Diffusion Language Models Know the Answer Before Decoding
https://arxiv.org/abs/2508.19982
Pengxiang Li, Yefan Zhou, Dilxat Muhtar, Lu Yin, Shilin Yan, Li Shen, Yi Liang, Soroush Vosoughi, Shiwei Liu | The Hong Kong Polytechnic University, Dartmouth College, University of Surrey, Sun Yat-sen University, Google DeepMind, Max Planck Institute for Intelligent Systems, ELLIS Institute Tübingen | arXiv:2508.19982 | 2025년 8월 | ICLR 2026
1. 서론: 확산 언어 모델의 추론 가속화를 향한 새로운 관점
최근 확산 모델(diffusion model)은 이미지 생성, 분자 구조 예측, 음성 합성 등 다양한 연속 도메인에서 혁신적인 성과를 보여왔으며, 이러한 성공에 힘입어 이산(discrete) 텍스트 도메인으로의 확장이 활발히 진행되고 있다. 확산 언어 모델(Diffusion Language Models, DLMs)은 기존의 자기회귀(autoregressive, AR) 모델과 근본적으로 다른 생성 패러다임을 제시하는데, 모든 토큰을 병렬적으로 생성하고 반복적인 디노이징(denoising) 및 재마스킹(re-masking) 과정을 통해 점진적으로 정제해 나간다는 점이 핵심적인 차별점이다. LLaDA, Dream, Mercury, Gemini Diffusion, Seed Diffusion 등 최근 공개된 상용 및 오픈소스 DLM들은 병렬 디코딩과 유연한 토큰 생성 순서라는 장점을 바탕으로 AR 모델의 유력한 대안으로 부상하고 있다.
그러나 DLM의 실제 추론 속도는 AR 모델에 비해 여전히 느린 것이 현실이다. 이러한 속도 저하의 주된 원인은 양방향 어텐션(bidirectional attention)의 연산 비용과 고품질 출력을 위해 요구되는 많은 수의 정제 단계(refinement steps)에 있다. AR 모델은 KV-캐시(KV-cache) 메커니즘을 통해 이전에 계산된 키-값 쌍을 재활용할 수 있지만, DLM은 양방향 특성상 이러한 최적화를 직접적으로 활용하기 어렵다. 이에 따라 KV-캐시 근사 기법, 블록 자기회귀 방식, 토큰 프루닝, 샘플링 최적화 등 다양한 가속화 기법들이 제안되어 왔다.
본 논문은 이러한 기존의 가속화 접근법들과는 근본적으로 다른 관점에서 DLM의 추론 효율성 문제를 바라본다. 저자들은 DLM이 가지는 간과된 속성, 즉 "조기 답변 수렴(early answer convergence)"이라는 현상에 주목한다. 광범위한 분석을 통해 저자들은 놀라운 사실을 발견하였는데, 대다수의 샘플에서 정답이 전체 디코딩 과정의 절반도 채 지나지 않은 시점에 이미 내부적으로 확정된다는 것이다. 예를 들어 GSM8K 벤치마크에서는 97%, MMLU에서는 99%의 인스턴스가 절반의 정제 단계만으로도 올바르게 디코딩될 수 있다. 이러한 관찰에 기반하여 저자들은 Prophet이라는 학습 불필요(training-free) 고속 디코딩 패러다임을 제안하며, 이는 모델의 예측 확신도를 동적으로 모니터링하여 적절한 시점에 조기에 디코딩을 종료하는 조기 커밋 디코딩(Early Commit Decoding) 전략을 구현한다.
2. 배경 및 관련 연구: 확산 언어 모델의 발전과 가속화 과제
2.1 확산 대규모 언어 모델의 이론적 기반
확산 과정을 이산 도메인에 적용하려는 시도는 Sohl-Dickstein 등(2015)과 Hoogeboom 등(2021)의 선구적 연구에서 시작되었다. 이후 D3PM(Austin et al., 2021a)에서 일반적인 확률론적 프레임워크가 개발되었으며, 이는 순방향 과정(forward process)을 이산 상태 마르코프 체인(discrete-state Markov chain)으로 모델링하여 깨끗한 입력 시퀀스에 시간 단계에 걸쳐 점진적으로 노이즈를 추가하는 방식을 채택하였다. 역방향 과정(reverse process)은 현재의 노이즈가 추가된 입력으로부터 깨끗한 텍스트 시퀀스를 예측하도록 파라미터화되며, 증거 하한(Evidence Lower Bound, ELBO)을 최대화하는 방식으로 학습된다.
이러한 관점은 이후 연속 시간(continuous-time) 설정으로 확장되었다. Campbell 등(2022)은 이산 체인을 연속 시간 마르코프 체인(Continuous-Time Markov Chain, CTMC) 공식화 내에서 재해석하였으며, SEDD(Lou et al., 2023)는 우도비(likelihood ratio)를 직접 추정하고 학습을 위한 디노이징 점수 엔트로피 기준을 도입하는 대안적 접근을 제시하였다. 최근 MDLM(Shi et al., 2024; Sahoo et al., 2024; Zheng et al., 2024)과 RADD(Ou et al., 2024)의 분석은 마스크된 확산 모델(MDM)의 다양한 파라미터화가 사실상 동등하다는 것을 증명하여, 이론적 기반을 더욱 공고히 하였다.
이러한 이론적 돌파구에 힘입어 실용적 수준의 DLM들이 성공적으로 구축되었다. 상용 모델로는 Mercury(Inception Labs, 2025), Gemini Diffusion(Google DeepMind, 2025), Seed Diffusion(Song et al., 2025b)이 있으며, 오픈소스 구현으로는 LLaDA(Nie et al., 2025)와 Dream(Ye et al., 2025)이 대표적이다. 그러나 이들 DLM은 공통적으로 효율성-정확도 간 트레이드오프 문제에 직면해 있다. 디노이징 단계당 동시에 디코딩하는 토큰 수를 늘리면 품질이 저하되고, 반대로 적은 수의 토큰만 디코딩하면 AR 모델 대비 높은 추론 지연이 발생하기 때문이다.
2.2 확산 언어 모델을 위한 가속화 기법의 세 가지 방향
DLM의 추론 속도를 향상시키면서 품질을 유지하기 위한 최근의 최적화 노력은 크게 세 가지 상호 보완적인 방향으로 분류할 수 있다. 논문은 이 세 가지 방향을 체계적으로 정리하며, Prophet가 이들과 어떻게 차별화되고 또한 결합될 수 있는지를 명확히 한다.
- 근사 캐싱(Approximate Caching) 기반 접근: 연속적인 디노이징 단계 간에 은닉 상태(hidden state)가 높은 유사성을 보인다는 경험적 관찰을 활용하여, KV-캐시를 근사적으로 구현하는 전략이다. dKV-cache(Ma et al., 2025b), dLLM-cache(Liu et al., 2025b), 그리고 Hu 등(2025)의 연구가 이에 해당하며, 블록 자기회귀(block-autoregressive) 방식으로 디노이징 과정을 재구조화하여 이전 컨텍스트의 캐시를 활용하는 Fast-dLLM(Wu et al., 2025b), Block Diffusion(Arriola et al., 2025) 등도 이 범주에 포함된다.
- 어텐션 비용 절감을 위한 토큰 프루닝: DPad(Chen et al., 2025)와 같은 학습 불필요 기법이 대표적이며, 미래(접미사) 토큰을 연산적 "스크래치패드"로 처리하고 원거리 토큰을 연산 전에 제거하는 방식으로 어텐션 비용을 줄인다.
- 샘플링 방법 최적화 및 전체 디노이징 단계 수 감소: 강화학습(Song et al., 2025b)이나 자기 증류(Wang et al., 2025a) 같은 학습 기반 방법 외에도, Fast-dLLM, SlowFast(Wei et al., 2025a), WINO(Song et al., 2025a) 등의 학습 불필요 전략이 동적 샘플링 스케줄이나 신뢰도 기반 병렬 디코딩을 도입하여 추론을 가속화한다.
조기 답변 수렴 현상은 우수한 동시 연구(concurrent work)인 Wang 등(2025a)에서도 독립적으로 발견되었다는 점을 언급할 필요가 있다. 그러나 두 연구의 접근 방향은 근본적으로 다르다. Wang 등은 시간 단계에 걸쳐 예측을 평균화(averaging)하여 정확도를 향상시키는 데 초점을 맞춘 반면, Prophet는 수렴이 감지되면 즉시 디코딩을 조기 종료하여 연산 비용을 절감하는 데 초점을 맞춘다. 이러한 차이는 동일한 현상에 대한 두 가지 보완적인 활용 방식을 제시하며, 향후 두 접근의 결합 가능성도 탐구할 가치가 있다.
본 논문의 Prophet는 이러한 기존 최적화 기법들과 근본적으로 다른 관점에서 출발한다. 기존 토큰 수준 가속화 기법(예: Fast-dLLM)이 단계당 비용(cost per step)을 최적화하는 데 초점을 맞추는 반면, Prophet는 조기 답변 수렴 현상을 포착하여 필요한 전체 단계 수(total number of steps) 자체를 줄인다. 따라서 Prophet는 기존 기법들과 직교적(orthogonal)이며, 이들과 결합하여 곱셈적 속도 향상(multiplicative speedup)을 달성할 수 있다는 것이 중요한 특징이다. 실제로 논문은 Prophet와 Fast-dLLM의 결합이 약 7.66배의 속도 향상을 달성함을 실험적으로 입증한다.
3. 이론적 배경: 확산 언어 모델의 수학적 프레임워크와 조기 답변 수렴 현상
3.1 확산 언어 모델의 수학적 기초
DLM의 작동 원리를 이해하기 위해서는 순방향 과정과 역방향 과정의 수학적 구조를 살펴볼 필요가 있다. 깨끗한 입력 시퀀스를 $x_0 \sim p_{\text{data}}(x_0)$으로 표기하고, 중간 노이즈 수준 $t \in [0, T]$에서 마스킹 절차가 적용된 손상된 버전을 $x_t$로 나타낸다.
순방향 과정(Forward Process)은 마르코프 체인으로 표현되며, 원본 샘플 $x_0$을 최대로 손상된 표현 $x_T$로 점진적으로 변환한다. 이 과정은 다음과 같이 정식화된다:
$$q(x_{1:T} | x_0) = \prod_{t=1}^{T} q(x_t | x_{t-1})$$
각 단계에서 추가적인 노이즈가 주입되어, $t$가 증가함에 따라 시퀀스가 점진적으로 더 많이 마스킹된다. 그러나 순방향 과정의 정확한 역전은 단계당 하나의 위치만 언마스킹하므로 비효율적이다. 이를 가속화하기 위해 $\tau$-도약 근사($\tau$-leaping approximation)(Gillespie, 2001)가 일반적으로 사용되며, 이를 통해 여러 마스킹 위치를 동시에 복구할 수 있다. 구체적으로, 손상 수준 $t$에서 더 이른 수준 $s < t$로의 전이는 다음과 같이 근사된다:
$$q_{s|t}(x_s^i | x_t) = \begin{cases} 1, & x_t^i \neq [\text{MASK}],\; x_s^i = x_t^i \\ \frac{s}{t}, & x_t^i = [\text{MASK}],\; x_s^i = [\text{MASK}] \\ \frac{t-s}{t} q_{0|t}(x_s^i | x_t), & x_t^i = [\text{MASK}],\; x_s^i \neq [\text{MASK}] \end{cases}$$
여기서 $q_{0|t}(x_s^i | x_t)$는 마스킹된 위치가 언마스킹될 때 모델 자체가 제공하는 어휘에 대한 예측 분포이다. 조건부 생성(예: 프롬프트 $p$가 주어진 상태에서 응답 $x_0$ 생성)에서는 이 예측 분포가 프롬프트에도 의존하게 된다.
역방향 생성(Reverse Generation)에서 텍스트를 합성하려면 역방향 동역학을 근사해야 한다. 생성 모델은 다음과 같이 파라미터화된다:
$$p_\theta(x_{0:T}) = p_\theta(x_T) \prod_{t=1}^{T} p_\theta(x_{t-1} | x_t) = \prod_{t=1}^{T} q(x_{t-1} | x_0) p_\theta(x_0 | x_t)$$
이 역방향 과정은 두 가지 보완적 구성요소로 자연스럽게 분해된다. 첫째, 예측 단계(Prediction Step)에서 모델 $p_\theta(x_0 | x_t)$은 수준 $t$에서의 손상된 입력으로부터 깨끗한 시퀀스를 재구성하려 시도한다. 이 단계 이후의 예측 시퀀스를 $x_0^t = p_\theta(x_0 | x_t)$로 표기한다. 둘째, 재마스킹 단계(Re-masking Step)에서는 후보 재구성 $x_0^t$가 얻어지면, $x_t$보다 노이즈가 적은 부분적으로 손상된 시퀀스 $x_{t-1}$을 생성하기 위해 순방향 노이징 메커니즘이 다시 적용된다. 이 재마스킹은 균일 무작위 마스킹이나 저신뢰도 위치의 선택적 마스킹 등 다양한 방식으로 구현될 수 있다. 이 두 단계의 상호작용을 통해 모델은 초기의 노이즈가 많은 시퀀스를 일관된 텍스트 출력으로 반복적으로 정제해 나간다.
이 과정에서 재마스킹 전략의 선택은 디코딩 품질과 효율성에 중대한 영향을 미친다. 저신뢰도 재마스킹(low-confidence remasking)은 모델이 가장 불확실한 위치의 토큰을 선택적으로 재마스킹하여, 어려운 위치에 연산 자원을 집중시키는 전략이다. 이 방식은 직관적으로 효율적이며, 실제로 높은 절대 정확도를 달성하는 경향이 있다. 무작위 재마스킹(random remasking)은 위치를 무작위로 선택하여 재마스킹하는 더 단순한 전략이지만, 조기 답변 수렴의 관점에서는 오히려 더 유리한 특성을 보인다. Top-k 마진 재마스킹은 상위 2 예측 간의 마진이 작은 위치를 우선적으로 재마스킹하는 방식으로, 저신뢰도 재마스킹과 유사하지만 더 정교한 불확실성 척도를 사용한다. Prophet의 중요한 특징 중 하나는 이 세 가지 전략 모두와 호환되며, 각각에 대해 일관된 향상을 제공한다는 것이다.
DLM의 디코딩 과정을 반자기회귀(semi-autoregressive) 방식으로 구조화할 수도 있다. 이 방식에서는 전체 생성 시퀀스를 블록 크기 $N_{\text{block}}$의 청크로 나누고, 각 블록을 순차적으로 처리한다. 각 블록 내에서는 확산 디코딩이 수행되며, 이전 블록의 출력은 다음 블록의 컨텍스트로 활용된다. 이러한 블록 기반 접근은 KV-캐시의 부분적 활용을 가능하게 하여 효율성을 높이지만, 블록 크기의 선택이 품질에 큰 영향을 미친다. 블록이 너무 크면 한번에 너무 많은 토큰을 병렬로 디코딩하여 품질이 저하되고, 블록이 너무 작으면 디코딩 효율이 떨어진다. Prophet는 이러한 블록 크기 선택의 민감도를 크게 완화하는 역할도 수행한다는 것이 ablation 연구를 통해 입증되었다.
3.2 조기 답변 수렴 현상의 발견과 분석
논문의 핵심 기여 중 하나는 DLM에서 조기 답변 수렴(Early Answer Convergence) 현상을 체계적으로 발견하고 분석한 것이다. 저자들은 LLaDA-8B를 사용하여 GSM8K(수학적 추론)와 MMLU(다분야 지식 평가)라는 두 가지 널리 사용되는 벤치마크에서 포괄적인 분석을 수행하였다. 구체적으로, 각 디코딩 단계에서 위치별 상위 1 예측 토큰이 어떻게 변화하는지의 디코딩 동역학을 조사하고, 상위 1 예측 토큰이 처음으로 정답 토큰과 일치하는 시점이 전체 디코딩 과정의 몇 퍼센트에 해당하는지를 보고한다.
이 분석에서 저자들은 실험 설정을 명확히 구분하였다. 저신뢰도 재마스킹(low-confidence remasking)의 경우 GSM8K에서는 답변 길이 256, 블록 길이 32를, MMLU에서는 답변 길이 128, 블록 길이 128을 사용하였다. 무작위 재마스킹(random remasking)의 경우 GSM8K에서는 답변 길이 256, 블록 길이 256을, MMLU에서는 답변 길이 128, 블록 길이 128을 설정하였다. 이러한 분석으로부터 세 가지 핵심적인 발견이 도출되었다.


Figure 1(a,b): LLaDA-8B의 GSM8K에서 저신뢰도 재마스킹 하의 조기 정답 탐지 분포. (a) 접미사 프롬프트 없이: 50% 시점까지 24.2% 수렴, (b) 접미사 프롬프트 사용 시: 50% 시점까지 75.8% 수렴. 접미사 프롬프트의 극적인 효과가 관찰된다.

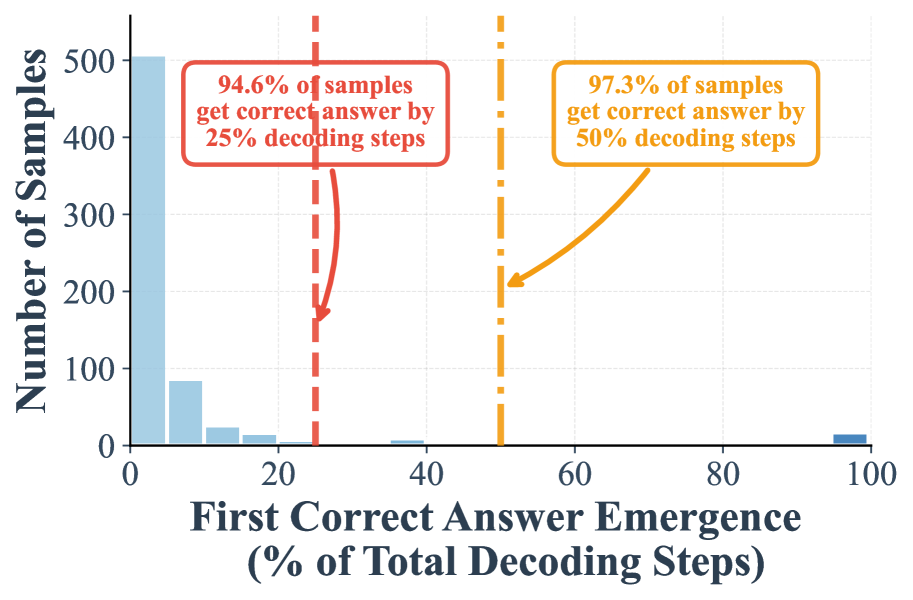
Figure 1(c,d): LLaDA-8B의 GSM8K에서 무작위 재마스킹 하의 조기 정답 탐지 분포. (c) 접미사 프롬프트 없이: 50% 시점까지 97.2% 수렴, (d) 접미사 프롬프트 사용 시: 50% 시점까지 97.3% 수렴. 무작위 재마스킹에서 조기 수렴이 훨씬 강하게 나타난다.
발견 I: 높은 비율의 샘플이 디코딩 초기 단계에서 올바르게 디코딩될 수 있다. Figure 1(a)는 저신뢰도 전략으로 재마스킹할 때, 전체 단계의 절반 시점에서 이미 24.2%의 샘플이 올바르게 예측되고, 전체의 25% 시점에서도 7.9%의 샘플이 올바르게 디코딩될 수 있음을 보여준다. 이 수치는 무작위 재마스킹으로 전환하면 Figure 1(c)에서 보이듯이 각각 97.2%와 88.5%로 크게 상승한다. 이 결과는 기존의 전체 길이 디코딩에 근본적인 중복성(redundancy)이 존재함을 시사한다.
발견 II: 접미사 프롬프트가 정답의 조기 출현을 더욱 증폭시킨다. "Answer:"라는 접미사 프롬프트를 추가하면 조기 디코딩이 크게 개선된다. 저신뢰도 재마스킹에서 25% 단계까지 정확한 샘플의 비율이 7.9%에서 59.7%로, 50% 단계까지는 24.2%에서 75.8%로 상승한다(Figure 1(b)). 무작위 재마스킹에서도 25% 단계의 비율이 88.5%에서 94.6%로 증가한다. 저자들은 이 접미사 프롬프트가 오라클 정보를 도입하는 것이 아니라 의미적 앵커(semantic anchor)로서 작용한다고 명확히 한다. DLM이 양방향으로 생성하므로, 이 앵커는 모델이 지정된 영역에서 해답을 찾도록 명시적으로 조건화하여 탐색 공간을 줄이고 수렴을 가속화하는 역할을 한다.
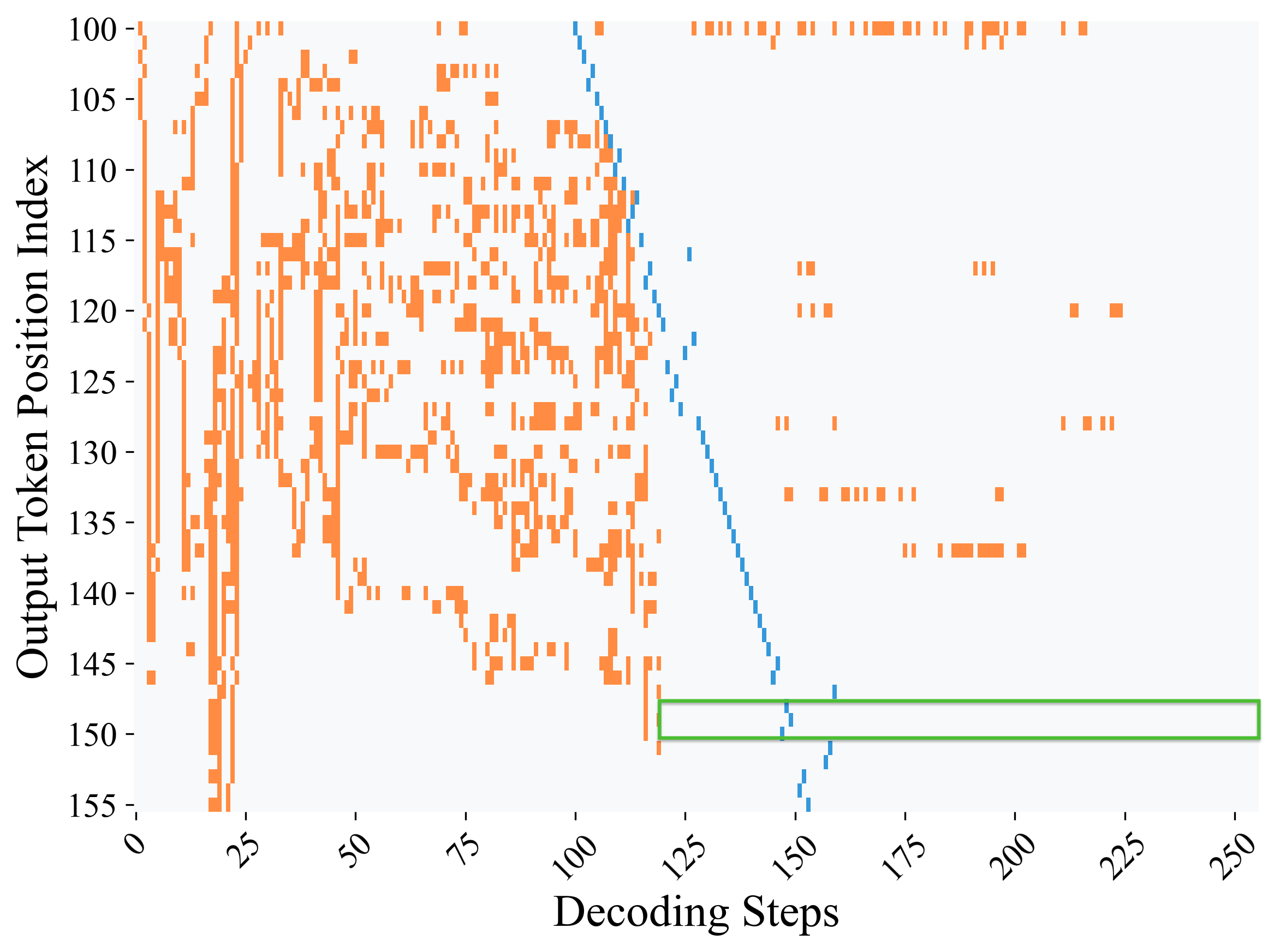
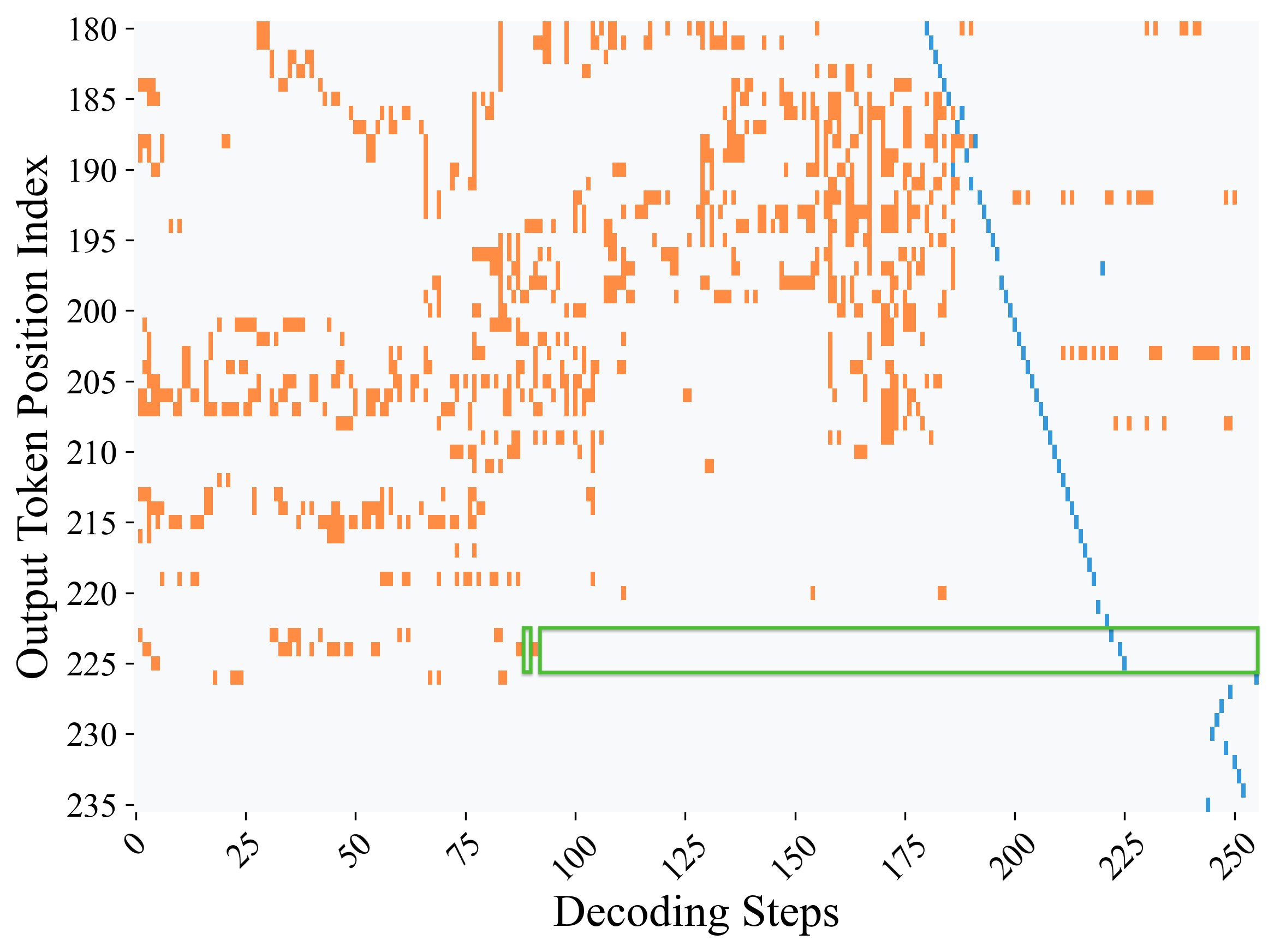
Figure 2: 최대 확률 예측에 기반한 모든 위치의 디코딩 동역학. LLaDA-8B의 GSM8K 문제 700번에 대한 결과. (a) 접미사 프롬프트 없이: 정답 토큰이 119단계에서 최대 확률에 도달. (b) 접미사 프롬프트 사용 시: 88단계에서 더 일찍 도달. 회색은 변화 없음, 주황은 토큰 변경, 파랑은 해당 위치가 실제 디코딩된 단계, 녹색 상자는 정답 영역을 나타낸다.
발견 III: 사고 사슬(Chain-of-Thought) 토큰의 디코딩 동역학. Figure 2는 답변 토큰뿐만 아니라 사고 사슬 토큰의 디코딩 동역학을 보여준다. 첫째, 대부분의 비답변 토큰은 최종 확정되기 전에 빈번하게 변동한다. 둘째, 답변 토큰은 훨씬 덜 자주 변경되며 더 일찍 안정화되어, 디코딩 과정의 나머지 동안 변하지 않는 경향을 보인다. 이는 모델이 추론 과정(사고 사슬)을 완성하기 훨씬 전에 이미 최종 답변을 "알고 있다"는 놀라운 사실을 시사한다. 히트맵에서 녹색 상자로 강조된 답변 영역은 디코딩 과정이 진행됨에 따라 상위 1 토큰으로서 안정적으로 유지되며, 추가적인 변경 없이 안전하게 디코딩될 수 있는 구간을 나타낸다.
4. 방법론: Prophet의 조기 커밋 디코딩 메커니즘
4.1 Prophet의 핵심 설계 원리와 동기
앞서 제시한 세 가지 발견—높은 비율의 조기 수렴, 접미사 프롬프트에 의한 수렴 증폭, 답변 토큰의 조기 안정화—은 기존 DLM 디코딩의 근본적인 비효율성을 드러낸다. 대부분의 샘플에서 정답이 디코딩 과정의 중반 이전에 이미 결정되었음에도 불구하고, 기존 접근은 미리 정해진 모든 단계를 맹목적으로 수행한다. 이는 마치 이미 정답을 확인한 시험에서 남은 시간 동안 불필요하게 답안을 수정하는 것과 유사하며, 경우에 따라서는 올바른 답변을 오히려 손상시킬 위험까지 내포한다(TruthfulQA에서의 실험 결과가 이를 뒷받침한다). 이러한 관찰은 "디코딩 단계 수를 어떻게 줄일 것인가"라는 기존의 질문을 "언제 디코딩을 멈추는 것이 안전한가"라는 새로운 질문으로 전환하는 패러다임 전환의 필요성을 제기한다.
이러한 배경 하에, 저자들은 Prophet이라는 학습 불필요 고속 디코딩 알고리즘을 제안한다. Prophet의 핵심 아이디어는 명확하다: 모델의 예측이 안정화되는 즉시, 남은 모든 토큰을 한 번에 커밋(commit)하여 답변을 예측하는 것이다. 이를 조기 커밋 디코딩(Early Commit Decoding)이라 명명한다. 기존의 고정 단계 디코딩과 달리, Prophet는 각 단계에서 모델의 확신도(certainty)를 능동적으로 모니터링하여, 생성을 언제 최종화할지에 대한 정보에 기반한 즉석 결정(on-the-fly decision)을 내린다.
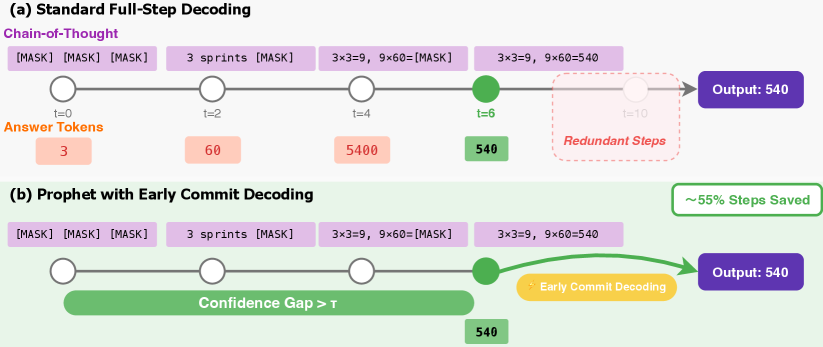
Figure 3: Prophet의 조기 커밋 디코딩 메커니즘 도해. (a) 표준 전체 단계 디코딩은 미리 정해진 모든 단계(예: 10단계)를 완료하며, 답변이 안정화된 후(t=6)에도 중복 연산이 발생한다. (b) Prophet는 모델의 확신도(Confidence Gap)를 동적으로 모니터링하고, 답변이 수렴하면 즉시 조기 커밋 디코딩을 실행하여 디코딩 단계의 상당 부분(이 경우 약 55%)을 절약한다.
Figure 3은 Prophet의 작동 방식을 직관적으로 보여준다. 표준 디코딩에서는 간단한 산술 문제의 답변 "540"이 이미 t=6 단계에서 안정화되었음에도 불구하고, t=10까지의 모든 단계를 수행하여 불필요한 연산이 발생한다. 반면 Prophet는 확신도 갭이 임계값을 초과하는 시점에서 즉시 디코딩을 종료하여, 약 55%의 단계를 절약하면서도 동일한 품질의 출력을 생산한다. 이 도해에서 흥미로운 점은 디코딩 초기(t=0~2)에서 답변 토큰이 3, 60, 5400 등으로 변동하다가 t=6 이후로 540으로 안정화되는 과정이 명확히 드러난다는 것이다.
4.2 신뢰도 갭: 수렴 판정을 위한 메트릭
Prophet의 핵심 메커니즘은 신뢰도 갭(Confidence Gap)이라는 단순하면서도 효과적인 메트릭이다. 이 메트릭은 주어진 토큰에 대한 모델의 확신도를 정량화하는 역할을 한다. 전체 생성 길이를 $N_{\text{gen}}$으로 표기하고, 반자기회귀(semi-autoregressive) 디코딩에서 토큰은 크기 $N_{\text{block}}$의 블록 단위로 생성된다. Prophet는 현재 생성 윈도우 내에서 길이 $N_{\text{ans}}$의 답변 영역(Answer Region) $\mathcal{A}$를 모니터링하는 데 집중한다.
디코딩 단계 $t$에서 DLM은 로짓 행렬 $L_t \in \mathbb{R}^{N \times |V|}$를 생성하며, 여기서 $N$은 시퀀스 길이이고 $|V|$는 어휘 크기이다. 각 위치 $i$에 대해 최고 로짓 값 $L_{t,i}^{(1)}$과 두 번째로 높은 값 $L_{t,i}^{(2)}$를 식별한다. 신뢰도 갭 $g_{t,i}$는 이 둘의 차이로 정의된다:
$$g_{t,i} = L_{t,i}^{(1)} - L_{t,i}^{(2)}$$
이 값은 예측적 확실성의 강건한 지표로 기능한다. 큰 신뢰도 갭은 예측이 수렴했을 가능성이 높으며, 최상위 토큰이 다른 모든 후보를 명확히 압도하고 있음을 시사한다. Prophet는 전체 시퀀스가 아닌 답변 영역 $\mathcal{A}$에 대해서만 평균 신뢰도 갭 $\bar{g}_t = \frac{1}{|\mathcal{A}|} \sum_{i \in \mathcal{A}} g_{t,i}$를 계산하여 민감도를 최대화한다. 이러한 설계 선택은 중요한 의미를 가지는데, 사고 사슬 토큰은 디코딩 과정 내내 변동이 크지만 답변 토큰은 일찍 안정화되므로, 답변 영역에만 집중함으로써 더 정확한 수렴 판단이 가능해진다.
4.3 시간에 따른 위험 회피 정책과 단계적 임계값 함수
디코딩 루프를 언제 종료할지의 결정은 최적 정지 문제(optimal stopping problem)로 프레이밍될 수 있다. 각 단계에서 추가 정제 반복의 연산 비용과 조기에 부정확한 결정을 내릴 위험이라는 두 가지 상충하는 비용 사이의 균형을 맞춰야 한다. 연산 비용은 남은 단계 수의 함수이며, 오류 위험은 모델의 예측 확실성과 역상관 관계에 있다.
Prophet는 시간에 따른 위험 회피(time-varying risk aversion) 원칙을 구현하는 적응적 전략으로 이 트레이드오프를 해결한다. 디코딩 진행도 $p = (T_{\max} - t) / T_{\max}$를 정의하며, 여기서 $T_{\max}$는 전체 디코딩 단계 수이다. 디코딩 초기의 노이즈가 많은 단계에서는(진행도 $p$가 작을 때), 예측 개선의 잠재력이 높으므로 이 단계에서 답변을 확정하면 높은 위험을 수반한다. 따라서 Prophet는 위험 회피적으로 행동하여, 조기 커밋을 정당화하기 위해 예외적으로 높은 임계값($\tau_{\text{high}}$)을 요구한다. 디코딩 과정이 성숙해짐에 따라(p가 증가), 모델의 예측이 안정화되고 조기 종료로 인한 잠재적 연산 절감도 줄어든다. 따라서 Prophet는 점진적으로 더 위험 허용적이 되어, 수렴을 확인하기 위해 점차 작은 임계값($\tau_{\text{low}}$)만을 요구한다.
이 동적 위험 회피 정책은 단계적 임계값 함수(staged threshold function)를 통해 구현된다:
$$\bar{g}_t \geq \tau(p), \quad \text{where} \quad \tau(p) = \begin{cases} \tau_{\text{high}} & \text{if } p < 0.33 \\ \tau_{\text{mid}} & \text{if } 0.33 \leq p < 0.67 \\ \tau_{\text{low}} & \text{if } p \geq 0.67 \end{cases}$$
종료 조건이 단계 $t^*$에서 충족되면, 반복 루프가 종료된다. 최종 출력은 현재 로짓 $L_{t^*}$의 argmax를 사용하여 남은 [MASK] 토큰을 채우는 단일 병렬 연산으로 구성된다. 이러한 3단계 임계값 구조는 디코딩 진행도에 따라 자연스럽게 위험 허용도를 조절하며, 초기에는 보수적으로 행동하고 후기에는 과감하게 종료를 결정할 수 있게 한다.
4.4 Prophet 알고리즘의 전체 절차
Prophet의 완전한 디코딩 절차는 다음과 같이 요약된다. 프롬프트 $x_{\text{prompt}}$에 $N_{\text{gen}}$개의 [MASK] 토큰을 연결하여 초기 시퀀스 $x_T$를 구성한다. 이후 $T_{\max}$부터 1까지의 각 단계에서 모델을 통해 로짓을 계산하고, 답변 영역에 대한 평균 신뢰도 갭을 산출한다. 디코딩 진행도에 따른 임계값과 비교하여 조건이 충족되면 즉시 종료하고, 그렇지 않으면 표준 DLM 정제 단계(재마스킹 전략에 따른 토큰 언마스킹)를 수행한다. 전체 반복이 완료되어도 조기 종료가 발생하지 않으면 최종 결과를 반환한다.
알고리즘의 핵심적인 장점은 다음과 같다:
- 신뢰도 갭 검사의 추가는 표준 DLM 디코딩 루프에 무시할 수 있는 수준의 연산 오버헤드만을 발생시킨다. 이미 계산된 로짓에서 상위 두 값의 차이를 구하는 것은 거의 비용이 들지 않기 때문이다.
- Prophet는 모델 불가지론적(model-agnostic)이며, 어떠한 재훈련도 필요로 하지 않는다.
- 기존 DLM 추론 코드에 대한 래퍼(wrapper)로 쉽게 구현할 수 있어 기존 시스템에 대한 통합이 용이하다.
- 기존의 토큰 수준 가속화 기법들과 직교적으로 결합 가능하여 곱셈적 속도 향상을 달성할 수 있다.
5. 실험 설정: 벤치마크, 모델 및 평가 프로토콜
5.1 데이터셋 및 벤치마크
Prophet의 효과를 포괄적으로 평가하기 위해, 저자들은 네 가지 능력 도메인에 걸친 12개의 벤치마크를 사용하였다. 이러한 다양한 벤치마크 선택은 Prophet의 범용성과 적응적 특성을 검증하기 위한 것으로, 단순한 지식 평가부터 복잡한 추론과 코드 생성에 이르는 넓은 스펙트럼의 과제를 포괄한다.
| 도메인 | 벤치마크 | 평가 내용 |
|---|---|---|
| 일반 추론 | MMLU | 다분야 지식 평가 |
| ARC-Challenge | 과학적 추론 | |
| HellaSwag | 상식적 추론 | |
| TruthfulQA | 진실성 평가 | |
| WinoGrande | 대명사 해소 | |
| PIQA | 물리적 상식 추론 | |
| 수학/과학 | GSM8K | 수학 문장제 |
| GPQA | 대학원 수준 Q&A | |
| 코드 생성 | HumanEval | 함수 수준 코드 생성 |
| MBPP | 기초 프로그래밍 문제 | |
| 계획 수립 | Countdown | 숫자 조합 퍼즐 |
| Sudoku | 논리 퍼즐 |
5.2 구현 세부사항
실험은 두 가지 최신 확산 언어 모델에서 수행되었다: LLaDA-8B-Instruct(Nie et al., 2025)와 Dream-7B-Instruct(Ye et al., 2025). 각 모델에 대해 두 가지 디코딩 전략을 비교한다: (1) Full은 전체 단계 예산 $T_{\max}$를 사용하는 표준 확산 디코딩이며, (2) Prophet는 동적 임계값 스케줄링을 통한 조기 커밋 디코딩을 사용한다. 임계값 파라미터는 예비 검증 실험을 통해 $\tau_{\text{high}} = 7.5$, $\tau_{\text{mid}} = 5.0$, $\tau_{\text{low}} = 2.5$로 설정되었으며, 전환은 디코딩 진행도의 33%와 67% 시점에서 발생한다.
벤치마크별 세부 설정은 다음과 같다. 일반 과제에는 생성 길이 $L = 128$을, GSM8K와 GPQA에는 $L = 256$을, 코드 벤치마크에는 $L = 512$를 설정하였다. 별도 명시가 없는 한, 모든 베이스라인은 지정된 생성 길이와 동일한 수의 반복 단계를 사용한다. 모든 실험은 결정론적이고 재현 가능한 결과를 보장하기 위해 그리디 디코딩(greedy decoding)을 사용하였다. 프롬프트는 simple-evals 형식을 따르며, 모델이 단계별로 추론하도록 설정하였다. Sudoku와 Countdown은 8-shot 설정으로, 나머지 모든 벤치마크는 zero-shot으로 평가되었다.
5.3 벤치마크별 상세 구성
아래 표는 각 벤치마크에 사용된 기본 예산(생성 길이 $L$, 전체 단계 수 $T$, 블록 길이 $B$)과 Prophet의 신뢰도 스케줄을 정리한 것이다. 대부분의 벤치마크에서 동일한 임계값 설정 $(7.5, 5.0, 2.5)$을 사용하지만, GSM8K/GPQA와 코드 생성 벤치마크에서는 과제의 복잡성을 반영하여 약간 다른 값을 적용하였다.
| 벤치마크 | 기본 예산 (L, T, B) | Prophet 임계값 ($\tau_{\text{high}}$, $\tau_{\text{mid}}$, $\tau_{\text{low}}$) | 전환점 |
|---|---|---|---|
| MMLU | L=64, T=64, B=16 | (7.5, 5.0, 2.5) | 33%, 67% |
| ARC-C | L=64, T=64, B=16 | (7.5, 5.0, 2.5) | 33%, 67% |
| HellaSwag | L=64, T=64, B=16 | (7.5, 5.0, 2.5) | 33%, 67% |
| TruthfulQA | L=64, T=64, B=16 | (7.5, 5.0, 2.5) | 33%, 67% |
| WinoGrande | L=64, T=64, B=16 | (7.5, 5.0, 2.5) | 33%, 67% |
| PIQA | L=64, T=64, B=16 | (7.5, 5.0, 2.5) | 33%, 67% |
| GSM8K | L=256, T=256, B=32 | (8.0, 5.0, 3.5) | 33%, 67% |
| GPQA | L=256, T=256, B=32 | (8.0, 5.0, 3.5) | 33%, 67% |
| HumanEval | L=512, T=512, B=32 | (7.5, 5.0, 4.5) | 33%, 67% |
| MBPP | L=512, T=512, B=32 | (7.5, 5.0, 4.5) | 33%, 67% |
| Sudoku | L=24, T=24, B=24 | (7.5, 5.0, 2.5) | 33%, 67% |
| Countdown | L=32, T=32, B=32 | (7.5, 5.0, 2.5) | 33%, 67% |
코드 생성 벤치마크에서 $\tau_{\text{low}}$가 4.5로 다른 벤치마크의 2.5보다 높게 설정된 점이 주목할 만하다. 이는 코드 생성이 정밀한 구문과 논리를 요구하는 복잡한 과제이므로, Prophet가 더 보수적으로 동작하여 충분한 정제가 이루어지도록 하기 위한 것이다. 마찬가지로 GSM8K와 GPQA에서는 $\tau_{\text{high}}$가 8.0, $\tau_{\text{low}}$가 3.5로 설정되어 수학적 추론의 정확성을 보장한다. 이러한 과제별 차별화된 설정은 Prophet가 범용적인 기본값으로 동작하면서도, 특정 도메인의 요구사항에 맞게 미세 조정될 수 있는 유연성을 갖추고 있음을 보여준다.
또한 모든 벤치마크에서 전환점이 동일하게 33%와 67%로 설정되어 있다는 것은 주목할 만한 점이다. 이 고정된 3분할 구조는 디코딩 과정을 초기(탐색 단계), 중기(안정화 단계), 후기(정제 단계)의 세 단계로 자연스럽게 분리하며, 각 단계에서의 위험 허용도를 직관적으로 제어한다. 이러한 일관된 전환점 설정이 다양한 과제에서 효과적으로 작동한다는 것은, DLM의 디코딩 동역학이 과제 유형에 관계없이 유사한 시간적 패턴을 따른다는 흥미로운 가설을 뒷받침한다.
6. 주요 실험 결과: Prophet의 성능과 속도 향상
6.1 LLaDA-8B 및 Dream-7B에서의 종합 벤치마크 결과
Table 1은 LLaDA-8B-Instruct와 Dream-7B-Instruct에 대한 12개 벤치마크의 종합 결과를 보여준다. 이 결과는 Prophet의 두 가지 핵심 가설을 검증한다: 첫째, Prophet가 실질적으로 더 적은 디노이징 단계를 사용하면서도 전체 예산 디코딩의 성능을 유지할 수 있는지, 둘째, 적응적 접근이 순진한 정적 베이스라인보다 더 신뢰성 있는 가속화를 제공하는지이다.
| 벤치마크 | LLaDA-8B | Dream-7B | ||||
|---|---|---|---|---|---|---|
| Full (%) | Prophet (∆) | 속도향상 | Full (%) | Prophet (∆) | 속도향상 | |
| 일반 추론 과제 | ||||||
| MMLU | 54.1 | 54.0 (-0.1) | 2.34× | 67.6 | 66.1 (-1.5) | 2.47× |
| ARC-C | 83.2 | 83.5 (+0.3) | 1.88× | 88.1 | 87.9 (-0.2) | 2.61× |
| HellaSwag | 68.7 | 70.9 (+2.2) | 2.14× | 81.2 | 81.9 (+0.7) | 2.55× |
| TruthfulQA | 34.4 | 46.1 (+11.7) | 2.31× | 55.6 | 53.2 (-2.4) | 1.83× |
| WinoGrande | 73.8 | 70.5 (-3.3) | 1.71× | 62.5 | 62.0 (-0.5) | 1.45× |
| PIQA | 80.9 | 81.9 (+1.0) | 1.98× | 86.1 | 86.6 (+0.5) | 2.29× |
| 수학 및 과학 추론 | ||||||
| GSM8K | 77.1 | 77.9 (+0.8) | 1.63× | 75.3 | 75.2 (-0.1) | 1.71× |
| GPQA | 25.2 | 25.7 (+0.5) | 1.82× | 27.0 | 26.6 (-0.4) | 1.66× |
| 코드 생성 | ||||||
| HumanEval | 30.5 | 30.5 (0.0) | 1.20× | 54.9 | 55.5 (+0.6) | 1.44× |
| MBPP | 37.6 | 37.4 (-0.2) | 1.35× | 54.0 | 54.6 (+0.6) | 1.33× |
| 계획 수립 과제 | ||||||
| Countdown | 15.3 | 15.3 (0.0) | 2.67× | 14.6 | 14.6 (0.0) | 2.37× |
| Sudoku | 35.0 | 38.0 (+3.0) | 2.46× | 89.0 | 89.0 (0.0) | 3.40× |
6.2 결과 분석: 과제 유형별 성능 패턴과 속도-정확도 트레이드오프
Table 1의 결과를 종합적으로 분석하면, Prophet의 성능 패턴에서 몇 가지 중요한 경향성을 식별할 수 있다. 가장 두드러진 패턴은 과제 복잡도와 속도 향상 사이의 역상관 관계이다. 일반 추론 과제와 계획 수립 과제에서는 1.45~3.40×의 높은 속도 향상이 관찰되는 반면, 코드 생성 과제에서는 1.20~1.44×의 상대적으로 보수적인 속도 향상이 달성된다. 이는 Prophet가 과제의 복잡도에 맞게 자동으로 디코딩 예산을 조절하는 적응적 특성을 가지고 있음을 보여주는 핵심 증거이다. 코드 생성처럼 정밀한 구문과 복잡한 논리가 요구되는 과제에서는 신뢰도 갭이 높은 임계값에 도달하기까지 더 많은 정제 단계가 필요하므로, Prophet가 자연스럽게 더 많은 연산 자원을 할당하게 된다.
또 다른 중요한 관찰은 두 모델(LLaDA-8B와 Dream-7B) 간의 성능 패턴 차이이다. 전반적으로 Dream-7B가 대부분의 벤치마크에서 더 높은 베이스라인 정확도를 보이며, Prophet와의 결합에서도 약간 다른 패턴을 나타낸다. 예를 들어, TruthfulQA에서 LLaDA-8B의 Prophet는 +11.7 포인트의 극적인 향상을 보이지만, Dream-7B에서는 -2.4 포인트의 하락이 관찰된다. 이는 동일한 Prophet 전략이라도 기반 모델의 특성에 따라 효과가 달라질 수 있음을 시사하며, 모델별 최적화의 필요성을 제기한다. 그럼에도 불구하고, 두 모델 모두에서 대부분의 벤치마크에서 정확도 저하가 최소화되면서 유의미한 속도 향상이 달성된다는 점에서, Prophet의 범용성은 충분히 검증된 것으로 판단할 수 있다.
일반 추론 과제에서 Prophet는 전체 베이스라인의 성능을 일치시키거나 오히려 초과하는 능력을 보여준다. LLaDA-8B에서 Prophet는 MMLU에서 54.0%, ARC-C에서 83.5%를 달성하며, 두 경우 모두 전체 단계 디코딩과 통계적으로 동등한 수준이다. 특히 주목할 만한 것은 TruthfulQA에서 LLaDA-8B의 Prophet가 46.1%를 달성하여 베이스라인(34.4%)을 무려 11.7 포인트 상회한다는 점이다. 이는 과도한 정제가 오히려 초기에 올바르게 생성된 답변을 손상시킬 수 있음을 시사하며, Prophet의 조기 종료가 이러한 "과잉 정제(over-refinement)" 문제를 효과적으로 방지한다는 증거이다.
수학 및 과학 추론에서도 Prophet는 높은 신뢰성을 유지한다. GSM8K에서 LLaDA-8B의 Prophet는 77.9%의 정확도를 달성하여 베이스라인의 77.1%를 초과한다. Dream-7B에서도 75.2%로 베이스라인(75.3%)과 거의 동일한 성능을 보인다. GPQA에서도 유사한 패턴이 관찰된다.
코드 생성 벤치마크에서는 Prophet의 가속화가 더 보수적이다(HumanEval에서 1.20×, MBPP에서 1.35×). 이는 Prophet의 적응적 특성을 잘 보여주는데, 코드 생성과 같은 복잡한 과제에서는 답변 토큰의 수렴이 더 늦게 발생하므로, Prophet가 동적으로 더 많은 디노이징 단계를 할당하여 정확도를 유지한다. 이러한 행동은 Prophet가 과제의 난이도에 맞춰 자동으로 조절되는 "안전한" 가속화 방법임을 확인해 준다.
Prophet가 일부 벤치마크에서 전체 디코딩보다 오히려 높은 정확도를 달성하는 현상은 깊이 분석할 가치가 있다. HellaSwag에서 LLaDA-8B의 Prophet는 70.9%로 베이스라인(68.7%)을 2.2 포인트 초과하며, Dream-7B에서도 81.9% vs. 81.2%로 유사한 패턴이 관찰된다. 이는 "과잉 정제(over-refinement)"의 부정적 효과를 시사하는 중요한 증거이다. DLM의 후기 디코딩 단계에서 발생하는 추가적인 토큰 수정이 이미 안정화된 정답을 불필요하게 변동시켜 오히려 성능을 저하시킬 수 있다는 것이다. Prophet는 이러한 위험한 후기 수정을 방지함으로써, 단순한 가속화를 넘어서 품질 보호(quality preservation)의 역할까지 수행하는 것이다.
계획 수립 과제에서 Prophet는 가장 인상적인 속도 향상을 달성한다. Sudoku에서 Dream-7B는 3.40×의 속도 향상을 정확도 저하 없이 달성하며, Countdown에서도 두 모델 모두 2.37×~2.67×의 속도 향상을 보인다. 이러한 과제들은 답변이 상대적으로 간결하고 명확하여 조기 수렴 현상이 더욱 두드러지기 때문에 Prophet의 효과가 극대화되는 것으로 해석된다. 특히 Sudoku에서 LLaDA-8B의 Prophet가 38.0%로 베이스라인(35.0%)을 3.0 포인트 초과하면서도 2.46×의 속도 향상을 달성하는 것은, Prophet가 정확도와 속도를 동시에 개선할 수 있는 드문 사례를 보여준다. Sudoku는 8-shot 설정으로 평가되었으며, 블록 길이가 생성 길이와 동일한 24로 설정되어 전체 시퀀스가 한번에 정제되는 완전 병렬 디코딩 방식이 사용되었다. 이러한 설정에서 Prophet의 대폭적인 속도 향상은, 계획 수립 과제의 답변이 매우 간결하고 구조화되어 있어 모델이 빠르게 높은 확신도에 도달할 수 있기 때문이다.
요약하면, Prophet의 실험 결과는 DLM이 정답을 최종 디코딩 단계 훨씬 이전에 결정한다는 핵심 가설을 강력히 지지한다. Prophet는 모델의 예측적 확신도를 동적으로 모니터링하고, 답변이 안정화되는 즉시 반복적 정제 과정을 종료함으로써 유의미한 연산 절감을 달성한다. 일부 경우에는 오히려 성능 향상까지 수반하는데, 이는 정적 절단 방법이 디코딩 과정을 시기상조적으로 중단하여 정확도를 손상시키는 위험과 대비된다. Prophet는 따라서 DLM 추론을 가속화하기 위한 강건하고 모델 불가지론적인(model-agnostic) 해법을 제공하며, 실세계 배포에서의 실용성을 높이는 데 기여한다.
7. 추가 분석 및 Ablation Study: Prophet의 강건성과 호환성 검증
7.1 단계 예산 대비 정확도: 정적 절단 대비 Prophet의 우위
Table 2의 Panel A는 두 가지 생성 길이($L = 256$과 $L = 128$) 하에서 정제 단계 수에 따른 GSM8K 정확도를 요약한다. 정적 단계 상한 하에서의 정확도는 더 많은 단계에 따라 단조적으로 증가하지만(예: L=256에서 16단계: 7.7% → 32단계: 22.5% → 64단계: 58.8% → 128단계: 76.2%), 전체 예산 디코딩이나 Prophet에는 여전히 미치지 못한다.
| L | 단계 예산 ($T_{\max}$) | Prophet (평균 단계) | Full | |||
|---|---|---|---|---|---|---|
| 16 | 32 | 64 | 128 | |||
| 256 | 7.7 | 22.5 | 58.8 | 76.2 | 77.9 (≈160) | 77.1 |
| 128 | 21.8 | 50.3 | 67.9 | 71.3 | 72.7 (≈74) | 71.3 |
Prophet는 $L = 256$에서 평균적으로 약 160단계에서 적응적으로 종료하여(약 38%의 단계 절약, 256/160 ≈ 1.63×), 256단계 베이스라인보다 높은 점수(77.9% vs. 77.1%)를 달성한다. $L = 128$에서도 Prophet는 약 74단계만으로 128단계 베이스라인을 초과한다(72.7% vs. 71.3%). 이러한 결과는 Prophet의 이득이 단순히 더 적은 단계를 사용한 부산물이 아님을 재확인한다. Prophet는 답변이 이미 안정화되었을 때의 후기 단계 과잉 정제를 방지하면서도, 필요할 때는 추가 반복을 할당하는 지능적인 전략을 구현한다.
이 결과에서 또 하나 주목할 점은 생성 길이 $L$에 따른 Prophet의 적응적 행동이다. $L = 256$에서 Prophet는 평균 약 160단계를 사용하여 약 37.5%의 단계를 절약하는 반면, $L = 128$에서는 평균 약 74단계를 사용하여 약 42.2%의 단계를 절약한다. 즉, 더 짧은 생성 길이에서 Prophet의 상대적 절약이 더 크다. 이는 짧은 시퀀스에서 답변 영역이 전체 시퀀스에서 차지하는 비율이 더 높아, 신뢰도 갭이 더 빨리 임계값에 도달하기 때문으로 해석된다. 반대로 긴 시퀀스에서는 사고 사슬이 더 길어져 답변 토큰의 안정화에 더 많은 컨텍스트가 필요할 수 있으므로, Prophet가 더 보수적으로 행동하는 것이다. 이러한 생성 길이에 대한 자연스러운 적응성은 Prophet의 설계가 다양한 조건에서 강건하게 작동함을 보여주는 추가적인 증거이다.
7.2 블록 길이에 대한 민감도 분석
반자기회귀 업데이트의 세분화 수준(블록 길이)에 대한 민감도는 Prophet의 강건성을 평가하는 중요한 지표이다. Table 3은 정적 블록 스케줄이 취약하다는 것을 보여준다: 정확도는 중간 정도의 블록에서 정점을 찍고 큰 블록에서는 급락한다(블록 64에서 59.9, 블록 128에서 33.1). Prophet는 이러한 취약성을 현저히 완화하여, 전체 범위에 걸쳐 일관된 향상을 제공한다.
| 블록 길이 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|
| Baseline | 67.1 | 68.7 | 71.3 | 59.9 | 33.1 |
| Prophet | 72.8 | 73.3 | 72.7 | 69.8 | 52.2 |
| ∆(절대치) | +5.7 | +4.6 | +1.4 | +9.9 | +19.1 |
특히 블록 길이 64와 128에서 Prophet는 각각 +9.9와 +19.1 포인트의 정확도 향상을 달성한다. 이 결과는 Prophet의 시간에 따른 위험 회피 메커니즘의 직접적인 결과이다. 성긴(coarse-grained) 업데이트가 불확실성을 높이면 임계값 스케줄이 조기 커밋을 미루고, 예측이 안정되면 Prophet가 즉시 종료하여 추가적인 노이즈가 많은 수정(noisy revision)을 방지한다. 큰 블록 길이에서의 이러한 극적인 개선은 Prophet가 과도하게 공격적인 병렬 업데이트가 주입하는 노이즈의 부정적 영향을 효과적으로 완화한다는 것을 의미한다.
7.3 재마스킹 전략과의 호환성
Table 2의 Panel B는 세 가지 기성 재마스킹 휴리스틱(무작위, 저신뢰도, top-k 마진)에 대한 Prophet의 호환성을 평가한다.
| 재마스킹 전략 | Baseline | Prophet | ∆ |
|---|---|---|---|
| Random | 63.8 | 66.6 | +2.8 |
| Low-confidence | 71.3 | 72.7 | +1.4 |
| Top-k margin | 72.4 | 73.1 | +0.7 |
Prophet는 모든 정적 대응물을 일관되게 능가하며, 무작위 재마스킹에서 가장 큰 향상(+2.8 포인트)을 보인다. 이는 무작위 스케줄이 조기 답변 수렴을 더욱 부각시킨다는 앞서의 관찰과 일치한다. 더 정보에 기반한 휴리스틱(저신뢰도: +1.4, top-k 마진: +0.7)에서도 개선이 지속된다는 점은, Prophet의 정지 규칙이 토큰 선택 정책을 대체하는 것이 아니라 보완한다는 것을 시사한다.
7.4 Fast-dLLM과의 통합: 곱셈적 속도 향상
Prophet가 기존의 시스템 수준 최적화와 직교적임을 검증하기 위해, 저자들은 Prophet를 Fast-dLLM(Wu et al., 2025b)과 통합하여 LLaDA-8B의 GSM8K에서 실험하였다. Fast-dLLM은 KV-캐시와 병렬 디코딩을 활성화하여 단계당 비용을 줄이는 기법이며, Prophet는 전체 단계 수를 줄이는 기법이므로, 이 둘의 결합은 곱셈적 효과를 기대할 수 있다.
| 방법 | 정확도 | 속도향상 |
|---|---|---|
| Baseline (LLaDA-8B) | 77.1% | 1.00× |
| Fast-dLLM | 76.6% | 6.82× |
| Prophet + Fast-dLLM | 77.3% | 7.66× |
결과는 매우 인상적이다. 조합된 시스템은 약 7.66×의 속도 향상을 달성하면서도 정확도를 77.3%로 유지하여, 오히려 베이스라인(77.1%)보다 약간 높은 성능을 보인다. 이는 두 가지 기법이 서로 다른 차원에서 효율성을 최적화하므로 호환성이 매우 높다는 것을 확인시켜 준다. Fast-dLLM 단독으로는 약간의 정확도 하락(77.1% → 76.6%)이 있었지만, Prophet와의 결합은 이를 상쇄하고도 남는 결과를 보여준다.
7.5 오답 샘플의 디코딩 동역학 분석
Prophet의 안전성을 더욱 검증하기 위해, 저자들은 오답 샘플의 디코딩 동역학을 분석하였다. 핵심적인 우려 사항은 Prophet가 잘못된 답변에 대해 조기에 커밋하여 성능을 저하시키지 않는가이다.
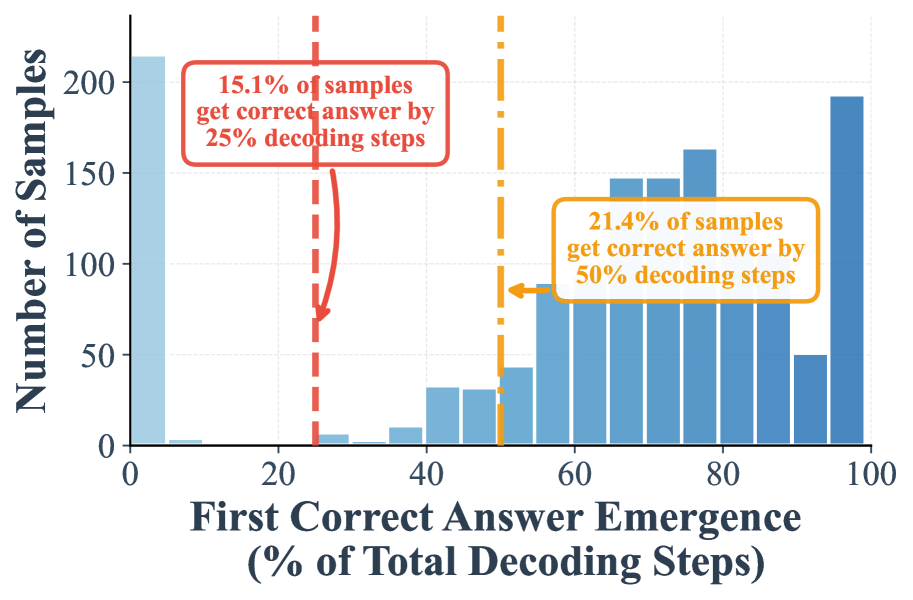

Figure 4(a,b): MMLU에서 저신뢰도 재마스킹 하의 조기 정답 탐지 분포. (a) 접미사 프롬프트 없이: 50% 시점까지 21.4%, (b) 접미사 프롬프트 사용 시: 50% 시점까지 99.9%. MMLU의 선택형 문제 특성상 극적인 조기 수렴이 관찰된다.

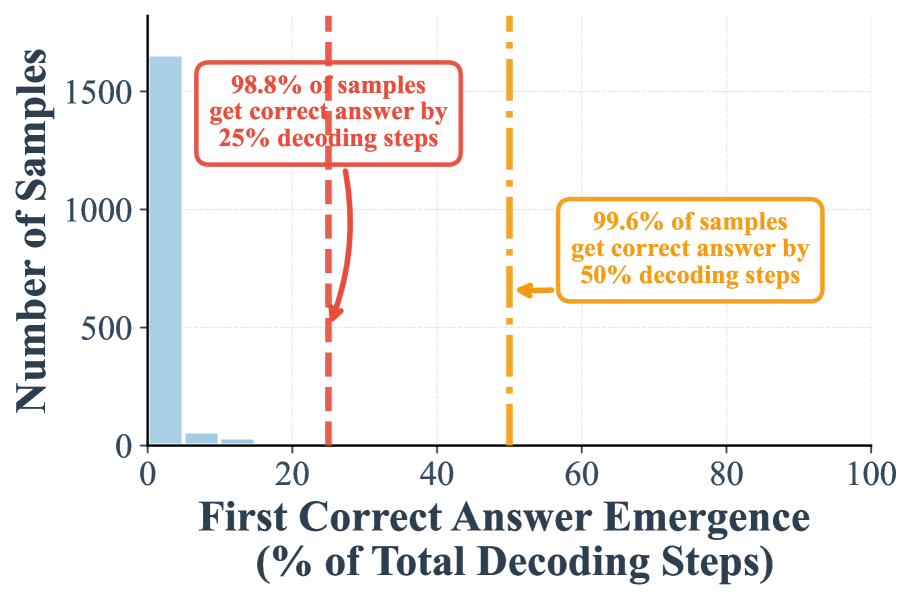
Figure 4(c,d): MMLU에서 무작위 재마스킹 하의 조기 정답 탐지 분포. (c) 접미사 프롬프트 없이: 50% 시점까지 99.2%, (d) 접미사 프롬프트 사용 시: 50% 시점까지 99.6%. 무작위 재마스킹에서 접미사 프롬프트 유무와 관계없이 매우 높은 조기 수렴률을 보인다.
Figure 4는 MMLU 벤치마크에서의 조기 정답 탐지 분포를 보여주며, GSM8K에서의 결과와 일관된 패턴을 확인할 수 있다. 특히 접미사 프롬프트와 저신뢰도 재마스킹의 조합(Figure 4(b))에서는 25% 시점까지 99.7%의 샘플이 정답에 도달하며, 50% 시점까지는 99.9%에 이른다. 이는 사실상 거의 모든 정답 샘플이 디코딩 과정의 극초기에 이미 수렴한다는 것을 의미한다. 무작위 재마스킹에서도 접미사 프롬프트 없이(Figure 4(c)) 25% 시점까지 95.3%, 50% 시점까지 99.2%의 정답률을 보이며, MMLU의 선택형 문제 특성상 답변 토큰이 매우 간결하여 수렴이 더욱 빠르게 일어남을 확인할 수 있다.
논문의 분석에 따르면, 오답의 업데이트는 전체 단계의 마지막 20%에 집중되어 있으며 강하게 우편향(right-skewed)되어 있다. 이는 모델이 틀렸을 때는 불확실성이 높은 상태를 유지한다는 것을 의미하며, 결과적으로 Prophet의 신뢰도 갭 기준이 충족되지 않아 조기 종료가 트리거되지 않는다. 즉, Prophet는 불확실한 샘플에 대해서는 자연스럽게 보수적으로 행동하여, 잘못된 조기 종료의 위험을 최소화한다. 이 자기 조절적 특성은 Prophet의 설계가 내재적으로 안전하다는 것을 보여주는 중요한 증거이다.
7.6 정성적 분석: 디코딩 궤적의 시각화
저자들은 DLM이 추론 체인이 완성되기 전에 답변을 식별한다는 것을 검증하기 위해 실제 디코딩 궤적을 제시한다. 간단한 산술 문제의 예시에서, 모델은 전체 단계의 10%에 불과한 시점에서 이미 답변 "3"을 최상위 토큰으로 확정한다. 이때 "To [MASK] [MASK] [MASK] add the [MASK] of blue [MASK] [MASK] the [MASK] of white [MASK] [MASK] [MASK] [MASK] 3 bolts ."와 같이 중간 추론 과정의 대부분은 여전히 마스킹된 상태이다. 50% 시점(Prophet의 종료 시점)에서는 "To find the total number of bolts, we need to add the [MASK] of blue fiber and the amount of white fiber. The robe takes 2 bolts of blue fiber. It also takes half that much white fiber, [MASK] [MASK] [MASK] 3 bolts."와 같이 추론 체인이 상당히 완성되었지만 여전히 일부 빈칸이 남아있는 상태에서 답변 "3"은 확정적이다. 100% 시점에서는 모든 토큰이 완성되어 "2/2 = 1"이라는 중간 계산이 드러나지만, 최종 답변은 동일한 "3"이다.
아래 표는 이 디코딩 궤적을 세 단계로 나누어 보여준다. 초기(약 10% 단계), Prophet의 조기 커밋 시점(약 50% 단계), 그리고 전체 디코딩 완료(100% 단계)에서의 시퀀스 상태를 비교할 수 있다.
| 단계 | 디코딩된 시퀀스 스트림 |
|---|---|
| 초기 (~10%) | To [MASK] [MASK] [MASK] add the [MASK] of blue [MASK] [MASK] the [MASK] of white [MASK] [MASK] [MASK] [MASK] 3 bolts . [MASK] [MASK] Answer : The answer is 3 |
| Prophet (~50%) | To find the total number of bolts , we need to add the [MASK] of blue fiber and the amount of white fiber . The robe takes 2 bolts of blue fiber . It also takes half that much white fiber , [MASK] [MASK] [MASK] 3 bolts . Final Answer : The answer is 3 |
| Full (100%) | To find the total number of bolts , we need to add the amount of blue fiber and the amount of white fiber . The robe takes 2 bolts of blue fiber . It also takes half that much white fiber , so it takes 2 / 2 = 1 bolt of white fiber . To find the total number of bolts , we add the amount of blue fiber and the amount of white fiber : 2 ( blue fiber ) + 1 bolt ( white fiber ) = 3 bolts . Therefore , the robe takes a total of 3 bolts . Final Answer : The answer is 3 |
이 정성적 분석은 Prophet의 조기 커밋 메커니즘의 효과를 직관적으로 확인시켜 준다. 모델의 내부 표현은 디코딩 과정의 매우 초기 단계에서 이미 정답 방향으로 수렴하고 있으며, 이후의 디코딩 단계는 주로 사고 사슬의 나머지 부분을 "채우는" 역할을 한다. 이는 DLM의 생성 메커니즘에 대한 흥미로운 통찰을 제공하는데, AR 모델이 순차적으로 추론하며 마지막에 답변에 도달하는 것과 달리, DLM은 먼저 답변을 "알고" 나서 이를 뒷받침하는 추론 과정을 구성해 나간다고 해석할 수 있다.
8. 심층 논의: DLM의 조기 수렴이 시사하는 바
8.1 왜 DLM은 디코딩 전에 답을 아는가: 내부 표현의 관점
본 논문의 가장 흥미로운 발견 중 하나는 확산 언어 모델이 사고 사슬(Chain-of-Thought)의 완성보다 훨씬 이전에 최종 답변을 내부적으로 결정한다는 것이다. 이 현상은 자기회귀 모델과 확산 모델의 근본적인 차이를 드러낸다. 자기회귀 모델에서는 토큰이 순차적으로 생성되므로, 모델은 반드시 추론 과정을 거쳐야 최종 답변에 도달할 수 있다. 즉, 사고 사슬이 답변의 전제조건이 된다. 반면 확산 모델에서는 모든 토큰이 병렬적으로 정제되므로, 모델의 내부 표현은 전체 시퀀스에 대한 전역적(global) 정보를 동시에 처리한다. 이러한 양방향 어텐션 메커니즘은 모델이 답변 토큰의 정확성을 사고 사슬 토큰의 완성과 독립적으로 조기에 확정할 수 있게 하는 구조적 기반을 제공한다.
이러한 관찰은 DLM의 내부 계산 과정에 대한 깊은 통찰을 제공한다. 확산 모델의 디노이징 과정에서, 초기 단계들은 전역적 의미 구조(global semantic structure)를 확립하는 데 주로 기여하는 반면, 후기 단계들은 로컬한 세부사항(local details)을 다듬는 역할을 한다는 해석이 가능하다. 답변 토큰은 의미 구조의 핵심적인 부분이므로 초기에 확정되고, 사고 사슬의 세부적인 표현(예: 구체적인 산술 계산 과정, 문법적 연결어 등)은 후기에 정제되는 것이다. 이는 이미지 생성을 위한 확산 모델에서 초기 단계가 전체적인 구조(예: 물체의 위치와 형태)를 결정하고 후기 단계가 세부 텍스처를 추가하는 현상과 유사한 계층적 생성 동역학으로 해석할 수 있다.
또한, 접미사 프롬프트("Answer:")가 조기 수렴을 크게 증폭시킨다는 발견은 DLM의 조건부 생성 메커니즘에 대한 추가적인 이해를 제공한다. DLM은 양방향으로 생성하기 때문에, 접미사 프롬프트는 답변이 위치해야 할 영역을 명시적으로 지정하는 구조적 단서(structural cue)로 작용한다. 이로 인해 모델의 어텐션이 답변 영역에 더 집중되고, 탐색 공간이 줄어들어 수렴이 가속화되는 것이다. 이는 실용적인 관점에서 DLM의 프롬프트 설계가 단순히 의미적 정보의 전달뿐만 아니라, 생성 과정의 구조적 유도에도 중요한 역할을 할 수 있음을 시사한다.
8.2 최적 정지 문제로서의 DLM 디코딩: 이론적 프레임워크
Prophet가 DLM 디코딩을 최적 정지 문제(optimal stopping problem)로 재구성한다는 점은 이론적으로 매우 의미심장하다. 최적 정지 문제는 확률론과 의사결정 이론에서 오랜 역사를 가진 고전적인 문제로, "비서 문제(secretary problem)"이나 금융의 옵션 행사 시점 결정 등 다양한 분야에서 연구되어 왔다. DLM 디코딩을 이 프레임워크에 매핑함으로써, 저자들은 단순한 엔지니어링 해법을 넘어서는 체계적인 접근 방식의 가능성을 열어준다.
구체적으로, 각 디코딩 단계에서의 결정은 "계속 정제할 것인가, 아니면 현재 상태로 최종화할 것인가"라는 이진 선택으로 모델링된다. 이때 두 가지 비용이 경쟁한다: 추가 정제의 연산 비용(시간과 에너지)과 조기 종료의 품질 위험(부정확한 답변의 가능성)이다. Prophet의 시간에 따른 위험 회피 정책은 이 트레이드오프에 대한 직관적이지만 효과적인 해법을 제공한다. 초기에는 위험 회피적으로(높은 임계값), 후기에는 위험 허용적으로(낮은 임계값) 행동함으로써, 이론적으로 최적에 가까운 정지 전략을 구현한다.
Prophet의 단계적 임계값 함수는 이 최적 정지 프레임워크의 가장 단순한 구현 형태로 볼 수 있다. 디코딩 진행도를 세 구간으로 분할하고, 각 구간에서 고정된 임계값을 적용하는 것은 본질적으로 구간별 상수 정책(piecewise constant policy)이다. 이러한 단순한 정책이 놀라울 정도로 효과적이라는 사실은, 조기 답변 수렴 현상이 매우 강건하고 일관적임을 반증한다. 만약 수렴 패턴이 과제나 샘플에 따라 크게 변동했다면, 이처럼 단순한 정책으로는 좋은 성능을 달성하기 어려웠을 것이다. 이는 DLM의 디코딩 동역학에 내재된 규칙성(regularity)의 존재를 시사하며, 더 정교한 정책의 설계를 위한 이론적 토대를 제공한다. 향후 연구에서는 이 규칙성의 수학적 특성화와 이에 기반한 이론적 최적 정지 규칙의 도출이 중요한 연구 과제가 될 것이다. 특히, 디코딩 진행도에 따른 신뢰도 갭의 확률적 모델을 구축하고, 이를 바탕으로 기대 비용을 최소화하는 최적 임계값 함수를 분석적으로 유도할 수 있다면, Prophet의 성능을 더욱 향상시킬 수 있을 것이다.
이 프레임워크의 확장 가능성도 풍부하다. 예를 들어, 벨만 방정식(Bellman equation)이나 지텐스-인덱스(Gittins index) 등의 최적 정지 이론의 도구를 적용하여, 단순한 3단계 임계값 대신 디코딩 상태의 충분 통계량(sufficient statistics)에 기반한 이론적으로 최적의 정지 규칙을 도출할 수 있을 것이다. 또한, 다중 무장 도적 문제(multi-armed bandit) 프레임워크를 적용하여, 여러 디코딩 전략(다양한 재마스킹 방법, 블록 크기 등) 간의 적응적 선택과 조기 종료를 동시에 최적화하는 통합적 접근도 가능할 것이다.
8.3 무작위 재마스킹 대 저신뢰도 재마스킹의 조기 수렴 차이
논문에서 관찰된 흥미로운 현상 중 하나는 무작위 재마스킹이 저신뢰도 재마스킹보다 훨씬 더 강한 조기 답변 수렴을 보인다는 것이다. GSM8K에서 접미사 프롬프트 없이 50% 단계까지 정답에 도달하는 비율이 저신뢰도 재마스킹에서는 24.2%에 불과하지만, 무작위 재마스킹에서는 97.2%에 달한다. 이 극적인 차이는 두 재마스킹 전략의 본질적 특성의 차이에서 비롯된다.
저신뢰도 재마스킹은 모델이 가장 불확실한 위치의 토큰을 선택적으로 재마스킹하는 전략이다. 이 방법은 직관적으로는 효율적으로 보이지만, 답변 영역의 토큰도 불확실성이 높으면 반복적으로 재마스킹되어 수렴이 지연될 수 있다. 특히 디코딩 초기에는 대부분의 토큰이 높은 불확실성을 가지므로, 답변 토큰이 일찍 안정화되더라도 재마스킹에 의해 다시 손상될 수 있다. 반면 무작위 재마스킹은 위치를 무작위로 선택하여 재마스킹하므로, 답변 토큰이 한번 올바르게 예측되면 재마스킹되지 않을 확률이 높아 안정적인 수렴이 촉진된다.
이러한 차이의 근본적인 원인을 더 깊이 이해하기 위해, 두 전략의 토큰 선택 메커니즘을 비교해 보자. 저신뢰도 재마스킹에서는 각 단계에서 가장 불확실한 $k$개의 토큰을 선택하여 재마스킹한다. 이때 $k$는 현재 디코딩 진행도에 따라 결정된다. 문제는 답변 토큰이 초기에는 상대적으로 높은 불확실성을 가질 수 있으며, 이 경우 반복적으로 재마스킹 대상으로 선택되어 "수렴-재마스킹-재예측"의 사이클에 빠질 수 있다는 것이다. 반면 무작위 재마스킹에서는 각 토큰이 균일한 확률로 재마스킹되므로, 한번 올바르게 예측된 답변 토큰이 재마스킹될 확률이 전체 마스킹 비율에 의해서만 결정되어, 대부분의 경우 한번 수렴한 답변이 유지된다.
이러한 분석은 실용적인 시사점을 가진다. 만약 주된 목표가 최대한 빠른 추론이라면, 무작위 재마스킹과 Prophet의 조합이 저신뢰도 재마스킹보다 더 효과적일 수 있다. 실제로 Table 2의 Panel B에서도 무작위 재마스킹에서 Prophet의 향상이 가장 크다(+2.8 포인트). 그러나 절대적인 정확도의 관점에서는 저신뢰도 재마스킹(72.7%)이 무작위 재마스킹(66.6%)보다 여전히 우수하므로, 속도와 정확도 간의 트레이드오프를 과제의 특성에 맞게 최적화하는 것이 중요하다.
8.4 Prophet와 자기회귀 모델의 추측적 디코딩과의 비교
Prophet의 조기 커밋 디코딩 아이디어는, 자기회귀 모델 영역에서의 추측적 디코딩(speculative decoding)과 흥미로운 유사점을 가진다. 추측적 디코딩에서는 작은 초안(draft) 모델이 빠르게 여러 토큰을 생성하고, 큰 검증(verification) 모델이 이를 한꺼번에 검증하여 올바른 토큰만을 수용한다. Prophet도 본질적으로 유사한 구조를 가지는데, 디코딩 중간 단계의 예측이 "초안"에 해당하고, 신뢰도 갭 기반의 수렴 판정이 "검증"에 해당한다고 볼 수 있다.
그러나 핵심적인 차이점이 존재한다. 추측적 디코딩은 별도의 초안 모델을 필요로 하며, 검증 과정에서도 큰 모델의 추가적인 순전파(forward pass)가 필요하다. 반면 Prophet는 이미 계산된 로짓에서 신뢰도 갭을 추출하므로 추가적인 모델 호출이 전혀 필요 없다. 또한, 추측적 디코딩은 토큰 수준의 정확성을 보장하는 반면, Prophet는 답변 영역 수준의 수렴을 판정한다는 점에서 추상화의 수준이 다르다. 이러한 비교는 DLM과 AR 모델이 효율적 추론이라는 동일한 목표를 향해 서로 다른 경로로 접근하고 있음을 보여준다.
이러한 비교는 더 넓은 맥락에서 효율적 추론(efficient inference)이라는 공통 목표를 향한 다양한 접근법들의 관계를 이해하는 데 도움을 준다. AR 모델 영역에서 추측적 디코딩이 큰 성공을 거둔 것처럼, DLM 영역에서도 Prophet와 같은 조기 종료 기법이 핵심적인 가속화 도구로 자리매김할 가능성이 높다. 두 패러다임 모두 "불필요한 연산을 식별하고 제거한다"는 공통 원칙에 기반하지만, 그 구체적 메커니즘은 각 모델 패러다임의 고유한 특성에 맞게 설계된다. 실제로 DLM 영역에서도 추측적 디코딩의 아이디어를 적용한 연구(Spiffy; Agrawal et al., 2025)가 있으며, Prophet와의 결합 가능성도 탐구할 가치가 있다. DLM 자체를 초안 모델로 사용하고 Prophet의 신뢰도 갭 기반 검증을 통합하면, 토큰 수준과 답변 수준의 두 가지 검증 메커니즘을 조합한 더욱 정교한 가속화 전략이 가능할 것이다.
8.5 실용적 배포에서의 고려사항
Prophet를 실제 프로덕션 환경에 배포할 때는 몇 가지 추가적인 고려사항이 있다. 첫째, 배치 처리(batch processing)에서의 효율성 문제이다. Prophet는 각 샘플이 서로 다른 시점에서 조기 종료되므로, 배치 내의 샘플들이 비동기적으로 완료된다. 이는 GPU 활용률의 관점에서 비효율적일 수 있으며, 동적 배치 스케줄링이나 조기 완료된 샘플의 패딩 처리 등의 추가적인 엔지니어링이 필요할 수 있다.
둘째, 스트리밍 생성(streaming generation)과의 호환성이다. 사용자 인터페이스에서 토큰이 점진적으로 나타나는 스트리밍 경험을 제공하려면, Prophet의 조기 종료 시점에서 갑작스럽게 모든 남은 토큰이 한꺼번에 출력되는 현상에 대한 사용자 경험(UX) 최적화가 필요하다. 예를 들어, 조기 커밋된 토큰들을 인위적으로 시간을 두고 순차적으로 표시하는 방식이 고려될 수 있다.
넷째, 지연 시간(latency) 대 처리량(throughput)의 관점도 중요하다. Prophet의 조기 종료는 개별 요청의 지연 시간을 줄이는 데 효과적이지만, 서버 환경에서의 처리량 최적화에는 별도의 고려가 필요하다. 예를 들어, 배치 내에서 서로 다른 시점에 조기 종료되는 샘플들을 어떻게 효율적으로 관리할 것인가의 문제, 그리고 조기 완료된 샘플의 GPU 메모리를 다른 요청에 재할당하는 동적 스케줄링 등이 시스템 수준에서 해결해야 할 과제이다. 현재 논문은 단일 샘플 수준의 단계 수 감소만을 보고하며, 실제 벽시계 시간(wall-clock time) 기준의 성능 비교나 다중 요청 환경에서의 처리량 분석은 포함되어 있지 않다.
다섯째, 안전성 및 신뢰성의 관점에서, Prophet의 조기 종료가 잘못된 답변을 고착시킬 가능성에 대한 추가적인 보호 장치가 필요할 수 있다. 현재 논문의 분석은 오답 샘플에서 신뢰도 갭이 낮게 유지된다는 것을 보여주지만, 이는 평균적인 경향이며 개별 사례에서는 높은 신뢰도로 잘못된 답변을 생성할 수 있다. 이러한 "자신감 있는 오답" 사례에 대한 추가적인 안전장치(예: 주기적인 확인 단계, 다중 샘플링과의 결합)가 실용적 배포에서 중요할 것이다.
9. 한계점 및 향후 연구 방향: 남은 과제와 가능성
9.1 현재 접근법의 한계
Prophet는 인상적인 결과를 달성하지만, 몇 가지 한계점을 가지고 있다. 첫째, 답변 영역의 사전 지정이 필요하다는 점이다. Prophet는 답변 영역 $\mathcal{A}$에 대한 평균 신뢰도 갭을 계산하므로, 이 영역이 명확하게 정의되어야 한다. 수학 문제나 다지선다형 질문에서는 답변 영역이 상대적으로 잘 정의되지만, 자유 형식의 장문 생성(open-ended long-form generation)에서는 답변 영역의 경계가 모호할 수 있다. 이러한 경우 Prophet의 적용이 제한될 가능성이 있다. 예를 들어, 에세이 작성이나 창의적 스토리 생성에서는 "답변"이라는 개념 자체가 불분명하며, 텍스트의 전체적인 일관성과 품질이 중요하므로 특정 영역에 대한 신뢰도 갭만으로는 수렴을 판단하기 어렵다.
둘째, 임계값의 수동 설정 문제가 있다. 현재 Prophet의 3단계 임계값($\tau_{\text{high}}$, $\tau_{\text{mid}}$, $\tau_{\text{low}}$)과 전환점(33%, 67%)은 예비 검증 실험을 통해 결정되며, 새로운 모델이나 도메인에 대해서는 별도의 튜닝이 필요할 수 있다. 논문은 대부분의 벤치마크에서 동일한 설정이 효과적임을 보여주지만, 최적의 임계값이 모델 아키텍처나 과제 특성에 따라 변동될 수 있다는 점은 완전한 자동화의 관점에서 개선의 여지가 있다. 특히, 코드 생성 벤치마크에서는 이미 $\tau_{\text{low}}$를 4.5로 높여야 했다는 사실은 과제별 튜닝의 필요성을 시사하며, 이는 범용적 적용에 대한 실질적인 장벽이 될 수 있다.
셋째, Prophet의 평가는 주로 정답이 명확한 과제들(수학, 지식 QA, 코드)에 집중되어 있다. 창의적 글쓰기, 대화 생성, 요약 등 출력의 품질이 다양한 차원에서 평가되는 개방형 생성 과제에서의 Prophet의 효과는 충분히 검증되지 않았다. 조기 커밋 디코딩이 텍스트의 유창성, 일관성, 다양성 등에 미치는 영향은 추가적인 연구가 필요하다. 특히, DLM이 장문의 텍스트를 생성할 때 조기 커밋이 텍스트의 후반부 품질에 미치는 영향, 그리고 생성된 텍스트의 의미적 완전성(semantic completeness)에 대한 체계적 평가가 부재하다.
넷째, WinoGrande에서의 성능 하락(-3.3 포인트 on LLaDA-8B)과 같은 일부 벤치마크에서의 성능 저하가 관찰된다. 이는 특정 유형의 과제에서는 후기 단계의 정제가 여전히 중요한 역할을 하며, Prophet의 조기 종료가 이러한 정제를 방해할 수 있음을 시사한다. WinoGrande와 같은 대명사 해소 과제는 문맥에 대한 미묘한 이해를 요구하며, 이러한 미묘한 차이는 신뢰도 갭에 충분히 반영되지 않을 수 있다. 또한 Dream-7B에서의 TruthfulQA(-2.4 포인트) 결과도 모델에 따라 Prophet의 효과가 다를 수 있음을 보여준다.
다섯째, 논문의 실험은 그리디 디코딩(greedy decoding)만을 사용하여 수행되었으며, 확률적 샘플링(stochastic sampling)이나 빔 서치(beam search) 등 다른 디코딩 전략과의 상호작용은 검토되지 않았다. 확률적 샘플링에서는 토큰의 선택이 본질적으로 확률적이므로, 신뢰도 갭의 의미와 수렴 판정의 신뢰성이 달라질 수 있다. 또한, 온도(temperature) 파라미터나 top-p/top-k 필터링과 Prophet의 조합에 대한 연구도 필요하다.
9.2 향후 연구 방향
본 연구는 DLM 디코딩을 최적 정지 문제로 재구성하는 새로운 관점을 제시하며, 이는 여러 흥미로운 후속 연구 방향을 열어준다. 첫째, 현재의 3단계 임계값 함수를 연속적이고 학습 가능한 함수로 대체하는 것이 가능할 것이다. 예를 들어, 별도의 작은 네트워크가 디코딩 상태(신뢰도 갭, 엔트로피, 진행도 등의 특성)를 관찰하고 최적의 종료 시점을 예측하도록 학습시키는 접근이 고려될 수 있다. 이러한 학습 기반 접근은 과제별 튜닝의 필요성을 제거하고, 더 세밀한 종료 결정을 가능하게 할 것이다.
둘째, 신뢰도 갭 외에도 엔트로피, 토큰 변동률, 은닉 상태의 코사인 유사도 등 다양한 수렴 메트릭을 조합하여 더 강건한 종료 기준을 설계할 수 있을 것이다. 예를 들어, 연속적인 디코딩 단계 간 은닉 상태의 변화량이 특정 임계값 이하로 떨어지면, 이는 모델 내부의 표현이 수렴했음을 의미하므로 종료 신호로 활용할 수 있다. 이러한 다중 메트릭 기반 접근은 신뢰도 갭만으로는 포착할 수 없는 수렴 패턴을 탐지할 수 있어, 개방형 생성 과제로의 확장에도 도움이 될 것이다.
셋째, 조기 답변 수렴 현상 자체에 대한 더 깊은 이론적 이해가 필요하다. 왜 DLM이 추론 체인의 완성 전에 답변을 "알 수" 있는지, 이것이 모델의 내부 표현 구조와 어떤 관계가 있는지에 대한 연구는 DLM의 작동 메커니즘에 대한 근본적인 통찰을 제공할 수 있다. 예를 들어, 디코딩 과정 중간의 어텐션 패턴 분석, 잔차 스트림(residual stream)의 분해, 프로빙(probing) 실험 등을 통해 모델이 답변 정보를 어떤 계층과 메커니즘을 통해 조기에 인코딩하는지를 밝힐 수 있을 것이다.
넷째, Prophet를 더 많은 DLM 아키텍처(Mercury, Gemini Diffusion, Seed Diffusion 등)와 다양한 규모의 모델에 적용하여 범용성을 더욱 검증하는 것이 필요하다. 특히, 모델 규모에 따른 조기 수렴 현상의 변화(더 큰 모델이 더 빨리 수렴하는가?)와 아키텍처적 차이(연속 시간 vs. 이산 시간 확산)에 따른 Prophet의 효과 차이를 체계적으로 분석하는 것이 중요하다. 또한, 다국어(multilingual) 과제에서의 Prophet의 효과도 탐구할 가치가 있다.
다섯째, 개방형 생성 과제에서의 Prophet의 확장과 적응, 특히 답변 영역이 명확하지 않은 경우의 자동 감지 메커니즘 개발이 중요한 연구 주제가 될 것이다. 예를 들어, 전체 시퀀스의 신뢰도 갭 분포를 분석하여 자연스럽게 수렴하는 "앵커 영역"을 자동으로 식별하는 방법이나, 과제의 유형을 자동으로 분류하여 적합한 모니터링 전략을 선택하는 메타 학습(meta-learning) 기반 접근이 고려될 수 있다.
10. 결론: 조기 수렴의 발견에서 실용적 가속화까지
본 논문은 확산 언어 모델의 근본적이면서도 간과되어 온 속성인 조기 답변 수렴(early answer convergence)을 체계적으로 식별하고 이를 실용적인 추론 가속화에 활용하였다. 포괄적인 분석을 통해, 최대 99%의 인스턴스가 절반의 정제 단계만으로도 올바르게 디코딩될 수 있음이 입증되었으며, 이는 기존의 전체 길이 디코딩에 내재된 상당한 연산적 중복성(computational redundancy)의 존재를 명확히 드러낸다. 이 관찰에 기반하여 제안된 Prophet는, 학습이 불필요하고 추가 오버헤드가 무시할 수 있는 수준인 조기 커밋 디코딩 패러다임으로서, 상위 2 예측 후보 간의 신뢰도 갭을 동적으로 모니터링하고 시간에 따른 위험 회피 정책에 기반한 단계적 임계값 함수를 통해 최적의 종료 시점을 결정한다.
LLaDA-8B-Instruct와 Dream-7B-Instruct에서의 12개 벤치마크에 걸친 실험은 Prophet가 최대 3.4배의 디코딩 단계 감소를 달성하면서도 생성 품질을 유지하거나 오히려 향상시킬 수 있음을 입증하였다. 특히 TruthfulQA에서의 +11.7 포인트 향상과 블록 길이 128에서의 +19.1 포인트 향상은 과잉 정제의 해로운 효과를 방지하는 Prophet의 독특한 이점을 보여준다. 또한 Fast-dLLM과의 통합을 통한 7.66배의 곱셈적 속도 향상은 Prophet가 기존 최적화 기법과 직교적으로 결합 가능한 범용적 가속화 도구임을 확인시켜 준다.
본 연구의 가장 심원한 기여는 DLM 디코딩을 고정 예산 반복(fixed-budget iteration) 문제가 아닌 최적 정지 문제(optimal stopping problem)로 재구성한 관점의 전환에 있다. 이 새로운 프레임워크는 효율적인 DLM 추론 연구의 방향을 근본적으로 전환하며, "각 단계를 어떻게 더 빠르게 할 것인가"에서 "언제 멈추는 것이 최적인가"로 질문을 바꾼다. 또한, 조기 수렴 현상의 발견은 DLM이 내부적으로 불확실성을 해소하는 메커니즘에 대한 과학적 이해를 심화시키며, 확산 모델의 계층적 생성 동역학—전역적 의미 구조의 조기 확립 후 로컬 세부사항의 점진적 정제—에 대한 새로운 통찰을 제공한다. 이러한 통찰은 DLM의 아키텍처 설계, 학습 전략, 프롬프트 엔지니어링에 이르기까지 광범위한 영향을 미칠 수 있으며, 확산 기반 언어 모델의 실용적 배포를 향한 중요한 진전이라 할 수 있다. 확산 언어 모델이 상용화 단계에 진입하고 있는 현재 시점에서, Prophet와 같은 학습 불필요 가속화 기법의 개발은 이론적 탐구를 넘어 실질적인 산업적 가치를 지니며, DLM 생태계의 성숙과 발전에 핵심적으로 기여할 것이다.
종합하면, Prophet는 DLM의 추론 가속화에 대한 새로운 패러다임을 확립하였다. 기존의 "단계당 비용 절감" 접근과 달리 "전체 단계 수 감소"라는 직교적 방향을 개척함으로써, 두 접근의 결합을 통한 곱셈적 속도 향상의 가능성을 열었다. 특히, 조기 답변 수렴이라는 현상의 발견과 이에 대한 체계적 분석은 DLM의 내부 작동 메커니즘에 대한 과학적 이해를 심화시키며, 이는 향후 DLM의 아키텍처 설계와 학습 전략에도 영향을 미칠 수 있을 것이다. 모델이 추론 과정의 완성 전에 이미 답변을 "알고 있다"는 사실은, 확산 기반 언어 모델이 정보를 처리하고 불확실성을 해소하는 방식이 기존의 자기회귀 모델과 근본적으로 다르다는 것을 시사하며, 이 차이를 더 깊이 이해하고 활용하는 것이 DLM 연구의 핵심적인 미래 방향이 될 것이다.
Prophet가 제시한 핵심 통찰은 확산 언어 모델에만 국한되지 않을 수 있다. "반복적 정제를 수행하는 모든 시스템에서, 최종 출력의 핵심 요소가 과정의 초기에 결정되는 현상"은 더 일반적인 원리일 수 있으며, 이미지 생성, 음성 합성, 분자 설계 등 다른 확산 기반 생성 시스템에서도 유사한 조기 수렴 현상이 관찰될 가능성이 높으며, 이를 검증하는 것은 중요한 연구 과제이다. 이러한 보편적 원리의 탐구와 활용은 확산 모델 전반의 효율성을 향상시키는 데 기여할 수 있으며, Prophet의 프레임워크는 이러한 포괄적 탐구를 위한 방법론적 출발점과 견고한 이론적 기반을 매우 충실하게 제공한다.
11. 요약 정리
- 조기 답변 수렴 현상 발견: DLM에서 최대 99%의 인스턴스가 전체 디코딩 과정의 절반 시점 이전에 이미 올바른 답변을 내부적으로 확정한다는 사실이 체계적으로 입증되었다.
- Prophet 제안: 학습이 불필요하고 추가 연산 오버헤드가 거의 없는 조기 커밋 디코딩 패러다임이며, 기존 DLM 추론 코드에 래퍼로 쉽게 통합할 수 있다.
- 신뢰도 갭 메트릭: 답변 영역에서 상위 2 예측 후보 간의 로짓 차이를 수렴 판정 기준으로 활용하며, 시간에 따른 3단계 임계값 스케줄로 동적 위험 회피를 구현한다.
- 최대 3.4배의 디코딩 단계 감소: Dream-7B의 Sudoku 과제에서 달성되었으며, 대부분의 벤치마크에서 1.5~2.5배의 속도 향상을 정확도 저하 없이 또는 오히려 정확도 향상과 함께 달성한다.
- 과잉 정제 방지 효과: TruthfulQA에서 +11.7 포인트, Sudoku에서 +3.0 포인트 등 일부 벤치마크에서 Prophet가 전체 디코딩을 초과하는 성능을 보이며, 이는 후기 단계의 과도한 정제가 오히려 해로울 수 있음을 시사한다.
- 블록 길이에 대한 강건성: 큰 블록에서 정적 스케줄이 급락하는 반면(블록 128에서 33.1%), Prophet는 52.2%로 +19.1 포인트의 향상을 달성하며 취약성을 현저히 완화한다.
- 다양한 재마스킹 전략과의 호환성: 무작위, 저신뢰도, top-k 마진 등 모든 재마스킹 휴리스틱에서 일관된 향상을 보이며, 토큰 선택 정책을 보완하는 역할을 한다.
- 기존 최적화 기법과의 곱셈적 결합: Fast-dLLM과의 통합으로 7.66배의 속도 향상을 달성하여, Prophet가 단계당 비용 최적화 기법과 직교적으로 결합 가능함을 입증한다.
- 자기 조절적 안전성: 오답 샘플에서는 신뢰도 갭이 낮게 유지되어 조기 종료가 자연스럽게 억제되며, 이는 Prophet가 불확실한 예측에 대해 보수적으로 행동하는 내재적 안전 메커니즘을 갖추고 있음을 보여준다.
- 새로운 관점의 제시: DLM 디코딩을 고정 예산 반복 문제가 아닌 최적 정지 문제로 재구성하여, 효율적 DLM 추론 연구의 새로운 방향을 개척하였다.