은 N개의 후보 중 보상 모델에 의해 가장 높은 점수를 받은 응답을 선택하는 방법이며, 트리 탐색은 토큰 레벨이나 단계 레벨에서 분기를 생성하고 보상 신호를 기반으로 탐색하는 방법이다. 최근에는 보상 모델에 대한 의존도를 줄이기 위해 LLM을 퓨저(fuser)로 활용하는 연구도 등장했으며, LLM-Blender나 Multi2 등의 시스템이 여러 후보 응답을 LLM이 직접 융합하여 단일 최종 응답을 생성하는 방식을 제안하였다. 병렬 스케일링은 더 나은 확장성과 더 넓은 솔루션 커버리지를 제공하여 복잡한 태스크에서 선호된다.
테스트 타임 연산 최적 스케일링에 관한 기존 연구는 최적 전략을 갖춘 소형 모델이 대형 모델을 능가할 수 있음을 보여주었다. 대표적으로 Brown 등은 반복 샘플링만으로도 소형 모델이 대형 모델의 단일 샘플 성능을 능가할 수 있음을 입증했고, s1은 단순한 테스트 타임 스케일링만으로도 상당한 성능 향상이 가능함을 보여주었다. 난이도 기반 모델 선택, 보상 가이드 투표, 예산 인식 프롬프팅 등 다양한 접근법이 제안되었으나, 이들은 모두 단일 단계 태스크에 초점을 맞추고 있다. 논문은 이를 다단계 태스크로 확장하여, 상호의존적인 서브태스크들 사이에서 예산을 적응적으로 할당해야 하는 새로운 문제 설정을 다룬다는 점에서 기존 연구와 근본적으로 차별화된다. 단일 단계에서의 "더 많은 연산 = 더 나은 성능"이라는 단순한 관계가 다단계 시나리오에서는 서브태스크 간 상호의존성으로 인해 성립하지 않기 때문에, 완전히 새로운 최적화 접근법이 필요하다.
2.2 LLM 기반 하이퍼파라미터 최적화
LLM은 하이퍼파라미터 최적화(HPO) 도구로서 베이지안 최적화(Bayesian Optimization, BO) 같은 전통적 AutoML 기법을 능가하는 성능을 보여주고 있다. LLM이 HPO에서 효과적인 이유는 문맥적 추론 능력과 사전 지식을 활용하여 탐색 공간을 효율적으로 탐색할 수 있기 때문이다. LLM 기반 HPO 연구는 크게 두 방향으로 진행된다. 첫째는 탐색 공간의 축소로, GPT-NAS는 LLM을 활용하여 신경망 아키텍처 탐색(NAS)의 대규모 공간을 가지치기하고, AutoM3L은 멀티모달 머신러닝의 하이퍼파라미터 공간을 축소하며, Llambo는 베이지안 최적화와 LLM을 결합하여 탐색 효율성을 향상시킨다. 둘째는 하이퍼파라미터 구성의 직접 생성으로, LLM을 자율적인 최적화 도구로 활용하는 방향이다. AutoMMLab은 멀티모달 모델의 자동 학습을 위한 에이전트 프레임워크를 제공하고, GENIUS는 LLM 기반의 과학적 전문가 시스템으로 실험 설계를 자동화하며, MLCopilot은 유사 태스크의 경험을 전이하여 새로운 태스크의 하이퍼파라미터를 생성한다. AgentHPO는 피드백 기반의 반복적 시행착오를 통해 하이퍼파라미터를 정제하는 에이전트 프레임워크이다.
논문은 이러한 LLM 기반 하이퍼파라미터 최적화 연구의 흐름을 다단계 태스크의 테스트 타임 연산 최적 스케일링으로 확장한다. 기존 HPO 방법들이 범용적인 하이퍼파라미터 튜닝에 초점을 맞추었다면, AgentTTS는 테스트 타임 스케일링이라는 비교적 새로운 기법에 특화된 경험적 인사이트를 LLM 에이전트에 통합함으로써, 기존 방법들이 갖지 못한 도메인 특화 지식을 활용한다는 점에서 차별화된다. AgentHPO나 MLCopilot이 범용 하이퍼파라미터에 대한 일반적인 탐색 전략만을 사용하는 반면, AgentTTS는 "서브태스크마다 모델 선호도가 다르다", "최적 예산 이후 성능이 포화된다", "선행 서브태스크의 품질이 후속 서브태스크에 영향을 미친다"와 같은 구체적이고 검증된 인사이트를 탐색 과정에 직접 주입한다. 이러한 도메인 특화 지식의 활용이 탐색 효율성에서의 현저한 차이를 만들어낸다.
3. 문제 정의: 다단계 태스크에서의 연산 예산 할당
3.1 다단계 복합 태스크의 형식화
논문은 다단계 복합 태스크 $\mathcal{T} = [T_1, T_2, \ldots, T_n]$을 $n$개의 단순한 서브태스크로 구성된 것으로 정의한다. 여기서 서브태스크들은 순차적으로 실행되며, 선행 서브태스크의 출력이 후속 서브태스크의 입력으로 전달되는 파이프라인 구조를 형성한다. 각 서브태스크 $T_i$는 후보 모델 집합 $\mathcal{M}_i$를 가지며, 각 모델 $M_i \in \mathcal{M}_i$는 해당 서브태스크에 적합하도록 설계되어 있다. 전체 복합 태스크 $\mathcal{T}$에 대해 고정된 총 연산 예산 $B$가 주어지면, 각 서브태스크에 $B_i$의 예산이 배분되어야 하며 이때 $\sum_{i=1}^{n} B_i = B$를 만족해야 한다. 이러한 예산 제약 조건은 현실적인 배치 설정을 반영하는데, 실제 응용에서는 GPU 시간, API 비용, 지연 시간 등의 이유로 무한한 연산 자원을 사용할 수 없기 때문이다.
각 서브태스크 $T_i$에서는 할당된 예산 $B_i$ 내에서 더 큰 모델을 적은 추론 샘플로 사용하는 것과 더 작은 모델을 많은 샘플로 사용하는 것 사이의 트레이드오프가 존재한다. 논문이 정의하는 핵심 문제는 다음과 같다. 고정된 총 연산 예산 $B$가 주어졌을 때, 서브태스크 간의 예산을 $B \mapsto \{B_1, B_2, \ldots, B_n\}$으로 최적 할당하고, 적절한 모델 $M_i$를 선택하며, 할당된 자원을 효과적으로 분배하여 전체 성능을 극대화하는 것이다.
3.2 반복 샘플링과 퓨전 기반 테스트 타임 스케일링
논문은 테스트 타임 스케일링 모드로 반복 샘플링과 퓨전(Repeated Sampling with Fusion) 전략을 채택한다. 이 전략은 Best-of-N이나 트리 탐색 알고리즘과 달리 추가적인 보상 모델이나 검증기를 필요로 하지 않으며, 순차적 스케일링에 비해 더 우수한 확장성을 제공한다. 구체적으로, 문제 $p$와 파라미터 $\theta$를 가진 언어 모델 $M$이 주어지면, 반복 샘플 수 $k$를 증가시키는 방식으로 테스트 타임 스케일링을 수행한다. 다양한 생성을 유도하기 위해 온도(temperature) 하이퍼파라미터를 0.9로 고정한다. 반복 샘플링을 통해 생성된 여러 후보 솔루션은 퓨전 프롬프트를 사용하여 집계된다.
수식으로 표현하면 다음과 같다:
$$o = f_{\text{fuse}}(\mathcal{S}, M), \quad \mathcal{S} = \{s_i \mid 1 \leq i \leq k\}, \quad s_i \sim M(s \mid p, \theta)$$
여기서 $\mathcal{S}$는 샘플링된 응답의 집합을 나타내며, 각 $s_i$는 입력 프롬프트 $p$와 모델 파라미터 $\theta$에 조건부로 모델 $M$에서 독립적으로 추출된다. 퓨전 함수 $f_{\text{fuse}}$는 퓨전 프롬프트를 사용하여 샘플링된 응답들을 통합한다. 주목할 점은 솔루션 생성과 퓨전 수행 모두에 동일한 LLM이 사용된다는 것이다. 이 설계는 추가적인 보상 모델이나 외부 검증기 없이도 효과적인 테스트 타임 스케일링을 가능하게 한다.
이 반복 샘플링과 퓨전 방식의 선택에는 명확한 근거가 있다. Best-of-N 방식은 보상 모델이 필요하며, 이 보상 모델의 학습과 보정에 추가적인 비용이 소요된다. 트리 탐색 방식은 단계별 보상 신호가 필요하며, 구현이 복잡하다. 순차적 정제 방식은 초기 응답의 품질에 크게 의존하는 단점이 있다. 반면 반복 샘플링과 퓨전은 동일한 모델만으로 구현 가능하고, 병렬 실행이 용이하여 확장성이 뛰어나며, 복잡한 태스크에서 더 넓은 솔루션 공간을 탐색할 수 있다는 장점을 가진다. 특히 다단계 태스크에서는 각 서브태스크가 독립적으로 샘플링되고 퓨전되므로, 서브태스크 간 예산 할당의 유연성이 극대화된다.
3.3 통합 예산 변환 프레임워크
서로 다른 모델과 태스크는 다양한 수준의 연산 자원을 요구한다. 대형 모델은 더 많은 추론 FLOPs를 필요로 하고, 복잡한 태스크는 일반적으로 더 긴 입력 또는 출력 토큰을 수반하여 연산 비용이 증가한다. 이러한 불균형은 모델과 태스크 간의 공정한 연산 오버헤드 비교를 어렵게 만든다. 논문은 이를 해결하기 위해 예산 정규화 프레임워크(budget normalization framework)를 제안한다. 이 프레임워크는 대형 모델의 적은 추론 샘플 비용을 소형 모델의 많은 샘플 비용과 동등하게 치환하면서, 태스크별 연산 변동을 명시적으로 반영한다.
공통 예산 단위를 설정하기 위해, 가장 작은 모델(예: LLaMA 3B)이 가장 낮은 연산 소비 태스크 $T_{\text{lowest}}$에서 단일 추론 패스를 수행하는 비용을 기본 단위 1로 정의한다. 이를 통해 모든 모델-태스크 조합의 연산 비용을 이 기본 단위의 배수로 표현할 수 있어, 이질적인 서브태스크 간의 예산 비교와 할당이 가능해진다:
$$f_{\text{budget}}(M_{\text{smallest}}, 1, T_{\text{lowest}}) = 1$$
주어진 모델 $M_\ell$, 샘플 수 $S_\ell$, 태스크 $T_\ell$에 대해 정규화된 예산 $B$는 다음과 같이 계산된다:
$$B = f_{\text{budget}}(M_\ell, S_\ell, T_\ell) = S_{\text{smallest}} \;\; \text{such that} \;\; f_{\text{cost}}(M_\ell, S_\ell, T_\ell) = f_{\text{cost}}(M_{\text{smallest}}, S_{\text{smallest}}, T_{\text{lowest}})$$
논문은 추론 FLOPs를 주요 비용 메트릭으로 채택하며, 이에 대한 구체적인 예산 변환 공식을 정리(Theorem 1)로 제시한다. 추론 FLOPs는 모델 크기와 토큰 수로부터 결정론적으로 계산될 수 있어, 재현성이 높고 하드웨어에 독립적인 비용 메트릭이다. 구성 $(M_\ell, S_\ell, T_\ell)$이 주어지고 기준 구성이 $(M_{\text{smallest}}=3\text{B}, N_{p,\text{lowest}}=128, N_{d,\text{lowest}}=64)$일 때, 정규화된 예산은 다음과 같다:
$$B = f_{\text{budget}}(M_\ell, S_\ell, T_\ell) = \frac{2\alpha\beta_2 S_\ell}{\beta_1} + 2(\alpha\beta_2 - 1)$$
여기서 $\alpha = M_\ell / M_{\text{smallest}}$는 모델 크기 비율, $\beta_1 = N_{p,\ell} / N_{d,\ell}$는 프롬프트 대 생성 길이 비율, $\beta_2 = N_{p,\ell} / N_{p,\text{lowest}}$는 프롬프트 길이 비율을 나타낸다. 이 변환 하에서 예산 $B$는 직관적으로 "3B 파라미터 모델을 기준 구성 $T_{\text{lowest}}$에서 사용할 때 몇 번의 패스가 동일한 비용을 유발하는가"를 나타낸다. 이러한 통합 예산 변환은 서로 다른 모델-태스크 조합 간의 공정한 연산 비용 비교를 가능하게 하며, 다단계 태스크 전반에 걸친 예산 할당 최적화의 기초를 제공한다.
4. 핵심 경험적 인사이트: 다단계 태스크에서의 테스트 타임 스케일링 특성
논문은 AgentTTS의 설계에 앞서, 다단계 복합 태스크에서 LLM의 테스트 타임 스케일링 행동을 이해하기 위한 광범위한 사전 실험을 수행한다. 이 사전 실험은 논문의 핵심 기여 중 하나로, 단순히 방법론의 동기부여를 위한 것이 아니라 다단계 테스트 타임 스케일링의 근본적 특성을 체계적으로 밝히는 독립적인 연구 기여이다. 네 가지 태스크 유형(검색 기반 QA, 지식 그래프 QA, 태스크 자동화, 자동 소프트웨어 개발)과 여섯 개의 데이터셋에 걸친 실험으로부터 세 가지 핵심 인사이트를 도출하며, 이 인사이트들이 다양한 태스크 유형에서 일관되게 관찰된다는 점이 그 일반성을 뒷받침한다. 이들은 이후 AgentTTS의 탐색 전략 설계를 직접적으로 안내한다.

Figure 1: 2WikiMultiHopQA에서 샘플링 수 및 추론 FLOPs 증가에 따른 성능 변화. 상단: 샘플 수별 성능, 하단: 로그 스케일 추론 FLOPs별 성능. (a) Ret_F1로 측정한 검색 정확도. (b-d) 다양한 검색 품질 수준에서의 QA 성능(Gen_EM).
4.1 Insight 1: 서브태스크별 차별화된 모델 선호도
Figure 1(a)에서 확인할 수 있듯이, 검색(retrieval) 서브태스크의 성능은 모델 크기와 강한 양의 상관관계를 보이며, 소형 모델은 예산을 증가시켜도 미미한 개선만을 제공한다. 이는 검색 태스크가 긴 문맥 이해 능력에 크게 의존하여 대형 모델이 유리하며, 적은 수의 고용량 샘플이 더 나은 결과를 산출함을 시사한다. 반면 Figure 1(b)에서 보이는 질의응답(QA) 서브태스크에서는 제한된 예산(예: $10^{14}$ FLOPs 미만) 하에서 LLaMA-3 3B와 LLaMA-3 8B가 LLaMA-3 70B를 능가하여, 소형 모델에 대한 선호도가 관찰된다.
이러한 차이는 서브태스크별 요구사항의 특성에서 비롯된다. 검색은 긴 문맥 이해를 강조하여 대형 모델이 유리한 반면, 질의응답은 주로 검색된 내용에서 정보를 추출하는 작업으로 소형 모델이 우수한 성능을 보이며 반복 샘플링을 통한 테스트 타임 스케일링을 더 효과적으로 활용할 수 있다. 이 패턴은 검색 기반 QA뿐만 아니라 지식 그래프 QA, 태스크 자동화 등 다른 태스크 유형에서도 유사하게 관찰되어 일반화 가능한 인사이트임이 확인된다. 예를 들어 TaskBench의 태스크 분해 서브태스크에서는 대형 모델이 더 정확한 분해를 수행하는 반면, 파라미터 예측 서브태스크에서는 소형 모델이 반복 샘플링을 통해 경쟁력 있는 성능을 보인다.
논문은 이를 Insight 1로 정리한다: "서로 다른 서브태스크는 각 서브태스크가 요구하는 특정 역량에 따라 언어 모델과 샘플링 빈도 간에 고유한 선호도를 보인다." 이 인사이트의 실용적 함의는 매우 크다. 다단계 태스크에서 모든 서브태스크에 동일한 대형 모델을 사용하는 것은 비효율적일 뿐만 아니라, 제한된 예산 하에서는 오히려 성능 저하를 초래할 수 있다. 소형 모델이 더 적합한 서브태스크에 대형 모델을 사용하면, 그 예산이 대형 모델이 진정으로 필요한 다른 서브태스크에서 부족해지기 때문이다.
4.2 Insight 2: 최적 예산 초과 시 수확 체감 및 성능 하락
Figure 1(b-d)는 QA 서브태스크에서 모델들의 비단조적(non-monotonic) 성능 추세를 보여준다. 반복 샘플링 수가 증가함에 따라 성능이 처음에는 향상되지만, 최적 예산에 도달한 후에는 종종 진동하거나 하락한다. 예를 들어 LLaMA-3 3B는 10개 샘플(FLOPs 예산 약 $2 \times 10^{13}$)에서 정점 성능에 도달하며, 추가적인 연산이 항상 더 나은 결과를 산출하지는 않음을 보여준다.
논문은 이 현상의 원인을 다음과 같이 분석한다. 후보 수가 증가함에 따라 퓨전 과정이 더 복잡해지며 성능 병목이 될 수 있다. 퓨전은 여러 후보 응답을 하나의 최종 응답으로 통합하는 과정인데, 후보 수가 지나치게 많으면 모순되거나 저품질인 응답들이 섞여 퓨전의 품질이 오히려 저하된다. 소형 모델은 제한된 용량으로 인해 높은 샘플링 수에서 더 큰 어려움을 겪고 성능이 저하되는 경향이 있는 반면, 대형 모델은 광범위한 퓨전을 처리하는 데 더 유능하여 더 큰 내성을 보인다. 구체적인 예를 들면, LLaMA-3 3B는 QA 서브태스크에서 10개 샘플 정도에서 최적 성능에 도달하지만, 30개 이상의 샘플에서는 성능 변동이 심해지고 일부 구성에서는 10개 샘플 시점의 성능보다 낮아진다. 이는 소형 모델의 퓨전 능력이 대량의 후보를 효과적으로 통합하기에 부족하기 때문이다.
이를 Insight 2로 정리한다: "서브태스크 수준의 테스트 타임 스케일링은 일반적으로 최적 예산이 존재하며, 그 이상의 예산은 제한적이거나 오히려 부정적인 수익을 초래한다." 이 인사이트는 테스트 타임 스케일링에서 "더 많은 연산 = 더 나은 성능"이라는 직관이 항상 성립하지 않음을 명확히 보여준다. 각 모델과 서브태스크 조합마다 고유한 최적 예산이 존재하며, 이를 정확히 식별하는 것이 전체 파이프라인의 성능과 효율성 모두에 결정적이다. 최적 예산을 초과하는 연산은 성능에 기여하지 못할 뿐 아니라, 다른 서브태스크에 할당될 수 있는 소중한 연산 자원을 낭비하는 이중의 비효율을 초래한다.
4.3 Insight 3: 서브태스크 간 예산 할당의 상호의존성
Figure 1(b-d)는 검색 품질 수준(F1 점수 약 0.80, 0.60, 0.35)에 따른 QA 서브태스크의 성능 변화도 보여준다. 고품질 검색이 대형 모델에 의해 제공될 때(Figure 1(b)), QA의 최적 테스트 타임 예산이 더 일찍 도달되며(LLaMA-3 8B가 10개 샘플에서 정점), 소형 모델(3B, 8B)이 동일 연산 예산 하에서 대형 모델(70B)을 능가할 수 있다. 반면 저품질 검색(Figure 1(c)(d))에서는 정점 성능 도달이 지연된다. Ret_F1=0.6일 때 LLaMA-3 8B는 20개 샘플(예산 약 $3 \times 10^{13}$ FLOPs)에서 정점에 도달하고, Ret_F1=0.35일 때는 90개 샘플(예산 약 $10^{14}$ FLOPs)에서도 아직 정점 성능에 도달하지 못한다.
더 나아가 저품질 검색 하에서는 소형 모델이 대형 모델을 능가할 가능성이 낮아진다. Figure 1(d)에서 3B 및 8B 모델의 정점 성능은 70B 모델의 최저 성능조차 초과하지 못한다. 이러한 발견은 한 서브태스크의 스케일링 행동이 선행 서브태스크의 성능에 의해 영향을 받음을 나타낸다. 열악한 검색은 하류 태스크의 난이도를 높이며, 누락된 정보를 보상하기 위해 대형 모델이 더 유리해진다.
이 현상을 더 구체적으로 이해하면 다음과 같다. 고품질 검색(Ret_F1 약 0.80)이 제공될 때는 검색 결과에 정답에 필요한 정보가 대부분 포함되어 있으므로, QA 모델은 단순히 제공된 문맥에서 관련 정보를 추출하면 된다. 이 작업은 소형 모델로도 충분히 수행 가능하며, 반복 샘플링을 통해 다양한 추출 시도를 하면 정확도가 빠르게 향상된다. 반면 저품질 검색(Ret_F1 약 0.35)에서는 검색 결과에 핵심 정보가 누락되어 있으므로, QA 모델은 불완전한 정보를 기반으로 추론해야 하고, 때로는 모델 자체의 내부 지식에 의존해야 한다. 이는 훨씬 더 높은 수준의 추론 능력을 요구하며, 이러한 고수준 추론은 대형 모델에서만 효과적으로 수행된다. 따라서 저품질 검색 하에서는 소형 모델의 반복 샘플링이 근본적으로 한계가 있으며, 더 많은 샘플을 생성하더라도 기본적인 추론 능력의 부족을 보상하지 못한다.
논문은 이를 Insight 3로 정리한다: "선행 서브태스크에 대한 예산 할당이 후속 서브태스크의 모델 선택과 최적 예산에 영향을 미친다." 이 인사이트의 핵심적 함의는 다단계 태스크의 예산 할당이 비분리적(non-separable) 최적화 문제라는 것이다. 각 서브태스크의 최적 구성을 독립적으로 결정한 후 합치는 방식으로는 전역 최적에 도달할 수 없으며, 서브태스크 간의 상호작용을 고려한 통합적 최적화가 반드시 필요하다. 이는 단일 단계 테스트 타임 스케일링에서는 존재하지 않는 근본적으로 새로운 도전이며, AgentTTS가 이 문제를 LLM의 계획 능력을 활용하여 해결한다.
5. 방법론: AgentTTS 프레임워크
앞서 도출된 세 가지 인사이트를 기반으로, 논문은 AgentTTS(Agent for Test-Time compute-optimal Scaling)를 제안한다. AgentTTS의 핵심 아이디어는 LLM이 하이퍼파라미터 최적화에서 보여준 강력한 계획 및 추론 능력을 테스트 타임 스케일링의 예산 할당 문제에 적용하되, 단순히 범용 HPO 방법을 그대로 적용하는 것이 아니라 다단계 테스트 타임 스케일링에 특화된 경험적 인사이트를 체계적으로 통합하여 탐색 효율성을 극대화하는 것이다. 이 프레임워크는 LLM 기반 에이전트에 경험적 인사이트를 통합하여, 다단계 태스크의 연산 할당 공간을 자율적으로 탐색하고 서브태스크별 모델 선호도, 최적 예산, 서브태스크 간 의존성을 포착한다.

Figure 2: LLM Agent를 활용한 테스트 타임 스케일링 예산 할당의 전체 개요. (b) Agent가 후보 시행과 가이드라인을 생성하고, (c) Environment가 실제 실행 환경에서 시행을 평가하며, (d) Archive가 가이드라인, 시행, 피드백의 이력을 저장한다.
5.1 전체 아키텍처: Agent, Archive, Environment
Figure 2에서 보여주듯이, AgentTTS 프레임워크는 세 가지 핵심 컴포넌트로 구성된다. Agent는 LLM을 사용하여 구현되며, 테스트 타임 예산 할당 후보 시행(trial)과 가이드라인을 생성하는 역할을 담당한다. Archive는 생성된 가이드라인과 후보 시행을 해당 데이터베이스에 저장하여 탐색 과정 전체에 걸친 이력을 기록한다. Environment는 실제 런타임 환경에서 시행을 실행하고 평가하며, 성능 피드백을 Agent에 반환한다.
전체 워크플로우는 다음과 같이 진행된다. 먼저 Agent가 Insight 1에 기반하여 초기 후보 시행 배치를 생성한다. 각 시행은 $(M_1, B_1, M_2, B_2, \ldots)$ 형태로, 각 서브태스크에 대한 모델 선택과 예산 할당을 지정한다. 이 시행들은 Archive에 저장되고 Environment로 전달되어 실제 태스크 플랫폼에서 평가된다. 결과로 얻어진 성능 피드백은 Agent에 반환되어 초기 가이드라인을 구성하는 데 사용되며, 이 가이드라인은 후속 시행에서 소형 또는 대형 모델 중 어느 쪽을 우선시해야 할지를 제안한다. 후속 반복에서 Agent는 기존 가이드라인에 기반하여 새로운 시행을 생성하고, Insight 2와 3을 활용하여 새로운 가이드라인을 추가한다. 이 루프는 사전 정의된 중단 기준이 충족될 때까지 반복된다.
5.2 Agent 컴포넌트와 인사이트 통합
Agent 컴포넌트는 LLM을 사용하여 구현되며, 테스트 타임 스케일링에 대한 도메인 지식이 부족한 LLM의 한계를 세 가지 인사이트의 통합으로 보완한다. Insight 1의 통합은 초기 탐색 단계에서 수행된다. 서로 다른 서브태스크가 특정 역량의 모델을 선호한다는 인사이트에 기반하여, 적합한 모델을 조기에 매칭함으로써 탐색을 효과적인 구성 방향으로 유도하고 열등한 옵션에 대한 낭비를 줄인다. 구체적으로 초기화 단계에서 각 서브태스크 $T_i$에 대해 사용 가능한 가장 큰 모델의 예산 $B_i^{\max}$와 가장 작은 모델의 예산 $B_i^{\min}$을 계산한다. 그리고 대상 서브태스크의 모든 후보 모델을 비교하되, 다른 서브태스크들은 각각 사용 가능한 가장 큰 모델로 고정하여 단일 패스 추론을 수행함으로써 공정한 비교를 보장한다.
초기 시행과 후속 단계의 시행 생성을 형식화하면 다음과 같다:
$$\mathcal{C} = \begin{cases} \{(\ldots, M_i, B_i, \ldots) \mid 1 \leq i \leq N, M_i \in \mathcal{M}_i, B_i = B_i^{\max}\}, & \text{initial stage} \\ \{c \mid c \in \mathcal{A}.\texttt{generate}(\mathcal{G}, \mathcal{M}, \mathcal{T}, B)\}, & \text{subsequent stages} \end{cases}$$
여기서 각 시행은 $c = (M_1, B_1, \ldots, M_n, B_n)$으로 표현되며, $M_i \in \mathcal{M}_i$는 선택된 모델, $B_i$는 서브태스크 $i$에 할당된 예산이다. 초기 피드백을 수신한 후, Agent는 성능 비교에 기반하여 초기 가이드라인 $\mathcal{G}$를 요약한다. 대형 모델이 소형 모델을 현저히 능가하면 대형 모델이 선호되고, 그렇지 않으면 후속 탐색에서의 유연성 때문에 소형 모델이 선호된다.
Insight 2의 통합에서는, 테스트 타임 연산 증가가 초기에는 성능을 향상시키지만 최적점을 넘어서면 진동이나 성능 저하를 초래할 수 있다는 인사이트를 가이드라인 생성 프롬프트에 포함시킨다. LLM에게 "각 서브태스크에 대한 최적 샘플 수를 찾기 위한 탐색 방향을 식별"하라고 지시함으로써, 에이전트가 다음 탐색 라운드를 올바른 범위 내에서 집중할 수 있도록 하여 최적 할당으로의 수렴을 가속화한다. 예를 들어, Agent가 이전 시행에서 "8B 모델로 10개 샘플(EM=0.78)이 20개 샘플(EM=0.76)보다 우수했다"는 피드백을 받으면, Insight 2에 기반하여 "이 서브태스크의 최적 샘플 수는 5-15 범위에 있을 가능성이 높으므로, 다음 시행에서는 이 범위를 집중적으로 탐색"이라는 가이드라인을 생성한다. 이러한 범위 축소 메커니즘이 불필요한 탐색을 방지하고 수렴을 가속화하는 핵심 동력이 된다.
Insight 3의 통합에서는, 선행 서브태스크의 예산 할당이 하류 서브태스크의 모델 선택과 샘플링 요구에 영향을 미친다는 인사이트를 프롬프트에 내장한다. 제한된 예산 하에서 모든 서브태스크에 최적 구성을 할당할 수 없으며, 한 서브태스크에 더 많은 자원을 할당하면 다른 서브태스크의 최적 설정이 변경될 수 있다. 이를 위해 LLM의 계획 능력을 활용하여 서브태스크 간 할당 트레이드오프를 탐색하는 지시를 프롬프트에 삽입한다. 구체적으로, Agent는 "검색 서브태스크에 72B 모델 1개 샘플을 사용하면 고품질 검색 결과가 생성되어, QA 서브태스크에서는 3B 모델 10개 샘플만으로도 충분한 성능을 달성할 수 있다. 반면 검색에 8B 모델 5개 샘플을 사용하면 중간 품질의 검색 결과가 생성되어, QA에서는 70B 모델이 필요해질 수 있다"와 같은 크로스-서브태스크 추론을 수행하도록 안내된다. 이러한 서브태스크 간 상호작용에 대한 명시적 추론은 기존 HPO 방법들에서는 제공되지 않는 AgentTTS만의 고유한 능력이다.
5.3 알고리즘 흐름과 Environment 및 Archive 컴포넌트
AgentTTS의 전체 알고리즘(Algorithm 1)은 다음과 같은 체계적 흐름으로 진행된다. 입력으로 Agent $\mathcal{A}$, 모델 집합 $\mathcal{M}$, 서브태스크 $\mathcal{T}$, Environment $\mathcal{E}$, 총 예산 $B$가 주어진다. 알고리즘의 각 단계를 상세히 살펴보면 다음과 같다.
1단계(초기화): 실험 아카이브 $\mathcal{L}$을 빈 집합으로 초기화하고, Insight 1에 기반하여 초기 후보 시행 $\mathcal{C}$를 생성한다. 이 초기 시행들은 각 서브태스크에 대해 사용 가능한 모든 후보 모델을 최대 예산으로 테스트하되, 나머지 서브태스크는 가장 큰 모델의 단일 패스로 고정하여 공정한 비교를 보장한다. 2단계(초기 평가): 생성된 시행들을 Environment에 제출하여 실행하고, 성능 피드백 $\mathcal{S}$를 수집한다. 3단계(반복 탐색): 중단 기준이 충족될 때까지 다음을 반복한다. Agent가 현재 시행과 피드백을 기반으로 Insight 2와 3을 활용하여 탐색 가이드라인 $\mathcal{G}$를 생성하고, 실험 로그를 $(C, S, G)$ 튜플로 갱신하며, 가이드라인에 기반하여 새로운 후보 시행을 생성하고, 이를 Environment에서 평가한다. 4단계(종료): 아카이브 $\mathcal{L}$에서 최고 성능 시행을 반환한다.
Environment 컴포넌트는 Archive로부터 시행을 수신하면 이를 실행 가능한 스크립트로 변환하여 태스크 플랫폼에 제출하는 역할을 담당한다. 각 시행은 모델 선택과 샘플 수 등의 구성을 포함하며, Environment는 이를 실제 추론 파이프라인의 설정으로 매핑한다. 소규모 훈련 세트(50개 샘플)에서 실행한 후, 해당 태스크의 평가 메트릭(EM, F1, Consistency 등)에 따른 성능 피드백을 Agent에 반환한다. 이 과정에서 실제 추론을 수행해야 하므로, 각 시행의 평가에는 상당한 시간(수 분에서 수 시간)이 소요될 수 있으며, 이것이 탐색 효율성이 중요한 근본적 이유이다.
Archive 컴포넌트는 두 가지 핵심 베이스를 관리한다. 가이드라인 베이스(Guideline Base)는 각 반복에서 생성된 탐색 가이드라인을 저장하며, 시간에 따른 가이드라인의 진화를 추적한다. 시행 베이스(Trial Base)는 생성된 후보 시행과 대응하는 성능 피드백을 저장한다. Archive는 반복 과정 전체에 걸쳐 탐색의 이력을 체계적으로 기록하므로, Agent가 과거의 탐색 경험을 참조하여 더 정보에 기반한 의사결정을 내릴 수 있도록 지원한다. 종료 시에는 저장된 모든 시행 중 최고 성능을 달성한 시행을 출력한다. 이 세 컴포넌트의 유기적 상호작용을 통해 AgentTTS는 해석 가능한 가이드라인 생성에 기반한 투명한 의사결정과, 비매끄러운 탐색 지형에서의 강건한 탐색이라는 두 가지 핵심 이점을 제공한다.
5.4 기존 HPO 방법과의 구조적 비교
AgentTTS의 설계를 기존 LLM 기반 HPO 방법들과 구조적으로 비교하면 차별점이 더 명확해진다. 다음 표는 AgentTTS와 주요 베이스라인의 핵심 설계 차이를 정리한 것이다.
| 특성 | AgentTTS | AgentHPO | MLCopilot | LLM_ZS |
|---|---|---|---|---|
| 초기화 | Insight 1 기반 모델 선호도 탐색 | LLM 자율 생성 | 유사 태스크 경험 전이 | 직접 프롬프팅 |
| 가이드라인 생성 | Insight 2, 3 통합 | 일반적 피드백 기반 | 일반적 피드백 기반 | 가이드라인 없음 |
| 도메인 지식 | TTS 특화 인사이트 3개 | 없음 | 없음 | 없음 |
| 서브태스크 의존성 고려 | 명시적 (Insight 3) | 암시적 | 암시적 | 없음 |
| 해석 가능성 | 높음 (명시적 가이드라인) | 중간 | 중간 | 낮음 |
이 비교에서 핵심적인 차이는 AgentTTS가 테스트 타임 스케일링에 특화된 세 가지 검증된 인사이트를 탐색 과정의 각 단계에 체계적으로 통합한다는 점이다. AgentHPO와 MLCopilot은 가이드라인 기반 탐색이라는 유사한 프레임워크 구조를 공유하지만, 테스트 타임 스케일링의 특수한 패턴에 대한 사전 지식이 없어 더 많은 시행착오가 필요하다. 이들은 범용 HPO의 일반적 원칙(예: "이전에 좋았던 구성 근처를 탐색한다")에만 의존하므로, 다단계 태스크의 고유한 특성을 포착하는 데 한계가 있다. LLM_ZS는 가이드라인 자체가 없어 순수히 LLM의 제로샷 추론 능력에만 의존하므로 가장 비효율적이며, 이는 LLM이 테스트 타임 스케일링이라는 비교적 새로운 기법에 대한 충분한 사전 지식을 내재적으로 보유하지 않기 때문이다. AgentTTS의 Insight 1은 초기 탐색 공간을 대폭 축소하여 모델-서브태스크 매핑의 올바른 방향을 조기에 설정하고, Insight 2는 각 서브태스크의 유효 예산 범위를 좁혀 불필요한 과다 샘플링을 방지하며, Insight 3는 서브태스크 간의 상호작용을 명시적으로 모델링하여 전역 최적을 향한 크로스-서브태스크 추론을 가능하게 한다. 이 세 차원에서의 동시적 최적화가 효율적인 수렴을 가능하게 한다.
6. 실험 설정
6.1 데이터셋 및 벤치마크
논문은 네 가지 태스크 유형에 걸친 여섯 개의 데이터셋에서 실험을 수행한다. 이러한 다양한 태스크 선택은 AgentTTS의 범용성을 검증하기 위한 것으로, 각 태스크 유형은 서로 다른 특성의 다단계 파이프라인을 포함한다.
검색 기반 질의응답(Retrieval-based QA)은 2WikiMultiHopQA와 HotpotQA 데이터셋을 사용한다. 2WikiMultiHopQA는 두 개 이상의 위키피디아 문서를 거쳐야 하는 멀티홉 추론을 요구하는 질의응답 데이터셋으로, 복잡한 추론 체인이 필요하다. HotpotQA 역시 멀티홉 추론 기반의 질의응답 데이터셋이다. 이 태스크는 검색(retrieval)과 질의응답(QA)의 두 서브태스크로 구성되며, 검색 서브태스크에서는 관련 문서를 찾아 추출하고, QA 서브태스크에서는 검색된 문서를 기반으로 질문에 답변한다. 평가 메트릭으로 Exact Match(EM)를 사용한다.
지식 그래프 질의응답(Knowledge Graph QA)은 CWQ(ComplexWebQuestions)와 WebQSP(WebQuestionsSP) 데이터셋을 사용한다. 이 태스크는 지식 그래프에서 관련 정보를 검색하는 서브태스크와 이를 기반으로 답변을 생성하는 서브태스크로 구성된다. CWQ는 복잡한 구성적 질문을 포함하여 난이도가 높으며, WebQSP는 상대적으로 간단한 질문을 포함한다. 평가 메트릭으로 역시 EM을 사용한다.
태스크 자동화(Task Automation)는 TaskBench 데이터셋을 사용하며, 세 개의 서브태스크로 구성된다. 태스크 분해(task decomposition)는 복잡한 사용자 지시를 하위 태스크로 분할하고, 도구 선택(tool selection)은 각 하위 태스크에 적합한 도구를 선택하며, 파라미터 예측(parameter prediction)은 선택된 도구에 입력할 파라미터를 예측한다. 평가 메트릭으로 precision-F1(p-F1)을 사용한다.
자동 소프트웨어 개발(Automated Software Development)은 ChatDev 데이터셋을 사용하며, 요구사항 분석, 시스템 설계, 코딩, 테스트로 이어지는 네 단계의 폭포수 방식 개발 프로세스를 포함한다. 이 태스크는 서브태스크 수가 가장 많고 각 단계의 상호의존성이 매우 높다는 점에서 가장 복잡한 설정이다. 평가 메트릭으로 Consistency(Cons.) 점수를 사용한다. 다음 표는 각 태스크의 구성을 요약한 것이다.
| 태스크 유형 | 데이터셋 | 서브태스크 수 | 서브태스크 구성 | 평가 메트릭 |
|---|---|---|---|---|
| 검색 기반 QA | 2WikiMultiHopQA | 2 | 검색 + QA | EM |
| 검색 기반 QA | HotpotQA | 2 | 검색 + QA | EM |
| 지식 그래프 QA | CWQ | 2 | 검색 + QA | EM |
| 지식 그래프 QA | WebQSP | 2 | 검색 + QA | EM |
| 태스크 자동화 | TaskBench | 3 | 분해 + 도구 선택 + 파라미터 예측 | p-F1 |
| 자동 SW 개발 | ChatDev | 4 | 요구분석 + 설계 + 코딩 + 테스트 | Cons. |
각 태스크의 서브태스크는 프롬프트와 생성 길이가 상이하여 서로 다른 연산 자원을 요구한다. 검색 서브태스크는 일반적으로 더 긴 프롬프트를 사용하는 반면, QA 서브태스크는 더 긴 생성 길이를 필요로 한다. 사용된 모델은 3B에서 72B 파라미터 범위의 LLaMA-3 및 Qwen2.5 계열 모델이며, 서브태스크별 모델 선택 분석(Appendix A.5)을 통해 검색 관련 서브태스크에는 Qwen 계열, 나머지에는 LLaMA-3 계열이 선택되었다. 이러한 모델 계열 선택은 각 서브태스크의 특성에 맞는 모델 역량을 활용하기 위한 것으로, 검색에서의 긴 문맥 이해와 QA에서의 정보 추출 능력이 모델 계열에 따라 차이를 보이기 때문이다.
논문은 부록(Appendix A.5)에서 모델 계열 선택의 근거를 상세히 제시한다. 각 서브태스크에 대해 모든 비대상 서브태스크를 LLaMA-3 70B의 단일 패스 추론으로 고정한 상태에서, 대상 서브태스크의 모델 크기와 계열에 따른 성능을 비교한다. 이 비교는 두 가지 주요 모델 계열(LLaMA-3와 Qwen2.5)에 대해 3B, 8B, 70B/72B 크기에서 수행된다. 2Wiki와 HotpotQA의 검색 서브태스크에서는 Qwen2.5 계열이 LLaMA-3 계열보다 일관되게 높은 Ret_F1을 달성하는 반면, QA 서브태스크에서는 LLaMA-3 계열이 더 나은 Gen_EM을 보인다. 이는 Qwen2.5 계열이 긴 문맥 이해에 더 특화되어 있어 검색 태스크에서 유리하고, LLaMA-3 계열이 정보 추출과 추론에 더 강점을 보여 QA 태스크에서 유리하기 때문으로 해석된다. CWQ와 WebQSP에서도 유사한 패턴이 관찰되며, TaskBench의 세 서브태스크(분해, 도구 선택, 파라미터 예측) 모두에서는 LLaMA-3 계열이 더 우수한 성능을 보인다. ChatDev는 중간 단계의 개별 서브태스크 수준 평가 메트릭이 제공되지 않아 이 서브태스크별 분석에서 제외된다. 이러한 체계적인 모델 선택 과정은 AgentTTS의 탐색 공간을 합리적으로 제한하는 데 기여하며, 이 자체가 Insight 1의 구체적 실현이라 할 수 있다.
6.2 구현 세부사항
실험의 주요 구현 세부사항은 다음과 같다.
- 탐색 반복 횟수: 모든 방법은 50회의 탐색 반복(iteration)을 수행한다. 각 반복에서 하나 이상의 후보 시행이 생성되고 평가된다.
- 훈련 세트: 50개 샘플로 구성된 훈련 세트에서 탐색을 수행한다. 이 소규모 훈련 세트는 현실적인 설정을 반영하며, 강건성 평가에서 75개 및 100개로도 실험된다.
- 테스트 세트: 500개 샘플로 구성된 테스트 세트에서 최종 평가를 수행한다. 훈련 세트의 10배 규모이므로 일반화 성능의 신뢰할 수 있는 평가가 가능하다.
- LLM 탐색 에이전트: GPT-o3-mini를 LLM 탐색 에이전트로 사용한다. 이 모델은 추론 능력과 비용 효율성의 균형을 고려하여 선택되었다.
- 기본 예산: 기본 예산은 900으로 설정되며, 이는 가장 큰 모델을 사용하여 각 서브태스크에서 단일 패스 추론을 수행하는 데 필요한 최소 예산의 합에 해당한다.
- 비용 메트릭: 주요 비용 메트릭으로 추론 FLOPs를 사용하며, API 가격 기반 메트릭도 추가 실험에서 일반화 능력 검증을 위해 사용된다.
- 온도 설정: 다양한 생성을 유도하기 위해 온도를 0.9로 고정한다. 이 온도 값은 출력 다양성과 품질의 균형을 고려한 것으로, 별도의 온도 실험에서 그 적절성이 검증된다.
- 퓨전 설정: 생성과 퓨전 모두에 동일한 LLM을 사용한다. 퓨전 프롬프트는 여러 후보 응답을 입력으로 받아 통합된 최종 응답을 생성하도록 설계되었으며, 추가적인 보상 모델이나 검증기는 사용하지 않는다.
탐색 과정에서의 연산 비용은 주로 각 시행의 평가에서 발생한다. 각 시행을 평가하려면 해당 구성(모델, 샘플 수)으로 훈련 세트의 50개 샘플에 대해 실제 추론을 수행해야 하므로, 시행당 수 분에서 수 시간의 GPU 시간이 소요된다. 이것이 탐색 효율성이 AgentTTS의 핵심 기여인 이유이다. 50회 반복 내에 최적 구성을 발견하는 것과 10회 내에 발견하는 것의 차이는 실질적으로 수십 시간의 GPU 시간 차이를 의미한다. Table 1에서 보고된 탐색 시간은 이러한 실제 추론 시간을 포함한 것으로, AgentTTS의 시간 절감이 실질적인 연산 비용 절감으로 직결됨을 보여준다.
6.3 베이스라인
비교 대상 베이스라인은 크게 전통적 머신러닝 방법과 LLM 기반 방법의 두 그룹으로 나뉜다. 전통적 베이스라인으로는 베이지안 최적화(BO)와 랜덤 서치(Random Search)가 포함된다. LLM 기반 접근법으로는 세 가지가 고려된다.
- AgentHPO: 피드백 기반 가이드라인 생성과 가이드라인 기반 후보 시행 생성의 2단계 파이프라인을 사용하며, LLM이 자율적으로 초기 가이드라인을 생성한다.
- MLCopilot: AgentHPO와 유사한 2단계 파이프라인을 사용하지만, 유사 태스크에서 관찰된 성능 추세에 기반하여 가이드라인을 초기화한다.
- LLM_ZS(Zero-Shot): 가이드라인이나 외부 참조 없이 LLM에 직접 프롬프트하여 후보 시행을 생성한다.
이러한 LLM 기반 방법들은 원래 하이퍼파라미터 튜닝용으로 제안되었으나, 논문에서는 테스트 타임 예산 할당 문제에 적응시켜 사용한다. 적응 과정에서 각 방법의 "하이퍼파라미터"를 "(모델 선택, 샘플 수) 튜플의 시퀀스"로 재정의하고, 평가 메트릭을 해당 태스크의 성능 메트릭(EM, F1, Consistency)으로 설정한다. AgentHPO와 MLCopilot 모두 피드백 기반 가이드라인 생성과 가이드라인 기반 후보 시행 생성이라는 동일한 파이프라인 구조를 따르지만, 가이드라인 초기화 방식에서 차이를 보인다. AgentHPO는 LLM이 사전 지식만으로 초기 가이드라인을 생성하는 반면, MLCopilot은 유사 태스크(예: 다른 데이터셋의 동일 유형 태스크)에서 관찰된 성능 패턴을 참조하여 초기 가이드라인을 구성한다. LLM_ZS는 가이드라인이나 피드백 루프 없이 LLM의 제로샷 능력만으로 직접 후보 구성을 생성하는 방식이다. 이전 시행의 결과를 활용하지 않으므로 가장 단순한 접근법이지만, 학습 없이 매 시행을 독립적으로 생성하기 때문에 탐색 효율성이 가장 낮은 베이스라인이다.
7. 주요 실험 결과: 탐색 효율성과 성능 분석
7.1 탐색 효율성 및 테스트 성능

Figure 3: 50회 시행에 걸친 다양한 탐색 방법의 성능 궤적. X축은 시행 횟수, Y축은 해당 시행까지의 최고 성능. 'Best Score'는 사전 그리드 서치에서 얻은 최적 시행의 점수로 모든 방법의 벤치마크 역할을 한다.
Figure 3은 훈련 세트에서의 테스트 타임 연산 최적 예산 할당에 대한 AgentTTS와 베이스라인의 탐색 궤적을 보여준다. 각 그래프에서 X축은 시행 횟수, Y축은 해당 시행까지의 최고 성능을 나타내며, 점선으로 표시된 'Best Score'는 사전 그리드 서치에서 얻은 최적 시행의 점수로 모든 방법의 도달 목표 벤치마크 역할을 한다. 여섯 개 데이터셋 전반에 걸쳐 AgentTTS는 다른 모든 방법보다 빠르게 최적 성능에 수렴하는 것이 관찰된다. 특히 2WikiMultiHopQA, HotpotQA, CWQ, WebQSP 데이터셋에서 AgentTTS는 10회 미만의 시행 내에 최적 또는 최적에 근접한 구성을 발견하는 반면, 베이스라인 방법들은 동일 수준에 도달하기 위해 훨씬 더 많은 시행을 필요로 한다. TaskBench과 ChatDev에서는 AgentTTS 역시 최적에 도달하기까지 다소 더 많은 시행이 필요하지만, 이는 이 태스크들이 3-4개의 서브태스크를 포함하여 탐색 공간이 더 크기 때문으로 해석된다.
Table 1은 탐색 시간(시간 단위)과 테스트 세트 성능의 비교를 제시한다. 주요 관찰 결과를 정리하면 다음과 같다.
| Method | 2Wiki (Time/EM) | Hotpot (Time/EM) | CWQ (Time/EM) | WebQSP (Time/EM) | TaskBench (Time/p-F1) | ChatDev (Time/Cons.) |
|---|---|---|---|---|---|---|
| Random | – / 0.66 | – / 0.71 | – / 0.76 | – / 0.86 | – / 0.40 | – / 0.74 |
| BO | – / 0.60 | – / 0.71 | – / 0.76 | – / 0.85 | – / 0.52 | – / 0.75 |
| LLM_ZS | 12.5h / 0.70 | – / 0.71 | 55.3h / 0.76 | 37.7h / 0.89 | – / 0.49 | – / 0.74 |
| MLCopilot | 12.5h / 0.70 | 46.3h / 0.72 | 48.4h / 0.78 | 20.8h / 0.88 | – / 0.53 | – / 0.75 |
| AgentHPO | 8.3h / 0.70 | 36.3h / 0.74 | 37.4h / 0.78 | 48.1h / 0.89 | – / 0.49 | – / 0.74 |
| AgentTTS (Ours) | 2.5h / 0.72 | 17.5h / 0.74 | 11.1h / 0.78 | 7.8h / 0.89 | 64.3h / 0.53 | 14.3h / 0.75 |
Table 1에서 "–"는 사용 불가능한 결과 또는 최적 시행을 찾지 못한 경우를 나타낸다. 핵심 관찰 결과는 다음과 같다. 첫째, AgentTTS는 대부분의 태스크에서 탐색 효율성과 테스트 세트 성능 모두에서 베이스라인을 능가한다. 가장 높은 결과를 달성할 뿐 아니라 더 적은 시행으로 이를 달성한다. 예를 들어 2WikiMultiHopQA에서 AgentTTS는 단 2.5시간만에 최적 구성을 발견하며, 이는 차선의 방법인 AgentHPO의 8.3시간과 비교하여 70% 이상의 시간 절감을 의미한다. 또한 테스트 세트에서 0.72의 EM 점수를 달성하여 차선 방법들(0.70)을 2% 포인트 상회한다.
둘째, LLM 에이전트 기반인 AgentHPO 및 MLCopilot과 비교할 때, AgentTTS는 더 빠르게 수렴하여 통합된 인사이트가 연산 최적 할당에 대한 탐색 효율성을 개선함을 보여준다. 특히 HotpotQA에서 AgentTTS는 17.5시간만에 최적 구성을 발견하는 반면, AgentHPO는 36.3시간, MLCopilot은 46.3시간이 소요된다. CWQ에서도 AgentTTS(11.1시간)는 AgentHPO(37.4시간) 대비 약 70%의 시간 절감을 달성한다. 이는 테스트 타임 스케일링에 특화된 인사이트가 범용 HPO 전략보다 현저히 효율적임을 입증한다.
셋째, BO와 같은 전통적 방법은 비매끄러운 지형으로 인해 종종 지역 최적값에 갇히는 문제를 보인다. 이는 테스트 타임 스케일링의 비단조적 성능 곡선(Insight 2)과 서브태스크 간 상호의존성(Insight 3)이 탐색 지형을 매우 비매끄럽게 만들기 때문이다. BO는 가우시안 프로세스를 사용한 대리 모델링에 의존하는데, 비매끄러운 지형에서는 대리 모델의 정확도가 저하되어 효과적인 탐색이 어렵다. 반면 랜덤 서치는 탐색 지형의 특성에 무관하게 균일하게 탐색하므로 잡음에는 강하지만 수렴이 매우 느리다. 특히 2WikiMultiHopQA에서 BO의 테스트 EM은 0.60으로, 랜덤 서치(0.66)보다도 낮은 성능을 보이는데, 이는 BO가 지역 최적값에 수렴하여 전역 최적에서 벗어난 구성을 선택했기 때문이다. LLM 기반 방법들은 사전 하이퍼파라미터 튜닝 지식과 자연어 추론 능력을 활용하여 차선 영역을 우회함으로써 더 나은 탐색 성능을 달성한다.
넷째, 훈련 세트와 테스트 세트 간의 일반화 성능에서도 AgentTTS가 우수하다. 일부 베이스라인은 훈련 세트에서 유사한 성능을 달성하더라도 테스트 세트에서 성능 저하를 보이는 반면, AgentTTS는 일관되게 높은 테스트 성능을 유지한다. 2WikiMultiHopQA에서 AgentTTS의 테스트 EM(0.72)이 차선 방법들(0.70)을 2% 포인트 상회하는 것이 대표적이다. 논문은 이러한 일반화 성능의 우위가 Insight 2가 최소 필요 예산을 식별하여 과도한 샘플링을 방지하고, 이를 통해 과적합을 줄이는 효과에 기인한다고 분석한다.
7.2 다양한 예산 설정에서의 성능

Figure 6: 저(500), 중(900, 기본), 고(2000) 연산 예산 설정에서의 비교 탐색 결과. AgentTTS는 모든 예산 수준에서 일관되게 베이스라인을 능가한다.
다양한 예산 설정에서의 탐색 효율성을 평가하기 위해, 논문은 2WikiMultiHopQA에서 두 가지 추가 예산 설정을 실험한다. 저예산(500) 설정은 하나의 서브태스크만 최적값에 도달할 수 있는 제약적 상황이며, 고예산(2000) 설정은 모든 서브태스크가 최적값에 도달할 수 있지만 탐색 공간이 확장되는 상황이다. 기본 설정에 해당하는 중간 예산(900)은 일부 서브태스크가 최적에 도달하되 모든 서브태스크의 동시 최적화는 불가능한 중간적 상황을 나타낸다.
Figure 6에서 보여주듯이, AgentTTS는 저예산에서도 최적 구성을 발견하여 서브태스크 상호의존성에 대한 트레이드오프에서 통합된 인사이트의 이점을 확인해 준다. 저예산 설정에서의 성공은 특히 주목할 만한데, 이 상황에서는 한 서브태스크에 예산을 집중하면 다른 서브태스크의 성능이 크게 저하되므로, 서브태스크 간 트레이드오프를 정확하게 파악하는 것이 핵심이다. AgentTTS의 Insight 3가 이러한 상호의존성을 명시적으로 모델링함으로써, 제한된 예산 내에서도 전체 성능을 극대화하는 구성을 효율적으로 발견한다. 고예산 설정에서는 탐색 공간이 크게 확장되어 더 많은 유효한 구성이 존재하지만, 동시에 무관한 구성도 크게 증가한다. 이 상황에서도 AgentTTS는 Insight 1과 2를 통해 탐색 공간을 효과적으로 축소하여 베이스라인보다 빠르게 최적에 수렴한다. 저예산에서 고예산까지의 모든 설정에서 AgentTTS가 일관되게 베이스라인을 탐색 효율성에서 능가하여, 인사이트 기반 LLM 에이전트가 확장된 탐색 공간에도 강건함을 보여준다.
7.3 온도에 따른 성능 변화
테스트 타임 스케일링에서 온도의 영향을 평가하기 위해, 논문은 2Wiki 데이터셋에서 추가 실험을 수행한다. 검색기는 Qwen2.5-72B(단일 검색 결과 생성)로 고정하고, QA 모델 LLaMA 3 3B에 대해 샘플 수와 온도 값을 변화시킨다. Table 2의 결과를 통해 흥미로운 패턴을 관찰할 수 있다.
| Samples | Temp = 0.1 | Temp = 0.5 | Temp = 0.9 |
|---|---|---|---|
| 1 | 0.70 | 0.64 | 0.66 |
| 10 | 0.70 | 0.78 | 0.78 |
| 20 | 0.72 | 0.76 | 0.78 |
| 30 | 0.74 | 0.78 | 0.72 |
| 40 | 0.74 | 0.76 | 0.78 |
| 50 | 0.74 | 0.72 | 0.78 |
| 60 | 0.74 | 0.78 | 0.80 |
| 70 | 0.76 | 0.72 | 0.74 |
| 80 | 0.76 | 0.76 | 0.78 |
| 90 | 0.74 | 0.72 | 0.76 |
Table 2의 결과에 따르면, 높은 온도(예: 0.9)는 다중 샘플 상황에서 성능을 향상시키는 반면, 낮은 온도(예: 0.1)는 단일 샘플 상황에서 더 효과적이다. 이는 높은 온도가 출력 다양성과 샘플링 기반 추론에서의 퓨전을 향상시키는 반면, 낮은 온도는 더 안정적이고 결정론적인 출력을 촉진하기 때문이다. 온도 0.9에서 60개 샘플일 때 최고 EM 점수 0.80을 달성하는 것이 관찰되며, 이는 온도 유도 다양성이 추론 태스크에서 샘플 효율성을 향상시킨다는 기존 연구 결과와 일치한다. 이러한 결과는 반복 샘플링 기반 테스트 타임 스케일링에서 높은 온도 설정의 중요성을 실증적으로 뒷받침한다.
흥미로운 점은 온도 0.1에서 단일 샘플(1개)의 EM이 0.70으로, 온도 0.9에서의 0.66보다 높다는 것이다. 이는 단일 샘플 상황에서는 다양성이 필요하지 않으므로 결정론적 출력이 더 높은 정확도를 제공하기 때문이다. 반면 10개 이상의 샘플에서는 온도 0.9가 일관되게 높은 성능을 보이는데, 이는 높은 온도가 다양한 관점의 후보 응답을 생성하여 퓨전 과정에서 보완적 정보를 활용할 수 있게 하기 때문이다. 또한 온도 0.5는 중간적 성능을 보이며, 30개 샘플에서 0.78로 온도 0.9(0.72)보다 높은 경우도 있어 온도 설정이 샘플 수와 상호작용하는 비선형적 관계를 보여준다. 이 실험 결과는 AgentTTS에서 온도를 0.9로 고정한 설계 결정의 합리성을 뒷받침하면서도, 향후 온도를 추가적인 최적화 변수로 포함시키는 확장의 가능성을 시사한다.
7.4 API 가격 기반 비용 메트릭
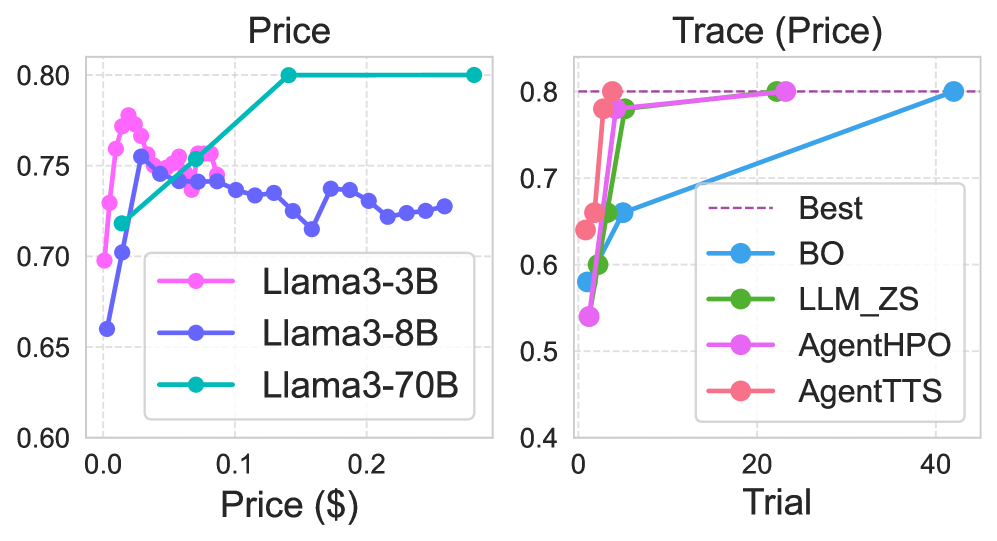
Figure 7: API 가격 예산 하의 테스트 타임 스케일링 및 AgentTTS 탐색 궤적. 왼쪽: 스케일링 곡선, 오른쪽: 해당 탐색 궤적. 가격 기반 메트릭에서도 AgentTTS의 인사이트가 탐색 효율성을 개선한다.
추론 FLOPs 외에 최종 사용자가 더 관심을 가질 수 있는 금전적 비용(API 가격)을 대안적 예산 메트릭으로 도입하여 추가 실험을 수행한다. Figure 7 왼쪽은 API 가격 메트릭을 사용한 2WikiMultiHopQA의 QA 서브태스크에 대한 테스트 타임 스케일링 곡선을 보여준다. 결과는 제한된 예산 하에서 소형 모델이 여전히 선호되는 것으로 나타나며, 이는 FLOPs 기반 실험과 일관된 경향이다. Figure 7 오른쪽에서 보이듯이, 제안된 인사이트는 API 가격 메트릭 하에서도 AgentTTS의 탐색 효율성과 성능을 지속적으로 향상시켜, 다양한 비용 메트릭에 걸친 강한 일반화 능력을 입증한다. 이는 AgentTTS의 세 가지 인사이트가 특정 비용 메트릭에 종속되지 않는 범용적인 테스트 타임 스케일링 특성을 포착하고 있음을 시사한다.
8. 추가 분석 및 Ablation Study
8.1 Ablation Study: 인사이트별 기여도 분석
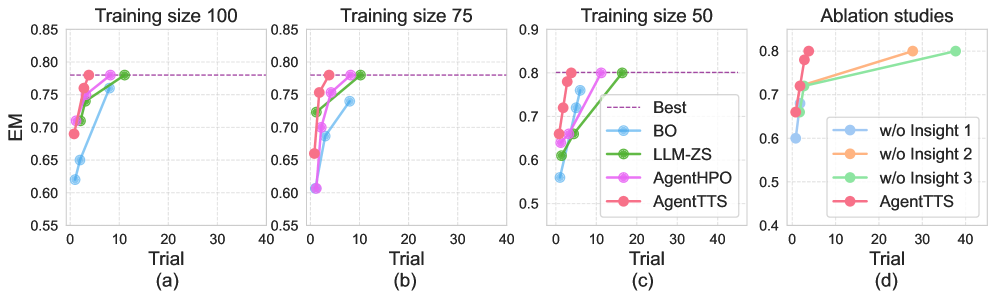
Figure 4: (a-c) 2WikiMultiHopQA에서 다양한 훈련 세트 크기에 따른 탐색 궤적. (d) 총 예산 900에서의 ablation study. Insight 1, 2, 3 각각을 제거했을 때의 성능 변화를 보여준다.
AgentTTS에서 각 인사이트의 기여를 평가하기 위해, 논문은 개별 인사이트를 제거한 변형과 비교하는 ablation study를 수행한다. AgentTTS-w/o-Insight1은 Insight 1을 랜덤 초기화로 대체하고, AgentTTS-w/o-Insight2는 최적 예산 이후의 수확 체감을 다루는 프롬프트 구성요소를 제거하며, AgentTTS-w/o-Insight3는 서브태스크 간 상호의존성을 다루는 프롬프트 구성요소를 제거한다.
Figure 4(d)에서 보이는 결과는 다음과 같다. AgentTTS-w/o-Insight1(Insight 1 제거)은 50회 반복 내에 최적 구성에 도달하지 못하는 것으로 나타난다. 이는 초기 모델 선택이 후속 탐색을 안내하는 데 핵심적인 역할을 함을 보여준다. 랜덤 초기화를 사용하면 탐색의 초기 방향이 무작위로 설정되어, 부적합한 모델-서브태스크 매핑에서 출발하는 경우 이후의 반복적 정제로도 이를 극복하기 어렵다. 예를 들어, 검색 서브태스크에 소형 모델이 배정되고 QA 서브태스크에 대형 모델이 배정되는 역방향 초기화가 이루어지면, 이후 가이드라인이 이 잘못된 초기 할당을 기준으로 생성되므로 전체 탐색이 차선 영역에 갇히게 된다.
AgentTTS-w/o-Insight2(Insight 2 제거)에서는 탐색 효율성이 저하되어 최적 시행이 29단계까지 지연된다. Insight 2가 없으면 Agent는 "더 많은 샘플이 항상 더 나은 성능을 의미한다"는 잘못된 가정 하에 탐색을 수행할 수 있으며, 최적 예산을 초과하는 구성들을 반복적으로 시도하여 탐색 자원을 낭비한다. 이는 서브태스크별 최적 예산을 식별하는 것이 효율적인 탐색에 필수적임을 보여준다. AgentTTS-w/o-Insight3(Insight 3 제거)에서는 최적 시행이 38단계까지 더욱 지연된다. Insight 3이 없으면 Agent는 각 서브태스크를 독립적으로 최적화하려 하여, 서브태스크 간 예산 할당의 상호의존성을 포착하지 못한다. 이로 인해 한 서브태스크의 예산 변경이 다른 서브태스크에 미치는 영향을 무시한 채 탐색이 진행되어, 전역 최적에 도달하기까지 더 많은 시행착오가 필요해진다.
이 ablation 결과는 세 가지 인사이트 모두가 AgentTTS의 성능에 상보적으로 기여하며, 어느 하나라도 빠지면 탐색 효율성이 현저히 저하됨을 명확히 입증한다. 인사이트별 기여도를 정량적으로 비교하면 다음과 같다.
| 변형 | 제거된 인사이트 | 최적 도달 시행 | 영향 수준 |
|---|---|---|---|
| AgentTTS (full) | 없음 | ~5단계 | 기준선 |
| w/o Insight 1 | 서브태스크별 모델 선호도 | 미도달 (50회 내) | 가장 심각 |
| w/o Insight 2 | 최적 예산 수확 체감 | 29단계 | 효율성 저하 |
| w/o Insight 3 | 서브태스크 간 상호의존 | 38단계 | 수렴 지연 |
Insight 1의 부재가 가장 심각한 영향을 미치고(최적 미도달), Insight 3의 부재(38단계까지 지연)가 Insight 2의 부재(29단계까지 지연)보다 더 큰 영향을 미친다. 이는 초기화의 올바름이 가장 결정적이며, 서브태스크 간 상호의존성 모델링이 서브태스크별 예산 범위 식별보다 더 복잡하고 중요한 문제임을 시사한다.
8.2 학습 세트 크기에 대한 강건성
소규모 훈련 세트는 불안정한 성능을 초래하여 비매끄러운 탐색 지형을 생성하고 최적화를 방해할 수 있다. 이러한 조건에서의 강건성을 평가하기 위해, 논문은 훈련 세트 크기를 50, 75, 100개 샘플로 변화시키며 각 탐색 방법의 효과를 평가한다. Figure 4(a-c)에서 보이듯이, LLM 기반 베이스라인과 베이지안 최적화의 탐색 효율성은 훈련 세트가 작아질수록 저하되는 반면, AgentTTS는 일관된 효율성을 유지한다.
이는 AgentTTS에 통합된 경험적 인사이트가 LLM 에이전트에게 가치 있는 사전 지침(prior guidance)을 제공하여 비매끄러운 탐색 공간을 효과적으로 탐색할 수 있도록 돕기 때문이다. 특히 소규모 훈련 세트에서 성능 변동이 큰 상황에서도, 세 가지 인사이트가 탐색 방향에 대한 구조적 제약을 제공함으로써 무작위적인 성능 변동에 덜 민감한 탐색이 가능하다.
구체적으로, 50개 샘플의 훈련 세트에서는 개별 시행의 성능이 상당한 분산을 보일 수 있어, 순수하게 관찰된 성능만에 기반하여 탐색 방향을 결정하면 잡음에 의해 잘못된 방향으로 이끌릴 위험이 있다. 베이지안 최적화는 이러한 잡음에 특히 취약한데, 대리 모델이 잡음이 많은 관찰로부터 잘못된 탐색 지형을 학습하기 때문이다. AgentHPO와 MLCopilot 역시 피드백의 잡음에 의해 영향을 받지만, 가이드라인 기반 구조가 어느 정도의 완충 역할을 한다. 그러나 AgentTTS는 인사이트를 통해 탐색의 기본 구조를 사전에 설정하므로, 개별 시행의 잡음에 덜 의존적인 탐색이 가능하다. 예를 들어 Insight 1은 "이 서브태스크에는 대형 모델이 적합하다"는 구조적 판단을 제공하는데, 이는 소수의 잡음 있는 관찰로도 확인할 수 있는 강건한 패턴이다. 이러한 강건성은 실제 응용에서 매우 중요한 속성인데, 현실 세계의 복합 태스크에서는 충분한 양의 레이블된 학습 데이터를 확보하기 어려운 경우가 많기 때문이다.
8.3 해석 가능성 분석

Figure 5: 경험적 인사이트를 통한 AgentTTS 해석의 상세 사례. 2WikiMultiHopQA에서의 세 가지 케이스 스터디로, 각 인사이트가 시행 생성과 가이드라인 구성에 어떻게 기여하는지를 보여준다.
논문은 LLM 에이전트에 사전 인사이트를 통합함으로써 얻어지는 해석 가능성(interpretability)의 이점을 설명하기 위해 2WikiMultiHopQA에서 세 가지 케이스 스터디를 제시한다. Figure 5의 첫 번째 행은 Insight 1이 서브태스크별 모델 사용을 가능하게 하여, 검색에는 대형 모델을, QA에는 소형 모델을 선호하는 방식으로 효율적인 시행을 안내하는 과정을 보여준다. Agent는 "검색 태스크에는 큰 모델이 유리하고, QA에서는 작은 모델이 반복 샘플링과 퓨전을 통해 더 나은 결과를 얻을 수 있다"는 명시적 가이드라인을 생성한다.
두 번째 행은 Insight 2가 최적 샘플링 범위(5-50)를 정확히 지목하여 탐색 공간을 효과적으로 축소하는 과정을 보여준다. Agent는 "5개 미만의 샘플에서는 성능이 부족하고, 50개 이상에서는 퓨전 복잡도로 인해 성능이 감소하므로 5-50 범위에서 집중 탐색"이라는 구체적인 지침을 생성한다. 세 번째 행은 Insight 3가 균형 잡힌 할당을 촉진하여, 단일 샘플의 "고용량" 검색과 "저비용" QA 구성을 선호함으로써 전체 성능을 위한 효과적인 트레이드오프를 가능하게 하는 과정을 보여준다.
이러한 해석 가능성은 AgentTTS의 주요 장점 중 하나이다. 전통적인 베이지안 최적화나 랜덤 서치는 최적 구성을 발견하더라도 왜 그 구성이 최적인지에 대한 설명을 제공하지 못한다. 이들 방법은 수치적 최적화에 기반하여 구성 공간을 탐색하므로, 최종 결과는 단순히 "이 구성이 가장 높은 점수를 얻었다"는 사실만을 제시한다. 반면 AgentTTS는 명시적인 가이드라인 생성을 통해 의사결정의 근거를 자연어 수준에서 투명하게 제시하므로, 사용자가 탐색 과정의 논리적 흐름을 이해하고 필요에 따라 개입하거나 조정할 수 있다.
예를 들어, AgentTTS의 가이드라인에는 "이전 시행에서 72B 모델의 단일 검색이 3B 모델의 30회 검색보다 더 높은 Ret_F1을 달성했으므로, 검색 서브태스크에서는 대형 모델을 우선적으로 사용해야 한다"나 "QA 서브태스크에서 8B 모델의 샘플 수를 10에서 50으로 증가시켰을 때 성능 향상이 미미했으므로, 최적 샘플 수는 10 근처에 있을 것으로 판단된다"와 같은 구체적인 추론이 포함된다. 이러한 수준의 해석 가능성은 특히 고위험 응용이나 대규모 시스템에서의 배치에서 매우 중요한 속성이다. 시스템 관리자가 자동화된 최적화 결과를 검증하고, 도메인 지식에 기반하여 탐색 방향을 조정하거나, 예기치 않은 결과의 원인을 진단하는 것이 가능해지기 때문이다.
9. 한계점 및 향후 연구 방향
논문에서 직접 서술하거나 분석 과정에서 도출할 수 있는 AgentTTS의 한계점과 향후 연구 방향은 다음과 같다.
첫째, 퓨전 기반 스케일링의 한계이다. AgentTTS는 반복 샘플링과 퓨전(Repeated Sampling with Fusion) 전략을 채택하는데, 이 전략은 샘플 수가 증가함에 따라 퓨전 과정이 병목이 될 수 있다. Insight 2에서 관찰된 비단조적 성능 추세는 퓨전의 복잡도 증가가 성능 저하를 초래할 수 있음을 시사한다. 특히 소형 모델은 대량의 후보를 효과적으로 통합하는 퓨전 능력이 부족하여, 샘플 수 증가의 이점을 충분히 활용하지 못한다. 향후 보상 모델 기반 선택(Best-of-N)이나 트리 탐색, 또는 계층적 퓨전(소규모 그룹으로 먼저 퓨전한 후 최종 퓨전을 수행하는 방식) 등 다른 테스트 타임 스케일링 모드를 다단계 태스크에 적용하는 연구가 필요하다. 이러한 대안적 스케일링 모드에서도 세 가지 인사이트가 유효한지 검증하는 것은 중요한 후속 연구 방향이다.
둘째, 탐색 에이전트의 LLM 의존성이다. 현재 AgentTTS는 GPT-o3-mini를 탐색 에이전트로 사용하는데, 탐색 에이전트의 역량이 전체 프레임워크의 성능에 직접적으로 영향을 미친다. GPT-o3-mini는 강력한 추론 능력을 갖춘 상용 모델인데, 더 약한 모델(예: GPT-4o-mini, 소형 오픈소스 모델)을 사용했을 때 인사이트 기반 가이드라인의 품질이 저하되어 탐색 효율성이 떨어질 가능성이 있다. 반대로 더 강력한 모델(예: GPT-4o, Claude)을 사용하면 추가적인 성능 향상이 가능할 수 있으나, 탐색 에이전트의 API 비용도 증가한다. 탐색 에이전트의 비용 대비 성능 트레이드오프, 그리고 오픈소스 모델(예: LLaMA-3 70B 또는 Qwen2.5-72B)의 탐색 에이전트 활용 가능성은 AgentTTS의 접근성과 비용 효율성 측면에서 중요한 향후 연구 주제이다.
셋째, 서브태스크 수의 확장성이다. 현재 실험은 2-4개의 서브태스크를 가진 태스크에서 수행되었으나, 서브태스크 수가 크게 증가하는 매우 복잡한 파이프라인(예: 10개 이상의 단계를 가진 워크플로우)에서의 확장성은 검증되지 않았다. 서브태스크 수가 증가하면 탐색 공간이 기하급수적으로 확장된다. 예를 들어, 서브태스크가 2개이고 각각에 3개의 모델과 10가지 샘플 수 옵션이 있으면 탐색 공간은 $(3 \times 10)^2 = 900$이지만, 서브태스크가 10개로 증가하면 $(3 \times 10)^{10} \approx 3 \times 10^{14}$로 폭발적으로 증가한다. 이러한 규모의 탐색 공간에서는 50회 반복만으로는 충분한 탐색이 불가능할 수 있다. 계층적 탐색(서브태스크를 그룹으로 나누어 그룹 단위로 먼저 최적화한 후 세부 조정), 서브태스크 그룹화(유사한 특성의 서브태스크에 동일 구성 적용), 또는 점진적 탐색(서브태스크를 순차적으로 추가하며 최적화) 등의 추가 전략이 필요할 수 있다.
넷째, 훈련 세트와 테스트 세트 간의 분포 차이이다. AgentTTS는 소규모 훈련 세트(50개 샘플)에서 탐색을 수행하고 테스트 세트(500개 샘플)에서 평가한다. 훈련 세트가 테스트 세트를 충분히 대표하지 못하는 경우 일반화 성능이 저하될 수 있다. 논문은 훈련 세트 크기를 50, 75, 100으로 변화시키는 실험을 수행했으나, 훈련 세트와 테스트 세트 간의 난이도 분포나 도메인 분포 차이에 따른 영향은 명시적으로 분석하지 않았다. 예를 들어, 훈련 세트에 쉬운 질문만 포함되고 테스트 세트에 어려운 질문이 많은 경우, 훈련 세트에서 최적인 구성이 테스트 세트에서는 차선이 될 수 있다. 이에 대한 체계적인 분석과 분포 이동에 강건한 탐색 전략의 개발이 향후 연구에서 필요하다.
다섯째, 동적 예산 할당의 가능성이다. 현재 AgentTTS는 고정된 총 예산 내에서 정적인 할당을 탐색하지만, 실시간으로 각 인스턴스의 난이도에 따라 예산을 동적으로 조정하는 방식은 다루지 않는다. 예를 들어, 쉬운 질문에는 적은 연산만 투입하고 어려운 질문에 더 많은 연산을 투입하는 인스턴스 수준의 적응적 예산 할당은 전체 시스템의 효율성을 더욱 향상시킬 수 있는 유망한 방향이다. 기존의 난이도 기반 테스트 타임 스케일링 연구를 다단계 설정으로 확장하면, 각 인스턴스에 대해 서브태스크별 모델과 샘플 수를 동적으로 결정하는 보다 세밀한 최적화가 가능할 것이다.
여섯째, 비용 메트릭의 다양화이다. 논문은 추론 FLOPs와 API 가격이라는 두 가지 비용 메트릭을 실험했으나, 실제 배치 환경에서는 지연 시간(latency), GPU 메모리 사용량, 에너지 소비 등 다양한 비용 요소가 중요할 수 있다. 특히 지연 시간은 실시간 서비스에서 매우 중요한 메트릭인데, 대형 모델의 단일 패스와 소형 모델의 다중 패스가 FLOPs는 동일하더라도 병렬 처리 가능성에 따라 지연 시간이 크게 달라질 수 있다. 다중 비용 메트릭을 동시에 고려하는 다목적 최적화(multi-objective optimization)로의 확장도 의미 있는 향후 연구 방향이 될 것이다.
마지막으로, 모델 계열 간 전이 가능성의 문제가 있다. 현재 실험에서는 LLaMA-3와 Qwen2.5 계열 모델을 사용하지만, 다른 모델 계열(예: Mistral, Gemma, 또는 GPT-4o와 Claude 같은 상용 API 모델)에서의 인사이트 유효성은 검증되지 않았다. 서로 다른 모델 계열은 각기 다른 강점과 약점을 가지므로, 세 가지 인사이트의 구체적인 양상(예: 어떤 크기의 모델이 특정 서브태스크에서 선호되는지, 최적 샘플 수가 어느 범위에 위치하는지)이 달라질 수 있다. 특히 상용 API 모델을 사용하는 경우, 모델의 내부 아키텍처와 훈련 데이터가 공개되지 않으므로 예산 변환 공식(Theorem 1)을 직접 적용할 수 없으며, API 가격 기반 예산 변환만 사용 가능하다. 다만 인사이트 자체의 방향성, 즉 서브태스크별 선호도의 존재, 최적 예산의 존재, 서브태스크 간 상호의존성은 모델에 무관한 구조적 특성이므로, 다른 모델 계열에서도 유사한 패턴이 관찰될 것으로 예상된다. 다양한 모델 생태계에서의 인사이트 검증과 프레임워크 적용은 AgentTTS의 실용적 가치를 더욱 높일 수 있는 중요한 후속 연구 방향이며, 특히 이종 모델 계열(heterogeneous model families)을 동일 파이프라인 내에서 혼합 사용하는 시나리오에 대한 연구가 유의미할 것이다.
10. 결론
논문은 다단계 복합 태스크에서의 테스트 타임 연산 최적 스케일링이라는 새로운 문제를 연구한다. 이 문제는 기존의 단일 단계 테스트 타임 스케일링과 근본적으로 다른 도전을 제기한다. 모델 선택과 서브태스크 수의 증가에 따라 탐색 공간이 기하급수적으로 확장되며, 서브태스크 간의 예산 할당이 상호의존적이어서 각 서브태스크를 독립적으로 최적화하는 것이 불가능하다. 네 가지 태스크 유형(검색 기반 QA, 지식 그래프 QA, 태스크 자동화, 자동 소프트웨어 개발)과 여섯 개의 데이터셋에 걸친 체계적인 경험적 분석을 통해 세 가지 핵심 인사이트가 도출된다. 서브태스크는 요구하는 역량에 따라 소형 또는 대형 모델에 대한 고유한 선호도를 가지며(Insight 1), 테스트 타임 스케일링은 각 서브태스크에 고유한 최적 예산이 존재하고 그 이상에서는 수확 체감 또는 성능 저하를 보이며(Insight 2), 선행 서브태스크에 할당된 예산과 그 결과물의 품질이 하류 서브태스크의 스케일링 행동과 모델 선택에 직접적으로 영향을 미친다(Insight 3).
이러한 인사이트에 기반하여 제안된 AgentTTS는 LLM 에이전트 기반 프레임워크로, 실제 태스크 플랫폼과의 상호작용을 통해 연산 최적 구성을 반복적으로 탐색한다. Agent, Archive, Environment의 세 컴포넌트가 유기적으로 상호작용하며, 경험적 인사이트가 초기화(Insight 1), 가이드라인 생성(Insight 2, 3), 시행 생성의 각 단계에 체계적으로 통합된다.
실험 결과는 AgentTTS가 전통적 방법(베이지안 최적화, 랜덤 서치)과 LLM 기반 베이스라인(AgentHPO, MLCopilot, LLM_ZS) 모두를 탐색 효율성, 최종 테스트 성능, 비매끄러운 탐색 지형에 대한 강건성에서 능가함을 보여준다. 특히 2WikiMultiHopQA에서는 차선 방법 대비 70% 이상의 탐색 시간 절감(2.5시간 vs 8.3시간)과 2% 포인트의 테스트 성능 향상(0.72 vs 0.70)을 달성한다. Ablation study는 세 가지 인사이트 각각이 전체 성능에 고유하고 상보적인 기여를 함을 입증하며, 특히 Insight 1에 의한 초기 모델 선택이 가장 결정적인 역할을 담당한다.
AgentTTS의 해석 가능한 가이드라인 생성은 의사결정 근거의 투명성을 제공하여, 사용자가 "왜 이 구성이 선택되었는가"를 자연어 수준에서 이해할 수 있게 한다. 이는 기존의 블랙박스 최적화 방법에서는 달성할 수 없는 속성이다. 또한 다양한 예산 수준(500, 900, 2000), 비용 메트릭(FLOPs, API 가격), 훈련 세트 크기(50, 75, 100)에 걸친 일관된 성능은 프레임워크의 범용성과 실용성을 강력히 입증한다. 본 연구는 테스트 타임 스케일링 연구를 단일 단계 태스크에서 다단계 복합 태스크로 확장하는 중요한 첫걸음으로, 향후 더 복잡한 현실 세계 파이프라인에서의 연산 최적화 연구를 위한 기초를 마련한다. 특히 LLM 에이전트가 도메인 특화 인사이트와 결합될 때 전통적 최적화 방법을 능가할 수 있다는 실증은, 다른 복잡한 시스템 최적화 문제에도 유사한 패러다임이 적용될 수 있음을 시사한다.
11. 요약 정리
- 논문은 다단계 복합 태스크에서의 테스트 타임 연산 최적 스케일링이라는 새로운 문제를 형식화하고, 서브태스크별 모델 선택과 예산 할당의 동시 최적화를 연구한다.
- 네 가지 태스크 유형(검색 기반 QA, 지식 그래프 QA, 태스크 자동화, 자동 소프트웨어 개발)과 여섯 개의 데이터셋에서 세 가지 핵심 인사이트를 도출한다: 서브태스크별 모델 선호도(Insight 1), 최적 예산 이후의 수확 체감(Insight 2), 서브태스크 간 예산 할당의 상호의존성(Insight 3).
- AgentTTS는 Agent, Archive, Environment의 세 컴포넌트로 구성된 LLM 에이전트 기반 프레임워크로, 경험적 인사이트를 탐색 과정에 직접 통합하여 효율적인 연산 최적 구성 탐색을 수행한다.
- 통합 예산 변환 프레임워크를 통해 서로 다른 모델-태스크 조합의 연산 비용을 정규화된 예산 단위로 변환하여 공정한 비교를 가능하게 한다.
- 반복 샘플링과 퓨전 전략을 테스트 타임 스케일링 모드로 채택하며, 추가적인 보상 모델 없이도 효과적인 스케일링을 달성한다.
- 실험 결과, AgentTTS는 베이지안 최적화, 랜덤 서치, AgentHPO, MLCopilot, LLM_ZS 등 모든 베이스라인을 탐색 효율성과 테스트 성능 모두에서 능가한다.
- 2WikiMultiHopQA에서 차선 방법 대비 70% 이상의 탐색 시간 절감(2.5시간 vs 8.3시간)과 2% 포인트의 테스트 성능 향상(0.72 vs 0.70)을 달성한다.
- Ablation study는 세 가지 인사이트 모두가 상보적으로 기여하며, 특히 Insight 1(초기 모델 선택)이 가장 결정적인 역할을 함을 보여준다.
- 소규모 훈련 세트(50, 75, 100개)에 대한 강건성과 저/중/고 예산 설정에서의 일관된 성능, 그리고 FLOPs 및 API 가격 메트릭 모두에서의 일반화 능력을 입증한다.
- 명시적 가이드라인 생성을 통한 해석 가능성은 기존 블랙박스 최적화 방법 대비 AgentTTS의 핵심 차별점으로, 사용자가 탐색 과정의 의사결정 근거를 투명하게 파악할 수 있도록 한다.