Recurrent-Depth VLA: Implicit Test-Time Compute Scaling of Vision–Language–Action Models via Latent Iterative Reasoning
https://arxiv.org/abs/2602.07845
Yalcin Tur, Jalal Naghiyev, Haoquan Fang, Wei-Chuan Tsai, Jiafei Duan, Dieter Fox, Ranjay Krishna | Stanford University, Technical University of Munich, University of Washington, Allen Institute for AI | arXiv:2602.07845 | 2026년 2월 | NeurIPS 2025
1. 서론: 로봇 제어에서 테스트 타임 연산 확장의 필요성
인간의 인지 시스템은 고정된 연산 예산으로 작동하지 않는다. 물건을 살짝 밀거나 손잡이를 조정하는 단순한 동작에서는 거의 반사적인 저노력 반응에 의존하지만, 복잡하게 어질러진 환경에서 정밀한 조작이 필요하거나 장기적 선견지명이 요구되는 상황에서는 인간의 인지가 적응적으로 자원을 재할당하여 감각 증거를 처리하고 내부 모델을 정제한 뒤에야 행동으로 옮긴다. 이처럼 과제 복잡도에 따라 "연산량"을 조절하는 능력은 효율적 추론의 핵심 특성이지만, 현대 로봇 공학에서는 여전히 중대한 도전 과제로 남아 있다.
현재 대부분의 비전-언어-행동(Vision-Language-Action, VLA) 모델은 고정된 연산 깊이를 사용하여 모든 제어 스텝을 동일한 수의 파라미터로 처리한다. 즉, 단순한 그리퍼 조정과 복잡한 공간에서의 고정밀 내비게이션에 동일한 연산량이 할당되는 것이다. 이러한 비효율성을 극복하기 위해 Chain-of-Thought(CoT) 프롬프팅을 활용한 추론 중심 VLA 모델들이 등장했으나, 이들은 토큰 수준에서 추론을 수행하기 때문에 메모리 사용량이 추론 체인 길이에 비례하여 선형적으로 증가하며, 연속적인 행동 공간에 적합하지 않다는 근본적 한계를 지닌다.
본 논문은 이러한 문제를 해결하기 위해 Recurrent-Depth VLA(RD-VLA)라는 새로운 아키텍처를 제안한다. RD-VLA는 명시적 토큰 생성 대신 잠재 공간(latent space)에서의 반복적 정제(iterative refinement)를 통해 연산 적응성을 달성하는 모델이다. 핵심 아이디어는 놀랍도록 단순하면서도 강력하다. 가중치가 공유된(weight-tied) 순환 액션 헤드를 사용하여, 동일한 트랜스포머 블록을 여러 번 반복 적용함으로써 잠재 표현을 점진적으로 정제하는 것이다. 이 구조는 상수 메모리 풋프린트로 임의의 추론 깊이를 지원하며, 파라미터를 추가하지 않고도 연산 깊이를 자유롭게 확장할 수 있다는 근본적 이점을 가진다.
훈련 시에는 Truncated Backpropagation Through Time(TBPTT)을 사용하여 정제 과정을 효율적으로 감독한다. 전체 순환 깊이에 대해 기울기를 전파하는 것은 메모리와 연산 비용 면에서 비현실적이므로, 마지막 8개 반복에 대해서만 기울기를 전파하고 그 이전 스텝은 기울기를 분리한다. 추론 시에는 잠재 수렴에 기반한 적응적 중단 기준을 통해 동적으로 연산을 할당하는데, 연속 반복 간 행동 출력의 차이가 임계값 이하로 줄어들면 모델이 충분히 수렴했다고 판단하여 반복을 중단한다. 논문의 실험 결과에 따르면, 단일 반복으로는 0%의 성공률을 보이던 과제가 4회 반복으로 90% 이상의 성공률을 달성하며, 기존 추론 기반 VLA 모델 대비 최대 80배의 추론 속도 향상을 달성한다.
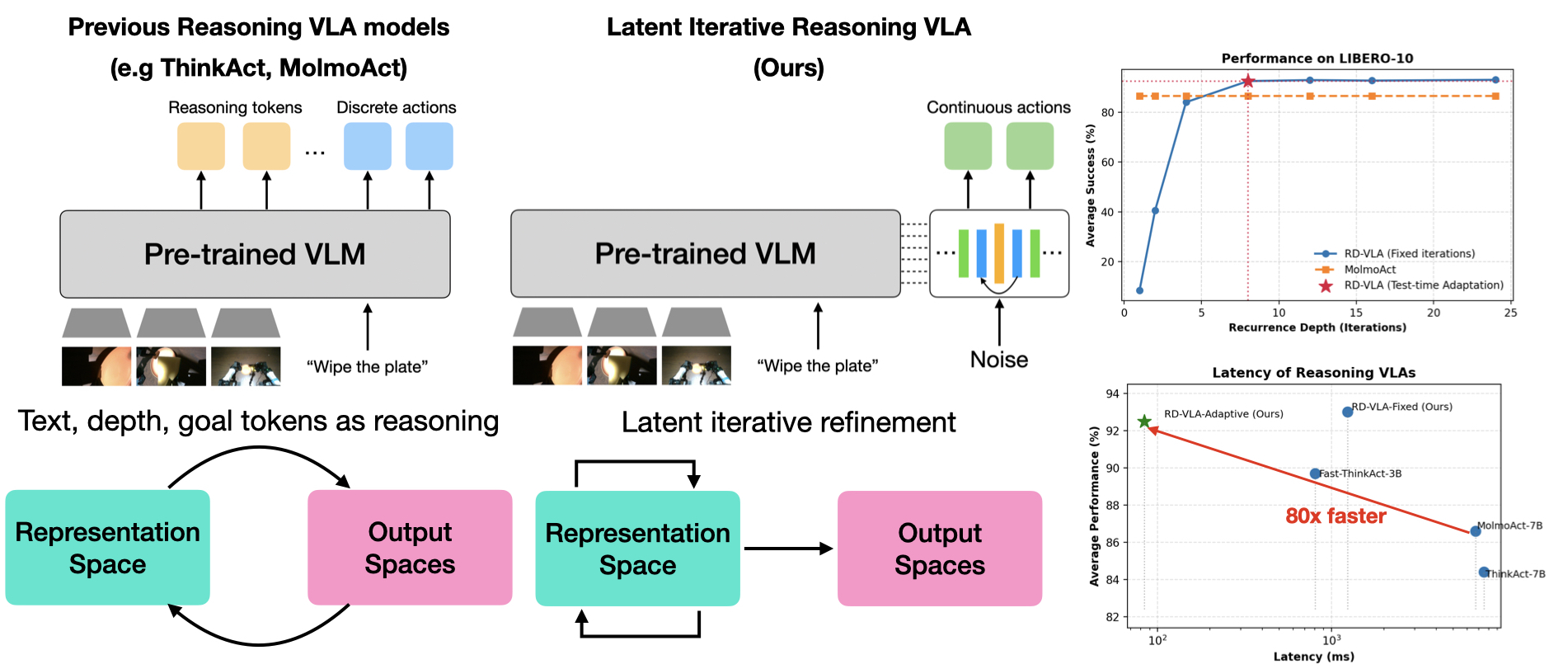
Figure 1: Recurrent-Depth VLA 개요. (좌) 기존의 추론 VLA(예: ThinkAct, MolmoAct)는 출력 공간에서 명시적 추론 토큰을 생성하여 비용이 큰 자기회귀적 디코딩이 필요하다. (중앙) RD-VLA는 잠재 표현 공간에서 전적으로 반복 정제를 수행하여 토큰 생성 오버헤드를 우회한다. (우) RD-VLA는 LIBERO-10에서 자기회귀적 추론 베이스라인과 동등한 성능을 달성하면서 적응적 연산 덕분에 실질적으로 더 빠르다.
이 논문의 핵심 기여는 크게 세 가지로 요약할 수 있다. 첫째, 로봇 추론이 중간 토큰을 디코딩하거나 행동 공간에서 계산 비용이 높은 디노이징 반복을 수행할 필요 없이 표현 공간 내에서 전적으로 이루어질 수 있다는 핵심 통찰을 제시한다. 이는 물리적 조작에 필요한 추론이 본질적으로 언어적 토큰화에 적합하지 않으며, 연속적인 내부 표현의 반복적 정제가 보다 자연스러운 추론 방식이라는 관점에 기반한다. 둘째, 액션 헤드를 Prelude(초기 인코딩 스택), Recurrent Core(가중치 공유 순환 블록), Coda(최종 프로젝션 레이어)의 세 단계로 분해하는 구체적인 아키텍처 설계를 도입한다. 이 삼분 구조는 순환 부분과 비순환 부분을 명확히 분리하여 각 구성 요소의 역할을 최적화하며, 백본에 구애받지 않는 모듈형 설계를 가능하게 한다. 셋째, KL 발산에 기반한 적응적 중단 기준과 적응적 실행 전략을 결합하여 과제 복잡도에 따라 연산량과 행동 지평을 동적으로 조절하는 추론 시간 프레임워크를 제안한다. 이 프레임워크는 외부에서 과제 난이도를 지정하지 않더라도 모델 내부의 수렴 신호만으로 최적의 연산-성능 균형점을 자동으로 찾을 수 있다는 점에서 실용적 가치가 높다.
본 논문의 실험적 검증은 포괄적이고 체계적이다. LIBERO 벤치마크의 4개 과제 범주(Spatial, Object, Goal, Long)에서 엔드-투-엔드 VLA, 토큰 추론 VLA 등 광범위한 베이스라인과의 비교를 수행하고, CALVIN 벤치마크에서 장기 지평 일반화를 검증하며, 실세계 양팔 로봇 환경에서의 배포 결과를 보고한다. 특히 0.5B 파라미터만으로 7B 모델들을 능가하는 결과는 아키텍처 설계의 중요성을 강하게 시사하며, 잠재 공간 추론이 파라미터 효율성과 연산 효율성 모두에서 토큰 기반 추론을 압도할 수 있는 잠재력을 보여준다.
2. 배경 및 관련 연구: VLA 모델과 추론 기반 접근법의 진화
2.1 비전-언어-행동(VLA) 모델의 발전
대규모 언어 모델(LLM)과 비전-언어 모델(VLM)은 시각 및 텍스트 데이터에 대한 깊은 의미적 이해와 강력한 문제 해결 능력을 보여왔다. GPT-4, LLaMA 3, Mixtral 같은 LLM들은 복잡한 추론과 계획 수립에서 인상적인 성과를 보이며, LLaVA, Qwen2-VL 같은 VLM들은 시각적 이해와 텍스트 추론을 결합하여 다중 모달 과제에서 강력한 일반화를 달성했다. 이러한 모델들은 대규모 인터넷 데이터를 활용하여 미지의 과제로 일반화할 수 있지만, 이에 필적할 만한 실세계 로봇 데이터를 수집하는 것은 여전히 어렵다. 로봇 데이터는 물리적 하드웨어와의 상호작용을 필요로 하므로 수집 비용이 높고, 환경의 다양성을 포괄하기 어렵기 때문이다. 로봇 데이터셋 구축의 발전에도 불구하고, 현재까지 가장 큰 데이터셋인 Open X-Embodiment는 21개 기관에서 22종의 로봇, 527개의 기술, 160,266개의 과제를 포함하고 있다.
이 데이터셋을 활용하여 Octo와 RT-1 같은 트랜스포머 기반 범용 로봇 정책이 훈련되었다. Octo는 0.09B 파라미터의 비교적 경량 모델로 다양한 로봇 플랫폼에서 동작하도록 설계되었으며, RT-1은 대규모 실세계 데이터를 통해 실시간 제어가 가능한 정책을 학습했다. 그러나 로봇 과제를 위해 처음부터 훈련된 이러한 모델들은 새로운 환경, 과제, 객체로의 일반화에 어려움을 겪었다. 이는 로봇 데이터의 규모와 다양성이 인터넷 데이터에 비해 근본적으로 제한적이기 때문이다.
RT-2는 550억 파라미터의 사전 훈련된 비전-언어 모델을 사용하여 행동을 생성함으로써 이 일반화 문제를 해결했다. 인터넷 규모의 사전 훈련을 통해 획득한 풍부한 시각적, 언어적 지식을 로봇 제어에 전이(transfer)하는 이 접근법은 큰 성공을 거두었으나, 모델 규모가 매우 커서 실시간 배포에 제약이 있었다. OpenVLA는 7B 파라미터 규모의 대표적인 오픈소스 대안으로 부상했으며, 후속작인 OpenVLA-OFT는 파인튜닝 전략을 최적화하여 속도와 성능을 동시에 개선했다. 이를 기반으로 $\pi_0$는 플로우 매칭(flow-matching)을 사용한 범용 정책을 도입하여 다중 모달 행동 분포를 효과적으로 모델링했고, $\pi_{0.5}$는 실시간 배포를 위한 보다 효율적이고 고성능인 후속 버전을 제공했다. 이러한 발전은 VLA 모델이 사전 훈련된 대규모 모델의 풍부한 표현력을 활용하는 방향으로 진화해왔음을 보여주지만, 연산 효율성과 추론 능력 사이의 균형은 여전히 핵심 과제로 남아 있다.
2.2 추론 및 효율적 연산 VLA 모델
VLA 모델의 파라미터 규모가 커짐에 따라, 연산 요구량과 로봇 제어의 실시간 요구사항 간의 균형이 점차 중요해지고 있다. 로봇 제어는 일반적으로 수십~수백 Hz의 주기로 행동 명령을 생성해야 하므로, 수 기가 파라미터 규모의 트랜스포머 백본을 매 제어 스텝마다 전체 실행하는 것은 실시간성을 심각하게 저해한다. 논문은 이 문제를 해결하기 위한 최근 연구가 두 가지 주요 방향으로 분기되었다고 서술한다.
첫 번째 방향은 기존 백본의 효율성을 최적화하는 것이다. TinyVLA는 대규모 모델의 지식을 소규모 모델로 증류(distillation)하여, 데이터 효율성을 유지하면서도 추론 속도를 크게 개선하는 데 집중한다. 이를 통해 제한된 컴퓨팅 자원을 가진 로봇 플랫폼에서도 고성능 VLA를 실행할 수 있게 한다. VLA-Cache는 로봇 제어에서 연속 프레임 간 시각 장면이 크게 변하지 않는다는 관찰에 기반하여, 텍스트 및 시각적 특성을 제어 스텝 간에 재사용하는 적응적 토큰 캐싱 메커니즘을 도입한다. 이 접근법은 불변하는 시각적 컨텍스트에 대한 중복 연산을 제거함으로써 추론 지연을 상당히 줄인다. DeeR-VLA는 모델 깊이를 동적 변수로 취급하여 과제 난이도에 따라 모델 세그먼트를 활성화하는 접근법을 제안한다. 사소한 움직임(예: 직선 이동)에서는 초기 레이어만 활성화하여 빠른 조기 종료(early exit)를 가능하게 하면서, 고엔트로피 조작(예: 정밀 파지)에서는 전체 모델 용량을 활용한다. DeeR-VLA의 접근법은 RD-VLA와 개념적으로 유사한 측면이 있으나, DeeR-VLA가 모델의 서로 다른 레이어를 선택적으로 활성화하는 반면, RD-VLA는 동일한 가중치의 레이어를 반복적으로 재사용한다는 점에서 근본적으로 다르다.
두 번째 방향은 중간 수준 표현을 통한 명시적 추론으로 성능을 향상시키는 것이다. Mobility-VLA는 장기 컨텍스트 VLM을 사용하여 토폴로지 그래프를 통한 내비게이션 추론을 수행하고, TraceVLA는 시각적 트레이스 프롬프팅을 활용하여 시공간 인식을 강화한다. 이들은 주로 이동(navigation) 과제에 특화된 반면, 조작(manipulation) 과제에서는 보다 일반적인 추론 메커니즘이 필요하다.
조작 과제를 위한 추론 중심 VLA 방법들도 활발히 연구되고 있다. Embodied Chain of Thought(ECoT)는 행동 출력 전에 텍스트 기반 정당화를 생성하는 체화된 사고 연쇄를 활용한다. 이 방법은 모델이 "왜 이 행동을 수행하는지"를 텍스트로 명시함으로써 행동의 질을 높이지만, 텍스트 생성에 따른 추가 지연이 발생한다. ThinkAct는 강화 학습을 통한 시각적 잠재 계획(visual latent planning)을 사용하여 행동 전 단계에서 시각적 추론을 수행하며, 최근 발표된 Fast-ThinkAct는 이를 더욱 효율화하여 언어화 가능한 잠재 계획(verbalizable latent planning)을 도입했다. MolmoAct는 깊이 인식 지각 토큰과 편집 가능한 궤적을 생성하는 Action Reasoning Models(ARMs)를 도입하여, 로봇이 행동 전에 시각적 궤적을 예측하고 검증할 수 있게 한다. CoT-VLA는 공간 제약과 객체 관계에 대한 시각적 사고 연쇄 추론이 분포 외 환경에서의 일반화를 크게 개선함을 보여준다. 그러나 이러한 토큰 수준 추론 방법들은 모두 메모리 사용량이 추론 체인 길이에 선형적으로 증가하고, 연속적 행동 공간과의 정합성이 떨어진다는 공통적 한계를 지닌다. 특히 토큰화된 추론은 이산적 표현으로의 변환 과정에서 정보 손실이 발생하며, 물리적 환경의 연속적 역학을 충실히 반영하기 어렵다.
2.3 순환 트랜스포머(Recurrent Transformers)
순환 트랜스포머는 트랜스포머의 전체 또는 일부 레이어를 순환시키는 아키텍처로, 나중 레이어의 표현이 이전 레이어로 다시 주입되는 구조를 의미한다. 이는 전통적인 순환 신경망(RNN)의 반복적 특성과 트랜스포머의 어텐션 메커니즘을 결합한 하이브리드 접근법이다. 초기 연구는 Dehghani 등이 제안한 Universal Transformer에서 시작되었으며, 이 모델은 단일 트랜스포머 레이어를 반복적으로 적용하여 가변적인 연산 깊이를 지원했다. 이후 다양한 아키텍처와 훈련 방법이 탐구되었으며, Gatmiry 등은 루핑과 깊이가 인컨텍스트 학습에서의 과제 다양성 처리에 중요한 역할을 한다는 이론적 분석을 제시했고, Saunshi 등은 레이어 스태킹이 추론 성능을 향상시키는 귀납적 편향을 제공함을 보여주었다.
대부분의 초기 연구가 장난감 규모에서의 귀납적 편향 검토와 알고리즘적 환경(산술, 패리티 검사 등)에 집중했으나, 최근 중요한 전환점이 되는 결과들이 발표되었다. Geiping 등의 "Scaling up Test-Time Compute with Latent Reasoning" 연구는 순환 트랜스포머가 파운데이션 모델 규모에서 효과적으로 작동하며, 잠재 추론을 통한 테스트 타임 연산 확장이 가능함을 입증했다. McLeish 등은 사전 훈련된 언어 모델에 순환성을 레트로핏(retrofit)하는 방법을 제안하여, 처음부터 순환 구조로 훈련하지 않더라도 기존 모델에 반복적 정제 능력을 부여할 수 있음을 보여주었다. 또한 Hao 등은 연속적 잠재 공간에서 추론하도록 대규모 언어 모델을 훈련하는 방법을 제시하여, 토큰 기반이 아닌 잠재 공간 기반 추론의 가능성을 열었다.
순환 트랜스포머는 레이어를 반복함으로써 연산을 확장할 수 있게 하며, 이를 통해 몇 가지 유용한 특성을 제공한다. 이러한 특성들을 구체적으로 살펴보면 다음과 같다.
- 테스트 타임 스케일링: 추론 시 순환 스텝 수를 증가시켜 모델의 유효 연산 깊이를 확장할 수 있다. 훈련 시의 깊이와 추론 시의 깊이를 분리할 수 있어, 동일한 모델로 다양한 연산 예산을 수용할 수 있다.
- 불확실성 정량화: 표현 수준에서 작동하므로 연속 반복 간의 코사인 거리, KL 발산, MSE 등을 통해 모델 확신도를 반영하는 지표를 자연스럽게 정의할 수 있다. 이는 토큰 공간에서의 불확실성 추정보다 더 풍부하고 연속적인 정보를 제공한다.
- 적응적 연산: 위의 불확실성 지표를 활용하여 반복 횟수를 동적으로 조정할 수 있다. 쉬운 입력에서는 적은 반복으로 빠르게 수렴하고, 어려운 입력에서는 더 많은 반복을 통해 정교한 추론을 수행한다.
- 특수 CoT 데이터 불필요: 큐레이팅된 사고 연쇄 감독 데이터 없이도 반복적 추론을 위한 아키텍처적 메커니즘을 제공한다. 이는 로봇 분야에서 특히 중요한데, 로봇 행동에 대한 사고 과정을 텍스트로 주석 달기가 매우 어렵고 비용이 높기 때문이다. "왜 이 방향으로 힘을 가해야 하는지"를 자연어로 설명하는 것은 거의 불가능하지만, 잠재 공간에서는 이러한 물리적 직관이 암묵적으로 인코딩될 수 있다.
이러한 특성들이 RD-VLA의 설계 영감이 되었음을 논문은 서술한다. 특히 NLP 분야에서 검증된 순환 트랜스포머의 잠재 추론 능력을 로봇 제어의 연속적 행동 공간으로 확장한다는 점에서, RD-VLA는 기존 연구의 자연스러운 발전이자 새로운 영역으로의 의미 있는 도약이라 할 수 있다.
2.4 확산 정책(Diffusion Policies)과의 차별점
RD-VLA의 반복적 정제 과정을 이해하기 위해, 확산 정책(Diffusion Policies)과의 차이를 명확히 하는 것이 중요하다. 확산 정책은 다단계 정제를 통해 행동을 생성하는 또 다른 반복적 접근법이다. Chi 등이 제안한 확산 정책은 행동 궤적을 출력 공간에서 반복적으로 디노이징하여 생성하며, 다중 모달 분포를 효과적으로 모델링하는 데 강점이 있다. 그러나 논문은 확산 정책이 근본적으로 생성적 샘플링 기법(generative sampling technique)이지 숙의적 기법(deliberative technique)이 아니라고 구분한다. 확산 정책은 행동 신호를 정제하지만, 장면에 대한 기저 표현을 확장하거나 풍부하게 하지는 않는다. 반면 RD-VLA의 순환 정제는 잠재 공간에서 장면의 내부 표현 자체를 반복적으로 개선함으로써, 보다 풍부한 이해에 기반한 행동 생성이 가능하다. 이러한 구분은 RD-VLA가 단순한 행동 정제가 아닌 진정한 의미의 "추론"을 수행한다는 주장의 근거가 된다.
3. 방법론: Recurrent-Depth VLA 아키텍처의 설계와 작동 원리
RD-VLA는 사전 훈련된 비전-언어 백본의 고정된 아키텍처적 제약으로부터 연산 깊이를 분리하도록 설계된 프레임워크이다. 표준 VLA 아키텍처가 고정 깊이 MLP 헤드나 출력 공간에서의 계산 집약적 반복 프로세스(확산 또는 플로우 매칭 액션 헤드)를 사용하는 반면, RD-VLA는 연산 부담을 연속적인 잠재 매니폴드(latent manifold) 내에서 작동하는 가중치 공유 순환 트랜스포머 코어로 전환한다. 이 설계는 순환 블록을 임의의 깊이 $r$로 언롤링하여 테스트 타임 연산을 확장할 수 있게 하며, 과제 복잡도에 따라 동적으로 연산을 할당할 수 있게 한다.
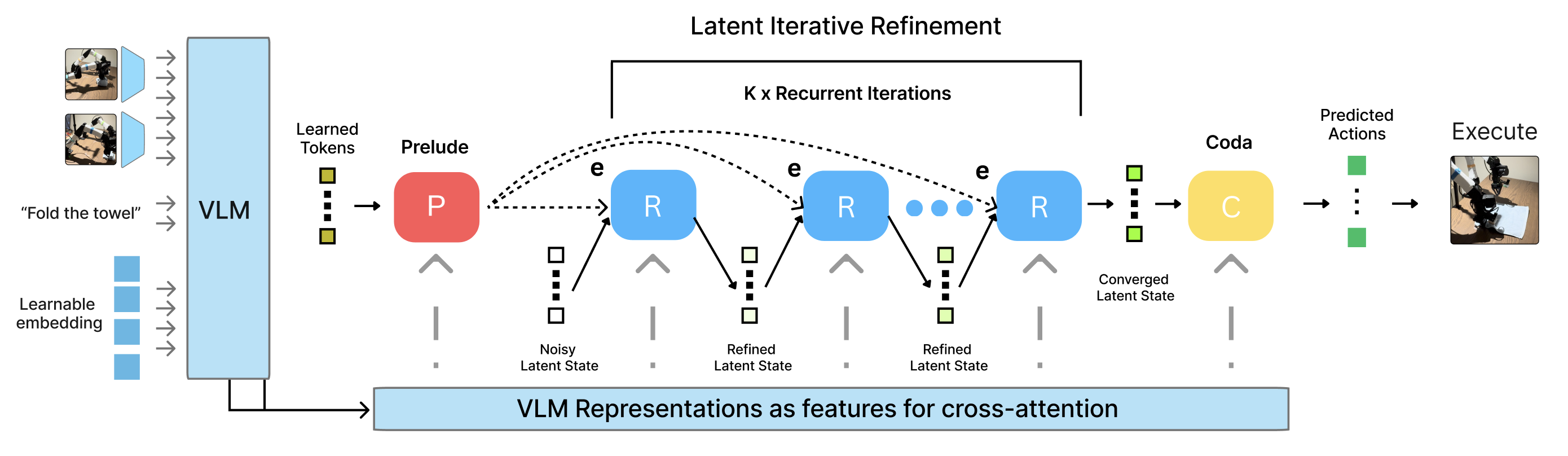
Figure 2: Recurrent-Depth VLA 아키텍처. Prelude(P)는 학습된 쿼리를 VLM 중간 레이어 특성에 대한 교차 어텐션을 통해 접지(grounding)한다. 가중치 공유 Recurrent Core(R)는 노이즈가 있는 잠재 스크래치패드를 $K$번 반복하여 정제하며, 최종 레이어 VLM 표현과 고유 수용 감각(proprioception)에 교차 어텐션한다. Coda(C)는 수렴된 상태를 행동으로 디코딩한다. 순환 깊이 $K$는 과제 복잡도에 따라 추론 시 동적으로 적응한다.
3.1 아키텍처 백본 및 토큰 흐름
RD-VLA의 액션 헤드는 밀집 잠재 표현을 생성하는 모든 비전-언어 모델(VLM)과 통합할 수 있도록 설계된 모듈형 프레임워크이다. 논문에서는 MiniVLA의 Qwen2.5-0.5B 기반 VLM을 사용하여 프레임워크를 구체화한다. 이 VLM은 Prismatic 훈련 레시피를 따르며, MiniVLA의 동결된(frozen) DINOv2와 SigLIP 융합 비전 인코더를 활용한다. 동결된 비전 인코더는 이미지 관측당 256개의 비전 토큰을 생성하며(손목 카메라와 메인 카메라 합산 시 512개), 이들은 LoRA로 파인튜닝된 Qwen2-0.5B(24레이어) LLM 백본에 프로젝션된다.
OpenVLA-OFT의 아키텍처 설계 원칙을 따라, VLM 입력 시퀀스에 64개의 전용 학습된 잠재 임베딩(learned latent embeddings)이 추가된다. 이 토큰들은 LLM의 순방향 패스 동안 다중 모달 컨텍스트에 어텐션하는 특수화된 접지 플레이스홀더 역할을 한다. VLM 실행 후, 히든 상태가 추출되어 두 가지 별개의 집합으로 분할된다. 첫째는 공간적 및 의미적 장면 정보를 포착하는 태스크/비전 표현 $h_{vis} \in \mathbb{R}^{512 \times D}$이고, 둘째는 잠재 토큰 위치에서 추출되어 압축된 과제 정렬 특성을 제공하는 잠재 특화 표현 $h_{lat} \in \mathbb{R}^{64 \times D}$이다. 이 표현들은 결합되어 정적 조건화 매니폴드를 형성하며, 순환 헤드 $R_\theta$는 각 반복 $k$에서 연결된 컨텍스트 벡터 $[h_{vis+lat}^{(24)}; p]$에 교차 어텐션을 수행하여 잠재 추론 과정을 관측과 고수준 의미 토큰 모두에 효과적으로 접지한다.
3.2 순환 깊이 아키텍처: Prelude, Recurrent Core, Coda
RD-VLA는 Huggin 접근법에 영감을 받아 아키텍처를 기능적 삼중체(functional triplet)로 분할한다. 이는 Prelude(서곡), Recurrent Core(순환 코어), Coda(종결부)로 구성되며, Prelude와 Coda는 반복적 추론에 최적화된 전용 잠재 매니폴드 안팎으로 표현을 매핑하는 비순환 인터페이스 레이어 역할을 한다. 이러한 삼분 구조는 순환 부분과 비순환 부분을 명확히 분리함으로써, 순환 코어가 표현 정제에만 전념할 수 있게 하면서도 입출력 인터페이스의 유연성을 보장한다.
프로세스는 Prelude ($P_\phi$)에서 시작된다. Prelude는 $K=8$개의 학습된 쿼리를 소비하는 비순환 인터페이스이다. 먼저 $K$개의 쿼리가 양방향으로 자기 어텐션을 수행한 후, VLM의 중간 레이어(12번째 레이어) 시각적 특성 $h_{vis+lat}^{(12)}$에 대한 교차 어텐션을 수행하여 이들 쿼리를 접지된 잠재 기반으로 변환한다.
$$S_{pre} = P_\phi(\text{Queries}, h_{vis+lat}^{(12)}) \in \mathbb{R}^{K \times D}$$
이와 병렬로, 추론 과정의 진화하는 상태로 사용될 잠재 스크래치패드(latent scratchpad) $S \in \mathbb{R}^{K \times D}$가 고엔트로피 절단 정규 분포로부터 초기화된다.
$$S_0 \sim \text{TruncNormal}(0, \gamma_{init} \cdot \sigma_{init})$$
스크래치패드라는 명칭은 이 텐서가 모델의 "작업 메모리(working memory)" 역할을 한다는 개념에서 유래한다. 마치 인간이 복잡한 문제를 풀 때 종이 위에 중간 계산을 기록하듯, 모델은 스크래치패드에 반복적으로 정보를 기록하고 수정하며 최종 결과에 도달한다. 이 노이즈 초기화는 $S$를 모델이 반복적으로 "정리"하고 정제해야 하는 빈 작업 공간으로 변환한다. 노이즈가 있는 상태에서 시작함으로써, 모델은 특정 시작점에 과적합하지 않고 임의의 초기 상태에서도 안정적으로 수렴하는 일반적인 정제 연산자를 학습하게 된다.
이러한 노이즈 초기화 전략은 확산 모델에서의 가우시안 노이즈 초기화와 표면적으로 유사하지만, 근본적으로 다른 목적과 메커니즘을 가진다. 확산 모델은 출력 공간(행동 궤적)에서 노이즈를 점진적으로 제거하여 샘플을 생성하는 생성 모델이다. 반면 RD-VLA는 잠재 표현 공간에서 노이즈를 정리하여 행동의 기반이 되는 내부 이해를 구축하는 숙의 모델이다. 확산 정책은 각 디노이징 스텝에서 출력 분포를 직접 정제하지만, RD-VLA의 순환 코어는 장면과 과제에 대한 모델의 내부 표현을 정제한다. 이 차이는 실용적으로도 중요한데, 확산 정책은 보통 수십~수백 스텝의 디노이징이 필요한 반면, RD-VLA는 8-12회의 순환으로 충분히 수렴하며, 각 순환의 연산 비용도 전체 모델 순방향 패스보다 훨씬 저렴하다.
3.3 잠재 반복 추론과 입력 주입(Input Injection) 전략
핵심적인 반복 정제는 Recurrent Core ($R_\theta$)에서 이루어진다. 이는 가중치가 공유된 트랜스포머 블록으로, 긴 언롤링 과정에서 모델이 물리적 관측에 대한 파악력을 잃는 표현 붕괴(representational collapse)를 방지하기 위해 지속적인 입력 주입(Input Injection) 전략을 활용한다. 각 스텝 $k$에서 순환 블록은 현재 스크래치패드 상태 $S_{k-1}$과 Prelude가 제공한 정적 기반 $S_{pre}$ 모두를 관측한다.
구체적으로, 각 반복 $k = 1 \dots r$에서 이전 스크래치패드 상태 $S_{k-1}$이 고정된 $S_{pre}$와 특성 차원을 따라 연결되어 $2D$ 차원의 컨텍스트를 형성한다. 이것은 학습된 어댑터를 통해 매니폴드 차원으로 다시 매핑되고 정규화된다.
$$x_k = \text{RMSNorm}\left(\gamma_{adapt} \cdot W_{adapt}[S_{k-1}; S_{pre}]\right)$$
여기서 $W_{adapt} \in \mathbb{R}^{D \times 2D}$이다. 이후 스크래치패드 상태는 가중치 공유 순환 블록을 통해 업데이트된다.
$$S_k = R_\theta(x_k, [h_{vis+lat}^{(24)}; p])$$
이 업데이트 과정에서 $R_\theta$는 먼저 $K$에 대해 양방향 자기 어텐션을 수행한 후, 쿼리가 $x_k$에서 유도되고 키/값이 연결된 조건화 매니폴드 $[h_{vis+lat}^{(24)}; p]$에서 유도되는 게이트 교차 어텐션(gated cross-attention)을 수행한다. 이 매니폴드는 VLM 최종 레이어의 64개 과제 정렬 잠재 토큰과 512개 비전 토큰, 그리고 로봇의 현재 고유 수용 감각 $p$로 구성된다. 입력 주입 전략의 핵심은 매 반복마다 원래의 정적 기반 정보를 재주입함으로써 긴 반복 과정에서도 관측 정보가 희석되지 않도록 보장한다는 것이다.
이 설계 결정의 중요성을 이해하기 위해, 입력 주입 없이 순수하게 스크래치패드 상태만 전달하는 경우를 고려해보자. 반복이 깊어질수록 초기 관측 정보가 점차 소실되는 표현 붕괴(representational collapse) 현상이 발생할 수 있다. 이는 순환 신경망(RNN)에서의 기울기 소실(vanishing gradient) 문제와 유사한 맥락이지만, RNN이 시간 축을 따라 정보를 전달하는 반면 RD-VLA는 동일 입력에 대한 반복적 정제에서 이 문제가 발생한다는 점에서 다르다. 입력 주입은 이 문제를 $S_{pre}$의 연결(concatenation)과 어댑터를 통한 재매핑으로 우아하게 해결한다. 매 반복에서 모델은 항상 (1) 이전 반복의 정제 결과와 (2) 원래 관측에서 파생된 고정 기반 정보를 모두 접근할 수 있으므로, 정제 과정이 아무리 깊어져도 물리적 관측과의 연결이 유지된다. 이는 ResNet의 잔차 연결(residual connection)이 깊은 네트워크에서 기울기 흐름을 보장하는 것과 개념적으로 유사하지만, 여기서는 기울기가 아닌 정보의 흐름을 보장한다. 또한 게이트 교차 어텐션을 통해 순환 코어가 VLM 최종 레이어의 576개 토큰(512 비전 + 64 잠재)과 고유 수용 감각 정보에 매 반복 어텐션함으로써, 현재 장면 상태에 대한 최신 정보가 지속적으로 순환 정제 과정에 주입된다.
3.4 Coda를 통한 행동 프로젝션과 랜덤화된 순환 훈련
순환이 원하는 깊이 $r$에 도달하면, 수렴된 스크래치패드 $S_r$은 비순환 Coda ($C_\psi$)에 의해 처리된다. Coda는 Prelude와 대칭적인 구조를 가지며, 잠재 매니폴드 내의 정제된 표현을 행동 공간으로 변환하는 최종 디코딩 단계 역할을 한다. Coda는 표현을 잠재 매니폴드 밖으로 이동시키는 최종 디코딩 패스를 수행하며, 자기 어텐션과 고수준 VLM 특성 $h_{vis+lat}^{(24)}$에 어텐션한다. 이 과정에서 Coda는 순환 코어가 정제한 추상적 추론 결과를 구체적인 로봇 제어 명령으로 "번역"하는 역할을 수행한다. 마지막으로 출력 프로젝션 레이어가 이 정제된 특성을 로봇의 행동 공간으로 매핑한다.
$$\mathbf{a} = W_{out} \cdot \text{RMSNorm}(C_\psi(S_r, [h_{vis}^{(24)}; h_{lat}^{(24)}; p]))$$
여기서 $W_{out}$은 제어 명령 $\mathbf{a}$를 생성하는 최종 선형 레이어이다. 이 아키텍처는 모든 중간 상태 $S_k$가 유효한 표현이 되도록 보장하면서, $S_{k+1}$이 행동 계획의 엄격하게 더 정제된 반복을 나타내도록 한다.
훈련 시 초기화 깊이와 무관하게 정상 상태로의 수렴을 촉진하기 위해, 반복 횟수 $N$은 중꼬리 로그-정규 포아송 분포에서 샘플링된다.
$$\tau \sim \mathcal{N}(\ln(\mu_{rec}) - 0.125, \sigma^2), \quad N \sim \text{Poisson}(e^\tau) + 1$$
여기서 $\mu_{rec} = 32$이다. 훈련에는 TBPTT(Truncated Backpropagation Through Time)가 사용되며, 기울기는 마지막 $d = 8$개 반복에 대해서만 전파되고 그 이전 스텝들은 기울기가 분리(detached)된 상태로 연산된다. 이 접근법은 네트워크가 모든 노이즈 초기화에서 스크래치패드를 안정적인 매니폴드로 반복 정제하는 것을 학습하도록 강제하여, $S_{k+1}$이 $S_k$의 엄격하게 더 나은 정제임을 보장한다. 이를 통해 모델은 재훈련 없이도 추론 시 연산을 동적으로 확장할 수 있게 된다. 랜덤화된 순환 깊이는 모델이 특정 반복 횟수에 의존하지 않고, 임의의 깊이에서 시작하더라도 점진적으로 정제할 수 있는 일반적인 연산자를 학습하도록 하는 핵심 훈련 전략이다.
3.5 적응적 연산(Adaptive Computation)
모델의 내재적 특성을 활용하여, RD-VLA는 추론 시 적응적 연산 메커니즘을 구현한다. 고정된 반복 횟수를 지정하는 대신, 모델 자체의 내부 수렴을 추론 확실성의 프록시로 활용한다. 중단 기준은 연속 반복 간 행동 분포의 Kullback-Leibler(KL) 발산에 기반하여 정의된다. 행동 공간에서 평균 제곱 오차(MSE)를 통해 KL을 근사하면, 추론 루프는 다음 조건이 충족되는 스텝 $k^*$에서 종료된다.
$$\|\mathbf{a}_k - \mathbf{a}_{k-1}\|_2^2 < \delta$$
여기서 $\mathbf{a}_k$는 스텝 $k$에서의 예측 행동 청크이고, $\delta$는 수렴 임계값(예: $1e^{-3}$)이다. 이를 통해 모델은 자기 조절이 가능해진다. 즉, 사소한 움직임에서는 즉시 종료하면서 복잡한 상황에서는 확장된 연산을 할당할 수 있다. 이러한 적응적 연산 메커니즘은 외부에서 과제 난이도를 판단할 필요 없이, 모델이 자체적으로 내부 표현의 수렴 정도를 모니터링하여 연산량을 결정한다는 점에서 우아한 설계라 할 수 있다.
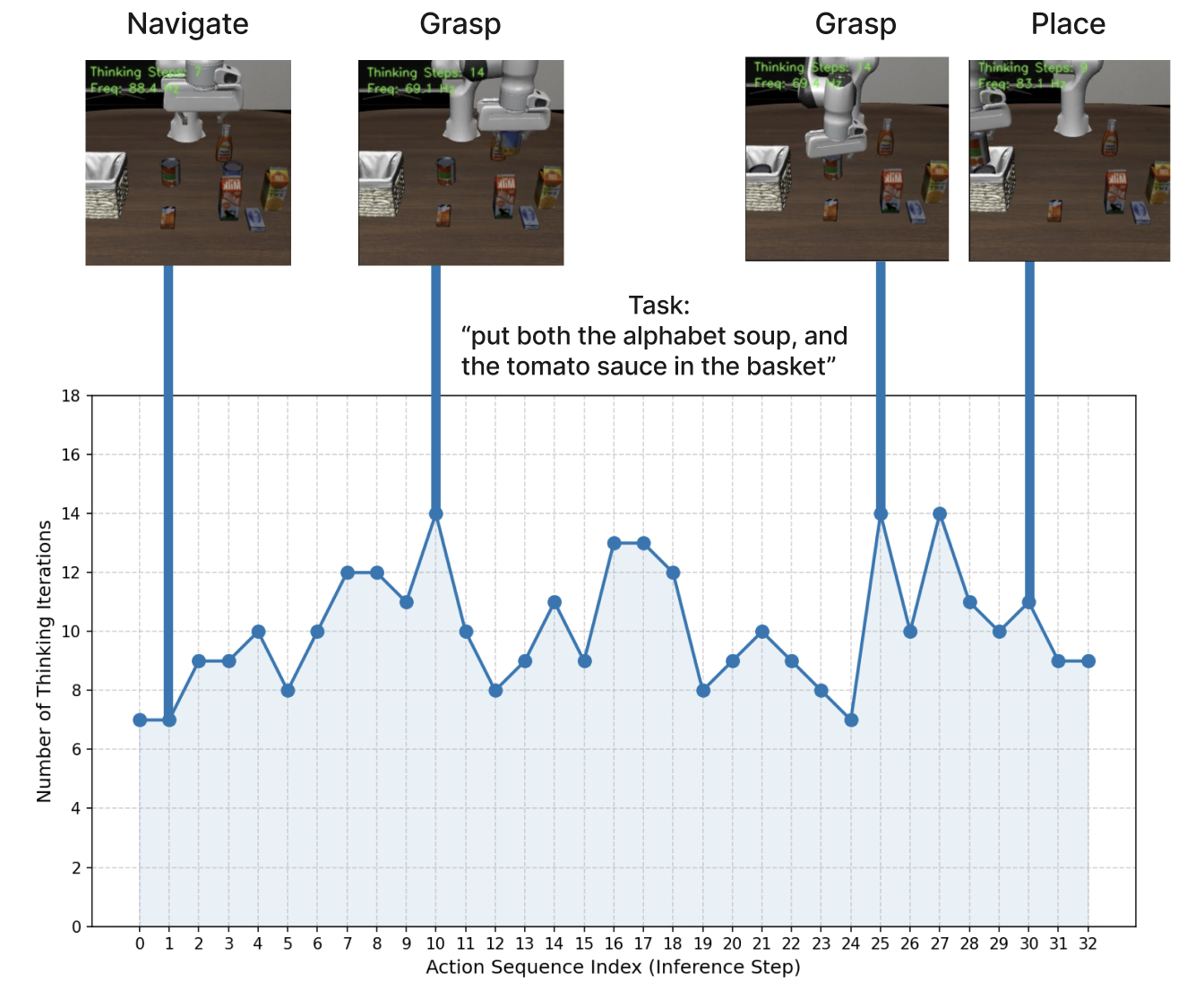
Figure 3: 적응적 연산 사례 연구. LIBERO 롤아웃에서 모델은 실행 상태에 따라 종료 전 서로 다른 수의 반복을 동적으로 선택한다. 내비게이션과 배치 같은 단순한 동작에 해당하는 스텝 1과 30에서는 더 적은 반복(7-9회)을 사용하고, 파지와 같이 더 복잡한 행동이 요구되는 스텝 10과 25에서는 더 많은 반복(약 14회)을 사용한다.
3.6 적응적 실행(Adaptive Execution)
적응적 연산이 순환의 지속 시간을 결정하는 반면, 적응적 실행은 몇 개의 행동을 실행할 것인지를 결정한다. 논문은 깊은 순환이 필요한 경우($k^* > 8$)가 종종 높은 불확실성 상태에 대응한다고 관찰한다. 이러한 상황에서 긴 행동 지평(horizon)을 실행하는 것은 위험한데, 초기 계획의 작은 오류가 시간이 지남에 따라 복합적으로 증가하기 때문이다. 이를 해결하기 위해 논문은 추론 깊이와 행동 실행을 결합하는 두 가지 전략을 제안한다.
첫 번째는 임계값 기반 적응적 실행(Threshold-Based Adaptive Execution)으로, 이진 추론 임계값 $\tau$를 사용하여 실행 지평을 조절한다. 수렴에 $k^* > \tau$ 스텝이 필요하면 복합 오류를 완화하기 위해 지평을 $H_{short}$로 단축하고, 확신 있는 예측($k^* \leq \tau$)에서는 $H_{long}$을 유지한다.
$$H_{exec} = \begin{cases} H_{long} & \text{if } k^* \leq \tau \\ H_{short} & \text{if } k^* > \tau \end{cases}$$
두 번째는 선형 감쇠 실행(Linear Decay Execution)으로, 추론 깊이에 반비례하여 실행 지평을 줄이는 연속적 스케일링 메커니즘이다. 기본 반복 예산 $\tau_{base}$가 주어지면, 수렴에 필요한 추가 반복마다 지평 $H_{exec}$이 한 스텝씩 감소한다.
$$H_{exec}(k^*) = \max\left(H_{min}, H_{max} - \max(0, k^* - \tau_{base})\right)$$
두 번째 전략의 수학적 표현에서 $H_{min}$은 최소 실행 지평(최소한 한 스텝은 실행), $H_{max}$는 최대 실행 지평(전체 행동 청크)을 나타낸다. 예를 들어 $\tau_{base} = 4$, $H_{max} = 10$, $H_{min} = 1$인 설정에서 수렴에 $k^* = 8$회 반복이 필요하면, 실행 지평은 $\max(1, 10 - 4) = 6$으로 설정된다. 이 접근법은 연산 수요가 증가할수록 에이전트가 더 자주 재계획하도록 강제하며, 복잡한 상태에서 효율성보다 안전을 우선시한다. 두 전략 모두 추론 깊이라는 모델의 내부 신호를 활용하여 행동 실행의 보수성을 조절한다는 공통적 통찰에 기반한다.
이러한 적응적 실행 전략은 로봇 제어에서 매우 실용적인 가치를 지닌다. 불확실한 상황에서 긴 행동 시퀀스를 한 번에 실행하면, 첫 몇 스텝에서의 작은 오차가 후속 스텝으로 복합적으로 증가하여 과제 실패로 이어질 수 있다. 적응적 실행은 불확실성이 높은 상태에서 실행 지평을 줄여 더 자주 재관측하고 재계획하도록 함으로써 이러한 위험을 완화한다. 이는 인간의 행동 패턴과도 유사한데, 익숙한 환경에서는 무의식적으로 긴 동작 시퀀스를 수행하지만, 낯설거나 위험한 환경에서는 한 동작씩 확인하며 신중하게 움직이는 것과 같은 원리이다. 적응적 연산과 적응적 실행의 결합은 RD-VLA를 단순한 정책 모델이 아닌, 자체 불확실성을 인식하고 이에 따라 행동 전략을 조절할 수 있는 메타 인지적(metacognitive) 에이전트로 만들어준다.
4. 실험 설정: 시뮬레이션과 실세계 평가 환경
4.1 데이터셋 및 벤치마크
RD-VLA는 시뮬레이션과 실세계 환경 모두에서 포괄적으로 평가된다. 평가는 다섯 가지 핵심 질문에 답하도록 설계되었다. (1) 순환 연산에 따라 성능이 어떻게 확장되는가? (2) 로봇 조작 과제에서 적응적 연산이 필요한가? (3) 추론 시 적응적 연산을 위한 가장 효과적인 전략은 무엇인가? (4) 행동 예측에서 표현 수준 추론이 토큰 수준 추론보다 효과적인가? (5) 실세계 배포에서 어떤 성능을 보이는가? 시뮬레이션 실험은 널리 사용되는 두 가지 조작 벤치마크인 LIBERO와 CALVIN에서 수행되며, 실세계 실험은 양팔 YAM 매니퓰레이터에서 수행된다.
LIBERO 벤치마크는 Liu 등이 제안한 로봇 학습을 위한 지식 전이 평가 프레임워크로, 4개의 과제 범주로 구성된다. LIBERO-Spatial은 "서랍 위의 컵을 테이블 왼쪽으로 옮기시오"와 같이 공간 관계 이해에 초점을 맞추며, 로봇이 상대적 위치 관계를 정확히 추론해야 하는 과제들로 구성된다. LIBERO-Object는 훈련 시 접하지 못한 새로운 객체 조합을 다루어 객체 수준의 일반화를 평가한다. LIBERO-Goal은 동일한 객체 집합에서 새로운 목표 상태로의 조작을 요구하여 목표 조건부 계획 능력을 검증한다. LIBERO-Long은 여러 하위 목표를 순차적으로 달성해야 하는 장기 지평 과제를 포함하며, 가장 높은 연산 복잡도를 요구하는 범주이다. 각 범주에는 10개의 과제가 포함되어 있으며, 과제당 50개의 전문가 시연이 제공된다.
CALVIN 벤치마크는 Mees 등이 제안한 언어 조건부 정책 학습 벤치마크로, ABC→D 설정으로 평가된다. 이 설정에서 모델은 환경 A, B, C에서 훈련된 후, 미지의 환경 D에서 평가된다. CALVIN의 핵심 평가 지표는 연속으로 완료한 과제 수(task chaining)로, 모델이 최대 5개의 연속 과제를 순차적으로 수행해야 한다. 각 과제는 이전 과제의 종료 상태에서 시작되므로, 오류가 누적되어 후속 과제의 성공 확률이 점차 감소한다. 이러한 특성은 모델의 장기 지평 일반화 능력과 순차적 계획 능력을 엄격하게 검증한다.
실세계 실험은 양팔 YAM(Yet Another Manipulator) 로봇에서 수행된다. 네 가지 가정용 과제가 선정되었으며, 이들은 난이도와 요구되는 기술의 다양성을 고루 반영한다. 큐브 배치(cube in bowl)는 정밀한 파지와 배치를 요구하는 기본 과제이고, 접시 닦기(wipe dish)는 반복적 동작 패턴을 요구한다. 수건 접기(fold towel)는 변형 가능한 객체(deformable object)를 다루는 고난이도 과제이며, 빵 굽기(toast bread)는 빵을 잡아 토스터에 넣고 레버를 내리는 등 도구 사용과 다단계 순차적 계획을 포함하는 장기 지평 과제로, 가장 높은 난이도를 보인다.
4.2 구현 세부사항
RD-VLA의 구현 세부사항을 정리하면 다음과 같다. 아키텍처 백본으로는 MiniVLA의 Qwen2.5-0.5B가 사용되며, DINOv2와 SigLIP의 융합 비전 인코더를 활용한다. LLM 백본은 LoRA로 파인튜닝되며, 64개의 학습된 잠재 임베딩이 입력 시퀀스에 추가된다. 주요 하이퍼파라미터와 아키텍처 설정은 다음과 같다.
| 구성 요소 | 설정 |
|---|---|
| VLM 백본 | Qwen2.5-0.5B (24 레이어), LoRA 파인튜닝 |
| 비전 인코더 | DINOv2 + SigLIP 융합 (동결) |
| 비전 토큰 수 | 256/이미지 (총 512, 메인+손목 카메라) |
| 학습된 잠재 임베딩 | 64개 |
| Prelude 쿼리 수 ($K$) | 8 |
| Prelude 교차 어텐션 대상 | VLM 12번째 레이어 ($h_{vis+lat}^{(12)}$) |
| Recurrent Core 교차 어텐션 대상 | VLM 24번째 레이어 ($h_{vis+lat}^{(24)}$) + 고유 수용 감각 |
| 스크래치패드 초기화 | 절단 정규 분포 (TruncNormal) |
| 훈련 시 평균 순환 횟수 ($\mu_{rec}$) | 32 |
| TBPTT 기울기 전파 깊이 ($d$) | 8 |
| 총 파라미터 수 | 약 0.5B |
Prelude와 Coda가 VLM의 서로 다른 레이어로부터 특성을 추출한다는 점이 아키텍처 설계에서 주목할 만하다. Prelude는 12번째(중간) 레이어의 특성을 사용하여 쿼리를 접지하고, Recurrent Core와 Coda는 24번째(최종) 레이어의 특성을 사용한다. 이러한 이중 레이어 활용은 VLM의 서로 다른 추상화 수준의 정보를 효과적으로 결합하기 위한 설계 선택으로, 중간 레이어의 보다 구체적인 시각적 특성과 최종 레이어의 고수준 의미적 특성을 모두 활용할 수 있게 한다. 훈련 시 순환 횟수는 로그-정규 포아송 분포에서 샘플링되며($\mu_{rec} = 32$), TBPTT의 기울기 전파 깊이는 $d = 8$로 설정된다. 이러한 설정은 모델이 0.5B 파라미터라는 비교적 작은 규모로도 강력한 성능을 달성할 수 있게 한다.
4.3 베이스라인
비교 대상 베이스라인은 세 가지 범주로 분류된다. 이 분류 체계는 VLA 모델이 행동을 생성하기 전에 어떤 종류의 중간 처리를 수행하는지에 기반한다.
첫째는 중간 추론 단계 없이 직접 로봇 행동을 예측하는 엔드-투-엔드(E2E) VLA이다. 이 범주에는 다양한 규모와 설계 철학의 모델들이 포함된다. Octo(0.09B)는 가장 경량인 베이스라인으로 Open X-Embodiment 데이터셋에서 훈련된 범용 정책이다. Diffusion Policy(0.3B)는 확산 기반 행동 생성을 사용하며, 다중 모달 행동 분포 모델링에 강점을 보인다. OpenVLA(7B)와 그 최적화 버전 OpenVLA-OFT(7B)는 대표적인 오픈소스 VLA로, 각각 표준 파인튜닝과 최적화된 파인튜닝 전략을 사용한다. DeeR-VLA(7B)는 동적 깊이 활성화를 통해 효율성을 추구하며, SpatialVLA(4B)는 공간 표현 학습을 강화한 모델이다. $\pi_0$(3B)은 플로우 매칭 기반의 범용 정책으로, 3B 파라미터라는 비교적 효율적인 규모에서 강력한 성능을 보인다.
둘째는 행동 출력 전에 토큰을 생성하여 명시적 추론을 수행하는 토큰 추론 VLA이다. ECoT(7B)는 체화된 사고 연쇄를 통해 텍스트 형태의 추론을 생성하며, 가장 초기의 추론 중심 VLA 중 하나이다. ThinkAct(7B)와 Fast-ThinkAct(7B)는 강화 학습 기반 시각적 잠재 계획을 사용하며, Fast-ThinkAct는 ThinkAct의 효율적 변형으로 89.7%의 강력한 성능을 보인다. MolmoAct(7B)는 깊이 인식 추론을, CoT-VLA(7B)는 시각적 사고 연쇄를 사용한다. 이 범주의 모든 모델이 7B 파라미터를 사용한다는 점은 주목할 만한데, 이는 토큰 기반 추론이 충분한 언어 이해 능력을 필요로 하기 때문이다.
셋째는 행동 출력 전에 순환 구조를 사용하여 잠재 공간에서 반복적 추론을 수행하는 잠재 추론으로, RD-VLA 자체가 이 범주를 새로이 정의한다. RD-VLA는 0.5B 파라미터만을 사용하면서, 14배 큰 토큰 추론 모델들을 능가하는 성능을 목표로 한다. 이러한 삼분 분류는 RD-VLA가 기존 접근법들과 질적으로 다른 범주에 속함을 명확히 하며, 잠재 공간 추론이라는 새로운 설계 패러다임의 가능성을 탐색한다.
5. 주요 실험 결과: 잠재 순환의 스케일링 효과와 성능 분석
5.1 순환 연산을 통한 성능 확장
논문은 먼저 연산 깊이와 과제 성공률 간의 관계를 확립하기 위해, 고정된 수의 순환 반복 $N_{inf} \in \{1, \ldots, 32\}$로 LIBERO의 모든 과제에서 RD-VLA를 평가한다. Figure 4에 나타난 바와 같이, 성능은 순환 증가에 따라 명확한 로그-선형 개선을 보인다. $N_{inf} = 1$에서의 거의 무작위 수준 성능(8.4% 평균)에서 시작하여, 연산 배가마다 실질적인 성능 향상이 달성된다. $N_{inf} = 2$에서 40.5%(382% 증가), $N_{inf} = 4$에서 84.1%(108% 증가), $N_{inf} = 8$에서 92.6%(10% 증가)를 달성한다. 성능은 8-12회 반복 사이에서 포화되며, 최고 성능 93.1%는 $N_{inf} = 24$에서 달성된다.
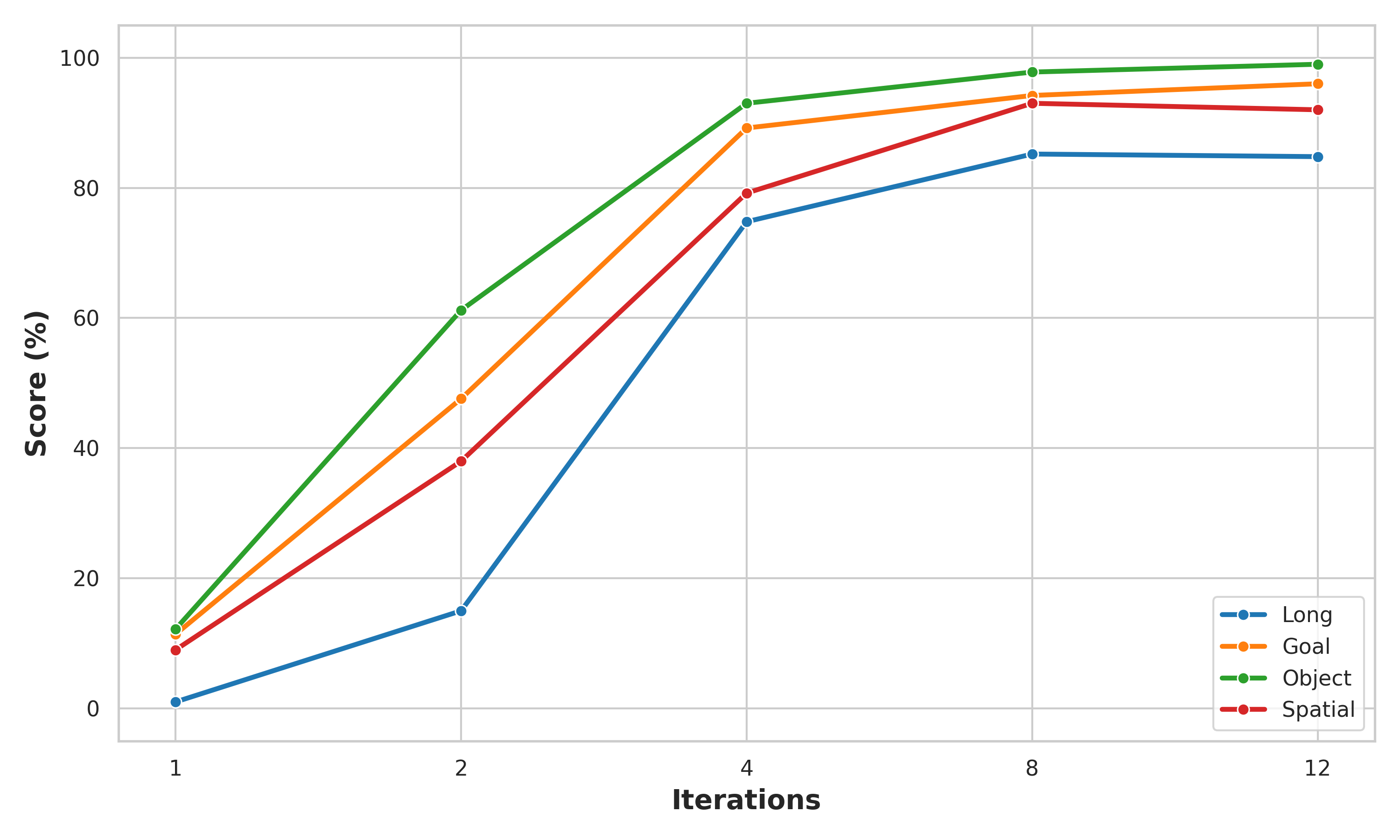
Figure 4: 다양한 순환 횟수에 대한 LIBERO 벤치마크 성능. 모든 과제 범주가 연산 깊이 증가에 따라 일관된 개선을 보이며, 평균적으로 8-12회 반복에서 수렴한다.
이 결과는 몇 가지 중요한 시사점을 제공한다. 우선, 단일 반복의 성능이 8.4%에 불과하다는 것은 모델의 능력이 순환 정제 과정에 본질적으로 의존함을 보여준다. 이는 RD-VLA 아키텍처에서 Recurrent Core가 단순한 성능 향상 모듈이 아니라, 의미 있는 행동을 생성하기 위한 핵심 연산 단위임을 입증한다. 단순히 VLM의 표현을 한 번 통과시키는 것만으로는 복잡한 조작 과제를 해결할 수 없으며, 반복적 정제가 성능의 핵심 동인이다.
범주별 분석에서 더욱 흥미로운 패턴이 드러난다. LIBERO-Long 범주의 성능 변화가 가장 극적인데, Rec=1에서 단 1.0%의 성공률이 Rec=4에서 74.8%로 급등한다. 이는 장기 지평 과제의 복잡한 다단계 계획이 깊은 반복적 추론 없이는 사실상 불가능하다는 것을 의미한다. 반면 LIBERO-Object 범주는 Rec=4에서 이미 93.0%에 도달하여 가장 빠르게 수렴하는데, 이는 새로운 객체 조합에 대한 시각적 인식이 비교적 적은 반복으로도 충분히 정제될 수 있음을 시사한다. LIBERO-Spatial 범주는 Rec=8에서 93.0%의 최고 성능에 도달한 후 유지되는 패턴을 보이며, 공간 관계 추론에 중간 수준의 반복이 필요함을 보여준다. LIBERO-Goal 범주는 Rec=12에서 96.0%의 최고 성능에 도달하며, 목표 조건부 계획이 객체 인식보다 더 깊은 추론을 필요로 함을 나타낸다.
또한 성능의 포화가 12회 이후에 나타난다는 것은 과도한 반복이 불필요하며, 적응적 연산으로 이 영역을 효율적으로 활용할 수 있음을 시사한다. $N_{inf} = 12$ 이후 성능이 약간 감소하기도 하는데(예: $N_{inf} = 32$에서 92.1%), 이는 과도한 순환이 상태 포화 또는 성능 저하를 야기할 수 있음을 의미한다. 그러나 이 감소 폭이 매우 작다는 점(1% 미만)은 모델이 과도한 순환에도 비교적 강건하다는 것을 보여주며, 이는 훈련 시 랜덤화된 순환 횟수와 TBPTT가 모델을 다양한 깊이에서 안정적으로 작동하도록 정규화하는 효과가 있음을 시사한다.
5.2 태스크별 연산 복잡도의 차이
집계 성능을 넘어서, 논문은 개별 과제가 서로 다른 수렴 프로파일을 보이며, 이는 과제마다 연산 복잡도에 대한 요구사항이 다름을 반영한다고 서술한다. Figure 5는 LIBERO의 선택된 장기 지평(Long-horizon) 과제에서 이러한 과제 의존적 행동을 보여준다.
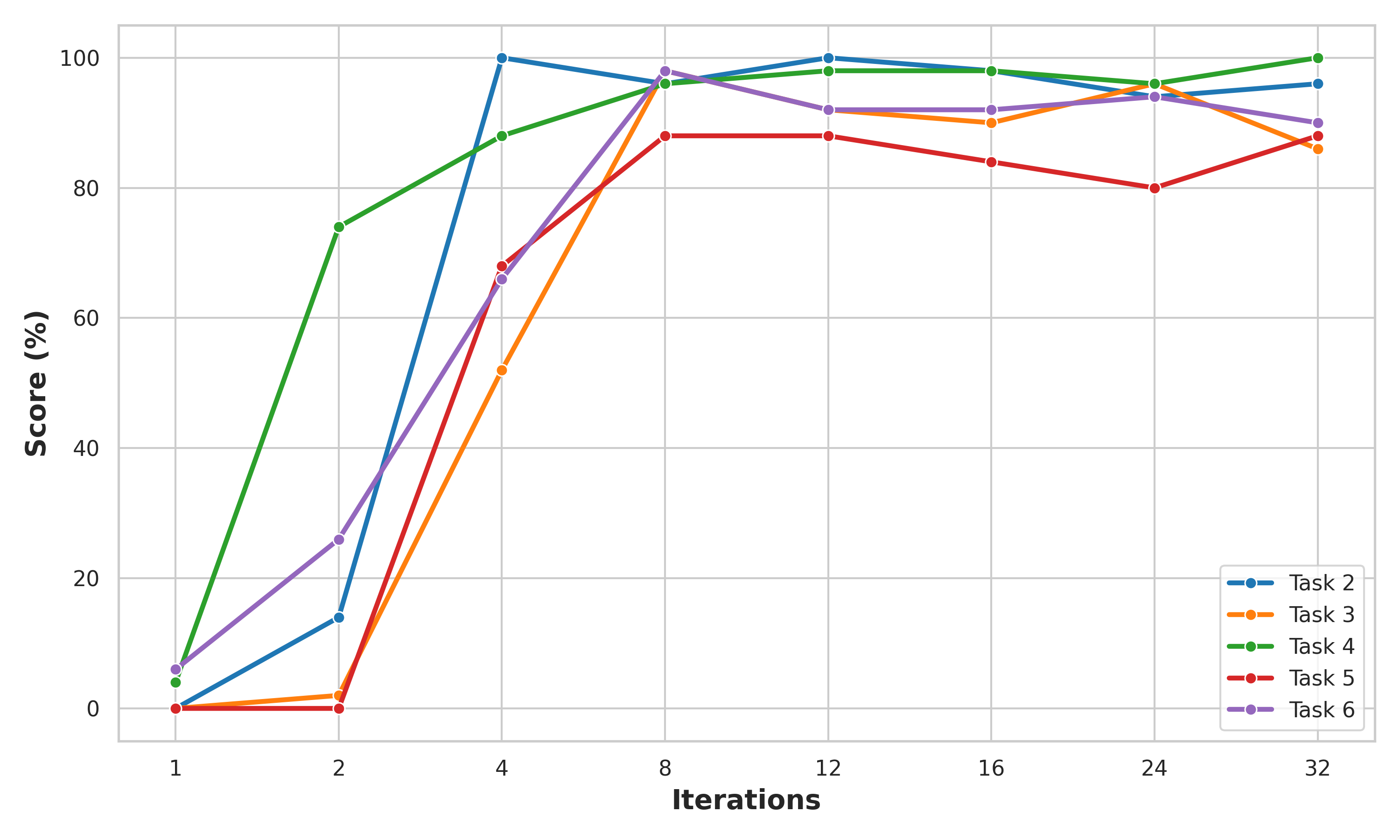
Figure 5: 선택된 5개의 Long 과제에 대한 순환 스텝별 성능. 각 과제가 고유한 수렴 행동을 보인다. Task 4는 반복 1에서 6%에서 반복 2에서 거의 80%로 점프하는 반면, Task 5는 반복 2까지 0%에 머물다가 반복 3에서야 약 70%에 도달한다.
중요하게도, 필요한 반복 횟수는 사전에 규정되는 것이 아니라 과제 맥락에서 자연스럽게 도출된다. Task 4 같은 일부 과제는 단 2회 반복으로 거의 완벽한 성능을 달성하는 반면, Task 5 같은 다른 과제는 의미 있는 성공이 나타나기까지 3회 이상의 반복이 필요하다. 이러한 관찰은 서로 다른 과제가 잠재 추론 과정에서 서로 다른 최적 반복 횟수를 가질 수 있다는 현상을 밝혀낸다. 이것이 바로 적응적 연산 전략의 동기가 된다. 즉, 고정된 연산 예산을 사용하는 대신 모델이 현재 상태의 난이도에 따라 동적으로 반복을 할당해야 한다는 것이다.
5.3 적응적 연산 전략 비교
논문은 모델이 KL 발산 중단 기준을 사용하여 자체 연산 예산을 동적으로 조정할 수 있는지 평가한다. Table II는 고정 연산 깊이와 세 가지 적응적 전략(Binary Adaptation, Linear Decay, Pure KL 임계값)을 비교하는 포괄적인 어블레이션 연구 결과를 제시한다.
| 전략 | 평균 반복 | Spatial | Object | Goal | Long | 평균 |
|---|---|---|---|---|---|---|
| Rec=1 | 1.0 | 9.0 | 12.2 | 11.4 | 1.0 | 8.4 |
| Rec=2 | 2.0 | 38.0 | 61.2 | 47.6 | 15.0 | 40.5 |
| Rec=4 | 4.0 | 79.2 | 93.0 | 89.2 | 74.8 | 84.1 |
| Rec=8 | 8.0 | 93.0 | 97.8 | 94.2 | 85.2 | 92.6 |
| Rec=12 | 12.0 | 92.0 | 99.0 | 96.0 | 84.8 | 93.0 |
| Rec=16 | 16.0 | 91.6 | 99.0 | 95.2 | 85.2 | 92.8 |
| Rec=24 | 24.0 | 92.4 | 99.2 | 94.2 | 86.6 | 93.1 |
| Rec=32 | 32.0 | 91.4 | 98.8 | 93.8 | 84.4 | 92.1 |
결과는 적응적 연산이 최고의 고정 깊이 모델과 동등한 성능을 유지하면서 평균 추론 비용을 줄인다는 것을 보여준다. $\tau = 5 \times 10^{-4}$에서 Binary Adaptation 전략은 평균 $\bar{k} = 7.93$회 반복만을 사용하여 92.5%의 성공률을 달성하는데, 이는 $N = 12$에서의 고정 순환 최고 성능 93.0%에 필적하면서 연산량을 34% 절감한 결과이다.
| 전략 | 임계값 $\tau$ | 평균 반복 $\bar{k}$ | $\sigma$ | Spatial | Object | Goal | Long | 평균 |
|---|---|---|---|---|---|---|---|---|
| Binary Adaptation | $1e^{-4}$ | 11.04 | 1.20 | 91.2 | 98.2 | 96.0 | 79.8 | 91.3 |
| $2e^{-4}$ | 9.71 | 1.11 | 90.6 | 97.2 | 96.0 | 80.8 | 91.2 | |
| $5e^{-4}$ | 7.93 | 1.03 | 88.6 | 98.8 | 96.8 | 85.8 | 92.5 | |
| $1e^{-3}$ | 6.61 | 0.89 | 88.6 | 97.8 | 94.6 | 84.8 | 91.5 | |
| $5e^{-3}$ | 4.27 | 0.41 | 83.2 | 93.6 | 87.4 | 61.8 | 81.5 | |
| $1e^{-2}$ | 3.36 | 0.19 | 74.6 | 88.6 | 81.6 | 43.6 | 72.1 | |
| Linear Decay | $1e^{-4}$ | 11.55 | 1.03 | 91.2 | 97.2 | 96.2 | 80.0 | 91.2 |
| $2e^{-4}$ | 9.86 | 1.10 | 91.2 | 98.4 | 96.6 | 82.0 | 92.1 | |
| $5e^{-4}$ | 7.90 | 1.05 | 88.8 | 97.6 | 94.4 | 82.0 | 90.7 | |
| Pure KL | $1e^{-4}$ | 10.58 | 1.40 | 91.2 | 98.2 | 93.8 | 81.8 | 91.3 |
| $5e^{-4}$ | 7.66 | 0.95 | 90.8 | 99.4 | 93.2 | 82.0 | 91.4 | |
| $1e^{-3}$ | 6.57 | 0.79 | 89.8 | 98.2 | 93.8 | 79.6 | 90.4 |
세 가지 적응적 전략 모두 동일한 연산 예산에서 비슷한 성능을 보이며, 이는 핵심 통찰이 특정 중단 기준이 아니라 조건 의존적 연산 할당의 원칙 자체에 있음을 시사한다. 다만 Binary Adaptation with $\tau = 5 \times 10^{-4}$가 효율성과 성능 간의 최적 균형을 달성한다고 논문은 보고한다. 임계값이 너무 크면(예: $\tau = 1e^{-2}$) 조기 종료가 빈번하여 성능이 급격히 하락하고(평균 72.1%), 임계값이 너무 작으면(예: $\tau = 1e^{-4}$) 불필요하게 많은 반복을 수행하게 된다.
5.4 기존 베이스라인과의 성능 비교
RD-VLA를 LIBERO와 CALVIN 벤치마크에서 최신 VLA 방법들과 비교한 결과가 Table 3과 Table 4에 제시된다. LIBERO 벤치마크에서 방법들은 엔드-투-엔드 VLA, 토큰 수준 추론 방법, 잠재 추론 접근법의 세 범주로 분류된다.
| 유형 | 방법 | 파라미터 | Spatial | Object | Goal | Long | 평균 |
|---|---|---|---|---|---|---|---|
| E2E VLA | Octo | 0.09B | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 |
| Diffusion Policy | 0.3B | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 | |
| OpenVLA | 7B | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 | |
| OpenVLA-OFT | 7B | 88.4 | 95.0 | 87.2 | 74.6 | 86.3 | |
| DeeR-VLA | 7B | 87.2 | 92.4 | 83.8 | 69.0 | 83.1 | |
| SpatialVLA | 4B | 82.8 | 92.4 | 89.6 | 74.4 | 84.8 | |
| $\pi_0$ | 3B | 86.8 | 93.0 | 84.4 | 65.8 | 82.5 | |
| 토큰 추론 VLA | ECoT | 7B | 75.0 | 85.0 | 78.0 | 58.0 | 74.0 |
| ThinkAct | 7B | 88.0 | 94.0 | 89.0 | 77.0 | 87.0 | |
| MolmoAct | 7B | 91.2 | 96.0 | 91.0 | 76.2 | 88.6 | |
| CoT-VLA | 7B | 87.6 | 93.8 | 88.4 | 76.0 | 86.5 | |
| Fast-ThinkAct | 7B | 91.8 | 96.0 | 92.4 | 78.8 | 89.7 | |
| 잠재 추론 | RD-VLA (고정) | 0.5B | 92.0 | 99.0 | 96.0 | 84.8 | 93.0 |
| RD-VLA (적응적) | 0.5B | 88.6 | 98.8 | 96.8 | 85.8 | 92.5 |
RD-VLA는 고정 순환으로 93.0%의 최신 성능을 달성하며, 강력한 Fast-ThinkAct 베이스라인(89.7%)을 포함한 모든 기존 방법을 크게 능가한다. 주목할 만한 점은 이 결과를 단 0.5B 파라미터로 달성했다는 것으로, 이는 7B 토큰 추론 방법들보다 14배 작은 규모이다. 적응적 변형은 동적 연산 할당의 효율성 이점을 제공하면서도 경쟁력 있는 성능(92.5%)을 유지한다. 이러한 결과는 명시적 토큰 기반 추론이 반드시 더 큰 모델이나 더 복잡한 데이터를 필요로 하는 것이 아니며, 잠재 공간에서의 반복 정제가 효율성과 성능 모두에서 우위를 점할 수 있음을 시사한다.
CALVIN ABC→D 벤치마크의 결과는 장기 지평 과제 연쇄를 평가한다. RD-VLA는 3.39의 최고 평균 체인 길이를 달성하며, OpenVLA(3.27)를 포함한 모든 베이스라인을 능가한다. 이는 잠재 정제가 모델의 순차적 계획 능력을 효과적으로 확장함을 검증한다.
| 방법 | Task 1 | Task 2 | Task 3 | Task 4 | Task 5 | 평균 길이 |
|---|---|---|---|---|---|---|
| SuSIE | 87.0 | 69.0 | 49.0 | 38.0 | 26.0 | 2.69 |
| GR-1 | 85.4 | 71.2 | 59.6 | 49.7 | 40.1 | 3.06 |
| OpenVLA | 88.0 | 76.0 | 62.0 | 55.0 | 46.0 | 3.27 |
| RD-VLA | 89.3 | 76.3 | 66.7 | 61.3 | 45.3 | 3.39 |
CALVIN 결과에서 특히 주목할 점은 과제 연쇄가 길어질수록(Task 3, 4, 5) RD-VLA와 베이스라인 간의 성능 격차가 더 벌어진다는 것이다. Task 1에서는 모든 방법이 85-89%의 비슷한 성능을 보이지만, Task 5에 이르면 RD-VLA(45.3%)가 SuSIE(26.0%)를 거의 20% 포인트 차이로 앞서게 된다. Task 2에서 Task 3으로의 성능 하락률을 살펴보면, RD-VLA는 76.3%에서 66.7%로 12.6% 감소하는 반면, SuSIE는 69.0%에서 49.0%로 29.0%나 감소한다. 이러한 패턴은 잠재 정제 메커니즘이 긴 시퀀스에서의 오류 누적(error compounding)을 효과적으로 완화함을 시사한다.
CALVIN에서의 오류 누적이 특히 문제되는 이유는, 각 과제가 이전 과제의 종료 상태에서 시작되기 때문이다. 첫 번째 과제에서의 미세한 위치 오차가 두 번째 과제의 초기 조건을 악화시키고, 이것이 세 번째, 네 번째 과제로 누적되면서 성공 확률이 급격히 떨어진다. RD-VLA의 순환적 정제는 이러한 누적 오류에 대한 내재적 강건성을 제공하는 것으로 해석할 수 있다. 각 제어 스텝에서 잠재 스크래치패드를 반복적으로 정제함으로써, 약간 치우친 초기 상태에서도 관측 정보와의 반복적 교차 어텐션을 통해 정확한 현재 상태 인식을 회복할 수 있기 때문이다. 이는 단일 패스 모델에서는 어려운, 일종의 암시적 상태 보정(implicit state correction) 메커니즘으로 작동한다.
5.5 실제 로봇 환경에서의 실험
실세계 환경에서의 검증을 위해 RD-VLA를 양팔 YAM 매니퓰레이터에 배포하여 네 가지 가정용 과제에서 평가했다. 이 과제들은 그릇에 큐브 넣기(cube in bowl), 접시 닦기(wipe dish), 수건 접기(fold towel), 빵 굽기(toast bread)로 구성되며, 각각 고정 8회 반복과 Pure KL 임계값 $\tau = 10^{-4}$를 사용하여 훈련 및 비교된다.




Figure 7: 실세계 과제에서의 성능 비교. (좌상) 그릇에 큐브 넣기, (우상) 접시 닦기, (좌하) 수건 접기, (우하) 빵 굽기. RD-VLA 변형들이 $\pi_{0.5}$와 Diffusion Policy 베이스라인 대비 모든 과제에서 일관되게 우수한 성능을 보인다.
Figure 7은 Diffusion Policy와 $\pi_{0.5}$ 베이스라인과의 과제 진행 점수 비교를 보여준다. 고정 8회 반복의 RD-VLA는 모든 테스트 시나리오에서 뛰어난 강건성을 보이며, 접시 닦기에서 거의 100% 완료율을 달성하고 나머지 과제에서도 베이스라인을 크게 능가한다. 적응적 변형(RD-VLA-adaptive, Pure KL $\tau = 10^{-4}$)은 경쟁력 있는 성능을 유지하면서 큐브 배치에서 가장 높은 점수를 달성한다. 이러한 결과는 물리적 환경에서의 동적 연산의 실행 가능성을 보여주며, 수건 접기 같은 복잡한 조작 과제에서는 약간의 성능 트레이드오프가 있을 수 있음을 시사한다.
실세계 실험의 의의는 시뮬레이션에서 관찰된 잠재 추론의 이점이 물리적 환경으로 전이된다는 것을 확인한 데 있다. 특히 접시 닦기와 같이 반복적 동작이 필요한 과제에서의 높은 성능과, 빵 굽기와 같이 도구 사용이 포함된 장기 지평 과제에서의 우수한 결과는 RD-VLA의 실용적 가치를 입증한다. 다만 수건 접기에서 적응적 변형의 성능이 고정 변형보다 다소 낮은 것은, 변형 가능한 객체(deformable objects) 조작에서 적응적 중단의 최적 임계값이 과제 유형에 따라 달라질 수 있음을 시사한다. 변형 가능한 객체는 형태가 지속적으로 변하므로, 잠재 상태의 수렴이 행동의 올바름을 보장하지 않을 수 있기 때문이다.
또한 실세계 배포에서 관찰되는 중요한 특성은 RD-VLA의 강건성(robustness)이다. 시뮬레이션 환경과 달리 실세계에서는 조명 변화, 카메라 노이즈, 물리적 상호작용의 비결정성 등 다양한 불확실성 요인이 존재한다. RD-VLA의 반복적 정제 메커니즘은 이러한 노이즈가 있는 입력으로부터도 안정적인 행동을 추출할 수 있는 내재적 강건성을 제공한다. 각 반복에서 스크래치패드가 관측 정보와 반복적으로 교차 어텐션함으로써, 단일 패스에서 놓칠 수 있는 미세한 시각적 단서를 점진적으로 통합할 수 있기 때문이다. 이는 특히 빵 굽기 과제처럼 여러 단계(빵 잡기 → 토스터에 넣기 → 레버 내리기)를 순차적으로 수행해야 하는 경우에 각 단계 전환점에서의 정확한 상태 인식이 중요하며, 잠재 추론이 이를 효과적으로 지원함을 보여준다.
6. 추가 분석 및 Ablation Study: 적응적 연산의 상세 특성
6.1 적응적 종료 분포의 과제별 분석
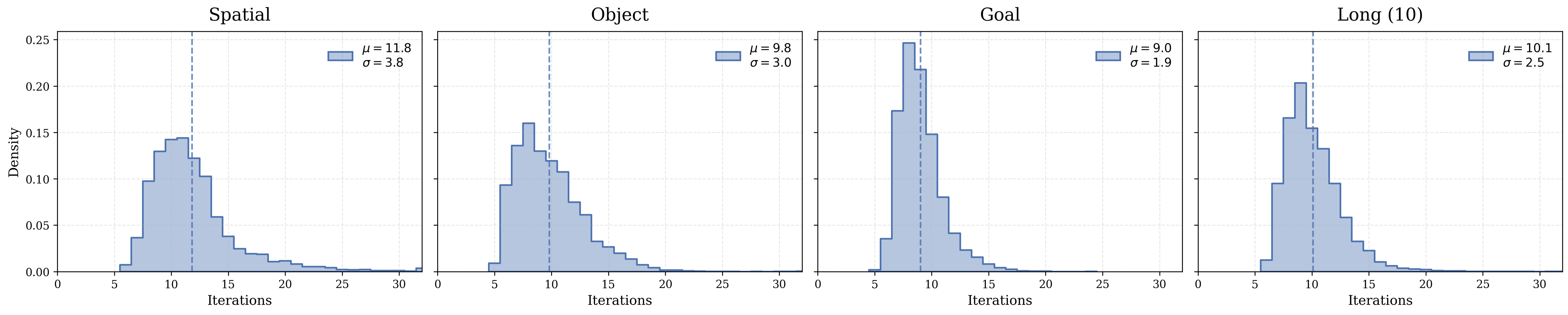
Figure 6: 연속 스텝 간 KL 발산 기반 제로샷, 토큰별 적응적 종료의 히스토그램($\tau = 10^{-4}$). 분포가 과제 의존적 반복 횟수를 보여준다. Spatial 과제가 가장 많은 반복을 필요로 하고($\mu = 11.8$), Object($\mu = 9.8$)와 Goal($\mu = 9.0$) 과제가 그 뒤를 따르며, 이는 상대적 복잡도를 반영한다.
Figure 6은 과제 범주별로 적응적 종료가 어떻게 분포하는지를 히스토그램으로 보여준다. 이 분석에서 가장 흥미로운 발견은 모델이 명시적인 난이도 레이블 없이도 과제 복잡도에 따라 자연스럽게 서로 다른 연산량을 할당한다는 것이다. Spatial 과제는 공간 관계 추론이 필요하여 가장 많은 반복($\mu = 11.8$)을 요구하며, 이는 공간적 배치에 대한 정밀한 추론이 더 깊은 잠재 정제를 필요로 함을 반영한다. Object 과제($\mu = 9.8$)는 새로운 객체 조합에 대한 적응이 필요하여 중간 수준의 연산을 요구하고, Goal 과제($\mu = 9.0$)는 목표 상태 도달에 집중하여 상대적으로 적은 연산이 필요하다.
각 범주 내에서도 반복 횟수의 분산이 존재한다는 점도 주목할 만하다. Spatial 과제의 표준편차가 다른 범주보다 크다는 것은 같은 범주 내에서도 개별 상태의 복잡도가 크게 달라질 수 있음을 의미한다. 이는 과제 수준의 고정 연산 예산이 아닌 상태 수준의 동적 연산 할당이 필요하다는 RD-VLA의 핵심 설계 원칙을 뒷받침한다.
6.2 고정 깊이 대비 적응적 전략의 효율성-성능 트레이드오프
Table 2의 상세 어블레이션에서 몇 가지 중요한 관찰이 도출된다. 먼저, 고정 순환에서 Rec=1의 성능이 8.4%에 불과한 것은 단일 패스 추론이 복잡한 조작에 근본적으로 불충분함을 보여준다. 이 결과는 RD-VLA 아키텍처에서 순환 정제가 선택적 강화가 아닌 필수적 구성 요소임을 입증한다. 단순히 VLM의 출력을 한 번 통과시켜 행동을 생성하는 것만으로는, 복잡한 공간 관계나 다단계 조작을 해결할 수 없는 것이다. Rec=1에서 Rec=2로의 전환만으로도 평균 성능이 8.4%에서 40.5%로 약 5배 향상되는데, 이는 첫 번째 추가 반복이 가장 큰 정보적 가치를 지님을 시사한다. 특히 Object 범주에서는 12.2%에서 61.2%로 급등하는데, 이는 새로운 객체 조합에 대한 시각적 이해가 단 한 번의 추가 반복으로 크게 개선될 수 있음을 보여준다.
Rec=4에서 84.1%로의 급격한 성능 향상은 4회 반복이 대부분의 과제에서 기본적인 추론 요구를 충족시키는 임계점(critical threshold)임을 나타낸다. Object 범주에서는 이미 93.0%에 도달하여 12회 반복의 최고 성능과 거의 동일하다. 반면 Long 범주에서는 74.8%로 여전히 최고 성능(86.6%, Rec=24)과 상당한 차이가 있어, 장기 지평 과제가 더 깊은 추론을 필요로 함을 확인할 수 있다. 이러한 범주별 수렴 속도의 차이는 적응적 연산이 과제 범주뿐 아니라 개별 상태 수준에서도 연산을 차별화해야 하는 근거를 제공한다.
고정 순환에서 Rec=12(93.0%)를 넘어서면 성능이 포화되거나 약간 감소하는 경향이 관찰된다. Rec=16에서 92.8%, Rec=32에서 92.1%로 감소하는 것은 과도한 순환이 상태 포화(state saturation)를 야기할 수 있음을 시사한다. 이는 잠재 스크래치패드가 특정 깊이 이후로는 유의미한 정보 정제를 수행하지 못하고 표현이 고정점(fixed point) 주변에서 진동하거나, 과도한 반복이 오히려 정제된 표현에 미세한 섭동을 추가할 수 있음을 의미한다. 흥미롭게도 이 감소는 크지 않아(Rec=12의 93.0%에서 Rec=32의 92.1%로 0.9% 감소), 모델이 깊은 순환에서도 비교적 안정적임을 보여준다. 이러한 관찰은 적응적 연산의 필요성을 더욱 강화하는데, 고정된 깊이는 일부 과제에서 과소 연산, 일부에서 과잉 연산을 초래하기 때문이다.
적응적 전략 간의 비교에서는 Binary Adaptation, Linear Decay, Pure KL 세 전략 모두 동일한 연산 예산에서 매우 유사한 성능을 달성한다는 점이 눈에 띈다. 예를 들어 $\tau = 1e^{-3}$에서 Binary Adaptation은 91.5%, Linear Decay는 91.5%, Pure KL은 90.4%를 기록한다. $\tau = 5e^{-4}$에서는 Binary Adaptation 92.5%, Linear Decay 90.7%, Pure KL 91.4%로 약간의 차이가 있으나 모두 고정 최적(93.0%)에 근접한다. 이러한 유사성은 핵심 요소가 특정 중단 메커니즘이 아니라 조건 의존적 연산 할당이라는 원칙 자체임을 강력하게 시사한다. 다만 Long 과제 범주에서 Binary Adaptation($\tau = 5e^{-4}$)이 85.8%로 가장 높은 성능을 보이는 것은, 장기 지평 과제에서 실행 지평을 동적으로 조절하는 것이 특히 효과적임을 나타낸다.
적응적 전략의 표준편차($\sigma$) 분석도 흥미로운 통찰을 제공한다. 임계값이 작을수록(예: $\tau = 1e^{-4}$) 표준편차가 크고(1.20-1.40), 임계값이 클수록(예: $\tau = 1e^{-2}$) 표준편차가 작다(0.18-0.19). 이는 엄격한 임계값에서 모델이 과제 난이도에 따라 반복 횟수를 더 다양하게 할당하는 반면, 느슨한 임계값에서는 대부분의 과제가 비슷한 (적은) 반복으로 종료됨을 의미한다. 표준편차가 큰 설정이 더 나은 성능을 보이는 경향은, 과제별 연산 차별화가 효과적임을 간접적으로 입증한다.
6.3 추론 효율성과 파라미터 규모의 이점
RD-VLA의 가장 두드러진 장점 중 하나는 극적인 파라미터 효율성이다. 0.5B 파라미터로 7B 모델들을 능가한다는 결과는 모델 크기가 아닌 아키텍처 설계가 성능의 핵심 동인임을 보여준다. 가중치 공유를 통한 순환 구조는 파라미터를 추가하지 않으면서 연산 깊이를 증가시킬 수 있으므로, 실질적인 "연산 깊이 대 파라미터 수" 비율이 기존 모델들보다 훨씬 높다. 또한 토큰 기반 추론과 달리 잠재 공간 추론은 중간 토큰을 생성하고 디코딩하는 오버헤드가 없으므로, 논문이 보고하는 최대 80배의 추론 속도 향상이 가능하다.
메모리 사용량 측면에서도 RD-VLA는 상수 메모리 풋프린트를 유지한다. 구체적으로, RD-VLA의 추론 시 메모리 사용량은 VLM 순방향 패스에 필요한 메모리와 크기 $K \times D$의 스크래치패드 텐서, 그리고 고정된 조건화 매니폴드로 구성된다. 순환 반복이 아무리 깊어지더라도 이 메모리 요구량은 일정하다. 이는 가중치 공유로 인해 순환 블록의 파라미터가 모든 반복에서 동일하고, 스크래치패드가 인플레이스(in-place)로 업데이트되기 때문이다. 반면 CoT 기반 방법들은 추론 체인의 각 토큰에 대한 키-값(KV) 캐시를 유지해야 하므로, 추론 체인 길이에 비례하여 메모리가 선형적으로 증가한다. 예를 들어 100개의 추론 토큰을 생성하는 CoT-VLA는 100개의 KV 쌍에 해당하는 추가 메모리가 필요하지만, RD-VLA는 100회 반복을 수행하더라도 추가 메모리가 전혀 필요 없다.
이러한 상수 메모리 특성은 메모리 제약이 있는 로봇 시스템에서의 배포에 특히 유리하다. 엣지 디바이스나 임베디드 시스템에서 실행되는 로봇 정책은 제한된 GPU 메모리 내에서 작동해야 하므로, 예측 불가능하게 증가하는 메모리 사용량은 실배포의 주요 장벽이 된다. RD-VLA의 일정한 메모리 요구량은 이러한 제약 하에서의 안정적 배포를 보장한다. $K = 8$의 스크래치패드 크기와 고정된 조건화 매니폴드만으로도 충분한 추론 능력을 확보할 수 있다는 것은, 잠재 공간에서의 정보 밀도가 토큰 공간에서보다 훨씬 높음을 시사한다. 8개의 잠재 벡터가 수십~수백 개의 추론 토큰보다 더 많은 정보를 압축적으로 담을 수 있으며, 이는 잠재 표현의 정보 이론적 효율성에 대한 흥미로운 질문을 제기한다.
7. 한계점 및 향후 연구 방향: 잠재 추론 확장의 미해결 과제
논문은 몇 가지 중요한 한계점과 향후 연구 방향을 명시적으로 서술한다. 첫째, 깊이 일반화의 경계(boundary of depth generalization) 문제가 있다. 순환 스텝 수에 따라 성능이 예측 가능하게 확장되지만, 최적 반복 횟수를 넘어서면 상태 포화나 성능 저하가 발생할 수 있다. 이 문제를 해결하는 것은 아키텍처 혁신이나 특정 훈련 프로토콜을 통해 가능할 수 있으나, 로봇 분야에서 잠재 추론을 확장하기 위한 열린 과제로 남아 있다. 이러한 깊이 포화 현상의 정확한 메커니즘을 이해하고, 보다 깊은 순환에서도 지속적인 정제가 가능한 훈련 방법을 개발하는 것이 중요한 연구 주제가 될 것이다.
둘째, 논문의 주요 목표가 잠재 반복 추론의 가능성을 탐구하는 것이었으며, 특정 모델을 최첨단 지배를 위해 하이퍼 최적화하는 것이 아니었다는 점이 강조된다. 결과가 최소한의 하이퍼파라미터 튜닝과 상대적으로 작은 백본(0.5B 파라미터)으로 달성되었으므로, 더 큰 백본으로의 확장과 더 다양한 데이터셋에서의 훈련이 상당한 성능 향상을 가져올 것으로 기대된다고 서술한다. 현재 결과가 0.5B 모델로 7B 모델을 능가한다는 점에서, 3B-7B 규모로 확장 시 어떤 수준의 성능이 가능할지는 매우 흥미로운 질문이다.
셋째, 순환 아키텍처는 본질적으로 모델 불확실성의 프록시 역할을 할 수 있는 내부 상태 역학을 노출한다. 이는 적응적 연산이나 불확실성 인식 실행 같은 테스트 타임 개입 능력을 제공한다. 예를 들어 순환 상태 간의 분산이 안전 임계값을 초과하면 시스템이 자율적으로 실행을 중단하거나 운영자 지원을 요청할 수 있다. 논문은 이러한 메커니즘의 실행 가능성을 보여주었으나, 구체적 구현은 향후 연구로 남겨두었다. 안전 임계 시나리오에서의 자동 중단은 실세계 배포에서 핵심적인 기능이 될 수 있으며, 이를 위한 체계적인 안전 프로토콜의 설계가 필요하다.
넷째, 토큰 기반 CoT 추론의 지연시간과 메모리 한계를 지적하면서도, Recurrent-Depth 접근법이 보완적 경로를 제공한다고 논문은 서술한다. 향후 연구에서는 순환 깊이가 토큰별로 조절되어 체화된 에이전트의 CoT 추론 능력을 강화하는 하이브리드 접근법이 탐구될 수 있다고 제안한다. 이는 토큰 기반 추론의 해석 가능성과 잠재 추론의 효율성을 결합하는 방향으로, 두 패러다임의 장점을 모두 활용할 수 있는 가능성을 열어준다.
다섯째, 현재 RD-VLA는 Qwen2.5-0.5B라는 상대적으로 작은 백본에서만 검증되었다. 논문은 이 아키텍처가 백본에 구애받지 않는(backbone-agnostic) 모듈형 설계임을 강조하지만, 더 큰 규모의 VLM(예: 3B, 7B)에서 순환 정제의 효과가 어떻게 달라지는지는 아직 검증되지 않았다. 더 큰 백본이 더 풍부한 초기 표현을 제공하므로, 순환 정제에 필요한 반복 횟수가 줄어들 수 있다는 가설도 세울 수 있으나, 이는 향후 실험적 검증이 필요한 부분이다. 또한 다양한 로봇 형태(morphology)와 센서 구성에서의 일반화 능력도 추가 검증이 필요하다.
여섯째, 현재 실험이 LIBERO와 CALVIN이라는 특정 시뮬레이션 벤치마크와 제한된 수의 실세계 과제에서만 수행되었다는 점도 한계이다. 보다 다양한 환경(예: 야외 환경, 다중 로봇 협업, 인간-로봇 상호작용)과 과제 유형(예: 도구 사용, 양손 협응, 이동+조작 통합)에서의 검증이 필요하다. 또한 적응적 연산의 수렴 임계값 $\delta$ 선택이 과제와 환경에 따라 달라질 수 있다는 점도 열린 과제로 남아 있다. 현재는 고정된 임계값을 사용하지만, 환경 복잡도나 과제 유형에 따라 임계값을 동적으로 조정하는 메타 학습 기반 접근법이 향후 연구 방향이 될 수 있다. 이를 통해 모델이 새로운 환경에 보다 빠르게 적응하고, 최적의 연산-성능 균형점을 자동으로 찾을 수 있을 것이다. 특히 강화 학습(RL)을 통해 적응적 연산의 임계값과 실행 지평을 과제 성공률을 최대화하는 방향으로 동시 최적화하는 접근법은 흥미로운 향후 연구 방향이 될 수 있다. 현재의 고정 임계값 접근법은 이미 인상적인 결과를 보이지만, 학습 가능한 중단 정책은 과제의 시간적 구조와 위험도까지 고려한 보다 정교한 연산 할당을 가능하게 할 것이다.
8. 결론: 잠재 공간 추론을 통한 로봇 제어의 새로운 패러다임
RD-VLA는 로봇 추론을 이산적 출력 공간에서 연속적 잠재 공간으로 전환하는 새로운 아키텍처로, 시각-운동 정책을 위한 잠재 반복 추론의 최초 구현이라 할 수 있다. 기존의 VLA 모델들이 고정된 연산 깊이로 모든 제어 스텝을 동일하게 처리하거나, 토큰 공간에서의 명시적 추론을 통해 성능을 개선하는 접근법을 취한 반면, RD-VLA는 가중치 공유 순환 트랜스포머 코어를 통해 잠재 공간에서의 반복적 정제라는 근본적으로 다른 추론 패러다임을 제시한다. Prelude-Recurrent Core-Coda의 삼분 구조, 표현 붕괴를 방지하는 입력 주입 전략, TBPTT 기반의 랜덤화된 순환 훈련, KL 발산 기반의 적응적 중단 기준, 그리고 추론 깊이와 실행 지평을 연계하는 적응적 실행 전략까지, 각 구성 요소가 유기적으로 결합하여 완전한 프레임워크를 형성한다. 이 연구는 자기회귀적 Chain-of-Thought 생성의 메모리 및 지연시간 오버헤드 없이도 효과적인 테스트 타임 연산 확장이 달성될 수 있음을 보여준다. 실험 결과는 모델이 순환 반복을 성공적으로 활용하여 내부 상태를 정제하며, 성능이 연산 깊이에 따라 로그-선형적으로 확장된다는 실질적 증거를 제공한다.
이 아키텍처가 체화된 에이전트에 제공하는 새로운 능력은 두 가지로 요약된다. 하나는 더 어려운 과제에 대해 더 오래 사고하는 능력이고, 다른 하나는 잠재 수렴을 통해 자체 불확실성을 측정하는 능력이다. 논문은 효율적이고 추론이 가능한 로봇 정책을 위한 새로운 설계 공간을 여는 것을 목표로 했으며, 적응적 연산의 최적화 체제를 탐구하고 잠재 순환의 스케일링 법칙을 밝히는 것이 유망한 향후 연구 방향이라고 서술한다. 잠재 반복 정제의 효능을 검증함으로써, RD-VLA는 차세대 자원 효율적이고 강건한 로봇 파운데이션 모델을 위한 토대를 제공한다.
RD-VLA의 성공은 "더 큰 모델이 아닌 더 깊은 사고"라는 패러다임 전환의 가능성을 보여준다. 기존의 VLA 연구들은 성능 향상을 위해 주로 모델 크기를 확장하는 방향(7B → 55B 등)을 추구해왔다. 그러나 RD-VLA는 0.5B의 비교적 작은 모델에 순환적 추론 구조를 추가함으로써, 14배 큰 모델들을 능가하는 성능을 달성했다. 이는 로봇 제어에서의 핵심 병목이 모델의 절대적 크기가 아니라, 주어진 관측에 대해 얼마나 깊이 사고할 수 있는지에 있음을 시사한다. 특히 실시간 제어가 요구되는 로봇 분야에서, 더 작은 모델이 동적으로 깊이를 조절하며 더 나은 성능을 달성한다는 결과는 향후 로봇 AI 시스템 설계에 중요한 방향성을 제시한다.
보다 넓은 맥락에서, RD-VLA는 최근 NLP 분야에서 활발히 연구되고 있는 테스트 타임 연산 확장(test-time compute scaling) 패러다임을 로봇 제어 영역으로 성공적으로 확장한 사례이다. 언어 모델에서의 Chain-of-Thought, Tree-of-Thought 등이 토큰 공간에서의 연산 확장이라면, RD-VLA의 잠재 순환은 표현 공간에서의 연산 확장으로 볼 수 있다. 이러한 관점은 로봇 제어뿐 아니라, 연속적 행동 공간을 다루는 모든 영역(자율 주행, 산업 자동화 등)에서 잠재 추론의 잠재력을 시사한다. 토큰 기반 추론이 근본적으로 이산적이고 순차적인 성질을 지니는 반면, 잠재 공간 추론은 연속적이고 병렬적인 정보 처리를 가능하게 하므로, 물리적 세계와의 상호작용에 보다 자연스러운 추론 패러다임을 제공할 수 있다.
마지막으로, RD-VLA가 로봇 AI의 실용화에 미치는 함의를 고려할 필요가 있다. 현재 로봇 AI의 실배포를 가로막는 주요 장벽 중 하나는 대규모 모델의 높은 연산 비용과 지연시간이다. RD-VLA는 작은 모델(0.5B)과 효율적인 잠재 추론을 통해 이 장벽을 상당 부분 낮추면서도, 추론 능력에서는 오히려 큰 모델들을 능가한다. 이는 향후 가정용 로봇, 산업용 매니퓰레이터, 서비스 로봇 등 다양한 응용 분야에서의 VLA 모델 배포를 가속화할 수 있는 기술적 토대를 제공한다. 특히 적응적 연산을 통한 동적 자원 할당은, 배터리나 컴퓨팅 자원이 제한된 모바일 로봇 플랫폼에서 에너지 효율적인 운영을 가능하게 하는 핵심 기술이 될 수 있다. 필요한 때에만 깊이 사고하고, 단순한 상황에서는 빠르게 행동하는 이러한 능력은 실세계 배포에서의 핵심 요구사항과 정확히 부합한다. 이러한 효율적 자원 활용은 로봇 시스템의 전체 운영 시간을 연장하고, 동시에 복잡한 과제에 대한 성공률을 높이는 이중 이점을 제공한다.
또한 RD-VLA의 아키텍처적 원칙은 로봇 제어를 넘어 더 넓은 인공지능 연구에도 시사점을 제공한다. 잠재 공간에서의 반복적 정제가 토큰 공간에서의 명시적 추론보다 효율적일 수 있다는 발견은, 추론이 반드시 인간이 읽을 수 있는 형태로 이루어질 필요가 없으며, 오히려 연속적 잠재 공간에서의 암묵적 추론이 특정 영역에서는 더 자연스럽고 효율적일 수 있다는 근본적인 질문을 제기한다. 인간의 인지 과정에서도 의식적 언어적 추론은 전체 인지 활동의 극히 일부에 불과하며, 대부분의 복잡한 정보 처리는 의식 아래의 암묵적 과정에서 이루어진다. RD-VLA의 잠재 추론은 이러한 암묵적 인지 과정의 공학적 유사체로 볼 수 있으며, 이 방향의 연구가 더 효율적이고 강력한 AI 시스템으로 이어질 수 있음을 시사한다. 결론적으로, RD-VLA는 로봇 제어 분야에서의 잠재 추론이라는 새로운 장을 열었으며, 그 영향은 로봇 공학의 경계를 넘어 인공지능 전반에 걸쳐 파급될 잠재력을 지닌다.
9. 요약 정리
- 핵심 제안: RD-VLA는 가중치 공유 순환 트랜스포머 코어를 사용하여 잠재 공간에서 반복적으로 행동 표현을 정제하는 새로운 VLA 아키텍처로, 토큰 기반 추론 대신 잠재 추론을 통해 테스트 타임 연산을 동적으로 확장한다.
- 삼분 아키텍처: Prelude(VLM 중간 레이어 특성으로 쿼리 접지), Recurrent Core(가중치 공유 순환 블록에서 스크래치패드 반복 정제), Coda(수렴 상태를 행동으로 디코딩)의 기능적 삼중체로 구성되며, 입력 주입 전략으로 표현 붕괴를 방지한다.
- 상수 메모리와 연산 확장성: 고정 크기($K=8$)의 잠재 스크래치패드를 사용하여 반복 횟수에 관계없이 상수 메모리를 유지하면서, 임의의 추론 깊이를 지원하여 과제 복잡도에 따른 동적 연산 할당이 가능하다.
- 로그-선형 성능 확장: LIBERO 벤치마크에서 1회 반복 시 8.4%에서 12회 반복 시 93.0%까지 연산 깊이에 따른 로그-선형 성능 향상을 보이며, 8-12회 반복에서 성능이 포화된다.
- 적응적 연산 메커니즘: KL 발산(MSE 근사) 기반 수렴 기준으로 과제/상태별 연산량을 자동 조절하며, Binary Adaptation($\tau=5e^{-4}$)이 평균 7.93회 반복으로 92.5% 성공률을 달성하여 고정 최적 대비 34% 연산 절감을 실현한다.
- 극적인 파라미터 효율성: 0.5B 파라미터로 7B 토큰 추론 방법(Fast-ThinkAct 89.7%)을 포함한 모든 기존 VLA를 능가하여 LIBERO에서 93.0% 최고 성능을 달성하며, 14배 작은 규모로 최대 80배의 추론 속도 향상을 보고한다.
- 장기 지평 일반화: CALVIN ABC→D 벤치마크에서 평균 체인 길이 3.39, Task-5 성공률 45.3%를 달성하여 OpenVLA(3.27)를 포함한 모든 베이스라인을 능가하며, 순차적 과제 연쇄에서의 잠재 정제의 효과를 검증한다.
- 실세계 검증: 양팔 YAM 매니퓰레이터에서 큐브 배치, 접시 닦기, 수건 접기, 빵 굽기 등 네 가지 가정용 과제에서 Diffusion Policy와 $\pi_{0.5}$ 대비 일관되게 우수한 성능을 보이며, 시뮬레이션 결과의 실세계 전이를 확인한다.
- 과제 의존적 연산 분배: 명시적 난이도 레이블 없이 모델이 자연스럽게 과제 복잡도에 따라 서로 다른 반복 횟수를 할당하며(Spatial: 11.8, Object: 9.8, Goal: 9.0), 이는 적응적 행동이 아키텍처에서 자연스럽게 도출됨을 보여준다.
- 향후 연구 방향: 깊이 일반화 경계 극복, 더 큰 백본으로의 확장, 하이브리드 토큰-잠재 추론 접근법, 불확실성 기반 안전 프로토콜, 메타 학습 기반 적응적 임계값 등이 유망한 연구 방향으로 제시된다.